
Asian Paints Alchemy 2026
Table of content:
- Basic DBMS interview questions
- Intermediate-Level DBMS Interview Questions
- Advanced DBMS Interview Questions
- About DBMS
45+ Frequently Asked DBMS Interview Questions With Answers
Brush up your DBMS knowledge with these frequently asked interview questions with answers and step up your preparation.

A database management system, often known as a DBMS, is a piece of software installed on a computer to manage, store, retrieve, and update data. It handles the data, the database engine, as well as the conceptual database schema to make the organizing and manipulation of data easier. It thus acts as an interface between the customer and the database and helps to alter the data format, column names, document structure, as well as file structure itself.
Basic DBMS interview questions
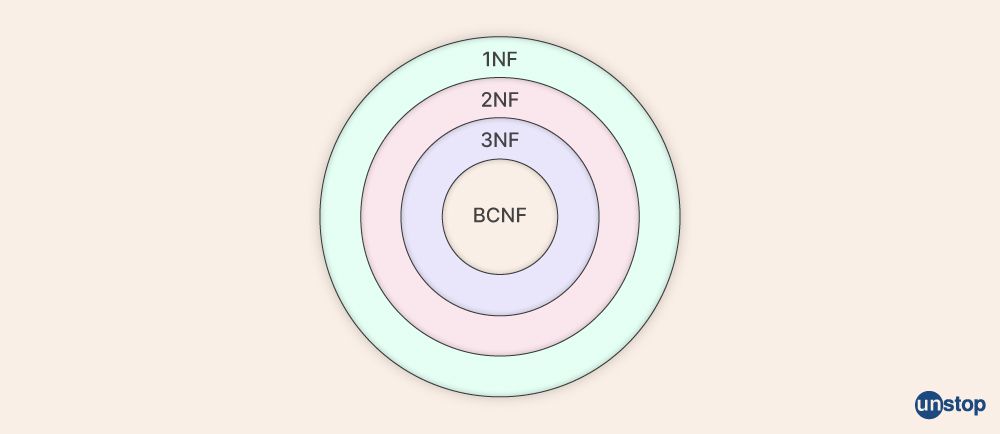
Q1. What are the different types of normalization in DBMS, and explain them?
There are four types of normalization in DBMS, namely, 1NF, 2NF, 3NF, and BCNF (Boyce-Codd Normal Form).
- 1NF: A given relation is in First Normal From (1NF) if each cell of the table contains only atomic values, i.e., attributes of each tuple should have a single value or NULL values. the objective is to remove the duplicate columns from tables.
- 2NF:- A given relation is in the second normal form (2NF) if it is in the first normal form and no partial dependency exists between relationships.
- 3NF:- A given relation is called in Third Normal Form (3NF) if and only if: 1. Relation already exists in 2NF. 2. No transitive dependency exists for non-prime attributes. A → B is called a transitive dependency if and only if- A is not a super key and B is a non-prime attribute.
- BCNF(Boyce-Codd Normal Form): This relationship is called in BCNF only when the following conditions meet: 1. The relationship already exists in 3NF. 2. For all non-trivial functional dependencies “A → B”, A is the super key of the relation.
Q2. What is RDBMS? Differentiate between RDBMS and DBMS.
Its stands for Relational Database Management System (RDMS). It is a database system that accesses the database on the basis of standard fields between tables. The primary difference between RDBMS and DBMS is that DBMS mainly stores data in the form of files, while RDBMS stores data in the form of tables.
Q3. What is the difference between the DROP command, TRUNCATE command, and DELETE command?
TRUNCATE and DROP commands are both DDL commands that are used to delete the database tables, and once the tables are deleted from the database, they cannot be rolled back, so you have to use them at the end only. Indexes related to the table also get deleted when DROP or TRUNCATE is used. DELETE is a DML command which is used to delete rows or columns from the table, and they can be rolled back.
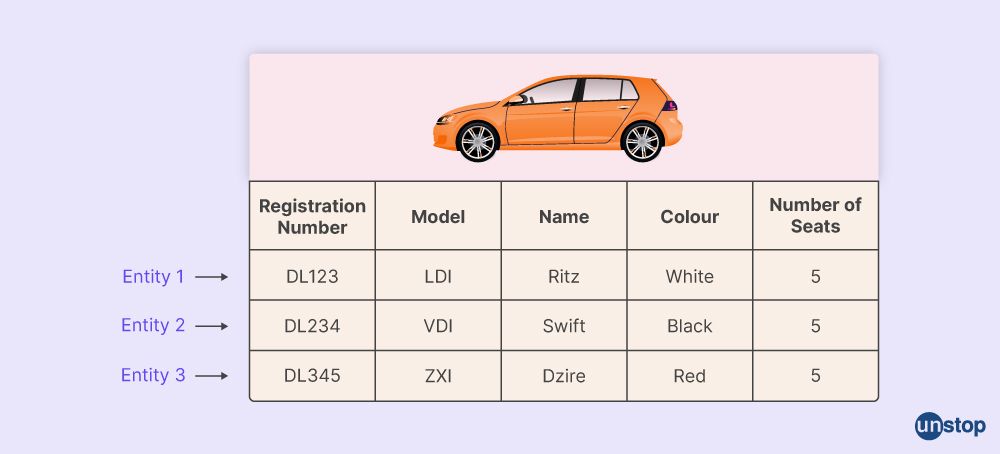
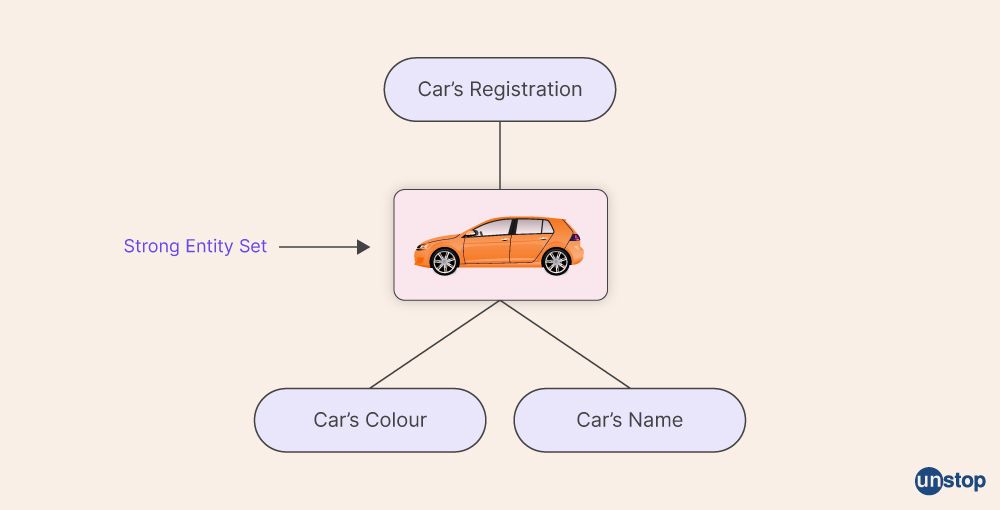
Q4. What is an Entity, Entity Type, and Entity Set in DBMS?
1. Entity is a thing that can exist independently and is distinguishable from other objects.
2. Entity Type refers to the category to which an Entity belongs.

3. Entity Set is a collection or set of all entities of a particular entity type at any point in time.
Q5. What are the advantages of DBMS over traditional File-based Systems?
- No unauthorized access to data
- Easy retrieval
- Atomicity of the data (Multiple operations can be grouped into a single logical entity)
- Easy accessibility and processing of data
- Redundancy control
- Integrity check
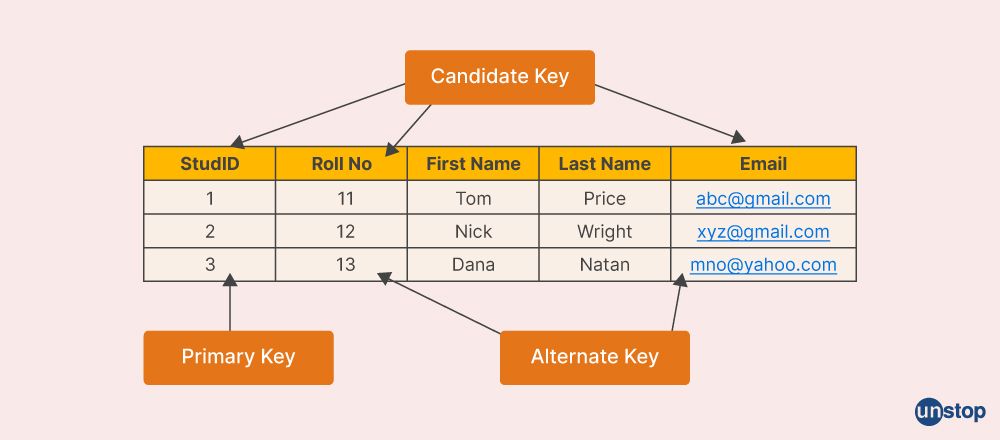
Q6. Explain the term key and its different types in DBMS.
A key is a set of attributes that can identify each tuple uniquely in the given database. We have different types of keys, such as:
- Super key is a set of attributes that can identify each tuple uniquely. It can have any number of attributes.
- Candidate key is a set of minimal attributes that can define a tuple uniquely in a given relationship.
- Primary key is a candidate key that a database designer selects while designing the database. It should be unique and can have a NULL value.
- Alternate key are the keys that are left unused or unimplemented while selecting the primary key known as an alternate key.
- Foreign key: An attribute ‘X’ is called a foreign key to some other attribute ‘Y’ when its values are dependent on the values of attribute ‘Y’. The relation in which attribute ‘Y’ is present is called the referenced relation. The relation in which attribute ‘X’ is present is called the referencing relation.
- Composite key: When the primary key consists of more than one attribute, it is known as a composite key.
Q7. What do you mean by the term 'Join'?
Join is a SQL clause that is used to combine rows from two or more tables having some standard fields between them.
Q8. What do you mean by a correlated subquery in DBMS?
A subquery is also called a nested query, i.e., a query written in a query. When a subquery is executed for each row of the outer query, it is called a correlated subquery.
Example: This is an example of a correlated query that contains an outer query as well as an inner query.
What is a one-to-one relationship? A single table having drawn relationship with another table having similar kinds of columns.
Q9. What are integrity rules in DBMS?
There are two major integrity rules in DBMS:
- Entity Integrity: It states that the primary key should not have NULL values.
- Referential Integrity: This rules states that Foreign should either have a NULL value or should be the primary key of any other relation.
Q10. What is 'normalization', and why is it applied to data in the first place?
The term data redundancy refers to the practice of repeating the same data in several different places over and over again. As a consequence of this, deleting, inserting, and updating the data becomes an uphill task, and in addition to this, a significant amount of storage space is also squandered. The elimination of redundant data is one of the significant advantages of database normalization, which enables the solution to be applied.
Q11. What do you mean by a deadlock in Database Management System?
A situation is said to be in a deadlock state whenever one task waits for another job to release a resource that the first task is currently holding.
Q12. What is denormalization?
Denormalization is a database optimization technique where redundant data is intentionally introduced into a database. This redundancy helps improve performance by reducing the need for complex join operations when querying the data. By eliminating joins, denormalization can enhance functionality and speed up the retrieval of data from the database.

Q13. What are the checkpoints for DBMS?
The checkpoint method is a process that clears the system of all previous logs and saves them in a format that cannot be altered on the storage device.
After every checkpoint, the previous logs are deleted from the system and placed on the storage drive instead. This approach can speed up the recovery process because only the logs since the last checkpoint need to be applied during recovery rather than processing the entire log history. Storing the logs on a separate storage drive can also help improve performance by reducing the overhead on the main database system.
Q14. What is meant by the phrase 'data independence'?
The term data independence refers to a situation where the application is independent of the storage structure. In other words, the capability to modify the schema definition at one level should not influence the schema definition at the next higher level.
Q15. What is an object-oriented model?
The object-oriented model is a programming paradigm and a software design approach that organizes data and behavior into objects. In this model, objects are instances of classes, which serve as blueprints or templates defining the properties and methods that the objects possess.
It promotes modular and reusable code, as well as concepts such as data abstraction, modularity, and separation of concerns. It is widely used in various programming languages such as Java, C++, Python, and many others, providing a powerful and flexible way to structure and organize complex software systems.
Q16. In DBMS, what is meant by the term 'query decomposition'?
The initial step in processing complex queries is called query decomposition. A query based on distributed calculus is converted into an algebraic query based on global relations using query decomposition.
The primary goal of the query in terms of decomposition is to convert a high-level query into a relational algebra query and verify that the question is correct on both the syntactical and semantic levels. Analysis, normalization, semantic analysis, simplification, and outer query rearrangement are the typical stages involved in query decomposition.
Q17. What is a functional dependency?
A functional dependency is a set of conditions that must be met by two qualities for the relationship to be valid. It states that if two tuples have the same values for the characteristics A1, A2,..., and An, then all those two tuples must be identical in their values for the non-key attributes B1, B2,..., and Bn.
It is denoted by symbol (), which reads as "XY," indicating that "X" is the operational factor that determines "Y." The values of the key attributes on the right-hand side are established according to the values of the characteristics on the left-hand side.
Q18. What is meant by the term 'Serializability' when referring to DBMS?
Within a transaction, the concept of serializability is what assists in determining which of the possible non-serial schedules is appropriate and will successfully keep the entire database consistent. It has to do with the isolation attribute of transactions in the database. It is the concurrency scheme wherein concurrent transactions' execution equals serial transactions' execution.
Q17. Can you define DML?
Users can gain access to and make changes to the data stored in the database using a DML or non-procedural query language. The process of data manipulation includes obtaining information from the database, adding new data to the database, removing information from the database, and modifying previously stored information or adding new information.

Intermediate-Level DBMS Interview Questions
Q18. What are entity integrity constraints?
Entity integrity constraints stipulate that the value of the main key cannot be null in any circumstance. This is because the primary key is employed to identify each tuple contained within the relation schema. Therefore, we are unlikely to be able to identify the records containing null values for the main key properties in a way that is both unique and distinguishable. This key constraint is only applicable to one specific relation at a time.
Q19. What is the meaning of the term transaction?
A transaction is a logical program execution unit that accesses and perhaps modifies various data items. Transactions can occur at any point throughout the execution of a program.
For every transaction, four vital properties should be successful. These are called ACID properties, which stand for Atomicity, Consistency, Isolation, and Durability.
It started with a user program developed in a high-level data-manipulation language or computer program (for example, SQL, COBOL, C, C++, or Java). It is bounded by statements (or user-defined functions) in the form of beginning and end transactions.
Q20. What do you know about atomicity and aggregate levels?
Atomicity requires that either every action be carried out or none of them. Users shouldn't be concerned about the repercussions of transactions that are only partially completed. This is ensured by the DBMS, which rolls back the results of any transactions that were left unfinished.
Aggregation is a notion that is utilized in the modeling of a relationship that exists between a group of items and the types of relationships between them. It is utilized in situations where it is necessary to convey a relationship between partnerships.
Q21. What do you mean when you talk about a correlated subquery?
Nested queries, also known as subqueries, are used to retrieve a collection of rows that may be utilized by the query being run on the parent table. Depending on how the subquery is constructed, it may only be executed one time for the parent query, or it may be executed once for each row that is returned by the parent query. One uses the term correlated subquery to refer to a situation in which the child query is carried out for each row of the parent query.
If the WHERE clause of the subquery in question references the columns of the parent subquery, then the subquery in question is correlated. It is impossible to make any references to the columns from the subquery anywhere else in the parent query optimization.
Q22. What is meant by the term 'RDBMS Kernel'?
The kernel, which comprises the database software, and the data dictionary, which also comprises system-level physical storage structures utilized by the kernel for database management, are two essential components of RDBMS architecture. The kernel is responsible for managing the database, as well as the data dictionary is used to store and retrieve information about the database.
You could take a Database Management System (RDBMS) as an operating system (or group of major subsystems) developed primarily for controlling data user access. Its essential duties are storing data, reading the data, as well as safeguarding data.
An RDBMS has its list of authorized users and the rights that are associated with them; it manages memory caches & paging; it regulates locking for simultaneous resource consumption via database lock; it dispatches as well as schedules user requests, and it manages space usage inside its table-space structures.
Q23. What is the meaning of 'Database Trigger'?
A database trigger is a "PL/SQL" block that can be specified to automatically execute for insert, update, and delete command statements made against a separate table. The trigger's execution can be set to occur only once for the entire statement. A database trigger can interact with database procedures that have also been written in PL/SQL and can call those procedures.
Q24. What do you know about 'Stand-Alone Procedures'?
Procedures that aren't part of a package are referred to as stand-alone processes since they are separately specified.
A procedure that is written in an application that uses SQL*Forms is an excellent illustration of a stand-alone procedure. These specific kinds of processes cannot be accessed for reference using any of the Oracle tools.
Stand-alone procedures have several drawbacks, one of which is that their execution can be slowed down since they must be compiled while the program is still running.
Q25. What is SQL, and why is it considered to be so crucial today?
The term SQL refers to the Structured Query Language, widely recognized as the essential language for data processing. It is not a complete programming language such as Java or C#; instead, it is a data sublanguage used to generate and interpret database data and metadata. Today, SQL is used by every single database management system software.
Q26. Why are 'Functional Dependencies' not defined as equations?
Equations are used to represent various types of relationships between numerical values. So, the concept of functional database dependency examines the existence of a determining link between qualities, regardless of whether or not those traits share a numerical relationship.
Q27. What is meant by the phrase 'cascading update'?
To maintain referential integrity, it is necessary to ensure that the values of foreign keys in one entire table correlate to the values of primary keys in another table. If the value of the primary key is modified, also known as updated, the value of such foreign key should be modified immediately to correspond with the primary key's modification.
Cascading updates will cause this change to be implemented seamlessly by the DBMS anytime it is required.
Q28. What are the reasons behind the need for a new database design?
A redesigned database is essential for a couple of reasons. To begin, a redesign is required to correct errors made during the initial database design and improve the database's overall structure. The second issue is that the database will need to be redesigned to accommodate the shifting requirements of the system.
These kinds of shifts are prevalent because information systems, as well as organizations, do not just impact but also co-construct one another. As a result, changes in system needs are brought about by introducing new information systems.
Q29. What do you know about OLAP?
A reporting solution for Business Intelligence (BI), On-line Analytical Processing (OLAP) is a highly advanced tool. OLAP allows users to do basic arithmetic credit operations, such as summing, counting, and averaging, as well as other operations on groupings of data.
A report generated by an OLAP system will have both measurements and dimensions. The values of the data that will be displayed are called measures. The features that make up the measures are known as their dimensions. OLAP reports are sometimes referred to as OLAP cubes, even though these reports do not need to be restricted to just three dimensions.
Advanced DBMS Interview Questions
Q30. Explain E-R Diagram.
It stands for the Entity-Relationship model, which is a comprehensive and precise logical depiction of the information for an organization. The collection of entities, non-prime attributes, relationship matrices, and cardinalities are all components of the E-R Diagram. A system for displaying an entity-relationship network model or conceptual data model is referred to as an entity relationship diagram, or E-R Diagram for short.
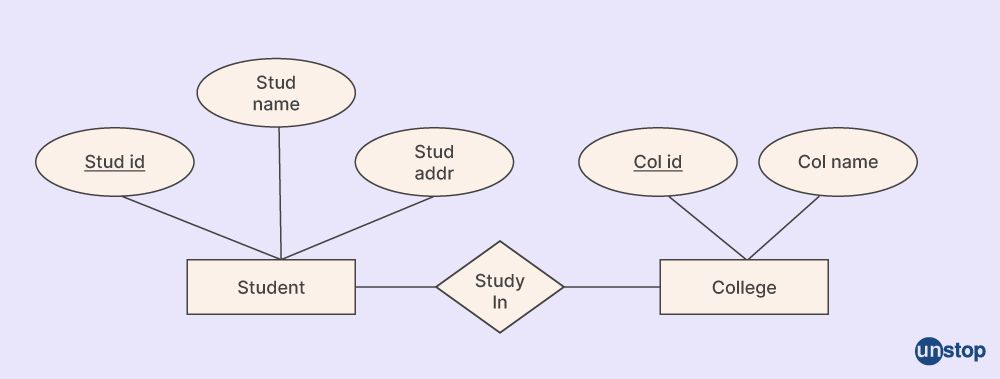
Q31. Please describe the domain constraints.
Entity integrity, as well as referential integrity, are both included in the list of domain constraints. The domain is composed of all of the possible values that might be associated with common attributes.
According to the entity type database integrity rule, there can be no null values in any of the components that make up a primary key. According to the principle of referential integrity, every value for a foreign key must either correspond to a value for a primary key or be null.
Q32. What is data warehousing?
Data warehousing refers to storing data in central area and providing users with concurrent access to that data from inside that location to facilitate making strategic decisions. Data warehousing is a framework that is managed through the use of enterprise management, which is utilized to handle the information.
Q33. What is 'System R'?
System R is a database management system that offers high data independence and a physical database level of abstraction from the end users. IBM developed System R, which includes a clause for data consistency and data management features such as triggered transactions, authentication, integrity assertions, and more.
Q34. Can you describe the major differences between extension & intention?
The intention is a fixed value specified during the database design process, also known as the table schema, and it is not anticipated to undergo significant or frequent shifts in value. On the other hand, the actual data that exists at a particular time is referred to as a database snapshot, which is also denoted by the term extension.
Q35. Can you describe 2-Tier architecture?
In database management systems (DBMS), a 2-Tier architecture can be taken as the sort of logical database architecture in which the User Interface (UI) or view layer (also called the presentation) operates on a client computer (such as a desktop, laptop, tablet, or phone). As a result of this architecture, the client does not have direct access to the database, which increases the database's level of protection against unauthorized use.
Q36. What are the key differences between 2-tier architectures and 3- tiers architecture?
A two-tier architecture conceals the application logic in one of three locations: the server database, the client (inside the user interface), or both of these locations. In 3-tier database architecture, the logic for the process or application is buried in the intermediate layer. As a result, it functions as an independent entity in comparison to the Client/User Interface in addition to the data Interface.
Q37. What is 'MongoDB'?
'MongoDB' is a non-relational, open-source database that lacks a hierarchical organizational hierarchy. Your information is organized into collections, each represented by a single document within our document-oriented database.
A document in MongoDB is nothing more than a large "JSON" object and does not adhere to any particular structure or relational schemas. Documents stored in MongoDB are represented using a binary-encoded format called "BSON."
Also Read: MongoDB Interview Questions That Can Up Your Game
Q38. What is a catalog?
A catalog is a table containing information such as the structure of each database file, the simplest type of each data item, and the storage format of such a data item, in addition to numerous constraints just on data. Metadata is the name given to the information kept in the catalog.
Q39. What are Indexes?
Database indexes are complex data structures employed to increase the speed at which data retrieval database activities are performed on a database table. This speed increase comes at the expense of an increase in the number of writes performed and the amount of storage space required to keep an additional copy of the data. Data may only be stored on a disc in a single order at any time. It is desirable to have a speedier search, such as an iterative method for different values, to enable faster access based on the varied numeric values. Tables typically have a collection of indexes built into them specifically for this reason. This collection of non-clustered indexes consumes extra space on the disc, but they make it possible to do searches that are more quickly tailored to several factors that are regularly searched.
Q41. Can you explain QBE?
Query-by-example is indeed a visual/graphical method for extracting information from a database. This is done so that the query template may be generated. The QBE database engine is used by a wide variety of consistent database systems for personal computers. QBE is a very powerful tool that does not require the user to have any prior knowledge of programming languages to gain access to the information they are looking for. In QBE, the expression of queries is done with the help of skeleton tables. Two features set QBE apart from other companies:
The queries in QBE are written using two-dimensional grammar, which gives them the appearance of being tables.
Q42. What are temporary tables?
Tables that are only utilized for a single session and whose data is still only kept for the duration of such database transactions are referred to as temporary tables. Temporary tables can also be used interchangeably with session tables. Temporary tables are most frequently employed to provide support for one-of-a-kind rollups or particular application processing requirements.
In contrast to a permanent table, a temporary table doesn't start with any allocated space when it is first created. The table's available space will be dynamically distributed under the number of rows that have been added. Oracle's CREATE “GLOBAL TEMPORARY TABLE” or SQL command is what you'll need to execute to create a temporary table.
Q43. What do you mean by the durability in DBMS?
Once the DBMS notifies the user that a transaction has been completed successfully, the effect of the transaction should continue even if the file processing system crashes before all the changes are reflected on the disc. This is because a transaction is considered to have been completed successfully once the DBMS notifies the user. Its other name, durability, more commonly refers to this characteristic.
Once a transaction has been committed to the database users, durability ensures that the data associated with that transaction will be saved in non-volatile memory, which will be protected if the system experiences an unexpected failure.
Q44. Can you explain the 'Stored Procedure'?
The term "stored procedure" refers to a collection of SQL statements that are formatted into the form of a function. These SQL statements are given a specific name and saved in relational database management systems (RDBMS), which can be retrieved at any time.
Q45. What exactly do you mean when you talk about the 'E-R Model'?
The acronym "E-R model" refers to a structure known as the Entity Relational Model. To build a database for every single database user, you can use the "E-R model, "which is a technique for symbolizing the logical connections between the collection of entities or real-world objects. "Peter Pin-Shan Chen" was the one who came up with the idea for the entity-relationship mode back in the 1970s.
Q46. Can you describe ODBC?
Application programs can access and process SQL databases using the standardized interface provided by the "Open Database Connectivity "(ODBC) standard. This interface offers a common programming language for application programmers. To utilize ODBC, you will need a driver, the name of the server, the name of the actual database, a user id, and a password. The "Open Database Connectivity" (ODBC) standard is becoming increasingly popular and is essential for Internet applications
About DBMS
The acronym DBMS stands for "Database Management System." It is a software package that facilitates communication with a database by facilitating tasks such as creating, upgrading, eliminating, fetching, viewing, attempting to manipulate, and administering the Database system as its contents. This software package typically comes with predefined tools, functions, and functional operations capable of defining the data, fetching the data, managing the access permissions again for the database, manipulating the data and the form of tables, and so on.
A good understanding of this topic is essential to face all the DBMS interview questions confidently. We hope the above list of DBMS interview questions will prove to be helpful for you in this regard. Keep learning!
You may also be interested to read:
Login to continue reading
And access exclusive content, personalized recommendations, and career-boosting opportunities.
Don't have an account? Sign up
Never miss an
Update

Featured Opportunities
Top-Rated Practice by Students





Subscribe
to our newsletter



Comments
Add comment