
Asian Paints Alchemy 2026
Table of content:
- Basic MongoDB Interview Questions
- Intermediate MongoDB Interview Questions
- Advanced MongoDB Interview Questions
50+ MongoDB Interview Questions That Can Up Your Game
Prepare for your interview with these important MongoDB interview questions and answers, divided into basic, intermediate, and advanced categories.

MongoDB is a document database that uses JSON documents to hold its data. It goes over the idea of documents and collections. In addition to scalability and redundancy, MongoDB offers improved performance and the ability to store numerous databases. The primary purpose of this MongoDB interview question set is to give you a general sense of the kinds of questions you can encounter in an interview.
Recruiters typically begin interviews with simple questions before progressively raising the bar. Thus, we will address the fundamental questions in this MongoDB Interview Questions blog post before moving on to the more difficult ones. You can get ready for your MongoDB job interview with the help of these carefully chosen interview questions.
Basic MongoDB Interview Questions
1) What is MongoDB?
MongoDB is a Document-Oriented, Cross-Platform NoSQL Database. It is based on the document structure and with dynamically typed schema, which makes it easier to access the data integration in certain types of applications.
2) What are the features of MongoDB?
MongoDB boasts several key features, including:
1. MongoDB uses a BSON (binary JSON-like) structure for storing data. The document-oriented structure makes it simple to display sophisticated data and fluid schemes.
2. Horizontal scalability is the structure used by MongoDB. This architecture allows you to manage multiple servers for distributing data and scalability for growing applications.
3. It has a feature of quick data access and retention. It is well suited for storing high-velocity data because it performs read/write operations efficiently.
4. MongoDB utilizes a powerful and expressive query language that caters to queries such as range queries, geospatial queries, and text searches.
5. Replica set and automatic failover in MongoDB help assure data availability and fault tolerance.
6. By sharding, data is distributed across numerous servers, making large-scale data storage and management possible.

3) What type of NoSQL database is MongoDB?
MongoDB is a Document-oriented NoSQL Database. It uses the BSON (Binary JSON) format for storing data, making it a good option for the flexible and schema-less data structure. Data is grouped into sets equivalent to the tables in a relational database. The model is suitable for handling complicated, unstructured, or volatile data types that are constantly changing and can be retrieved quickly.
4) Explain about Namespace in MongoDB.
A namespace in MongoDB consists of a database name and a collection name, which uniquely specify the location storage of data. It is similar to a file path in a filesystem that facilitates effective data management by MongoDB. Furthermore, every database is associated with a set of namespaces that separate and organize collection data for that particular database.
5) Differentiate MongoDB and MySQL.
The main differences between MongoDB and MySQL include data modelling, transactions, performance, querying, schema design, and normalization. However, it can be noted that MySQL is a normalized relational database, whereas MongoDB is a NoSQL database.
6) What is the role of indexes in MongoDB?
An index in MongoDB is a data structure that greatly enhances query speeds. If there were no indexes in MongoDB, it would be necessary to examine every document stored in a particular collection to match any query. With an appropriate index, Mongo can effectively search and retrieve relevant documents quickly, reducing queries' execution time, among many other benefits.
7) Why is MongoDB considered the best NoSQL database?
MongoDB is often referred to as the leading NoSQL database. MongoDB has outstanding performance, high availability, scalability, and feature-rich queries. It uses a document-oriented database that allows storing data of different types in a flexible and structured form. Being a robust open-source database system with a vibrant community and numerous features, it has become popularly known among application scenarios of NoSQL Database and serves as the go-to solution.
8) Explain the significance of a covered query in MongoDB.
Covered queries are essential for optimizing query performance in MongoDB. When all the fields required for a query are included in an index, MongoDB can satisfy the query directly from the index. This has several benefits, including reduced disk I/O, faster query execution, and less strain on system resources. Covered queries are particularly valuable in scenarios where speed and efficiency are critical, such as real-time data retrieval in web applications and analytics processing.
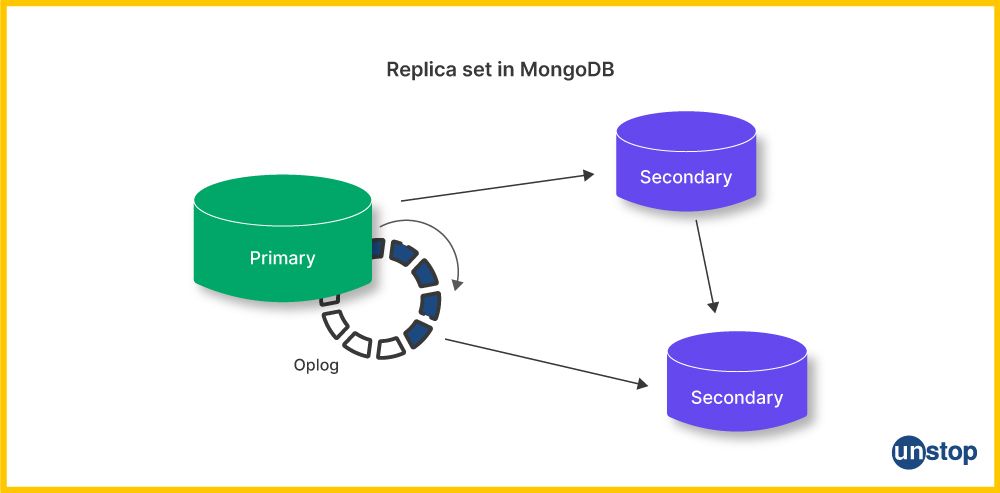
9) Explain about replica set in MongoDB.
A replica set in MongoDB serves as a mechanism to ensure high availability, data redundancy, and failover support. It typically consists of at least three nodes. One primary node is responsible for accepting written operations, and secondary nodes are replicating primary data. At a primary node failure event, one of the secondaries automatically gets promoted to primary.
This design ensures data continuity and reliability, making replica sets fundamental for mission-critical applications like e-commerce, financial systems, and content delivery networks. Replica sets provide data durability and prevent data loss even in the face of hardware or network failures. They are a cornerstone of MongoDB's fault tolerance and data safety mechanisms.
10) Differentiate MongoDB and Cassandra.
Here are some key differences between MongoDB and Cassandra, highlighting their varying data models, query languages, scalability approaches, and consistency models.
|
Feature |
MongoDB |
Cassandra |
|
Data Model |
Document-oriented (BSON) |
Column-family (wide-column) |
|
Query Language |
Rich and expressive |
Limited querying capabilities |
|
Scalability |
Horizontal scaling |
Designed for horizontal scaling |
|
Schema |
Dynamic (No fixed schema) |
Schema-agnostic (flexible) |
|
Consistency |
Eventual consistency |
Tunable consistency levels |
11) Explain about storage encryption.
Storage encryption in MongoDB involves encrypting all data stored within the database, either at the storage or operating system levels. This security measure ensures that only authenticated processes can access and decrypt the protected data, safeguarding sensitive information from unauthorized access.
12) What are primary and secondary replica sets in MongoDB?
In MongoDB, a primary replica set receives all write operations from clients, making it the point of authority for data modifications. Secondary replica sets replicate the data from the primary and can be used to read data. They also serve as backups to ensure data redundancy, high availability, and data durability. If the primary fails, one of the secondaries can be automatically promoted to primary, ensuring uninterrupted service.
13) What is the importance of GridFS and Journaling in MongoDB?
GridFS is a MongoDB feature that stores and retrieves large files like images, videos, and audio files, breaking them into smaller chunks for efficient storage. On the other hand, journaling is a mechanism for secure backups in MongoDB, ensuring data durability by recording write operations in on-disk journal files, even before they are written to the database itself.
14) How to do locking or transactions?
MongoDB employs a different approach to locking and transactions than traditional relational databases. It uses a combination of reader-writer locks to manage concurrency efficiently. MongoDB's concurrency control is designed to be lightweight and high-speed, enhancing performance in multi-server environments.
15) How to do Journaling?
Journaling in MongoDB involves saving write operations in memory while simultaneously writing them to on-disk journal files. These journal files provide a reliable record of write operations and are essential for data recovery and durability. MongoDB creates a journal subdirectory within the database path to store these journal files.
16) How does MongoDB provide concurrency?
MongoDB utilizes reader-writer locks to allow concurrent access to collections or databases. Concurrent readers can access data simultaneously, while writers have exclusive access to perform write operations. This design balances efficiency and data consistency, making it well-suited for scenarios where multiple clients must access the database simultaneously.
17) What is the importance of profiler?
The database profiler in MongoDB is a valuable tool for understanding the performance characteristics of database operations. It allows users to identify slower-than-expected queries and analyze their execution. Profiling data can be used to pinpoint performance bottlenecks, optimize queries, and determine when the creation of specific indexes is necessary for improving query performance.
Intermediate MongoDB Interview Questions
18) Differentiate MongoDB and CouchDB.
|
Aspect |
MongoDB |
CouchDB |
|
Core Features |
MongoDB is known for its speed and performance. |
Places a strong emphasis on data security. |
|
Trigger Support |
MongoDB does not support triggers. |
Supports triggers for enhanced flexibility. |
|
Data Format |
MongoDB serializes data to BSON. |
CouchDB stores data in JSON format. |
19) Explain a capped collection in MongoDB.
A capped collection in MongoDB is a special type of collection with a fixed size. You can create a capped collection with the following syntax:
db.createCollection("<collection_name>", {
capped: true,
size: <max_size_in_bytes>,
max: <max_documents>
})
- collection_name: This is the name of the capped collection.
- capped: Set to `true` to create a capped collection.
- size: Specifies the maximum size in bytes for the collection.
- max: Sets the maximum number of documents the collection can hold.
Example:
db.createCollection("log", {
capped: true,
size: 1048576, // 1 MB
max: 100
})
In this example, a capped collection named "log" is created with a maximum size of 1 MB and a limit of 100 documents. Once the collection reaches its limit, older documents are automatically removed to make room for new ones.
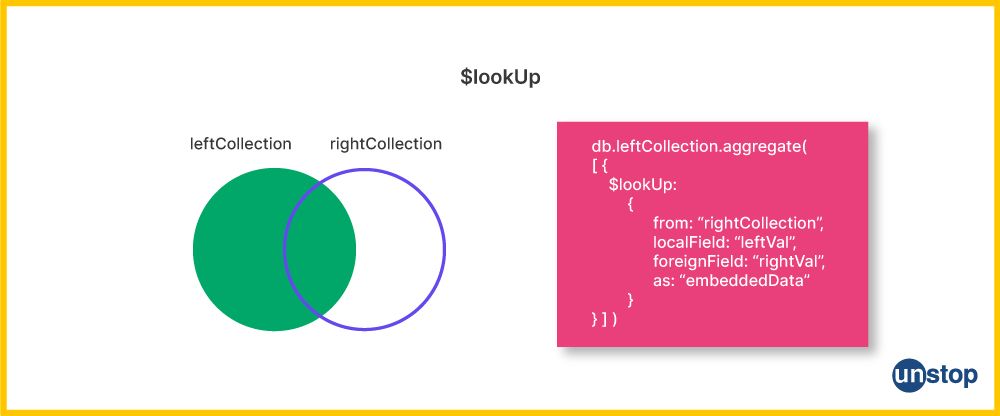
20) How can we perform join operations in MongoDB?
In MongoDB, we can perform join operations using the `$lookup` operator within the built-in aggregation framework. This operator acts similarly to a left outer join in SQL.
Example:
db.orders.aggregate([
{
$lookup:
{
from: "products",
localField: "product_id",
foreignField: "_id",
as: "orderDetails"
}
}
])
In this example, we are joining the "orders" collection with the "products" collection using the `product_id` field in the "orders" collection and the `_id` field in the "products" collection. The result will include the matched documents from both collections.
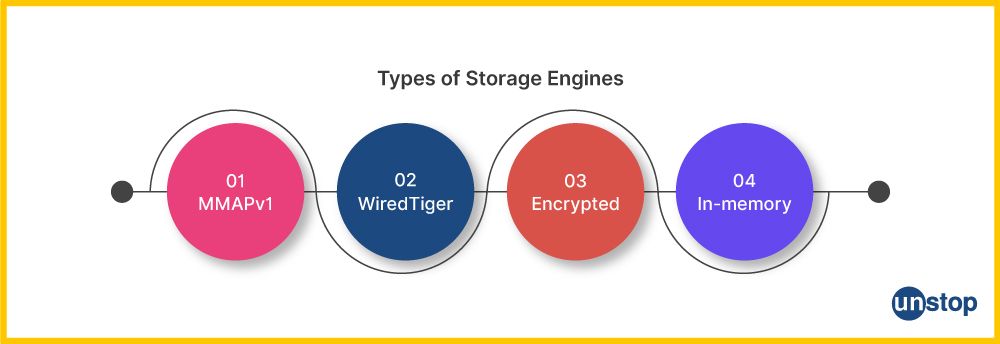
21) What are the storage engines used in MongoDB?
MongoDB primarily uses two storage engines:
- WiredTiger: This is the default storage engine for MongoDB, starting from version 3.2. It offers compression, document-level concurrency support, and efficient data storage.
- MMAPv1: This was the original storage engine used by MongoDB. While it is still available, it is considered less efficient and less feature-rich than WiredTiger.
Apart from these, the following storage engines are available in select versions:
-
Encrypted: Only MongoDB Enterprise has access to it. Master keys and database keys are used in the encryption process. The master key encrypts the database keys, and the database keys encrypt the data. Within the application layer, application-level encryption provides encryption on a per-field or per-document basis.
- In-memory: Starting with version 3.2.6, it's available in the enterprise editions. It manages extremely high throughput while maintaining low latency and great availability. It's predictable and it has low latency with less in-memory infrastructure and supports zonal sharding-based high-level infrastructure.
22) How to configure the cache size in MongoDB?
In MongoDB, we cannot configure the cache size directly. MongoDB relies on the operating system's memory management and memory-mapped files for caching. The OS automatically manages caching, using available memory for database operations.
23) How to control MongoDB Performance?
We can control MongoDB's performance through various means:
- Locking Performance: Monitor and optimize locking to prevent contention.
- Connection Management: Identify and manage the number of connections effectively.
- Database Profiling: Use the database profiler to analyze and optimize query performance.
- Full-time Diagnostic Data Capture: Continuously capture and analyze diagnostic data to identify and address performance issues.
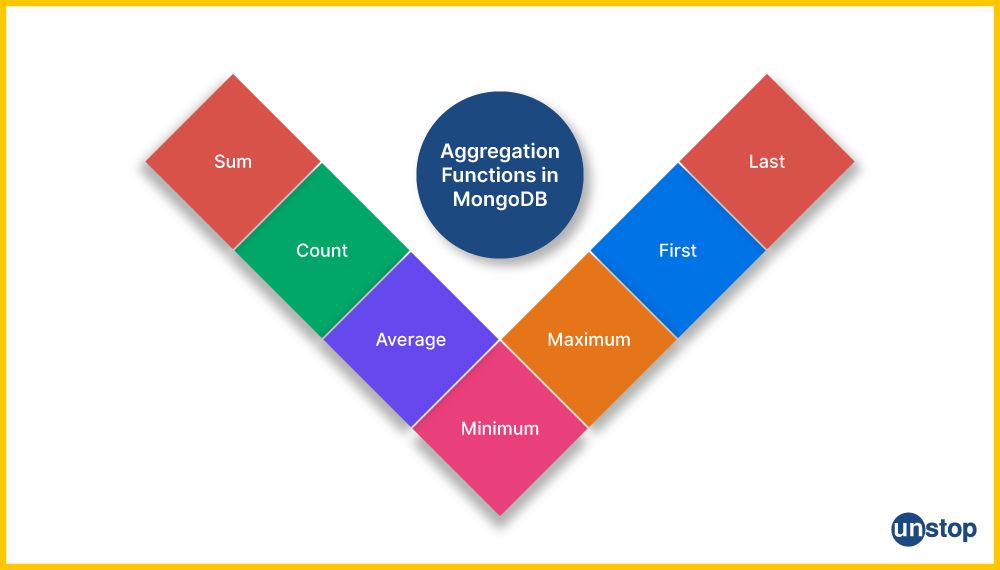
24) What are the aggregate functions of MongoDB?
MongoDB provides several aggregate functions, including:
- $avg: Calculates the average value.
- $sum: Calculates the sum of values.
- $min: Finds the minimum value.
- $max: Finds the maximum value.
- $first: Selects the first document.
- $push: Appends values to an array.
- $addToSet: Adds values to an array without duplicates.
- $last: Select the last document.
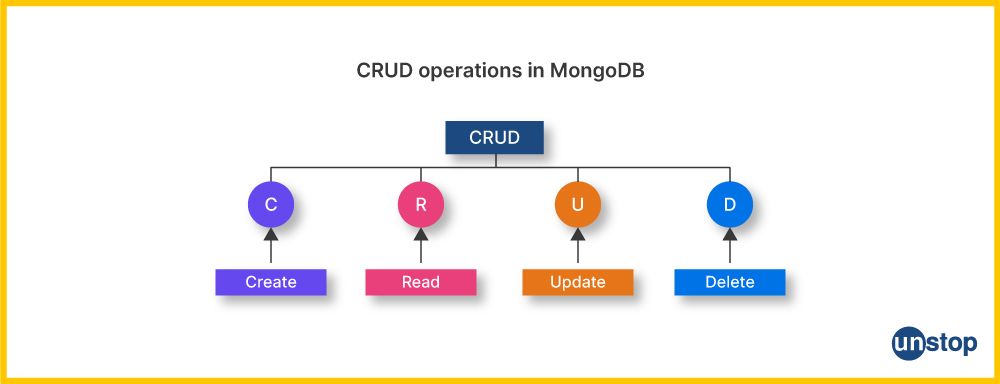
25) What are the fundamental CRUD operations in MongoDB, and give an example of each operation?
CRUD operations in MongoDB are fundamental:
- Create (Insert): `db.collection.insert()`
- Read (Query): `db.collection.find()`
- Update: `db.collection.update()`
- Delete: `db.collection.remove()`
Here is an example of each operation:
- Create:
db.students.insert({ name: "Alice", age: 25 })
- Read:
db.students.find({ name: "Alice" })
- Update:
db.students.update({ name: "Alice" }, { $set: { age: 26 } })
- Delete:
db.students.remove({ name: "Alice" })
26) Is it required to invoke "getLastError" to make a write durable?
No, it is not mandatory to invoke "getLastError." The server ensures that write operations are durable without explicitly invoking "getLastError." "getLastError" provides confirmation that a write operation is committed, but durability and safety are independent of this command.
27) What happens when a shard is slow or down while querying?
When a shard is slow or unresponsive during querying, MongoDB may return an error if the response time exceeds a threshold. MongoDB waits for the shard to respond, and the query will continue once the shard becomes responsive.
28) How do we use a primary key?
In MongoDB, the primary key is reserved for the `_id` field. It is automatically created as a unique identifier for documents in a collection. If you do not explicitly set a value for `_id`, MongoDB will generate a unique ObjectId. However, you can use any unique value as the primary key by setting it as the `_id` field in your documents.
29) How do we see the connections utilized by MongoDB?
To view the connections used by MongoDB, you can execute the `db_adminCommand("connPoolStats")` command. This command provides information about the current connection pool, including the connections' number, status, and other relevant details.
30) When a "moveChunk" fails, is it required to clean up partly moved docs?
No, cleaning up partly moved documents is unnecessary when a "moveChunk" operation fails. Chunk moves in MongoDB are deterministic and consistent. If a move operation fails, MongoDB will retry it, and once it is completed, the data will be entirely on the target shard.
31) How to start the MongoDB instance or server?
To start the MongoDB server, follow these steps:
- Open the command prompt.
- Navigate to the MongoDB installation directory.
- Run the `mongod` executable or use the `mongod.exe` file in the "bin" directory.
- Alternatively, you can start the MongoDB shell by running `mongo`.
32) Differences between MongoDB and RDBMS
A detailed comparison between MongoDB and traditional relational database management systems (RDBMS) includes comparing data modelling, schema flexibility, query language, transactions, scalability, and more. Each has strengths and limitations, making them suitable for different use cases. Here is a more detailed comparison in table form:
|
Aspect |
MongoDB |
RDBMS |
|
Data Modeling |
MongoDB uses a flexible, schema-less data model with JSON-like documents. |
RDBMS relies on a structured, predefined schema with tables, rows, and columns. |
|
Schema Flexibility |
MongoDB allows dynamic schemas, enabling changes to data structure without affecting existing documents. |
RDBMS enforces a fixed schema that requires schema modifications for data changes. |
|
Query Language |
MongoDB uses a rich and expressive query language with JSON-based queries. |
RDBMS typically employs SQL (Structured Query Language) for querying data. |
|
Transactions |
MongoDB supports multi-document transactions for data consistency. |
RDBMS offers full ACID (Atomicity, Consistency, Isolation, Durability) transactions. |
|
Scalability |
MongoDB scales horizontally with ease, making it suitable for distributed, large-scale applications. |
RDBMS scales vertically, which can be costly and have limitations on scalability. |
|
Joins |
MongoDB provides limited support for joins but encourages denormalization for data access. |
RDBMS excels in complex joins and relational queries. |
|
Use Cases |
MongoDB is suitable for agile, unstructured data, real-time analytics, IoT, and big data applications. |
RDBMS is well-suited for structured data, financial systems, and applications requiring data integrity. |
|
ACID Compliance |
MongoDB is designed for high availability and partition tolerance with eventual consistency (BASE). |
RDBMS focuses on strict ACID compliance for data integrity. |
33) How do applications access real-time data modifications in MongoDB?
Applications can access real-time data modifications in MongoDB using Change Streams. Change Streams serve as a data change notification mechanism and allow applications to subscribe to changes in a collection levels. This feature enables applications to react to inserts, updates, deletes, and other real-time data modifications.
For example, in Node.js, you can use the `watch()` method to create a Change Stream and listen for changes:
const changeStream = db.collection('mycollection').watch();
changeStream.on('change', (change) => {
console.log('Change detected:', change);
});
This allows applications to respond to data changes instantly, making MongoDB suitable for real-time applications and event-driven architectures.
34) What are the different kinds of indexes in MongoDB?
MongoDB supports various types of indexes to optimize query performance:
- Default: MongoDB automatically creates an index on the `_id` field.
- Compound: These indexes involve multiple fields and can improve query performance for complex queries significantly.
- Multi-key: Index arrays or embedded documents within a single field.
- Single Field: Indexes a single field for faster retrieval of documents.
- Geospatial: Designed for location-based queries, such as geospatial coordinates.
- Hashed: Creates indexes using a hash function for equality-based queries on the indexed field.
These index types allow you to tailor your database for specific use cases and query requirements.
Advanced MongoDB Interview Questions
35) What are the benefits of using an aggregation pipeline in MongoDB?
We can pass through a complex operation with a big dataset without loading all of it into memory using an aggregation pipeline in MongoDB. It plays an active role in processing large data sets. The aggregation pipelines are considered very flexible with regard to processing the data. They help us filter, group, sort, and accumulate data in many ways.
36) What types of indexes can we create in MongoDB?
There are four main types of indexes that we can create in MongoDB:
- Single-field indexes: They are constructed upon a single field of a document.
- Compound indexes: Several fields of this document are created in these indexes.
- Multikey indexes: They are defined or declared in an array field of a document.
- Geospatial indexes: They create such indexes on geographical fields within a document.
37) When should we use sharding in MongoDB?
Sharding enables us to distribute the data between various MongoDB servers. It works well with big data that does not fit in a single server. Try sharding if the dataset is more than 10 GB or expanding quickly. We may also consider sharding to enhance the readability of the database for read operations.
38) What are the different types of database servers in MongoDB?
There are two main types of database servers in MongoDB:
- Primary servers: The data’s primary copy is stored in these servers.
- Secondary servers: These servers store a backup of the primary server’s data.
Read operations take place on secondary servers.
Whenever a primary server goes down, one of the secondary servers becomes primary.
39) How can we improve the performance of complex aggregations in MongoDB?
There are a few things that can be done to improve the performance of complex aggregations in MongoDB:
- Indexes are used while filtering, grouping, and sorting.
- Do not use the $sort stage in the aggregation pipeline whenever possible.
- Limit the number of documents that the aggregation pipeline should process at the $limit stage.
- Use the $explain() method to evaluate the performance of your aggregation pipeline so that there may be enhancement in weak sections.
40) What are the benefits of using a document database like MongoDB?
Document databases like MongoDB offer several benefits over traditional relational databases, including:
- Flexibility: Documents can be stored in an elastic and unstructured form using document databases. They are perfect for storing intricate data models.
- Scalability: Document databases excel in scalability, making them ideal for managing growing and large datasets. They can quickly adapt to the increasing volume of data without a significant drop in performance.
- Performance: Document databases offer notable advantages in terms of performance speed, especially for specific workloads like read operations and complex aggregations. Their design and query capabilities make them highly efficient for handling these tasks, resulting in faster and more responsive data retrieval and analysis.
41) How can we avoid file system fragmentation when using a document database like MongoDB?
There are a few things that can be done to avoid file system fragmentation when using a document database like MongoDB:
- Use of ext4 or XFS for large file systems.
- Use a file system like ext4 or XFS, which supports preallocation.
- Use MongoDB with mmapv1 storage engine.
- Compact the database regularly.
42) What is the difference between a collection and index scans?
- A collection scan is a query that scans every single document in a collection. An index scan is a query that uses an index to find the documents it needs to return.
- Index scans are generally much faster than collection scans, so we should always try to use indexes in our queries whenever possible.
43) What are some challenges of using MongoDB on 32-bit systems?
The memory limit is the biggest problem with using MongoDB on a 32-bit system. On a 32-bit system, MongoDB has a memory limit of 2GB. However, this may constitute a limitation concerning large datasets.
The other issue with using MongoDB on 32-bit systems is that there is no support for certain functionalities like 64-bit BSON and 64-bit.
44) What is a database shard in MongoDB, and how does it improve performance?
MongoDB implements database shard, i.e. breaking down data into different pieces and then distributing the resulting slices vertically among various servers or shards. Each shard comprises part of the dataset, distributing the workload on both reads and writes. The scalability method is done based on the record of the database, allowing for an increase in distributive storage, which efficiently handles large amounts of data.
45) Explain the concept of master nodes and slave nodes in a MongoDB replica set. How do they work together to ensure high availability and fault tolerance?
Master nodes are responsible for writing on the primary database in a MongoDB replica set while handling write operations. The master node sends data, which is then replicated by slave nodes that act as backup storage devices. They also enhance read operations and offer increased data redundancy. Master and slave nodes constitute a replication architecture, which results in high availability and fault tolerance by default, with the automatic electing of one of the slave nodes as a new master as the current master node fails, thereby preventing data loss.
46) What is the significance of using 64-bit builds in MongoDB over 32-bit builds?
Using 64-bit builds in MongoDB provides the benefit of utilizing modern hardware on its full scale. 64-bit builds provide greater efficiency and flexibility for MongoDB, offering larger memory address space, better performance, advanced record storage capabilities, and large dataset support.
47) What is vertical scaling in MongoDB, and when is it suitable for improving database performance?
MongoDB achieves vertical scaling by adding more capacity in one instance, usually done through an increased amount of CPU, RAM and storage on the server. The method is appropriate when improving hardware resources in the present server and provides an opportunity to eliminate performance bottlenecks of the database. Vertical scaling provides a viable solution for small to medium-scale workloads that do not require complex distributed architectures.
48) How does MongoDB handle aggregation tasks, and what are the advantages of using aggregation in MongoDB?
The Aggregation Framework in MongoDB is used for data transformation and processing as it enables the handling of aggregation tasks. Using aggregation in MongoDB, such as grouping, filtering and computing value on large datasets, is significant because it enables complex data analysis. It is essential as it presents fast, effective ways of performing advanced queries and various reporting duties necessary in data analytics.
49) Differentiate between relational and non-relational databases and explain when we would choose MongoDB as a non-relational database.
Relational databases use structured schemas with tables and SQL. Non-relational databases such as MongoDB adopt flexibility, and non-schema documents are stored.
When it comes to unstructured or semi-structured data, real-time analytics, IoT, big data apps, or horizontally-scaling applications, a non-relational database such as MongoDB would be favoured. MongoDB meets these requirements as it can operate with its own JSON-like object format, perform querying through dot notation, and allow chained replication for such use cases.
50) What is the role of circular queries in MongoDB, and how do they contribute to query optimization?
We can query data in a circular or cyclical order with circular queries in MongoDB. These are suitable for dealing with data structures such as graphs and networks. Circular queries optimize complex queries by involving efficient navigation and data access in a cyclic relationship, making meeting the specific queries and advanced-level query standards simple.
51) Explain the concept of chained replication in MongoDB. How does it work, and what advantages does it offer in a distributed database system?
In chained replication of MongoDB, a secondary database would replicate from another secondary database instead of replicating directly from the primary database. Through the process, it establishes a replication chain. The chained replication provides fault tolerance and high availability due to the fact that the data can move through various nodes, leading to fewer chances of data loss when a node fails. It spreads data across replication geographies, making it a resilient two-venture replication measure; therefore, data will always remain available even in harsh conditions.
Suggested Reads:
Login to continue reading
And access exclusive content, personalized recommendations, and career-boosting opportunities.
Don't have an account? Sign up
Never miss an
Update

Featured Opportunities
Top-Rated Practice by Students





Subscribe
to our newsletter
Blogs you need to hog!

This Is My First Hackathon, How Should I Prepare? (Tips & Hackathon Questions Inside)
D2C Admin

10 Best C++ IDEs That Developers Mention The Most!
D2C Admin

Advantages and Disadvantages of Cloud Computing That You Should Know!
D2C Admin

Is IoT Valuable? Advantages And Disadvantages Of IoT Explained
Shivangi Vatsal
Comments
Add comment