

Asian Paints Alchemy 2026
Table of content:
- What is regression?
- Regression in Data Mining
- Application of regression
- Difference between regression, classification and clustering in Data Mining
- What is overfitting?
- Evaluating a regression model
- Regression algorithms in Oracle Data Mining
- Summing Up
- Test Your Regression Knowledge With This Quiz!
Regression In Data Mining: Types, Techniques, Application And More

There is a large data set that is used for various applications. The practice of extracting useful information from enormous volumes of data is known as data mining. You may utilize this information to enhance sales, lower expenses, strengthen customer connections, reduce risks, and more using a variety of approaches.
Being a fundamental component of the data science workflow, data mining provides the tools and methods necessary to discover knowledge and insights from large datasets. To detect the relationship and analyze features between the data points, data mining plays a key role. To deal with issues in data mining various techniques are used. Among various techniques, regression plays a vital role in data mining. Let's discuss regression in data mining in detail.
What is regression?
Regression is a statistical technique used in various fields to identify the strength and nature of a connection between one dependent variable (typically indicated by Y) and a set of other variables called independent variables.
Any continuous-valued attribute may be predicted using regression, which is a form of supervised machine learning approach. Any business organization can use regression to examine the correlations between the target variable and the predictor variable. It is a crucial tool for data analysis that may be applied to business valuation and data set forecasting.
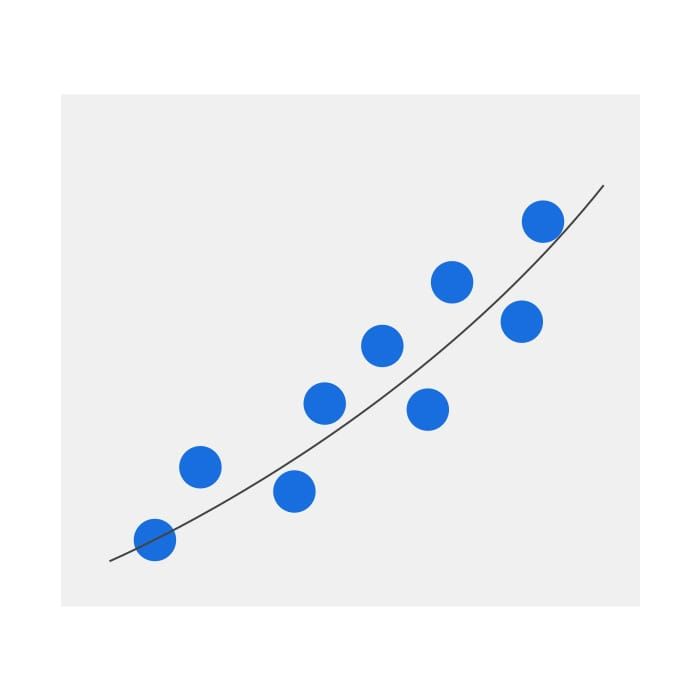
The process of fitting a perfectly straight line or a curve to a set of data points is known as regression. It structures in such a way that the distance between the sample points and the remedy is the shortest.
Linear and logistic regressions are the most common forms and popular types of regression. Aside from that, many other forms of regression can be used, depending on how well they work on a certain data set. In this module, you'll see about different concepts related to regression.
Regression in Data Mining
The term 'regression' refers to a data mining approach for predicting numeric values in data collection. Regression may be used to forecast the cost of a product or service, as well as other variables. It's also utilized for business and marketing behavior, environmental modeling, trend research, and financial forecasting in a variety of sectors. Regression is one of the data mining techniques.
Types of Regression techniques
The basic types of regression can be categorized as follows,
1. Linear Regression
Eg. Quantify the impact of age/ gender on height
2. Polynomial Regression

Eg. COVID-19 and many other infectious illnesses transmission rates to be predicted
3. Logistic Regression
Eg. Poll conducted - whether a politician will lose or win the election
4. Ridge Regression
Eg. Prostate-specific antigen was analyzed, as well as clinical measures, in men who were ready to have their prostates excised.
5. Lasso Regression
Eg. The estimate of robust variance-covariance matrices for asset prices is one active topic of study in finance.
| Regression names | Regression equation | Definition |
| Linear Regression |
Linear equation, Y = a + b*X + e. Where, a - intercept b - a slope of the line e - error X - predictor Y - Target variable |
|
|
Polynomial Regression |
Y = a + b * x2 |
|
| Logistic Regression |
The link function is log(p/1-p). This is based on yes or no |
|
| Ridge Regression | Hridge = X(X′X + λI)−1X
HAT matrix with regularization penalty |
|
| Lasso Regression | Minimization objective = LS Obj + α * (sum of absolute value of coefficients) |
|
Other types of regression are as follows:
- Decision tree / Regression tree - In the shape of a tree structure, a decision tree constructs regression or classification models. It gradually greatly reduces a dataset into increasingly smaller sections while also developing an associated decision tree. A tree containing a set of nodes with leaf nodes is the end result. Eg. Civil planning
- Support vector regression - The supervised learning technique Support Vector Regression model to predict distinct values. SVMs and Support Vector Regression are both based on the same premise. Eg. Identifying gene classifications, people with genetic disorders, and other biological issues.
- Random forest regression - For regression, this is a supervised learning technique that uses the ensemble learning approach. The ensemble learning approach combines predictions from several machine learning techniques to get a more accurate forecast than a single model. Eg. Stock market prediction, Product recommendation
- ElasticNet regression - Elastic net is a sort of regularised linear regression that includes two well-known penalties, the L2 and L1 penalty functions. Elastic Net is a linear regression modification that incorporates regularization penalties into the gradient descent during training. Eg. Analysis of genomic data
In addition, we have various forms of regression which can be further divided into:
- Standard multiple regression - The most popular type of multiple regression analysis is this one. The equation is filled in with all of the independent variables at the same time. The predictive ability for every independent variable is assessed. Eg. Blood pressure may be predicted using independent factors such as height, weight, age, and weekly activity hours.
- Stepwise multiple regression - A stepwise regression technique will examine which predictors are most effective in predicting neighborhood choice — that is, the stepwise model will rank the predictor variables in order of relevance before selecting a meaningful subset. The regression equation is developed in "steps" in this sort of regression issue. All variables may not even exist in the overall regression model in this sort of analysis. Eg. To design an optimized electric machine - multiobjective optimization design.
- Hierarchical regression - After controlling for all other factors, hierarchical regression may be used to see if variables of interest describe a statistically significant variance in your Exogenous Variables (Dependent variable). Instead of a statistical procedure, this is a paradigm for model comparison. Eg. Health service research
- Set-wise regression - It is the iterative creation of a regression model in which the data points to be utilized in the final model are chosen step by step. It entails incrementally adding or eliminating possible explanatory factors, with each iteration requiring statistical significance assessment. Eg. Utilizing Case/Control or Parent Data to Assess the Comparative Impact of Genetic variants within a Gene
Application of regression
- Drug Response modeling
- Planning for business and marketing
- Forecasting or financial predictions
- Observing and analyzing patterns or trends
- Modeling of the environment
- The pharmacological response over time
- Calibration of statistical data
- Physiochemical relationship
- Satellite image analysis
- Crop yield estimation
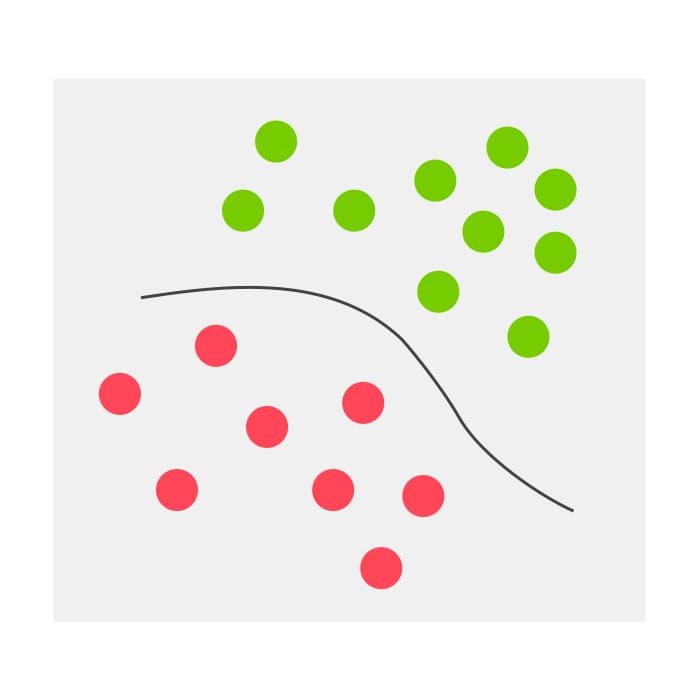
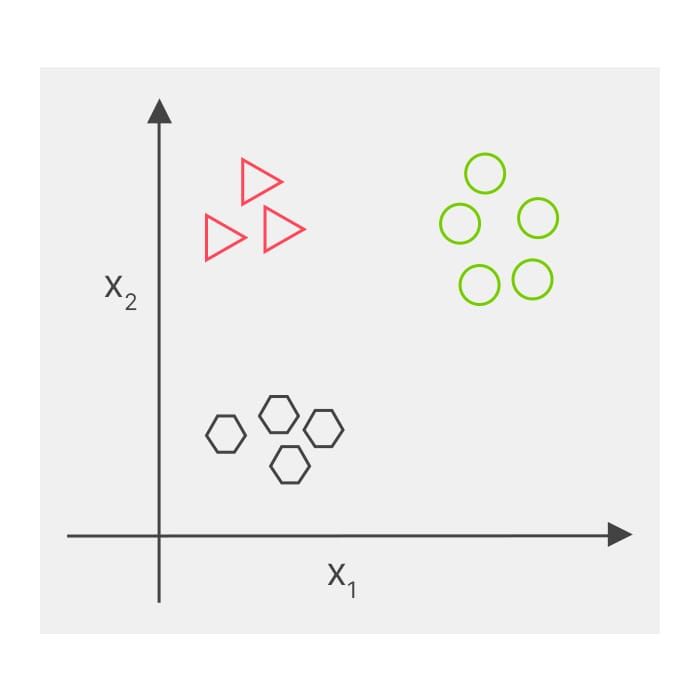
Difference between regression, classification and clustering in Data Mining
The following table shows important points of differences between the three data mining techniques- regression, classification and clustering.
| Regression | Classification | Clustering |
| Supervised learning | Supervised learning | Unsupervised learning |
| Output is a continuous quantity | Output is a categorical quantity | Assigns data points into clusters |
| The main aim is to forecast or predict | The main aim is to compute the category of the data | The main aim is to group similar item clusters |
| Calculations- Root mean square error | By measuring the efficiency calculations are done | The calculations are done based on the distance between cluster points |
| Eg. Predict stock market price | Eg. Classify emails as spam or non-spam | Eg. Find all transactions which are fraudulent in nature |
|
|
|
|
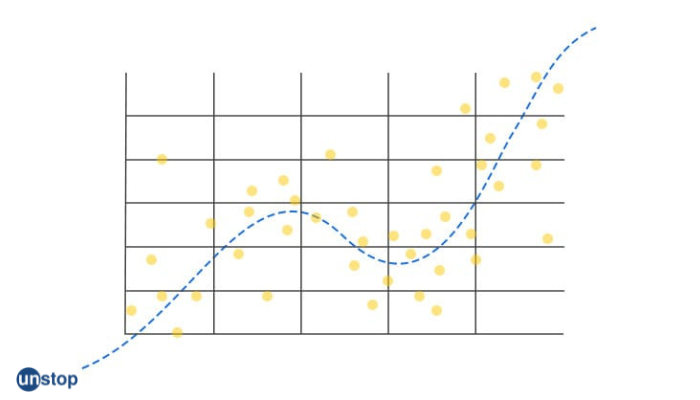
What is overfitting?
When the sample size is too small, the model becomes too sophisticated for the data, resulting in overfitting. Shall obtain a model that seems significant if sufficient predictor variables in the regression model are included. By increasing the sample size, overfitting can be avoided. Overfitting can be detected by,
- Cross-validation - Cross-validation is an effective tool for avoiding overfitting. Create several tiny train-test splits using your initial training data. These divisions can be used to fine-tune your model. We split it up into k subsets, or folds, in typical k-fold cross-validation.
- Data augmentation - Data augmentation, that are less expensive than training with extra data, is an alternative to the former. You can make the given data sets look varied if you are unable to acquire new data on a regular basis. Data augmentation changes the appearance of a sample data set each time it is analyzed by the model. The process made each data set look unique to the algorithm and prevents it from learning the data sets' properties.
- Regularization - Regularization is a strategy for reducing the model's complexity. This is accomplished by penalizing the loss function. This aids in the resolution of the overfitting issues
Evaluating a regression model
There are 3 main performance metrics for evaluating regression model
- R Square or adjusted R square - Adjusted R-squared is just a variant of R-squared that takes into account the degree of predictor variables. When the additional word enhances the equation more than would be anticipated by chance, the adjusted R-squared rises. When a prediction enhances the model than less than predicted, it declines.
- Root Mean Square Error(RMSE) or Mean Square Error (MSE) - The root mean square error is the residuals' standard deviation (prediction errors). Residuals are a measurement of how distant the data points are from the regression line; RMSE is an estimate of how wide out these residuals are. In the other words, it indicates how tightly the data is clustered all-around line of best fit.
- Mean Absolute Error (MAE) - It is a regression model assessment statistic. The mean absolute error of the predictor with regard to a test set is the average of all specific prediction errors on all occurrences in the test set.
Regression algorithms in Oracle Data Mining
Regression is supported by two methods in Oracle Data Mining. Both algorithms excel at mining data sets with a large dimensionality (number of characteristics), such as commercial and unstructured information.
- Generalized Linear Models (GLMs): They are a type of linear model and are widely used as a statistical approach for linear modeling. GLM is used by Oracle Data Mining for regression and binary classification. GLM has a wide range of coefficient and model stats, and also row diagnostics. Confidence bounds are also supported by GLM. Eg. To predict customer affinity, the agriculture weather modeling logistic regression model of GLM is used.
- Support Vector Machines (SVMs): SVM is a strong, cutting-edge linear and nonlinear regression technique. SVM is used by Oracle Data Mining for regression as well as other mining activities. The Gaussian kernel for nonlinear regression and the linear kernel for linear regression are supported by SVM regression. Active learning is also supported by SVM. Eg. Facial recognition, Speech recognition, Text classification
Summing Up
In this article, we understood the fundamental concepts behind regression, its types, applications, and regression algorithms. Regression analysis plays a major role in data mining. Because most economic analysis questions are based on cause-and-effect relationships, regression analysis is an extremely useful technique in business and economic research. If you're not a statistician, regression analysis may be a strong explanatory tool and a convincing means for illustrating correlations between complicated events.
Click here to explore a specialized placement-focused crash course in data science that takes you from a rookie to an evolving expert in 2.5 months.
Test Your Regression Knowledge With This Quiz!
You may also like to read:
- Importance Of Data Transformation In Data Mining
- Difference Between Preemptive And Non-Preemptive Scheduling
- Encryption Vs. Decryption | Know How Your Data Is Protected On Internet
- What Is Beta Testing? Understand Alpha Testing Vs Beta Testing
- What Is Scalability Testing? How Do You Test Application Scalability?
Login to continue reading
And access exclusive content, personalized recommendations, and career-boosting opportunities.
Don't have an account? Sign up
Never miss an
Update

Featured Opportunities
Top-Rated Practice by Students





Subscribe
to our newsletter



Comments
Add comment