
Asian Paints Alchemy 2026
Table of content:
- D.E. Shaw Technical Interview Questions
- D.E. Shaw coding questions
- D.E. Shaw HR Interview Questions
D. E. Shaw Interview Questions For Coding, Technical & HR Round

D. E. Shaw, a pioneer in quantitative investment hires top talent from around the world. The interview process at D. E. Shaw is rigorous and competitive, and it typically involves multiple interview rounds with different members of the team.
The D.E. Shaw recruitment process typically involves the following rounds:
- Round 1: Coding Round
- Round 2: Technical Interview 1
- Round 3: Technical Interview 2
- Round 4: HR/Managerial Interview
To prepare for your dream job at D. E. Shaw, here are some tips and common job interview questions you may encounter during the hiring process :
-
Before the interview, it is important to research the D.E. Shaw interview questions and understand the company's culture, core values, financial products, and investment philosophy. This will help you answer questions more effectively and demonstrate your interest in the company.
-
Brush up on your technical skills as D.E. Shaw is known for its quantitative approach to investing, so it is important to have a strong background in mathematics, statistics, and computer science. Make sure to review key concepts in these areas before the interview.
- D. E. Shaw is interested in candidates who have a track record of success and can demonstrate their ability to work in a fast-paced, collaborative environment. Be prepared to discuss your previous work and highlight specific achievements that demonstrate your skills.
-
D. E. Shaw may ask you to solve case studies or provide solutions to hypothetical investment scenarios. It is important to practice these types of questions and case studies beforehand to develop a structured approach and showcase your problem-solving abilities.
-
At the end of the interview, you will likely have an opportunity to ask questions of your own. Prepare thoughtful questions that demonstrate your interest in the company and show that you have done thorough research.
Note: This article includes D.E. Shaw interview questions for freshers as well as experienced professionals
D.E. Shaw Interview Questions and Answers

D.E. Shaw Technical Interview Questions
Q. What is a MAC address and how many bits does it consists of?
A Media Access Control (MAC) address is a unique identifier assigned to a network interface controller (NIC) for use as a network address in communications within a network segment. It is also sometimes called a hardware address, physical address, or Ethernet address.
A MAC address is a 48-bit address and is typically represented as a series of six pairs of hexadecimal digits, separated by colons or hyphens. The first three pairs of digits identify the manufacturer of the network interface card, while the last three pairs are assigned by the manufacturer and serve as a unique identifier for the device. The 48-bit MAC address provides a theoretical maximum of 2^48, or 281,474,976,710,656, possible unique addresses. However, the actual number of available addresses is much lower due to network addressing schemes and other factors.
Q.What is operator overloading and polymorphism?
Operator overloading and polymorphism are two important concepts in object-oriented programming (OOP). Here's a brief explanation of each:
-
Operator Overloading: Operator overloading is a feature in OOP that allows operators such as +, -, *, /, ==, and != to be overloaded so that they can be used with custom classes and objects. This enables developers to define how operators should behave when used with objects of a particular class. For example, the + operator can be overloaded to concatenate two strings or add two custom objects together.
-
Polymorphism: Polymorphism is the ability of an object to take on many forms. In OOP, polymorphism allows objects of different classes to be treated as if they are objects of the same class, by using a common interface. This can be achieved through method overriding or method overloading. Method overriding occurs when a subclass provides its own implementation of a method that is already defined in the parent class. Method overloading occurs when a class has two or more methods with the same name, but different parameters.
Q. When is a switch considered congested?
A switch is considered congested when the volume of traffic passing through the switch exceeds its capacity to process that traffic. Congestion can cause delays, packet loss, and degraded network performance.
There are several indicators that can suggest a switch is congested:
-
High utilization: If the switch's CPU or memory utilization is consistently high, it may indicate that the switch is struggling to keep up with the traffic passing through it.
-
Packet loss: If packets are being dropped or lost, it may be a sign that the switch is unable to handle the volume of traffic.
-
Latency: If network latency is high, it may be a sign that packets are being delayed due to congestion within the switch.
-
Fluctuating throughput: If the switch's throughput is inconsistent or fluctuating, it may be a sign that the switch is congested.
Q. What do you mean by cycle stealing?
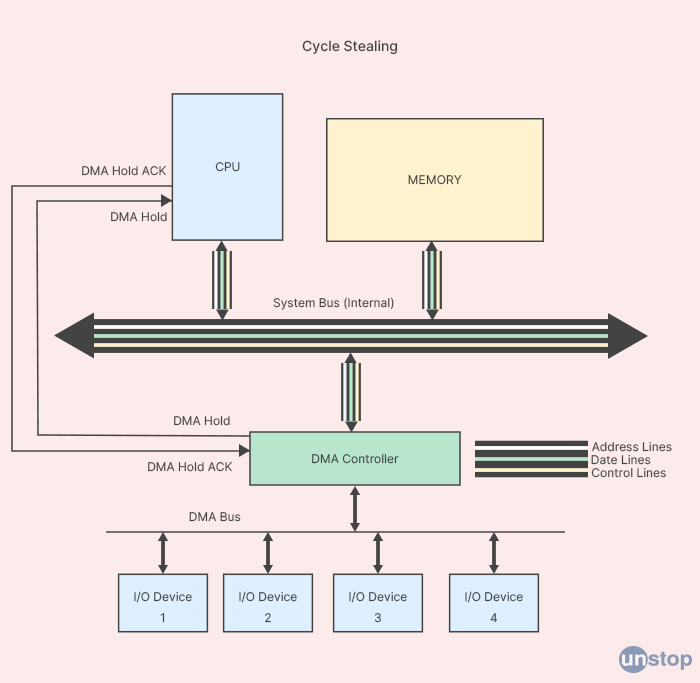
Cycle stealing is a technique used in computer systems to optimize the usage of a CPU (Central Processing Unit) and other system resources, such as memory or I/O (Input/Output) devices. In cycle stealing, a peripheral device or subsystem (such as a disk controller, a DMA controller, or a network interface card) temporarily takes control of the CPU and other resources to perform some operations directly, instead of waiting for the CPU to handle them.
This can improve the overall efficiency and speed of the system, as the peripheral device can perform some tasks faster and more efficiently than the CPU. Cycle stealing can be implemented in hardware or software, depending on the specific system architecture and requirements. It is often used in real-time systems or systems that require high performance, such as gaming consoles, multimedia systems, or scientific computing clusters.
Q. What is a semantic gap?
In computer science and information science, the term "semantic gap" refers to the difference between the representation of information in a computer system and the meaning or understanding of that information by a human user.
More specifically, it describes the mismatch between the low-level, machine-oriented representation of data (e.g., binary code or numerical default values) and the high-level, human-oriented understanding of the meaning and context of that data (e.g., language, concepts, and relationships).
This gap can make it difficult for computers to accurately interpret and understand the information in the same way that humans do, leading to potential errors or misunderstandings. It is a challenge that researchers and developers are constantly trying to bridge by developing more advanced algorithms and technologies.
Q. What do you mean by a binary semaphore?
In computer science and operating system theory, a binary semaphore is a synchronization primitive that is used to control access to a shared resource by multiple processes or threads. A semaphore is a variable that is used to manage concurrent access to shared resources. In a binary semaphore, the value of the semaphore is restricted to two possible states, usually represented as 0 and 1, or "locked" and "unlocked".
When a process or thread wants to access a shared resource, it first tries to acquire the binary semaphore. If the semaphore is currently in the "unlocked" state (i.e., its value is 1), the process or thread can acquire it and proceed to access the shared resource. If the semaphore is currently in the "locked" state (i.e., its value is 0), the process or thread will be blocked until the semaphore becomes available again.
Binary semaphores are commonly used in multi-threaded and multi-process applications to provide synchronization and mutual exclusion. They are a fundamental building block of many concurrent algorithms and data structures.
Q. What is 3-bit parity?
3-bit parity is a method of error detection in digital communication that involves adding an extra bit, known as a parity bit, to a group of 3 bits. The parity bit is set so that the total number of 1s in the group of 4 bits (3 data bits + 1 parity bit) is either even or odd.
For example, if the 3 data bits are 101, the parity bit is set to 0 so that the total number of 1s is even (2). If the 3 data bits are 110, the parity bit is set to 1 so that the total number of 1s is odd (3). When transmitting the 4-bit group, the receiving end can check the parity bit to detect whether any errors occurred during transmission. If the total number of 1s in the group of 4 bits is not even or odd as expected, an error is detected. 3-bit parity is a relatively simple and efficient method of error detection, but it is not as reliable as other error detection methods such as checksums or cyclic redundancy checks (CRCs).
Q. Suggest some test cases for an ATM machine.
Here are some possible test cases for an ATM machine:
- Verify that the ATM machine is properly connected to the network and can access the banking system's APIs.
- Test the encryption and decryption of sensitive data such as PIN numbers and account information to ensure that they are transmitted securely.
- Check if the system is resilient to common attacks such as skimming, card trapping, and shoulder surfing.
- Verify that the ATM machine can handle concurrent transactions without crashing or producing incorrect results.
- Test the timeout settings to ensure that the user session ends after a certain period of inactivity.
- Check the average time of the system to ensure that the transaction processing time is within acceptable limits.
- Verify that the ATM machine is able to detect and reject counterfeit bills.
- Test the system's ability to recover from errors such as paper jams or network failures.
- Check that the ATM machine is able to handle both online and offline transactions.
- Verify that the system is compatible with different types of operating systems and browsers.
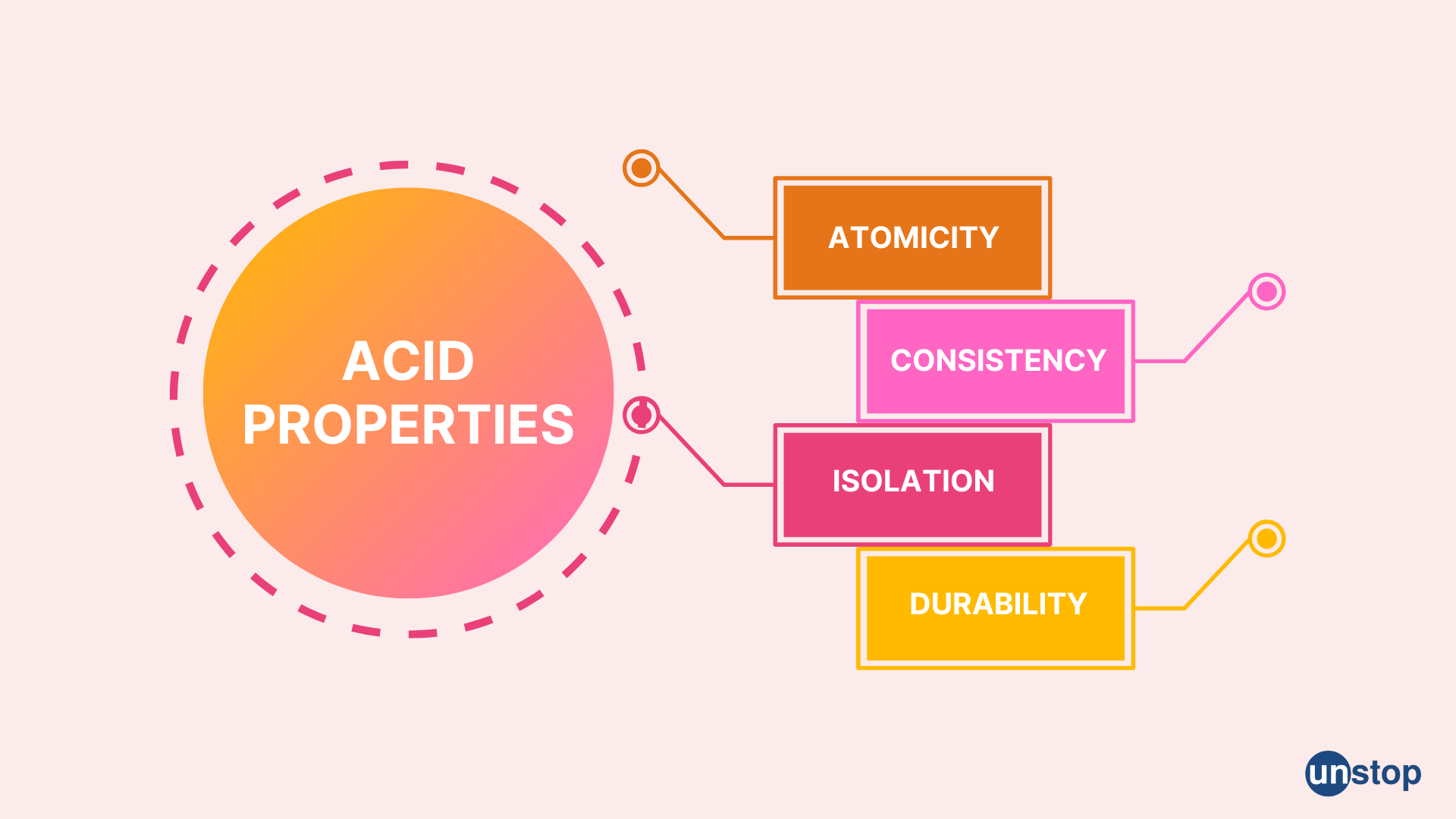
Q. Describe the implementation of acid properties.
ACID is an acronym that stands for Atomicity, Consistency, Isolation, and Durability. These are fundamental properties of database transactions that ensure the reliability, integrity, and consistency of data in a DBMS. Here's a brief explanation of how each of these properties is implemented:
-
Atomicity: Atomicity ensures that a transaction is treated as a single, indivisible unit of work. This means that either all the operations within a transaction are completed successfully or none of them are. To implement atomicity, DBMS uses transaction logs, rollback mechanism, and write-ahead logging. The DBMS writes every transaction to a log file, which can be used to recover the database in case of a failure.
-
Consistency: Consistency ensures that the database remains in a valid state before and after a transaction. It means that any transaction must transform the database from one valid state to another. To ensure consistency, DBMS uses integrity constraints, data validation, and data normalization. The DBMS ensures that data entered in the database adheres to specific rules, and any inconsistency is detected and prevented.
-
Isolation: Isolation ensures that multiple transactions can run concurrently without affecting the integrity of the database. To implement isolation, DBMS uses locking mechanisms, concurrency control, and transaction isolation levels. The DBMS locks the data being modified by a transaction, preventing other transactions from accessing the same data until the first transaction completes.
-
Durability: Durability ensures that once a transaction is committed, it will remain in the database even if a system failure occurs. To implement durability, DBMS uses write-ahead logging and transaction logs. The DBMS writes every transaction to a log file and ensures that the log is written to disk before the transaction is marked as committed.
Q. What is the use of volatile keyword in Java?
In Java, the volatile keyword is used to indicate that a variable's value may be modified by multiple threads, and therefore the value of the variable should not be cached in a thread's local memory. When a variable is declared volatile, the JVM guarantees that all reads and writes to the variable are atomic (i.e., indivisible) and that the value of the variable is always up-to-date and consistent across all threads.
In practical terms, using the volatile keyword ensures that the most recent value of a variable is always visible to all threads and that any updates to the variable made by one thread are immediately visible to all other threads.
Q. What do you understand by graph theory?
Graph theory is a branch of mathematics that deals with the study of graphs, which are mathematical structures that represent a set of objects (or vertices/nodes) and the relationships (or edges/links) between them. In a graph, each node represents an entity (such as a person, a city, a website, or a gene) and each edge represents a relationship or connection between two nodes i.e. child node and the root node.
For example, in a social network, each user would be represented by a node, and each friendship between users would be represented by an edge connecting their respective nodes.
Graph theory provides a framework for analyzing and modeling complex systems and networks across a wide range of fields, including computer science, physics, biology, economics, and social sciences. Some of the key concepts in graph theory include:
-
Graph properties: Graph theory studies the properties of graphs, such as their connectivity, degree distribution, and clustering coefficient, to better understand their structure and behavior.
-
Graph algorithms: Graph theory provides a variety of algorithms for analyzing graphs, such as shortest path algorithms, network flow algorithms, and centrality algorithms.
-
Network models: Graph theory can be used to construct and analyze different models of networks, such as random graphs, scale-free networks, and small-world networks, to better understand their properties and behavior.
-
Applications: Graph theory has a wide range of applications, including social network analysis, recommendation systems, network routing, gene expression analysis, and image segmentation.
Q. Explain the time complexity for searching an element in a hash map.
The time complexity for searching an element in a hashmap is O(1) on average. This means that the duration of time taken to search for an element is constant and does not depend on the size of the hashmap. In a hashmap, each element is stored at a specific index that is determined by a hash function. When searching for an element, the hash function is used to calculate the index where the element is expected to be located. Then, the element at that index is checked to see if it matches the search key.
Since the hash function distributes the current elements uniformly across the array, the number of elements that need to be checked is, on average, proportional to the load factor of the hashmap, which is the ratio of the number of current elements to the size of the array. In a well-designed hashmap, the load factor is typically kept below a certain threshold to ensure that the number of collisions (i.e., elements that hash to the same index) is minimized.
As a result, the usual time complexity for searching a neighbouring element in a hashmap is O(1) on average, which means that the search time is constant and does not depend on the size of the hashmap. However, in the worst-case scenario where there are a lot of collisions, the search time can degrade to O(n), where n is the number of elements in the hashmap.
Q. What is the difference between garbage collection in Java and C++?
The main difference between garbage collection in Java and C++ is that Java has automatic garbage collection, while C++ does not.
In Java, the garbage collector is a background thread that automatically manages the memory used by the program. It periodically scans the heap memory to identify objects that are no longer in use (i.e., they are not reachable from any active references) and frees their memory. This means that Java programmers do not need to manually manage memory allocation and deallocation, which can reduce the likelihood of memory leaks and segmentation faults.
In C++, on the other hand, memory management is done manually using pointers and the new and delete operators. When an object is created, memory is allocated for it using new. When the object is no longer needed, the memory must be manually deallocated using delete. If memory is not deallocated properly, it can result in memory leaks or segmentation faults.
Q. Explain top-n analysis in DBMS.
Top-N analysis is a common technique used in database management systems (DBMS) to retrieve the top N records from a table based on a specified criterion or criteria. It is a type of data analysis that is used to extract the most relevant information from large datasets.
In top-N analysis, the user specifies the number of records (N) that they want to retrieve from the database, and the DBMS retrieves the N records that meet a specific criterion or criteria. For example, a user may want to retrieve the top 10 highest-selling products, the top 5 employees with the highest sales figures, or the top 20 most visited web pages.
Top-N analysis is typically performed using SQL queries, which can use various aggregation functions (such as COUNT, SUM, and AVG) and sorting methods (such as ORDER BY) to identify and retrieve the desired records. Depending on the complexity of the query and the size of the database, top-N analysis can be performed in real-time or may require more advanced optimization techniques.
Q. State some design issues of a computer network.
Here are some design issues that should be considered when designing a computer network:
-
Scalability: The network should be able to handle growth in terms of the number of users, devices, and data traffic.
-
Reliability: The network should be designed to ensure that data is delivered reliably, with a limited time frame or disruption.
-
Security: The network should be designed to prevent unauthorized access, data breaches, and other security threats.
-
Performance: The network should be designed to provide optimal performance, with minimal latency, packet loss, and congestion.
-
Manageability: The network should be designed to be easily managed, with tools and systems in place to monitor, troubleshoot, and optimize the network.
-
Compatibility: The network should be designed to be compatible with existing systems and technologies.
-
Cost: The network should be designed to be cost-effective, with a balance between performance, reliability, and scalability.
Q. What do you understand by demand-paging and pre-paging?
Demand paging and pre-paging are memory management techniques used by operating systems to efficiently manage memory usage in computer systems.
Demand paging is a memory management scheme in which pages of data are loaded into memory only when they are needed. In other words, pages are not loaded into memory until they are requested by a process that needs them. This helps to conserve memory resources since not all pages need to be loaded into memory at once.
Pre-paging, on the other hand, is a technique used to proactively load pages into memory before they are requested by a process. In pre-paging, the operating system predicts which pages are likely to be needed by a process in the near future, and loads them into memory in advance. This can help to reduce the amount of time that a process has to wait for pages to be loaded into memory since they are already available.
D.E. Shaw Coding Questions
Q.You are given a BST, find the elements in the tree under a given range.
To find the elements in a binary search tree (BST) under a given range, we can use the following algorithm:
class Node:
def __init__(self, val):
self.val = val
self.left = None
self.right = None
def range_in_bst(root, lower, upper):
result = []
if root is None:
return result
if lower <= root.val <= upper:
result.append(root.val)
if root.val > lower:
result += range_in_bst(root.left, lower, upper)
if root.val < upper:
result += range_in_bst(root.right, lower, upper)
return result
Y2xhc3MgTm9kZToKZGVmIF9faW5pdF9fKHNlbGYsIHZhbCk6CnNlbGYudmFsID0gdmFsCnNlbGYubGVmdCA9IE5vbmUKc2VsZi5yaWdodCA9IE5vbmUKCmRlZiByYW5nZV9pbl9ic3Qocm9vdCwgbG93ZXIsIHVwcGVyKToKcmVzdWx0ID0gW10KaWYgcm9vdCBpcyBOb25lOgpyZXR1cm4gcmVzdWx0CgppZiBsb3dlciA8PSByb290LnZhbCA8PSB1cHBlcjoKcmVzdWx0LmFwcGVuZChyb290LnZhbCkKCmlmIHJvb3QudmFsID4gbG93ZXI6CnJlc3VsdCArPSByYW5nZV9pbl9ic3Qocm9vdC5sZWZ0LCBsb3dlciwgdXBwZXIpCgppZiByb290LnZhbCA8IHVwcGVyOgpyZXN1bHQgKz0gcmFuZ2VfaW5fYnN0KHJvb3QucmlnaHQsIGxvd2VyLCB1cHBlcikKCnJldHVybiByZXN1bHQ=
This function takes in the root node of the BST, as well as the lower and upper bounds of the range. It returns a list of all the values in the BST that are within the given range. The function works by recursively traversing the tree and checking each node to see if its value is within the range. If it is, then the value is added to the list of elements within the range. The function also checks the left and right subtrees of each node, if necessary, to see if there are additional elements within the range.
Q. Given an array arr, find the peak element in arr.
A peak element in an array is an element that is greater than its neighbor unsorted array. In other words, for an element arr[i], it is a peak element if and only if arr[i] > arr[i-1] and arr[i] > arr[i+1].
One simple approach to find the peak element in an array is to iterate through the array in input and check each element to see if it is greater than its neighbors. Here's an implementation of this approach in Python:
def find_peak(arr):
start = 0
end = len(arr) - 1
while start <= end:
mid = (start + end) // 2
if (mid == 0 or arr[mid-1] <= arr[mid]) and (mid == len(arr)-1 or arr[mid+1] <= arr[mid]):
return arr[mid]
elif mid > 0 and arr[mid-1] > arr[mid]:
end = mid - 1
else:
start = mid + 1
return -1
ZGVmIGZpbmRfcGVhayhhcnIpOgpzdGFydCA9IDAKZW5kID0gbGVuKGFycikgLSAxCgp3aGlsZSBzdGFydCA8PSBlbmQ6Cm1pZCA9IChzdGFydCArIGVuZCkgLy8gMgppZiAobWlkID09IDAgb3IgYXJyW21pZC0xXSA8PSBhcnJbbWlkXSkgYW5kIChtaWQgPT0gbGVuKGFyciktMSBvciBhcnJbbWlkKzFdIDw9IGFyclttaWRdKToKcmV0dXJuIGFyclttaWRdCmVsaWYgbWlkID4gMCBhbmQgYXJyW21pZC0xXSA+IGFyclttaWRdOgplbmQgPSBtaWQgLSAxCmVsc2U6CnN0YXJ0ID0gbWlkICsgMQoKcmV0dXJuIC0x
The first few lines handle some special cases: if the array has only one element or the first or last element is a peak element. Then, we iterate through the remaining elements and check if each element is a peak element. If we find one, we return it. Here's an example usage of the function:
arr = [1, 3, 5, 7, 6, 4, 2]
peak = find_peak(arr)
print("The peak element in arr is:", peak)
This algorithm has a time complexity of O(n), where n is the length of the array. There are more efficient algorithms that can solve this problem in O(log n) time, but they require more complex implementations, such as binary search.
Q. How will you search for an element in a rotated array?
To search for an element in a rotated array, we can use a modified binary search algorithm that takes into account the rotation of the array. Here's how it works:
def find_peak(arr):
start = 0
end = len(arr) - 1
while start <= end:
mid = (start + end) // 2
if (mid == 0 or arr[mid-1] <= arr[mid]) and (mid == len(arr)-1 or arr[mid+1] <= arr[mid]):
return arr[mid]
elif mid > 0 and arr[mid-1] > arr[mid]:
end = mid - 1
else:
start = mid + 1
return -1
ZGVmIGZpbmRfcGVhayhhcnIpOgpzdGFydCA9IDAKZW5kID0gbGVuKGFycikgLSAxCgp3aGlsZSBzdGFydCA8PSBlbmQ6Cm1pZCA9IChzdGFydCArIGVuZCkgLy8gMgppZiAobWlkID09IDAgb3IgYXJyW21pZC0xXSA8PSBhcnJbbWlkXSkgYW5kIChtaWQgPT0gbGVuKGFyciktMSBvciBhcnJbbWlkKzFdIDw9IGFyclttaWRdKToKcmV0dXJuIGFyclttaWRdCmVsaWYgbWlkID4gMCBhbmQgYXJyW21pZC0xXSA+IGFyclttaWRdOgplbmQgPSBtaWQgLSAxCmVsc2U6CnN0YXJ0ID0gbWlkICsgMQoKcmV0dXJuIC0x
This function takes in the rotated array nums and the target element target. It returns the index of the target element in the array nums, or -1 if the target element is not found. The function works by using a modified binary search algorithm to search for the target element. The algorithm takes into account the rotation of the array by checking which half of the array binary is sorted in ascending order, and then comparing the target element to the elements in that half of the array to determine which half to search next.
Q. Given an array of positive integers, each of which represents the number of liters of water in that particular bucket, we have to make the litres of water in every bucket equal. We are allowed to do two types of operations any number of times:
-
We can altogether remove a bucket from the sequence
-
We can remove some water from a bucket
We have to tell the minimum number of liters removed to make all buckets have the same amount of water.
To make all buckets have the same amount of water, we need to find the most common amount of water present in the buckets, let's call it a target. Then, we need to calculate the total amount of water that needs to be removed in order to make each bucket contain target liters of water.
The total amount of water that needs to be removed is the sum of the excess water in all buckets.
Here's the code in Python:
from collections import Counter
def min_water_removed(buckets):
counts = Counter(buckets)
target = counts.most_common(1)[0][0]
excess_water = sum(bucket - target for bucket in buckets if bucket > target)
return excess_water
buckets = [1, 2, 3]
print(min_water_removed(buckets))
ZnJvbSBjb2xsZWN0aW9ucyBpbXBvcnQgQ291bnRlcgoKZGVmIG1pbl93YXRlcl9yZW1vdmVkKGJ1Y2tldHMpOgpjb3VudHMgPSBDb3VudGVyKGJ1Y2tldHMpCnRhcmdldCA9IGNvdW50cy5tb3N0X2NvbW1vbigxKVswXVswXQpleGNlc3Nfd2F0ZXIgPSBzdW0oYnVja2V0IC0gdGFyZ2V0IGZvciBidWNrZXQgaW4gYnVja2V0cyBpZiBidWNrZXQgPiB0YXJnZXQpCnJldHVybiBleGNlc3Nfd2F0ZXIKCmJ1Y2tldHMgPSBbMSwgMiwgM10KcHJpbnQobWluX3dhdGVyX3JlbW92ZWQoYnVja2V0cykpwqA=
Q. Calculate the number of trailing 0’s in 100!
To calculate the number of trailing zeros in the factorial of a number, we need to count the number of factors of 5 in the product. This is because each pair of 2 and 5 contributes one factor of 10, which produces a trailing zero.
In the factorial of a number, there are always more factors of 2 than factors of 5, so we only need to count the number of factors of 5.
For example, in 10! = 10 x 9 x 8 x 7 x 6 x 5 x 4 x 3 x 2 x 1, there are two factors of 5 (from 5 and 10), so the number of trailing zeros is 2.
To calculate the number of factors of 5 in 100!, we can use the following formula: number_of_factors_of_5 = 100 // 5 + 100 // 25 + 100 // 125 + ...
This formula counts the number of factors of 5, 25, 125, etc., by dividing the number by the powers of 5.
Using this formula, we get:
number_of_factors_of_5 = 100 // 5 + 100 // 25 = 20 + 4 = 24
Therefore, there are 24 trailing zeros in 100!
Q. Show the implementation of the queue using stack.
We can implement a queue using two stacks. The first stack, let's call it s1, will be used for enqueuing elements, and the second stack, let's call it s2, will be used for dequeuing elements. When we want to enqueue an element, we simply push it onto s1. When we want to dequeue an element, we first check if s2 is empty. If it is empty, we pop all the elements from s1 and push them onto s2, so that the first element pushed onto s1 is now at the top of s2. We can then pop the top element from s2 and return it as the dequeued element.
Here's the internal implementation of the queue using two stacks in Python:
class Queue:
def __init__(self):
self.s1 = []
self.s2 = []
def enqueue(self, x):
self.s1.append(x)
def dequeue(self):
if not self.s2:
while self.s1:
self.s2.append(self.s1.pop())
if not self.s2:
raise IndexError("Queue is empty")
return self.s2.pop()
Y2xhc3MgUXVldWU6CmRlZiBfX2luaXRfXyhzZWxmKToKc2VsZi5zMSA9IFtdCnNlbGYuczIgPSBbXQoKZGVmIGVucXVldWUoc2VsZiwgeCk6CnNlbGYuczEuYXBwZW5kKHgpCgpkZWYgZGVxdWV1ZShzZWxmKToKaWYgbm90IHNlbGYuczI6CndoaWxlIHNlbGYuczE6CnNlbGYuczIuYXBwZW5kKHNlbGYuczEucG9wKCkpCmlmIG5vdCBzZWxmLnMyOgpyYWlzZSBJbmRleEVycm9yKCJRdWV1ZSBpcyBlbXB0eSIpCnJldHVybiBzZWxmLnMyLnBvcCgp
In this implementation, enqueue() appends the element to s1, and dequeue() checks if s2 is empty. If it is, it pops all the elements from s1 and pushes them onto s2. Then, it pops the top element from s2 and returns it. If both stacks are empty, it raises an IndexError to indicate that the queue is empty.
Q. Create a global variable to store largest sum subtree.
To create a global variable to store the largest sum subtree, you can use the global keyword in Python to declare a global variable inside a function. Here's an example:
# Define a global variable to store largest sum subtree
global_max_sum = float('-inf')
# Definition of a binary tree node
class TreeNode:
def __init__(self, val=0, left=None, right=None):
self.val = val
self.left = left
self.right = right
# Function to calculate the sum of a subtree
def subtree_sum(root):
if not root:
return 0
left_sum = subtree_sum(root.left)
right_sum = subtree_sum(root.right)
subtree_total = root.val + left_sum + right_sum
# Update global variable if subtree_total is greater than current max sum
global global_max_sum
global_max_sum = max(global_max_sum, subtree_total)
return subtree_total
IyBEZWZpbmUgYSBnbG9iYWwgdmFyaWFibGUgdG8gc3RvcmUgbGFyZ2VzdCBzdW0gc3VidHJlZQpnbG9iYWxfbWF4X3N1bSA9IGZsb2F0KCctaW5mJykKCiMgRGVmaW5pdGlvbiBvZiBhIGJpbmFyeSB0cmVlIG5vZGUKY2xhc3MgVHJlZU5vZGU6CmRlZiBfX2luaXRfXyhzZWxmLCB2YWw9MCwgbGVmdD1Ob25lLCByaWdodD1Ob25lKToKc2VsZi52YWwgPSB2YWwKc2VsZi5sZWZ0ID0gbGVmdApzZWxmLnJpZ2h0ID0gcmlnaHQKCiMgRnVuY3Rpb24gdG8gY2FsY3VsYXRlIHRoZSBzdW0gb2YgYSBzdWJ0cmVlCmRlZiBzdWJ0cmVlX3N1bShyb290KToKaWYgbm90IHJvb3Q6CnJldHVybiAwCmxlZnRfc3VtID0gc3VidHJlZV9zdW0ocm9vdC5sZWZ0KQpyaWdodF9zdW0gPSBzdWJ0cmVlX3N1bShyb290LnJpZ2h0KQpzdWJ0cmVlX3RvdGFsID0gcm9vdC52YWwgKyBsZWZ0X3N1bSArIHJpZ2h0X3N1bQojIFVwZGF0ZSBnbG9iYWwgdmFyaWFibGUgaWYgc3VidHJlZV90b3RhbCBpcyBncmVhdGVyIHRoYW4gY3VycmVudCBtYXggc3VtCmdsb2JhbCBnbG9iYWxfbWF4X3N1bQpnbG9iYWxfbWF4X3N1bSA9IG1heChnbG9iYWxfbWF4X3N1bSwgc3VidHJlZV90b3RhbCkKcmV0dXJuIHN1YnRyZWVfdG90YWw=
In this example, we define a global variable global_max_sum to store the largest sum subtree. We also define a binary tree node class TreeNode and a function subtree_sum to calculate the sum of a subtree recursively. Inside the subtree_sum function, we update the value of global_max_sum if the total sum of the current subtree is greater than the current maximum subtree. The global keyword is used to indicate that we are modifying the global variable global_max_sum instead of creating a new local variable with the same name as of maximum sum subtree.
Most Important D.E. Shaw HR Interview Questions
Q. Why do you want to work at D. E. Shaw?
D. E. Shaw is a reputable quantitative investment firm known for its innovation and excellence in the industry. The company has a history of attracting top talent from various fields offering a challenging and intellectually stimulating work environment for employees. This is what drives me to work at D. E. Shaw - its intellectually challenging work environment and innovative culture.
Q. How do you stay up to date on industry trends and developments?
I stay up to date on industry trends and developments through continuous training, programming, and access to a vast amount of data and information from a variety of sources, including online news articles, research papers, academic journals, social media, online coding, and other relevant resources. Keeping up with industry publications and news sources provide me with valuable insights into current and emerging trends, as well as developments in the field, and hence brush up on my basic concepts.
Q. What are your long-term career goals?
I’d love to become an expert in one specific field of programming in the long term, but I know the first step is to build a solid foundation and learn the basics in an entry-level role. This job offers exposure to a variety of areas and the company is known for its innovative culture - which is something I like.
Also read: The Aptest Reply To "Where Do You See Yourself In 5 Years?
Q. How do you approach problem-solving?
I approach problem-solving through a series of algorithms and processes such as :
-
Define the problem: The first step in problem-solving is to clearly define the problem and identify the specific issue that needs to be addressed.
-
Gather information: Once the problem is defined, it's important to gather as much information as possible about the issue.
-
Generate potential solutions: Based on the available information, it's important to generate potential solutions to the problem.
-
Evaluate solutions: After potential solutions are identified, it's important to evaluate each option to determine its feasibility, potential outcomes, and impact on stakeholders.
-
Implement the solution: Once a solution is selected, it's important to develop an action plan and implement the solution.
-
Evaluate the outcome: Finally, it's important to evaluate the outcome of the solution and determine whether it achieved the desired results.
Q. Can you explain a complex technical concept to someone without a technical background?
Explaining complex technical concepts to someone without a technical background can be challenging, but there are several strategies that can help make the concept more accessible and understandable. Here are some tips:
-
Start with the basics: When explaining a complex technical concept, start with the basics and build up from there. This helps to establish a foundation of understanding before introducing more complex ideas.
-
Focus on the benefits: Explain the benefits of the concept and how it can be useful in a real-world context. This helps to make the concept more tangible and relevant to the listener.
-
Visual aids: Visual aids such as diagrams, charts, or graphs can help simplify complex technical concepts by presenting the information in a more visual and accessible way.
-
Ask questions: Ask questions to gauge the listener's understanding and address any confusion or misconceptions. This helps to ensure that the concept is effectively communicated and understood.
Q. What is the difference between smart work and hard work?
The difference between smart work and hard work is as follows:
-
Smart work is about working efficiently, while hard work is about working tirelessly.
-
Smart work involves using your intelligence and skills to achieve the desired outcome, while hard work requires putting in a lot of physical and mental effort.
-
Smart work involves finding the most effective and efficient way to get things done, while hard work involves putting in long hours and persevering through difficult tasks.
-
Smart work often involves prioritizing tasks and delegating responsibilities, while hard work is about putting your head down and working through difficult tasks.
The following additional HR interview questions can help you nail the job:
- 64 Toughest Interview Questions For Job (With 17+ Prep Resources)
- Answering 'How Do You Prioritize Your Work?' During Job Interview
- Guide To Answer- "What Is Your Greatest Strength?" (Samples Inside)
- Top 35 Interview Questions For Freshers With Answers
- Know How You Can Negotiate Your Salary Well (With CTC Explained In Simple Terms)
Login to continue reading
And access exclusive content, personalized recommendations, and career-boosting opportunities.
Don't have an account? Sign up
Never miss an
Update

Featured Opportunities
Top-Rated Practice by Students





Subscribe
to our newsletter




Comments
Add comment