
Asian Paints Alchemy 2026
Table of content:
- Why data science is so important?
- Data science lifecycle in the modern era
- Summing up
- Test Your Skills: Quiz Time
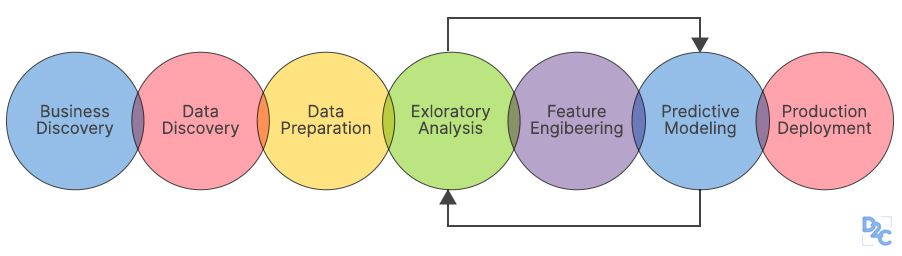
What Is A Data Science Lifecycle?
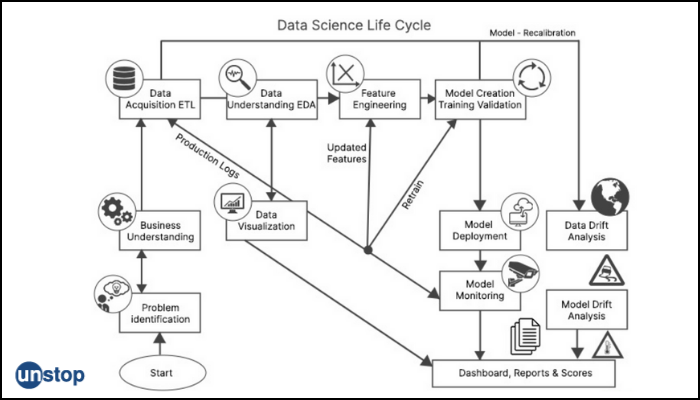
As a data scientist aspirant, you must be eager to learn about the data science lifecycle so that you may optimize and streamline business operations by implementing a perfectly carved-out data science lifecycle. Business objectives can be achieved efficiently and effectively through a well-structured data science lifecycle.
In basic terms, a data science lifecycle is a series of iterative steps that need to be performed in order to finish and deliver a project/product to a client that addresses their business challenges by adapting to a new evaluation metric. Despite the fact that data science projects and the teams participating in deploying and developing the model will differ, every data science lifecycle in every other firm will only be slightly different due to a closely related business understanding. The majority of data science initiatives follow a similar procedure.
We need to understand the various roles and duties of the science professionals engaged in constructing and growing a data science model by using their skill sets. They are-
- Business Analyst
- Data Analyst
- Data Scientists
- Data Engineer
- Data Architect
- Machine Learning Engineer
These professionals take on the task of business problem understanding, data collection, data cleaning and processing, exploratory data analysis, model building, and evaluation model family, model communication, model deployment, and evaluation.
Why data science is so important?
Data used to be considerably less and typically available in a well-structured form, which we could save simply and quickly in Excel sheets, which then would be analyzed swiftly with the aid of business intelligence tools. However, in today's world, we deal with a massive explosion of records and data, such as the 3.0 quintals bytes of records produced per day.
According to recent studies, 1.9 MB of data and records are produced in a second by a single person. So dealing with such a tremendous volume of data is a huge task for any firm.
The need for sophisticated, complicated algorithms and technologies to handle and evaluate this data is real, which is where data science comes into play.
The following are some of the most important reasons to adopt data science technology:
- It aids with the conversion of large amounts of raw and unstructured data into actionable insights.
- Neural networks may help with a variety of forecasts, such as surveys, elections, and so on.
- It also aids in the automation of transportation, such as the development of self-driving cars, which we might say is the transportation of the future.
- Data science is becoming more popular among businesses, and they are adopting this technology. Amazon, Netflix, and other companies that deal with large amounts of data utilize information science techniques to improve the customer experience.
Data science lifecycle in the modern era
The life cycles shown below are more current methods of data science. OSEMN, like data mining procedures, focuses on the core data problem. The majority of the others, particularly Domino's, prefer to focus on a more comprehensive solution.
- OSEMN is a five-phase life cycle that stands for Obtain, Scrub, Explore, Model, and iNterpret.
- The Team Data Science Process (Microsoft TDSP) combines several contemporary agile concepts and intelligent applications with a life cycle that is comparable to CRISP-DM. Business understanding, data acquisition and understanding, modeling, deployment, and customer acceptance are the five phases.
- Life cycle of domino data labs: A final operations stage is included in this life cycle. Ideation, data acquisition and exploration, research and development, validation, delivery, and monitoring are the six processes in the customs process.
- By delivering preliminary findings in the form of descriptive statistics, fascinating insights, a report on model performance, or a dashboard, key stakeholders may provide context to items that the data team may have missed.
Some data science life cycles concentrate just on the data, modeling, and evaluation stages. Others are more complete, beginning with knowledge of the company and ending with the subsequent step like deployment, which includes training and monitoring of model performance. Let us dive deeper into the elaborate technique of the data science life cycle:
1) Recognizing the client's business problem
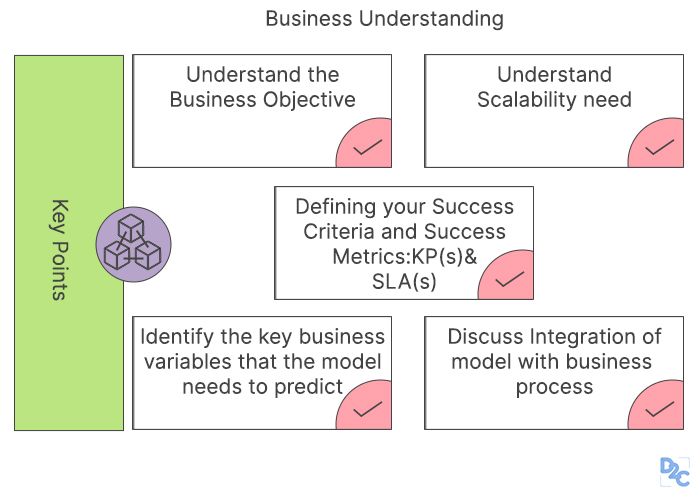
In order to create a successful business model, it's critical to first recognize the client's business challenges. Assume he wants to forecast his retail business's client attrition rate.
You should first learn about his company, his requirements, business challenges, and what business goals he aims to achieve from the forecast. In such circumstances, it is critical to seek advice from domain specialists and, ultimately, to comprehend the system's core flaws. A Business Analyst is in charge of acquiring the necessary information from the customer and delivering it to the data scientist team for further analysis. Even the tiniest mistake in identifying the problem and comprehending the need can have a significant impact on the project, thus it must be done with extreme care.
We go on to the following step, data collecting, after asking the necessary questions of the company's stakeholders or clients.
Here's where we'll need the correct metrics:
- KPI (Key Performance Indicator)
Assess your performance in relation to major business goals. Businesses use this to track their progress toward their goals and assess their overall health. It's critical to agree on the correct set of KPIs for each company and avoid the temptation of chasing vanity metrics that seem good but aren't useful.
- SLA (Service Level Agreement)
A Service-Degree Agreement (SLA) specifies the level of performance that a client expects from a provider, as well as the metrics that are used to assess that service. For example, suppose you're building a sophisticated pipeline with an SLA of 100 milliseconds and a tonne of transactions to process.
This initial phase should include the following:
- Clearly state the problem that needs to be solved and why it has to be solved.
- Encourage everyone engaged to work toward this goal.
- Define the project's potential benefit. Identify the project's dangers, including ethical issues.
- Determine who the important stakeholders are.
- Align the data science team with the stakeholders.
- High-level knowledge about the subject of research
- Determine how many resources (data science teams and infrastructure) you'll require.
- Create a high-level, flexible project strategy and explain it.
- Determine the sort of problem that has to be solved*
- Obtain support for the initiative.
2) Data Gathering
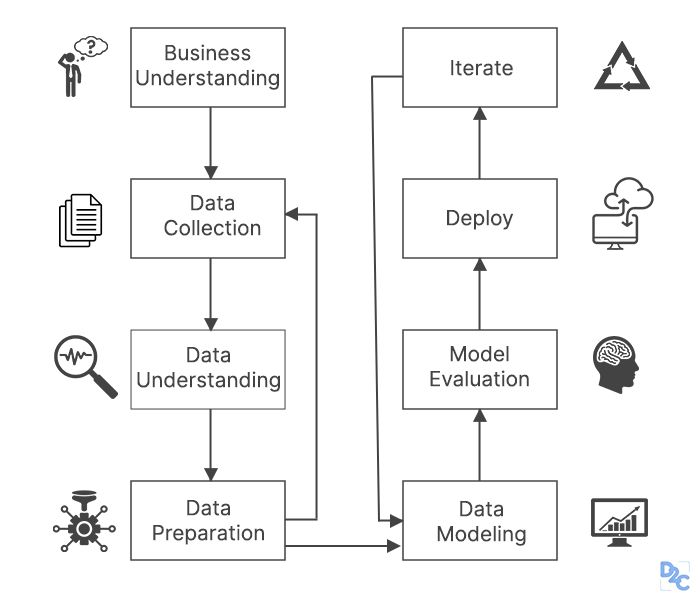
After we've clarified the issue statement, we'll need to gather relevant data in order to split the problem down into smaller parts. The data science project begins with the identification of multiple data sources, which might include web server logs, social media postings, data from digital libraries like the US Census databases, data obtained via APIs, web scraping, or information already available in an excel spreadsheet.
Data collecting comprises gathering information from both known internal and external sources that might help solve the problem. The data analyst team is usually in charge of gathering the information.
To acquire the necessary outcomes, they must find out how to properly gather and collect data.
The data can be obtained in two ways:
- Using Python to scrape the web
- Using APIs from outside parties to extract data
3) Preparation of data
We must proceed to data preparation after acquiring data from appropriate sources. This stage, unlike the previous step, aids with the comprehension of the data and prepares it for subsequent analysis. This step is often referred to as Data Wrangling or Data Cleaning.
Selecting relevant data, merging it by mixing data sets, cleaning it, dealing with missing values by either eliminating them or imputing them with relevant data, dealing with inaccurate data by removing it, and checking for and dealing with outliers are all procedures involved.
You may build new data and extract new features from current data by utilizing feature selection. Remove any extraneous columns or functions from the data and format it according to the required structure.
The most time-consuming phase, accounting for up to 90% of the total project length, is data preparation, which is also the most important stage throughout the whole life cycle.
At this stage, exploratory data analysis (EDA) is crucial since summarising clean data allows you to identify the data's structure, outliers, anomalies, and patterns. These findings can assist in the selection of the best collection of characteristics, the development of a model-creation algorithm, and the building of the model.
4) Modeling of data
In most situations of data analysis, data modeling is considered the most crucial step. A data scientist first builds a baseline model that has been successful in the past and then customizes it to fit the needs of the company. We use the prepared data as the input in this data modeling procedure, and we strive to produce the required model output with it. Whether the challenge is a regression, classification, or clustering-based problem, we first prefer to pick the suitable type of model that will be used to obtain results. We determine the optimum method for the machine learning model based on the type of data we get. After that, we must modify the hyperparameters of the predictive models to get a desirable result.
Finally, we assess the model by determining its correctness and relevance. In addition to this endeavor, we must ensure that there is a proper balance of specificity and generalizability and that the model generated is unbiased.
5) Model evaluation
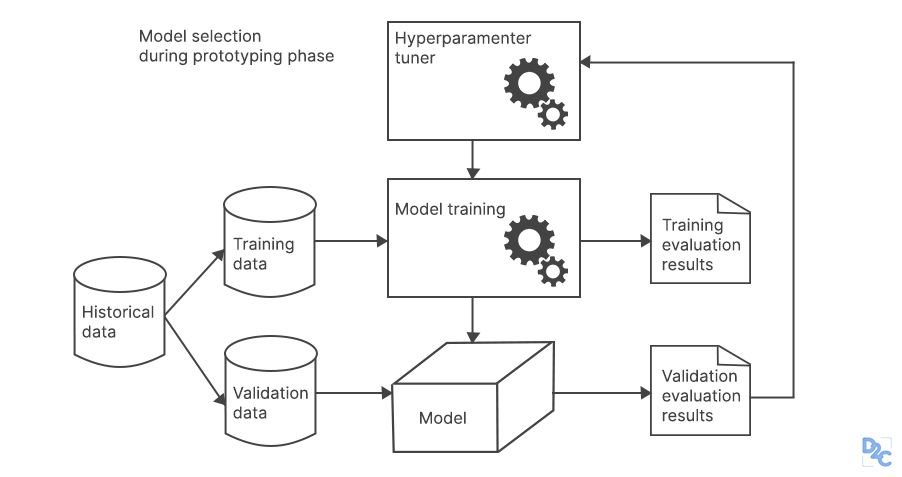
Here, the model is assessed to see if it is ready for deployment. The model is tested on previously unknown data and assessed using a carefully developed set of assessment measures. In addition, we must ensure that the model is accurate. If the evaluation does not yield a satisfactory outcome, we must repeat the entire modeling approach until the desired level of metrics is reached. Any data science solution, such as a machine learning model, must develop, be able to improve itself with fresh data, and adapt to a new assessment measure. We can create several models for a given occurrence, but many of them will be flawed.
- Data Drift Analysis: We compare the incoming data distribution from the actual world with the one that has been scored, and if there is a difference, we must choose a threshold.
If the discrepancy is significant, the incoming data will be skewed. In this scenario, we'll have to go back and look at the differences again.
- Model Drift Analysis: we compare the difference between the score of the real-world model distribution and the scored model distribution, and this information is fed into a system that reports and outputs to the business user on a regular basis.
It would state, for example, how many consumers the company gained, how much money company made in dollars, what this means in terms of income streams, and so on.
Data drift can be caused by a variety of factors, including:
- Alters in upstream processes, such as the replacement of a sensor that changes the units of measurement, or a damaged sensor that always reads 0.
- A natural variation in the data, such as the change in mean temperature with the seasons.
- Changes in the nature of the relationship between characteristics.
- What can you do to help?
- Erroneous labeling should be removed.
- Model retraining/calibration
- Early detection and correction of upstream data issues
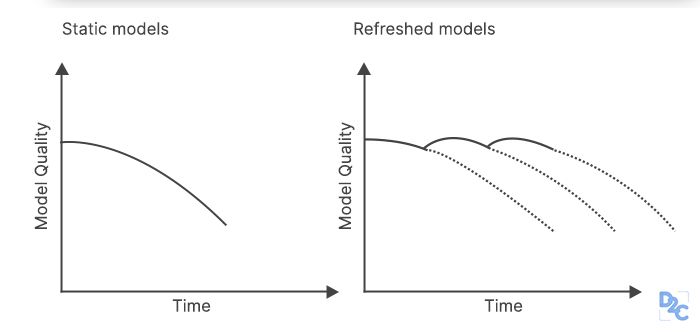
In scenarios when your machine learning model(s) become stale due to concept or data drift, as seen in the graph below on the left, we may prevent model staleness over time by refreshing the model over time.
6) Deployment of the model
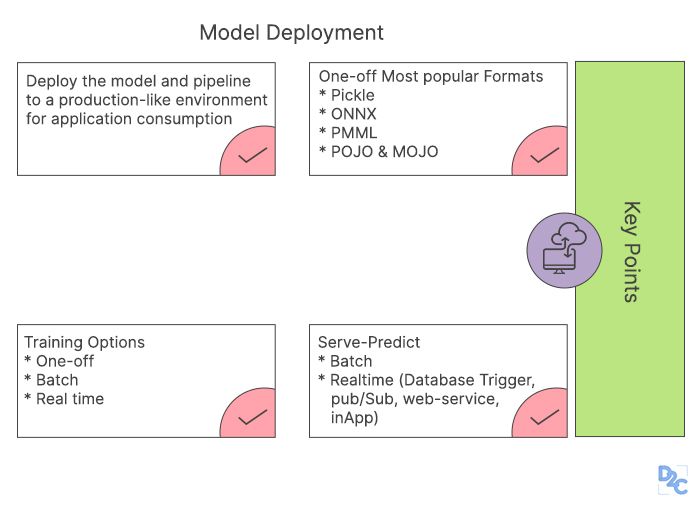
We need to be sure we've chosen the proper answer after a thorough examination before we deploy a particular type of model. It's then distributed in the specified channel and format. Deployment of a particular type of model is, of course, the final phase in the data science project life cycle. To avoid unintended mistakes, please exercise additional caution before completing each phase in the life cycle.
For example, if you use the incorrect machine learning method for data modeling, you will not attain the needed accuracy and will have a tough time obtaining stakeholder support for the project. If your data isn't adequately cleaned, you'll have to deal with missing values or noise in the dataset afterward.
As a result, comprehensive testing will be required at each phase of deploying a type of model to monitor model performance and to ensure that it is effectively deployed and approved in the actual world as an ideal use case. All of the processes outlined above are equally relevant to both novice and experienced data scientists. As a newbie, your task is to first understand the technique, then practice and launch smaller analytics projects such as the false news detector and the Titanic dataset.
Your first task is to thoroughly complete all elements of the data science life cycle, and once you have completed the process and deployment, you are ready to take the next step toward a career in this sector.
Python and R are the two most extensively used languages in data science applications. An application developer should be comfortable coding in these languages in addition to having a clear understanding of the process. You must be proficient in all areas, from process comprehension to programming language expertise.
Summing up
Choose the optimal solution for your problem by analyzing specific use cases and selecting the appropriate metrics, starting with the business perspective: KPIs and SLAs will aid in determining the best path from development to production deployment of machine learning or artificial intelligence models for predictive models, as choosing the way to deploy predictive models into the production is a challenging task.
Machine learning is not the answer to every problem; if you can handle a problem in a more straightforward manner without using Ml, you should do so; the simpler the solution, the better.
Test Your Skills: Quiz Time
You might also be interested in reading:
Login to continue reading
And access exclusive content, personalized recommendations, and career-boosting opportunities.
Don't have an account? Sign up
Never miss an
Update

Featured Opportunities
Top-Rated Practice by Students





Subscribe
to our newsletter
Blogs you need to hog!

This Is My First Hackathon, How Should I Prepare? (Tips & Hackathon Questions Inside)
D2C Admin

10 Best C++ IDEs That Developers Mention The Most!
D2C Admin

Advantages and Disadvantages of Cloud Computing That You Should Know!
D2C Admin

Is IoT Valuable? Advantages And Disadvantages Of IoT Explained
Shivangi Vatsal
Comments
Add comment