
Asian Paints Alchemy 2026
Table of content:
- PL SQL Interview Questions: Basics
- PL SQL Interview Questions: Intermediate
- PL SQL Interview Questions: Advanced
- Conclusion
70+ PL/SQL Interview Questions With Answers (2026) For All Levels
Procedural Language/Structured Query Language (PL/SQL) is a programming language used to create, manage and manipulate Oracle database objects. Here are some top interview questions that will help you quickly brush up on your PL/SQL knowledge.

PL/SQL (Procedural Language/Structured Query Language) is Oracle Corporation's procedural extension for SQL and the Oracle relational database. It is a powerful language that combines the data manipulation capabilities of SQL with procedural programming constructs, enabling developers to create sophisticated database applications. As a core technology for database programming, PL/SQL is essential for anyone pursuing a career in database administration, development, or data analysis within an Oracle environment.
This article provides a comprehensive list of commonly asked Oracle PL/SQL interview questions designed to help candidates prepare for technical interviews. By reviewing these questions, you'll gain insights into the key concepts and skills that employers look for when hiring PL/SQL professionals.
PL SQL Interview Questions: Basics
1. What is PL/SQL?
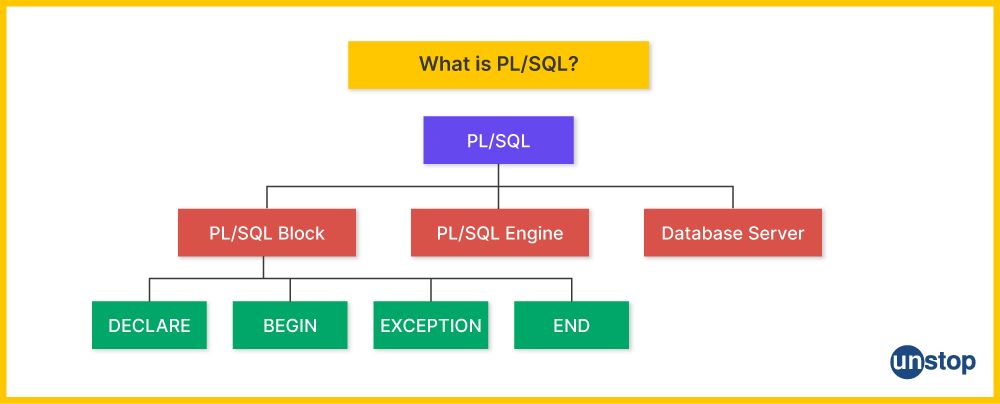
PL/SQL (Procedural Language/SQL) is an extension of SQL specifically designed for use within Oracle databases. It combines the data manipulation power of SQL with the procedural capabilities of a programming language, allowing for the creation of more complex and powerful database applications.
2. Compare SQL and PL/SQL.
Here's a table highlighting the key differences between SQL and PL/SQL:
| Feature | SQL (Structured Query Language) | PL/SQL (Procedural Language/SQL) |
|---|---|---|
| Purpose | Querying and manipulating databases | Application logic and procedural tasks |
| Nature | Declarative | Procedural |
| Scope | Data retrieval, insertion, updation, deletion | Complex scripts, stand-alone files, batch operations, exception handling |
| Statements | SELECT, INSERT, UPDATE, DELETE, CREATE, DROP | DECLARE, BEGIN, END, IF, FOR, WHILE (in addition to SQL statements) |
| Execution | Executes one statement at a time | Executes blocks of code as a unit |
| Interaction | Direct interaction with the database | Can include SQL statements and procedural constructs |
| Environment | Standard across various databases | Specific to Oracle databases |
3. Explain the features of PL/SQL.
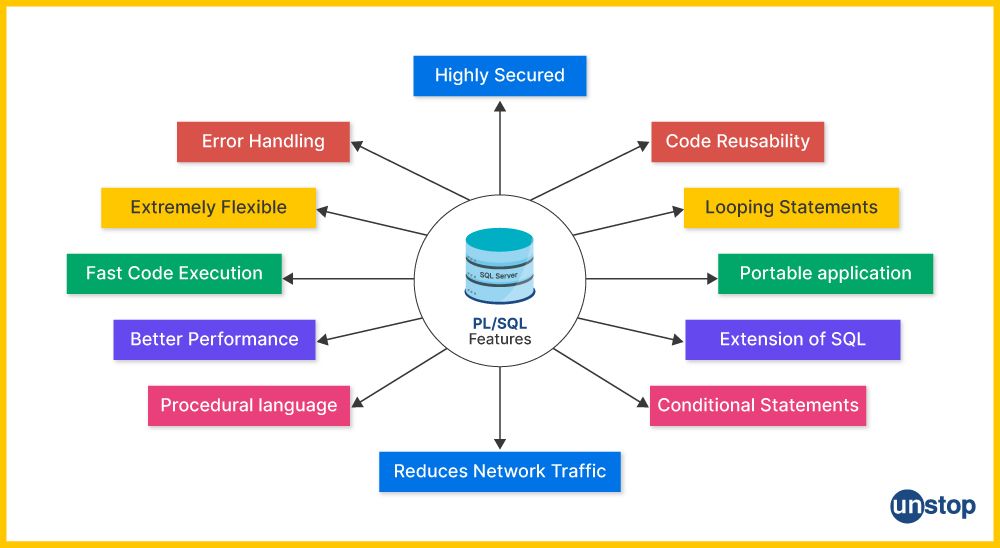
Some of the most common features of PL/SQL are:
- Procedural Capabilities: Unlike SQL, which is purely declarative, PL/SQL includes procedural constructs such as loop statements, logical conditions, and variables, enabling developers to write full-fledged programs.
- Blocks of Code: PL/SQL code is organized into blocks, each containing a declarative section (for table variable declarations), an executable section (for procedural P-code and SQL statements), and an exception-handling section (for error management).
- Integration with SQL: PL/SQL can include SQL statements within its code blocks/ piece of code, allowing for seamless integration of procedural logic and SQL data manipulation.
- Error Handling: It provides robust error-handling capabilities through the use of exceptions, which can catch and handle runtime errors.
- Modularity: PL/SQL supports the creation of modular and reusable components such as procedures, functions, packages, and triggers.
4. What are the advantages and disadvantages of PL/SQL?
Some of the advantages and disadvantages of PL/SQL are as follows:
Advantages of PL/SQL:
-
Tight Integration with SQL: PL/SQL allows seamless integration with SQL, enabling complex queries and data manipulation within procedural code blocks.
-
Modularity: PL/SQL supports the creation of modular components like procedures, functions, packages, and triggers, promoting code reusability and maintainability.
-
Performance: PL/SQL code can execute multiple SQL statements as a single block, reducing the context switching between client and server, which can lead to improved performance.
-
Robust Error Handling: PL/SQL provides comprehensive error-handling mechanisms through exceptions, allowing developers to manage and respond to runtime errors effectively.
-
Security: Stored procedures and package specifications can encapsulate business logic, ensuring that data manipulation is done consistently and securely. Access to database objects can be controlled more tightly.
-
Portability: PL/SQL code can run on any Oracle database platform, making it a portable solution for Oracle environments.
-
Reduced Network Traffic: Executing multiple operations within a single PL/SQL block can minimize network traffic between the client and server. This can enhance application response time, especially in data-intensive applications.
Disadvantages of PL/SQL:
-
Oracle Dependency: PL/SQL is specific to Oracle databases, which means code written in PL/SQL is not directly portable to other database systems without modification.
-
Complexity: The procedural nature of PL/SQL can increase code complexity, especially for developers more familiar with declarative SQL. Debugging and maintaining complex PL/SQL code can be challenging.
-
Learning Curve: Developers new to PL/SQL may face a steep learning curve due to its procedural constructs and the need to understand both SQL and programming concepts.
-
Limited GUI and Reporting Capabilities: PL/SQL is not designed for building graphical user interfaces or generating complex reports. It is primarily focused on server-side processing.
-
Performance Considerations: PL/SQL can lead to substantial performance benefits in some scenarios. However, poorly written PL/SQL code can lead to performance bottlenecks and have an adverse impact on database performance, particularly if it is not optimized for efficiency.
-
Limited Cross-Platform Use: Since PL/SQL is an Oracle-specific technology, applications that need to support multiple database systems may require additional effort to ensure compatibility.
5. Explain the basic structure of a PL/SQL block.
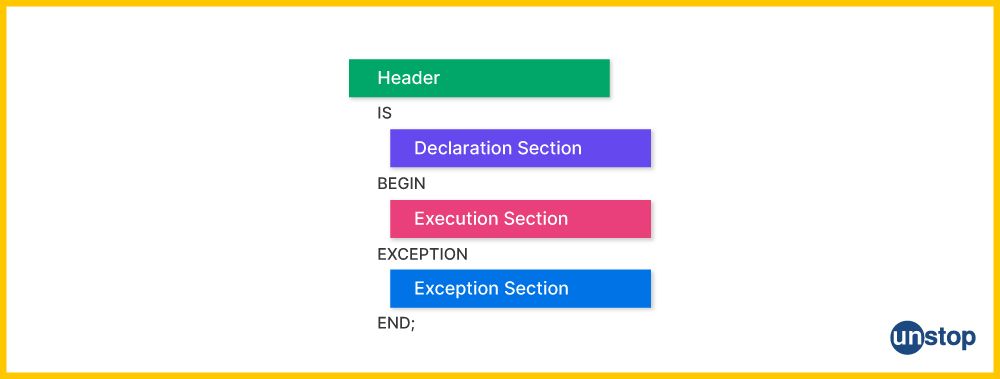
PL/SQL programs are structured into blocks. A PL/SQL block is a unit of code that consists of three main sections: the declarative section, the executable section, and the exception-handling section. Here's a complete breakdown of each section:
Declarative Section:
- Purpose: This section declares integer variables, code constants, cursors, and user-defined exceptions that will be used in the block.
- Location: It is optional and placed at the beginning of the block, after the DECLARE keyword (if present). Example:
DECLARE
v_name VARCHAR2(50);
v_age NUMBER := 30;
Executable Section:
- Purpose: This section contains the actual code that performs operations such as SQL queries, data manipulation, and procedural logic (loops, conditions, etc.).
- Location: It follows the BEGIN keyword and is the only mandatory section of a PL/SQL block. Example:
BEGIN
SELECT name INTO v_name FROM employees WHERE id = 1;
v_age := v_age + 5;
Exception-Handling Section:
- Purpose: This section handles exceptions (runtime errors) that occur during the block's execution. It allows the developer to define actions to take when specific errors are encountered.
- Location: It follows the EXCEPTION keyword and is optional. Example:
EXCEPTION
WHEN NO_DATA_FOUND THEN
DBMS_OUTPUT.PUT_LINE('No data found for the specified ID.');
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE('An unexpected error occurred.');
6. What is a cursor in PL/SQL?
A cursor in PL/SQL is a pointer that enables you to manage and control the context area—a memory region where Oracle processes SQL statements. Cursors (and various cursor commands) allow you to fetch and manipulate rows returned by a query one at a time, which is particularly useful for handling multi-row result sets. There are two primary types of cursors: explicit and implicit.
7. What is the difference between an implicit cursor and an explicit cursor?
The key differences between both the types of cursors in PL/SQL are as follows:
| Feature | Implicit Cursor | Explicit Cursor |
|---|---|---|
| Definition | Automatically created by PL/SQL for single SQL operations. | Explicitly defined and controlled by the programmer for complex queries. |
| Control | Automatically managed by PL/SQL. | Manually managed by the programmer, with specific cursor commands for opening, fetching, and closing. |
| Scope | Limited to single-row SQL operations, with cursor commands like SELECT INTO, INSERT, UPDATE, DELETE. | Can handle multi-row queries and provides finer control over the query execution. |
| Declaration | No explicit declaration is needed. | Explicit declaration is required using the CURSOR keyword. |
| Attributes | Uses SQL% attributes (e.g., SQL%FOUND, SQL%NOTFOUND) to check the status of the operation. | Uses cursor-specific attributes (e.g., cursor_name%FOUND, cursor_name%NOTFOUND) to check the status. |
| Memory Management | Managed automatically by the system. | Requires explicit handling, including allocation and deallocation of memory. |
| Fetch Mechanism | Automatically fetches the result set (single row). | Requires explicit fetch commands to retrieve rows one by one. |
| Usage Scenario | Simple SQL operations, typically single-row operations. | Complex SQL queries, multi-row operations, or when specific control over the result set is needed. |
| Example Usage (Cursor Commands) |
plsql BEGIN SELECT name INTO v_name FROM employees WHERE id = 1; END; | plsql DECLARE CURSOR c_employees IS SELECT name FROM employees; v_name employees.name%TYPE; BEGIN OPEN c_employees; FETCH c_employees INTO v_name; CLOSE c_employees; END; |
8. Can EXECUTE keyword be used to execute anonymous blocks in PL/SQL?
Yes, the EXECUTE keyword can be used to execute anonymous blocks in PL/SQL. An anonymous block is a set of valid SQL and PL/SQL statements grouped together as one segment that does not have an assigned name.
They are typically typed directly into command-line interfaces such as Oracle SQL*Plus or used within application programming sources to interact with underlying relational databases without having actual subprogram definitions created for the same operations every time they need to be executed again later on.
9. How to create and use user-defined exceptions in PL/SQL?
In PL/SQL, user-defined exceptions allow developers to define and handle specific error conditions that are not covered by the built-in exceptions. Here's how to create and use user-defined exceptions:
Steps to Create and Use User-Defined Exceptions:
- Declare the Exception: In the declarative section, declare the user-defined exception using the EXCEPTION keyword.
- Raise the Exception: Use the RAISE statement to trigger the exception in the executable section when a specific condition occurs.
- Handle the Exception: In the exception-handling section, define how the program should respond when the user-defined exception is raised.
10. How do you declare a variable in PL/SQL?
In PL/SQL, variables are declared in the declarative section of a block, subprogram, or package. The syntax for declaring a variable involves specifying the variable name, different data types, and optionally, an initial value.
Syntax:
variable_name data_type [NOT NULL] [:= initial_value];
- variable_name: The name of the variable.
- data_type: The type of data the variable can hold (e.g., NUMBER, VARCHAR2, DATE).
- NOT NULL (optional): Ensures that the variable cannot hold NULL values.
- initial_value (optional): Assigns an initial value to the variable.
11. What are the different types of loop statements in PL/SQL?
PL/SQL provides several types of loop constructs:
- Basic loop: Iterates indefinitely until explicitly exited.
- While loop: Iterates as long as a specified condition is true.
- For Loop: Iterates over a specific range or through each element of a collection.
Each type has its specific use cases and advantages, depending on the nature of the iteration required. Well-written constructs can help the code sail smoothly and improve readability.
12. What is a database server, and how is it used in PL/SQL?
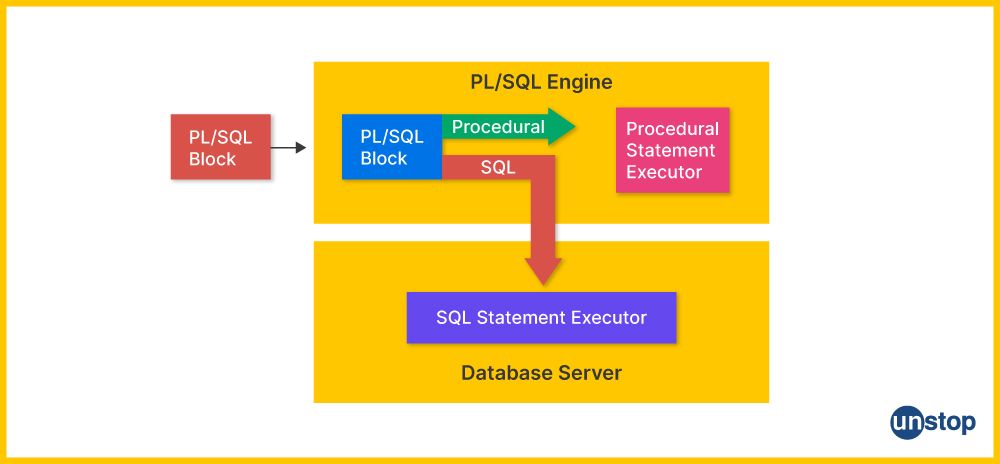
A database server is a computer system or a software application that provides database services to other computers or applications. It is responsible for storing, retrieving, and managing data in a database. The database server handles all database-related tasks, such as executing SQL queries, managing transactions, ensuring data integrity, and providing security.
Role of Database Server in PL/SQL Development:
In the context of PL/SQL, the database server plays a crucial role as it is where PL/SQL code is executed. PL/SQL is an extension of SQL designed for procedural programming and is primarily used within Oracle databases. Here’s how a database server is used in PL/SQL:
- Code Compilation and Execution: PL/SQL code is compiled and executed on the database server.
- Data Management: The server handles data storage, retrieval, and manipulation.
- Transaction Management: It ensures data consistency and integrity through transaction control (COMMIT, ROLLBACK).
- Concurrency Control: Manages concurrent access to data by multiple users or applications.
- Security: Enforces data access policies and user privileges.
13. What is the %TYPE attribute used for?
The %TYPE attribute in PL/SQL is used to declare a variable with the same data type as a column in a database table or another variable. It is a convenient way to ensure that the variable's data type matches the corresponding table column or table variable, especially when the data type might change in the future.
Syntax:
variable_name table_name.column_name%TYPE;
variable_name existing_variable%TYPE;
Key Benefits of Using %TYPE:
-
Data Type Consistency: Ensures that the variable has the same data type as the table column or table variable it refers to. This helps maintain consistency and avoid data type mismatches.
-
Ease of Maintenance: If the data type of the referenced column or table variable changes, the PL/SQL block does not need to be modified. The variable will automatically adopt the new data type.
-
Code Readability: This attribute makes the code smooth, i.e., more readable and self-explanatory, as it clearly indicates the source of the data type.
14. What are the type of exceptions in PL/SQL? How can you handle exceptions in PL/SQL?
In PL/SQL, exception handling is a mechanism that allows developers to manage errors and unexpected conditions that arise during the execution of PL/SQL code. Exceptions can be of two types: predefined exceptions or user-defined exceptions. They can be handled in a controlled manner to ensure that the program continues to function properly or gracefully exits when necessary.
Types of Exceptions:
- System-Defined/ Predefined Exceptions: These are standard exceptions provided by PL/SQL. Some examples of predefined exceptions are NO_DATA_FOUND, TOO_MANY_ROWS, and ZERO_DIVIDE.
- User-Defined Exceptions: These are custom exceptions defined by the user using the EXCEPTION keyword and PRAGMA EXCEPTION_INIT directive.
Basic Structure of Exception Handling:
A PL/SQL block has an optional EXCEPTION section where you can handle exceptions. The structure is as follows:
DECLARE
-- Declaration section (optional)
BEGIN
-- Executable section
EXCEPTION
-- Exception handling section
WHEN exception_name1 THEN
-- Handle the exception
WHEN exception_name2 THEN
-- Handle the exception
WHEN OTHERS THEN
-- Handle all other exceptions
END;
15. What is a trigger in PL/SQL? How does it work?
A trigger in PL/SQL is a stored procedure that automatically executes or "fires" in response to specific events occurring on a table or view. Triggers are used to enforce business rules, maintain data integrity, or perform automatic actions when certain conditions are met. They are an essential feature in relational databases for implementing complex, automated logic.
Types of Triggers:
-
DML Trigger Statements: Fired in response to Data Manipulation Language (DML) events, such as INSERT, UPDATE, or DELETE.
- BEFORE Trigger Statement: Executes before the DML operation.
- AFTER Trigger Statement: Executes after the DML operation.
- INSTEAD OF Trigger Statement: Executes instead of the DML operation.
-
DDL Trigger Statements: Fired in response to Data Definition Language (DDL) events, such as CREATE, ALTER, or DROP. They are used to manage changes to the database schema.
-
SYSTEM Trigger Statements: Fired in response to system events, such as database startup, shutdown, or user logon/logoff.
Components of a Trigger:
- Trigger Name: A unique identifier for the trigger.
- Trigger Event: The database event that causes the trigger to fire (e.g., INSERT, UPDATE, DELETE).
- Trigger Timing: Specifies whether the trigger should fire BEFORE or AFTER the event or INSTEAD OF the event.
- Trigger Body: Contains the PL/SQL code that is executed when the trigger fires.
How Triggers Work:
-
Definition: A trigger is created using the CREATE TRIGGER statement, specifying the event, timing, and the PL/SQL code to execute.
-
Execution: When the specified event occurs (e.g., an INSERT operation on a table), the database server automatically executes the trigger's PL/SQL code.
-
Scope: Triggers can be defined to act on individual rows (row-level triggers) or on the entire table (statement-level triggers).
16. How can numeric values be manipulated using PL/SQL?
In PL/SQL, numeric values can be manipulated through arithmetic operations such as addition, subtraction, multiplication, and division. Built-in functions like ABS, ROUND, and SQRT provide additional capabilities for handling numeric values, such as rounding and finding square roots.
Numeric variable values can be converted and formatted using functions like TO_NUMBER and TO_CHAR. Precision and scale can be managed by defining appropriate numeric data types, while error handling ensures robustness against issues like division by zero. These tools collectively allow for comprehensive and precise numeric manipulation in PL/SQL.
17. Describe the compilation process for a PL/SQL program.
The compilation process for a PL/SQL program involves several key steps, which transform the PL/SQL code into executable machine code or bytecode that the Oracle Database can run. Here's an overview of the compilation process:
- Parsing: Syntax and semantic checks.
- Pre-Compilation: Parse tree generation and resolution of variables and objects.
- Compilation: Conversion to bytecode and generation of executable code.
- Optimization: Performance and execution plan optimization.
- Storing: Storage of compiled code and metadata in the database.
- Error Handling: Detection and reporting of compilation issues or errors.
- Execution: Loading and executing the compiled code.
18. What is the syntax for creating a SQL table in PL/SQL?
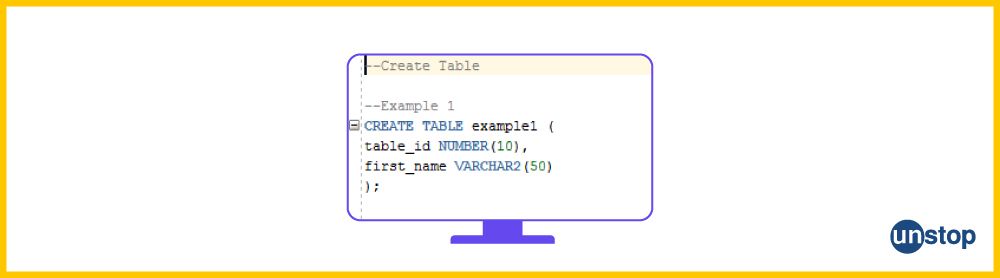
The syntax for creating a SQL table in PL/SQL involves using the CREATE TABLE statement. It requires you to specify an optional list of column definitions and other necessary parameters.
Generally, you must provide details for various fields of tables like name, data type to be used (e.g., text, number, etc.), size if applicable, and any default constraints that need setting up before actual row data can be added to those tables. For example:
CREATE TABLE myTableName(id INTEGER PRIMARY KEY NOT NULL, name VARCHAR2(50) DEFAULT 'John Doe');
In this example, "myTableName" is the new Table defined internally inside the Oracle database. It has two columns named id & Names, both conforming to predefined types 'INTEGER' & 'VARCHAR2' respectively.
19. Can PL/SQL commands store or display graphic images?
Yes, PL/SQL commands can store and display graphic images. Graphics files such as JPEGs or PNGs can be stored in the database within BLOB (binary large objects) fields that efficiently store digital properties. Likewise, these binary data types can then be used to output graphical elements from the results of a query via display packages like Oracle's own HTP package.
- This package allows developers to store pictures directly into their application databases and then render them on web pages without any extra work.
- This is done by utilizing functions like htp.image or even generating dynamic bar charts with graphs with code similar to htp.p ('<img src="data:image/png;base64,' || utl_encode( img ) || '" />' );
20. How do you declare an array in PL/SQL?
In PL/SQL, we declare arrays using collection types, specifically VARRAYs and nested tables. Below is a brief explanation of how to declare each type:
1. VARRAY (Variable-Size Array)
A VARRAY is a collection with a fixed maximum size. It is declared as follows:
-- Declare a VARRAY type
TYPE varray_type IS VARRAY(5) OF NUMBER;-- Declare a variable of that VARRAY type
varray_var varray_type;
2. Nested Table
A nested table is a collection that does not have a fixed size and can grow dynamically. It is declared as follows:
-- Declare a Nested Table type
TYPE nested_table_type IS TABLE OF VARCHAR2(100);-- Declare a variable of that Nested Table type
nested_table_var nested_table_type;
21. What is a ROLLBACK statement in PL/SQL?
The ROLLBACK statement in PL/SQL is a critical tool for managing transactions, allowing you to undo any changes made to the database within the current transaction.
- When a ROLLBACK is issued, it reverts all modifications made since the beginning of the transaction or since the last savepoint, restoring the database to its previous state.
- This is especially useful for handling errors or exceptions by ensuring that incomplete or erroneous changes do not affect the database.
- It is important to note that once a COMMIT statement is executed, the changes become permanent, and a subsequent ROLLBACK cannot undo those changes.
The ROLLBACK statement helps maintain data integrity and consistency by providing a way to discard unwanted changes and control the outcome of database operations.
22. Can video clips be included inside a PL/SQL program code?
No, video clips cannot be directly included or embedded inside PL/SQL program code. PL/SQL is a procedural language used to manage and manipulate data in Oracle databases. It primarily handles data processing, business logic, and database interactions, and it does not support embedding multimedia content, such as video clips, directly within its code.
23. What are the record-type statements available in PL/SQL?
Record-type statements in PL/SQL store data from database tables or other queries as a set of related elements. These statements provide the ability to process multiple values simultaneously instead of looping through each row individually.
The four record types in PL/SQL are CURSOR, RECORD, TABLE, and %ROWTYPE.
- Cursor is a special type that enables users to iterate the results set multiple times.
- Record allows access to individual columns within rows contained by query results.
- Table can hold one or more records for further operations such as sorting and selection.
- %ROWTYPE provides variable declarations that contain all fields from an associated table automatically populated with their corresponding values upon execution against it.
24. What is the purpose of WHEN clause in the trigger?
The WHEN clause in a trigger is used to specify a condition that must be met for the trigger's actions to be executed.
- It allows us to add a conditional filter to the trigger, ensuring that the trigger fires only when certain criteria are satisfied.
- This can be particularly useful for optimizing performance and ensuring that the trigger's logic applies only in relevant situations.
- For example, in a BEFORE INSERT trigger on a table, we can use the WHEN clause to check if the inserted value meets specific conditions before executing the trigger's actions, thereby avoiding unnecessary processing for all insertions.
25. What is the use of WHERE CURRENT OF in cursors?
The WHERE CURRENT OF clause in PL/SQL cursor commands is used to reference the current row in the cursor result set for update or delete operations.
- This clause/ cursor attribute is particularly useful when we need to update or delete the row that has just been fetched by the cursor, ensuring that the modifications are applied to the correct row.
- By using WHERE CURRENT OF, we avoid the need for a separate WHERE condition that matches the primary key or unique identifier of the row, simplifying the code and reducing the risk of errors. Here is an example of its usage:
DECLARE
CURSOR emp_cursor IS SELECT emp_id, salary FROM employees;
BEGIN
FOR emp_rec IN emp_cursor LOOP
-- Some processing logic
IF emp_rec.salary < 5000 THEN
UPDATE employees
SET salary = salary * 1.10
WHERE CURRENT OF emp_cursor;
END IF;
END LOOP;
END;
24. What do you understand by PL/SQL table?
In PL/SQL, a PL/SQL table, also known as an associative array or index-by table, is a collection type that allows us to store and manipulate a set of values indexed by either integers or strings.
- Unlike regular SQL tables, PL/SQL tables exist only in memory and are used within PL/SQL blocks, procedures, or functions to hold temporary data.
- PL/SQL tables are similar to arrays in other programming languages but provide more flexibility.
- We can dynamically add or remove elements, and the indexes do not need to be sequential. This makes them particularly useful for operations requiring temporary storage, complex data manipulation, or passing collections of data between PL/SQL programs.
25. Why is SYSDATE used in PL/SQL?
In PL/SQL, SYSDATE is used to retrieve the current date and time from the Oracle database server. It returns the system's current date and time in the default date format. This function is commonly used for various purposes, such as timestamping transactions, calculating the age of data, auditing, and scheduling tasks.

PL SQL Interview Questions: Intermediate
26. Write PL/SQL program to find the sum of digits of a number.
Here is a PL/SQL program that calculates the sum of the digits of a given number:
DECLARE
input_number NUMBER := 12345; -- Replace with the number you want to find the sum of digits
digit NUMBER;
sum_of_digits NUMBER := 0;
BEGIN
-- Ensure input_number is positive
input_number := ABS(input_number);
-- Loop to extract and sum each digit
WHILE input_number > 0 LOOP
digit := MOD(input_number, 10); -- Get the last digit
sum_of_digits := sum_of_digits + digit; -- Add the digit to the sum
input_number := TRUNC(input_number / 10); -- Remove the last digit
END LOOP;
-- Output the result
DBMS_OUTPUT.PUT_LINE('Sum of digits: ' || sum_of_digits);
END;
/
REVDTEFSRQppbnB1dF9udW1iZXIgTlVNQkVSIDo9IDEyMzQ1OyAtLSBSZXBsYWNlIHdpdGggdGhlIG51bWJlciB5b3Ugd2FudCB0byBmaW5kIHRoZSBzdW0gb2YgZGlnaXRzCmRpZ2l0IE5VTUJFUjsKc3VtX29mX2RpZ2l0cyBOVU1CRVIgOj0gMDsKQkVHSU4KLS0gRW5zdXJlIGlucHV0X251bWJlciBpcyBwb3NpdGl2ZQppbnB1dF9udW1iZXIgOj0gQUJTKGlucHV0X251bWJlcik7CgotLSBMb29wIHRvIGV4dHJhY3QgYW5kIHN1bSBlYWNoIGRpZ2l0CldISUxFIGlucHV0X251bWJlciA+IDAgTE9PUApkaWdpdCA6PSBNT0QoaW5wdXRfbnVtYmVyLCAxMCk7IC0tIEdldCB0aGUgbGFzdCBkaWdpdApzdW1fb2ZfZGlnaXRzIDo9IHN1bV9vZl9kaWdpdHMgKyBkaWdpdDsgLS0gQWRkIHRoZSBkaWdpdCB0byB0aGUgc3VtCmlucHV0X251bWJlciA6PSBUUlVOQyhpbnB1dF9udW1iZXIgLyAxMCk7IC0tIFJlbW92ZSB0aGUgbGFzdCBkaWdpdApFTkQgTE9PUDsKCi0tIE91dHB1dCB0aGUgcmVzdWx0CkRCTVNfT1VUUFVULlBVVF9MSU5FKCdTdW0gb2YgZGlnaXRzOiAnIHx8IHN1bV9vZl9kaWdpdHMpOwpFTkQ7Ci8=
Explanation:
In the above PL/SQL code, we calculate the sum of the digits of a given number. It loops through each digit of the input_number, adds each digit to sum_of_digits, and then removes the last digit until the entire number is processed. Finally, it outputs the sum of the digits.
27. Write a PL/SQL code to find whether a given string is palindrome or not.
Here's a PL/SQL block that checks whether a given string is a palindrome or not:
DECLARE
input_string VARCHAR2(100) := 'madam'; -- Replace with the string you want to check
reversed_string VARCHAR2(100) := '';
len NUMBER := 0;
is_palindrome BOOLEAN := TRUE;
BEGIN
-- Get the length of the input string
len := LENGTH(input_string);
-- Reverse the input string
FOR i IN REVERSE 1..len LOOP
reversed_string := reversed_string || SUBSTR(input_string, i, 1);
END LOOP;
-- Check if the input string is equal to the reversed string
IF input_string = reversed_string THEN
is_palindrome := TRUE;
ELSE
is_palindrome := FALSE;
END IF;
-- Output the result
IF is_palindrome THEN
DBMS_OUTPUT.PUT_LINE(input_string || ' is a palindrome.');
ELSE
DBMS_OUTPUT.PUT_LINE(input_string || ' is not a palindrome.');
END IF;
END;
/
REVDTEFSRQppbnB1dF9zdHJpbmcgVkFSQ0hBUjIoMTAwKSA6PSAnbWFkYW0nOyAtLSBSZXBsYWNlIHdpdGggdGhlIHN0cmluZyB5b3Ugd2FudCB0byBjaGVjawpyZXZlcnNlZF9zdHJpbmcgVkFSQ0hBUjIoMTAwKSA6PSAnJzsKbGVuIE5VTUJFUiA6PSAwOwppc19wYWxpbmRyb21lIEJPT0xFQU4gOj0gVFJVRTsKQkVHSU4KLS0gR2V0IHRoZSBsZW5ndGggb2YgdGhlIGlucHV0IHN0cmluZwpsZW4gOj0gTEVOR1RIKGlucHV0X3N0cmluZyk7CgotLSBSZXZlcnNlIHRoZSBpbnB1dCBzdHJpbmcKRk9SIGkgSU4gUkVWRVJTRSAxLi5sZW4gTE9PUApyZXZlcnNlZF9zdHJpbmcgOj0gcmV2ZXJzZWRfc3RyaW5nIHx8IFNVQlNUUihpbnB1dF9zdHJpbmcsIGksIDEpOwpFTkQgTE9PUDsKCi0tIENoZWNrIGlmIHRoZSBpbnB1dCBzdHJpbmcgaXMgZXF1YWwgdG8gdGhlIHJldmVyc2VkIHN0cmluZwpJRiBpbnB1dF9zdHJpbmcgPSByZXZlcnNlZF9zdHJpbmcgVEhFTgppc19wYWxpbmRyb21lIDo9IFRSVUU7CkVMU0UKaXNfcGFsaW5kcm9tZSA6PSBGQUxTRTsKRU5EIElGOwoKLS0gT3V0cHV0IHRoZSByZXN1bHQKSUYgaXNfcGFsaW5kcm9tZSBUSEVOCkRCTVNfT1VUUFVULlBVVF9MSU5FKGlucHV0X3N0cmluZyB8fCAnIGlzIGEgcGFsaW5kcm9tZS4nKTsKRUxTRQpEQk1TX09VVFBVVC5QVVRfTElORShpbnB1dF9zdHJpbmcgfHwgJyBpcyBub3QgYSBwYWxpbmRyb21lLicpOwpFTkQgSUY7CkVORDsKLw==
Explanation:
In the above code, we check whether a given string is a palindrome. It reverses the input_string, compares it with the original string, and sets is_palindrome to TRUE if they match. Finally, it outputs whether the string is a palindrome or not.
28. How to create and use database links in different schemas using PL/SQL programs?
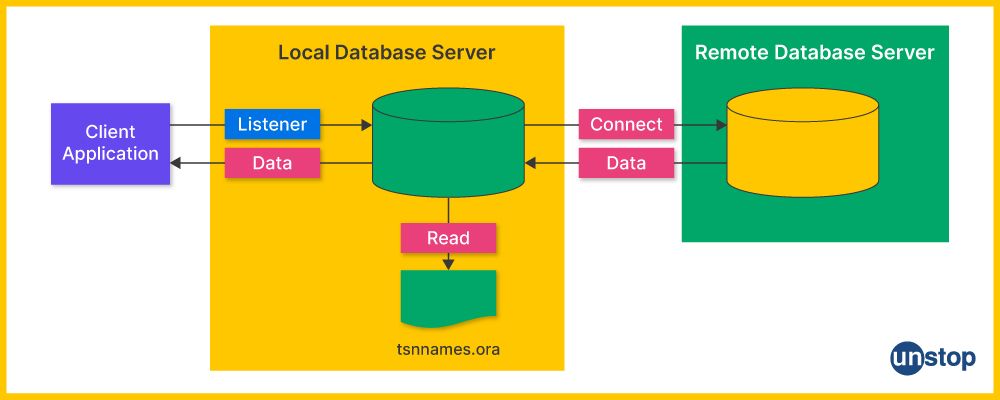
Creating and using database links in different schemas using PL/SQL programs involves several steps. A database link is a schema object in one database that allows you to access objects (tables, views, etc.) in another database. Here’s a step-by-step guide to creating and using database links:
- Create a Database Link: To create a database link, you need to have the appropriate privileges and specify the connection details to the remote database. For example-
CREATE DATABASE LINK link_name
CONNECT TO remote_user IDENTIFIED BY password
USING 'connect_string';
- Use the Database Link in PL/SQL Programs: Once the database link is created, you can use it in your PL/SQL programs to perform operations on remote database objects. You can reference the remote objects using the database link name. For example-
BEGIN
-- Query a remote table using the database link
FOR rec IN (SELECT * FROM remote_table@remote_db_link) LOOP
-- Process each record
DBMS_OUTPUT.PUT_LINE('Remote Table Data: ' || rec.column_name);
END LOOP;-- Insert data into a local table from a remote table
INSERT INTO local_table (column1, column2)
SELECT column1, column2 FROM remote_table@remote_db_link;-- Commit changes
COMMIT;
EXCEPTION
WHEN OTHERS THEN
-- Handle exceptions
DBMS_OUTPUT.PUT_LINE('An error occurred: ' || SQLERRM);
ROLLBACK;
END;
29. How can we manipulate data stored within database tables using SQL blocks in PL/SQL?
In PL/SQL, we can manipulate data stored within database tables using SQL blocks. Here’s a breakdown of how this can be achieved:
- Using SELECT Statements: Use SELECT statements to fetch data from tables and assign it to PL/SQL variables or cursors. For example, SELECT column_name INTO variable_name FROM table_name WHERE condition;
- Using INSERT Statements: Use INSERT statements to add new rows to tables. For example: INSERT INTO table_name (column1, column2) VALUES (value1, value2);
- Using UPDATE Statements: Use UPDATE statements to change data in existing rows based on specified conditions. For Examples: UPDATE table_name SET column1 = value1 WHERE condition;
- Using DELETE Statements: Use DELETE statements to remove rows from tables based on specified conditions. For Examples: DELETE FROM table_name WHERE condition;
- Using PL/SQL Variables and Cursors: Store and manipulate data fetched from or to be inserted into tables using PL/SQL variables. Use explicit or implicit cursors to handle multiple rows and perform operations on them.
- Error Handling: Use exception handling to manage errors that occur during data manipulation operations, such as constraint violations or data integrity issues.
- Dynamic SQL: Use the EXECUTE IMMEDIATE statement to execute dynamically constructed SQL statements or PL/SQL blocks.
30. List various schema objects associated with SQL tables in PL/SQL?
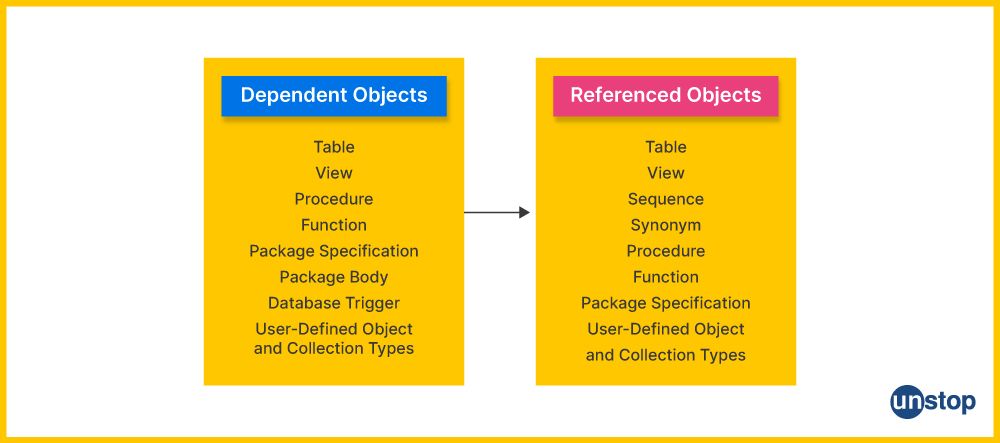
In PL/SQL, various schema objects are associated with SQL tables used to define database structure and the interaction between different queries in an application program. These include:
- Tables - Tables are collections of connected data items made up of rows and columns that include details about a specific subject or entity.
- Views - It refers to a virtual table containing data from one or multiple tables.
- Sequences - They generate unique numerical values automatically whenever required.
- Indexes – An index helps improve query performance by providing quick access to specific records within large datasets.
- Synonyms - Synonyms act as aliases for schema objects like tables & views to be referenced using more structured naming conventions without repeating their underlying structures across applications programs repeatedly each time they need fetching from databases at runtime.
- Stored Procedures - Stored procedures contain PL/SQL code blocks that execute predefined tasks on behalf of application programs, making them easier to maintain centrally rather than repeating similar sections in all related client programs independently.
- Triggers – Triggers react dynamically based on defined events inside databases, like before updates, after inserts, etc., allowing developers to write custom code for processing complex operations.
- Packages – Packages contain predefined procedures and functions that provide abstracted access to underlying data structures (like tables & views).
31. How do you handle table errors in PL/SQL programming?
Handling table errors in PL/SQL programming involves addressing issues that arise during DML operations (such as INSERT, UPDATE, DELETE) or during interactions with the database schema. These errors can range from data integrity violations to constraint violations. Here’s how to handle and manage such errors effectively:
-
Exception Handling:
- Use PL/SQL’s EXCEPTION block to catch and handle errors during execution.
- Handle specific exceptions such as NO_DATA_FOUND, DUP_VAL_ON_INDEX, and VALUE_ERROR.
- Use the OTHERS handler to catch any unanticipated exceptions.
-
Constraint Violations:
- Manage errors related to database constraints (e.g., primary key, foreign key, unique constraints) using exception handling.
- Address errors such as CHECK_CONSTRAINT_VIOLATED when constraints are violated.
-
DML Operations:
- Handle errors that occur during INSERT, UPDATE, and DELETE operations.
- Catch exceptions related to data integrity and referential integrity constraint violations.
-
Logging Errors:
- Log error details to a dedicated error log table for troubleshooting and auditing purposes.
- Use DBMS_OUTPUT for actual error message display during development.
-
Deadlock Management:
- Prevent deadlocks by designing transactions to acquire locks in a consistent order.
- Implement timeout settings to detect and manage deadlocks.
-
Data Validation:
- Validate data before performing DML operations to avoid errors related to invalid or inappropriate data.
32. What is the purpose of a database trigger in PL/SQL? 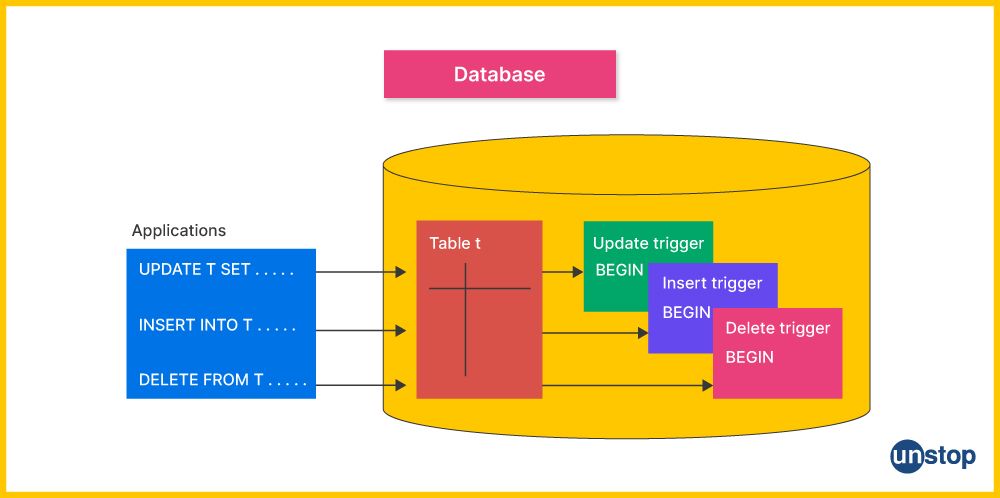
In PL/SQL, a database trigger is a specialized type of stored procedure that is automatically executed or fired in response to specific events on a table or view. The primary purpose of a database trigger is to enforce business rules, maintain data integrity, and automate certain actions based on changes in the database. Here’s a detailed overview of its purposes:
- Enforce Business Rules: Automatically apply business rules to data changes.
- Maintain Data Integrity: Validate and ensure consistent data entry and updates.
- Automate System Tasks: Perform automatic updates, calculations, and other tasks.
- Enforce Referential Integrity: Manage cascading updates or deletions in related tables.
- Audit and Log Changes: Track and log changes for auditing and compliance.
- Prevent Unauthorized Actions: Restrict or control changes based on permissions or rules of complex security authorization.
33. What is the difference between a procedure and a function?
The key differences between a procedure and a function are as follows:
| Aspect | Procedure | Function |
|---|---|---|
| Purpose | Performs an action or a series of actions. | Computes and returns a single value. |
| Return Value | Does not return a value. | Returns a single value. |
| Usage | Used for operations like data modification, logging, etc. | Used for arithmatic calculations or data transformations. |
| Syntax | PROCEDURE procedure_name IS ... BEGIN ... END; | FUNCTION function_name RETURN data_type IS ... BEGIN ... END; |
| Calling | Called using EXECUTE procedure_name; or directly in PL/SQL blocks. | Called as part of an expression or assignment (e.g., result := function_name(parameters);). |
| Output | Can have multiple OUT parameters to return values. | Returns a value via the RETURN statement. |
| Example | PROCEDURE update_salary(emp_id NUMBER, new_salary NUMBER) IS ... BEGIN ... END; | FUNCTION calculate_bonus(salary NUMBER) RETURN NUMBER IS ... BEGIN ... RETURN bonus; END; |
34. How can you handle NULL values in PL/SQL?
Handling NULL values in PL/SQL is crucial as they represent the absence of a value, which can affect the outcome of expressions, conditions, and assignments. Here are some common ways to handle NULL values in PL/SQL:
- Checking for NULL: You can check if a value is NULL using the IS NULL and IS NOT NULL operators.
- NVL Function: The NVL function replaces NULL with a specified value. It's commonly used to provide a default value when a column or variable is NULL.
- COALESCE Function: The COALESCE function returns the first non-NULL value from a list of expressions. It is useful when you want to check multiple values and find the first non-NULL one.
- NULLIF Function: The NULLIF function returns NULL if the two arguments are equal; otherwise, it returns the first argument.
35. What is a forward declaration in PL/SQL?
A forward declaration in PL/SQL refers to the practice of declaring the interface of a procedure, function, or package before its actual implementation is provided. This allows you to reference or call these constructs before their full definitions are available in the code. Forward declarations are particularly useful in scenarios involving recursive calls or when defining dependencies between PL/SQL objects.
Syntax:
CREATE OR REPLACE PACKAGE my_package AS
PROCEDURE my_procedure; -- Forward declaration
FUNCTION my_function (param1 NUMBER) RETURN NUMBER; -- Forward declaration
END my_package;
36. How do you execute a PL/SQL block in SQL*Plus?
To execute a PL/SQL block in SQL*Plus, follow these steps:
- Open SQL*Plus: Start SQL*Plus from your command line or terminal:
sqlplus username/password@database
- Write the PL/SQL Block: Enter the PL/SQL block in SQL*Plus. The block should be enclosed in BEGIN and END; statements. Use / on a new line to execute the block.
BEGIN
DBMS_OUTPUT.PUT_LINE('Hello, World!');
END;
/
- Execute the Block: After typing the PL/SQL block, press Enter to execute it. The / on a new line tells SQL*Plus to execute the PL/SQL block.
- View Output: To see output from DBMS_OUTPUT.PUT_LINE, ensure that server output is enabled:
SET SERVEROUTPUT ON;
37. How do you define and use a cursor for loop?
In PL/SQL, a cursor for loop simplifies the process of fetching and processing rows from a cursor. It automatically handles the opening, fetching, and closing of the cursor, making the code more concise and readable. Here’s how to define and use a cursor for loop:
- Define the cursor: A cursor must be declared to specify the query whose results you want to process.
CURSOR emp_cursor IS
SELECT employee_id, first_name, last_name
FROM employees;
- Use the cursor for Loop: Use the cursor for loop to iterate over each row returned by the cursor.
DECLARE
CURSOR emp_cursor IS
SELECT employee_id, first_name, last_name
FROM employees;
BEGIN
FOR emp_record IN emp_cursor LOOP
DBMS_OUTPUT.PUT_LINE('ID: ' || emp_record.employee_id ||
', Name: ' || emp_record.first_name || ' ' || emp_record.last_name);
END LOOP;
END;
Key points:
- Automatic Management: The for loop automatically handles cursor operations like opening the cursor, fetching rows, and closing the cursor.
- Record Variable: Inside the loop, the record is a record variable that represents each row fetched by the cursor. You can access columns using record.column_name.
- Simplified Code: This method reduces the need for explicit cursor handling (e.g., OPEN, FETCH, CLOSE) and makes the code cleaner and easier to maintain.
38. What is the BULK COLLECT clause? How is it used?
The BULK COLLECT clause in PL/SQL is used to fetch multiple rows from a query into PL/SQL collections (such as arrays) in a single operation. This clause is designed to improve performance when dealing with large volumes of data by reducing the number of context switches between SQL and PL/SQL.
Syntax:
SELECT column1, column2
BULK COLLECT INTO collection1, collection2
FROM table_name;
Its key features are as follows:
- Efficiency: Fetches multiple rows in one go, reducing the number of SQL calls and improving performance.
- Collections: Can be used with different PL/SQL collection types, such as VARRAYs, TABLEs, and ASSOCIATIVE ARRAYS.
How It’s Used:
-
Declare Collections: Define PL/SQL collections to hold the fetched data.
-
Use BULK COLLECT: Fetch the data from the database into these collections in one operation.
-
Process Data: Iterate through the collections to process the retrieved data.
39. How can you optimize PL/SQL code?
Optimizing PL/SQL code involves various strategies to enhance performance, reduce execution time, and efficiently manage resources. Here are key techniques for optimizing PL/SQL code:
1. Use Efficient SQL Queries:
- Indexing: Ensure that proper indexes are used to speed up query performance.
- Avoid Full Table Scans: Use selective queries and proper WHERE clauses to minimize the number of rows processed.
- Use Bind Variables: Reduce parsing overhead by using bind variables instead of hard-coded series of literals.
2. Minimize Context Switching:
- Bulk Processing: Use BULK COLLECT and FORALL to minimize context switches between PL/SQL and SQL.
- Reduce SQL Calls: Combine multiple SQL operations into a single batch where possible.
3. Optimize PL/SQL Code Structure:
- Efficient Loops: Use FOR loops and BULK COLLECT to process large datasets efficiently.
- Avoid Nested Loops: Minimize the use of nested loops within PL/SQL blocks.
4. Use Efficient Data Structures:
- Collections: Use appropriate collection types (e.g., associative arrays, nested tables) based on the requirements.
- Limit Memory Usage: Manage the size of collections and data buffers to avoid excessive memory consumption.
5. Improve Exception Handling: Avoid catching generic exceptions that might mask underlying issues. Handle specific exceptions to provide more targeted error handling.
6. Optimize Cursor Usage:
- Cursor Sharing: Use FOR loops with implicit cursors to simplify cursor management and improve performance.
- Use Cursors Efficiently: Limit the use of explicit cursors when not necessary and ensure proper cursor management (open, fetch, close).
7. Leverage PL/SQL Built-in Functions: Utilize PL/SQL built-in functions for common operations to leverage optimized internal implementations.
8. Minimize Redundant Operations
- Avoid Redundant Calculations: Cache memory results of expensive operations or calculations to avoid redundant processing.
- Optimize Data Manipulation: Ensure data manipulation operations (e.g., INSERT, UPDATE) are performed efficiently.
9. Tune PL/SQL Performance
- Analyze Execution Plans: Use tools like Oracle’s SQL*Plus or SQL Developer to analyze execution plans and identify bottlenecks.
- Profile Code: Use Oracle’s built-in profiling tools to identify performance issues.
10. Manage Transactions Efficiently: Minimize transaction size to reduce locking and contention issues. Use commits and rollbacks judiciously.
40. How can the table column be modified using the ALTER command as part of DDL operations?
- To modify a table column using the ALTER command as part of DDL operations, the server-side hosting instance-related services running under RDBMS software must support a dynamic SQL execution mechanism.
- Tables should reside inside schema-based repositories developed based on a relational paradigm consistent with following ACID principles adopted from autonomous transaction processing theory.
- In order to execute such a statement, the user will have to login into a database and acquire the necessary privileges for performing the operation without any conflicts generated by other transactions in the same or different schemas involved in the current session.
41. What are actual parameters, and how do they work with current transactions when programming with PL/SQL?
Actual parameters are values passed to a procedure or function during invocation. When programming with PL/SQL, they can be used within the current transaction by referencing them in SQL statements (e.g., SELECT * FROM TABLE WHERE id =:p_id). This enables developers to conditionally execute database operations depending on the values provided during execution.
For example: If some procedure was designed to retrieve data only from recent entries, then p_id being not null would trigger a query that selects all records created after the given date. Having it set as NULL would cause those lines of code to be skipped altogether.
42. In PL/SQL, how do you add a new table row using DML operations?
New table rows can be added using DML (Data Manipulation Language) methods in PL/SQL. The INSERT statement, which describes the columns and values of a specific row that you want to add to your database, is used to do this.
For instance: (column1, column2,...) INSERT INTO MY TABLE VALUES ('value1', 'value2',...); This will create a new table row in "my_table" containing the appropriate values for each provided column. You can insert several rows simultaneously using stored procedures or dynamic SQL.
43. How can you use pseudo-columns to manipulate data within PL/SQL?
Pseudo columns are virtual columns that present particular values in a SELECT statement but have no actual existence within the underlying table. In PL/SQL, pseudo-columns can manipulate data by providing additional information for operations such as sorting or replacing existing column names when selecting records from tables.
For example, you could use the ROWID pseudo-column to retrieve the unique row identifier of each record without having it explicitly defined in your SELECTquery like so:
SELECT ... FROM my_table ORDER BY ROWID;
This would result in all queried rows being sorted according to their row identifiers instead of any other previously specified order criteria.
44. Describe a Database Management System (DBMS) and explain how PL/SQL uses one.
A Database Management System (DBMS) is software that facilitates the creation, manipulation, and management of databases. It provides a systematic way to store, retrieve, and manage data efficiently, ensuring data integrity, security, and concurrent access by multiple users.
PL/SQL (Procedural Language/Structured Query Language) is Oracle's procedural extension to SQL. It allows users to write complex scripts and procedures that interact with Oracle databases. Here’s how PL/SQL utilizes a DBMS:
- Data Manipulation: PL/SQL enables users to perform data manipulation operations (e.g., INSERT, UPDATE, DELETE) within procedural code blocks. It allows for complex business logic to be implemented directly in the database.
BEGIN
INSERT INTO employees (employee_id, first_name, last_name)
VALUES (1, 'John', 'Doe');
END;
- Data Retrieval: PL/SQL allows for querying data using SQL within PL/SQL blocks. It can fetch data into variables or collections for further processing.
DECLARE
emp_name VARCHAR2(50);
BEGIN
SELECT first_name INTO emp_name
FROM employees
WHERE employee_id = 1;
DBMS_OUTPUT.PUT_LINE('Employee Name: ' || emp_name);
END;
- Stored Procedures and Functions: PL/SQL supports the creation of stored procedures and functions that encapsulate business logic. These procedures and functions can be called from other PL/SQL blocks, SQL queries, or applications.
CREATE OR REPLACE PROCEDURE update_salary (emp_id NUMBER, new_salary NUMBER) IS
BEGIN
UPDATE employees
SET salary = new_salary
WHERE employee_id = emp_id;
END;
- Error Handling: PL/SQL provides robust exception handling to manage and respond to runtime errors effectively, ensuring smooth execution of database operations.
BEGIN
-- Some operations
EXCEPTION
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE('An error occurred: ' || SQLERRM);
END;
45. How can you write a single query in PL/SQL to search for duplicate values?
You can use a combination of SQL aggregation functions and the GROUP BY clause to search for duplicate values in a table using a single query in PL/SQL. This approach identifies duplicate rows based on one or more columns by counting occurrences and filtering results with a count greater than one.
Here’s a general approach to writing such a query:
SELECT email
FROM employees
GROUP BY email
HAVING COUNT(email) > 1;
Finding Duplicates Based on Multiple Columns
If duplicates are determined by a combination of columns, you can extend the query to include those columns. For example, to find duplicates based on both first_name and last_name:
SELECT first_name, last_name
FROM employees
GROUP BY first_name, last_name
HAVING COUNT(*) > 1;
46. What different object types are available when using PL/SQL?
When using PL/SQL, several object types are available to help structure and manage your code and data. These object types include various constructs for handling data, organizing code, and enhancing database operations. Here’s an overview of the different object types:
- Tables: It is a database object that stores data in rows and columns values. Tables are used to persistently store data that can be queried, updated, or deleted.
- Views: It is a virtual table based on the result of a SELECT query. Views provide a way to simplify complex queries, present data in a specific format, or restrict access to certain columns or rows.
- Indexes: They are database objects that improve the speed of data retrieval operations on a table. Indexes are used to enhance query performance by providing quick access to rows based on the values of indexed columns.
- Sequences: It is an object that generates a series of unique numbers. Sequences are commonly used to generate primary key values or unique identifiers.
- Stored Procedures: This is a named PL/SQL block that performs a specific task and can be called with parameters. Stored procedures encapsulate business logic and can be reused across different applications or processes.
- Functions: It is a named PL/SQL block that performs a computation and returns a single value. Functions are used to perform calculations or return values based on input parameters.
- Packages: It is a collection of related procedures, functions, variables, and cursors grouped together. Packages provide modularity and encapsulation, allowing related code to be organized and managed as a single unit.
- Triggers: It is a PL/SQL block that is automatically executed (fired) in response to specific events on a table or view. Triggers are used to enforce business rules, maintain data integrity, or audit changes.
- Types: Custom data types defined in PL/SQL, such as records, arrays, or objects. Custom types are used to define complex data structures and improve code readability and maintainability.
- Object Types: They help define a user-defined data structure with attributes and methods. Object types support object-oriented programming features, allowing you to model real-world entities.
- Exceptions: Exception handling objects to manage runtime errors. They are used to handle errors and manage the flow of execution in case of exceptional conditions.
47. What is the default mode of parameters in a PL/SQL procedure?
In PL/SQL, the default mode for parameters in a procedure is IN. This means that unless specified otherwise, parameters are treated as input-only parameters.
- In this mode, the procedure can use the values passed to it but cannot modify them. This is because IN parameters are read-only within the procedure.
- To change this behavior, we can explicitly declare parameters as OUT or IN OUT.
- OUT parameters are used to return values from the procedure to the caller, while IN OUT parameters allow both input and output operations, meaning they can be used to pass initial values and also receive modified values from the procedure.
48. What is the difference between a RECORD and a ROWTYPE in PL/SQL?
Here's a table outlining the key differences between RECORD and ROWTYPE in PL/SQL:
| Feature | RECORD | ROWTYPE |
|---|---|---|
| Definition | A user-defined composite data type. | A data type that represents a row in a table or cursor. |
| Structure | Defined explicitly with named fields. | Automatically inherits the structure of a table or cursor. |
| Flexibility | Can include any combination of data types. | Structure matches exactly with the table or cursor's column structure. |
| Usage | Useful for custom data structures. | Useful for working with entire rows of data from tables or cursors. |
| Example | TYPE my_record IS RECORD (name VARCHAR2, age NUMBER); | TYPE my_rowtype IS RECORD (name employees.name%TYPE, age employees.age%TYPE); |
PL SQL Interview Questions: Advanced
49. How can you select a range of values within my PL/SQL query?
To select a range of values within a PL/SQL query, you can use various SQL constructs depending on the specific needs of your query. The most common method is to use the WHERE clause with comparison operators to filter data within a specified range. Here’s how you can achieve this:
1. Using Comparison Operators: For a basic range selection, you can use comparison operators such as BETWEEN or a combination of >= and <= operators. For example:
SELECT *
FROM employees
WHERE salary BETWEEN 50000 AND 100000;
2. Using IN for Discrete Values: If you need to select rows based on a set of discrete values rather than a continuous range, you can use the IN operator. For example:
SELECT *
FROM employees
WHERE department_id IN (10, 20, 30);
3. Selecting Ranges Based on Date Values: For selecting a range based on date values, you use the BETWEEN operator or >= and <= with date literals. For example:
SELECT *
FROM orders
WHERE order_date BETWEEN DATE '2023-01-01' AND DATE '2023-12-31';
4. Using ROWNUM or ROW_NUMBER() for Limited Ranges: If you want to select a specific range of rows based on their order, you can use ROWNUM or ROW_NUMBER(). For example:
SELECT *
FROM (
SELECT *
FROM employees
ORDER BY hire_date
)
WHERE ROWNUM BETWEEN 10 AND 20;
50. What types of records can be manipulated through PL/SQL programming?
In PL/SQL, you can manipulate various types of records, including:
- Explicit Records: Custom-defined records with specific fields.
- Cursor Records: Rows returned by a cursor query.
- %ROWTYPE Records: Automatically adapt to the structure of a table or cursor.
- PL/SQL Records: Custom records for specific use cases.
- Table Records: Direct manipulation of rows in database tables.
51. What are the modes of parameters available in PL/SQL when passing arguments to stored procedures?
When passing arguments to stored procedures in PL/SQL, there are different modes of parameters available that can be used. The four main modes are IN, OUT, INOUT, and DEFAULT, which indicate the type of input accepted for a particular parameter or argument.
- The mode 'IN' indicates an argument passed into the procedure from its calling environment.
- 'OUT' specifies that data will flow back to its calling environment.
- 'INOUT' signifies both incoming and outgoing information between a given procedure's environment.
- Finally, when no explicit mode is specified, it defaults to 'DEFAULT' mode, where any changes this parameter makes within the execution context remain local.
52. What are row-level triggers, and how do they work in PL/SQL programming?
Row-level triggers in PL/SQL are a type of database trigger that executes for each row affected by an INSERT, UPDATE or DELETE operation on a table. They are used to perform specific actions or enforce business rules at the row level, meaning they execute once for each row that meets the triggering condition.
Key Characteristics of Row-Level Triggers:
-
Execution Per Row: Row-level triggers fire once for each row affected by the operation. If a statement affects multiple rows, the trigger is executed multiple times—once for each row.
-
Trigger Timing: Row-level triggers can be set to execute either BEFORE or AFTER the row-level operation.
- BEFORE Trigger: Executes before the row operation is applied.
- AFTER Trigger: Executes after the row operation is applied.
-
Trigger Actions: The actions performed by row-level triggers can include validation checks, logging, or modifying data before or after the changes are applied.
How Row-Level Triggers Work:
-
Trigger Definition: Define the row-level trigger using the CREATE TRIGGER statement. Specify the triggering event (INSERT, UPDATE, or DELETE), timing (BEFORE or AFTER), and the actions to be performed.
-
Trigger Execution: When the specified event occurs on the table, the row-level trigger fires for each row affected by the operation. The trigger can access the old and new values of the row being processed.
53. How can network traffic be monitored with the help of PL/SQL commands?
Network traffic can be monitored using PL/SQL commands and database packet sniffing. Packet sniffing is a method of intercepting and analyzing network packets sent over various networks, including local area and wide-area networks.
With this technique, developers can use PL/SQL packages such as DBMS_NETWORK_PACKET to look at all incoming and outgoing network requests from their program or script in order to detect malicious daily activities or analyze performance issues like slow response times.
54. What is a pipeline function in PL/SQL? How do you create one?
A pipeline function in PL/SQL is a specialized type of table function that returns a set of rows that can be used in a SQL query as if it were a regular table or view. Pipeline functions are particularly useful for integrating custom data processing and transformations directly into SQL queries, enabling the handling of complex data processing tasks.
Here’s a step-by-step guide to creating a pipeline function in PL/SQL:
-
Define a Collection Type: Create a collection type (e.g., TABLE OF) to hold the rows returned by the pipeline function.
-
Create the Pipeline Function: Implement the pipeline function using the PIPELINED keyword and specify the collection type.
-
Use the Function in a SQL Query: Query the pipeline function as if it were a table.
55. What is a cursor variable, and how can it be used in PL/SQL?
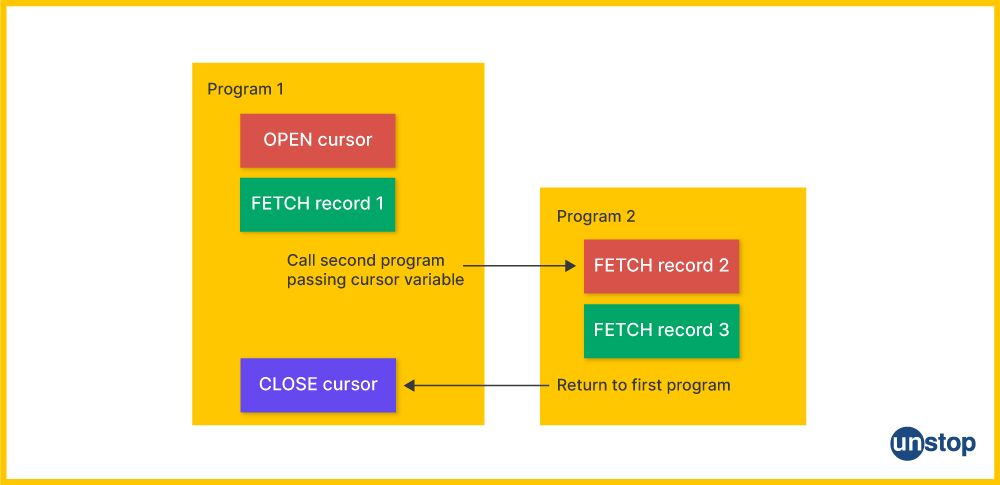
A cursor variable is a pointer or reference to the memory address of an Oracle server-side cursor that enables stored procedures and functions in PL/SQL to access data from relational databases.
It can be used to retrieve rows from one or more database tables by using SQL queries within PL/SQL code. The returned result set is assigned into a record structure that remains accessible for the duration of the program execution.
56. What is the use of package body statements while working on a complex database system with PL/SQL code?
The package body statement in PL/SQL is used to develop complex database systems with procedural logic. It is a collection of related functions and procedures whose code must be defined for the program to run properly. It can also serve as a wrapper around several other elements, like any variables and type definitions it needs.
With this form of encapsulation, developers can better organize their programs into logical groupings based on what they do, making them easier to read while maintaining their performance tuning when executing tasks.
57. What are the different collection types available for exit statements in PL/SQL programming language?
In PL/SQL, collections are data structures that allow you to store multiple values of the same type in a single variable. When dealing with collections, the exit statement is used to exit from loops or conditions. However, the exit statement itself is not directly related to collection types. Instead, it controls the flow of execution in loops.
Here are the different collection types available in PL/SQL:
1. Associative Arrays (Index-by Tables): Associative arrays are collections that allow for the storage of key-value pairs where the keys are unique. The keys can be of any scalar data type, such as numbers or strings. Useful for scenarios where you need to access elements by an index that is not necessarily a sequential number.
DECLARE
TYPE emp_array IS TABLE OF VARCHAR2(100) INDEX BY PLS_INTEGER;
emp_names emp_array;
BEGIN
emp_names(1) := 'John Doe';
emp_names(2) := 'Jane Smith';
FOR i IN emp_names.FIRST .. emp_names.LAST LOOP
DBMS_OUTPUT.PUT_LINE(emp_names(i));
END LOOP;
END;
2. Nested Tables: Nested tables are collections that can store a variable number of elements, similar to arrays. They are defined with a fixed structure and can be used to store data that may grow dynamically. Useful when you need to store and manipulate a list of elements that can grow or shrink in size.
DECLARE
TYPE num_table IS TABLE OF NUMBER;
nums num_table := num_table(1, 2, 3, 4, 5);
BEGIN
FOR i IN 1 .. nums.COUNT LOOP
DBMS_OUTPUT.PUT_LINE(nums(i));
END LOOP;
END;
3. VARRAYs (Variable-Size Arrays): VARRAYs are collections with a fixed maximum size but can contain any number of elements up to that maximum. They are defined with a maximum size constraint. Useful when you need a fixed-size array with a known upper limit.
DECLARE
TYPE num_varray IS VARRAY(5) OF NUMBER;
nums num_varray := num_varray(1, 2, 3, 4, 5);
BEGIN
FOR i IN 1 .. nums.COUNT LOOP
DBMS_OUTPUT.PUT_LINE(nums(i));
END LOOP;
END;
58. How do you implement advanced exception handling and logging mechanisms?
Implementing advanced exception handling and logging mechanisms in PL/SQL involves creating a structured approach to manage error messages and log important events. This approach ensures that exceptions are properly handled, relevant information is captured, and developers can debug and audit the system effectively.
-
Defining Custom Exceptions: Create user-defined exceptions for specific error conditions that are not covered by built-in exceptions.
-
Exception Propagation: Use nested exception blocks to handle predefined exceptions at different levels of the application. If an exception is not handled in the current block, it can propagate to the calling block or the outer block.
-
Using Named Exceptions: Associate ORA- error codes with named exceptions for better readability and management.
-
Logging and Rethrowing Exceptions: Log files the exception details before rethrowing it, ensuring that the information is captured even if the unhandled exception is handled at a higher level.
59. How do you integrate PL/SQL with other programming languages and technologies?
Integrating PL/SQL with other programming languages and technologies allows for the creation of robust, multi-layered applications that leverage the strengths of each component. Here are several ways to achieve integration:
1. Database APIs
Most programming languages provide APIs to interact with Oracle databases, where PL/SQL is used. These APIs allow you to execute PL/SQL code, call stored procedures and functions, and handle results.
- JDBC (Java Database Connectivity): Java applications can use JDBC to connect to Oracle databases, execute PL/SQL blocks, and handle the results.
- ODBC (Open Database Connectivity): Allows languages like C++ and Python to interact with Oracle databases.
- OCI (Oracle Call Interface): Provides a low-level API for C and C++ to execute SQL and PL/SQL in Oracle databases.
- OLE DB and ADO.NET: Used by .NET applications to connect to Oracle databases and run PL/SQL.
Example (Java using JDBC):
Connection conn = DriverManager.getConnection(url, username, password);
CallableStatement stmt = conn.prepareCall("{call my_procedure(?)}");
stmt.setInt(1, 123);
stmt.execute();
stmt.close();
conn.close();
2. Web Technologies
- Oracle Application Express (APEX): A web-based application development framework integrated with the Oracle database. It uses PL/SQL for business logic and data manipulation.
- Oracle REST Data Services (ORDS): Enables you to expose PL/SQL procedures and functions as RESTful web services, allowing other applications to interact with Oracle databases over HTTP/HTTPS.
Example (Using ORDS to call a PL/SQL procedure):
CREATE OR REPLACE PROCEDURE my_procedure AS
BEGIN
-- Procedure logic
END;
Exposed via ORDS, this can be called with a simple HTTP request.
3. Middleware and Integration Frameworks
- Oracle Fusion Middleware: Includes products like Oracle WebLogic Server, Oracle SOA Suite, and Oracle Service Bus, which can use PL/SQL for backend processing and data access.
- Enterprise Service Bus (ESB): Facilitates communication between different systems, allowing for the integration of PL/SQL with various enterprise applications.
4. Message Queues and Event-Driven Systems
PL/SQL can interact with messaging systems like Oracle Advanced Queuing (AQ) and JMS (Java Message Service). This is useful for implementing asynchronous communication between systems.
Example (PL/SQL enqueue operation):
DECLARE
msg SYS.AQ$_JMS_TEXT_MESSAGE;
BEGIN
msg := SYS.AQ$_JMS_TEXT_MESSAGE.construct;
msg.set_text('Hello, World!');
DBMS_AQ.ENQUEUE(queue_name => 'my_queue', enqueue_options => my_opts, individual message_properties => msg_props, payload => msg, msgid => msgid_out);
END;
60. In what situations will loop statements be necessary for developing complex logic in a PL/SQL program?
LOOP statements in PL/SQL are essential for implementing repetitive operations, iterating over collections or datasets, and managing complex business logic. Here are some common situations where LOOP statements are necessary:
- Iterating Over Result Sets: When working with explicit cursors or collections (like PL/SQL tables, associative arrays, or nested tables), LOOP statements are used to process each row or element individually.
- Performing Batch Processing: In scenarios where operations need to be performed on multiple records in batches, LOOP statements are used to fetch and process records in chunks.
- Complex Calculations and Aggregations: When performing complex calculations that require iterative logic, such as summing totals, calculating averages, or performing custom aggregations, LOOP statements are useful.
- Implementing Business Rules and Validation: LOOP statements are useful for iterating through data to enforce complex business rules, validate data integrity, or apply conditional logic.
- Generating Reports or Summarized Data: LOOP statements can be used to iterate over data and generate reports or summarized outputs, often involving aggregations and complex formatting.
- Dynamic SQL Execution: When building and executing dynamic SQL statements based on varying conditions, LOOP statements can be used to construct and execute SQL strings iteratively.
61. How do you handle migration and versioning of PL/SQL code?
Handling migration and versioning of PL/SQL code is crucial for maintaining the integrity and functionality of database systems, especially in development and production environments. Proper management ensures that changes are correctly implemented and that different versions of source code can be tracked and reverted if necessary. Here’s a guide on how to handle migration and versioning of PL/SQL code:
- Use version control systems to track changes.
- Organize code in a structured repository.
- Employ migration tools for automated processes.
- Define change management procedures for making and deploying changes.
- Version your code using tagging or numbering schemes.
- Create and manage change scripts for database updates.
- Implement deployment strategies for reliable and repeatable processes.
- Test and validate changes before deployment.
- Prepare for rollback with backup plans.
- Document changes thoroughly for clarity and tracking.
62. How does one create objects at the schema level using PL/SQL code?
Creating objects at the schema level using PL/SQL involves using PL/SQL blocks to define and manage various database objects such as tables, indexes, views, sequences, and more. Here’s how you can create different types of schema objects using PL/SQL code complexity:
1. Creating Tables: To create a temporary table using PL/SQL, you use dynamic SQL within an anonymous block or stored procedure.
BEGIN
EXECUTE IMMEDIATE 'CREATE TABLE employees (
employee_id NUMBER PRIMARY KEY,
first_name VARCHAR2(50),
last_name VARCHAR2(50),
hire_date DATE
)';
END;
/
2. Creating Indexes: Indexes can be created similarly using dynamic SQL.
BEGIN
EXECUTE IMMEDIATE 'CREATE INDEX idx_emp_lastname ON employees (last_name)';
END;
/
3. Creating Views: To create a view, use dynamic SQL in a PL/SQL block.
BEGIN
EXECUTE IMMEDIATE 'CREATE VIEW emp_view AS
SELECT employee_id, first_name, last_name
FROM employee Table
WHERE hire_date > SYSDATE - INTERVAL ''1 YEAR''';
END;
/
4. Creating Sequences: Sequelize is often created to generate unique values for primary keys.
BEGIN
EXECUTE IMMEDIATE 'CREATE SEQUENCE emp_seq
START WITH 1
INCREMENT BY 1
NOCACHE
NOCYCLE';
END;
/
5. Creating Procedures and Functions: To create a stored procedure statement or function, you can use PL/SQL blocks with the CREATE PROCEDURE or CREATE FUNCTION statement.
BEGIN
EXECUTE IMMEDIATE 'CREATE OR REPLACE PROCEDURE greet_employee (p_emp_id IN NUMBER) AS
v_name VARCHAR2(100);
BEGIN
SELECT first_name INTO v_name
FROM employees
WHERE employee_id = p_emp_id;
DBMS_OUTPUT.PUT_LINE(''Hello, '' || v_name || ''!'');
END;';
END;
/
63. Describe the control structures used in PL/SQL programming language.
PL/SQL control structure helps to design a program in an orderly manner. It provides the flexibility and functionality of large programs by allowing blocks of code to execute conditionally or repeatedly based on user input, conditions, etc. All programming languages have their implementation of these structures; in PL/SQL, there are three main categories: statements, loops, and branches.
- Statements: A statement is used when no further decision-making needs to be done – it simply allows you to perform one action at a time (e.g., assign values).
- Loops: Loops allow you to set up instructions that will repeat until some criteria are reached - for example, iterate through records returned from SQL query or looping over data defined within your block itself (using ‘for’ loops).
- Branches: Branches let you specify different sets of instructions depending on certain factors – such as variables being equal/not-equal - if the result is true, then branch down this route; else, take another path.
64. Explain how to construct a logical table using SQL queries and statements in a database environment.
A logical table in a database environment is an organized set of data stored according to a predetermined structure that allows easy retrieval of information from relational databases. To construct a logical table using SQL queries and statements, one needs to create a table statement consisting of three sub-parts - column definitions (name, type), constraints (primary key or foreign key), and storage output parameters.
- The first step involves defining the columns with "data types" such as INTEGER(number without decimal points); VARCHAR2 for character strings;
- DATE for date fields etc., followed by 'constraints' defining rules about inserting values into specific columns like NOT NULL for mandatory inserts or UNIQUE KEY when records need not repeat themselves in more than one row/column pairs.
- The last part specifies how much memory space will be allocated while saving data and other details related to Indexes on particular tables in memory, allowing quick search operations over them.
- Once all these elements are supplied properly using CREATE TABLE command, this should successfully form your desired Logical Table BLOCK structure within any given DBMS system!
65. What are the different types of joins in Oracle PL/SQL?
There are four different types of joins in Oracle PL/SQL:
- Oracle Simple JOIN: This type of join is also known as an inner or equi-join. It displays all the records from both fields of tables where there is a match with the specified columns in each table.
- Oracle LEFT JOIN: The left join returns all rows that exist in the left side table and optionally any matching rows from the right side table if they exist. If there are no matches, NULL values will be returned for the right column’s results.
- Oracle RIGHT JOIN: The Right outer join performs similarly to the Left Outer join but reverses roles between the two tables. It returns information from the second table (right) and matching info from the first one (left). Unmatched entries containing Nulls will be included for the Right Table data fields of tables only, while on the Left side - the usual query output and result set will appear.
- Oracle FULL JOIN: A full outer join combines elements of a left outer join and a right outer join into one statement, thus giving us access to every row existing within either joined relation regardless of whether there was/was not a matched value present when comparing keys across participating relations.
66. Name and explain some implicit cursor attributes associated with cursors in PL/SQL.
The implicit cursor attributes associated with cursors in PL/SQL are:
- %FOUND: This cursor attribute is a Boolean variable that returns true if the last fetch from the cursor was successful and false otherwise. If no rows were found, an internal exception would be raised instead of returning false for this value.
- %NOTFOUND: This cursor attribute is also a Boolean variable that returns true when nothing has been returned by the previous fetch statement or outer query execution but can return NULL when no data operation has occurred yet on that particular context area (i.e., after opening the cursor).
- %ISOPEN: A built-in function that checks whether or not your defined SQL Cursor is open, and if so, it's True; else, False.
- %ROWCOUNT: It keeps track of how many records have been fetched from within its loop to return multiple rows as part of its results set as per user requirement.
- %BULK_ROWCOUNT: This attribute returns the total number of rows processed in a bulk operation, such as when using FORALL or BULK COLLECT operations to insert multiple rows at once into an Oracle table type with PL/SQL code (i.e., "bulk DML").
67. What is the return type of a PL/SQL function? Explain each return type.
The return type of a PL/SQL function can be any valid data type such as NUMBER, VARCHAR2, BOOLEAN, and DATE.
- The NUMBER type holds numeric values such as integers, real numbers, and floating-point numbers.
- The VARCHAR2 data type stores character (or string) values of fixed or variable length up to 4 gigabytes.
- BOOLEAN datatype holds a boolean "true" or "false". It can be represented by 0 for false and 1 for true value.
- DATE types are used to store date and time information in the Oracle Database, which includes the year, month, day, hours, minutes, etc.; each DATE column occupies 7 bytes on disk and has maximum precision up to 9 decimal places.
68. What are some of the list of parameters used to define a cursor inside an anonymous block or stored procedure?
The list of parameters used to define a cursor inside an anonymous block or stored procedure includes:
- CURSOR_NAME: This is the name you assign to the cursor.
- SELECT_STATEMENT: This is the SQL engine query that forms your result set.
- ORDER BY: An optional clause that can be used to sort your data in ascending/descending order based on one or more column values.
- FOR UPDATE [OF column_list]: Specify this update statement option if you want other users (in another session) to be blocked from updating rows included in the resultset while it’s being processed by the current user’s open cursor statement.
- OPEN, CLOSE and FETCH statements are used to fetch records from the database into program table variables.
- NO_PARSE: Specifying this clause will force the SQL engine to parse your SQL query once instead of parsing it every time when fetched.
- USING Clause: This is an optional clause used to pass values from SQL program unit variables in a PL/SQL block while opening the cursor or during fetching records.
69. How do you ensure that initial values are correctly assigned when executing a PL/SQL program?
Ensuring that initial values are correctly assigned when executing a PL/SQL program involves several steps, including proper variable declaration, initialization, and verification. Here’s a straightforward approach:
- Declare Variables with Initial Values: When declaring variables in PL/SQL, you can assign initial values directly. This ensures that the variables start with known values when the program runs.
DECLARE
v_pls_integer PLS_INTEGER := 100;
v_binary_integer BINARY_INTEGER := 200;
v_number NUMBER(10) := 300;
v_simple_integer SIMPLE_INTEGER := 400;
BEGIN
DBMS_OUTPUT.PUT_LINE('PLS_INTEGER: ' || v_pls_integer);
END;
- Use Default Values in Declarations: For parameters in procedures or functions, you can set default values to ensure they are initialized if not provided by the caller.
CREATE OR REPLACE PROCEDURE example_procedure (
p_value PLS_INTEGER DEFAULT 10
) IS
BEGIN
DBMS_OUTPUT.PUT_LINE('Parameter value: ' || p_value);
END;
- Explicit Initialization in the BEGIN Block: If you prefer, you can also initialize variables within the BEGIN block. This method allows for more complex initialization logic if needed.
DECLARE
v_pls_integer PLS_INTEGER;
BEGIN
v_pls_integer := 100;
DBMS_OUTPUT.PUT_LINE('PLS_INTEGER: ' || v_pls_integer);
END;
- Verify Initialization with DBMS_OUTPUT: Use DBMS_OUTPUT.PUT_LINE to print the values of variables at various points in your program. This helps to verify that the variables are correctly initialized and hold the expected values.
DECLARE
v_pls_integer PLS_INTEGER := 100;
BEGIN
DBMS_OUTPUT.PUT_LINE('Initial PLS_INTEGER: ' || v_pls_integer);
END;
70. Write a PL/SQL program to convert each digit of a given number into its corresponding word format.
Here's a PL/SQL program that converts each digit of a given number into its corresponding word format:
DECLARE
input_number VARCHAR2(100) := '12345'; -- Replace with the number you want to convert
digit CHAR(1);
word_format VARCHAR2(4000) := '';
BEGIN
-- Loop through each character in the input number
FOR i IN 1..LENGTH(input_number) LOOP
digit := SUBSTR(input_number, i, 1);
-- Convert each digit to its corresponding word
CASE digit
WHEN '0' THEN
word_format := word_format || 'Zero ';
WHEN '1' THEN
word_format := word_format || 'One ';
WHEN '2' THEN
word_format := word_format || 'Two ';
WHEN '3' THEN
word_format := word_format || 'Three ';
WHEN '4' THEN
word_format := word_format || 'Four ';
WHEN '5' THEN
word_format := word_format || 'Five ';
WHEN '6' THEN
word_format := word_format || 'Six ';
WHEN '7' THEN
word_format := word_format || 'Seven ';
WHEN '8' THEN
word_format := word_format || 'Eight ';
WHEN '9' THEN
word_format := word_format || 'Nine ';
ELSE
-- Handle invalid characters
word_format := word_format || 'Invalid ';
END CASE;
END LOOP;
-- Output the result
DBMS_OUTPUT.PUT_LINE('Number in word format: ' || TRIM(word_format));
END;
/
REVDTEFSRQppbnB1dF9udW1iZXIgVkFSQ0hBUjIoMTAwKSA6PSAnMTIzNDUnOyAtLSBSZXBsYWNlIHdpdGggdGhlIG51bWJlciB5b3Ugd2FudCB0byBjb252ZXJ0CmRpZ2l0IENIQVIoMSk7CndvcmRfZm9ybWF0IFZBUkNIQVIyKDQwMDApIDo9ICcnOwpCRUdJTgotLSBMb29wIHRocm91Z2ggZWFjaCBjaGFyYWN0ZXIgaW4gdGhlIGlucHV0IG51bWJlcgpGT1IgaSBJTiAxLi5MRU5HVEgoaW5wdXRfbnVtYmVyKSBMT09QCmRpZ2l0IDo9IFNVQlNUUihpbnB1dF9udW1iZXIsIGksIDEpOwoKLS0gQ29udmVydCBlYWNoIGRpZ2l0IHRvIGl0cyBjb3JyZXNwb25kaW5nIHdvcmQKQ0FTRSBkaWdpdApXSEVOICcwJyBUSEVOCndvcmRfZm9ybWF0IDo9IHdvcmRfZm9ybWF0IHx8ICdaZXJvICc7CldIRU4gJzEnIFRIRU4Kd29yZF9mb3JtYXQgOj0gd29yZF9mb3JtYXQgfHwgJ09uZSAnOwpXSEVOICcyJyBUSEVOCndvcmRfZm9ybWF0IDo9IHdvcmRfZm9ybWF0IHx8ICdUd28gJzsKV0hFTiAnMycgVEhFTgp3b3JkX2Zvcm1hdCA6PSB3b3JkX2Zvcm1hdCB8fCAnVGhyZWUgJzsKV0hFTiAnNCcgVEhFTgp3b3JkX2Zvcm1hdCA6PSB3b3JkX2Zvcm1hdCB8fCAnRm91ciAnOwpXSEVOICc1JyBUSEVOCndvcmRfZm9ybWF0IDo9IHdvcmRfZm9ybWF0IHx8ICdGaXZlICc7CldIRU4gJzYnIFRIRU4Kd29yZF9mb3JtYXQgOj0gd29yZF9mb3JtYXQgfHwgJ1NpeCAnOwpXSEVOICc3JyBUSEVOCndvcmRfZm9ybWF0IDo9IHdvcmRfZm9ybWF0IHx8ICdTZXZlbiAnOwpXSEVOICc4JyBUSEVOCndvcmRfZm9ybWF0IDo9IHdvcmRfZm9ybWF0IHx8ICdFaWdodCAnOwpXSEVOICc5JyBUSEVOCndvcmRfZm9ybWF0IDo9IHdvcmRfZm9ybWF0IHx8ICdOaW5lICc7CkVMU0UKLS0gSGFuZGxlIGludmFsaWQgY2hhcmFjdGVycwp3b3JkX2Zvcm1hdCA6PSB3b3JkX2Zvcm1hdCB8fCAnSW52YWxpZCAnOwpFTkQgQ0FTRTsKRU5EIExPT1A7CgotLSBPdXRwdXQgdGhlIHJlc3VsdApEQk1TX09VVFBVVC5QVVRfTElORSgnTnVtYmVyIGluIHdvcmQgZm9ybWF0OiAnIHx8IFRSSU0od29yZF9mb3JtYXQpKTsKRU5EOwov
71. Write a PL/SQL code to count the number of Sundays between the two inputted dates.
Here's a PL/SQL code that counts the number of Sundays between two inputted dates:
DECLARE
start_date DATE := TO_DATE('2024-01-01', 'YYYY-MM-DD'); -- Replace with your start date
end_date DATE := TO_DATE('2024-12-31', 'YYYY-MM-DD'); -- Replace with your end date
num_sundays NUMBER := 0;
BEGIN
FOR d IN start_date..end_date LOOP
IF TO_CHAR(d, 'DY', 'NLS_DATE_LANGUAGE = ENGLISH') = 'SUN' THEN
num_sundays := num_sundays + 1;
END IF;
END LOOP;
DBMS_OUTPUT.PUT_LINE('Number of Sundays: ' || num_sundays);
END;
/
REVDTEFSRQpzdGFydF9kYXRlIERBVEUgOj0gVE9fREFURSgnMjAyNC0wMS0wMScsICdZWVlZLU1NLUREJyk7IC0tIFJlcGxhY2Ugd2l0aCB5b3VyIHN0YXJ0IGRhdGUKZW5kX2RhdGUgREFURSA6PSBUT19EQVRFKCcyMDI0LTEyLTMxJywgJ1lZWVktTU0tREQnKTsgLS0gUmVwbGFjZSB3aXRoIHlvdXIgZW5kIGRhdGUKbnVtX3N1bmRheXMgTlVNQkVSIDo9IDA7CkJFR0lOCkZPUiBkIElOIHN0YXJ0X2RhdGUuLmVuZF9kYXRlIExPT1AKSUYgVE9fQ0hBUihkLCAnRFknLCAnTkxTX0RBVEVfTEFOR1VBR0UgPSBFTkdMSVNIJykgPSAnU1VOJyBUSEVOCm51bV9zdW5kYXlzIDo9IG51bV9zdW5kYXlzICsgMTsKRU5EIElGOwpFTkQgTE9PUDsKCkRCTVNfT1VUUFVULlBVVF9MSU5FKCdOdW1iZXIgb2YgU3VuZGF5czogJyB8fCBudW1fc3VuZGF5cyk7CkVORDsKL8Kg
Conclusion
In this article, we have covered some of the most crucial PL SQL interview questions for experienced as well as freshers, which will help you get through even the most difficult of interviews. These PL SQL interview questions will cover the most crucial aspects of PL/SQL and will undoubtedly assist you in acing interviews. Here are some additional resources that can help you brush up on your SQL knowledge:
- Difference Between Super Key And Candidate Key in SQL Explained
- Difference Between DELETE and TRUNCATE Command In SQL
- Difference between CHAR and VARCHAR: String Data Types in SQL Server
You may also want to read:
Login to continue reading
And access exclusive content, personalized recommendations, and career-boosting opportunities.
Don't have an account? Sign up
Never miss an
Update

Featured Opportunities
Top-Rated Practice by Students





Subscribe
to our newsletter
Blogs you need to hog!

How To Write Finance Cover Letter For Morgan Stanley (+Free Sample!)
Unstop

55+ Data Structure Interview Questions For 2026 (Detailed Answers)
Muskaan Mishra

How To Negotiate Salary With HR: Tips And Insider Advice
Srishti Magan

80+ TCS NQT Interview Questions & Answers (2026) You Must Prepare
Urvashi Singhal
Comments
Add comment