
Asian Paints Alchemy 2026
Table of content:
- What is Data Independence in DBMS?
- Achieving Data Independence in DBMS Through Data Abstraction
- Three Levels of Data Abstraction
- Levels of Data Independence in DBMS
- Difference Between Logical Data Independence and Physical Data Independence
- Advantages of Data Independence in DBMS
- Disadvantages of Data Independence in DBMS
- Conclusion
- Frequently Asked Questions
Data Independence In DBMS Explained: Types, Benefits & Drawbacks
Data Independence refers to the modification of information without affecting the result of the external program execution in the system. Understand this concept with examples.
In today’s digital age, data is considered the new currency—a powerful asset that drives decisions, innovation, and business growth. But with great value comes great responsibility. Managing this data efficiently and securely is where Database Management Systems (DBMS) step in.
DBMS are software systems designed to store, organize, retrieve, and manipulate data. They help ensure that data is accessible and usable while maintaining its integrity. Data independence in DMBS is a crucial concept that enhances the power and flexibility of DBMS—a feature that allows data to evolve without disrupting the applications that use it.
In this article, we’ll break down the concept of data independence in DBMS, how it works, its types, and why it’s essential for modern database architecture.
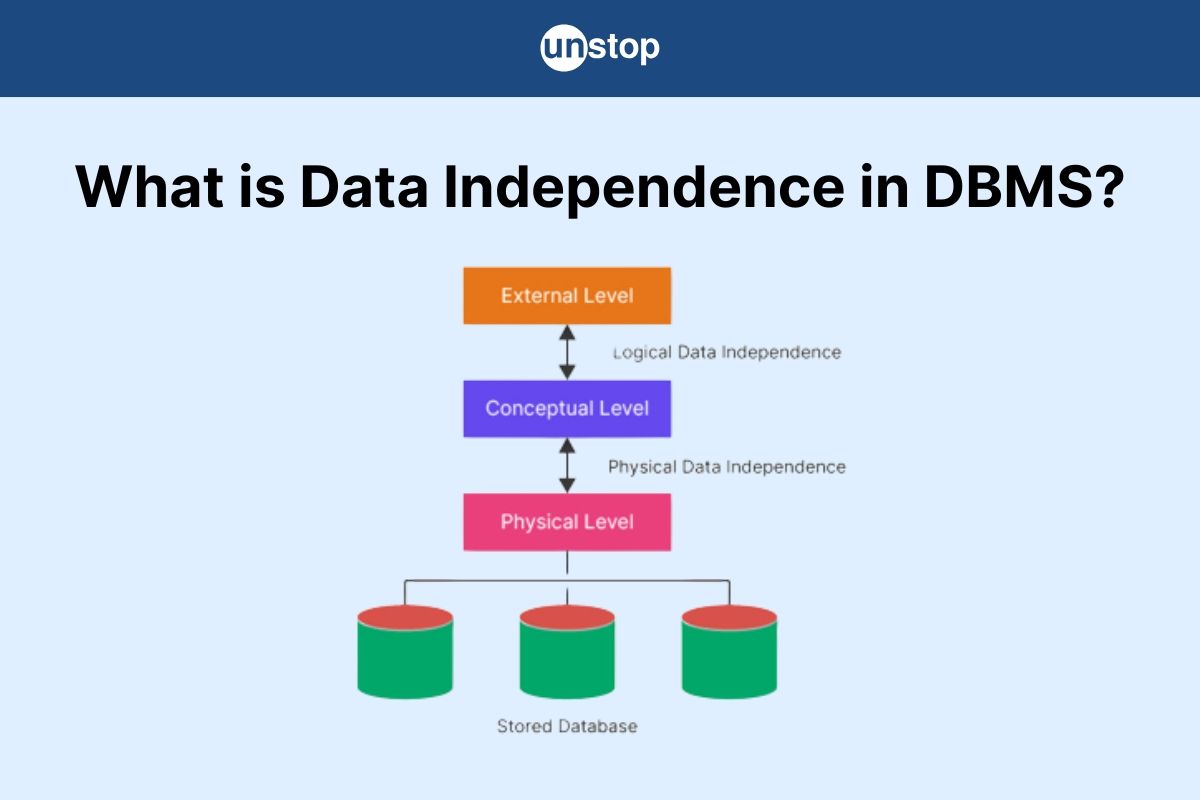
What is Data Independence in DBMS?
Data independence in DBMS refers to the ability to modify the database schema at one level without affecting the schema at the next higher level. In simple words, we can say that Data independence is a property of a database that allows the User or Database Administrator to change the schema at one level without affecting the data or schema at another level.
This makes database systems more flexible, maintainable, and scalable over time.
Example: If the internal storage format of a table changes from one file structure to another, applications using that table should still work without any modifications.
Purpose of Data Independence in DBMS
The main goals of data independence include:
- Security: Prevents users from seeing or interacting with internal complexities.
- Cost-efficiency: Reduces the time, effort, and cost of maintaining and updating data.
- System durability: Supports long-term evolution and scaling of systems without downtime or code rewrites.
Achieving Data Independence in DBMS Through Data Abstraction
To understand how data independence in DBMS is achieved, it's essential to grasp the concept of data abstraction. Data abstraction is the process of isolating essential information while hiding the complexities and irrelevant details from users.
Real-World Analogy: ATM Machines
A perfect real-world example of data abstraction is the ATM (Automated Teller Machine). When users interact with an ATM—for withdrawing cash or checking balances—they aren’t exposed to the underlying data storage, server communication, or encryption mechanisms. They simply see a user interface that lets them complete their task. This separation of interface from internal workings is what data abstraction achieves, and it’s foundational to enabling data independence.
Looking for roles that value your DBMS skills? Explore jobs now.
Three Levels of Data Abstraction
The main purpose of data abstraction is to achieve data independence. There are three levels of data abstraction in DBMS, each responsible for separating concerns and promoting independence across layers:
1. Physical (Internal) Level
- Description: This is the lowest level of abstraction, describing how data is physically stored in the system. It includes file structures, storage blocks, indexing methods, and access paths.
- Purpose: It defines the internal schema and is concerned with optimizing storage and access mechanisms for efficient data retrieval.
- Key Point: Changes at this level should not affect the higher-level schemas.
2. Conceptual (Logical) Level
- Description: This level provides a logical view of the entire database, independent of how the data is stored. It defines entities, relationships, constraints, and the logical structure of data.
- Purpose: It bridges the gap between the physical and external levels, describing what data is stored and how it's related, without involving storage concerns.
- Key Point: Changing logical relationships (like adding new fields) shouldn't require changes to how users interact with the database.
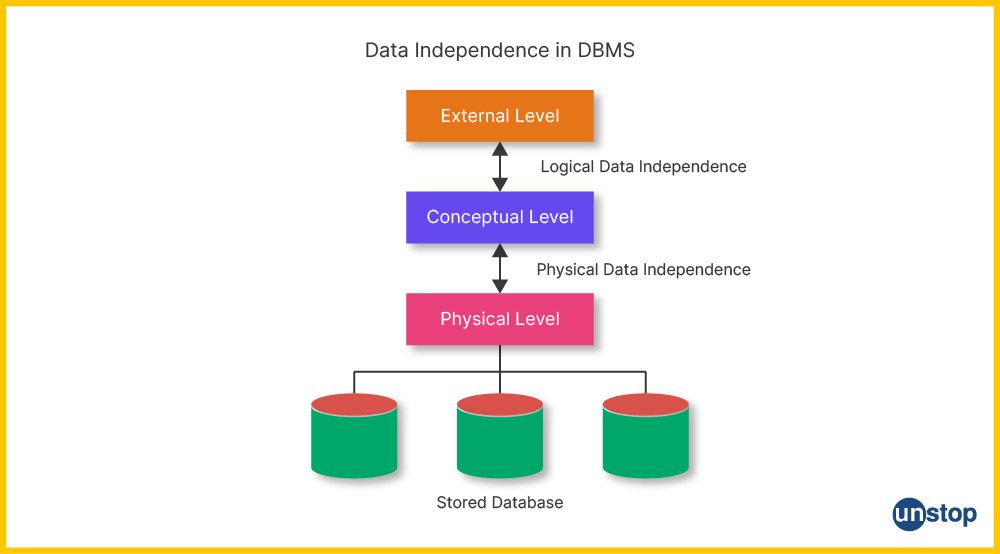
3. External (View) Level
- Description: The highest level of abstraction, this defines how end-users interact with the database via specific views or interfaces.
- Purpose: Users can access data relevant to their needs through Graphical User Interfaces (GUIs) or APIs without knowing how or where data is stored or structured.
- Key Point: Multiple users can have different external views based on their roles and permissions.
Levels of Data Independence in DBMS
Based on these levels of abstraction, there are two main types of data independence in DBMS:
- Physical Data Independence
- Logical Data Independence
Each level contributes to making databases more robust, flexible, and easier to manage in the long term.
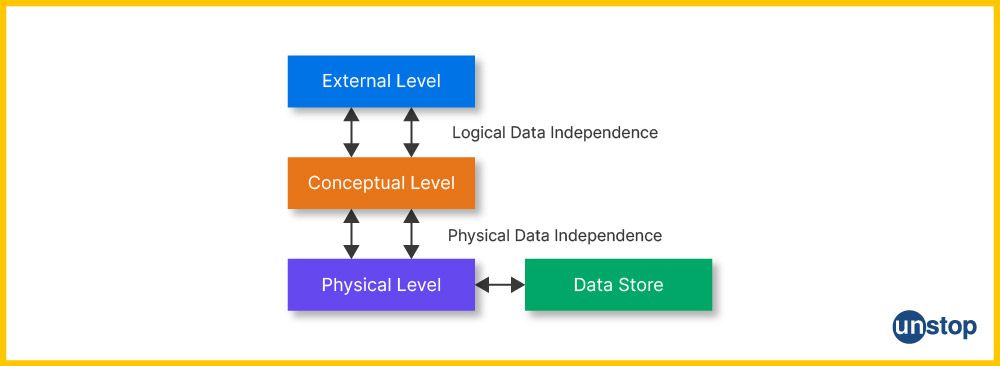
Let’s discuss the properties of these two levels of data independence.
1. Physical Data Independence in DBMS
Definition: Physical Data Independence is the ability to change the physical level without affecting the logical or Conceptual level. Physical data independence gives us the freedom to modify the - Storage device, File structure, location of the database, etc. without changing the definition of conceptual or view level.
Benefits:
- Allows for optimization (e.g., moving from HDD to SSD or cloud storage)
- No need to rewrite application code after storage changes
- Simplifies maintenance and hardware upgrades
Example: In a banking database, suppose the team decides to upgrade the database storage from magnetic tapes to SSDs or optimize indexes for faster access. These changes can be made without affecting how account information or customer data is logically structured or accessed by applications.
Below changes can be done at the physical layer without affecting the conceptual layer -
- Changing the storage devices like SSD, hard disk and magnetic tapes, etc.
- Changing the access technique and modifying indexes.
- Changing the compression techniques or hashing algorithms.
2. Logical Level Data Independence in DBMS
Definition: Logical Data Independence is a property of a database that can be used to change the logic behind the logical level without affecting the other layers of the database. Logical data independence is usually required for changing the conceptual schema without having to change the external schema or application programs. It allows us to make changes in a conceptual structure like adding, modifying, or deleting an attribute in the database.
Benefits:
- Supports schema evolution (e.g., adding new fields)
- Enables application scalability
- Reduces code refactoring needs
Example: In the same banking database, if the organization wants to add a new field to track customer KYC verification or modify customer address formats, these changes can be made at the logical level. Applications and user interfaces accessing the data remain unaffected.
These changes can be made at a logical level without affecting the application program or the external layer.
- Adding, deleting, or modifying the entity or relationship.
- Merging or breaking the record present in the database.
Summary of the Two Types of Data Independence
| Type | Affected Level | Protected Level | Key Examples |
|---|---|---|---|
| Physical Data Independence | Physical/Internal | Logical & External Schemas | Changing file formats, storage devices, indexing |
| Logical Data Independence | Logical/Conceptual | External/User Interfaces | Adding new columns, modifying relationships |
Also read: Data Models In DBMS: Types, Uses, And More
Difference Between Logical Data Independence and Physical Data Independence
Understanding the difference between logical data independence and physical data independence is crucial to designing efficient and flexible database systems. While both contribute to data abstraction, they function at different levels of the DBMS architecture and address different types of changes.
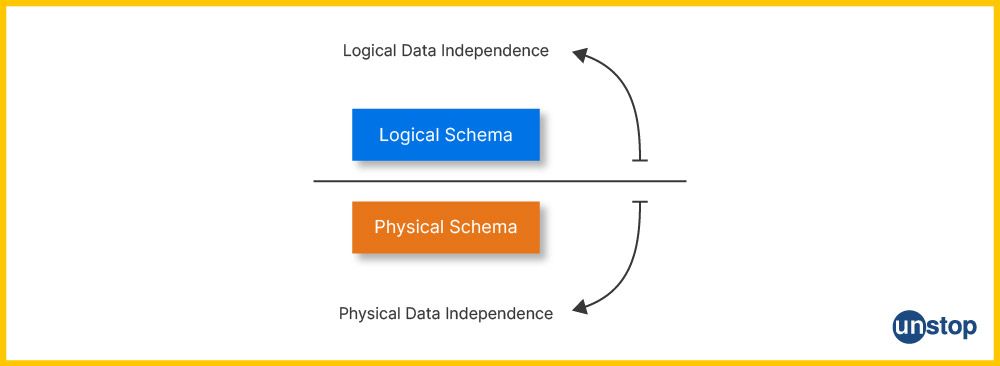
Below is a detailed comparison between the two types of data independence in DBMS:
| Aspect | Physical Data Independence | Logical Data Independence |
|---|---|---|
| Definition | Ability to change the internal schema without altering the logical schema. | Ability to change the logical schema without needing to modify the external schema or application programs. |
| Impact Area | Affects the physical storage and access methods. | Affects the logical structure and relationships of the data. |
| Ease of Implementation | Easier to achieve compared to logical data independence. | Harder to implement due to the tight coupling between logical design and applications. |
| Purpose | Allows flexibility in storage changes like switching devices, file formats, or indexing strategies. | Enables flexibility in data model updates like adding new fields, modifying attributes, or changing entity relationships. |
| Schema Involved | Involves changes in the internal (physical) schema. | Involves changes in the conceptual (logical) schema. |
| Examples | - Changing storage devices (e.g., HDD to SSD) - Updating compression or hashing algorithms - Modifying index structures or access paths |
- Adding or deleting attributes or entities - Modifying relationships between tables - Restructuring data models without changing physical storage |
Also read: DBMS Vs RDBMS: How RDBMS Is An Advanced Version Of DBMS?
Advantages of Data Independence in DBMS
Data independence in Database Management Systems (DBMS) brings numerous benefits that simplify database management, support scalability, and reduce the overall maintenance effort. Here are some key advantages:
- Flexibility: Data independence allows for changes to be made in the database schema (structure) without affecting the way data is accessed or presented to users. This flexibility makes it easier to adapt the database to evolving requirements and business needs.
- Application Compatibility: Changes to the logical schema do not impact the application programs or queries that rely on the database. This means that existing applications can continue to function correctly even when the database structure changes, reducing the risk of disruptions.
- Easier Maintenance: Database administrators can perform routine maintenance tasks, such as reorganizing data for performance optimization or implementing security updates, without disrupting user access or application functionality.
- Enhanced Security: Data independence allows for security measures and access controls to be implemented at the logical level, protecting sensitive data from unauthorized access or modification. Security policies can be enforced without exposing the underlying physical storage details.
- Data Continuity: When migrating data to new storage technologies or platforms, data independence ensures that the logical schema remains consistent, preserving data continuity and application functionality.
- Scalability: As the database grows, data independence facilitates the addition of new data elements or tables without affecting existing queries or applications. This scalability is crucial for accommodating increasing data volumes.
- Reduced Development Time: Developers can focus on designing and building applications without needing to worry about changes in the underlying database structure. This separation of concerns can lead to faster development cycles.
- Ease of Integration: Data independence simplifies the integration of data from multiple sources into a single database storage system. External schemas can be defined to provide unified views of the data, regardless of its source or format.
- Data Integrity: Changes to the logical schema can be managed carefully to ensure data integrity and consistency. Referential integrity constraints and validation rules can be applied at the logical level to maintain data quality.
- Adaptation to Technology Changes: As technology evolves, the physical storage and organization of data may need to change to take advantage of new hardware or software capabilities. Data independence allows these changes to be made without affecting the logical schema.
- Reduced Risk: By minimizing the impact of schema changes, data independence reduces the risk of errors and data corruption that can occur when modifying a database's structure hence helping in the improvement in database security.
Need guidance on cracking DBMS interviews? Find a mentor here.
Disadvantages of Data Independence in DBMS
While data independence offers many advantages in database management systems, it's essential to consider its potential disadvantages and limitations:
- Complexity: Maintaining multiple levels of schema (external, conceptual, and internal) to achieve data independence can introduce complexity into the database system. This complexity can make database design and management more challenging.
- Performance Overhead: Implementing data independence can sometimes result in performance overhead. The added layers of abstraction between the logical and physical data can impact query performance and data retrieval efficiency.
- Resource Consumption: Managing data independence may require additional system resources, such as storage space and processing power, to handle the various schema layers and translations between them.
- Potential for Redundancy: In some cases, data independence may lead to data redundancy. Different external schemas might require the same data to be stored in multiple formats or physical locations, which can increase storage requirements and synchronization challenges.
- Migration Complexity: While data independence simplifies schema changes, it may not eliminate all complexities associated with data migration. Migrating data between different versions of the database organization or across different DBMS platforms can still be complex and time-consuming.
- Compatibility Challenges: Changes made to the logical or conceptual schema may not always be compatible with existing application programs or queries. This can require additional effort to ensure backward compatibility and may involve rewriting or updating applications.
- Data Integrity Risk: Changes in the logical schema, if not managed carefully, can lead to data integrity issues. Ensuring that data remains consistent and that referential integrity constraints are maintained can be challenging when altering the logical schema.
- Development and Maintenance Effort: Implementing data independence often requires thorough planning, documentation, and adherence to best practices. It can involve additional development and maintenance effort to create and manage various schema layers and ensure that changes do not introduce errors.
- Training and Expertise: Database administrators and developers may require specific training and expertise to effectively manage data independence in a DBMS. Understanding how changes at one level of the schema affect other levels is crucial for maintaining data integrity.
- Risk of Over-Abstraction: In an attempt to achieve data independence, designers may over-abstract the logical schema, leading to a lack of transparency in the database structure. This can make it more challenging for developers and users to understand and work with the data.
- Potential for Suboptimal Physical Design: Complete physical data independence can make it challenging to optimize the physical storage of data effectively. Performance optimizations that require tight integration between logical and physical structures may not be feasible.
Conclusion
Data independence is a foundational principle in DBMS that enables flexibility, scalability, and long-term maintainability of database systems. By separating how data is stored from how it's accessed, it allows developers and administrators to make structural changes without disrupting application performance or user experience.
Whether it's adapting to new business needs, integrating new technologies, or optimizing system performance, data independence plays a vital role in supporting modern, large-scale databases. It not only ensures smoother transitions and upgrades but also strengthens data quality, security, and consistency—making it a must-have for any robust database design
Want to master DBMS concepts like this one? Practice real questions here.
Frequently Asked Questions
Q1. What is data independence in DBMS?
Data independence in DBMS refers to the capacity to change the schema (structure) of the database without affecting the application programs or user views that access the data. It is a fundamental concept that simplifies database maintenance and enhances flexibility.
Q2. Explain the three-level architecture of the database structure.
The three-level architecture of a database, also known as the three-schema architecture, is a conceptual framework that describes the organization and structure of a database system. This architecture helps in separating the database into three distinct levels, each with its own purpose and abstraction. These levels are:
-
External Level (User View):
- The external level is the topmost layer of the three-level architecture and is also known as the user view or user interface level.
- This level is concerned with the way users interact with the database. It defines various user views or user interfaces that cater to the specific needs and requirements of different types of users, such as end-users, application programmers, and database administrators.
- Each user view presents a subset of the data from the overall database, showing only the relevant information to the users.
- Users at this level are typically unaware of the internal structure of the database and interact with it using high-level query languages and applications.
-
Conceptual Level (Logical Schema):
- The conceptual scheme is the middle level of the three-level architecture.
- It represents the overall logical interface level and organization of the entire database system, independent of any specific user's view or application.
- At this middle layer, the data model is defined, which includes the schema (simple structure) of the entire database, relationships between data elements, integrity constraints, and security rules.
- The conceptual schema provides a global and integrated view of the data, ensuring data consistency and integrity across different user views.
- Changes to the conceptual schema affect all user views, but users at the external level are shielded from these changes.
-
Internal Level (Physical Schema):
- The internal level is the lowest layer of the three-level architecture, also known as the physical schema.
- It deals with the physical storage and internal implementation of data on the underlying storage devices (such as hard drives or solid-state drives).
- This level involves decisions related to data storage structures, indexing methods, data compression, and access paths for optimizing data retrieval and storage efficiency.
- The internal schema may be different from the conceptual schema, as it is optimized for performance and storage considerations rather than representing the logical structure of the data.
- Changes at this level, such as storage optimizations or database reorganization, do not impact the external or conceptual levels as long as the external schema remains unchanged.
Q3. How does data independence improve database management?
Data independence simplifies database maintenance and management by reducing the impact of changes. It allows for greater flexibility in adapting to evolving requirements, reduces the risk of errors during schema modifications, and makes it easier to manage large and complex databases.
Q4. What is the relationship between data independence and database security?
Data independence can enhance database security by allowing security measures and access controls to be implemented at the logical level without exposing the underlying physical implementation. This separation helps protect sensitive data from unauthorized access or manipulation.
Q5. Give a real-world application of data independence in DBMS.
Consider a healthcare management system where a new module is added to track vaccination history. Thanks to logical data independence, this new data can be integrated into the schema without rewriting existing appointment or billing systems. Similarly, if the database shifts from on-premise storage to cloud infrastructure, physical data independence ensures that the system continues operating without changing user access or logic.
Another real-world application of data independence in DBMS could be how a large retail chain can seamlessly introduce a new customer loyalty program with additional data requirements (logical data independence) and optimize data retrieval and storage by migrating to cloud-based storage allocation with new indexing methods (physical data independence) without disrupting existing operations or customer interactions.
Q6. Are there key limitations to data independence in DBMS?
While data independence in Database Management Systems (DBMS) offers significant advantages, it is essential to be aware of its limitations:
- Added Complexity: Implementing data independence can add complexity to the database system, as it involves managing multiple levels of schemas (external, conceptual, and internal). This complexity can make the database design and maintenance more challenging, particularly in large and complex database systems.
- Performance Trade-offs: Achieving complete physical data independence, where changes to the physical schema have no impact on performance, can be challenging. Certain physical optimizations may be closely tied to the logical structure, making it difficult to implement changes without affecting database performance.
- Resource Overhead: Maintaining data independence may require additional resources, such as disk space and processing power, especially when managing multiple layers of schemas. This overhead can affect database system server performance and scalability.
- Potential for Redundancy: In some cases, achieving data independence may lead to redundancy in data storage. For example, if different external schemas require the same data to be stored in multiple formats or database locations, it can result in increased storage requirements and synchronization challenges.
- Migration Complexity: While data independence facilitates schema changes, it may not eliminate all complexities associated with schema migrations. Migrating data between different versions of the database or across different DBMS platforms can still be a non-trivial task.
- Compatibility Issues: Changes made to the logical or conceptual schema may not always be compatible with existing application programs or queries. In some cases, backward compatibility efforts may be required to ensure that legacy applications continue to work correctly.
- Potential for Data Integrity Issues: Changes in the logical schema, if not carefully managed, can lead to data integrity problems. Ensuring that data remains consistent and that referential integrity constraints are maintained can be challenging when altering the logical schema.
- Development and Maintenance Effort: Implementing data independence often requires careful planning, documentation, and adherence to best practices. It can involve additional development process and maintenance efforts to create and manage various schema layers and ensure that changes do not introduce errors.
- Training and Expertise: Database administrators and developers may require specific training and expertise to effectively manage data independence in a DBMS. Understanding how changes at one level of the schema affect other levels is crucial for maintaining data integrity.
Q7. What is physical data independence, and why is it important?
Physical data independence is one of the two types of data independence in the context of Database Management Systems (DBMS). It refers to the capacity to make changes in the physical storage and organization of data without affecting the conceptual schema or the way data is logically represented and accessed. In other words, changes made at the physical level should not impact the applications, queries, or the overall logical structure of the database.
Here's why physical data independence is important:
- Flexibility and Adaptability: Physical data independence allows database administrators to modify the underlying storage structure or technology to improve performance, scalability, or resource utilization without having to alter the logical schema. This flexibility is crucial in evolving database systems to meet changing requirements and technological advancements.
- Performance Optimization: Database systems often need performance enhancements as data grows. Physical data independence enables administrators to implement performance optimizations, such as changing indexing methods, data compression techniques, or storage devices, to achieve better query response times and overall system efficiency.
- Minimizing Disruption: Without physical data independence, any change to the structure for storage or organization would necessitate modifications to the logical schema and all the application programs and queries that interact with the data. This can be time-consuming, error-prone, and disruptive to ongoing operations.
- Data Migration and Platform Changes: Organizations may need to migrate their data to new storage technologies or platforms over time. Physical data independence simplifies this process since it allows data to be migrated without altering the logical schema, ensuring data continuity and preserving application functionality.
- Security and Access Control: Security measures and access controls can be implemented at the logical level, shielding sensitive data from unauthorized users. Physical data independence ensures that these security measures remain effective even as the physical storage configuration evolves.
- Reducing Maintenance Overhead: With physical data independence, maintenance tasks, such as reorganizing data for optimal storage or backup strategies, can be performed more efficiently without impacting the users or applications that rely on the data.
You might also be interested in reading:
Login to continue reading
And access exclusive content, personalized recommendations, and career-boosting opportunities.
Don't have an account? Sign up
Never miss an
Update

Featured Opportunities
Top-Rated Practice by Students





Subscribe
to our newsletter



Comments
Add comment