
Asian Paints Alchemy 2026
Table of content:
- Understanding Classification Models
- Lazy Learners vs. Eager Learners
- Classification vs. Regression in Machine Learning
- Different Types of Classification Tasks
- Evaluating Classification Models
- Real-Life Applications of Classification Models
- Conclusion
- Frequently Asked Questions (FAQs)
Classification Models In Machine Learning
This article explores the fundamentals of classification models, their types, learning styles, and real-world applications.

Classification models are a cornerstone of machine learning, employed to categorize data into predefined classes. From spam email detection to medical diagnosis, classification models power a wide range of applications in diverse domains. These models utilize labeled datasets to learn patterns and make predictions on new, unseen data.
In this article, we’ll delve into the fundamentals of classification models, their types, learning styles, and real-world applications. Along the way, we’ll explore practical examples to make the concepts accessible and relatable.
Understanding Classification Models
Classification models address problems where the goal is to assign labels to data points. They cater to binary classification problems (e.g., yes/no decisions) and multi-class classification problems (e.g., identifying handwritten digits).
Imagine a spam filter in your email system—it learns to classify incoming emails as either "spam" or "not spam." This simple idea scales to numerous applications in different industries.
Types of Classification Models
Let’s explore the most common classification models, their characteristics, and practical use cases.
Logistic Regression
Logistic Regression is a statistical model that predicts the probability of a binary outcome based on input features. It uses the sigmoid function to map predictions to probabilities between 0 and 1.
- Applications: Fraud detection, medical diagnostics.
- Example: Predicting whether a customer will churn based on their transaction history and support call logs.
Decision Trees
Decision Trees represent decisions in a tree-like structure, where each node corresponds to a feature-based decision. They are simple to interpret and effective for small datasets.
- Applications: Credit scoring, customer segmentation.
- Example: Determining loan approval based on income, credit history, and employment status.
Random Forest
Random Forest combines multiple decision trees to reduce overfitting and enhance accuracy. It is an ensemble learning method widely used in predictive analytics.
- Applications: Stock market prediction, recommendation systems.
- Example: Predicting product categories based on customer reviews and ratings.
Support Vector Machines (SVM)
SVMs find the optimal hyperplane that separates data points of different classes, making them effective for high-dimensional data.
- Applications: Text classification, image recognition.
- Example: Sorting emails into "important" or "not important" folders based on content.
K-Nearest Neighbors (KNN)
KNN is a non-parametric model that classifies data points based on the majority class of their k-nearest neighbors.
- Applications: Pattern recognition, anomaly detection.
- Example: Classifying flowers into species based on petal and sepal dimensions.
Naive Bayes
Naive Bayes relies on Bayes' theorem and assumes feature independence. Despite its simplicity, it performs well in text classification tasks.
- Applications: Spam filtering, sentiment analysis.
- Example: Detecting spam emails based on word frequency.
Neural Networks
Inspired by the human brain, Neural Networks consist of layers of interconnected nodes (neurons). They excel in handling complex, non-linear relationships.
- Applications: Speech recognition, medical imaging.
- Example: Diagnosing diseases from X-ray images or identifying objects in photos.
Lazy Learners vs. Eager Learners
Classification models can be classified based on their learning style into Lazy Learners and Eager Learners.
Lazy Learners
Lazy learners do not build a model during the training phase. Instead, they store the training data and process it only when making a prediction. It is like keeping a directory of restaurant reviews and deciding where to eat only when hungry.
Example: K-Nearest Neighbors (KNN).
- Pros: Simple and effective for small datasets.
- Cons: Computationally expensive during prediction.
Eager Learners
Eager learners build a model during training, enabling quick predictions. It is like pre-choosing a set of favorite restaurants based on your preferences.
Examples: Decision Trees, Random Forests.
- Pros: Efficient during prediction.
- Cons: Requires more time to train.
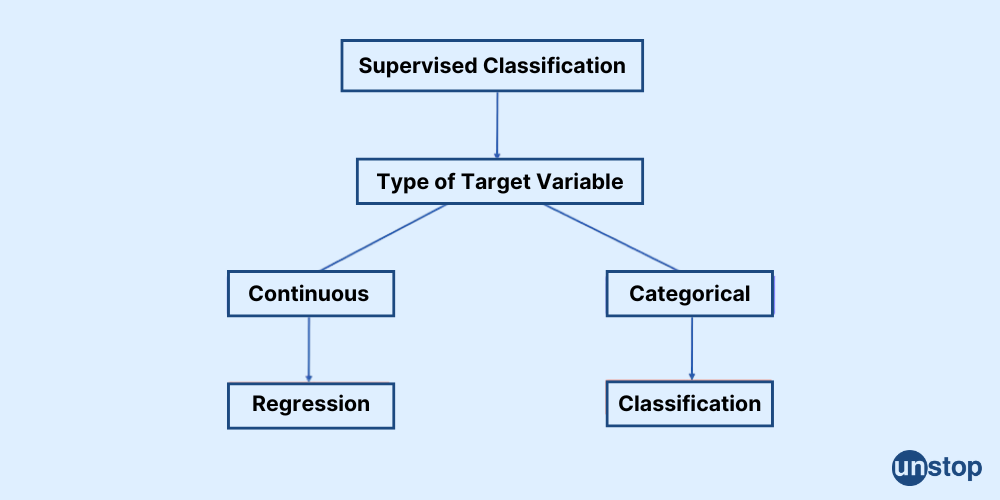
Classification vs. Regression in Machine Learning
Classification and regression are both from the category of supervised learning. Here's the table that summarizes the differences:
| Aspect | Classification | Regression |
|---|---|---|
| Definition | Predicts categorical outcomes or discrete labels. | Predicts continuous outcomes or numerical values. |
| Nature of Output | Labels like "yes/no," "spam/not spam," or multiple classes (e.g., "dog," "cat," "bird"). | A single continuous value (e.g., 52.4, 1987.6). |
| Goal | Categorize data into predefined groups. | Estimate relationships to predict a continuous variable. |
| Examples | Email spam detection ("spam" vs. "not spam"), loan approval ("approved" vs. "rejected"). | Predicting house prices, forecasting sales revenue, or estimating employee salaries. |
| Algorithms Used | Logistic Regression, Decision Trees, Random Forests, SVM, KNN, Naïve Bayes, Neural Networks. | Linear Regression, Polynomial Regression, Ridge Regression, Lasso Regression, Neural Networks. |
| Evaluation Metrics | Accuracy, Precision, Recall, F1-Score, ROC-AUC, Confusion Matrix. | Mean Squared Error (MSE), Root Mean Squared Error (RMSE), Mean Absolute Error (MAE), R² Score. |
| Visualization | Often represented using classification boundaries in 2D or 3D space. | Typically visualized as a line or curve fitting the data points. |
| Handling Outliers | May handle outliers well depending on the algorithm (e.g., Random Forest is robust). | Sensitive to outliers, especially algorithms like Linear Regression. |
| Training Complexity | Models may require relatively fewer computations during training. | Regression models may involve complex calculations, especially with higher-dimensional data. |
| Dataset Requirement | Requires labeled data with predefined classes for supervised learning. | Requires labeled data with continuous target values. |
| Real-Life Analogy | Sorting emails into "important" or "not important" folders. | Predicting the total cost of a shopping cart based on selected items. |
| Applications in Industries | Fraud detection, healthcare diagnosis, recommendation systems. | Stock price prediction, weather forecasting, and sales analysis. |
| Common Use Cases | Customer churn prediction, image recognition, language translation classification. | Predicting economic growth rates, creating salary prediction models, or forecasting energy usage. |
| Model Complexity | Can range from simple (Logistic Regression) to highly complex (Deep Learning for image recognition). | Varies from simple (Linear Regression) to highly intricate (Neural Networks for time series). |
Different Types of Classification Tasks
Classification tasks vary based on complexity and requirements:
- Binary Classification: Two classes. Example: Fraud detection (fraudulent or not).
- Multi-Class Classification: Multiple classes. Example: Classifying handwritten digits (0-9).
- Multi-Label Classification: Multiple labels for a single instance. Example: Tagging an image with "sunset," "mountains," and "clouds."
- Imbalanced Classification: Skewed class distribution. Example: Fraud detection, where fraudulent transactions are rare.
How Classification Models Work
Building and using classification models involves several key steps:
- Data Preprocessing: Transform raw data by cleaning, normalizing, and encoding it.
- Model Training: Learn patterns from labeled datasets by minimizing prediction errors.
- Validation: Tune model parameters to avoid overfitting.
- Testing: Evaluate model performance using test data and metrics.
Evaluating Classification Models
The performance of classification models is measured using:
- Accuracy: Proportion of correctly classified instances.
- Precision and Recall: Precision focuses on positive predictions, while recall considers all actual positives.
- F1-Score: Balances precision and recall.
- ROC-AUC: Evaluates the trade-off between true and false positives.
- Confusion Matrix: Summarizes predictions versus actual outcomes.
Real-Life Applications of Classification Models
The versatility of classification models makes them indispensable in numerous domains. Here are some notable examples:
- Email Spam Detection: Automatically filters promotional emails into a separate folder.
- Medical Diagnosis: Predicts diseases based on symptoms, such as identifying diabetes from patient history.
- Customer Segmentation: Groups customers for targeted marketing campaigns.
- Credit Risk Assessment: Evaluates loan applicants as "high risk" or "low risk."
- Facial Recognition: Unlocks smartphones using facial recognition technology.
Conclusion
Classification models play a pivotal role in deriving insights from data. By understanding their types, learning styles, and evaluation metrics, data professionals can make informed decisions about their applications. As machine learning continues to evolve, classification models will remain at the forefront of technological advancements.
Frequently Asked Questions (FAQs)
Q1. What is the difference between classification and regression models?
Classification predicts categories, while regression predicts continuous values.
Q2. How do you choose the best classification model for a problem?
Factors include dataset size, complexity, interpretability, and computational efficiency.
Q3. What is overfitting in classification models?
When a model performs well on training data but poorly on unseen data.
Q4. Can classification models handle imbalanced datasets?
Yes, using techniques like resampling or employing specialized algorithms.
Q5. What role does feature selection play in classification models?
It improves performance by reducing irrelevant or redundant features, minimizing complexity.
Suggested Reads:
Login to continue reading
And access exclusive content, personalized recommendations, and career-boosting opportunities.
Don't have an account? Sign up
Never miss an
Update

Featured Opportunities
Top-Rated Practice by Students





Subscribe
to our newsletter
Comments
Add comment