
Asian Paints Alchemy 2026
Table of content:
- What is data mining?
- Data extraction as a process
- Data mining process models
- Steps in the data mining process
- The data mining process in Oracle DBMS
- The data mining process in the data warehouse
- Applications of data extraction
- Data mining challenges
- Techniques in the data mining process
- Challenges of implementation of data mining process
- Data mining process examples
- Tools used in the data mining process
- Advantages of the data mining process
- Disadvantages of the data mining process
- Data mining process applications
- Test Your Skills: Quiz Time
Data Mining Process: Models, Applications, Techniques & More!
Data mining is a fundamental component of the data science workflow. It provides necessary tools and methods to discover insights from large datasets. Data mining can be done with various methods like the clustering technique, associations, sequential form or pattern analysis, and a decision tree model. Data mining process is also known as Knowledge Discovery in Databases (KDD) process. It is the process of locating valuable information from huge volumes of data.
These data are stored in data warehouses and databases, that identify patterns within large data sets, involving techniques at the intersections between machine learning, and artificial intelligence statistics. The data mining process is carried out for making decisions within businesses.
Note: If you want to land a dream job in data science, don't miss out on this crash course.
What is data mining?
Data mining is the process of identifying fascinating patterns and information from huge quantities of data. It includes various data sources, such as data warehouses, databases as well as the internet, other repositories of information, and data streams that are fed into the system continuously.
The data mining process is a part of the Knowledge Discovery process in data mining. The Knowledge Discovery in Databases (KDD) process in data mining involves extracting data from large chunks of information. Hence, KDD consists of multiple steps. On the other hand, the data mining process involves specific algorithms used to certain extract data.
Data extraction as a process
Every business objective will require raw data to create an outline of the data and provide the reports required for the business. The process of building a model based on data sources and formats is iterative because raw data can be found in a myriad of sources and a variety of formats.
Data is growing every day, so whenever a new source of data is discovered, it could alter the results.
Why do businesses need data extraction?
Since the advent of Big Data, data mining has become more popular. Big data are huge collections of data that can be analyzed by computers to uncover patterns, relationships, and trends that are comprehended by human beings. Big data provides a wealth of data on various types of data and diverse information.
With this volume of data, basic stats using manual manipulation won't be effective. It is accomplished through the data mining process. This is a result of the shift from basic statistics for data to more complex algorithms for mining data. Thus, data processing in data mining helps convert raw data into usable data.
The data mining process finds pertinent information from raw data, including photographs, transactions, videos flat files. After this, it automates the process to produce reports that allow businesses to make decisions.
The business requirement of the data mining process is essential for companies to make better decisions through identifying patterns and trends in the data, analyzing the data, and extracting relevant data.
Data mining process models
Numerous industries like manufacturing marketing, chemical, and aerospace are benefiting from data mining. Therefore, the need for reliable and standard processes for mining data has increased dramatically. The most important data mining models are:
1. Cross-industry standard process (CRISP)
CRISP-DM is a reliable and secure data mining model that is comprised of six stages. It is a cyclical procedure that offers a well-organized method for the process of mining data. The six phases are completed in any order however it may require retracing to the earlier steps and repeating the actions.
The six CRISP-DM processes comprise:
- Business understanding: In this step, the objectives of the business are established and the key factors that can help achieve the goals and business intelligence are identified.
- Data understanding: This step will take all data available and then populate it into the tool (if you are using an application). The data is listed along with its source of data, where it came from, how it was obtained, and any issues that were encountered. Data is visually displayed and queried to verify its accuracy.
- Data preparation phase: This step involves selecting the correct data, cleaning and constructing attributes from the data, and integrating data from various databases.
- Modeling: Selection of the method of data mining, like a decision tree, creating test designs to evaluate the chosen model, creating models using the data and evaluating the model kinds of knowledge with experts, and discussing the model's results at this stage.
- Evaluation: This step will assess the extent of the model that has been created is in line with the business needs. Evaluation is done by testing the model using actual applications. The model is inspected to identify any errors or actions which need to be replicated.
- Deployment: In the step of deployment, an implementation plan has developed A strategy to monitor and keep track of the data mining model's results to verify its effectiveness is developed, the final reports are prepared and a review of the entire procedure is carried out to verify any mistakes and to determine the possibility of repeating any step. The deployment phase involves the distribution of the data.
2. SEMMA (Sample, Explore, Modify, Model, Assess)
The acronym SEMMA stands for sample, explore, modify, model, and assess. It is a different method of KDD process in data mining developed by the SAS Institute.
SEMMA allows users to apply visual and exploratory techniques. These are used to select and transform the most important predicted variables, and construct models using these variables. Then, It produces the model and tests its accuracy of the model. SEMMA is additionally driven by a repeated cycle.
Steps in SEMMA
- Example: In this step, an enormous dataset is extracted, and a sample that represents the entire data is extracted. The sampling process will lower the cost of computation and processing time.
- Discover: The data is examined for outliers or anomalies to gain greater knowledge of the information. It is also visually examined to identify patterns and groups.
- Modify: At this stage manipulating data, such as grouping and subgrouping, is accomplished to keep the focus on the model that is to be constructed.
- Model: In the light of research and modification, the models that explain the patterns that appear in data are built.
- Examine: The usefulness and accuracy of the model are evaluated during this stage in the KDD process in data mining. The test of the model against actual data is conducted in this step.
Both SEMMA and CRISP approaches are used to support the Knowledge Discovery Process in data mining. Once models have been built they can be used for research and business purposes.
Steps in the data mining process
The steps in the data mining process have two components. These are data preprocessing and data mining. Data mining is the process of analysis of data, studying data mining patterns, mining algorithms, analysis, and representation of knowledge of data. Data preprocessing entails data cleaning, data integration, data cleaning, data reduction, as well as data transformation.
What is the reason we need to preprocess data?
There are a variety of factors that affect the quality of data, including accuracy, completeness, and timeliness. Data must be reliable to meet the objective. Preprocessing is therefore essential in the process of mining data. The main aspects of data preprocessing are outlined in the following paragraphs.
Step 1: Data cleaning
Data cleaning is the primary step in mining data. In the initial phase, it is important because contaminated data when used directly in mining may create confusion and lead to incorrect results.
The basic idea is the elimination of data that is noisy or insufficient from the data collection. A variety of methods that cleanse data on their own can be found, however, they're not very reliable.
This step is used to complete the regular cleaning tasks by:
(i) Fill in the missing data
Incomplete data in the KDD process in data mining could be filled with methods like:
- Not paying attention to the tuple.
- Manually fill in the missing value.
- Make use of to measure central tendencies either median or central tendency.
- Filling in the most likely value.
(ii) Eliminate the noisy data Random errors are known as noisy data.
Methods for removing noise include:
Binning Methods: Binning is used to sorting values into bins or buckets. Smoothing is done by analyzing neighboring values.
Binning is achieved by smoothing the bin i.e. every bin is replaced by the median of each bin. Smoothing use a medium in which each bin's value is replaced with the median of the bin.
Smoothing through borders of the bin i.e. The values of the minimum and maximum in the bin represent bin boundaries, and each bin value will be replaced with that closest value to the boundary.
- Identifying the Outliers
- Resolving Inconsistencies
Step 2: Data integration
If multiple heterogeneous sources of data like the databases of data cubes, or files are combined to analyze, this process is known as data integration. This improves the efficiency and speed of data mining.
Different databases use different conventions for naming variables, which can cause duplicates in databases. Additional Data Cleaning is a way to eliminate redundancies and inconsistent data integration, but without affecting the validity of the data.
Data integration can be achieved by using Data Migration Tools like Oracle Data Service Integrator and Microsoft SQL etc.
Step 3: Data Reduction
This method is used to collect relevant information for analysis through the collection of data. This representation size can be smaller, while still maintaining integrity. Data reduction is achieved by using techniques like Naive Bayes Decision Trees, Neural networks, etc.
A few strategies for data reduction include:
- Reduced dimension: Reducing the number of attributes contained in the data.
- Numbers reduction Replacing the primary data volume with smaller versions that represent data.
- Data compression: The original information is compressed.
Step 4: Data transformation
The data transforms into a format that is suitable to be used in the data mining process. Data is then consolidated to ensure that the data mining process is more efficient and patterns are simpler to comprehend. Transformation of data is a Data Mapping and Code Generation process.
Strategies to transform data include:
- Smoothing - Eliminating noise in data by methods of clustering, regression, and more.
- Aggregation - The summary operation is applied to the data.
- Normalization - The scaling of the data to be within a narrower area.
- Description - Raw values of numeric data are replaced with intervals. For Example, age.
Step 5: Data mining
Data mining is a method to find interesting patterns and information from large amounts of data. Through these steps, intelligent patterns are used to identify the patterns in data. The data is then represented by patterns, and models are organized by using clustering and classification techniques.
Step 6: Pattern evaluation
This involves identifying interesting patterns that represent the knowledge based on interest measures. The data is summarized and visual techniques can be used to make information understandable to the user.
Step 7: Knowledge representation
Knowledge representation is the process that involves data visualization tools and knowledge representation tools are employed to represent extracted data. Data is presented using tables, reports, etc.
The data mining process in Oracle DBMS
RDBMS is a database that stores data in tables that have columns and rows. The data can be accessed by making queries for databases.
Relational Database management systems like Oracle can support the data mining process with CRISP-DM. The capabilities provided by the Oracle database can be useful for the preparation of data and understanding. Oracle database allows data mining using Java interfaces, PL/SQL interface, automated data mining, SQL interface functions, and GUIs for users.
The data mining process in the data warehouse
Data warehouses are modeled by a multidimensional structure known as a data cube. Each cell of a data cube stores the values of several aggregate measures.
Multidimensional data mining is carried out by OLAP fashion (Online Analytical Processing) which permits the exploration of multiple dimensions at different levels of granularity.
Applications of data extraction
A list of fields where data mining is used extensively includes:
1. Financial Data Analysis: Data mining programs are extensively used in the fields of banking, investment mortgage, credit services, auto loans, as well as insurance and stock investment services. The data gathered from these mining programs are completely reliable and of excellent quality. This makes it easier to conduct a systematic analysis of data as well as data mining.
2. Retail and Telecommunication Industries: The retail Sector collects vast amounts of data about the history of customer purchases as well as consumption, transportation of goods, and even service. Data mining in the retail sector helps determine the buying habits of customers and patterns of shopping and trends. It also helps improve services to customers, improve retention of customers and improve satisfaction.
3. Science and Engineering: Data mining in computer engineering and science could help to track system status to improve system performance, identify software bugs, spot software plagiarism, and spot problems with the system.
4. Intrusion Detection and Prevention: Intrusion is defined as any series of activities that compromise the security, integrity, or accessibility of network resources. Data mining methods can assist in the detection and prevention of intrusions to help systems to increase the efficiency of their performance.
5. Recommender Systems: Recommender systems assist consumers by providing recommendations for products that are relevant to consumers.
Data mining challenges
Below are the different challenges when it comes to data mining:
- Data mining projects need large databases and data collection, which are hard to manage. Project objectives are the initial phase of data mining.
- Data mining needs domain experts, which are difficult to locate.
- Integration of heterogeneous databases is a difficult process.
- The practices at the organizational level need to be changed to make use of the results of data mining. Restructuring the process takes effort and expense.
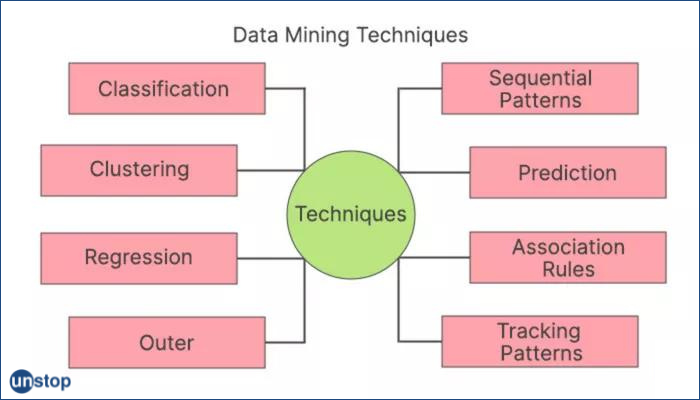
Techniques in the data mining process
Techniques of data mining can be defined by object-oriented and object-relational databases.
1. Classification
This analysis can be used to find important and pertinent data information, as well as metadata. This method of data mining helps to categorize data into various categories.
2. Clustering
The clustering process is a mining technique that helps to find data that are similar to each other. This helps in understanding the similarities and differences between the data.
3. Regression
Regression analysis is a method for mining data that identifies and studies the relationships between variables. It can be used to determine the probabilities of a certain variable in light of the presence of additional variables.
4. Association Rules
This method of data mining assists to discover the relationship between two and more Items. It finds an undiscovered pattern within the set of data.
5. Outer detection
This particular type of data mining method is the observations of data elements in the data that don't match the pattern expected or behavior. This technique is used in a wide range of areas like intrusion detection of fraud, fault detection, and so on. Outer detection can also be referred to as Outlier Analysis and Outlier mining.
6. Sequential patterns
This technique of data mining helps to identify or discover patterns or trends that are similar in transactions for a specific period.
7. Prediction
Mining prediction is a mix with other methods of data mining such as patterns that repeat, trends and clustering, classification, and more. Studies past events or events in a proper sequence to anticipate the outcome of a future event. Hence, it is an important component of the KDD process in data mining.
8. Tracking pattern
The tracking of patterns is an essential method for data mining. It involves identifying and monitoring patterns or trends that are present in the data to draw predictions about business results. When an organization has identified trends for sales statistics, say it's time to consider making a decision to take advantage of that knowledge.
Challenges of implementation of data mining process
- Experts with expertise are needed to develop the queries for data mining.
- Overfitting: Due to the tiny size of training databases the model might not be suitable for future states.
- Data processing in data mining requires huge databases that can be hard to manage.
- It is possible that business practices require modification to make use of the information discovered.
- When a dataset isn't varied, the results of the data mining process could not be correct.
- The integration of information from different database systems and information systems worldwide can be complicated in the KDD process in data mining.
Data mining process examples
Let’s use some examples to discover more about the data mining process:
Example 1:
Think about a marketing director of a provider of telecom services who are looking to boost the revenue for long-distance service. For a high return on marketing and sales activities, the customer profile is crucial. There is a huge collection of data about his customers like gender, age as well as income, credit history, and more. However, it is impossible to identify the characteristics of those who use long-distance calls using the manual method of analysis. Utilizing data mining methods can reveal patterns among high-long distance users and their traits.
For instance, he may find out that his top clients are married women aged between 45 and 54, who earn more than $80,000 a year. Marketing campaigns can be targeted toward this particular group of people.
Example 2:
A bank is looking for ways to generate more revenue from credit card transactions. They would like to determine if the user could double if fees were cut by half.
Bank has several years of data for average price and credit card balances and the number of payments, use of credit limits, as well as other crucial factors. They build a model to evaluate the effect of the new business policy. The results of the data show that reducing fees by half for customers with a targeted base can boost revenue by 10 million dollars.
Tools used in the data mining process
Here are two of the most popular data mining tools used in the KDD process in data mining that is widely used in the industry:
1. R-language
Language R is an open-source tool to uses statistical computing and graphics. R offers a variety of classical tests in statistics, time-series analysis classification, as well as graphical methods. It is a powerful data storage and data handling system.
2. Oracle Data Mining
Oracle Data Mining popularly knowns as ODM is a module within the Oracle Advanced Analytics Database. It is a Data mining tool that lets data analysts produce detailed insights and make mining predictions. Oracle data mining assists in predicting customer behavior and creates profiles for customers. It also identifies cross-selling opportunities.
Advantages of the data mining process
- The data mining process is a technique that helps businesses to gather information based on knowledge. It triggers new business questions to develop more ideal models.
- Data mining assists companies to make profitable changes to production and operation.
- The data mining process is an efficient and cost-effective option when compared with other data mining applications based on statistical data.
- The data mining process can aid in the process of making decisions.
- Learning of automated forecasting of patterns and patterns automates the discovery of patterns hidden from view.
- It can be utilized in brand-new systems, as well as on existing platforms.
- It's a speedy method that allows users to process large amounts of data in a shorter time by using deep learning algorithms and machine learning algorithms.
- Clustering or unsupervised learning techniques are employed to identify natural patterns or patterns in the data, even when the group's membership or category was not known previously.
Disadvantages of the data mining process
- There is a possibility that companies sell the user data of their clients to other companies in exchange for cash. For instance, American Express has sold purchases made by credit cards of their customers to other businesses.
- Many of the data mining analytics programs are difficult to use and require extensive education to operate.
- Different tools for the data mining process function in various ways due to the different algorithms utilized in their creation. So, choosing the appropriate data mining software is an extremely difficult job.
- The techniques used to undertake the data mining process aren't accurate therefore it could be a cause of serious harm in certain circumstances.
Data mining process applications
Data processing in data mining includes lots of applications whose data will be used for analytics.
1. Communications - Data mining techniques are employed in the field of communications to forecast the behavior of consumers to create specific and targeted advertising campaigns.
2. Insurance - Data mining assists insurance companies to price their products competitively and also to advertise new offerings to their perspective as well as existing clients.
3. Education - Data mining can help educators analyze student data, forecast performance levels, and pinpoint the students or even groups of pupils who require more focus. For instance, students who have a weak grasp of maths are likely to be weak.
4. Manufacturing - With the aid of data mining manufacturers can predict the wear and tear of their production equipment. They can predict maintenance, which allows them to reduce their costs to reduce the time to repair.
5. Banking - Data mining process assists the finance industry gain a better understanding of the risks in the market and managing compliance with regulations. It assists banks in identifying likely defaulters and deciding whether or not to issue credit loans, cards, etc.
6. Retail - Data mining methods help retailers stores and malls to find and place the most lucrative items and unknown objects in the most efficient places. They assist store owners in coming up with incentives to encourage customers to spend more.
7. Service Providers - Mobile phone service providers and utilities make use of data mining to predict the reasons why customers leave their businesses. They study billing data and customer service interactions as well as complaints and complaints submitted to the company and give the customer a probability score, and provide incentives.
8. E-Commerce - Websites that sell products online use data mining tasks to offer cross-sells and up-sells on their sites. The most renowned brand is Amazon which uses Data mining techniques to draw more customers to its eCommerce store.
9. Super Markets - Data mining process allows supermarkets develop rules to determine what the customers they serve were most likely to expect. Based on their shopping habits and identifying women shoppers who are likely to be expecting. They could start focusing on products such as baby powder or diapers, baby shops, and more.
10. Crime Investigation - Data mining process helps crime investigation agencies in deploying police forces (where is the crime most likely to occur and at what point? ) and for fraud detection who should be searched at the border crossing, action of frauds, etc.
11. Optimization of operations - Data processing in data mining utilizes mining strategies to lower costs across various functional areas, allowing companies to function more efficiently. This method has helped uncover bottlenecks that cost money and enhance the decision-making process of business leaders.
Test Your Skills: Quiz Time
You might also be interested in reading:
Login to continue reading
And access exclusive content, personalized recommendations, and career-boosting opportunities.
Don't have an account? Sign up
Never miss an
Update

Featured Opportunities
Top-Rated Practice by Students





Subscribe
to our newsletter
Blogs you need to hog!

This Is My First Hackathon, How Should I Prepare? (Tips & Hackathon Questions Inside)
D2C Admin

10 Best C++ IDEs That Developers Mention The Most!
D2C Admin

Advantages and Disadvantages of Cloud Computing That You Should Know!
D2C Admin

Is IoT Valuable? Advantages And Disadvantages Of IoT Explained
Shivangi Vatsal
Comments
Add comment