
Asian Paints Alchemy 2026
Table of content:
- Different Data Types
- Significance of collecting accurate and suitable data
- Data Handling Steps
- How to represent data?
- Summing up
What is Data Handling? Understanding The Basics
The act of obtaining, documenting, and presenting data that is present in raw form is known as data handling. Let's explore this topic in detail.

The act of obtaining, documenting, and presenting data that is present in raw form in a way that enables analysis, prediction, and decision-making is known as data handling. Data can be described as anything that can be classified according to a set of similar criteria. The context in which the things are compared is referred to as parameters. Pictographs, bar graphs, pie charts, histograms, line graphs, stem and leaf plots, and other visual representations of data management are common.
Different Data Types
Qualitative Data Type
In qualitative or categorical data, the item under examination is described using qualitative methods and a finite number of discrete classifications. This indicates that this type of information can't be easily counted or measured with numbers and has to be categorized. This data type includes things like a person's gender (male, female, or other).
These are frequently derived from reliable sources such as audio, images, or text-based media in a readable format. A smartphone brand, for example, may provide information such as the current rating, phone color, phone category, and so on. All of this information falls into the qualitative data category. There are two subcategories in this:
- Nominal: These are the values that don't follow any kind of natural order. Let's have a look at a few examples to assist you in understanding. The color of a smartphone can be considered a hypothetical data type because we can't compare one hue to another.
- Ordinal: These values have a natural ordering while remaining within their class of values. When it comes to clothing brands, we can easily classify them according to their name tag in small, medium, and big order. The grading method used to assess candidates in an exam may also be thought of as an ordinal data type, with an A+ clearly superior to a B grade.
These categories assist us in determining which encoding approach is appropriate for whatever sort of data. Because machine learning models are mathematical in nature, data encoding for qualitative data is necessary because these values cannot be handled directly by the models and must be translated to numerical kinds, and first-hand sources are needed.
For nominal data types where there is no comparison among the categories, one-hot encoding may be used, which is comparable to binary coding because there are less numbers, and for ordinal data types, label encoding, which is a sort of integer encoding, can be used.
Quantitative Data Type
This data type attempts to quantify things by taking into account numerical values that make it countable in nature. The price of a smartphone, the discount provided, the number of ratings on a product, the frequency of a smartphone's CPU, or the RAM of that specific phone are all examples of quantitative data kinds.
One thing to keep in mind is that a feature can have an infinite number of values. For example, the price of a smartphone can range from x amount to any value, and it can further be subdivided into fractional amounts. The two subcategories that best define them are:
- Discrete: This category includes numerical values that are either integers or whole numbers. The amount of speakers in a phone, cameras, processing cores, and the number of SIM cards supported are all instances of discrete data.
- Continuous: Fractional numbers are treated as continuous values. These might include the processors' working frequency, the phone's Android version, Wi Fi frequency, core temperature, and so on.
Significance of collecting accurate and suitable data
Effective data handling in research is vital for producing credible and reliable results. It involves meticulous processes from data collection to dissemination, ensuring data integrity, security, and ethical compliance.
Systematic data handling supports transparency and reproducibility in research, enabling other researchers to verify and build upon existing findings. By using appropriate data-gathering instruments and adhering to well-defined guidelines, researchers significantly reduce the risk of errors, ensuring the reliability and validity of their data.
The following are the consequences of poorly gathered data:
- Incapacity to appropriately answer research questions.
- The failure to replicate and confirm the study leading to skewed findings, wasting resources and prompting other academics to follow useless areas of exploration, jeopardizing public policy choices and causing harm to human participants and animal subjects.
- While the extent of the impact of inaccurate data collecting may vary depending on the field and type of the inquiry, when these research findings are used to support public policy recommendations, there is a risk of creating disproportionate harm.
Data Handling Steps
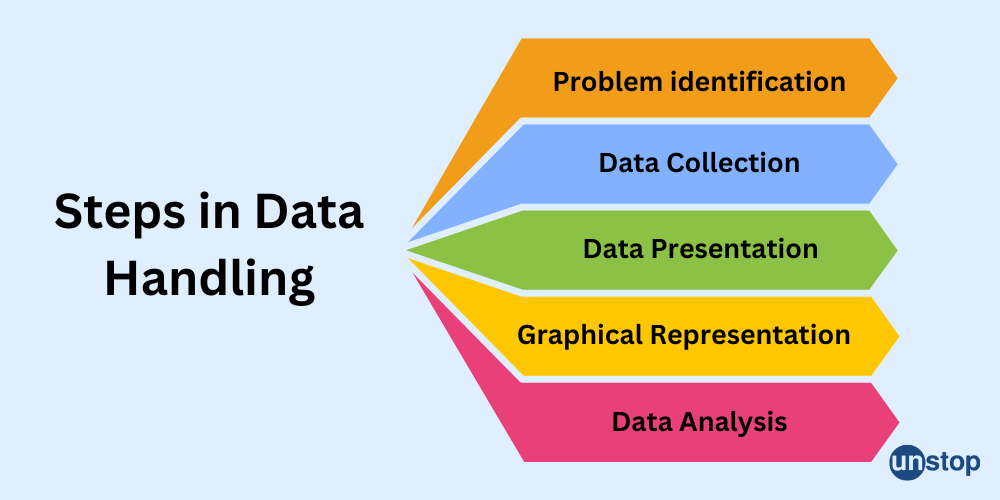
Here are the primary steps that are involved in data handling:
- Problem identification: The objective or issue statement must be recognized and adequately specified during the data handling process.
- Data Collection: Data pertinent to the issue statement is gathered.
- Data Presentation: The obtained data should be reported in a logical and understandable manner. It is possible to accomplish this by organizing the obtained data in tally marks, table shapes, and so on.
- Graphical Representation: Because visual or graphical representation of data facilitates analysis and comprehension, provided data can be displayed in graphs, charts such as bar graphs, pie charts, and so on.
- Data Analysis: The data should be analyzed so that the essential information can be derived from the data, allowing for subsequent actions to be taken.
How to Represent Data?
Data can be represented using the following ways:
1. Tally marks: The observations are organized using tally marks. Every observation should be documented with a vertical mark, but every fifth observation should be recorded with a mark over the four previous markings, as depicted below.

2. Bar Graphs: A bar chart is one of the simplest forms of graph that has rectangular bars. Typically, there are different forms of graph, the graph contrasts various categories. Although bar graphs can be produced vertically (bars standing up), also known as vertical bar graphs, or horizontally (bars resting flat from left to right), vertical bar graphs are the most common.
The horizontal (x) axis shows the categories, while the vertical (y) axis displays the values associated with those categories. The figures in the graph below are percentages.
A bar graph is useful for comparing and analyzing a set of data and visualizing a collection of observations. For example, rather than looking at a string of numbers, it's easier to understand which things are using the most of your money by glancing at the above chart. They can also highlight patterns in periodic sequences or indicate trends over time.
Stacked bar charts and grouped bar charts can also be used to show more complicated categories. For example, if you had two houses and needed budgets for each, you might use a grouped bar chart to plot both on the same x-axis, using different colors to represent each property.
Following are the types of bar graphs:
- Grouped Bar Graph: A grouped bar graph is a visual representation of data from sub-categories of the primary categories.
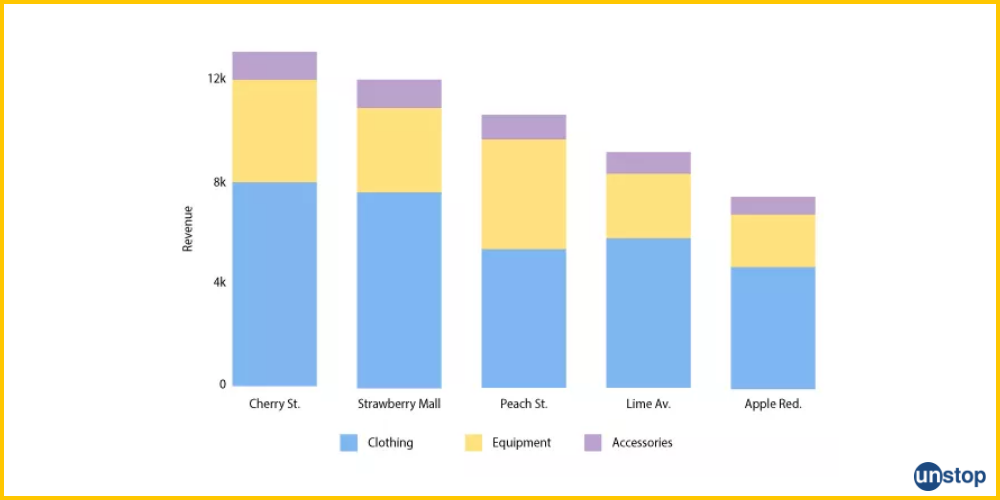
- Stacked Bar Chart: A stacked bar chart also shows sub-groups, but the sub-groups are stacked on the same bar.
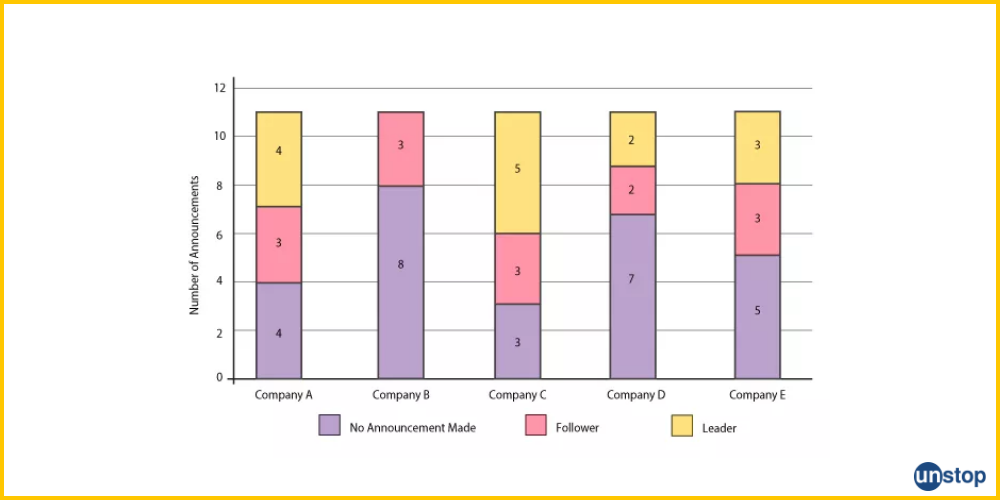
- Segmented Bar Graph: A type of stacked bar chart where each bar shows 100% of the discrete value. They should represent 100% on each of the bars or else it’s going to be an ordinary stacked bar chart.
- Double Bar Graph: When comparing two data sets, a double bar graph might be utilized. In a double bar graph, there are two axes. The x-axis of a double-bar graph represents the comparison categories, while the y-axis shows the scale. A scale is a collection of integers that represent data at equal intervals. It is critical to understand that all double bar graphs must have a title. The title of the double- bar graph gives the viewer a basic summary of what is being measured and compared. A key will be included with a double bar graph. The key to a double bar graph is to use two different colors to depict the groups being compared.
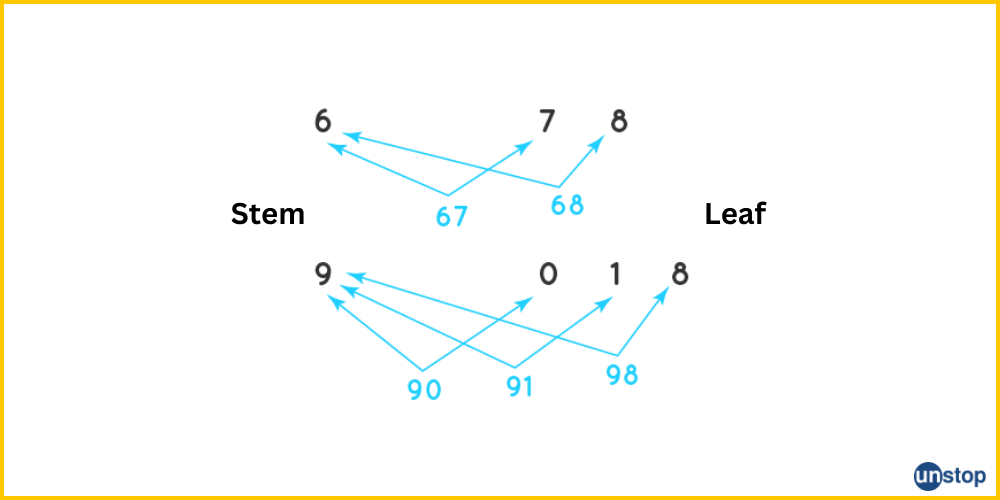
3. Stem and Leaf Plot: A stem and leaf plot is a one-of-a-kind table in which data values are divided into a stem and a leaf. The initial numeral or digits will be placed in the stem, and the last digit or digits will be written in the leaf. The following are the elements of a good stem and leaf plot:
- Portrays the number's earliest digits (thousands, hundreds, or tens) as the stem and the last digit (ones) as the leaf.
- Usually, entire numerals are used. Any number with a decimal point is rounded to the nearest whole number.
- When test results, speeds, heights, and weights are flipped on their side, they resemble a bar graph. It displays how the data is distributed—that is, the highest number, the lowest value, the most common number, and the outliers (a number that lies outside the main group of numbers). This provides valuable insights.
4. Pie Chart: A pie chart, often known as a circle chart, is a method of summarizing a collection of nominal data or illustrating the various values of a particular variable (e.g., percentage distribution). This style of chart consists of a circle split into parts. Each section represents a different category. The area of each segment is proportional to the size of a circle as the category is to the total data set. Usually, a circle chart depicts the constituent elements of a whole.
5. Picture chart: A pictorial chart (also known as a pictogram, pictograph, or picture chart) is a visual representation of data that highlights data patterns and trends using pictograms, icons or pictures in relative proportions. To graphically compare data, pictorial charts are commonly used in business communication, business operations or news articles.
What is Data Handling in Computers?
Data handling in computers includes the processes of collecting, storing, processing, managing, and securing data to ensure its accuracy, accessibility, and protection. Let's further understand these steps:
Data Collection and Storage
Data collection involves gathering information from various sources such as user inputs, sensors, and databases. Ensuring data accuracy at this stage is crucial. Once collected, data is stored in databases or cloud storage solutions. Effective storage ensures quick access and efficient processing, with considerations for scalability, speed, and security.
Data Processing and Management
Processing transforms raw data into useful information through cleaning and transformation using tools like Python, R, Apache Hadoop, and Spark. Effective data management maintains data organization and protection, involving data governance policies that ensure data quality and security. Regular backups and disaster recovery planning are also integral to data management.
Data Security
Securing data protects it from unauthorized access and breaches through encryption, access controls, and compliance with regulations like GDPR and HIPAA. Data security measures are essential to safeguard sensitive information and maintain data integrity.
Summing Up
A good knowledge of data handling can not only help you in managing unorganized data but can also provide you with a competitive edge over others. Data can be organized using pictographs, bar graphs, pie charts, histograms, line graphs, stem and leaf plots, and other visual representations of data management. In business, these can help to organize customer data and help in the analysis process or any other business process
Efficient data handling practices are vital for ensuring data integrity and security, supporting informed decision-making and operational efficiency. As data volumes grow, advanced data handling techniques are increasingly important for leveraging data effectively.
You may also like to read:
Login to continue reading
And access exclusive content, personalized recommendations, and career-boosting opportunities.
Don't have an account? Sign up
Never miss an
Update

Featured Opportunities
Top-Rated Practice by Students





Subscribe
to our newsletter
Blogs you need to hog!

This Is My First Hackathon, How Should I Prepare? (Tips & Hackathon Questions Inside)
D2C Admin

10 Best C++ IDEs That Developers Mention The Most!
D2C Admin

Advantages and Disadvantages of Cloud Computing That You Should Know!
D2C Admin

Is IoT Valuable? Advantages And Disadvantages Of IoT Explained
Shivangi Vatsal
Comments
Add comment