
Asian Paints Alchemy 2026
Table of content:
- What is Classification?
- What is Clustering?
- Comparison between Classification and Clustering
Classification vs Clustering: Understand Their Importance For Business
Classification and clustering are two very popular data mining techniques in machine learning. Understand these terms in detail and their importance in modern-day businesses.

If you’re working with big volumes of unstructured data, it is essential to partition the data logically into groups before you begin to analyze it.
Classification and clustering are two very popular data mining techniques in machine learning. Why are data mining techniques important? Data science and machine learning are about a huge stack of datasets all around! With the aim of sorting data and extracting meaningful information, data scientists use some practical data mining approaches to enhance the functionality of machines.
Also Read: Difference Between Classification And Regression
What is Classification?
Classification is the method of learning the structure of a dataset of examples that are already divided into groups referred to as categories or classes.
Classification is a supervised data mining technique. This technique is used to classify a new observation into the existing categories or classes on the basis of its structure. Identification of these categories is achieved with a classification model, which helps us estimate the group identifiers or class labels of the unseen data examples bearing unknown labels.
- In the classification algorithm, a discrete output function(y) is mapped to input variable(x)
- It is a supervised data mining technique.
Example of classification: Imagine a retail company wants to predict whether a new customer will belong to a specific segment based on their demographic information. They have historical data with labeled customer segments, including features such as age, gender, income, and location. By training a classification model, the company can predict the segment of a new customer based on their demographic information.
Types of Classification
- Binary Classification: Here we categorize the given dataset into two distinct classes. Or in other words, the tasks to be classified have two class labels. For example – some messages are detected as spam whereas others are not, similarly, yes or no, 0 or 1 and more such instances when the outcome is either a "true" or "false" is can be grouped as binary classification.
- Multiclass Classification: As the name suggests, here the number of classes is more than two. We can also say that they have more than two class labels. For Example – On the basis of features and traits about different species of cats, we have to determine which class does the new observation belongs to.
What is Clustering?
Clustering is a Machine Learning technique that deals with the grouping of data points. A given set of data points can be clustered based on some similar properties.
In data science, clustering algorithms are used to group data in a logical manner in order to extract some information. It is an unsupervised data mining technique that helps the grouping of similar data points and understanding the internal structure of the data.
- This technique is useful for anomaly detection.
- It is an unsupervised data mining technique.
- Some of the popular clustering algorithms are k-means clustering, mean-shift clustering, Expectation-Maximisation (EM), etc.
Example of clustering: Imagine a retail company wants to cluster their customers based on their purchasing behavior to gain insights into different customer segments. They collect data on various features such as the total amount spent per month, frequency of purchases, and average basket size. By applying clustering algorithms, they can identify distinct clusters of customers with similar purchasing patterns.
Types of Clustering
1. K-Means Clustering
K-Means is one the well-known clustering algorithms. K-means clustering is a type of unsupervised learning, which is used for unlabeled data (data without defined groups). This technique helps in finding groups in the data. The number of groups is represented by the variable K where the number of observations is n. This way data points are clustered based on the similarities among them.
2. Mean-Shift Clustering
Mean shift clustering is known as sliding-window-based algorithm that basically spots dense areas of data points. It is a centroid-based algorithm i.e that the aim of this algorithm is to locate the maxima point of each group or categories. These candidate windows are then shifted to a post-processing stage in order to eliminate near-duplicates. This forms the final set of center points along with their categories.
3. Expectation–Maximization (EM) Clustering
The EM (expectation maximization) algorithm is similar to the K-Means algorithm. K-means technique basically assigns examples to clusters in order to maximize the differences in means for continuous variables. Whereas, EM clustering algorithm calculates the probabilities of cluster memberships based on one or more probability distributions.
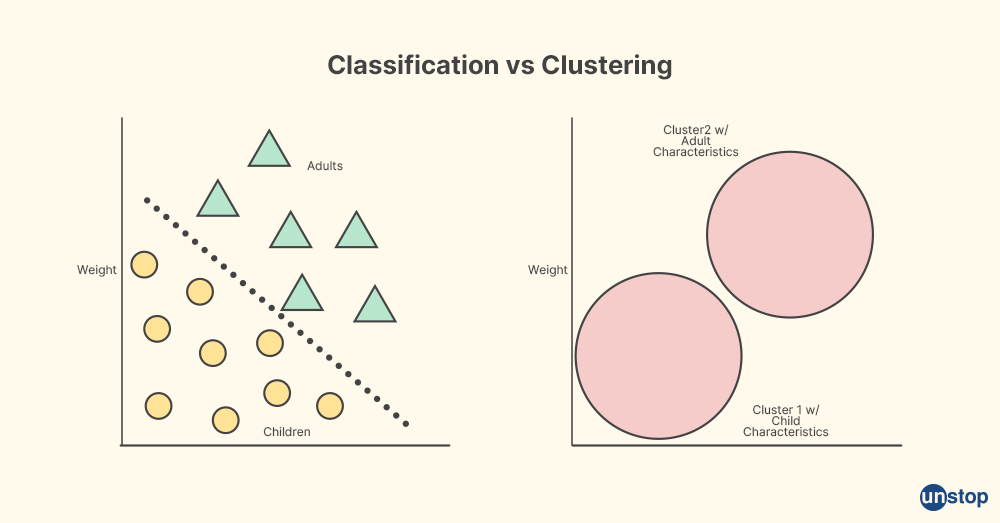
Comparison between Classification and Clustering
| Classification | Clustering |
| This technique classifies the new observation into one of the already defined classes. | This technique maps the data into one of the existing clusters where the data points are arranged based on the similarities between them. |
| Classification is used for supervised learning in machine learning. | Clustering is used for unsupervised learning in machine learning. |
| Classification contains labels. Therefore, training and testing of the datasets is necessary in order to verify the model. | Training and testing of data points are not required. |
| Classification is a more complex algorithm compared to clustering. | Clustering has a complexity less than that of Classification. |
| Examples of classification are - Logistic regression, Support vector machines, etc. | Examples of clustering are - the k-means clustering algorithm, mean shift clustering algorithm, Gaussian (EM) clustering algorithm, etc. |
What is the key difference?
Classification basically works by classifying the data with the help of class labels. On the other hand, clustering is done by putting similar data points together, and hence we don't need refined classes. Classification is a supervised learning technique, whereas clustering is unsupervised. Another difference is that classification has class labels but that is not the case with clustering.
Summing Up...
To summarize, clustering helps identify natural groupings within a dataset, while classification assigns predefined labels to data instances based on their features. Both techniques are valuable in data mining and can be used for different purposes, such as customer segmentation and targeted marketing.
You might also like to read:
- TCS Rebegin Recruitment 2021: Application process, skills required and much more!
- Tata Administrative Services is hiring via Tata Imagination Challenge; open to all college students and Tata employees
- 'Consulting is the most-sought after sector' - Really? This survey revealing top dream companies of MBA students speaks otherwise!
- 21 points that can make your resume any HR's favourite
Login to continue reading
And access exclusive content, personalized recommendations, and career-boosting opportunities.
Don't have an account? Sign up
Never miss an
Update

Featured Opportunities
Top-Rated Practice by Students





Subscribe
to our newsletter




Comments
Add comment