
Asian Paints Alchemy 2026
Table of content:
- What Is A Doubly Linked List Data Structure?
- Creation Of A Doubly Linked List Data Structure
- Traversing A Doubly Linked List Data Structure
- Insertion Operations On Doubly Linked Lists (+Examples)
- Deletion Operations On Doubly Linked Lists (+Examples)
- Finding Length Of A Doubly Linked List Data Structure
- Searching For A Node Of Doubly Linked List Data Structure
- Complexity Analysis Of Key Operations On Doubly Linked Lists
- Real-World Applications Of Doubly Linked Lists Data Structure
- Advantages & Disadvantages Of Doubly Linked Lists
- Doubly Linked List Vs. Singly Linked Lists
- Doubly Linked List Vs. Circular Linked Lists
- Conclusion
- Frequently Asked Question
Doubly Linked List Data Structure | All Operations Explained (+Codes)
Explore doubly linked lists in detail, from creation and traversal to real-world applications. Understand their advantages, complexities, and key differences with other linked lists.
Doubly linked lists might sound like an advanced concept at first, but once you understand their structure and how they work, they become an indispensable tool in the world of data structures. Whether you're working with complex data, trying to optimize memory usage, or navigating lists in both directions, a doubly linked list is a versatile option. In this article, we’ll dive deep into the mechanics of doubly linked lists, explore their advantages, and even see how they stack up against other types of linked lists. By the end, you’ll have a solid understanding of how to create, traverse, and manipulate doubly linked lists in your own coding projects.
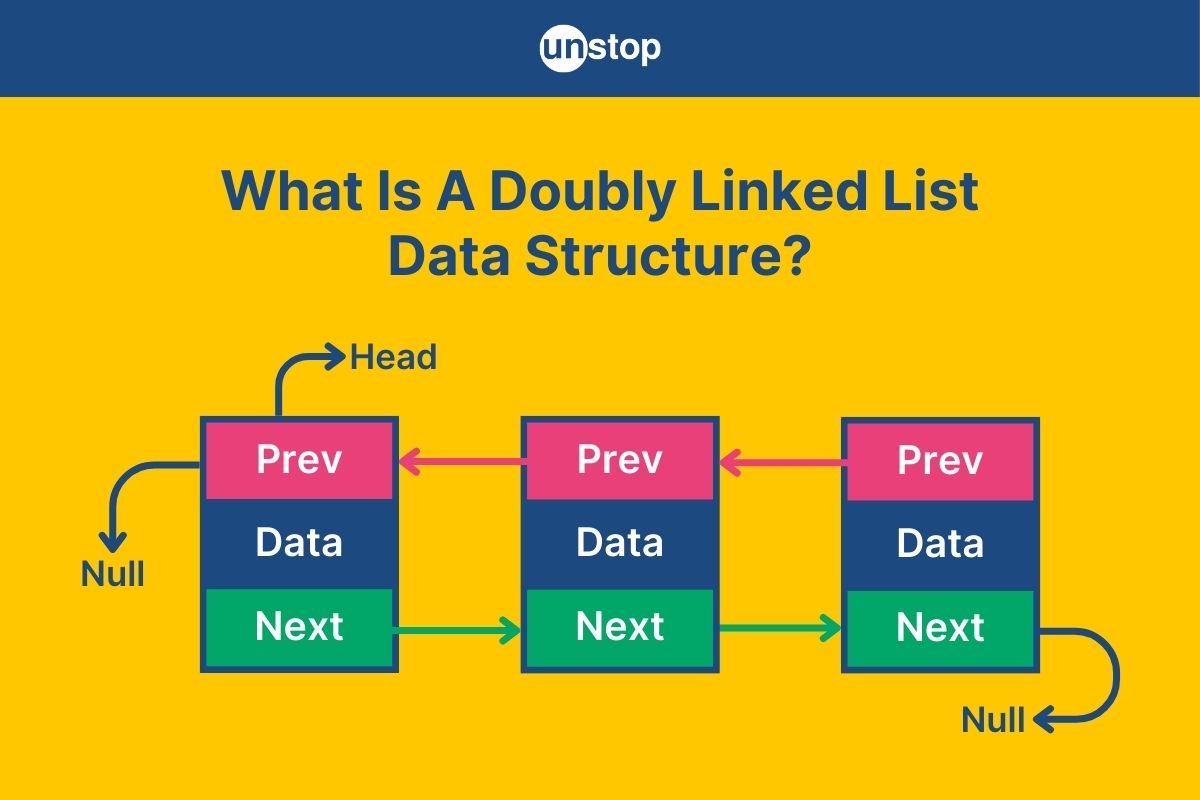
What Is A Doubly Linked List Data Structure?
A linked list is a data structure used to organize a collection of elements called nodes. Each node contains two parts: the data itself and a reference (or pointer) to the next node in the sequence. This structure allows for efficient insertion and deletion of elements, as there’s no need to shift other elements around like you would with arrays.
Now, imagine if each node could point not only to the next node but also to the previous one. This is where the doubly linked list comes in. In a doubly linked list, each node has two pointers:
- One pointer to the next node in the sequence.
- One pointer to the previous node in the sequence.
For example, think of a playlist on your music app. You can easily skip to the next song (forward traversal), but if you’ve skipped ahead too far, you might want to go back to the previous song (backward traversal). This bidirectional navigation is what makes doubly linked lists powerful.
How A Double Linked List Works
A doubly linked list is a type of linked list in which each node contains three main components:
- Data: The actual value or information stored in the node.
- Next Pointer: A reference to the next node in the list.
- Previous Pointer: A reference to the previous node in the list.
This is different from a singly linked list, where each node only points to the next node. The ability to traverse both forward and backward in a doubly linked list gives it an edge in applications requiring bidirectional navigation.
Here’s a simplified breakdown of how the structure looks:
- Head Node: The first node in the list with no previous pointer (its previous pointer is null).
- Tail Node: The last node in the list with no next pointer (its next pointer is null).
- Intermediate Nodes: These nodes connect to both the next node (via the next pointer) and the previous node (via the previous pointer).
Creation Of A Doubly Linked List Data Structure
Creating a doubly linked list involves allocating memory for nodes, linking them in both directions (forward and backward), and establishing a head node to start the list. Each node is dynamically created, and pointers are used to connect nodes together.
Here is how this works:
-
- Initialize the Head Node: The head node is the first node of the list. Initially, it can be set to null if the list is empty.
- Allocate Memory for Nodes: Each node is dynamically allocated memory using new (in C++). This ensures each node is created in the heap.
- Setting Pointers: The next pointer of a node refers to the node that comes after it in the list. The previous pointer refers to the node that precedes it in the list.
- Linking Nodes: When adding a new node to the list, the new node is linked by:
- Connecting its previous pointer to the current last node.
- Connecting the current last node’s next pointer to the new node.
- Memory Deallocation: In a doubly linked list, when a node is deleted, both its next and previous pointers need to be updated accordingly. The node's memory is deallocated when it's removed from the list.
Memory Representation Of A Doubly Linked List
A doubly linked list is stored as a series of dynamically allocated nodes. Each node consists of three parts: data, next pointer, and previous pointer. Memory is allocated for each node individually. In C++, this typically uses the new keyword. Here's how the memory is laid out:
- Head Node: Points to the first node of the list, with its previous pointer set to null.
- Tail Node: Points to null in its next pointer and its previous pointer points to the last node.
- Intermediate Nodes: Connect with both the next and previous nodes, creating a bidirectional structure.
Node Structure In Doubly Linked Lists
The structure of a node in a doubly linked list is simple but essential for understanding how the list operates. Here's a minimal C++ node structure:
struct Node {
int data; // Data stored in the node
Node* next; // Pointer to the next node
Node* prev; // Pointer to the previous node// Constructor to create a new node
Node(int data) {
data = data; // Direct assignment
next = nullptr;
prev = nullptr;
}
};
Each node holds:
- An integer data to store the value.
- A next pointer that points to the next node in the list.
- A prev pointer that points to the previous node.
This structure is used in the creation and traversal of a doubly linked list.
Creation Of Doubly Linked List Example
Let’s look at a C++ program example illustrating how to create a doubly linked list.
Code Example:
#include
using namespace std;
struct Node {
int data;
Node* next;
Node* prev;
Node(int newData) {
data = newData;
next = nullptr;
prev = nullptr;
}
};
int main() {
Node* head = new Node(10); // Create first node with data 10
Node* second = new Node(20); // Create second node with data 20
Node* third = new Node(30); // Create third node with data 30
// Linking the nodes
head->next = second; // head's next points to second node
second->prev = head; // second's previous points to head
second->next = third; // second's next points to third node
third->prev = second; // third's previous points to second
// Display the list
cout << "Doubly Linked List: " << endl;
Node* temp = head;
while (temp != nullptr) {
cout << temp->data << " ";
temp = temp->next;
}
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgp1c2luZyBuYW1lc3BhY2Ugc3RkOwoKc3RydWN0IE5vZGUgewppbnQgZGF0YTsKTm9kZSogbmV4dDsKTm9kZSogcHJldjsKCk5vZGUoaW50IG5ld0RhdGEpIHsKZGF0YSA9IG5ld0RhdGE7Cm5leHQgPSBudWxscHRyOwpwcmV2ID0gbnVsbHB0cjsKfQp9OwoKaW50IG1haW4oKSB7Ck5vZGUqIGhlYWQgPSBuZXcgTm9kZSgxMCk7IC8vIENyZWF0ZSBmaXJzdCBub2RlIHdpdGggZGF0YSAxMApOb2RlKiBzZWNvbmQgPSBuZXcgTm9kZSgyMCk7IC8vIENyZWF0ZSBzZWNvbmQgbm9kZSB3aXRoIGRhdGEgMjAKTm9kZSogdGhpcmQgPSBuZXcgTm9kZSgzMCk7IC8vIENyZWF0ZSB0aGlyZCBub2RlIHdpdGggZGF0YSAzMAoKLy8gTGlua2luZyB0aGUgbm9kZXMKaGVhZC0+bmV4dCA9IHNlY29uZDsgLy8gaGVhZCdzIG5leHQgcG9pbnRzIHRvIHNlY29uZCBub2RlCnNlY29uZC0+cHJldiA9IGhlYWQ7IC8vIHNlY29uZCdzIHByZXZpb3VzIHBvaW50cyB0byBoZWFkCnNlY29uZC0+bmV4dCA9IHRoaXJkOyAvLyBzZWNvbmQncyBuZXh0IHBvaW50cyB0byB0aGlyZCBub2RlCnRoaXJkLT5wcmV2ID0gc2Vjb25kOyAvLyB0aGlyZCdzIHByZXZpb3VzIHBvaW50cyB0byBzZWNvbmQKCi8vIERpc3BsYXkgdGhlIGxpc3QKY291dCA8PCAiRG91Ymx5IExpbmtlZCBMaXN0OiAiIDw8IGVuZGw7Ck5vZGUqIHRlbXAgPSBoZWFkOwp3aGlsZSAodGVtcCAhPSBudWxscHRyKSB7CmNvdXQgPDwgdGVtcC0+ZGF0YSA8PCAiICI7CnRlbXAgPSB0ZW1wLT5uZXh0Owp9CgpyZXR1cm4gMDsKfQ==
Output:
Doubly Linked List:
10 20 30
Code Explanation:
We begin the C++ code example by including the header file <iostream> for input/output operations.
- Node Structure: We define a structure, Node, containing three data members:
- data: An integer data type that stores the actual value of the node.
- next: A pointer of type Node* that points to the next node in the list.
- prev: A pointer of type Node* that points to the previous node in the list.
- The structure also contains a constructor Node() that takes an integer (data) as an argument. It initializes the data member with the passed value, and the next and prev members are initialized to nullptr.
- Memory Allocation: Three nodes (head, second, and third) are created using the new keyword, dynamically allocating memory for each node.
- In the main() function, we create and initialize three nodes with specific data values: 10, 20, and 30.
- Linking Nodes: We then link the nodes together using the next and prev pointers:
- head->next = second: The next pointer of the head node points to the second node.
- second->prev = head: The prev pointer of the second node points back to the head node.
- Similarly, the next and prev pointers for the second and third nodes are set.
- Displaying the List: To display the doubly linked list, we initialize a temporary pointer temp to head.
- We then traverse the list by following the next pointers from the head node to the last, printing the data of each node until temp becomes nullptr.
Traversing A Doubly Linked List Data Structure
In a doubly linked list, you can traverse the list in both forward and backward directions, thanks to the two pointers in each node (next and prev).
Forward Traversal:
- This involves starting from the head node and following the next pointers to move through the list. We continue traversing until we reach the last node, where the next pointer is nullptr.
- For Example: Start from the head node, print the data, and move to the next node using next.
Backward Traversal:
- This involves starting from the tail node and following the prev pointers to move backward through the list. We continue traversing until we reach the first node, where the prev pointer is nullptr.
- For Example: Start from the tail node, print the data, and move to the previous node using prev.
Code Example (Forward and Backward Traversal):
#include
using namespace std;
struct Node {
int data;
Node* next;
Node* prev;
Node(int newData) {
data = newData;
next = nullptr;
prev = nullptr;
}
};
int main() {
// Creating nodes
Node* head = new Node(10);
Node* second = new Node(20);
Node* third = new Node(30);
// Linking nodes
head->next = second;
second->prev = head;
second->next = third;
third->prev = second;
// Forward traversal
cout << "Forward Traversal: ";
Node* temp = head;
while (temp != nullptr) {
cout << temp->data << " ";
temp = temp->next;
}
cout << endl;
// Backward traversal (starting from the last node)
cout << "Backward Traversal: ";
temp = third; // Start from the tail node
while (temp != nullptr) {
cout << temp->data << " ";
temp = temp->prev;
}
cout << endl;
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgp1c2luZyBuYW1lc3BhY2Ugc3RkOwoKc3RydWN0IE5vZGUgewppbnQgZGF0YTsKTm9kZSogbmV4dDsKTm9kZSogcHJldjsKCk5vZGUoaW50IG5ld0RhdGEpIHsKZGF0YSA9IG5ld0RhdGE7Cm5leHQgPSBudWxscHRyOwpwcmV2ID0gbnVsbHB0cjsKfQp9OwoKaW50IG1haW4oKSB7Ci8vIENyZWF0aW5nIG5vZGVzCk5vZGUqIGhlYWQgPSBuZXcgTm9kZSgxMCk7Ck5vZGUqIHNlY29uZCA9IG5ldyBOb2RlKDIwKTsKTm9kZSogdGhpcmQgPSBuZXcgTm9kZSgzMCk7CgovLyBMaW5raW5nIG5vZGVzCmhlYWQtPm5leHQgPSBzZWNvbmQ7CnNlY29uZC0+cHJldiA9IGhlYWQ7CnNlY29uZC0+bmV4dCA9IHRoaXJkOwp0aGlyZC0+cHJldiA9IHNlY29uZDsKCi8vIEZvcndhcmQgdHJhdmVyc2FsCmNvdXQgPDwgIkZvcndhcmQgVHJhdmVyc2FsOiAiOwpOb2RlKiB0ZW1wID0gaGVhZDsKd2hpbGUgKHRlbXAgIT0gbnVsbHB0cikgewpjb3V0IDw8IHRlbXAtPmRhdGEgPDwgIiAiOwp0ZW1wID0gdGVtcC0+bmV4dDsKfQpjb3V0IDw8IGVuZGw7CgovLyBCYWNrd2FyZCB0cmF2ZXJzYWwgKHN0YXJ0aW5nIGZyb20gdGhlIGxhc3Qgbm9kZSkKY291dCA8PCAiQmFja3dhcmQgVHJhdmVyc2FsOiAiOwp0ZW1wID0gdGhpcmQ7IC8vIFN0YXJ0IGZyb20gdGhlIHRhaWwgbm9kZQp3aGlsZSAodGVtcCAhPSBudWxscHRyKSB7CmNvdXQgPDwgdGVtcC0+ZGF0YSA8PCAiICI7CnRlbXAgPSB0ZW1wLT5wcmV2Owp9CmNvdXQgPDwgZW5kbDsKCnJldHVybiAwOwp9
Output:
Forward Traversal: 10 20 30
Backward Traversal: 30 20 10
Code Explanation:
We begin by creating a doubly linked list with three nodes and link the nodes like in the previous example. We then show how to traverse the list forward as well as backward both marked in code comments.
In forward traversal:
- Starting Point: We first initialize a temporary pointer temp to the head of the doubly linked list (i.e., the first node in the list).
- Traversal Loop: Then, we use a while loop to traverse the list using the next pointer of each node. The condition for the loop (while (temp != nullptr)) ensures we continue until the pointer reaches the end of the list (i.e., nullptr).
- Accessing Data: Inside the loop, we access the data of the current node using the ‘this’ pointer and print it using the cout statement.
- Moving Forward: After printing the current node's data, temp is updated to point to the next node using temp = temp->next.
- In this example, the temp pointer initially points to head (10), and moves to the second (20), and then the third (30), before reaching the nullptr and exiting the loop.
In backward traversal:
- Starting Point: We start the traversal from the last node in the list (third in this case). To achieve this, the pointer temp is set to third (i.e., temp = third).
- Traversal Loop: We loop through the list using the prev pointer of each node. The condition for the loop (while (temp != nullptr)) ensures we continue until the pointer reaches the beginning of the list (i.e., nullptr).
- Accessing Data: The data of the current node is printed using temp->data, just as in forward traversal.
- Moving Backward: After printing the current node's data, temp is updated to point to the previous node using temp = temp->prev.
- In this example, the temp points to the third node (printing 30), then moves to the second (20), and then to the head (10) before reaching the nullptr and completing the loop.
Insertion Operations On Doubly Linked Lists (+Examples)
Insertion operations in a doubly linked list allow us to add new nodes at various positions within the list. With its bidirectional pointers, a doubly linked list supports three primary insertion operations: at the beginning, at the end, and at a specific position. These operations enable dynamic updates to the list without shifting other elements, making them highly efficient compared to arrays.
Insertion At Beginning Of A Doubly Linked List
Inserting a node at the beginning of a doubly linked list means adding a new node before the first node. This newly added node becomes the head of the list. The operation ensures that the list is updated while maintaining its doubly linked structure.
How It Works– To insert a node at the beginning of a doubly linked list:
- Create a new node using dynamic memory allocation.
- Assign the data value to the new node.
- Update the next pointer of the new node to point to the current head node.
- Update the prev pointer of the current head node to point to the new node (if the list is not empty).
- Update the head pointer to point to the new node.
Code Example:
#include
using namespace std;
struct Node {
int data;
Node* next;
Node* prev;
Node(int newData) {
data = newData;
next = nullptr;
prev = nullptr;
}
};
void insertAtBeginning(Node*& head, int newData) {
Node* newNode = new Node(newData);
if (head != nullptr) {
newNode->next = head;
head->prev = newNode;
}
head = newNode;
}
void displayList(Node* head) {
Node* temp = head;
while (temp != nullptr) {
cout << temp->data << " ";
temp = temp->next;
}
}
int main() {
Node* head = nullptr;
insertAtBeginning(head, 30);
insertAtBeginning(head, 20);
insertAtBeginning(head, 10);
displayList(head);
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgp1c2luZyBuYW1lc3BhY2Ugc3RkOwoKc3RydWN0IE5vZGUgewppbnQgZGF0YTsKTm9kZSogbmV4dDsKTm9kZSogcHJldjsKCk5vZGUoaW50IG5ld0RhdGEpIHsKZGF0YSA9IG5ld0RhdGE7Cm5leHQgPSBudWxscHRyOwpwcmV2ID0gbnVsbHB0cjsKfQp9OwoKdm9pZCBpbnNlcnRBdEJlZ2lubmluZyhOb2RlKiYgaGVhZCwgaW50IG5ld0RhdGEpIHsKTm9kZSogbmV3Tm9kZSA9IG5ldyBOb2RlKG5ld0RhdGEpOwppZiAoaGVhZCAhPSBudWxscHRyKSB7Cm5ld05vZGUtPm5leHQgPSBoZWFkOwpoZWFkLT5wcmV2ID0gbmV3Tm9kZTsKfQpoZWFkID0gbmV3Tm9kZTsKfQoKdm9pZCBkaXNwbGF5TGlzdChOb2RlKiBoZWFkKSB7Ck5vZGUqIHRlbXAgPSBoZWFkOwp3aGlsZSAodGVtcCAhPSBudWxscHRyKSB7CmNvdXQgPDwgdGVtcC0+ZGF0YSA8PCAiICI7CnRlbXAgPSB0ZW1wLT5uZXh0Owp9Cn0KCmludCBtYWluKCkgewpOb2RlKiBoZWFkID0gbnVsbHB0cjsKaW5zZXJ0QXRCZWdpbm5pbmcoaGVhZCwgMzApOwppbnNlcnRBdEJlZ2lubmluZyhoZWFkLCAyMCk7Cmluc2VydEF0QmVnaW5uaW5nKGhlYWQsIDEwKTsKCmRpc3BsYXlMaXN0KGhlYWQpOwoKcmV0dXJuIDA7Cn0=
Output:
10 20 30
Code Explanation:
We begin by defining a structure, Node, containing three elements: data, next, and prev. It also has a constructor to initialize the members when a new node is created.
- Insertion Process: We then define a function, insertAtBeginning(), to insert nodes to the beginning of the list. Inside the function:
- We first dynamically allocate a new node using the new operator, i.e., new Node(newData). That is, the given newData is stored in the node, and its next and prev pointers are initialized to nullptr (via the constructor).
- Check if the List is Empty: Then, we use an if-statement to check if the head pointer is null. If the head is nullptr, this means the list is empty. The new node becomes the first and only node, so the head pointer is updated to point to the new node.
- Update Pointers for a Non-Empty List: If the list is not empty, the next pointer of the new node is updated to point to the current head.
- The prev pointer of the current head is updated to point back to the new node.
- Finally, the head pointer is updated to point to the new node, making it the new first node of the list.
- Traversal & Printing: We also define a displayList() function that traverses the list from the head node to the end, printing the data values of each node.
- In the main() function, we initialize the head pointer to nullptr.
- Then, we use call the insertAtBeginning() function to insert three nodes with the values 30, 20, and 10 at the beginning of the list.
- Finally, we display the list using displayList().
Insertion At The End Of Doubly Linked List (+Example)
Inserting a node at the end of a doubly linked list means adding a new node after the last node. This newly added node becomes the tail of the list. The operation ensures the list is updated while maintaining its doubly linked structure.
How It Works– To insert a node at the end of a doubly linked list:
- Create a new node using dynamic memory allocation.
- Assign the data value to the new node.
- Check if the list is empty. If the list is empty, update the head and tail pointers to point to the new node.
- If the list is not empty, traverse the list to find the last node.
- Update the next pointer of the current last node to point to the new node.
- Update the prev pointer of the new node to point to the last node.
- Update the tail pointer to point to the new node.
Code Example:
#include
using namespace std;
struct Node {
int data;
Node* next;
Node* prev;
Node(int newData) {
data = newData;
next = nullptr;
prev = nullptr;
}
};
void insertAtEnd(Node*& head, Node*& tail, int newData) {
Node* newNode = new Node(newData);
if (head == nullptr) {
head = newNode;
tail = newNode;
} else {
tail->next = newNode;
newNode->prev = tail;
tail = newNode;
}
}
void displayList(Node* head) {
Node* temp = head;
while (temp != nullptr) {
cout << temp->data << " ";
temp = temp->next;
}
cout << endl;
}
int main() {
Node* head = nullptr;
Node* tail = nullptr;
insertAtEnd(head, tail, 10);
insertAtEnd(head, tail, 20);
insertAtEnd(head, tail, 30);
displayList(head);
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgp1c2luZyBuYW1lc3BhY2Ugc3RkOwoKc3RydWN0IE5vZGUgewppbnQgZGF0YTsKTm9kZSogbmV4dDsKTm9kZSogcHJldjsKCk5vZGUoaW50IG5ld0RhdGEpIHsKZGF0YSA9IG5ld0RhdGE7Cm5leHQgPSBudWxscHRyOwpwcmV2ID0gbnVsbHB0cjsKfQp9OwoKdm9pZCBpbnNlcnRBdEVuZChOb2RlKiYgaGVhZCwgTm9kZSomIHRhaWwsIGludCBuZXdEYXRhKSB7Ck5vZGUqIG5ld05vZGUgPSBuZXcgTm9kZShuZXdEYXRhKTsKCmlmIChoZWFkID09IG51bGxwdHIpIHsKaGVhZCA9IG5ld05vZGU7CnRhaWwgPSBuZXdOb2RlOwp9IGVsc2Ugewp0YWlsLT5uZXh0ID0gbmV3Tm9kZTsKbmV3Tm9kZS0+cHJldiA9IHRhaWw7CnRhaWwgPSBuZXdOb2RlOwp9Cn0KCnZvaWQgZGlzcGxheUxpc3QoTm9kZSogaGVhZCkgewpOb2RlKiB0ZW1wID0gaGVhZDsKd2hpbGUgKHRlbXAgIT0gbnVsbHB0cikgewpjb3V0IDw8IHRlbXAtPmRhdGEgPDwgIiAiOwp0ZW1wID0gdGVtcC0+bmV4dDsKfQpjb3V0IDw8IGVuZGw7Cn0KCmludCBtYWluKCkgewpOb2RlKiBoZWFkID0gbnVsbHB0cjsKTm9kZSogdGFpbCA9IG51bGxwdHI7Cmluc2VydEF0RW5kKGhlYWQsIHRhaWwsIDEwKTsKaW5zZXJ0QXRFbmQoaGVhZCwgdGFpbCwgMjApOwppbnNlcnRBdEVuZChoZWFkLCB0YWlsLCAzMCk7CgpkaXNwbGF5TGlzdChoZWFkKTsKCnJldHVybiAwOwp9
Output:
10 20 30
Code Explanation:
We begin by defining the Node structure, which contains three elements: data (integer), next (pointer to the next node), and prev (pointer to the previous node). The constructor initializes these components when a new node is created.
- Insertion Process: The insertAtEnd() function handles inserting a new node at the end of the list.
- Create the New Node: A new node is dynamically created using the new operator, with the given data.
- Check if the List is Empty: If the list is empty (i.e., the head pointer is nullptr), both the head and tail pointers are updated to point to the new node.
- Non-Empty List: If the list is not empty, we update the next pointer of the current tail node to point to the new node.
- The prev pointer of the new node is updated to point to the current tail.
- Finally, the tail pointer is updated to the new node, making it the last node of the list.
- Traversal & Printing: The displayList() function is used to traverse the list from the head node to the end, printing the data of each node.
- Main Function: We initialize the head and tail pointers to nullptr. Then, we call insertAtEnd() three times to insert nodes with data values 10, 20, and 30 at the end of the list. Finally, we display the list using displayList().
Insertion At A Specific Position In Doubly Linked List
Inserting a node at a specific position in a doubly linked list means adding a new node at any given location in the list (e.g., after the 2nd node). This operation helps maintain the order of the list while preserving its doubly linked structure.
How It Works– To insert a node at a specific position in a doubly linked list:
- Create a new node using dynamic memory allocation.
- Traverse the list to reach the desired position.
- Update the next and prev pointers of the surrounding nodes to link the new node at the specified position.
- Update the next and prev pointers of the new node to maintain the doubly linked structure.
Code Example:
#include
using namespace std;
struct Node {
int data;
Node* next;
Node* prev;
Node(int newData) {
data = newData;
next = nullptr;
prev = nullptr;
}
};
void insertAtPosition(Node*& head, int position, int newData) {
Node* newNode = new Node(newData);
if (position == 1) {
newNode->next = head;
if (head != nullptr) {
head->prev = newNode;
}
head = newNode;
return;
}
Node* temp = head;
int count = 1;
while (temp != nullptr && count < position - 1) {
temp = temp->next;
count++;
}
if (temp == nullptr) {
cout << "Position out of bounds." << endl;
return;
}
newNode->next = temp->next;
if (temp->next != nullptr) {
temp->next->prev = newNode;
}
temp->next = newNode;
newNode->prev = temp;
}
void displayList(Node* head) {
Node* temp = head;
while (temp != nullptr) {
cout << temp->data << " ";
temp = temp->next;
}
cout << endl;
}
int main() {
Node* head = nullptr;
insertAtPosition(head, 1, 10);
insertAtPosition(head, 2, 20);
insertAtPosition(head, 2, 15);
insertAtPosition(head, 4, 30);
displayList(head);
return 0;
}
I2luY2x1ZGU8aW9zdHJlYW0+CnVzaW5nIG5hbWVzcGFjZSBzdGQ7CgpzdHJ1Y3QgTm9kZSB7CmludCBkYXRhOwpOb2RlKiBuZXh0OwpOb2RlKiBwcmV2OwoKTm9kZShpbnQgbmV3RGF0YSkgewpkYXRhID0gbmV3RGF0YTsKbmV4dCA9IG51bGxwdHI7CnByZXYgPSBudWxscHRyOwp9Cn07Cgp2b2lkIGluc2VydEF0UG9zaXRpb24oTm9kZSomIGhlYWQsIGludCBwb3NpdGlvbiwgaW50IG5ld0RhdGEpIHsKTm9kZSogbmV3Tm9kZSA9IG5ldyBOb2RlKG5ld0RhdGEpOwoKaWYgKHBvc2l0aW9uID09IDEpIHsKbmV3Tm9kZS0+bmV4dCA9IGhlYWQ7CmlmIChoZWFkICE9IG51bGxwdHIpIHsKaGVhZC0+cHJldiA9IG5ld05vZGU7Cn0KaGVhZCA9IG5ld05vZGU7CnJldHVybjsKfQoKTm9kZSogdGVtcCA9IGhlYWQ7CmludCBjb3VudCA9IDE7CndoaWxlICh0ZW1wICE9IG51bGxwdHIgJiYgY291bnQgPCBwb3NpdGlvbiAtIDEpIHsKdGVtcCA9IHRlbXAtPm5leHQ7CmNvdW50Kys7Cn0KCmlmICh0ZW1wID09IG51bGxwdHIpIHsKY291dCA8PCAiUG9zaXRpb24gb3V0IG9mIGJvdW5kcy4iIDw8IGVuZGw7CnJldHVybjsKfQoKbmV3Tm9kZS0+bmV4dCA9IHRlbXAtPm5leHQ7CmlmICh0ZW1wLT5uZXh0ICE9IG51bGxwdHIpIHsKdGVtcC0+bmV4dC0+cHJldiA9IG5ld05vZGU7Cn0KCnRlbXAtPm5leHQgPSBuZXdOb2RlOwpuZXdOb2RlLT5wcmV2ID0gdGVtcDsKfQoKdm9pZCBkaXNwbGF5TGlzdChOb2RlKiBoZWFkKSB7Ck5vZGUqIHRlbXAgPSBoZWFkOwp3aGlsZSAodGVtcCAhPSBudWxscHRyKSB7CmNvdXQgPDwgdGVtcC0+ZGF0YSA8PCAiICI7CnRlbXAgPSB0ZW1wLT5uZXh0Owp9CmNvdXQgPDwgZW5kbDsKfQoKaW50IG1haW4oKSB7Ck5vZGUqIGhlYWQgPSBudWxscHRyOwoKaW5zZXJ0QXRQb3NpdGlvbihoZWFkLCAxLCAxMCk7Cmluc2VydEF0UG9zaXRpb24oaGVhZCwgMiwgMjApOwppbnNlcnRBdFBvc2l0aW9uKGhlYWQsIDIsIDE1KTsKaW5zZXJ0QXRQb3NpdGlvbihoZWFkLCA0LCAzMCk7CgpkaXNwbGF5TGlzdChoZWFkKTsKCnJldHVybiAwOwp9
Output:
10 15 20 30
Code Explanation:
We begin by defining a structure, Node, containing three elements: data, next, and prev, with a constructor to initialize the components when a new node is created.
- Insertion Process: We define a function, insertAtPosition(), to insert a node at a specific position in the list. Inside the function:
- A new node is dynamically allocated using new Node(newData), and its next and prev pointers are initialized to nullptr (via the constructor).
- If the position is 1 (i.e., inserting at the beginning), the new node is placed at the start of the list, with its next pointer pointing to the current head and the head pointer updated to the new node.
- For any other position, we traverse the list until we reach the node just before the desired position.
- The next pointer of the new node is updated to point to the node that comes after the current node, and the prev pointer of that node is updated to point back to the new node.
- Finally, the current node's next pointer is updated to point to the new node, and the new node's prev pointer is updated to point to the current node.
- Traversal & Printing: The displayList() function is used to print the entire list by traversing from the head node to the end. The nodes' data values are printed as we go along.
- In the main() function, we initialize the head pointer to nullptr and insert nodes at specific positions: first at position 1, then at position 2, and later, at positions 2 and 4. We then display the list to show the final arrangement.
Deletion Operations On Doubly Linked Lists (+Examples)
Doubly linked lists offer flexibility in deletion, allowing removal from the beginning, end, or any specific position with minimal pointer adjustments. Let's explore these operations step by step.
Deletion From The Beginning Of Doubly Linked List
Deleting a node from the beginning of a doubly linked list means removing the head node. This operation shifts the head pointer to the next node, ensuring the doubly linked structure is maintained.
How It Works– To delete a node from the beginning of a doubly linked list:
- Check if the list is empty (head is null).
- If the list is not empty, update the head pointer to point to the next node.
- Set the prev pointer of the new head node to null, as it will now be the first node.
- Delete the original head node to free memory.
Code Example:
#include
using namespace std;
struct Node {
int data;
Node* next;
Node* prev;
Node(int newData) {
data = newData;
next = nullptr;
prev = nullptr;
}
};
void deleteFromBeginning(Node*& head) {
if (head == nullptr) {
cout << "List is empty." << endl;
return;
}
Node* temp = head;
head = head->next;
if (head != nullptr) {
head->prev = nullptr;
}
delete temp;
}
void displayList(Node* head) {
Node* temp = head;
while (temp != nullptr) {
cout << temp->data << " ";
temp = temp->next;
}
cout << endl;
}
int main() {
Node* head = nullptr;
head = new Node(10);
head->next = new Node(20);
head->next->prev = head;
head->next->next = new Node(30);
head->next->next->prev = head->next;
deleteFromBeginning(head);
displayList(head);
return 0;
}
I2luY2x1ZGU8aW9zdHJlYW0+CnVzaW5nIG5hbWVzcGFjZSBzdGQ7CgpzdHJ1Y3QgTm9kZSB7CmludCBkYXRhOwpOb2RlKiBuZXh0OwpOb2RlKiBwcmV2OwoKTm9kZShpbnQgbmV3RGF0YSkgewpkYXRhID0gbmV3RGF0YTsKbmV4dCA9IG51bGxwdHI7CnByZXYgPSBudWxscHRyOwp9Cn07Cgp2b2lkIGRlbGV0ZUZyb21CZWdpbm5pbmcoTm9kZSomIGhlYWQpIHsKaWYgKGhlYWQgPT0gbnVsbHB0cikgewpjb3V0IDw8ICJMaXN0IGlzIGVtcHR5LiIgPDwgZW5kbDsKcmV0dXJuOwp9CgpOb2RlKiB0ZW1wID0gaGVhZDsKaGVhZCA9IGhlYWQtPm5leHQ7CmlmIChoZWFkICE9IG51bGxwdHIpIHsKaGVhZC0+cHJldiA9IG51bGxwdHI7Cn0KZGVsZXRlIHRlbXA7Cn0KCnZvaWQgZGlzcGxheUxpc3QoTm9kZSogaGVhZCkgewpOb2RlKiB0ZW1wID0gaGVhZDsKd2hpbGUgKHRlbXAgIT0gbnVsbHB0cikgewpjb3V0IDw8IHRlbXAtPmRhdGEgPDwgIiAiOwp0ZW1wID0gdGVtcC0+bmV4dDsKfQpjb3V0IDw8IGVuZGw7Cn0KCmludCBtYWluKCkgewpOb2RlKiBoZWFkID0gbnVsbHB0cjsKaGVhZCA9IG5ldyBOb2RlKDEwKTsKCmhlYWQtPm5leHQgPSBuZXcgTm9kZSgyMCk7CmhlYWQtPm5leHQtPnByZXYgPSBoZWFkOwpoZWFkLT5uZXh0LT5uZXh0ID0gbmV3IE5vZGUoMzApOwpoZWFkLT5uZXh0LT5uZXh0LT5wcmV2ID0gaGVhZC0+bmV4dDsKCmRlbGV0ZUZyb21CZWdpbm5pbmcoaGVhZCk7CmRpc3BsYXlMaXN0KGhlYWQpOwoKcmV0dXJuIDA7Cn0=
Output:
20 30
Code Explanation:
We begin by defining a structure, Node, containing three elements: data, next, and prev, with a constructor to initialize the components when a new node is created.
- Deletion Process: We define a function, deleteFromBeginning(), to delete the first node in the list. Inside the function:
- First, we check if the list is empty by verifying if the head pointer is null. If the list is empty, we simply print a message and exit.
- If the list is not empty, we update the head pointer to point to the next node (the second node in the list).
- We then check if the new head is not null and update its prev pointer to null, as it will now be the first node.
- Finally, we delete the original head node using the delete operator to free the allocated memory.
- Traversal & Printing: The displayList() function is used to print the entire list by traversing from the head node to the end. The nodes' data values are printed as we go along.
- In the main() function, we create a sample doubly linked list with three nodes. We then call deleteFromBeginning() to remove the first node from the list and display the updated list.
Deletion From The End Of A Doubly Linked List
Deleting a node from the end of a doubly linked list means removing the last node. This operation updates the tail pointer to the previous node while ensuring the doubly linked structure is maintained.
How It Works– To delete a node from the end of a doubly linked list:
- Check if the list is empty (i.e., head is nullptr).
- If the list contains only one node, delete it and set head to nullptr.
- Otherwise, update the tail pointer to point to the second-last node.
- Set the next pointer of the new last node to nullptr.
- Delete the original last node to free memory.
Code Example:
#include
using namespace std;
struct Node {
int data;
Node* next;
Node* prev;
Node(int newData) {
data = newData;
next = nullptr;
prev = nullptr;
}
};
void deleteFromEnd(Node*& head) {
if (head == nullptr) {
cout << "List is empty." << endl;
return;
}
if (head->next == nullptr) {
delete head;
head = nullptr;
return;
}
Node* temp = head;
while (temp->next != nullptr) {
temp = temp->next;
}
temp->prev->next = nullptr;
delete temp;
}
void displayList(Node* head) {
Node* temp = head;
while (temp != nullptr) {
cout << temp->data << " ";
temp = temp->next;
}
cout << endl;
}
int main() {
Node* head = new Node(10);
head->next = new Node(20);
head->next->prev = head;
head->next->next = new Node(30);
head->next->next->prev = head->next;
deleteFromEnd(head);
displayList(head);
return 0;
}
I2luY2x1ZGU8aW9zdHJlYW0+CnVzaW5nIG5hbWVzcGFjZSBzdGQ7CgpzdHJ1Y3QgTm9kZSB7CmludCBkYXRhOwpOb2RlKiBuZXh0OwpOb2RlKiBwcmV2OwoKTm9kZShpbnQgbmV3RGF0YSkgewpkYXRhID0gbmV3RGF0YTsKbmV4dCA9IG51bGxwdHI7CnByZXYgPSBudWxscHRyOwp9Cn07Cgp2b2lkIGRlbGV0ZUZyb21FbmQoTm9kZSomIGhlYWQpIHsKaWYgKGhlYWQgPT0gbnVsbHB0cikgewpjb3V0IDw8ICJMaXN0IGlzIGVtcHR5LiIgPDwgZW5kbDsKcmV0dXJuOwp9CgppZiAoaGVhZC0+bmV4dCA9PSBudWxscHRyKSB7CmRlbGV0ZSBoZWFkOwpoZWFkID0gbnVsbHB0cjsKcmV0dXJuOwp9CgpOb2RlKiB0ZW1wID0gaGVhZDsKd2hpbGUgKHRlbXAtPm5leHQgIT0gbnVsbHB0cikgewp0ZW1wID0gdGVtcC0+bmV4dDsKfQp0ZW1wLT5wcmV2LT5uZXh0ID0gbnVsbHB0cjsKZGVsZXRlIHRlbXA7Cn0KCnZvaWQgZGlzcGxheUxpc3QoTm9kZSogaGVhZCkgewpOb2RlKiB0ZW1wID0gaGVhZDsKd2hpbGUgKHRlbXAgIT0gbnVsbHB0cikgewpjb3V0IDw8IHRlbXAtPmRhdGEgPDwgIiAiOwp0ZW1wID0gdGVtcC0+bmV4dDsKfQpjb3V0IDw8IGVuZGw7Cn0KCmludCBtYWluKCkgewpOb2RlKiBoZWFkID0gbmV3IE5vZGUoMTApOwpoZWFkLT5uZXh0ID0gbmV3IE5vZGUoMjApOwpoZWFkLT5uZXh0LT5wcmV2ID0gaGVhZDsKaGVhZC0+bmV4dC0+bmV4dCA9IG5ldyBOb2RlKDMwKTsKaGVhZC0+bmV4dC0+bmV4dC0+cHJldiA9IGhlYWQtPm5leHQ7CgpkZWxldGVGcm9tRW5kKGhlYWQpOwpkaXNwbGF5TGlzdChoZWFkKTsKCnJldHVybiAwOwp9
Output:
10 20
Code Explanation:
We define a Node structure containing three members: data (stores the value), next (points to the next node), and prev (points to the previous node). It also has a constructor to initialize the members when a new node is created.
- Deletion Process: We then define the deleteFromEnd() function to delete the node from the end of the linked list. Inside:
- First, we check if the list is empty (head == nullptr) using relational equality operator. If it is, we print a message containing the string– “List is empty” and return.
- If the list contains only one node (i.e. next of head is null), we delete head and set head = nullptr.
- Otherwise, we traverse to the last node using a temporary pointer (temp).
- Once at the last node, we update the next pointer of the second-last node to nullptr, effectively removing the last node from the list.
- We delete the original last node to free memory.
- Traversal & Printing (displayList() function): This function prints the list by traversing from the head node to the end.
- Main Function Execution: We create a sample doubly linked list with three nodes (10 → 20 → 30). Then, we call deleteFromEnd() to remove the last node (30).
- Finally, we display the updated list, which now contains 10 → 20.
Deletion From A Specific Position In A Doubly Linked List
Deleting a node from a specific position in a doubly linked list means removing the node at a given index while ensuring that the list remains correctly linked.
How It Works– To delete a node at a specific position:
- Check if the list is empty (head is nullptr).
- If the position is 1, delete the first node (same as deletion from the beginning).
- Traverse to the node at the given position.
- Adjust the next and prev pointers of the adjacent nodes to bypass the node being deleted.
- Delete the node to free memory.
Code Example:
#include
using namespace std;
struct Node {
int data;
Node* next;
Node* prev;
Node(int newData) {
data = newData;
next = nullptr;
prev = nullptr;
}
};
void deleteFromBeginning(Node*& head){
if (head == nullptr){
cout << "List is already empty." << endl;
return;
}
Node* temp = head;
head = head->next;
if (head != nullptr) {
head->prev = nullptr;
}
delete temp;}
void deleteFromPosition(Node*& head, int position) {
if (head == nullptr || position <= 0) {
cout << "Invalid position or empty list." << endl;
return;
}
if (position == 1) {
deleteFromBeginning(head);
return;
}
Node* temp = head;
for (int i = 1; temp != nullptr && i < position; i++) {
temp = temp->next;
}
if (temp == nullptr) {
cout << "Position out of bounds." << endl;
return;
}
if (temp->next != nullptr) {
temp->next->prev = temp->prev;
}
if (temp->prev != nullptr) {
temp->prev->next = temp->next;
}
delete temp;
}
void displayList(Node* head) {
Node* temp = head;
while (temp != nullptr) {
cout << temp->data << " ";
temp = temp->next;
}
cout << endl;
}
int main() {
Node* head = new Node(10);
head->next = new Node(20);
head->next->prev = head;
head->next->next = new Node(30);
head->next->next->prev = head->next;
deleteFromPosition(head, 2);
displayList(head);
return 0;
}
I2luY2x1ZGU8aW9zdHJlYW0+CnVzaW5nIG5hbWVzcGFjZSBzdGQ7CgpzdHJ1Y3QgTm9kZSB7CmludCBkYXRhOwpOb2RlKiBuZXh0OwpOb2RlKiBwcmV2OwoKTm9kZShpbnQgbmV3RGF0YSkgewpkYXRhID0gbmV3RGF0YTsKbmV4dCA9IG51bGxwdHI7CnByZXYgPSBudWxscHRyOwp9Cn07Cgp2b2lkIGRlbGV0ZUZyb21CZWdpbm5pbmcoTm9kZSomIGhlYWQpewppZiAoaGVhZCA9PSBudWxscHRyKXsKY291dCA8PCAiTGlzdCBpcyBhbHJlYWR5IGVtcHR5LiIgPDwgZW5kbDsKcmV0dXJuOwp9Ck5vZGUqIHRlbXAgPSBoZWFkOwpoZWFkID0gaGVhZC0+bmV4dDsKaWYgKGhlYWQgIT0gbnVsbHB0cikgewpoZWFkLT5wcmV2ID0gbnVsbHB0cjsKfQpkZWxldGUgdGVtcDt9Cgp2b2lkIGRlbGV0ZUZyb21Qb3NpdGlvbihOb2RlKiYgaGVhZCwgaW50IHBvc2l0aW9uKSB7CmlmIChoZWFkID09IG51bGxwdHIgfHwgcG9zaXRpb24gPD0gMCkgewpjb3V0IDw8ICJJbnZhbGlkIHBvc2l0aW9uIG9yIGVtcHR5IGxpc3QuIiA8PCBlbmRsOwpyZXR1cm47Cn0KCmlmIChwb3NpdGlvbiA9PSAxKSB7CmRlbGV0ZUZyb21CZWdpbm5pbmcoaGVhZCk7CnJldHVybjsKfQoKTm9kZSogdGVtcCA9IGhlYWQ7CmZvciAoaW50IGkgPSAxOyB0ZW1wICE9IG51bGxwdHIgJiYgaSA8IHBvc2l0aW9uOyBpKyspIHsKdGVtcCA9IHRlbXAtPm5leHQ7Cn0KaWYgKHRlbXAgPT0gbnVsbHB0cikgewpjb3V0IDw8ICJQb3NpdGlvbiBvdXQgb2YgYm91bmRzLiIgPDwgZW5kbDsKcmV0dXJuOwp9CgppZiAodGVtcC0+bmV4dCAhPSBudWxscHRyKSB7CnRlbXAtPm5leHQtPnByZXYgPSB0ZW1wLT5wcmV2Owp9CmlmICh0ZW1wLT5wcmV2ICE9IG51bGxwdHIpIHsKdGVtcC0+cHJldi0+bmV4dCA9IHRlbXAtPm5leHQ7Cn0KZGVsZXRlIHRlbXA7Cn0KCnZvaWQgZGlzcGxheUxpc3QoTm9kZSogaGVhZCkgewpOb2RlKiB0ZW1wID0gaGVhZDsKd2hpbGUgKHRlbXAgIT0gbnVsbHB0cikgewpjb3V0IDw8IHRlbXAtPmRhdGEgPDwgIiAiOwp0ZW1wID0gdGVtcC0+bmV4dDsKfQpjb3V0IDw8IGVuZGw7Cn0KCmludCBtYWluKCkgewpOb2RlKiBoZWFkID0gbmV3IE5vZGUoMTApOwpoZWFkLT5uZXh0ID0gbmV3IE5vZGUoMjApOwpoZWFkLT5uZXh0LT5wcmV2ID0gaGVhZDsKaGVhZC0+bmV4dC0+bmV4dCA9IG5ldyBOb2RlKDMwKTsKaGVhZC0+bmV4dC0+bmV4dC0+cHJldiA9IGhlYWQtPm5leHQ7CgpkZWxldGVGcm9tUG9zaXRpb24oaGVhZCwgMik7CmRpc3BsYXlMaXN0KGhlYWQpOwoKcmV0dXJuIDA7Cn0=
Output:
10 30
Code Explanation:
We define a Node struct to create the doubly linked list node with data, next, and prev pointers. We also define a dislplayList() function and a deleteFromBeginning() function like in the earlier example.
- Deletion Process: Then, we define a deleteFromPosition() function to delete elements from the end of the list. Inside:
- First, we check if the list is empty. If the list is empty or the position is invalid (<= 0), we print an error message.
- We then check if the position is 1, if it is, we call the deleteFromBeginning() function.
- If the position is greater than 1, we use a temp pointer variable and set it to head. Then, we use it to traverse the list to locate the node at the given position.
- If the position index is out of bounds, we print an error message.
- Adjust the prev and next pointers of adjacent nodes to bypass the node being deleted.
- Delete the node to free memory.
- Main Function Execution: We create a sample doubly linked list (10 → 20 → 30). Then, we call deleteFromPosition(head, 2), removing 20.
- Finally, we call the displayList() function to print the updated list, which now contains 10 → 30.
Finding Length Of A Doubly Linked List Data Structure
Finding the length of a doubly linked list means counting the number of nodes present in the list. This can be done by traversing the list from the head to the last node while maintaining a count.
How It Works:
- Start from the head node.
- Initialize a counter to 0.
- Traverse through the list using the next pointer, incrementing the counter for each node.
- Stop when the pointer reaches nullptr.
- The final counter value represents the length of the list.
Code Example:
#include
using namespace std;
struct Node {
int data;
Node* next;
Node* prev;
Node(int newData) {
data = newData;
next = nullptr;
prev = nullptr;
}
};
int getLength(Node* head) {
int count = 0;
Node* temp = head;
while (temp != nullptr) {
count++;
temp = temp->next;
}
return count;
}
int main() {
Node* head = new Node(10);
head->next = new Node(20);
head->next->prev = head;
head->next->next = new Node(30);
head->next->next->prev = head->next;
cout << "Length of Doubly Linked List: " << getLength(head) << endl;
return 0;
}
I2luY2x1ZGU8aW9zdHJlYW0+CnVzaW5nIG5hbWVzcGFjZSBzdGQ7CgpzdHJ1Y3QgTm9kZSB7CmludCBkYXRhOwpOb2RlKiBuZXh0OwpOb2RlKiBwcmV2OwoKTm9kZShpbnQgbmV3RGF0YSkgewpkYXRhID0gbmV3RGF0YTsKbmV4dCA9IG51bGxwdHI7CnByZXYgPSBudWxscHRyOwp9Cn07CgppbnQgZ2V0TGVuZ3RoKE5vZGUqIGhlYWQpIHsKaW50IGNvdW50ID0gMDsKTm9kZSogdGVtcCA9IGhlYWQ7CndoaWxlICh0ZW1wICE9IG51bGxwdHIpIHsKY291bnQrKzsKdGVtcCA9IHRlbXAtPm5leHQ7Cn0KcmV0dXJuIGNvdW50Owp9CgppbnQgbWFpbigpIHsKTm9kZSogaGVhZCA9IG5ldyBOb2RlKDEwKTsKaGVhZC0+bmV4dCA9IG5ldyBOb2RlKDIwKTsKaGVhZC0+bmV4dC0+cHJldiA9IGhlYWQ7CmhlYWQtPm5leHQtPm5leHQgPSBuZXcgTm9kZSgzMCk7CmhlYWQtPm5leHQtPm5leHQtPnByZXYgPSBoZWFkLT5uZXh0OwoKY291dCA8PCAiTGVuZ3RoIG9mIERvdWJseSBMaW5rZWQgTGlzdDogIiA8PCBnZXRMZW5ndGgoaGVhZCkgPDwgZW5kbDsKcmV0dXJuIDA7Cn0=
Output:
Length of Doubly Linked List: 3
Code Explanation:
We define a Node struct that contains three elements: data, next, and prev, with a constructor to initialize these components. We will use this to create the doubly linked list.
- Length Calculation: We then define a getLength() function to check the length. Inside:
- We declare and initialize a variable count with the value 0 to keep track of the number of nodes.
- Then, we declare a temporary pointer temp is set to head to begin traversal.
- Next, we use a while loop to traverse through the list by updating temp = temp->next in each iteration, incrementing count for every node encountered.
- The function returns count when temp reaches nullptr, indicating the end of the list.
- Main Function Execution: We first create a sample doubly linked list (10 → 20 → 30). Then, we call the getLength(head), which returns 3.
- Finally, we print the length using the cout statement and the main function complete with a return 0 statement.
Searching For A Node Of Doubly Linked List Data Structure
Searching for a node in a doubly linked list involves traversing the list to find a node with a specific value. This can be done by iterating through the list and comparing each node’s data with the target value.
How It Works– To search for a node with a specific value:
- Start from the head of the list.
- Traverse the list using the next pointer.
- Compare each node’s data with the target value.
- If a match is found, return true (or the position, if required).
- If the end of the list is reached without finding the value, return false.
Code Example:
#include
using namespace std;
struct Node {
int data;
Node* next;
Node* prev;
Node(int newData) {
data = newData;
next = nullptr;
prev = nullptr;
}
};
bool searchNode(Node* head, int key) {
Node* temp = head;
while (temp != nullptr) {
if (temp->data == key) {
return true;
}
temp = temp->next;
}
return false;
}
int main() {
Node* head = new Node(10);
head->next = new Node(20);
head->next->prev = head;
head->next->next = new Node(30);
head->next->next->prev = head->next;
int key = 20;
if (searchNode(head, key)) {
cout << "Node found in the list." << endl;
} else {
cout << "Node not found in the list." << endl;
}
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgp1c2luZyBuYW1lc3BhY2Ugc3RkOwoKc3RydWN0IE5vZGUgewppbnQgZGF0YTsKTm9kZSogbmV4dDsKTm9kZSogcHJldjsKCk5vZGUoaW50IG5ld0RhdGEpIHsKZGF0YSA9IG5ld0RhdGE7Cm5leHQgPSBudWxscHRyOwpwcmV2ID0gbnVsbHB0cjsKfQp9OwoKYm9vbCBzZWFyY2hOb2RlKE5vZGUqIGhlYWQsIGludCBrZXkpIHsKTm9kZSogdGVtcCA9IGhlYWQ7CndoaWxlICh0ZW1wICE9IG51bGxwdHIpIHsKaWYgKHRlbXAtPmRhdGEgPT0ga2V5KSB7CnJldHVybiB0cnVlOwp9CnRlbXAgPSB0ZW1wLT5uZXh0Owp9CnJldHVybiBmYWxzZTsKfQoKaW50IG1haW4oKSB7Ck5vZGUqIGhlYWQgPSBuZXcgTm9kZSgxMCk7CmhlYWQtPm5leHQgPSBuZXcgTm9kZSgyMCk7CmhlYWQtPm5leHQtPnByZXYgPSBoZWFkOwpoZWFkLT5uZXh0LT5uZXh0ID0gbmV3IE5vZGUoMzApOwpoZWFkLT5uZXh0LT5uZXh0LT5wcmV2ID0gaGVhZC0+bmV4dDsKCmludCBrZXkgPSAyMDsKCmlmIChzZWFyY2hOb2RlKGhlYWQsIGtleSkpIHsKY291dCA8PCAiTm9kZSBmb3VuZCBpbiB0aGUgbGlzdC4iIDw8IGVuZGw7Cn0gZWxzZSB7CmNvdXQgPDwgIk5vZGUgbm90IGZvdW5kIGluIHRoZSBsaXN0LiIgPDwgZW5kbDsKfQoKcmV0dXJuIDA7Cn0=
Output:
Node found in the list.
Code Explanation:
We define a Node struct containing data, next, and prev pointers. A constructor initializes these components when a new node is created.
- Searching for a Node: We define a searchNode() function, where:
- We declare a temp pointer variable and set it to head to begin traversal.
- Then, we use a while loop to iterate through the list, comparing temp->data with the target value key.
- If a match is found, the function returns true.
- If the loop completes without finding the value, the function returns false.
- Main Function Execution: We create a double-linked list containing three nodes using the Node structure and link them using the ‘this’ pointer (10 → 20 → 30).
- Then, we call the searchNode() inside an if-else statement, passing head and value 20 as arguments. The function traverses the list and finds 20, so it returns true.
- As a result, the if-block executed, printing the string message– "Node found in the list." to the console.
Complexity Analysis Of Key Operations On Doubly Linked Lists
Understanding the time complexity of operations in a doubly linked list helps in evaluating its efficiency. Below is a breakdown of the key operations along with their time complexities.
|
Operation |
Time Complexity |
Explanation |
|
Insert at Beginning |
O(1) |
Only the head pointer and the new node’s pointers need to be updated. |
|
Insert at End |
O(1) |
The tail pointer allows direct access to the last node, requiring only a few pointer updates. |
|
Insert at Specific Position |
O(n) |
May require traversal up to the target position before insertion. |
|
Delete from Beginning |
O(1) |
Only the head pointer and the second node's prev pointer need to be updated. |
|
Delete from End |
O(1) |
The tail pointer allows direct access to the last node, requiring only a few pointer updates. |
|
Delete from Specific Position |
O(n) |
Requires traversal to locate the node before deletion. |
|
Forward Traversal |
O(n) |
The entire list must be visited sequentially using the next pointer. |
|
Backward Traversal |
O(n) |
Similar to forward traversal but uses the prev pointer instead. |
|
Get Length |
O(n) |
Requires traversing all nodes while counting them. |
|
Search by Value |
O(n) |
Requires traversing the list until the target node is found (or the end is reached). |
As evident from the table:
- Insertion & Deletion at the beginning or end are O(1) due to direct access.
- Insertion & Deletion at a specific position is O(n) since traversal may be needed.
- Traversal, length calculation, and searching are O(n) as they require visiting multiple nodes.
This complexity breakdown helps in choosing the right data structure for a given task.
Real-World Applications Of Doubly Linked Lists Data Structure
Doubly linked lists are widely used in various real-world applications where efficient insertions, deletions, and bidirectional traversals are required. Below are some key areas where they are commonly implemented.
- Browser History Navigation: Web browsers use doubly linked lists to store visited pages. The next and prev pointers allow users to move forward and backward in history.
- Text Editors (Undo/Redo Functionality): Many text editors store user actions in a doubly linked list. The prev pointer allows undoing an action, while the next enables redoing it.
- Music and Video Playlists: Media players use doubly linked lists to maintain playlists. Users can skip forward (next pointer) or go back to the previous track (prev pointer).
- Task Scheduling: Operating systems use doubly linked lists for task scheduling in process management. The bi-directional linking helps in efficient switching between processes.
- Memory Management in OS: Memory allocation and deallocation often involve doubly linked lists. It helps in managing free and allocated memory blocks efficiently.
- Implementation of LRU Cache: Least Recently Used (LRU) caches use doubly linked lists to track cache entries. The most recently used item moves to the front, and the least used is removed from the end.
- Navigation Systems: GPS and mapping applications use doubly linked lists to store routes. Users can move step-by-step in both forward and reverse directions.
Doubly linked lists offer flexibility in managing dynamic data and are crucial in applications where bidirectional traversal and efficient insertions/deletions are required.
Advantages & Disadvantages Of Doubly Linked Lists
Doubly linked lists provide significant advantages over singly linked lists but also come with some trade-offs. The table below highlights the key pros and cons.
|
Advantages |
Disadvantages |
|
Bidirectional Traversal – Nodes can be accessed in both forward and backward directions, making navigation more flexible. |
Increased Memory Usage – Each node requires extra space for an additional pointer (prev), increasing memory consumption. |
|
Efficient Deletion – Deleting a node is more efficient as we have direct access to both previous and next nodes. |
More Complex Implementation – Managing extra pointers increases code complexity and requires careful handling to avoid errors. |
|
Faster Insertion & Deletion – Inserting or deleting nodes in the middle is easier as there’s no need to traverse from the head. |
Higher Overhead – More pointer updates are needed during insertion and deletion operations. |
|
Better Use in Certain Applications – Ideal for applications like undo/redo functionality, navigation systems, and LRU caches. |
Slower Traversal Compared to Arrays – Unlike arrays, nodes are not stored in contiguous memory, leading to slower access times. |
Doubly Linked List Vs. Singly Linked Lists
Doubly linked lists and singly linked lists both serve as dynamic data structures, but they differ in terms of traversal, memory usage, and efficiency of operations. The table below highlights the key differences between them.
|
Feature |
Singly Linked List |
Doubly Linked List |
|
Structure |
Each node has data and a pointer to the next node. |
Each node has data, a pointer to the next node, and a pointer to the previous node. |
|
Traversal |
Can only be traversed in one direction (forward). |
Can be traversed in both forward and backward directions. |
|
Memory Usage |
Requires less memory as each node has only one pointer. |
Requires more memory due to the extra pointer (prev). |
|
Insertion & Deletion |
More complex in the middle, as the previous node must be accessed separately. |
Easier in the middle, as the previous node can be accessed directly. |
|
Use Cases |
Suitable for simpler applications like stacks and basic linked structures. |
Ideal for applications requiring bidirectional navigation, such as text editors, navigation systems, and LRU caches. |
Doubly Linked List Vs. Circular Linked Lists
Doubly linked lists and circular linked lists differ in how they connect their nodes and handle traversal. The table below compares their key characteristics.
|
Feature |
Doubly Linked List |
Circular Linked List |
|
Structure |
Each node has a next pointer and a prev pointer, with the last node pointing to nullptr. |
The last node’s next pointer connects back to the first node, forming a circular structure. |
|
Traversal |
Can be traversed in both forward and backward directions, but has a definite start and end. |
Can be traversed indefinitely without encountering nullptr. |
|
Memory Usage |
Requires additional memory due to the prev pointer. |
Requires only one pointer per node in a singly circular linked list but two in a doubly circular linked list. |
|
Insertion & Deletion |
Requires updating both prev and next pointers, but operations can be done from both ends. |
Requires special handling since the last node points back to the first, avoiding null references. |
|
Use Cases |
Used in applications needing bidirectional traversal, like undo-redo operations and navigation systems. |
Common in applications requiring continuous iteration, such as scheduling systems and buffer management. |
Conclusion
Doubly linked lists are a powerful data structure, offering efficient insertion and deletion operations at both ends and enabling traversal in both directions.
- By storing extra pointers (prev and next), they ensure that nodes can be reached from either direction, making them ideal for certain use cases like undo-redo operations, browser history, and navigation systems.
- While they do come with a bit more memory overhead due to the additional pointer, their advantages often outweigh the costs in scenarios that require bidirectional access to elements.
- On the other hand, circular linked lists offer continuous traversal, eliminating the concept of a “last” node, making them well-suited for circular queues or applications that need to keep iterating through elements without a defined start or end.
In summary, whether you opt for a doubly linked list or a circular linked list depends on your specific needs—bidirectional traversal or continuous looping.
Frequently Asked Question
Q1: What is the main difference between a doubly linked list and a singly linked list?
A doubly linked list has two pointers for each node: one pointing to the next node and the other to the previous node. In contrast, a singly linked list only has a pointer to the next node, making doubly linked lists more flexible for traversal in both directions.
Q2: Why do doubly linked lists use extra memory?
Doubly linked lists require extra memory because each node contains two pointers (next and prev), whereas singly linked lists only contain one pointer (next). This additional memory is used to store the previous node's address, which allows for reverse traversal.
Q3: Can I reverse traverse a singly linked list?
No, singly linked lists do not support reverse traversal because they only store a pointer to the next node. To reverse traverse, you would have to modify the list structure or implement additional logic.
Q4: Are doubly linked lists faster than singly linked lists?
Doubly linked lists can be faster in some cases, especially when performing insertions or deletions at both ends or in the middle of the list. However, the extra memory overhead can make them less efficient when only forward traversal is needed.
Q5: When should I use a circular doubly linked list?
Circular doubly linked lists are ideal for applications that require continuous looping, such as implementing a round-robin scheduling system, navigation through cyclic data, or managing buffers where you don't want to reach the "end" of the list.
This compiles our discussion on doubly linked lists. Here are a few more interesting articles you should explore:
- Advantages And Disadvantages Of Linked Lists Summed Up For You
- Python Linked Lists | A Comprehensive Guide (With Code Examples)
- 53 Frequently Asked Linked List Interview Questions With Answers 2026
- 55+ Data Structure Interview Questions For 2026 (Detailed Answers)
- What Is Linear Data Structure? Types, Uses & More (+ Examples)
Login to continue reading
And access exclusive content, personalized recommendations, and career-boosting opportunities.
Don't have an account? Sign up
Never miss an
Update

Featured Opportunities
Top-Rated Practice by Students





Subscribe
to our newsletter



Comments
Add comment