
Asian Paints Alchemy 2026
HackWithInfy 2025: Preparation Resources
- Infosys Interview Questions: Key Points
- Infosys Interview Questions: Technical Round
- Infosys Interview Questions: HR Round
- Recruitment Profiles for Infosys interview
- Eligibility Criteria for Infosys Technical Interview
- Tips to Answer Infosys Interview Questions
- Roadmap To DSA Mastery
- Your DSA Cheat Sheet: Topics You Must Master
- Practice & Interview Prep: Your Road to DSA Mastery
- Interview Prep Resoruces: Master Every Question Like a Pro
- What Is Competitive Programming?
- Benefits Of Competitive Programming
- Competitive Programming Questions
- Basic Operating System Questions
- Intermediate Operating System Questions
- Advanced Operating System Questions
- Conclusion
- Test Your Skills: Quiz Time
- What Is A Computer Network?
- Advantages And Disadvantages Of Computer Network
- Advantages Of Computer Network
- Disadvantages Of Computer Networks
- Applications Of Computer Network
- Best Books For Computer Network
- Frequently Asked Questions (FAQs)
- What is a Gateway in Computer Networks?
- Functions of Gateway in Computer Networks
- Types of Gateways
- Diagram of Gateway in Computer Networks
- Advantages and Disadvantages of Gateway in Computer Networks
- Use Cases of Gateways
- Conclusion
- Frequently Asked Questions
- What Is Flow Control In Computer Networks?
- Stop-and-Wait Method Of Flow Control In Computer Networks
- Sliding Window Method Of Flow Control In Computer Networks
- Purpose of Flow Control In Communication Network
- Conclusion
- Routing Algorithms In Computer Networks
- Classification Of Routing Algorithms
- Adaptive Vs. Non-Adaptive Routing Algorithms
- Static & Dynamic Routing Protocols
- Distance Vector Vs. Link State Routing
- Hybrid Routing Algorithms
- Role Of Routing In Internet Functionality
- Metrics Used In Routing Algorithm Evaluation
- Evolution Of Routing & Its Impact on Networking
- Frequently Asked Questions (FAQs)
- OOPs INTERVIEW QUESTIONS
51 Competitive Programming Questions (With Solutions) - Do NOT Skip These!
Here is an in-depth guide to competitive coding questions with solutions that are a must-read for anyone preparing for an interview or competitive programming challenges.

A competitive programming challenge refers to a competition or challenge where participants create computer programs for complex coding issues, in the specified time. Two main parameters used for determining the winners of the competition are analyzing their program's effectiveness and the time taken to create those programs.
For many tech companies and product-based companies, competitive programming exams or programming job interviews are the go-to choices for finding desirable candidates. In this article, you will find a comprehensive guide to competitive coding questions with solutions that you can leverage for both, competitive programming challenges and your professional growth. This guide includes competitive programming questions and competitive coding questions with solutions.
What Is Competitive Programming?
Competitive programming refers to a type of programming competition in which participants solve algorithmic problems under strict time constraints. It involves solving complex problems (with higher difficulty levels) efficiently and accurately using programming skills and algorithmic knowledge.
In competitive programming, participants typically compete individually or in teams, trying to solve a set of programming problems within a given time frame. The problems are usually well-defined and require designing and implementing algorithms to solve them. These problems often require a deep understanding of data structures, algorithms, and problem-solving techniques.
Competitive programming contests are held at various levels, ranging from local contests organized by universities or coding clubs to international competitions like the International Olympiad in Informatics (IOI), International Collegiate Programming Contest (ICPC), and Google Code Jam. These competitions assess participants' ability to think critically, devise efficient algorithms, and write high-quality code within the given constraints.
Competitive programming not only challenges programmers to solve complex problems but also emphasizes speed and efficiency. It helps in honing algorithmic thinking skills, improving problem-solving abilities, and enhancing coding techniques. Additionally, competitive programming can serve as a platform for learning and sharing knowledge with other participants, fostering a competitive yet collaborative programming community.
Benefits Of Competitive Programming
Competitive programming offers several benefits to participants. Here's a look at the skills and areas that a participant can improve by participating in competitive programming:
-
Problem-solving skills: Competitive programming enhances problem-solving abilities by exposing participants to a wide range of complex algorithmic problems. It trains them to think critically, break down problems into smaller components, and devise efficient solutions.
-
Algorithmic knowledge: Competitive programming requires a solid understanding of various data structures, algorithms, and problem-solving techniques. Participants gain exposure to different algorithms and learn when to apply them effectively, thus deepening their algorithmic knowledge.
-
Efficiency and optimization: The time constraints in competitive programming competitions push participants to optimize their code and algorithms for faster execution. This helps improve their programming efficiency and teaches them to write optimized and scalable solutions.
-
Coding skills: Regular participation in competitive programming contests improves coding skills. Participants learn to write clean, concise, and maintainable code under pressure. They also gain experience in working with different programming languages and become familiar with language-specific features and libraries.
-
Teamwork and collaboration: Some competitive programming competitions involve team participation, fostering teamwork and collaboration. Working together on complex problems encourages participants to communicate effectively, leverage each other's strengths, and collectively develop solutions.
-
Exposure to real-world scenarios: Competitive programming problems often simulate real-world scenarios, such as optimization problems or graph algorithms. By solving such problems, participants gain practical insights into applying programming concepts to real-life situations.
-
Competitive spirit and motivation: The competitive nature of these contests encourages participants to strive for excellence and push their limits. It also motivates participants to continuously improve their programming skills, learn new concepts, and stay updated with the latest algorithms and techniques.
-
Networking and community: Competitive programming provides opportunities to interact with like-minded individuals, both online and offline. Participants can join coding communities, discuss problem-solving approaches, and learn from experienced programmers. This networking can lead to collaborations, mentorships, and even career opportunities in the field of programming.
Overall, competitive programming serves as a platform for continuous learning, skill development, gaining experience in coding, and fostering growth in the field of programming.
Competitive Programming Questions
Here is a list of common competitive coding questions with solutions that can improve your knowledge and help you in competitions and programming interviews:
Q1. Can you explain a basic algorithm?
A basic algorithm is a step-by-step procedure or a set of instructions used to solve a specific problem or accomplish a particular task. It provides a clear and systematic approach to problem-solving. Algorithms can be implemented in various programming languages to perform specific computations or operations.
Here are some key components and characteristics of a basic algorithm:
-
Input: Algorithms typically require some form of input data to process. The input can be provided by the user, read from a file, obtained from sensors, or generated programmatically.
-
Output: Algorithms produce an output or result based on the given input. The output can be a computed value, a modified data structure, a message displayed to the user, or any other relevant outcome.
-
Sequence of steps: An algorithm consists of a sequence of well-defined steps or actions that need to be executed in a specific order. Each step represents an operation or decision to be performed.
-
Control flow: Algorithms often include control flow statements, such as conditional statements (if-else, switch) and loops (for, while), to control the execution path based on certain conditions or to iterate over a set of instructions.
-
Termination condition: Algorithms need to have a termination condition to determine when to stop the execution. This condition ensures that the algorithm doesn't run indefinitely and produces a result within a reasonable time frame.
-
Efficiency: Efficiency refers to how well an algorithm performs in terms of time and space complexity. An efficient algorithm executes the desired task with optimal use of computational resources and minimizes the required time and memory.
-
Correctness: An algorithm should produce the correct output for all valid inputs. It needs to be logically sound and accurately solve the problem it aims to address.
When designing a basic algorithm, it's essential to consider the problem requirements, constraints, and available resources. By breaking down a problem into smaller, manageable steps and designing an algorithm to solve each step, programmers can develop efficient and reliable solutions.
Q2. What do you understand by selection sort?
Selection sort is a simple sorting algorithm that works by repeatedly finding the minimum element from an unsorted portion of the list and swapping it with the element at the beginning of the unsorted portion. It gradually builds up a sorted portion of the list until the entire list is sorted.
Here's how the selection sort algorithm works:
- Start with an unsorted list of elements.
- Find the minimum element from the unsorted portion of the list.
- Swap the minimum element with the first element of the unsorted portion.
- Move the boundary of the sorted portion one element ahead.
- Repeat steps 2-4 for the remaining unsorted portion of the list until the entire list is sorted.
The selection sort algorithm divides the list into two portions: the sorted portion at the beginning and the unsorted portion at the end. In each iteration, it finds the smallest element from the unsorted portion and swaps it with the first element of the unsorted portion, thereby expanding the sorted portion.
The time complexity of selection sort is O(n^2), where n is the number of elements in the list. This makes it relatively inefficient for large lists. However, selection sort has the advantage of having a simple implementation and requires only a small number of swaps, making it useful for small lists or as a step within other sorting algorithms.
It's worth noting that selection sort is not a stable sorting algorithm, meaning that the relative order of equal elements may change during the sorting process.
Q3. Could you please explain how the binary search algorithm works?
The binary search algorithm is an efficient search algorithm that works on sorted arrays or lists. It follows a divide-and-conquer approach to quickly find the target element by repeatedly dividing the search space in half.
Here's how the binary search algorithm works:
- Start with a sorted array or list.
- Set the lower bound (start) and upper bound (end) of the search space. Initially, start = 0 and end = length of the array - 1.
- Calculate the middle index as the average of the start and end indices: middle = (start + end) / 2.
- Compare the target value with the middle element of the array:
- If the target is equal to the middle element, the search is successful, and the index of the target is returned.
- If the target is less than the middle element, update the end index to middle - 1 and go to step 3.
- If the target is greater than the middle element, update the start index to middle + 1 and go to step 3.
- Repeat steps 3-4 until the target element is found or the search space is exhausted (start becomes greater than the end).
- If the target is not found, return a "not found" indication.
The key idea behind binary search is to halve the search space at each step by comparing the target element with the middle element of the remaining subarray. Since the array is sorted, if the target is less than the middle element, it can only be present in the left half of the subarray. Similarly, if the target is greater, it can only be in the right half. By repeatedly dividing the search space, binary search achieves a logarithmic time complexity.
The time complexity of binary search is O(log n), where n is the number of elements in the array. This makes it very efficient for large arrays compared to linear search algorithms. Binary search is commonly implemented using a loop or recursive function.
Q4. What do you know about skip lists?
A skip list is a data structure that allows for efficient search, insertion, and deletion operations with an average time complexity of O(log n), where n is the number of elements in the list. It is an alternative to balanced binary search trees, providing similar performance characteristics while being simpler to implement.
A skip list consists of multiple layers, with each layer being a linked list. The bottom layer contains all the elements in sorted order. Each higher layer is formed by skipping some elements from the lower layer, connecting only certain nodes with additional pointers.
The key idea behind a skip list is to create "express lanes" or shortcuts that allow for faster traversal. By including additional pointers, a skip list reduces the number of comparisons needed during search operations, resulting in improved efficiency.
Here are the main operations and characteristics of a skip list:
-
Search: Searching in a skip list is similar to searching in a linked list. Starting from the top layer, the search moves right until finding a larger element or reaching the end of the layer. If the target element is found, the search is successful. Otherwise, the search drops down to the next layer and repeats the process until reaching the bottom layer.
-
Insertion: To insert an element into a skip list, the element is first inserted into the bottom layer in its proper sorted position. Then, with a predetermined probability, the element is also inserted into higher layers, using the "coin flip" technique. This probability typically ranges from 0.25 to 0.5.
-
Deletion: Deletion in a skip list involves removing the element from each layer in which it appears. However, to maintain the structure and integrity of the skip list, additional pointers are adjusted to bridge the gaps left by the deleted element.
-
Height and space complexity: The height of a skip list is determined by the number of elements and the coin flip probability during insertion. The expected height of a skip list with n elements is O(log n). The space complexity of a skip list is O(n), as each element occupies space in multiple layers.
Skip lists provide an efficient compromise between simplicity and performance, making them suitable for various applications where efficient search and insertion operations are required. They are commonly used in situations where balanced binary search trees might be overly complex or unnecessary.
Q5. How to determine whether or not the linked list contains a loop?
To determine whether a linked list contains a loop, you can use the "Floyd's cycle-finding algorithm" or the "hare and tortoise algorithm." Here's how it works:
- Start with two pointers, often referred to as the "hare" and the "tortoise," both initially pointing to the head of the linked list.
- Move the tortoise pointer one step at a time, and the hare pointer two steps at a time.
- Repeat the movement of pointers until one of the following conditions is met: a. If the hare pointer reaches the end of the list (i.e., it becomes null), the list does not contain a loop. b. If the hare and tortoise pointers meet or become equal at some point, a loop is detected.
- If a loop is detected, you can optionally find the starting point of the loop by resetting the hare pointer to the head of the list and moving both pointers one step at a time until they meet again. The meeting point will be the start of the loop.
The intuition behind this algorithm is that if there is a loop in the linked list, the faster hare pointer will eventually "catch up" to the slower tortoise pointer within the loop.
Here's an example implementation in Python:
def has_loop(head):
tortoise = head
hare = headwhile hare and hare.next:
tortoise = tortoise.next
hare = hare.next.nextif tortoise == hare:
return Truereturn False
This algorithm has a time complexity of O(n), where n is the number of nodes in the linked list. It only requires constant space for the two pointers, making it an efficient solution for detecting loops in linked lists.
Q6. Could you explain the function of the encryption algorithm?
The function of an encryption algorithm is to transform plaintext (original data) into ciphertext (encrypted data) in order to protect the confidentiality and integrity of the information. Encryption algorithms use mathematical techniques to convert data into a format that is not easily readable or understandable by unauthorized parties.
The primary goals of encryption are:
-
Confidentiality: Encryption ensures that only authorized parties can access and understand the encrypted data. By converting the plaintext into ciphertext, encryption obscures the original information, making it difficult for unauthorized individuals to decipher the content.
-
Integrity: Encryption algorithms can also provide integrity by ensuring that the encrypted data remains unaltered during transmission or storage. By using cryptographic techniques, any tampering or modification of the ciphertext will result in a detectable change when decrypting the data.
Encryption algorithms employ two main components:
-
Encryption Key: An encryption key is a piece of information used by the algorithm to perform the encryption process. It is typically an original string of bits or characters. The specific encryption algorithm and the length and complexity of the key used can significantly impact the strength and security of the encryption.
-
Encryption Algorithm: The encryption algorithm is a set of mathematical operations that transform the plaintext into ciphertext using the encryption key. There are various types of encryption algorithms, including symmetric key encryption (where the same key is used for both encryption and decryption) and asymmetric key encryption (where different keys are used for encryption and decryption). Common encryption algorithms include AES (Advanced Encryption Standard), RSA (Rivest-Shamir-Adleman), and DES (Data Encryption Standard).
When encrypted data needs to be accessed or transmitted, authorized parties can use the corresponding decryption algorithm and the correct decryption key to revert the ciphertext to its original plaintext form.
Encryption algorithms play a crucial role in securing sensitive information, such as personal data, financial transactions, and confidential communications. They provide a means to protect data from unauthorized access and ensure the privacy and integrity of the information.
Q7. What is meant by the term merge sort?
Merge sort is a popular sorting algorithm that follows the divide-and-conquer approach to sort elements in a list or array. It divides the input into smaller subproblems, sorts them individually, and then merges the sorted subproblems to produce a final sorted result.
Here's how the merge sort algorithm works:
-
Divide: The algorithm recursively divides the input array into two halves until each subarray contains only one element or is empty. This division process is repeated until the base case is reached.
-
Conquer: Once the subarrays are sufficiently small (individual elements or empty), the algorithm considers them sorted by default. In this phase, the algorithm starts merging the smaller subarrays back together in a sorted manner.
-
Merge: The merge step compares the elements of the subarrays and merges them into a single sorted subarray. It starts by comparing the first element of each subarray and selecting the smaller element to be placed in the merged array. The process continues until all elements are merged into a single sorted array.
-
Recombine: The above steps are repeated for each level of the division until the entire array is merged and sorted.
The key operation in merge sort is the merging step, where the subarrays are combined to produce a sorted output. This merging process takes advantage of the fact that the individual subarrays are already sorted.
Merge sort has a time complexity of O(n log n) in all cases, where n is the number of elements in the input array. This makes it one of the most efficient comparison-based sorting algorithms, especially for large lists. However, it does require additional space for the merging process, which contributes to a space complexity of O(n).
Merge sort is a stable sorting algorithm, meaning that it preserves the relative order of equal elements during the sorting process. It is widely used in practice due to its efficiency, stability, and ability to handle large data sets.
Q8. What is quicksort?
The quicksort algorithm is considered to be one of the more complicated ones. When dividing the array into two subarrays, it implements a divide-and-conquer approach to accomplish this task. We begin by selecting an element with the name pivot. Then we relocate it to the index that is appropriate for it. Finally, we rearrange the array of strings by moving every element that is inferior, to pivot to its left and moving all of the elements that are superior, to pivot to its right.
After that, we use a recursive sorting method to order these subarrays until the complete element of arrays is in alphabetical order. The quicksort algorithm's effectiveness is strongly dependent on the chosen pivot element.
Here's how the quicksort algorithm works:
-
Partitioning: The algorithm selects a pivot element from the array. The pivot element is used as a reference to divide the array into two partitions: elements smaller than the pivot and elements greater than the pivot. The exact partitioning process varies based on the specific implementation, but a common approach is the Lomuto partition scheme or the Hoare partition scheme.
-
Recursive Sort: Once the partitioning is done, the algorithm recursively applies the same process to the two sub-arrays created from the partitioning step. This means applying the partitioning process to the sub-array of elements smaller than the pivot and the sub-array of elements greater than the pivot.
-
Conquer: As the recursion progresses, the sub-arrays become smaller until they contain zero or one element, which are considered sorted by default.
-
Combine: No explicit combine step is required in quicksort, as the sorting is performed in-place by rearranging the elements within the array during the partitioning process.
The choice of the pivot element is crucial to the efficiency of quicksort. The ideal scenario is to select a pivot that divides the array into two nearly equal-sized partitions. This helps ensure balanced recursion and provides the best-case time complexity of O(n log n).
Q9. What is meant by the term 'counting sort'?
Counting sort works by recording the number of times each distinct element occurs in the input array into an auxiliary array whose size, k, is equivalent in length to the range of such input values. This information is then used to perform the sorting operation.
The formula k = (maximum element - minimum element plus 1) is valid according to the rules of mathematics. After then, this array is used to place the elements immediately into their appropriate positions where they should be.
Counting sort has a time complexity of O(n+k), where n is the number of elements in the input array and k is the range of values. It is a linear time sorting algorithm and performs particularly well when the range of values is small compared to the number of elements.
The counting sort is stable, meaning it maintains the relative order of equal elements in the input array. However, it is not suitable for sorting data with large ranges or non-integer values.
Counting sort finds applications in scenarios where the input elements are integers within a specific range, such as sorting grades, counting occurrences of elements, or sorting elements with limited values. Its simplicity and linear time complexity make it an efficient choice in these cases.
Q10. What is bucket sort?
Bucket sort is a sorting algorithm that works by dividing the input elements into different "buckets" based on their values and then sorting each bucket individually, either using another sorting algorithm or recursively applying bucket sort. It is primarily used for sorting elements that are uniformly distributed over a range.
Here's how the bucket sort algorithm works:
-
Determine the range: Find the minimum and maximum values in the input array to determine the range of values.
-
Create buckets: Divide the range of values into a fixed number of equally-sized buckets. The number of buckets depends on the specific implementation and the range of values. Each bucket represents a subrange of values.
-
Distribute elements: Iterate through the input array and place each element into its corresponding bucket based on its value. Elements with the same value may be placed in the same bucket, depending on the implementation.
-
Sort individual buckets: Sort each bucket individually, either by using another sorting algorithm (such as insertion sort or quicksort) or recursively applying the bucket sort algorithm. The choice of sorting algorithm for the buckets depends on the specific requirements and characteristics of the data.
-
Concatenate the buckets: Once each bucket is sorted, concatenate the elements from all the buckets in their sorted order to obtain the final sorted array.
Bucket sort has a time complexity that depends on the sorting algorithm used for the individual buckets and the distribution of elements into the buckets. If the elements are uniformly distributed and the bucket sizes are well-balanced, the average case time complexity can be linear, O(n), where n is the number of elements. However, in the worst case, bucket sort can have a time complexity of O(n^2), if all the elements fall into the same bucket.
Q11. What are insertion and deletion nodes?
In the context of data structures, insertion and deletion refer to the operations performed on nodes within the structure. The terms "insertion" and "deletion" are commonly used in the context of linked lists, binary trees, and other similar data structures.
Insertion of a node typically refers to adding a new node into the data structure at a specific position or location. The new node is created with the desired value or data, and then it is connected or linked appropriately within the structure. The exact method of insertion depends on the specific data structure being used.
For example, in a linked list, insertion involves creating a new node and adjusting the pointers of neighboring nodes to include the new node in the appropriate position. The new node is typically inserted either at the beginning of the list (head), at the end of the list (tail), or somewhere in between, based on the desired order or criteria.
Deletion of a node refers to removing a node from the data structure. Similar to insertion, the exact method of deletion depends on the specific data structure being used. Deletion typically involves adjusting the connections or pointers within the structure to exclude the node being deleted.
Using a linked list as an example again, deletion involves updating the pointers of neighboring nodes to bypass the node being deleted. The memory occupied by the deleted node may also need to be freed or released, depending on the programming language and memory management system.
Both insertion and deletion operations are fundamental for manipulating data structures and maintaining their integrity. These operations allow for dynamic updates and modifications to the structure as data is added or removed. The specific algorithms and techniques used for insertion and deletion can vary depending on the requirements and characteristics of the data structure being used.
Q12. What is the definition of the term 'postfix expression'?
In computer science and mathematics, a postfix expression, also known as reverse Polish notation (RPN), is a mathematical notation in which operators are written after their operands. In postfix notation, an expression is evaluated by scanning from left to right and performing operations on operands as soon as their corresponding operators are encountered.
Here's an example to illustrate the difference between infix notation (traditional notation) and postfix notation:
Infix Notation: 2 + 3 Postfix Notation: 2 3 +
In the infix notation, the operator "+" is placed between the operands "2" and "3". In the postfix notation, the operator "+" is placed after the operands "2" and "3".
In postfix notation, complex expressions can be represented in a concise and unambiguous manner without the need for parentheses to indicate the order of operations. The operators appear immediately after their respective operands, making it easier to evaluate the expression using a stack-based algorithm.
To evaluate a postfix expression, a stack-based approach is commonly used. Here's a high-level overview of the algorithm:
- Scan the expression from left to right.
- If an operand is encountered, push it onto the stack.
- If an operator is encountered, pop the required number of operands from the stack, perform the operation, and push the result back onto the stack.
- Repeat steps 2 and 3 until the entire expression is scanned.
- The final result will be the value remaining on the stack.
For example, let's evaluate the postfix expression "4 5 + 7 *":
- Push 4 onto the stack.
- Push 5 onto the stack.
- Encounter "+". Pop 5 and 4 from the stack, add them (5 + 4 = 9), and push the result (9) onto the stack.
- Push 7 onto the stack.
- Encounter "*". Pop 7 and 9 from the stack, multiply them (7 * 9 = 63), and push the result (63) onto the stack.
- The final result is 63.
Postfix notation has advantages in terms of simplicity and ease of evaluation, making it useful in certain applications, such as calculators, expression parsing, and stack-based virtual machines.
Q13. Explaining the difference between B-tree and B+ tree.
B-trees and B+ trees are two types of balanced search trees commonly used in computer science and database systems. While they share similarities in their structure and functionality, there are important differences between them.
Here are the key differences between B-trees and B+ trees:
-
Node Structure: In a B-tree, each node contains both keys and corresponding data pointers or values. On the other hand, in a B+ tree, only keys are stored in internal nodes, while data pointers or values are stored in the leaf nodes. This distinction allows B+ trees to have a more efficient use of storage, as the keys in internal nodes act as guides for efficient navigation, and the leaf nodes store more data per node.
-
Fanout: The fanout of a tree represents the maximum number of child nodes that a parent node can have. B-trees typically have a lower fanout compared to B+ trees because each node in a B-tree contains both keys and data pointers, resulting in larger nodes. In contrast, B+ trees have a higher fanout since they only store keys in internal nodes, enabling more keys to fit within a node.
-
Leaf Node Structure: In a B-tree, leaf nodes can be accessed directly for data retrieval. In contrast, B+ trees have a linked list structure among their leaf nodes, allowing for efficient range queries and sequential access. The linked list structure makes B+ trees particularly suitable for database systems, where sequential access is common.
-
Index vs. Data Storage: B-trees are suitable for both indexing and data storage since they store both keys and data pointers in internal nodes. On the other hand, B+ trees are primarily used for indexing, where the leaf nodes store the actual data.
-
Range Queries: B+ trees are better suited for range queries due to their linked list structure among leaf nodes. Range queries involve searching for a range of keys or values within a specified range, and B+ trees can efficiently traverse the linked list of leaf nodes to retrieve the desired data.
-
Leaf Node Access: B+ trees typically require one less level of indirection to access leaf nodes compared to B-trees since the internal nodes in B-trees also store data pointers or values. This makes B+ trees more efficient in terms of memory access and reduces the number of disk accesses required for data retrieval.
Q14. Explain the difference between a PUSH and a POP.
In computer science, "push" and "pop" are operations commonly associated with stacks, which are abstract data structures that follow the Last-In-First-Out (LIFO) principle. The "push" operation adds an element to the top of the stack, while the "pop" operation removes and returns the topmost element from the stack.
Here's a detailed explanation of the difference between a push and a pop operation:
Push Operation: The push operation adds a new element to the top of the stack. It involves the following steps:
-
Increment the stack pointer: The stack pointer keeps track of the current position of the topmost element in the stack. In the push operation, the stack pointer is incremented to make space for the new element.
-
Store the element: The new element is stored in the location indicated by the updated stack pointer. This effectively adds the element to the top of the stack.
-
Update the stack: After storing the new element, the stack is updated to reflect the addition of the element. The stack pointer is now pointing to the newly added element, becoming the new top of the stack.
Pop Operation: The pop operation removes and retrieves the topmost element from the stack. It involves the following steps:
-
Retrieve the topmost element: The pop operation accesses the element at the top of the stack using the stack pointer.
-
Decrement the stack pointer: After retrieving the element, the stack pointer is decremented to remove the topmost element from the stack. This effectively shrinks the stack size by one.
-
Update the stack: After the pop operation, the stack is updated to reflect the removal of the topmost element. The stack pointer now points to the element below the removed element, becoming the new top of the stack.
Q15. What is a doubly linked list?
A doubly linked list is a type of linked list where each node contains two pointers, one pointing to the previous node and another pointing to the next node. This bidirectional linkage allows traversal in both directions, forward and backward, unlike singly linked lists that only support forward traversal.
In a doubly linked list, each node typically consists of three components:
- Data: The actual value or data stored in the node.
- Previous Pointer: A pointer that points to the previous node in the list. For the first node (head) of the list, the previous pointer is usually set to null or a special value indicating the absence of a previous node.
- Next Pointer: A pointer that points to the next node in the list. For the last node (tail) of the list, the next pointer is typically set to null or a special value indicating the end of the list.
The presence of previous and next pointers enables efficient traversal in both directions. It allows operations such as forward traversal from the head to the tail, backward traversal from the tail to the head, and random access to any node in the list.
Some common operations performed on a doubly linked list include:
- Insertion: Inserting a new node at the beginning, end, or any position within the list involves adjusting the pointers of neighboring nodes to accommodate the new node.
- Deletion: Removing a node from the list requires updating the pointers of neighboring nodes to bypass the node being deleted and deallocate its memory if necessary.
- Search: Searching for a specific value involves traversing the list either forward or backward, comparing the values of nodes until a match is found or reaching the end of the list.
The main advantage of doubly linked lists over singly linked lists is the ability to traverse the list in both directions, which can be useful in certain scenarios. However, doubly linked lists require additional memory to store the previous pointers, and operations such as insertion and deletion can be slightly more complex due to the need for updating multiple pointers.
Doubly linked lists find applications in various data structures and algorithms, such as implementing queues, stacks, and circular lists, as well as providing efficient access to nodes for algorithms like quicksort or merge sort.
Q16. What is "basic string manipulation"?
Basic string manipulation refers to the process of manipulating or modifying strings, which are sequences of characters. String manipulation is a fundamental task in programming and involves various operations such as concatenation, splitting, searching, replacing, and extracting substrings.
Here are some common operations involved in basic string manipulation:
-
Concatenation: Combining two or more strings together to create a single string. This can be done using the concatenation operator (+) or specific string concatenation functions provided by programming languages.
-
Splitting: Breaking a string into smaller parts based on a delimiter or pattern. This operation is useful for separating a string into substrings or extracting specific information. The result is often stored in an array or list.
-
Searching: Finding the occurrence or position of a particular substring or character within a larger string. This can be done using functions or methods that perform pattern matching or by using built-in search functions provided by programming languages.
-
Replacing: Replacing occurrences of a substring or specific characters within a string with another substring or character. This operation helps modify or transform strings by substituting specific patterns or characters.
-
Extracting substrings: Retrieving a portion of a string, known as a substring, based on a starting index and length or based on specific patterns. Substring extraction is useful for manipulating specific parts of a string.
-
Changing case: Modifying the case of characters in a string, such as converting all characters to uppercase or lowercase. This operation can be used for normalization or formatting purposes.
-
Trimming: Removing leading and trailing whitespace or specific characters from a string. Trimming is useful for cleaning up user input or removing unnecessary characters.
Q17. What is "bit manipulation" when referring to C++?
Bit manipulation in C++ refers to manipulating individual bits or groups of bits within binary representations of data using bitwise operators. It involves performing logical and arithmetic operations at the bit level to achieve specific functionalities, optimize memory usage, or perform low-level operations.
C++ provides several bitwise operators that allow manipulation of individual bits or groups of bits within variables. The bitwise operators include:
-
Bitwise AND (&): Performs a bitwise AND operation on each pair of corresponding bits. It results in a new value with each bit set to 1 only if both corresponding bits are 1.
-
Bitwise OR (|): Performs a bitwise OR operation on each pair of corresponding bits. It results in a new value with each bit set to 1 if at least one of the corresponding bits is 1.
-
Bitwise XOR (^): Performs a bitwise XOR (exclusive OR) operation on each pair of corresponding bits. It results in a new value with each bit set to 1 if the corresponding bits are different (one 0 and one 1).
-
Bitwise NOT (~): Performs a bitwise NOT operation, also known as one's complement, on a single operand. It flips each bit, changing 1 to 0 and 0 to 1.
Additionally, C++ provides shift operators for shifting bits left or right:
-
Left Shift (<<): Shifts the bits of a value to the left by a specified number of positions. It effectively multiplies the value by 2 for each shift.
-
Right Shift (>>): Shifts the bits of a value to the right by a specified number of positions. It effectively divides the value by 2 for each shift.
Bit manipulation can be used for various purposes, including:
- Setting or clearing specific bits in a bit pattern.
- Extracting or manipulating specific fields or flags within a binary representation.
- Packing multiple values or flags into a single integer or bitset to optimize memory usage.
- Efficient implementation of bitwise algorithms or data structures.
- Performance optimizations in certain scenarios where bit-level operations can be more efficient than higher-level operations.
Bit manipulation requires a good understanding of binary representation and bitwise operators. It is commonly used in low-level programming, embedded systems, cryptography, and optimizing certain algorithms and data structures for efficiency.
Q18. Why does it make sense to use dynamic programming?
Dynamic programming is a powerful technique used in computer science and optimization problems to efficiently solve complex problems by breaking them down into smaller, overlapping subproblems. It makes sense to use dynamic programming for several reasons:
-
Optimal Substructure: Dynamic programming is particularly effective when a problem can be divided into smaller subproblems, and the optimal solution to the larger problem can be constructed from the optimal solutions of its subproblems. This property, known as optimal substructure, allows dynamic programming to systematically solve the problem by solving and storing the solutions to subproblems and then building up to solve larger instances of the problem.
-
Overlapping Subproblems: Dynamic programming excels when there are overlapping subproblems, meaning that the same subproblems are solved multiple times during the computation. Instead of recomputing the solutions for the same subproblems, dynamic programming stores the solutions in a table or cache, allowing for efficient reuse of previously computed results. This avoids redundant computations and significantly improves the overall efficiency of the algorithm.
-
Time Complexity Reduction: By breaking down a problem into smaller subproblems and storing their solutions, dynamic programming reduces the time complexity of the overall problem. It avoids repeating computations and solves each subproblem only once, resulting in a more efficient solution compared to naive approaches that may involve redundant computations or exponential time complexity.
-
Memoization: Dynamic programming often uses memoization, which is the technique of storing computed results for later reuse. Memoization allows for efficient retrieval of previously computed solutions, avoiding the need to recompute them. This technique greatly improves the performance of the algorithm, especially when there are overlapping subproblems.
-
Versatility: Dynamic programming is a versatile technique applicable to a wide range of problems across various domains, including algorithms, optimization, graph theory, string processing, and more. It can be used to solve problems involving sequences, graphs, trees, and other complex structures.
-
Problem Decomposition: Dynamic programming encourages breaking down a complex problem into simpler, more manageable subproblems, which can enhance understanding and modularity in problem-solving. This decomposition enables clearer thinking and can lead to more organized and maintainable code.
Q19. What is DSA game theory?
DSA stands for "Data Structure and Algorithms," which is a field of computer science that deals with the design, analysis, and implementation of efficient algorithms and data structures. Game theory, on the other hand, is a branch of mathematics and economics that studies strategic decision-making in situations where multiple players or agents are involved.
While DSA and game theory are distinct fields, they can intersect in certain areas, particularly when analyzing algorithms or data structures in the context of game-related problems or scenarios. DSA can provide tools and techniques for modeling and solving game-theoretic problems efficiently.
In the context of DSA, game theory can be applied to various scenarios, such as:
-
Competitive Programming: Competitive programming often involves solving algorithmic problems that can be framed as games. Game theory concepts can be employed to analyze the strategies, optimize decisions, and design efficient algorithms to solve these problems.
-
Multi-Agent Systems: In systems involving multiple agents or players, game theory can be used to analyze their interactions, strategies, and decision-making processes. DSA techniques can aid in modeling the problem and designing algorithms to optimize outcomes or find Nash equilibria.
-
Network and Graph Problems: Game theory can be applied to analyze problems related to networks or graphs, such as routing, resource allocation, or optimization of network flows. DSA algorithms and data structures can be utilized to find efficient solutions in these scenarios.
-
Auctions and Market Mechanisms: Game theory plays a significant role in analyzing and designing auction mechanisms and market protocols. DSA techniques can be employed to model bidding strategies, optimize auction outcomes, or solve related optimization problems.
-
Algorithmic Game Theory: Algorithmic game theory combines elements of both DSA and game theory to study the computational aspects of strategic interactions. It focuses on designing algorithms and data structures that consider the strategic behavior of agents or players.
Q20. What is the string search algorithm that has the fastest search time?
The string search algorithm that is known for its fastest search time is the Boyer-Moore algorithm. The Boyer-Moore algorithm is a string searching algorithm that exploits two key ideas: the bad character rule and the good suffix rule. These rules allow the algorithm to skip unnecessary comparisons and make efficient jumps, resulting in faster search times.
The algorithm starts matching the pattern from the end of the string to be searched, comparing characters from right to left. If a mismatch occurs, the algorithm uses the bad character rule to determine the maximum distance it can skip ahead. The bad character rule exploits the information of the mismatched character to shift the pattern to the right, aligning it with the next occurrence of the mismatched character in the string being searched.
In addition to the bad character rule, the Boyer-Moore algorithm employs the good suffix rule to handle mismatches occurring within the pattern. The good suffix rule determines the maximum distance the pattern can be shifted based on the longest suffix of the pattern that matches a suffix of the original string being searched. This rule allows the algorithm to make efficient jumps when encountering mismatches within the pattern.
By utilizing these two rules, the Boyer-Moore algorithm reduces the number of character comparisons required during the search process. This makes it one of the fastest string search algorithms, especially for large texts and patterns.
Q21. What is meant by the term "square root decomposition"?
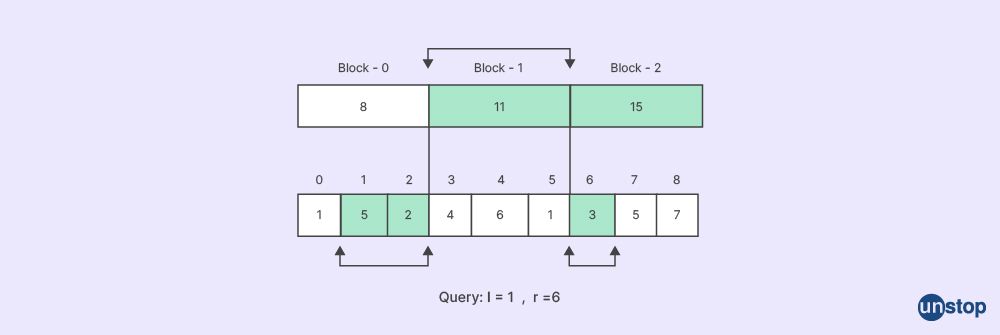
Square root decomposition, also known as square root partitioning or block decomposition, is a technique used in algorithm design to divide a data structure or an array into smaller blocks or segments. The main idea behind square root decomposition is to partition the data structure in a way that balances the trade-off between query time and update time.
In square root decomposition, the data structure is divided into blocks of equal size, except for the last block, which may have a smaller size if the total number of elements is not a perfect square. Each block typically contains a fixed number of elements, often equal to the square root of the total number of elements.
The key benefit of square root decomposition is that it allows for efficient querying operations while still maintaining reasonable update times. By dividing the data structure into blocks, the number of elements that need to be processed or updated during an operation is reduced.
Here's a general overview of how square root decomposition works:
-
Initialization: The data structure is divided into blocks, with each block containing a fixed number of elements (usually equal to the square root of the total number of elements).
-
Querying: When performing a query or search operation, it is often sufficient to only process or examine the relevant blocks instead of the entire data structure. This reduces the query time complexity as compared to performing operations on the entire data structure.
-
Updates: When updating or modifying elements within the data structure, the operation is typically performed on a block level. If an element is modified, the corresponding block is updated, ensuring the consistency of the data structure.
Square root decomposition is commonly used in scenarios where a balance between query time and update time is required. It finds applications in various problems such as range queries, range updates, prefix sums, minimum/maximum queries, and more.
Q22. What is a queue?
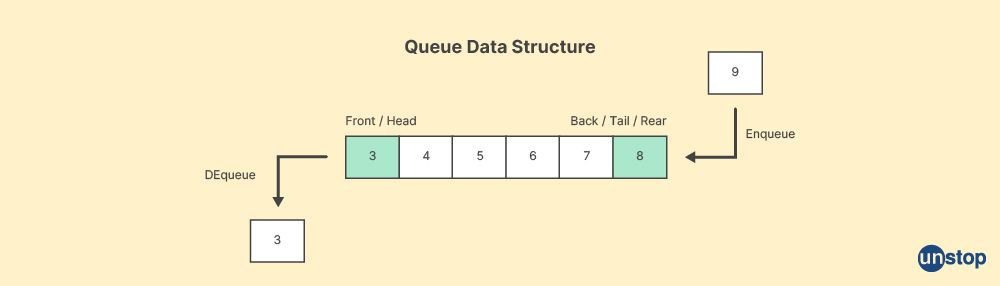
In computer science, a queue is an abstract data type (ADT) that represents a collection of elements with a particular ordering principle known as "first-in, first-out" (FIFO). It follows the concept that the element that is added first will be the first one to be removed.
A queue can be visualized as a line of people waiting for a service or entering a facility, where the person who arrives first is the first one to be served or leave the line. Similarly, in a queue data structure, elements are added at one end, called the rear or tail, and removed from the other end, called the front or head.
The key operations performed on a queue are:
-
Enqueue: Adding an element to the rear of the queue. The new element becomes the last element in the queue.
-
Dequeue: Removing the element from the front of the queue. The element that was added first is removed.
-
Peek/Front: Examining the element at the front of the queue without removing it.
-
IsEmpty: Checking if the queue is empty or contains any elements.
Queues can be implemented using various data structures, such as arrays or linked lists. In an array-based implementation, a fixed-size array is used, and the front and rear indices are maintained to keep track of the elements. In a linked list implementation, nodes are linked together, and pointers to the head and tail nodes are maintained.
Q23. What precisely is meant by the term "data abstraction"?
Data abstraction is a fundamental concept in computer science and software engineering that refers to the process of hiding implementation details and exposing only the essential characteristics or behaviors of a data type or object. It is a technique used to simplify complex systems by focusing on the essential aspects and providing a high-level interface for working with data.
In data abstraction, the emphasis is on what an object or data type does rather than how it is implemented internally. It allows programmers to work with complex data structures or objects by using a simplified and consistent interface, without needing to understand the intricacies of the underlying implementation. This promotes modularity, encapsulation, and separation of concerns in software design.
Data abstraction is typically achieved through the use of abstract data types (ADTs) or classes in object-oriented programming. An ADT defines a set of operations or methods that can be performed on the data, along with their behaviors and preconditions/postconditions, without specifying the internal details of how those operations are implemented.
By providing a clear and well-defined interface, data abstraction enables software developers to:
-
Hide complexity: Data abstraction allows complex data structures or objects to be represented and manipulated through a simplified interface, shielding users from the underlying implementation details. This simplifies the usage of data types and improves code readability.
-
Encapsulate implementation: The internal details of the data type or object are encapsulated and hidden from the user. This promotes information hiding and protects the integrity of the data, allowing for easier maintenance and modification of the implementation without affecting the users.
-
Promote modularity and reusability: Data abstraction enables modular design by separating the interface from the implementation. This promotes code reuse and modularity, as the same interface can be used with different implementations or extended to create new data types.
-
Enhance software maintenance and evolution: By providing a well-defined interface, data abstraction allows for easier maintenance and evolution of software systems. Modifications to the internal implementation can be made without affecting external usage, as long as the interface remains consistent.
Q24. What is hashing?
Hashing is a technique used in computer science to efficiently store, retrieve, and search for data in a data structure called a hash table. It involves applying a hash function to a given input (such as a key or data value) to generate a fixed-size numeric value called a hash code or hash value. The hash code is used as an index or address to store the data in the hash table.
The main goals of hashing are to achieve fast access to data and minimize collisions, where multiple inputs produce the same hash code. The hash function takes an input and computes a hash code that is typically smaller in size compared to the input. The hash code is then mapped to a specific location in the hash table, where the data associated with the input is stored.
The process of hashing involves the following steps:
-
Hash Function: A hash function takes an input and generates a hash code. The hash function should be deterministic, meaning that for a given input, it should always produce the same hash code. It should also distribute hash codes uniformly to minimize collisions.
-
Hash Table: A hash table is a data structure that consists of an array or a collection of buckets, each capable of storing data. The size of the hash table is typically determined based on the expected number of elements and the desired load factor. The load factor is the ratio of the number of elements stored to the total number of buckets in the hash table.
-
Hash Code to Index Mapping: The hash code generated by the hash function is mapped to an index within the range of the hash table. This mapping can be done using various techniques, such as modulo division by the size of the hash table. The resulting index determines the bucket or location where the data associated with the input will be stored.
-
Handling Collisions: Collisions occur when multiple inputs produce the same hash code and need to be stored in the same bucket. Various collision resolution techniques exist, such as separate chaining (where each bucket stores a linked list of elements) or open addressing (where alternative locations are searched within the hash table). These techniques allow for efficient retrieval of data even in the presence of collisions.
Hashing provides fast average-case time complexity for operations such as insertion, retrieval, and deletion, as they can be performed in constant time on average (O(1)). However, in the worst case, when there are many collisions, the time complexity can degrade to O(n), where n is the number of elements in the hash table.
Q25. What is meant by the term "singly linked list"?
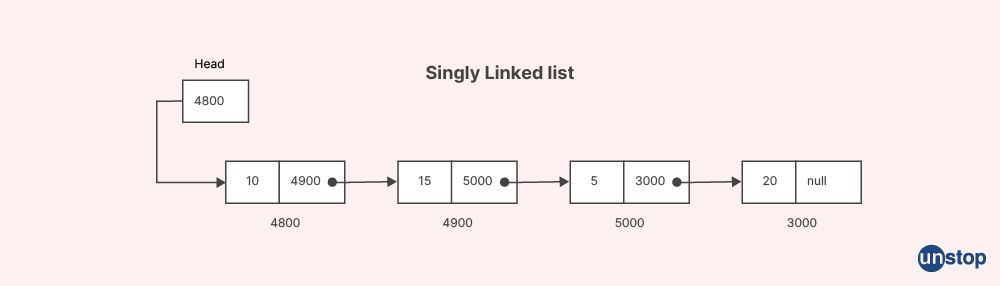
A singly linked list is a data structure used to store and manipulate a collection of adjacent data elements. It is composed of nodes, where each node contains an adjacent data element and a reference (or pointer) to the next node in the sequence. In a singly linked list, the nodes are linked in a linear manner, allowing traversal in only one direction.
Here are the key characteristics of a singly linked list:
-
Node Structure: Each node in a singly linked list consists of two parts: the data element and a reference to the next node. The key element holds the value or information associated with the node, while the reference points to the next node in the sequence.
-
Head Pointer: A singly linked list typically maintains a pointer called the "head" that points to the first node in the list. It serves as the starting point for accessing or traversing the linked list.
-
Tail Pointer: In some implementations, a singly linked list may also have a pointer called the "tail" that points to the last node in the list. This tail pointer simplifies appending adjacent elements to the end of the list.
-
Traversal: To traverse a singly linked list, you start at the head node and follow the next pointers until you reach the end of the list. This allows you to access or process each node in a sequential manner.
-
Insertion and Deletion: Inserting a new node into a singly linked list involves modifying the next pointer of an existing node to point to the new node. Similarly, deleting a node requires updating the next pointer of the preceding node to bypass the node being deleted.
Q26. Which is the longest possible sequence of palindromic words?
The concept of a "palindromic word" refers to a word that remains the same when read forwards or backwards. In the English language, palindromic words are relatively rare, but they do exist. Here are a few examples of palindromic words:
- "level"
- "deed"
- "radar"
- "noon"
- "civic"
- "stats"
- "madam"
The longest possible sequence of palindromic words would be a sequence of these palindromic words joined together. However, it is important to note that constructing a sequence of palindromic words that forms a meaningful sentence or coherent text may be challenging due to the limited availability of palindromic words in the English language.
It's worth mentioning that the length of the sequence will depend on the availability of palindromic words and their combination. Without any specific constraints or requirements, it is difficult to determine the exact length of the longest possible sequence of palindromic words.
Q27. Could you explain what C++ objects are?
In C++, objects are instances of classes, which are the fundamental building blocks of object-oriented programming (OOP). A class is a user-defined data type that encapsulates data and functions (known as member variables and member functions, respectively) into a single entity.
When you define a class in C++, you are essentially creating a blueprint or a template that describes the properties and behaviors that objects of that class can have. An object, also referred to as an instance, is created based on this blueprint and represents a specific occurrence of the class.
Here are some key points about C++ objects:
-
Data and Functions: A class defines the data (member variables) and functions (member functions) that are associated with objects of that class. The data represents the state or attributes of the object, while the functions define the behavior or actions that the object can perform.
-
Instantiation: To create an object of a class, you need to instantiate it using the
newkeyword or by declaring it as a local variable. The process of creating an object is called instantiation, and it involves allocating memory for the object and initializing its member variables. -
Object Identity: Each object has its own identity and occupies a unique memory location. You can interact with objects individually, accessing their member variables and invoking their member functions.
-
Object Interactions: Objects can interact with each other through their member functions or by accessing each other's public member variables. This enables communication, collaboration, and sharing of data between objects.
-
Encapsulation: C++ supports the principle of encapsulation, which means that the internal details of an object are hidden from the outside world. Access to the data and functions of an object is controlled through public, private, and protected access specifiers, ensuring data integrity and promoting modular design.
-
Object Lifecycle: Objects have a lifecycle that includes creation, manipulation, and destruction. You can create objects dynamically using
newand delete them usingdeletewhen they are no longer needed. Objects created as local variables are automatically destroyed when they go out of scope.
C++ objects provide a powerful mechanism for organizing and managing complex systems by grouping related data and behaviors into coherent entities. They facilitate code reuse, modularity, and maintainability by allowing you to create multiple instances of a class and interact with them independently. Object-oriented programming in C++ emphasizes the use of objects and classes to structure and model real-world entities and their interactions.
Q28. What is meant by the term "operator precedence" when referring to Java?
In Java (and in programming languages in general), operator precedence refers to the rules that determine the order in which operators are evaluated in an expression. When an expression contains multiple operators, operator precedence defines the sequence in which the operators are applied.
Different operators have different levels of precedence, and those with higher precedence are evaluated before those with lower precedence. If operators have the same precedence, their evaluation order may depend on their associativity, which can be left-to-right or right-to-left.
Understanding operator precedence is crucial for correctly interpreting and evaluating expressions, as it affects the outcome of calculations and the behavior of the program. It ensures that expressions are evaluated in a predictable and consistent manner.
In Java, operators are categorized into several precedence levels, with higher precedence operators evaluated first. Here are some examples of operator precedence in Java, from highest to lowest:
- Postfix operators:
expr++,expr-- - Unary operators:
++expr,--expr,+expr,-expr,!expr,~expr,(type)expr - Multiplicative operators:
*,/,% - Additive operators:
+,- - Shift operators:
<<,>>,>>> - Relational operators:
<,<=,>,>=,instanceof - Equality operators:
==,!= - Bitwise AND:
& - Bitwise XOR:
^ - Bitwise OR:
| - Logical AND:
&& - Logical OR:
|| - Ternary operator:
? : - Assignment operators:
=,+=,-=,*=,/=,%=,<<=,>>=,>>>=,&=,^=,|=
Q29. Could you briefly describe some OOPs ideas?
Sure! Here are brief descriptions of some fundamental Object-Oriented Programming (OOP) concepts:
-
Encapsulation: It is the bundling of data and methods/functions that manipulate that data into a single unit called an object. Encapsulation helps in achieving data hiding and abstraction, allowing the object to control access to its internal state.
-
Inheritance: Inheritance enables the creation of new classes (derived classes) based on existing classes (base classes). The derived classes inherit the properties and behaviors of the base class, promoting code reuse and establishing an "is-a" relationship between objects.
-
Polymorphism: Polymorphism allows objects of different classes to be treated as objects of a common superclass. It allows methods with the same name but different implementations to be invoked based on the type of object being referred to. Polymorphism facilitates code flexibility and extensibility.
-
Abstraction: Abstraction focuses on capturing the essential features of an object while ignoring the implementation details. It allows programmers to create abstract classes or interfaces that define a set of common methods or properties that derived classes must implement. Abstraction promotes code modularity and simplifies complex systems.
-
Class: A class is a blueprint or template for creating objects. It defines the attributes (data members) and behaviors (methods/functions) that objects of that class will possess. Objects are instances of classes.
-
Object: An object is an instance of a class. It represents a real-world entity or concept and encapsulates its state (data) and behavior (methods/functions).
-
Message Passing: Objects interact with each other by sending and receiving messages. A message is a request for an object to perform a specific operation or invoke a method. Message passing is a way of achieving communication and collaboration between objects in an OOP system.
These concepts form the foundation of OOP and are widely used in programming languages like Java, C++, Python, and others to develop modular, maintainable, and reusable code.
Q30. Why does Java's main function only support static parameters?
Java's main function is the entry point for a Java program. It is defined as public static void main (String [ ] args). The main function only supports static parameters because it needs to be accessed without creating an instance of the class containing it.
Here are a few reasons why Java's main function specifically supports static parameters:
-
Entry point: The main function serves as the starting point of execution for a Java program. It needs to be accessible without instantiating an object because when the Java Virtual Machine (JVM) launches the program, it doesn't create an instance of the class but rather directly invokes the main method.
-
Simplicity: By using static parameters, the
mainfunction can be called directly on the class itself, without the need to create an object. This simplifies the process of starting the program and avoids unnecessary object creation. -
Consistency: Java is an object-oriented language, and most methods are typically invoked on objects. However, the main method is an exception because it needs to be invoked without an object. By enforcing static parameters, Java maintains consistency with the rest of its object-oriented paradigm while allowing a special case for the program's entry point.
-
Compatibility: The requirement for static parameters in the
mainfunction makes it compatible with earlier versions of Java. It ensures that programs written in older versions can still be executed in newer versions without modification. If the main method allowed non-static parameters, it would break backward compatibility.
Q31. What is meant by the term "singleton class" when referring to Java?
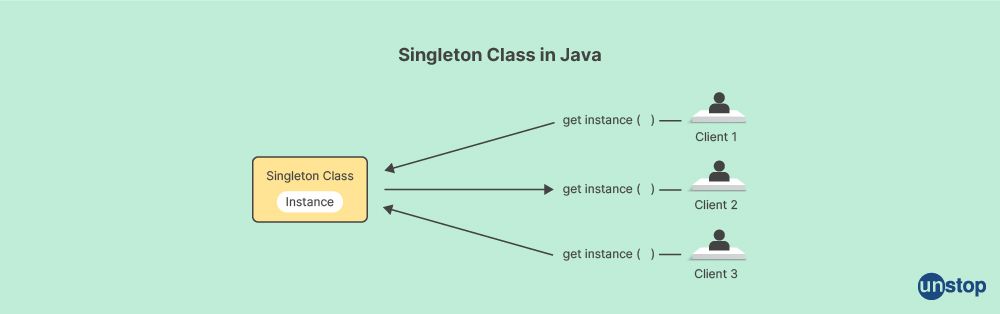
In Java, the term "singleton class" refers to a design pattern that restricts the instantiation of a class to a single object. It ensures that only one instance of the class can be created and provides a global point of access to that instance.
To create a singleton class, the following steps are typically followed:
- Make the constructor of the class private to prevent direct instantiation from outside the class.
- Declare a static variable of the class type that will hold the single instance of the class.
- Provide a public static method that acts as a getter for the instance. This method checks if the instance already exists and returns it if it does, or creates a new instance if it doesn't.
- Optionally, implement additional methods and properties in the singleton class.
Here's an example of a singleton class in Java:
CODE SNIPPET IS HEREcHVibGljIGNsYXNzIFNpbmdsZXRvbiB7CnByaXZhdGUgc3RhdGljIFNpbmdsZXRvbiBpbnN0YW5jZTsKCi8vIFByaXZhdGUgY29uc3RydWN0b3IgdG8gcHJldmVudCBkaXJlY3QgaW5zdGFudGlhdGlvbgpwcml2YXRlIFNpbmdsZXRvbigpIHsKfQoKLy8gUHVibGljIG1ldGhvZCB0byBnZXQgdGhlIGluc3RhbmNlIG9mIHRoZSBjbGFzcwpwdWJsaWMgc3RhdGljIFNpbmdsZXRvbiBnZXRJbnN0YW5jZSgpIHsKaWYgKGluc3RhbmNlID09IG51bGwpIHsKaW5zdGFuY2UgPSBuZXcgU2luZ2xldG9uKCk7Cn0KcmV0dXJuIGluc3RhbmNlOwp9CgovLyBPdGhlciBtZXRob2RzIGFuZCBwcm9wZXJ0aWVzCnB1YmxpYyB2b2lkIGRvU29tZXRoaW5nKCkgewovLyAuLi4KfQp9
Q32. What are "packages" in Java?
In Java, a package is a way to organize and group related classes, interfaces, and sub-packages. It provides a hierarchical structure for organizing Java code and helps avoid naming conflicts between classes.
A package is represented by a directory structure in the file system, where each package corresponds to a directory. The package name is typically written in reverse domain name notation, such as com.example.myapp. For example, if you have a package called com.example.myapp, the corresponding directory structure would be com/example/myapp on the file system.
Packages serve several purposes in Java:
-
Organization: Packages help organize code into meaningful units, making it easier to locate and manage classes and resources within a project. They provide a logical structure for organizing related code.
-
Encapsulation: Packages allow you to control access to classes and members by using access modifiers like public, protected, and private. Classes within the same package can access each other's package-private (default) members without explicitly specifying access modifiers.
-
Namespace Management: Packages provide a way to create unique namespaces for classes. Since packages are hierarchical, two classes with the same name can coexist in different packages without conflicts.
-
Access Control: Packages allow you to control the visibility of classes and members to other classes and packages. By using the public, protected, and private modifiers, you can define the level of access to classes and members within a package.
Q33. Please explain exception in Java.
In Java, an exception is an event that occurs during the execution of a program, which disrupts the normal flow of the program's instructions. When an exceptional condition arises, such as an error or an unexpected situation, Java throws an exception object to indicate that something went wrong.
Exceptions in Java are part of the exception handling mechanism, which allows you to gracefully handle and recover from errors or exceptional conditions. By using exception handling, you can separate the code that detects and handles exceptions from the regular program logic, improving the code's readability and maintainability.
The basic concept behind exception handling in Java is the "try-catch" block. You enclose the code that may throw an exception within a "try" block, and then you provide one or more "catch" blocks to handle specific types of exceptions. If an exception occurs within the "try" block, the program flow is transferred to the corresponding "catch" block that can handle that specific exception type.
Here's an example that demonstrates the usage of try-catch blocks:
try {
// Code that may throw an exception
int result = divide(10, 0); // Example division by zero
System.out.println("Result: " + result);
} catch (ArithmeticException ex) {
// Exception handling code for ArithmeticException
System.out.println("An arithmetic error occurred: " + ex.getMessage());
}
Q34. What is the meaning of the term "thread"?
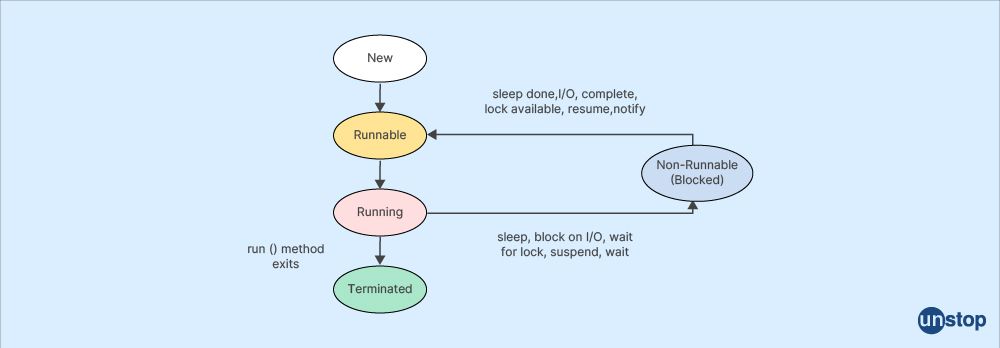
A thread refers to a sequence of instructions that can be executed independently within a program. It is the smallest unit of execution within a process.
A thread represents a single flow of control within a program and can perform tasks concurrently with other threads. In a multi-threaded program, multiple threads run concurrently, allowing for parallel or simultaneous execution of different parts of the program.
Threads are particularly useful in situations where an application needs to perform multiple tasks simultaneously or handle concurrent operations efficiently. By dividing the work into multiple threads, a program can utilize the available resources more effectively and improve overall performance.
Here are some key points about threads:
-
Concurrency: Threads enable concurrent execution of tasks. By dividing a program into multiple threads, different parts of the program can execute independently and concurrently.
-
Share Memory: Threads within the same process share the same memory space, allowing them to access and modify shared data. This shared memory can be a source of both coordination and potential issues like race conditions and synchronization problems.
-
Lightweight: Threads are relatively lightweight compared to processes. Creating and switching between threads is faster and require fewer system resources compared to creating and managing separate processes.
-
Scheduling: The operating system's scheduler determines the order and time allocated to each thread for execution. The scheduling algorithm and thread priorities influence the order in which threads are executed.
-
Thread States: Threads can be in different states during their lifecycle, such as new, runnable, blocked, waiting, and terminated. These states represent the various stages of thread execution and are managed by the operating system or a thread scheduler.
-
Thread Safety: Proper synchronization and coordination mechanisms need to be implemented to ensure thread safety when multiple threads access shared data concurrently. Failure to do so can lead to issues like race conditions and data corruption.
Java, specifically, has built-in support for multithreading. It provides a rich set of APIs and classes in the java.lang and java.util.concurrent packages to create and manage threads. You can create threads by extending the Thread class or implementing the Runnable interface. Java also provides synchronization mechanisms like locks, semaphores, and monitors to handle thread synchronization and coordination.
Understanding and effectively using threads is essential for developing concurrent and parallel programs, optimizing performance, and maximizing resource utilization in many software applications.
Q35. What is synchronization?

Synchronization refers to the coordination of multiple threads to ensure that they access shared resources or critical sections of code in a controlled and orderly manner. Synchronization prevents race conditions, data corruption, and other issues that can arise when multiple threads access shared data concurrently.
When multiple threads access shared resources simultaneously, problems can occur due to the unpredictable interleaving of their execution. Synchronization mechanisms provide a way to enforce mutual exclusion, allowing only one thread to access a shared resource or critical section at a time. This ensures that the shared data remains consistent and avoids conflicts between threads.
Java provides several mechanisms for synchronization:
-
Synchronized Methods: In Java, you can declare methods as synchronized using the
synchronizedkeyword. When a thread invokes a synchronized method, it acquires the intrinsic lock (also known as a monitor) associated with the object on which the method is called. Other threads trying to invoke the synchronized method on the same object must wait until the lock is released. -
Synchronized Blocks: In addition to synchronized methods, you can use synchronized blocks to synchronize specific sections of code. A synchronized block is defined using the
synchronizedkeyword followed by an object reference or a class literal. The block acquires the lock on the specified object or class, allowing only one thread at a time to execute the block. -
Volatile Variables: The
volatilekeyword can be used to mark a variable as volatile. Volatile variables have certain visibility and ordering guarantees, ensuring that the latest value of a volatile variable is always visible to all threads and that their reads and writes are atomic. Volatile variables are useful for simple state flags or shared variables accessed by multiple threads without the need for complex synchronization. -
Locks and Conditions: The
java.util.concurrent.lockspackage provides more flexible synchronization mechanisms through theLockinterface and its implementations likeReentrantLock. Locks allow for explicit control over the locking and unlocking of resources and can provide additional features like fairness policies and condition variables for more advanced synchronization scenarios.
Q36. What is the Java Virtual Machine (JVM), and can it run on any platform?
The Java Virtual Machine (JVM) is a crucial component of the Java platform. It is an abstract computing machine that provides an execution environment for Java bytecode, which is the compiled form of Java source code. The JVM acts as an intermediary between the Java programs and the underlying hardware and operating system.
The primary purpose of the JVM is to enable Java programs to be platform-independent. Java programs are written once and can be executed on any system that has a compatible JVM installed. This "write once, run anywhere" capability is one of the key features of the Java language.
The JVM is responsible for several important tasks, including:
-
Loading and verifying bytecode: The JVM loads the compiled bytecode into memory and verifies its integrity to ensure that it is safe to execute.
-
Just-in-time (JIT) compilation: The JVM includes a dynamic compiler that translates bytecode into machine code instructions that can be executed directly by the underlying hardware. This process, known as JIT compilation, improves the performance of Java programs.
-
Memory management: The JVM manages memory allocation and deallocation, including garbage collection, which automatically reclaims memory that is no longer needed by the program.
-
Security: The JVM provides a secure execution environment by enforcing various security measures, such as bytecode verification and sandboxing.
Regarding platform compatibility, the JVM is designed to run on various platforms, including Windows, macOS, Linux, and others. It is available for a wide range of operating systems and hardware architectures. The Java platform provides different implementations of the JVM for different platforms, ensuring that Java programs can be executed consistently across diverse environments.
Additionally, the Java language and JVM specifications are open standards, allowing for the development of alternative JVM implementations by different organizations. While the most widely used JVM implementation is Oracle's HotSpot JVM, there are other notable implementations like OpenJDK, IBM J9, and Azul Zing.
In summary, the JVM is a critical component of the Java platform that enables Java programs to be platform-independent, allowing them to run on various operating systems and hardware architectures.
Q37. What is the final keyword in Java?
In Java, the final keyword is used to define entities that cannot be modified. It can be applied to variables, methods, and classes, each with its own implications.
-
Final Variables: When applied to a variable, the
finalkeyword indicates that its value cannot be changed once it is assigned. A final variable is essentially a constant. It must be assigned a value either at the time of declaration or within the constructor of the class if it is an instance variable. Final variables are typically written in uppercase letters with underscores separating words (e.g.,final int MAX_VALUE = 10;). -
Final Methods: When applied to a method, the
finalkeyword indicates that the method cannot be overridden by subclasses. This is useful when a class wants to enforce the implementation of a particular method and prevent it from being modified by subclasses. Final methods are commonly used in the context of class inheritance and method overriding. -
Final Classes: When applied to a class, the
finalkeyword indicates that the class cannot be subclassed. In other words, it prevents other classes from extending the final class. This is typically done to ensure that the behavior of the class remains unchanged and cannot be modified by other classes.
The use of the final keyword brings several benefits, including:
- Guarantees immutability: Final variables ensure that their values remain constant, which can be useful for constants or values that should not be modified.
- Security and integrity: Final methods and classes provide a way to protect critical parts of code from being modified or overridden, ensuring the desired behavior is maintained.
- Performance optimizations: The JVM can perform certain optimizations when it encounters final variables, methods, or classes, which can lead to improved performance.
Q38. What is the meaning of the term "abstract class"?
In Java, an abstract class is a class that cannot be instantiated directly, meaning you cannot create objects of the abstract class type. It serves as a blueprint for subclasses and is intended to be extended by other classes.
The keyword "abstract" is used to declare an abstract class. Here are some key characteristics and purposes of abstract classes:
-
Incomplete implementation: An abstract class may contain both implemented and unimplemented methods. It is allowed to have regular methods with complete implementation, but it can also have abstract methods without any implementation. An abstract method is declared without a body and is meant to be overridden by concrete subclasses.
-
Blueprint for subclasses: Abstract classes provide a common template or blueprint that subclasses can extend and specialize. Subclasses of an abstract class are required to provide implementations for all the abstract methods defined in the abstract class. This promotes code reuse and supports the concept of inheritance.
-
Cannot be instantiated: Since abstract classes have unimplemented methods, they cannot be instantiated directly using the
newkeyword. However, you can create objects of concrete subclasses that extend the abstract class and use them to access the inherited methods and fields. -
Can have instance variables and constructors: Abstract classes can have instance variables, constructors, and regular methods, just like any other class. These elements contribute to the overall structure and behavior defined by the abstract class.
-
Can be used to achieve polymorphism: Abstract classes play a significant role in achieving polymorphism in Java. You can define variables and parameters of the abstract class type, and then assign or pass objects of the concrete subclasses to them. This allows for more flexible and generic programming.
It's worth noting that a class can be abstract even if it does not have any abstract methods. The abstract keyword can be used simply to prevent direct instantiation of the class and to indicate that it is meant to be extended.
Q39. What are "annotations" in Java?
In Java, annotations are a form of metadata that can be added to Java code elements, such as classes, methods, fields, and parameters, to provide additional information about them. Annotations are represented by annotations types, which are defined using the @interface keyword.
Annotations are used for various purposes, including:
-
Providing additional information: Annotations can be used to attach additional metadata to code elements. For example, the
@Deprecatedannotation indicates that a particular class, method, or field is deprecated and should no longer be used. Other examples include@Overrideto indicate that a method overrides a superclass method,@SuppressWarningsto suppress specific compiler warnings, and@Authorto indicate the author of a class or method. -
Compiler instructions: Annotations can provide instructions to the compiler or other tools during the compilation or build process. For instance, the
@SuppressWarningsannotation can be used to instruct the compiler to suppress specific warnings, allowing developers to ignore certain warnings without affecting the overall compilation process. -
Runtime behavior: Some annotations affect the runtime behavior of the program. For example, the
@Testannotation from the JUnit testing framework marks a method as a test case, and the testing framework recognizes and executes all methods annotated with@Test. -
Code generation and processing: Annotations can be used to generate code or trigger additional processing at compile-time or runtime. For instance, frameworks like Java Persistence API (JPA) use annotations to define mappings between Java objects and database tables, and tools like Java's Reflection API can examine annotations at runtime to perform specific actions.
Annotations are retained at runtime by default, which means they can be accessed and processed through Java's Reflection API. However, some annotations can be configured to be retained only during the compilation process, and their presence is not available at runtime.
Q40. What is meant by the phrase "anonymous inner class"?
In Java, an anonymous inner class is a class without a name that is defined and instantiated at the same time. It is a way to create a class that extends a class or implements an interface without explicitly defining a separate class.
Here are some key points about anonymous inner classes:
-
Definition and instantiation together: Anonymous inner classes are defined and instantiated in a single expression, typically as part of a method call or assignment. They are used when a temporary class implementation is required for a specific task, and it is not necessary to have a named class for reusability.
-
Extending a class or implementing an interface: Anonymous inner classes can extend a class or implement one or more interfaces. They provide a way to create specialized implementations on-the-fly without the need for creating a separate named class.
-
Limited in scope: Anonymous inner classes have a limited scope and are usually used within a specific code block where they are defined. They are often used in scenarios where a small, one-time implementation is needed, such as event handling or callback functions.
-
Overrides and additional methods: Anonymous inner classes can override methods from the superclass or interface they extend/implement. They can also define additional methods specific to their implementation needs.
-
Access to local variables: Anonymous inner classes have access to the local variables of the enclosing method or code block. However, these variables need to be effectively final (i.e., they should not be modified after being captured by the anonymous inner class).
Here is an example that demonstrates the usage of an anonymous inner class:
interface Greeting {
void greet();
}public class Main {
public static void main(String[] args) {
Greeting greeting = new Greeting() {
@Override
public void greet() {
System.out.println("Hello, world!");
}
};
greeting.greet();
}
}
Q41. What do you know about "infinite loop" when referring to Java code?
In Java, an infinite loop refers to a loop structure that continues to execute indefinitely without terminating naturally. In other words, the loop condition always evaluates to true, or there is no condition that would cause the loop to exit.
An infinite loop can be created intentionally or unintentionally. Here are a few scenarios where an infinite loop may occur:
-
Missing or incorrect loop termination condition: If the loop condition is not properly defined or mistakenly omitted, the loop will continue indefinitely. For example:
while (true) { // Code statements }In this case, the condition
trueis always true, resulting in an infinite loop. -
Inappropriate loop control variable: If the loop control variable or the variable used in the loop condition is not updated correctly within the loop body, it may lead to an infinite loop. For example:
int i = 0; while (i < 10) { // Code statements // Missing increment or update of i }Without updating
iinside the loop, the conditioni < 10will always be true, causing an infinite loop. -
Incorrect loop exit condition: If the loop exit condition is not correctly formulated or the exit condition is never met, the loop can become infinite. This can happen due to logical errors in the code.
An infinite loop can cause your program to become unresponsive and consume excessive CPU resources. It is generally considered a bug unless intentionally used in specific scenarios, such as event-driven programming or server applications that require continuous execution.
Q42. What is Java String Pool?
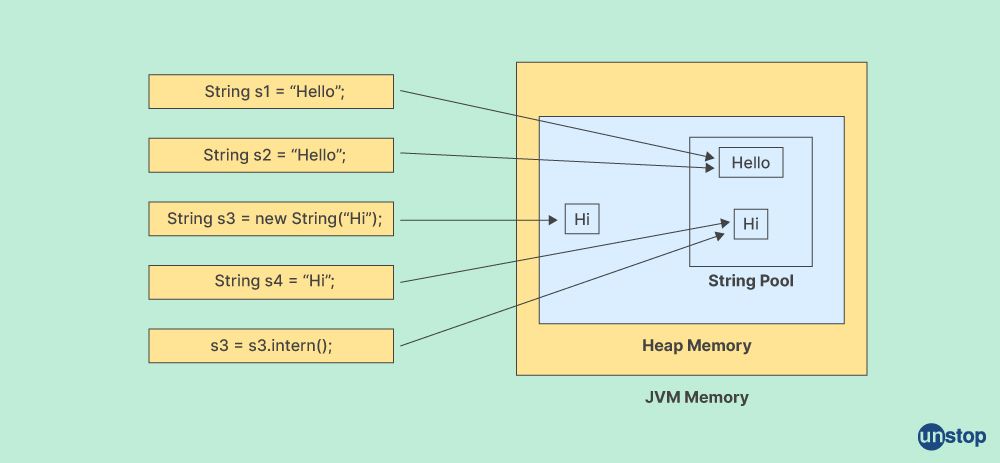
In Java, the String Pool refers to a specific area of memory where Java stores String objects. The String Pool is a mechanism that helps optimize memory usage and enhances performance by reusing String literals.
When a String literal (e.g., "Hello") is encountered in Java code, the JVM checks if an equivalent String object already exists in the String Pool. If it does, the existing String object is reused, and no new object is created. If the String literal is not present in the String Pool, a new String object is created and added to the String Pool for future reuse.
Here are some important points to understand about the Java String Pool:
-
String literals: String literals are the String values defined in Java code within double quotation marks, such as
"Hello","OpenAI", etc. -
String interning: The process of adding String literals to the String Pool is called string interning. The JVM interns (i.e., adds to the String Pool) all String literals by default, but not all dynamically created String objects.
-
String objects created dynamically: When you create String objects dynamically using the
newkeyword, such asnew String("Hello"), a new String object is created in the heap memory, independent of the String Pool. These objects are not automatically interned. -
String Pool and memory optimization: By reusing String literals, the String Pool helps conserve memory by avoiding the creation of multiple String objects with the same value. This is particularly beneficial when working with a large number of String objects or frequently used String literals.
-
String immutability: Strings in Java are immutable, meaning their values cannot be changed once created. This immutability allows String objects to be safely shared and reused, as they cannot be modified.
Q43. What is the meaning of the term "association"?
In the context of software development and object-oriented programming, the term "association" refers to a relationship between two or more classes that establishes a connection or dependency between them. It describes how objects of one class are related to objects of another class.
Associations are used to model the interactions and dependencies between classes in a software system. They provide a way to represent the logical connections between different entities in the system. Associations can be classified based on their cardinality and directionality.
Here are some key concepts related to associations:
-
Cardinality: Cardinality defines the number of instances of one class that can be associated with instances of another class. It describes the multiplicity of the association. Common cardinality values include one-to-one, one-to-many, many-to-one, and many-to-many.
-
Directionality: Directionality defines the flow or direction of the association between classes. Associations can be unidirectional or bidirectional. In a unidirectional association, one class is aware of the other class, but not vice versa. In a bidirectional association, both classes are aware of each other.
-
Navigability: Navigability indicates whether an object can navigate or access the associated objects. It specifies which end of the association can be used to access the related objects. Navigability can be unidirectional or bidirectional.
-
Association classes: In some cases, an association between classes may have additional attributes or behaviors. In such situations, an association class can be introduced to represent the relationship as a separate class. It contains attributes and methods specific to the association.
Q44. What does "super" mean in Java?
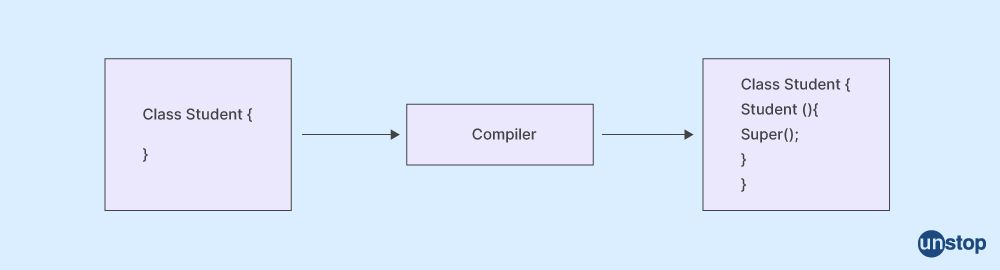
In Java, the keyword "super" is used to refer to the superclass of a subclass. It provides a way to access and invoke superclass members (such as fields, methods, and constructors) from within the subclass.
Here are the main uses of the "super" keyword in Java:
-
Accessing superclass members: By using the "super" keyword followed by a dot, you can access fields and invoke methods of the superclass. This is particularly useful when the subclass overrides a method or hides a field of the superclass and you still want to access the superclass implementation or value. For example:
CODE SNIPPET IS HEREY2xhc3MgVmVoaWNsZSB7CnByb3RlY3RlZCBpbnQgc3BlZWQ7CgpwdWJsaWMgdm9pZCBzdGFydCgpIHsKU3lzdGVtLm91dC5wcmludGxuKCJWZWhpY2xlIHN0YXJ0ZWQuIik7Cn0KfQoKY2xhc3MgQ2FyIGV4dGVuZHMgVmVoaWNsZSB7CnByaXZhdGUgaW50IG51bURvb3JzOwoKcHVibGljIHZvaWQgc3RhcnQoKSB7CnN1cGVyLnN0YXJ0KCk7IC8vIEludm9rZXMgdGhlIHN0YXJ0KCkgbWV0aG9kIG9mIHRoZSBzdXBlcmNsYXNzClN5c3RlbS5vdXQucHJpbnRsbigiQ2FyIHN0YXJ0ZWQuIik7Cn0KfQ==
In this example, the
start()method of theCarclass invokes thestart()method of the superclassVehicleusingsuper.start(). This allows the subclass to add additional behavior while still utilizing the superclass's implementation. -
Invoking superclass constructors: When creating an instance of a subclass, the "super" keyword can be used to invoke a constructor of the superclass. This is done in the first line of the subclass constructor, specifying the arguments required by the superclass constructor. For example:
CODE SNIPPET IS HEREY2xhc3MgVmVoaWNsZSB7CnByb3RlY3RlZCBpbnQgc3BlZWQ7CgpwdWJsaWMgVmVoaWNsZShpbnQgc3BlZWQpIHsKdGhpcy5zcGVlZCA9IHNwZWVkOwp9Cn0KCmNsYXNzIENhciBleHRlbmRzIFZlaGljbGUgewpwcml2YXRlIGludCBudW1Eb29yczsKCnB1YmxpYyBDYXIoaW50IHNwZWVkLCBpbnQgbnVtRG9vcnMpIHsKc3VwZXIoc3BlZWQpOyAvLyBJbnZva2VzIHRoZSBjb25zdHJ1Y3RvciBvZiB0aGUgc3VwZXJjbGFzcwp0aGlzLm51bURvb3JzID0gbnVtRG9vcnM7Cn0KfQ==
In this example, the constructor of the Car class uses super(speed) to invoke the constructor of the superclass Vehicle and passes the speed argument to it. This ensures that the superclass initialization is performed before initializing the subclass-specific attributes.
The "super" keyword is crucial in scenarios where you want to leverage the functionality of the superclass or when dealing with constructor chaining. It allows for code reuse, overriding, and proper initialization of the superclass.
It's important to note that the "super" keyword cannot be used in a static context (such as a static method or a static variable) since it refers to an instance of the superclass.
Q45. What is meant by the term "access modifiers"?

In Java, access modifiers are keywords used to specify the accessibility or visibility of classes, methods, variables, and constructors. They determine which parts of a Java program can access and interact with a particular class member.
Java provides four access modifiers:
-
Public (
public): The public access modifier allows unrestricted access to the class member from any part of the program, including other classes, packages, and subclasses. Public members are accessible by all code. -
Private (
private): The private access modifier restricts access to the class member only within the same class. Private members are not accessible from other classes, even subclasses. They encapsulate internal implementation details and provide data hiding. -
Protected (
protected): The protected access modifier allows access to the class member within the same class, subclasses, and other classes in the same package. Protected members are not accessible from classes in different packages unless they are subclasses. -
Default (no modifier): If no access modifier is specified, the member has default or package-private accessibility. Default members are accessible within the same package but not from classes in different packages, even subclasses. It provides a level of encapsulation within the package.
Access modifiers can be applied to classes, inner classes, constructors, methods, and variables. By specifying an appropriate access modifier, you control the visibility and accessibility of class members, ensuring encapsulation, information hiding, and proper separation of concerns in your code.
Q46. What is a JIT Compiler?
A JIT (Just-In-Time) compiler, also known as a dynamic compiler, is a component of a Java Virtual Machine (JVM) or other runtime environments that compiles bytecode into machine code at runtime, just before it is executed. The primary purpose of a JIT compiler is to improve the performance of an application by optimizing the execution of frequently executed code.
Here's how a JIT compiler works in the context of Java:
-
Java bytecode: Java source code is compiled into platform-independent bytecode, which is executed by the JVM. Bytecode is a low-level representation of Java code that is closer to machine code than the original source code.
-
Interpreter: Initially, the JVM interprets the bytecode line by line, executing it one instruction at a time. This interpretation process is relatively slower compared to executing machine code directly.
-
Profiling: While interpreting the bytecode, the JVM collects runtime information about the application's execution. It gathers data such as the most frequently executed methods, hotspots, and frequently accessed data structures.
-
Just-In-Time compilation: Based on the profiling information, the JIT compiler identifies sections of the bytecode that are executed frequently (known as "hotspots"). It then selectively compiles these hotspots into highly optimized machine code.
-
Machine code execution: Once the JIT compiler has compiled a hotspot into machine code, subsequent executions of that section of code use the compiled machine code, which is executed directly by the CPU. This results in faster execution since machine code is typically more efficient than interpreted bytecode.
Q47. What is the meaning of the term "aggregation"?
In software development and object-oriented programming, "aggregation" refers to a relationship between two classes where one class contains a reference to another class as part of its own structure. It represents a "has-a" or "part-of" relationship, where an object of one class is composed of or contains objects of another class.
Aggregation is a form of association that indicates a whole-part relationship between classes. It implies that the contained objects have an independent existence and can exist even if the containing object is destroyed.
Here are some key points to understand about aggregation:
-
Whole-part relationship: Aggregation represents a relationship where a class (the "whole") contains objects of another class (the "part") as its members or attributes. The part objects are not owned by the whole object and can exist independently.
-
Multiplicity: Aggregation can have different multiplicities to specify the number of part objects that can be associated with a whole object. It can be one-to-one, one-to-many, or many-to-many, depending on the design requirements.
-
Lifespan: In aggregation, the lifespan of the contained objects can be different from the containing object. The contained objects can exist before and after the existence of the containing object.
-
Code reusability and modularity: Aggregation promotes code reusability by allowing objects to be composed and reused in different contexts. It enhances modularity by separating concerns and allowing objects to encapsulate related functionality.
-
UML representation: Aggregation is typically represented in UML (Unified Modeling Language) diagrams using a diamond-shaped arrowhead line, pointing from the whole class to the part class.
Q48. What are JAR files?
JAR (Java Archive) files are a common file format in Java used for packaging and distributing Java libraries, classes, and associated resources. A JAR file combines multiple Java class files, metadata, and resources into a single compressed file, making it convenient for distribution, deployment, and sharing of Java applications or libraries.
Here are some key points to understand about JAR files:
-
Packaging format: A JAR file is essentially a ZIP file with a specific structure and a .jar extension. It contains compiled Java class files (.class), resource files, configuration files, and other relevant files for a Java application or library.
-
Compression: JAR files can be compressed to reduce their file size, making them easier to distribute and download over the network. The compression is lossless, meaning the contents can be extracted back to their original form.
-
Executable JARs: JAR files can also be created as executable JARs, which include a manifest file (META-INF/MANIFEST.MF) that specifies the main class to be executed when the JAR is launched. Executable JARs simplify the execution of Java applications by allowing them to be run directly from the command line or by double-clicking the JAR file.
-
Classpath and dependencies: JAR files are commonly used to package libraries or dependencies that a Java application requires. By including the necessary JAR files in the classpath, an application can access the classes and resources provided by those libraries.
-
Packaging and deployment: JAR files are widely used for packaging Java applications, applets, plugins, and libraries for distribution. They provide a standardized way to bundle Java code and resources, ensuring easy deployment and installation across different platforms.
-
Tools and utilities: Java development tools, such as the JDK's jar command or build tools like Apache Maven and Gradle, provide the functionality to create, extract, and manage JAR files. Integrated development environments (IDEs) also offer support for JAR file creation and management.
Q49. Can you explain negotiation in competitive programming?
In the context of competitive programming, negotiation does not have the same meaning as in traditional negotiation processes between parties. Competitive programming is a sport-like activity where participants solve algorithmic and coding problems in a time-limited competition setting. The focus is on problem-solving skills, efficiency, and algorithmic optimization rather than negotiation between parties.
In competitive programming, participants are typically presented with a set of programming problems and a specific time frame within which they need to solve as many problems as possible. The problems are designed to test the contestants' understanding of algorithms, data structures, and problem-solving techniques.
The negotiation aspect in competitive programming relates more to the strategic decision-making process during the competition. Contestants may need to make decisions on problem selection, time allocation for each problem, and trade-offs between attempting more challenging problems or solving easier ones to accumulate points. These decisions are made individually and do not involve negotiation between parties.
Competitive programming competitions, such as ACM ICPC, Google Code Jam, or International Olympiad in Informatics (IOI), focus on individual or team performance based on problem-solving skills and efficient algorithm implementation. Participants aim to solve problems within the given constraints and optimize their solutions to achieve the best possible performance.
Q50. What is the meaning of the term enumeration?
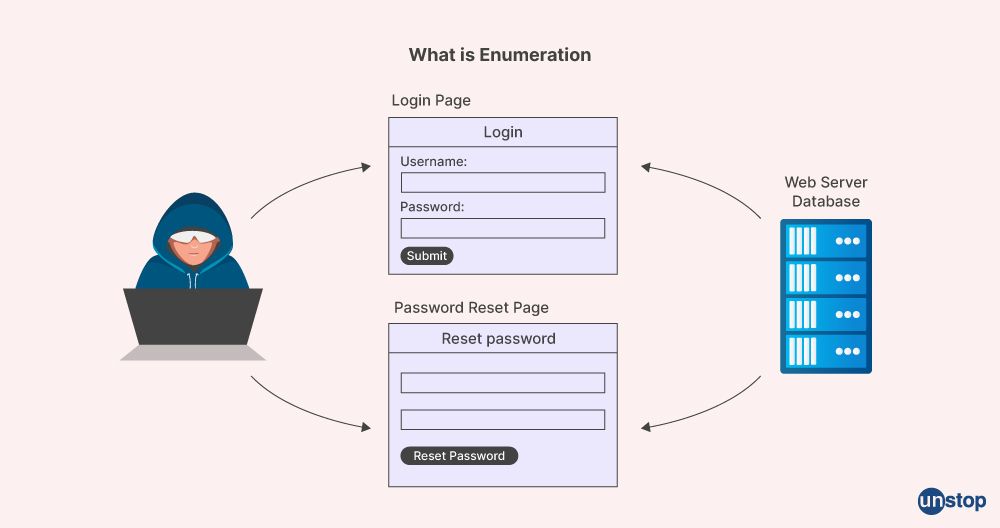
In programming, an "enumeration" (often referred to as an "enum") is a data type that consists of a set of named values. It is used to represent a fixed number of possible values or options for a variable. An enumeration defines a discrete list of constants, and each constant is typically given a meaningful name.
Here are some key points to understand about enumerations:
-
Representing choices or options: Enumerations are commonly used when there is a limited and predefined set of possible values that a variable can take. For example, days of the week, months of the year, or colors can be represented as enumerations.
-
Named constants: Each value in an enumeration is assigned a name that represents its meaning. These named constants provide a more readable and self-explanatory way to refer to the possible values, rather than using numeric or arbitrary values.
-
Type safety: Enumerations provide type safety because the compiler can check that values assigned to an enum variable belong to the defined set of constants. This helps catch potential errors at compile time, such as assigning an invalid value.
-
Enumerated values as objects: In some programming languages, enumerations are treated as objects, allowing additional properties, methods, or behaviors to be associated with each enumerated value. This allows for more flexibility and extensibility in certain situations.
-
Iteration and comparisons: Enumerations often provide built-in functionality for iterating over the defined constants and comparing them. This can simplify operations that involve iterating through all possible values or making comparisons between enum values.
-
Language support: Enumerations are supported in various programming languages, including Java, C#, C++, Python, and others. The syntax and features related to enumerations may vary slightly between languages.
Q51. What are "implicit objects"?
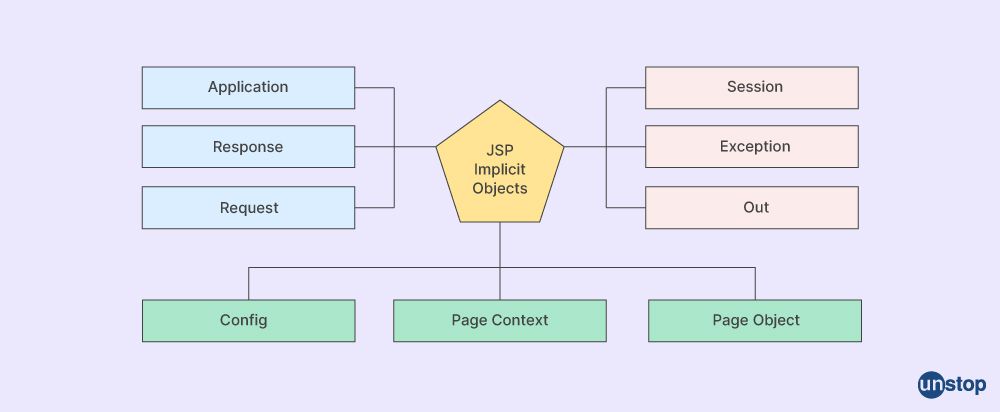
In the context of Java web programming, "implicit objects" refer to a set of predefined objects that are automatically available to the developers within the scope of a JavaServer Pages (JSP) page. These objects are created and managed by the JavaServer Pages implementation, and they provide access to various functionalities and information related to the JSP environment.
The implicit objects in JSP are accessible without the need for explicit declaration or initialization. They can be directly referenced in JSP expressions, scriptlets, or JSP tags.
The specific set of implicit objects may vary depending on the version of JSP specification being used and the web container implementation. However, some commonly available implicit objects in JSP include:
-
request: Represents the HttpServletRequest object, providing access to the request parameters, headers, session, and other request-related information.
-
response: Represents the HttpServletResponse object, enabling control over the response being sent back to the client.
-
session: Represents the HttpSession object, allowing access to session attributes and session-related operations.
-
application: Represents the ServletContext object, providing access to the application-wide context parameters, attributes, and resources.
-
out: Represents the JspWriter object, used to write output to the response stream.
-
pageContext: Represents the PageContext object, which serves as a gateway to various JSP-related objects and functionalities.
-
config: Represents the ServletConfig object, providing access to the configuration information of the servlet.
-
exception: Represents any exception object that occurred during the execution of the JSP page.
These implicit objects are automatically created and made available by the JSP container during the execution of a JSP page. They serve as a convenient means to access and manipulate various aspects of the JSP environment without the need for explicit object instantiation or retrieval.
We hope these competitive coding questions with solutions boost your confidence to participate in competitive programming challenges. So keep practicing and #BeUnstoppable.
Suggested Reads:
- How To Run C Program | A Step-by-Step Explanation (With Examples)
- Find In Strings C++ | Examples To Find Substrings, Character & More!
- Typedef In C++ | Syntax, Application & How To Use It (With Examples)
- What Is GitHub? An Introduction, How-To Use It, Components & More!
- History Of C++ | Detailed Explanation (With Timeline Infographic)
Login to continue reading
And access exclusive content, personalized recommendations, and career-boosting opportunities.
Don't have an account? Sign up
Never miss an
Update

Featured Opportunities
Top-Rated Practice by Students





Subscribe
to our newsletter



Comments
Add comment