
Feature selection is a vital process in machine learning, where the goal is to identify and select the most relevant features or variables from a dataset. This process helps improve the model's performance by eliminating irrelevant or redundant data, reducing overfitting, and increasing computational efficiency. Proper feature selection can enhance the accuracy of machine learning models, as it ensures that the model only focuses on the most significant predictors.
Importance of Feature Selection in Machine Learning
Feature selection plays a crucial role in ensuring that machine learning models are both efficient and effective. By reducing the number of irrelevant or redundant features, we can optimize model performance, increase interpretability, and save computational resources. Here is how feature selection is helpful:
- Reduces Overfitting: By removing irrelevant features, feature selection reduces the complexity of the model, helping to avoid overfitting and improve generalization.
- Improves Model Accuracy: A model trained with relevant features tends to provide more accurate predictions than one burdened with irrelevant data.
- Enhances Computational Efficiency: Fewer features mean lower computational cost and faster processing times, making feature selection crucial for large datasets.
- Better Interpretability: Selecting the most important features makes the model easier to interpret, which is particularly beneficial in fields like healthcare, finance, and business.
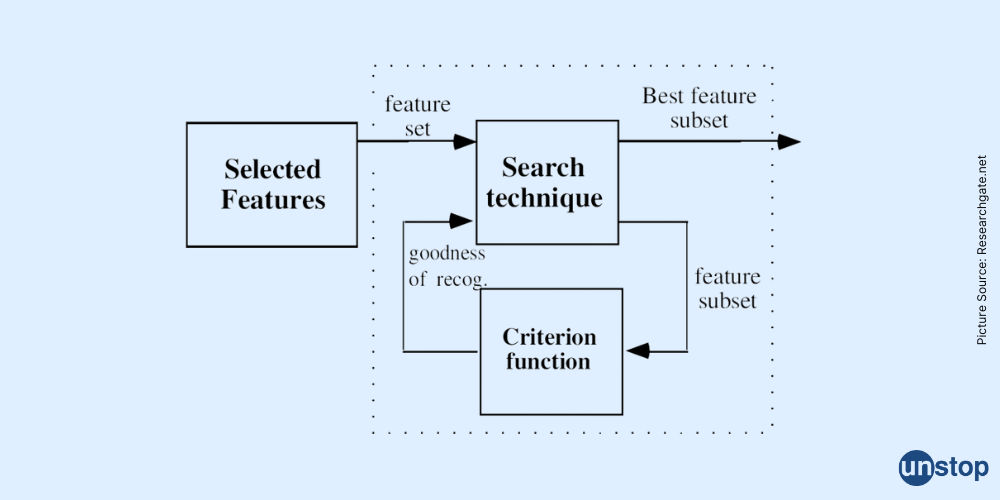
Methods of Feature Selection in Machine Learning
There are several methods of feature selection, each with its own strengths and use cases. These methods can be broadly categorized into filter methods, wrapper methods, and embedded methods, and each plays a different role in identifying the most important features.
Filter Methods
Filter methods are statistical techniques that evaluate the importance of each feature independently of the machine learning model. These methods score features based on their statistical relevance to the target variable. Some common filter methods include:
Chi-Square Test
Measures the independence between two variables and selects features that have the highest statistical significance.
Example: In a retail dataset, testing whether product category (categorical) is significantly associated with the likelihood of purchase.
Use case: An e-commerce business might use this to identify which product categories most influence purchasing behavior.
Correlation Coefficient
Calculates the correlation between each feature and the target variable, selecting features with high correlation.
Example: In a housing price prediction dataset, selecting features like square footage, number of bedrooms, and age of the house based on their correlation with the price.
Use case: Real estate businesses can focus on highly correlated features to predict home prices more effectively.
Mutual Information
Measures the amount of information shared between a feature and the target variable, selecting features that maximize this information.
Example: In a marketing campaign dataset, identifying which demographic features (e.g., age, income) provide the most information about whether a customer will click on an ad.
Use case: Advertising firms can target the most influential demographics for personalized marketing.
Wrapper Methods
Wrapper methods evaluate feature subsets based on the performance of the machine learning model. These methods are computationally expensive but often provide better feature subsets for a specific model. Some popular wrapper methods include:
Forward Selection
Starts with no features and adds the most significant features one by one based on model performance.
Example: In a medical diagnosis dataset, starting with no features and iteratively adding predictors like blood pressure, cholesterol levels, and age to find the combination that best predicts heart disease risk.
Use case: Healthcare providers can identify the most significant risk factors for preventive care.
Backward Elimination
Starts with all features and removes the least important features step by step, based on model performance.
Example: In a stock price prediction dataset, starting with all features (e.g., historical prices, trading volume, and market sentiment) and removing the least significant features based on model performance.
Use case: Financial analysts can simplify models by retaining only the most critical indicators.
Recursive Feature Elimination (RFE)
Iteratively builds models and eliminates the least significant features to find the optimal subset of features.
Example: In a sentiment analysis task, using RFE to identify the most impactful words (features) in determining positive or negative sentiment.
Use case: Social media monitoring systems can focus on key terms for sentiment analysis.









Comments
Add comment