
Asian Paints Alchemy 2026
Table of content:
- Overview of Data Mining Architecture
- How does Data Mining work?
- Parts of Data Mining Architecture
- Data Sources
- Different Processes in Data Mining
- Database or Data Warehouse Server
- Data Mining Engine
- Pattern Evaluation Modules
- Graphical User Interface
- Knowledge Base
- Types of Data Mining Architecture
- Techniques of Data Mining
- Advantages
- Disadvantages
- Conclusion
- Frequently Asked Questions
- Know Data Mining Architecture? Prove It With This Quiz
Understanding Data Mining Architecture In Detail
Data mining techniques uncover hidden relationships among different entities within a dataset for predictive modeling purposes. Let's explore more about it.

Data mining is the process of extracting patterns and knowledge from large datasets, typically stored in a data warehouse or other repository. Data mining techniques uncover hidden relationships among different items (entities) within a dataset for predictive modeling purposes. These patterns can help to make informed decisions in marketing campaigns, customer segmentation, fraud detection, and more.

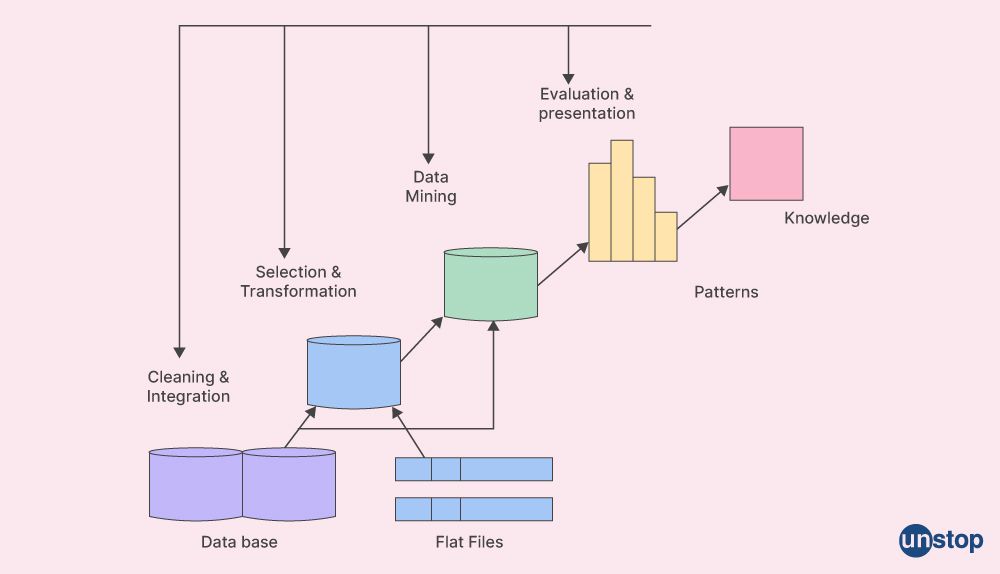
Overview of Data Mining Architecture
Data mining architecture is a complex system comprising various components and processes that extract meaningful knowledge from large volumes of data. It comprises primary sources such as file systems, databases, or web servers where the unstructured raw data lives.
This data is then collected for observations using neural networks, supervised machine learning algorithms like logistic regression or SVM (support vector machines), and Unsupervised Machine Learning techniques like clustering analysis and association rule mining, before it can be processed into information useful for decision-making.
The engine uses correlation analysis to evaluate patterns by computing the measure of interestingness between different variables to identify significant relationships within collections of records. This enables further investigation on them via linear programming methods such as dynamic programming approaches or heuristics optimization tools, thus forming crucial components in any modern data mining architecture.
Learn the nitty gritty of Data Analytics! Explore Here
Data mining architecture refers to the structure and system design of data warehousing solutions for decision support. It includes components such as hardware, software, databases, business rules, user interfaces and analytic tools, which extract valuable insights from large amounts of raw data.
Data mining architectures focus on integrating multiple sources of information into a unified platform easily accessible by end users. It usually involves a combination of data extraction, transformation and loading (ETL), analysis, and reporting to provide meaningful information for business process optimization.
How does Data Mining work?
Data mining is analyzing large data sets to discover patterns and trends to predict future outcomes. It involves identifying useful patterns from large amounts of data stored in databases, structured files, or other information repositories. Data mining uses sophisticated algorithms and statistical techniques such as regression analysis, clustering algorithms, decision trees, neural networks, and association rules to find hidden insights within a dataset. Data mining aims to extract valuable knowledge from datasets that can be used for making informed decisions about business processes or operations. The steps include:
- Data Collection: The first step in data mining is to collect data from various sources such as databases, spreadsheets, or other interactive applications.
- Data Cleaning and Preparation: After data collection takes place, it needs to be cleaned and prepared for further processing, which involves removing duplicate entries if any exist or correcting noisy/invalid values before using them with algorithms.
- Model Building: In this stage, different machine learning models are used depending on the type of problem that needs to be solved, like classification, regression etc. These models can range from simple linear regressions up to complex deep neural networks combining a large number of layers with multiple neurons in each layer.
- Evaluation & Deployment: The next important phase is evaluating our model's performance by testing it against unseen datasets (not used during training )to measure its accuracy levels while also looking at factors like time complexity, computational resources needed etc. Once we are satisfied with the results, our model will only proceed toward deployment into a production environment where real-world use cases can take advantage of these analyzed insights.
Parts of Data Mining Architecture
- Data Sources: Data used for mining can come from multiple sources such as databases, text documents, web pages, or any other electronic format.
- Data Pre-processing: This step involves transforming the raw data into a form more suitable for analysis by extracting relevant information and removing irrelevant and noisy data to make it easier to interpret results accurately.
- Mining Methodology: This refers to the techniques applied for learning knowledge from the data in various forms like clustering, classification, etc., which helps us identify patterns within datasets quickly and easily without manual processing of each record present in the dataset one by one.
- Evaluation & Interpretation: The outcome of pre-processing should be evaluated based on accuracy using different evaluation metrics along with predictive power/usefulness before arriving at conclusions about mined patterns so that appropriate decisions can be made accordingly. An understanding of domain expertise should also help interpret mined knowledge correctly according to their specific requirements.
- Visualization: To communicate effectively discovered patterns visually, graphical methods are used to represent relationships between variables found during the process, which eases comprehension and decision-making significantly when compared to traditional tabular reports representing the same information.
Data Sources
The data sources for Data Mining can be:
- Database: Databases are a great source of structured data, stored in tables and can be queried using SQL to retrieve useful information for analysis.
- Data Warehouses: A data warehouse stores electronic copies of operational databases from multiple sources that have been integrated and organized into an easily accessed set of historical records. These are used as the basis for reporting or analytics activities such as data mining, business intelligence, predictive modeling, etc.
- OLAP Cubes: Online Analytical Processing (OLAP) cubes provides multidimensional views of massive datasets by aggregating them across various dimensions such as periods, regions, or products, resulting in more concise summaries compared to traditional flat database structures, e.g., cube structure combined with MDX query language makes it easier to create complex analytical queries on large numbers quickly & accurately making this type ideal for use cases where powerful analytics are required.
- Web Logs: Weblogs offer detailed insight into website user behavior, including page visits/requests, which correlate with other factors like IP addresses & browser types, providing invaluable demographic details and allowing businesses to target their offerings better.
- Social Media Platforms: Analysing tweets' sentiment towards particular brands helps understand customer feedback so companies know.
- External Data Sources: Other external sources include government/industry data & surveys, online resources like blogs, etc., which provide additional insights into customers' behavior as they operate in the digital landscape.

Different Processes in Data Mining
- Data Selection: This process involves selecting the appropriate data for mining requests from a large pool of available information based on criteria such as relevance and usefulness.
- Pre-processing: This is an important step that carries out various tasks related to cleaning, transforming, and integrating the data before actually beginning with any form of analysis or applying techniques like clustering or classification. Data pre-processing includes operations such as removing irrelevant features (attributes), handling missing values, reducing noise in data by smoothing/averaging, etc. detecting outliers in records, normalizing attribute values if needed, encoding categorical variables using mapping functions, discretization .etc
- Transformation: It helps convert raw data into forms more suitable for mining processes like aggregation function apply(to combine the redundant transactions)and Generalization / Specialization concept used at lower level nodes while moving up through the hierarchy tree.
- Data Mining: Involves the application of algorithms and methods for discovering patterns hidden among the structured/unstructured datasets stored in databases or warehouses. These algorithms can be classified broadly into three categories supervised learning techniques (classification& regression), unsupervised techniques (clustering) & association rule mining techniques.
- Pattern Evaluation: This is the process of selecting and validating the discovered patterns which are useful and relevant for decision support. It involves assessing the quality or interestingness of patterns using different metrics such asApriori confidence, lift, etc.
- Knowledge Representation & Delivery: This phase focuses on converting the knowledge acquired from data mining into an understandable form so that users can interpret it to get necessary actionable insights. It also includes delivering knowledge effectively as per-user requirements like visualization/graphical representation/audio/text format etc.
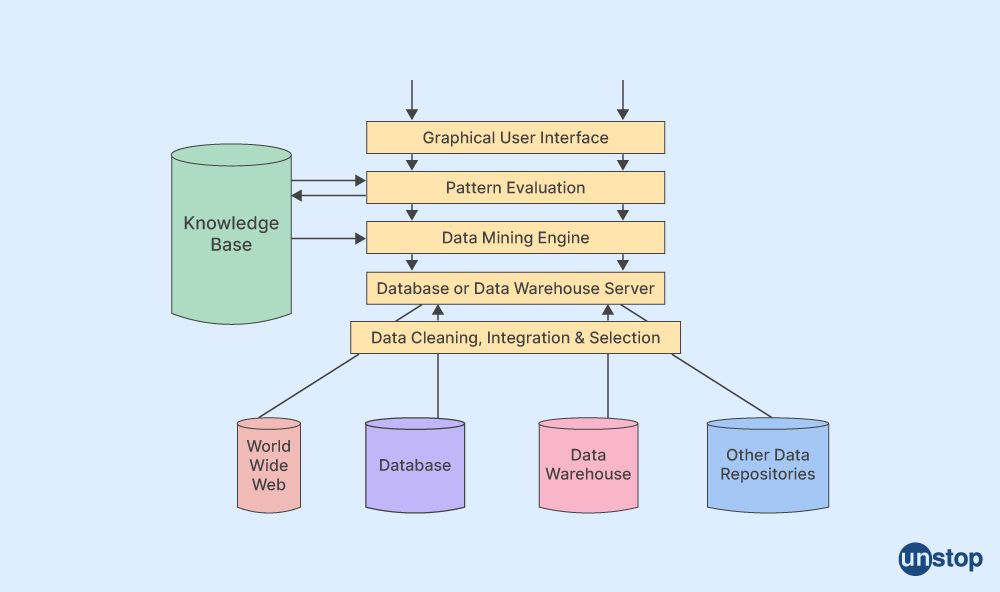
Database or Data Warehouse Server
The two main components in a data mining architecture are typically the database or data warehouse server and the analysis engines. The Database/Data Warehouse Server is responsible for storing large amounts of historical business, transactional, and operational information in an organized fashion. This could be relational databases such as Oracle, SQL Server or non-relational databases such as Hadoop or NoSQL solutions like MongoDB. The Data Warehouse contains all of this structured data combined into one larger repository, allowing analysts to query it efficiently via tools such as Business Intelligence Software (BI).
Analysis Engines allow users to analyze their collected datasets through various techniques, including clustering, classification rules generation & inference engine optimization algorithms, by leveraging sophisticated technologies such as Neuro Computing Platforms from IBM Watson Analytics Suite. Most importantly, these powerful engines also provide advanced predictive analytics that can help businesses make informed decisions regarding future investments and strategies based on what has been discovered in their past behavior using machine learning algorithms specifically designed for Big Data applications.
Data Mining Engine
Data mining engines are software programs that perform data mining tasks like pattern recognition and classification. They typically use algorithms derived from machine learning, statistics or artificial intelligence to search for patterns in large datasets. These engines can be used independently or integrated with other applications within a larger data processing architecture.
Data mining engine solutions offer various features that allow users more control over their results; these include advanced functionality such as interactive session management and intuitive graphical user interfaces (GUIs). Data miners can also access specialized tools for exploring models interactively, visualizing statistical correlations between variables and creating reports on the discovered analytics insights.
Data mining engine software packages often contain interfaces that facilitate integration with other systems and enable user requests to analyze their data sets more effectively. This can include features such as advanced query languages, user-defined functions (UDFs), and application programming interfaces (APIs).
Pattern Evaluation Modules
- Attribute Relevance Evaluation: This module evaluates the relevancy of attributes for mining tasks, such as association rules and classification trees. It uses statistical methods to select only those features that are important or highly related to the target attribute.
- Association Rule Quality Measurement: This module measures the strength of relationships between two items or attributes based on their frequency in a data set. Measures like support and confidence are commonly used in this analysis phase which helps identify important patterns among events from large datasets more quickly than if they were evaluated manually one by one.
- Cluster Validation Measures: Clustering algorithms group similar objects together into clusters, and cluster validation measures can be applied during the post-processing step after clustering has been completed so that best fitting model can be identified out of several possible ones with varying numbers of clusters produced by the same algorithm using same parameters settings but for different data sets or even same dataset/parameter setting combination. A good quality cluster should have high intra-cluster similarity while maintaining low inter-cluster similarities at once; many metrics exist, each having advantages over others depending upon the application scenario being considered (Purity measurements, Dunn’s index, etc.).
- Pattern Discovery Performance Metrics: This module evaluates the performance of a data mining algorithm on tasks like classification, clustering, and association. It measures how accurately the patterns discovered in datasets match known or predefined ones required to complete certain analysis jobs (F-measure score, precision/recall scores, etc.).
- Knowledge Representation and Interpretation: This module evaluates how well a data mining system represents the knowledge it extracts by using techniques such as explanatory rules, decision trees or Bayesian networks. It also looks at how easily interpretable the representations of acquired knowledge are to its users, providing an easier platform for manual intervention in cases where automated models cannot capture complex insights from datasets (information gain ratio, etc.).
Graphical User Interface
A GUI, or graphical user interface, allows people to communicate with electronic equipment without using text-based commands by using graphical icons and visual cues like secondary notation. The GUI provides convenience, speed and efficiency for users who want to work with complex data in data mining. It helps them easily explore different patterns or trends in their dataset while providing feedback on any potential outliers found along the way.
GUI elements such as checkboxes, sliders, drag & drop and buttons are all made available from within a single window, making it easier for end-users to access key features without needing expert knowledge of programming languages or having an extensive background in analysis techniques relating to big datasets. They also provide visualization tools that allow users to visualize their findings more effectively instead of just presenting plain tables/charts showing raw numbers - greatly enhancing communication between parties involved during decision-making processes associated with predictive models generated using advanced analytics approaches like machine learning algorithms.
Knowledge Base
Data mining architectures use various techniques from multiple disciplines, including machine learning, statistical analysis, database management and visualization. These methods are used to extract patterns and knowledge from large sets of data.
A knowledge base in such an architecture can provide a foundation for finding meaningful insights useful for decision-making, allowing the user to analyze previously unseen trends or correlations. The goal is to distill the information into actionable intelligence that can inform decisions about marketing campaigns, customer segmentation, product development, and more.
A good example of a knowledge base in Data Mining Architecture would be the KDD (Knowledge Discovery Database), which uses various algorithms like classification association rules clustering, anomaly detection, etc., to find meaningful patterns within datasets through automated processes as well as manual curation by domain experts using advanced visualizations toolsets. The result is a large knowledge base that can be used to gain better insights into customer behavior, product development and more.
Types of Data Mining Architecture
There are different types of data mining architecture:
1. No-coupling Data Mining
No-Coupling data mining is a data mining architecture that does not depend on other architectural components and works as an independent tunnel. It uses only the raw data in its system to generate new insights.
For example, suppose we have sales transaction records of a retail store with customer purchase details such as age, gender, location, etc. In that case, No-coupling data mining will use these fields to analyze transaction patterns to understand consumer behavior better. It can identify items commonly purchased together or predict customer preferences based on past purchases, enabling retailers to improve their marketing strategies.
2. Loose Coupling Data Mining
Loose coupling data mining in data mining architecture refers to the process of allowing components within a system to be connected without tight dependency on each other. This concept promotes scalability, extensibility, and maintainability by allowing individual components or modules to be changed or upgraded independently from the rest of the system.
For example, a company uses an open-source software platform for their web application with numerous third-party integrations such as payment processing gateway APIs and ML algorithms for natural language processing (NLP). Each integration can easily be swapped out without affecting changes in other parts of this system because they are loosely coupled, promoting flexibility without compromising reliability.
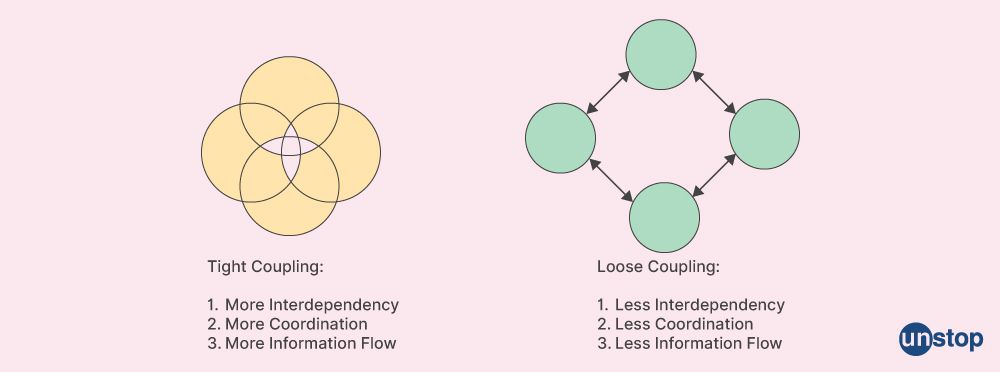
3. Tight Coupling Data Mining
Tight coupling data mining is an application architecture that uses the inherent structure and relationships between different data types. This type of architecture typically combines elements from multiple sources into one unified application, making integrating disparate pieces of information into a single entity easier.
For example, an airline company might use tight coupling data mining techniques to analyze large amounts of customer activity to make more informed decisions about which services or products should be offered at what prices. The airline will have access to many distinct datasets such as customer loyalty program membership details (age range, demographics), flight reservations (dates booked, etc.), ticket sales figures (prices/discounts applied), airports used by customers and other related information.
By using tight-coupling techniques, these various sources can be brought together into a single database with links established between them. Hence, they are all part of the same analysis process without manual inputting each time new insights are sought.
4. Semi-Tight Coupling Data Mining
Semi-Tight Coupling Data Mining is an architecture that facilitates data mining by connecting different elements of a larger system. It typically uses a database or other data repository to store the mined information and provides multiple analysis stages. This type of architecture allows organizations to identify trends and patterns in their datasets without having access to all of the underlying raw data points themselves.
For example, suppose an organization wants to collect customer feedback from online reviews on web pages. In that case, they can use Semi-Tight coupling data mining which would allow them to connect sites through APIs while maintaining confidentiality around customers' personal information such as name or address. They would then be able to gather relevant review comments using keywords like “satisfied” or “dissatisfied” before performing sentiment analysis on those words to determine overall customer sentiment towards certain products/services being reviewed while ensuring that individual customer identities are not compromised during this process.
5. Data layer
The Data Layer in a data mining architecture refers to the physical sources of raw data used for analysis. This usually comprises transactional and operational databases, spreadsheets or flat files from external sources such as public datasets. In addition, it may include web-based services that have application programming interfaces (APIs) allowing programmers to extract structured information from them.
For example, take an e-commerce website using Amazon Web Services (AWS). Their transaction database would be part of their Data Layer. At the same time, they also utilize Amazon Product Advertising APIs to access product reviews associated with items sold on the site, which serve as valuable sources for customer insights.
6. Data Mining Application layer
The Data Mining Application layer is the topmost layer in a data mining architecture. This layer provides an interface between business users and the lower-level layers of a data mining system, allowing customers to access complex analysis results without needing advanced knowledge or expertise in analytics.
An example of this could be customer segmentation using cluster analysis. Such as a group of business users may want to analyze their current client base but don't have any technical background on how to go about it. So they use software that allows them to provide some inputs like age range, occupation type, etc., and receive meaningful insights into different clusters within the existing customer set, such as "Young Professionals," "Retirees," or something similar. The application layer would then retrieve relevant datasets from other layers (such as database management) for analysis before providing actionable output backup through its user interface for decision-making purposes.
7. Front-end layer
The front-end layer refers to the user interface of data mining architecture. It is responsible for handling and displaying data for users interactively and providing access control over confidential information. The front-end layer also has a role in refining queries, allowing users to narrow search criteria or filter out irrelevant content from their search results with visual elements such as sliders or drop-down menus.
An example of this would be Amazon's 'refine by' feature; it allows customers to refine their search based on price range, brand name, color, etc., helping them find exactly what they are looking for quickly and efficiently without having to manually sift through large amounts of information.
Techniques of Data Mining
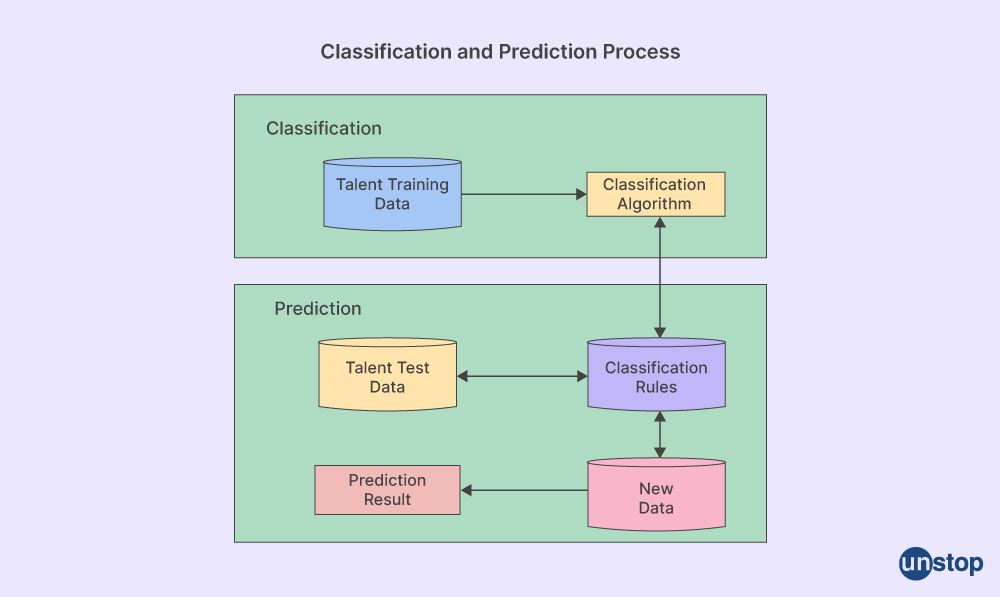
1. Classification Analysis
A data mining method called classification analysis is used to forecast an event's result based on previous observations. This type of predictive modelling can help organizations make better decisions and predict future trends.
For example, a retail store could use classification analysis to classify customers according to their spending habits so that they can target them with different marketing campaigns or offers. The store might use demographic information (such as age and gender) and location and purchase history data points when creating these classifications, which would then be mapped back onto the customer database for segmentation purposes.
2. Association Rule Analysis
Association Rule Analysis is a technique used in data mining that discovers patterns within large datasets to identify relationships between different items or variables. This type of analysis looks for correlations, which can be useful in predictive analytics and business decision-making.
For example, an association rule might find a high correlation between customers who purchase beer and pizza from the same store. With this information, increasing sales by offering discounted prices on both products when purchased together at checkout may be possible.
3. Anomaly or Outlier Detection
Anomaly or outlier detection is a technique of data mining used to identify rare instances in the dataset that do not conform to an expected pattern.
An example could be using anomaly detection to find fraudulent credit card transactions among normal activity. The system would analyze patterns from past purchases and flag any new transaction which deviates significantly from those observations for further investigation and possible rejection.
4. Clustering Analysis
Clustering Analysis is a Data Mining technique that falls under the unsupervised learning category. This method is used to discover natural groupings within data sets without using any labels or known target values. It attempts to partition a set of objects into groups such that objects in the same group have similar characteristics and are dissimilar from those in other groups.
For example, clustering analysis can analyze customer purchasing behavior by grouping customers based on their similarities according to purchase history, location, age etc. By doing this, marketers can identify different types or segments of customers like spendthrifts, bargain hunters etc., whose needs they may tailor their promotional campaigns accordingly.
5. Regression Analysis
Regression analysis is a data mining technique that uses various mathematical techniques to model relationships between two or more variables. This type of analysis helps business owners and other decision-makers better understand how changes in one variable affect another.
For example, suppose you are trying to determine the impact of advertising expenditure on product sales. You could use regression analysis to see if there is a relationship between these two factors by analyzing historical data points across many different periods. The results might show that for every 1% increase in advertising spending, there is an associated 2% rise in sales revenue - which can help inform future decisions about what levels of investment should be made into marketing campaigns going forward.
6. Prediction
Data mining is a process of using existing data to predict future trends or outcomes. For example, an online retailer may use historical sales figures and customer data to predict the total revenue they expect from customers during the upcoming holiday season. In this case, past information such as sales records and customer demographics are used as inputs for predictive models that generate statistical forecasts based on patterns found within their dataset.
7. Sequential Patterns
Sequential Patterns are one of the most popular techniques in data mining. It is a form of association rule learning that searches for frequent subsequences or patterns within a dataset. Sequential Patterns allow us to identify relationships between events and discover hidden trends, such as customer purchase behavior over time.
For example, consider an online store selling books where customers can purchase multiple titles simultaneously. Using sequential pattern analysis, we can observe common sequences wherein customers buy certain combinations of books more frequently than others. For example: Book A is often followed by Book B; Book F typically appears after both C and D; etc. This insight can then target marketing activities towards potential buyers who exhibit this purchasing behavior. For example: suggesting items based on past purchases or displaying related products when similar items have been ordered previously.
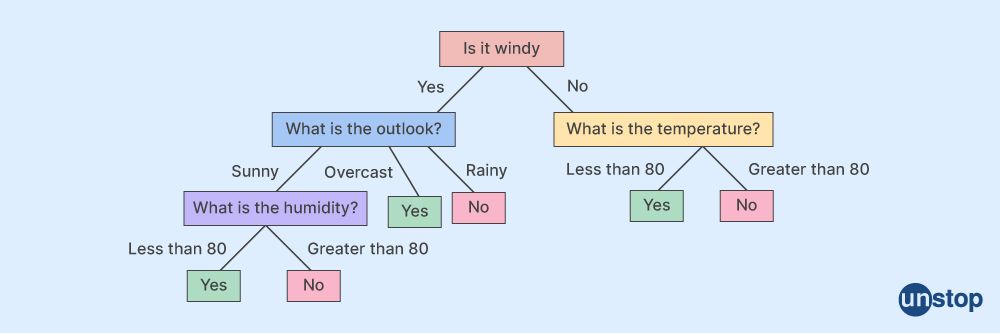
8. Decision Trees
Decision trees are a data mining technique that makes decisions based on input variables. Decision trees build models that can be applied to datasets with discrete results and predict the outcome for new observations or cases that were not present in the original dataset.
For example, when deciding whether or not to approve a loan application, decision tree algorithms would look at factors such as credit score, debt-to-income ratio, and other financial indicators of risk to determine if an applicant is likely enough to pay back the loan.
Advantages
- Improved Decision Making: Data mining helps organizations make smarter, more informed decisions by discovering patterns and correlations in the data that may have otherwise gone unnoticed. This can help improve efficiency and profitability and provide more meaningful insights into customer behavior or trends.
- Increased Productivity & Efficiency: By reducing the amount of manual labor involved in gathering information from disparate sources, data mining solutions allow employees to focus on their core competencies instead of administrative tasks such as data entry or analysis of large volumes of structured or unstructured datasets.
- Cost Savings: Automating parts (or all)of a company’s analytics processes often leads to cost savings due to reduced need for human resources, hardware costs associated with housing large datasets, and energy consumption required for running multiple algorithms simultaneously, etc. These resultant cost savings can then be used toward growth initiatives that will add long-term value to the organization, thereby directly impacting its bottom line over time.
- Improved Customer Segmentation: By analyzing customer data, businesses can better segment their customers into distinct groups for more tailored messaging or treatment based on the insights gained from such analysis. This makes it easier to create personalized offers and experiences that will benefit both parties leading to increased loyalty as well as a higher rate of satisfaction among customers.
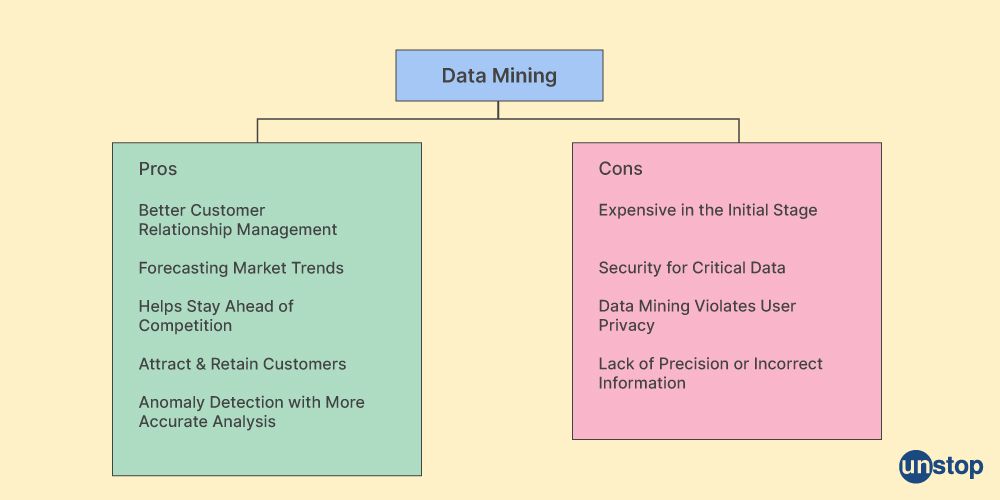
Disadvantages
- High cost: Data mining architecture requires large investments in hardware, software and personnel to ensure the system is set up correctly and functioning as expected.
- Inaccurate results: Poorly implemented or outdated data mining architectures can return inaccurate results due to incomplete or incorrect input data sets, leading to a waste of resources if not corrected promptly.
- Complexity: Developing an effective data mining framework often involves complex tasks such as preprocessing, feature selection, and model design, which require specialized knowledge to perform accurately with a high degree of accuracy for meaningful insights into business operations from mined datasets.
- Security concerns: The datasets used for machine learning are usually sensitive information about customers' private details like credit card numbers, making it vulnerable to attacks by hackers who might try accessing this confidential information illegally through the system's back-end code or front-end user interface elements.
Conclusion
Data mining architecture is a framework designed to integrate, store and analyze large amounts of data. This system uses sophisticated algorithms to uncover hidden relationships among data items for predictive modeling purposes.
By leveraging powerful analysis engines like IBM Watson Analytics Suite and advanced visualization toolsets, enterprises can gain valuable insights not initially visible through traditional methods. Tools like Decision Trees can be used in combination with these solutions, which allow users more control over their results by performing classification or clustering on input variables for better predictions & decision-making capabilities about future investments & strategies based on existing patterns found from large datasets quickly.
Overall such architecture provides great benefits when it comes to providing actionable intelligence necessary in making informed decisions about business processes or operations, thereby enabling organizations around the world to harness the power available within Big Data applications while ensuring scalability, extensibility and maintainability simultaneously!
Frequently Asked Questions
1. What is a database server in data mining architecture?
A database server is an essential part of data mining architectures, as it acts as the repository that stores all gathered and pre-processed information used for data analysis. It can also serve queries related to various aspects of stored information, such as classification or clustering patterns determined from the analytical process.
2. What are the core components of a data mining architecture?
- The core components of any given data mining architecture generally include a user interface, which allows users access to all tools;
- A warehouse system that serves as storage space; integrated services for managing tasks such as loading and staging area where datasets (data collection) reside before further processing;
- Pattern identification algorithms like neural networks for analyzing relationships between variables based on certain input metrics or criteria;
- Evaluation processes that determine true relevance by rating results according to quality and accuracy;
- Reporting services that deliver actionable insights back into the system by displaying findings through graphical visuals, etc.;
- Visualizing techniques help manipulate outputs into meaningful graphs, charts & tables, making them easier to analyze trends across multiple datasets/dimensions at once timeframes easily visible when needed.
3. What is stake measure in data mining architecture?
Stake measure determines the value of patterns identified from a given set of variables within the analyzed datasets, meaning it is possible to derive values representing their strength and significance.
By exploring underlying trends and correlations between certain metrics, one can understand much more about what specific information means for an organization or its performance overall as compared to standard statistical models, which may not always be sufficient when dealing with complex relationships existing between various factors affecting decision-making process on a whole different level.
4. What are the major components of a warehouse system in data mining architecture?
The core components of a warehouse system typically include an extraction process that allows for loading and staging datasets into the database, cleansing tools to ensure quality control (remove outliers or missing values), transformation services that transform raw input sources into recognizable structures by mapping rules; integration modules capable of integrating multiple databases/data sources as needed; finally, storage facilities where all information gets stored securely with minimal downtime due to proactive maintenance plans put in place beforehand.
5. What are the user beliefs in data mining architecture?
User beliefs refer to what a specific target audience believes or perceives when presented with certain information derived from applied analytical methods such as neural networks, decision trees, etc., which can be used to guide future decisions for better results while taking into account many factors that may have been previously overlooked due to lack of knowledge or intuition provided by the system itself.
6. What is a memory-based data mining system?
Memory-based data mining systems use techniques such as nearest neighbor classification and instance-based learning to identify patterns in a dataset. In this approach, the training dataset is stored in memory and used to predict new incoming data points by comparing them with previously encountered examples (or neighbors). This type of system does not require an explicit hypothesis or model but relies on empirical observations encoded within the underlying datasets.
7. What is a common technique used in memory-based data mining systems?
Nearest neighbor classification and instance-based learning are the most commonly used techniques for memory-based data mining systems. These methods use proximities between instances to classify new incoming datasets or identify patterns in existing ones without requiring an explicit hypothesis or model to be constructed beforehand.
8. What is the general procedure of simple data mining processes?
The general procedure of simple data mining processes typically involves the following steps:
- Data Collection: Gathering and obtaining data from structured or unstructured sources.
- Data Preparation: Cleaning, formatting, organizing, and transforming the collected data into a format suitable for analysis.
- Exploratory Analysis & Visualization: Using statistical methods to examine relationships between variables in the dataset while creating visualizations like charts and graphs to help understand patterns within the data more easily.
- Model Building & Validation: Applying machine learning algorithms to build models to predict future outcomes based on given input values or classify datasets into different categories using supervised classification techniques such as k-nearest neighbors (KNN) and support vector machines (SVM).
- Deployment & Maintenance: Deploying a trained model into production environments where it’s used as part of an automated system by running queries/predictions against new incoming datasets with real-time updates when required; this stage may also involve continuous training/retraining of existing models over time if newer versions become available with better accuracy.
Know Data Mining Architecture? Prove It With This Quiz
You may also like to read:
Login to continue reading
And access exclusive content, personalized recommendations, and career-boosting opportunities.
Don't have an account? Sign up
Never miss an
Update

Featured Opportunities
Top-Rated Practice by Students





Subscribe
to our newsletter



Comments
Add comment