
Asian Paints Alchemy 2026
Table of content:
- Data Redundancy: Understanding with Example
- Causes of Data Redundancy
- Problems Associated With Data Redundancy
- Advantages and Disadvantages of Data Redundancy
- Solution of Data Redundancy for Database Management Systems
- Summing Up
- Frequently Asked Questions(FAQs):
Decoding Data Redundancy In DBMS| Causes, Advantages, Solutions

Data Redundancy: Understanding with Example
As discussed above, data redundancy refers to the presence of duplicated or identical copies of the same data in multiple locations within a system or database. Let's consider a simple example to illustrate data redundancy in a relational database.
Suppose we have a database for a company that stores information about employees and the departments they work in. The database might have two tables: "Employees" and "Departments."
Employees Table:
| EmployeeID | EmployeeName | DepartmentID | Salary |
|---|---|---|---|
| 1 | Alice | 101 | 50000 |
| 2 | Bob | 102 | 60000 |
| 3 | Carol | 101 | 55000 |
Departments Table:
| DepartmentID | DepartmentName |
|---|---|
| 101 | Sales |
| 102 | Marketing |
In this example, the "DepartmentID" is used to link employees to their respective departments. However, notice that the department name is also stored in the "Employees" table. This redundancy arises because the department name information is repeated for each employee in the same department.
This situation can lead to potential issues:
-
Inconsistency: If the update is not performed consistently across all relevant records, the database may contain inconsistent information about the department names.
-
Update Anomalies: If the update is missed or not performed correctly in some places, it can result in inconsistencies, making it challenging to maintain accurate and reliable data.
To address data redundancy and improve normalization, the department name could be removed from the "Employees" table, and queries could use joins to retrieve information from both tables based on the common "DepartmentID." This way, changes to department names only need to be made in one place, reducing the risk of inconsistencies.
Causes of Data Redundancy
Various factors can cause data redundancy in a database, and it often arises unintentionally during the database design or data maintenance process. Here are some common causes of data redundancy:
-
Denormalization: Denormalization is a database design technique where redundant data is intentionally introduced to improve poor database design and query performance. While denormalization can enhance read performance, it also increases the risk of data redundancy and update anomalies.
-
Lack of Normalization: Normalization is the process of organizing data in a database to reduce redundancy and improve data integrity. If a database is not adequately normalized, meaning it has not gone through the process of breaking down tables into smaller or related tables, redundancy can occur.
-
Copy and Paste Operations: During data entry or maintenance, individuals may copy and paste information across records or tables. This manual process can lead to unnecessary duplication of data.
-
Incomplete Updates: If updates to data are not consistently applied across all relevant records, inconsistency and excessive redundancy can occur. This is particularly true when a piece of information needs to be updated in multiple places, and some updates are missed.
-
Changes in Requirements: Over time, business requirements may change, leading to updates in the database schema or data structure. If these changes are not carefully managed, they can introduce redundancy. For example, if a new attribute is added to one part of the system but not to another, redundancy may result.
-
Data Import and Integration: When integrating data from different redundant sources or importing data into a database, there may be challenges in aligning data structures. Merging data from diverse origins can lead to redundancy if there's not a clear strategy for handling overlapping information.
-
Historical Data: Storing historical data for auditing or analysis purposes can introduce redundancy. For instance, if historical data is stored alongside current data in the same tables, it may result in redundant information.
-
Application Design Choices: The design choices made in the development of applications that interact with the database can also contribute to data redundancy. If application developers duplicate data for convenience or performance reasons, it can lead to redundancy issues.
Also Read: Fact Table And Dimension Table | Types, Examples, Key Differences
Problems Associated With Data Redundancy
Data redundancy, while sometimes unavoidable, can introduce several problems and challenges in a database. These problems are associated with inconsistencies, update anomalies, and increased storage requirements. Let's explore these issues with examples:
- Inconsistency: Inconsistency arises when the same piece of information exists in multiple places and is not updated consistently across all instances. This can lead to conflicting or contradictory data within the database. Example: Consider a database that stores customer information, including addresses. If a customer changes their address, but the update is only applied to some records and not others, there will be inconsistency in the data. Some parts of the system will have the old address, while others will have the updated one.
- Update Anomalies: Update anomalies occur when an attempt to update data results in incomplete or incorrect changes, leading to inconsistencies in the database. Example: Continuing with the customer information example, suppose a customer has multiple orders associated with their ID. If the customer's name is misspelled and needs correction, updating it in one place but not in all related orders may lead to an update anomaly. Some orders will reflect the corrected name, while others will still have the old, incorrect name.
- Insertion Anomalies: Insertion anomalies occur when it is not possible to add certain data to the customer database without adding other unrelated data. This can make the insertion of new records challenging. Example: In a university database where student information is stored along with the courses they take, if a student has not yet registered for any courses, adding their information may be problematic if the database design requires the presence of at least one course. This unnecessary dependency can lead to insertion anomalies.
- Deletion Anomalies: Deletion anomalies occur when removing data from the database results in unintended loss of other related information. Example: Consider a database tracking employees and the projects they are assigned to. If deleting a project also deletes database entry about the employees involved in that project, it leads to a deletion anomaly. Removing one piece of information (the project) unintentionally causes the loss of another piece of information (employee details).
- Increased Storage Requirements: Redundant data consumes more storage space than necessary, leading to increased storage costs and potentially affecting performance. Example: In a product inventory database, if the supplier information is duplicated for each product they supply, it leads to increased storage requirements. Instead of storing supplier details with each product, a normalized approach would involve a separate table for suppliers, reducing redundancy and storage needs.
Advantages and Disadvantages of Data Redundancy
Advantages:
Advantages include the following:
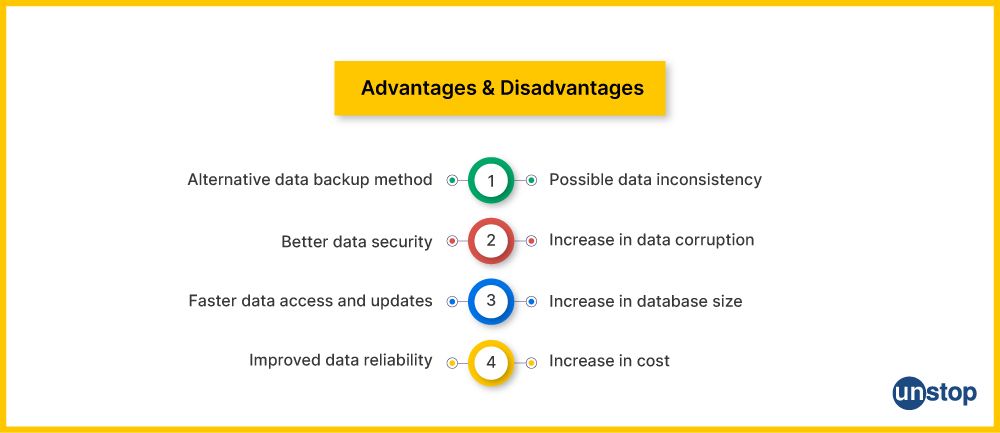
- Backing up of data - This alternative data backup method is done by creating compressed and encrypted versions of data and storing it in a computer system or the cloud. The data is replicated to another system to provide an extra layer of protection.
- Data Security enhancement - It provides better data security such that data in a database or file storage system is protected from unwanted activities such as cyber attacks or data breaches. The same data when stored in two or more places prevents loss of time and money in terms of lost data.
- Data Access and Updates faster - Redundant data allows faster access and quick updates so that necessary information is easily accessible and available on multiple systems. It allows promptness and efficiency.
- Data Reliability is improved - It makes data reliable, complete and accurate. Data can be confirmed to be complete or correct as it allows double checking of data.
Disadvantages
Drawbacks include the following points:
- Data Inconsistency - The term data inconsistency refers to existence of the same data in different formats in multiple databases. Redundant data leads to inconsistent duplicate copies of data and meaningless or unreliable information in a company's database.
- Data corruption is increased - The term data corruption refers to damage to data due to error in reading, writing, storage or processing. This happens when same data fields are repeated in a database or file storage system like when data is redundant. Corrupted files generate error message for the customers if the task is not completed
- Database size increases - Size and complexity of the database is increased due to redundant data making maintenance of the database a challenge. Larger database leads to long load times and longer time is spent on completion of daily tasks.
- Cost increase - Storage costs increase and can affect the profits and goals of the companies due to redundant data. The implementation of a database system becomes very expensive.
- Additional space consumed - Redundant data takes up additional space which adds up over time to form bloated databases. This can prove to be a problem for companies to meet the demands of their customers.
Solution of Data Redundancy for Database Management Systems
Many database administrators consider it important to have a certain level of redundant data as a backup of the master data. However the most important problem associated with this redundant data is the presence of database inconsistencies. This is avoided with the help of a central master field where the master field keeps a single source of the business data across multiple applications and ensures that changes in one database automatically update the other databases. This prevents data inconsistencies in the database management systems.
This problem can also be resolved by the process of database normalization. This database normalization process involves rearranging the rows and columns comprising relations and attributes, respectively. This organization is done to ensure that the dependencies are correctly enforced by database integrity constraints. Normalizing data makes the data resistant to data duplication errors. Normalizing data follows certain rules called normal form and the database is considered to be normalized when it is free of insert, delete, and update anomalies.
Solution of Data Redundancy for Different Systems
Redundant data present in different systems can be resolved by following multiple steps, like designing a data warehouse and cleansing the data. This is a time-intensive process but is very helpful in removing redundant data present in multiple systems.
Summing Up
- Data Redundancy refers to having multiple redundant copies of the same data stored in two or more separate places. It leads to the same data in multiple folders or databases, which can lead to a lot of problems.
- Data redundancy can occur either intentionally or accidentally. Accidental data redundancy can occur due to complex processes or inefficient coding, while intentional data redundancy can be done to protect the data by ensuring backups.
- Problems associated with data redundancy include insertion anomaly, deletion anomaly, and update anomaly.
- Advantages of data redundancy include backing up of data, data security enhancement, quicker data access and updates and improved data reliability.
- Disadvantages of data redundancy include data inconsistency, increased data corruption, increased database size, increased cost and consumption of additional space.
- This problem can be resolved in database management systems using a central master field and consistent database normalization process. This can also be resolved in multiple systems.
Frequently Asked Questions(FAQs):
1. What is data redundancy in a DBMS, and why is it a concern?
Data redundancy in a Database Management System (DBMS) refers to the repetition of the same data in multiple places within a database. It is a concern because it can lead to inconsistencies, update anomalies, and increased storage requirements, impacting data integrity and database performance.
2. How does data redundancy relate to normalization in a relational database?
Normalization is a process in database design that aims to minimize data redundancy by organizing data into smaller, related tables. By eliminating or reducing redundancy through normalization, databases achieve a more efficient structure that helps prevent data inconsistencies and anomalies.
3. What are some common examples of data redundancy in a DBMS?
Examples of data redundancy include storing the same information (such as names, addresses, or department names) in multiple tables or records within a table. For instance, duplicating customer addresses across orders or having repeated department names in an employee table can demonstrate data redundancy.
4. How can data redundancy lead to update anomalies?
Data redundancy can result in update anomalies when an attempt to update data is incomplete or inconsistent across all instances. For example, updating a customer's address in some records but not others can lead to inconsistencies, making it challenging to maintain accurate and reliable data.
5. What steps can be taken to mitigate data redundancy in a DBMS?
Mitigating data redundancy involves normalization, careful relational database design, and adherence to normalization forms. By breaking down tables into smaller, related tables and establishing relationships, redundant data can be minimized. Regular reviews of the database schema and data maintenance processes are also crucial to identify and address redundancy issues.
You may also like to read:
Login to continue reading
And access exclusive content, personalized recommendations, and career-boosting opportunities.
Don't have an account? Sign up
Never miss an
Update

Featured Opportunities
Top-Rated Practice by Students





Subscribe
to our newsletter
Blogs you need to hog!

This Is My First Hackathon, How Should I Prepare? (Tips & Hackathon Questions Inside)
D2C Admin

10 Best C++ IDEs That Developers Mention The Most!
D2C Admin

Advantages and Disadvantages of Cloud Computing That You Should Know!
D2C Admin

Is IoT Valuable? Advantages And Disadvantages Of IoT Explained
Shivangi Vatsal
Comments
Add comment