

Asian Paints Alchemy 2026
Company Interview Questions for Freshers
- TCS Technical Interview Questions & Answers
- TCS Managerial Interview Questions & Answers
- TCS HR Interview Questions & Answers
- Overview of Cognizant Recruitment Process
- Cognizant Interview Questions: Technical
- Cognizant Interview Questions: HR Round
- Overview of Wipro Technologies Recruitment Rounds
- Wipro Interview Questions
- Technical Round
- HR Round
- Online Assessment Sample Questions
- Frequently Asked Questions
- Overview of Google Recruitment Process
- Google Interview Questions: Technical
- Google Interview Questions: HR round
- Interview Preparation Tips
- About Google
- Deloitte Technical Interview Questions
- Deloitte HR Interview Questions
- Deloitte Recruitment Process
- Technical Interview Questions and Answers
- Level 1 difficulty
- Level 2 difficulty
- Level 3 difficulty
- Behavioral Questions
- Eligibility Criteria for Mindtree Recruitment
- Mindtree Recruitment Process: Rounds Overview
- Skills required to crack Mindtree interview rounds
- Mindtree Recruitment Rounds: Sample Questions
- About Mindtree
- Preparing for Microsoft interview questions
- Microsoft technical interview questions
- Microsoft behavioural interview questions
- Aptitude Interview Questions
- Technical Interview Questions
- Easy
- Intermediate
- Hard
- HR Interview Questions
- Eligibility criteria
- Recruitment rounds & assessments
- Tech Mahindra interview questions - Technical round
- Tech Mahindra interview questions - HR round
- Hiring process at Mphasis
- Mphasis technical interview questions
- Mphasis HR interview questions
- About Mphasis
- Technical interview questions
- HR interview questions
- Recruitment process
- About Virtusa
- Goldman Sachs Interview Process
- Technical Questions for Goldman Sachs Interview
- Sample HR Question for Goldman Sachs Interview
- About Goldman Sachs
- Nagarro Recruitment Process
- Nagarro HR Interview Questions
- Nagarro Aptitude Test Questions
- Nagarro Technical Test Questions
- About Nagarro
- PwC Recruitment Process
- PwC Technical Interview Questions: Freshers and Experienced
- PwC Interview Questions for HR Rounds
- PwC Interview Preparation
- Frequently Asked Questions
- EY Technical Interview Questions (2023)
- EY Interview Questions for HR Round
- About EY
- Morgan Stanley Recruitment Process
- HR Questions for Morgan Stanley Interview
- HR Questions for Morgan Stanley Interview
- About Morgan Stanley
- Recruitment Process at Flipkart
- Technical Flipkart Interview Questions
- Code-Based Flipkart Interview Questions
- Sample Flipkart Interview Questions- HR Round
- Conclusion
- FAQs
- Recruitment Process at Paytm
- Technical Interview Questions for Paytm Interview
- HR Sample Questions for Paytm Interview
- About Paytm
- Most Probable Accenture Interview Questions
- Accenture Technical Interview Questions
- Accenture HR Interview Questions
- Amazon Recruitment Process
- Amazon Interview Rounds
- Common Amazon Interview Questions
- Amazon Interview Questions: Behavioral-based Questions
- Amazon Interview Questions: Leadership Principles
- Company-specific Amazon Interview Questions
- 43 Top Technical/ Coding Amazon Interview Questions
- Juspay Recruitment: Stages and Timeline
- Juspay Interview Questions and Answers
- How to prepare for Juspay interview questions
- Prepare for the Juspay Interview: Stages and Timeline
- Frequently Asked Questions
- Adobe Interview Questions - Technical
- Adobe Interview Questions - HR
- Recruitment Process at Adobe
- About Adobe
- Cisco technical interview questions
- Sample HR interview questions
- The recruitment process at Cisco
- About Cisco
- JP Morgan interview questions (Technical round)
- JP Morgan interview questions HR round)
- Recruitment process at JP Morgan
- About JP Morgan
- Wipro Elite NTH: Selection Process
- Wipro Elite NTH Technical Interview Questions
- Wipro Elite NTH Interview Round- HR Questions
- BYJU's BDA Interview Questions
- BYJU's SDE Interview Questions
- BYJU's HR Round Interview Questions
- A Quick Overview of the KPMG Recruitment Process
- Technical Questions for KPMG Interview
- HR Questions for KPMG Interview
- About KPMG
- DXC Technology Interview Process
- DCX Technical Interview Questions
- Sample HR Questions for DXC Technology
- About DXC Technology
- Recruitment Process at PayPal
- Technical Questions for PayPal Interview
- HR Sample Questions for PayPal Interview
- About PayPal
- Capgemini Recruitment Rounds
- Capgemini Interview Questions: Technical round
- Capgemini Interview Questions: HR round
- Preparation tips
- FAQs
- Technical interview questions for Siemens
- Sample HR questions for Siemens
- The recruitment process at Siemens
- About Siemens
- HCL Technical Interview Questions
- HR Interview Questions
- HCL Technologies Recruitment Process
- List of EPAM Interview Questions for Technical Interviews
- About EPAM
- Atlassian Interview Process
- Top Skills for Different Roles at Atlassian
- Atlassian Interview Questions: Technical Knowledge
- Atlassian Interview Questions: Behavioral Skills
- Atlassian Interview Questions: Tips for Effective Preparation
- Walmart Recruitment Process
- Walmart Interview Questions and Sample Answers (HR Round)
- Walmart Interview Questions and Sample Answers (Technical Round)
- Tips for Interviewing at Walmart and Interview Preparation Tips
- Frequently Asked Questions
- Uber Interview Questions For Engineering Profiles: Coding
- Technical Uber Interview Questions: Theoretical
- Uber Interview Question: HR Round
- Uber Recruitment Procedure
- About Uber Technologies Ltd.
- Intel Technical Interview Questions
- Computer Architecture Intel Interview Questions
- Intel DFT Interview Questions
- Intel Interview Questions for Verification Engineer Role
- Recruitment Process Overview
- Important Accenture HR Interview Questions
- Points to remember
- What is Selenium?
- What are the components of the Selenium suite?
- Why is it important to use Selenium?
- What's the major difference between Selenium 3.0 & Selenium 2.0?
- What is Automation testing and what are its benefits?
- What are the benefits of Selenium as an Automation Tool?
- What are the drawbacks to using Selenium for testing?
- Why should Selenium not be used as a web application or system testing tool?
- Is it possible to use selenium to launch web browsers?
- What does Selenese mean?
- What does it mean to be a locator?
- Identify the main difference between "assert", and "verify" commands within Selenium
- What does an exception test in Selenium mean?
- What does XPath mean in Selenium? Describe XPath Absolute & XPath Relation
- What is the difference in Xpath between "//"? and "/"?
- What is the difference between "type" and the "typeAndWait" commands within Selenium?
- Distinguish between findElement() & findElements() in context of Selenium
- How long will Selenium wait before a website is loaded fully?
- What is the difference between the driver.close() and driver.quit() commands in Selenium?
- Describe the different navigation commands that Selenium supports
- What is Selenium's approach to the same-origin policy?
- Explain the difference between findElement() in Selenium and findElements()
- Explain the pause function in SeleniumIDE
- Explain the differences between different frameworks and how they are connected to Selenium's Robot Framework
- What are your thoughts on the Page Object Model within the context of Selenium
- What are your thoughts on Jenkins?
- What are the parameters that selenium commands come with a minimum?
- How can you tell the differences in the Absolute pathway as well as Relative Path?
- What's the distinction in Assert or Verify declarations within Selenium?
- What are the points of verification that are in Selenium?
- Define Implicit wait, Explicit wait, and Fluent
- Can Selenium manage windows-based pop-ups?
- What's the definition of an Object Repository?
- What is the main difference between obtainwindowhandle() as well as the getwindowhandles ()?
- What are the various types of Annotations that are used in Selenium?
- What is the main difference in the setsSpeed() or sleep() methods?
- What is the way to retrieve the alert message?
- How do you determine the exact location of an element on the web?
- Why do we use Selenium RC?
- What are the benefits or advantages of Selenium RC?
- Do you have a list of the technical limitations when making use of Selenium RC? Selenium RC?
- What's the reason to utilize the TestNG together with Selenium?
- What Language do you prefer to use to build test case sets in Selenium?
- What are Start and Breakpoints?
- What is the purpose of this capability relevant in relation to Selenium?
- When do you use AutoIT?
- Do you have a reason why you require Session management in Selenium?
- Are you able to automatize CAPTCHA?
- How can we launch various browsers on Selenium?
- Why should you select Selenium rather than QTP (Quick Test Professional)?
- Airbus Interview Questions and Answers: HR/ Behavioral
- Industry/ Company-Specific Airbus Interview Questions
- Airbus Interview Questions and Answers: Aptitude
- Airbus Software Engineer Interview Questions and Answers: Technical
- Importance of Spring Framework
- Spring Interview Questions (Basic)
- Advanced Spring Interview Questions
- C++ Interview Questions and Answers: The Basics
- C++ Interview Questions: Intermediate
- C++ Interview Questions And Answers With Code Examples
- C++ Interview Questions and Answers: Advanced
- Test Your Skills: Quiz Time
- MBA Interview Questions: B.Com Economics
- B.Com Marketing
- B.Com Finance
- B.Com Accounting and Finance
- Business Studies
- Chartered Accountant
- Q1. Please tell us something about yourself/ Introduce yourself to us.
- Q2. Describe yourself in one word.
- Q3. Tell us about your strengths and weaknesses.
- Q4. Why did you apply for this job/ What attracted you to this role?
- Q5. What are your hobbies?
- Q6. Where do you see yourself in five years OR What are your long-term goals?
- Q7. Why do you want to work with this company?
- Q8. Tell us what you know about our organization
- Q9. Do you have any idea about our biggest competitors?
- Q10. What motivates you to do a good job?
- Q11. What is an ideal job for you?
- Q12. What is the difference between a group and a team?
- Q13. Are you a team player/ Do you like to work in teams?
- Q14. Are you good at handling pressure/ deadlines?
- Q15. When can you start?
- Q16. How flexible are you regarding overtime?
- Q17. Are you willing to relocate for work?
- Q18. Why do you think you are the right candidate for this job?
- Q19. How can you be an asset to the organization?
- Q20. What is your salary expectation?
- Q21. How long do you plan to remain with this company?
- Q22. What is your objective in life?
- Q23. Would you like to pursue your Master's degree anytime soon?
- Q24. How have you planned to achieve your career goal?
- Q25. Can you tell us about your biggest achievement in life?
- Q26. What was the most challenging decision you ever made?
- Q27. What kind of work environment do you prefer to work in?
- Q28. What is the difference between a smart worker and a hard worker?
- Q29. What will you do if you don't get hired?
- Q30. Tell us three things that are most important for you in a job.
- Q31. Who is your role model and what have you learned from him/her?
- Q32. In case of a disagreement, how do you handle the situation?
- Q33. What is the difference between confidence and overconfidence?
- Q34. If you have more than enough money in hand right now, would you still want to work?
- Q35. Do you have any questions for us?
- Interview Tips for Freshers
- Tell me about yourself
- What are your greatest strengths?
- What are your greatest weaknesses?
- Tell me about something you did that you now feel a little ashamed of
- Why are you leaving (or did you leave) this position??
- 15+ resources for preparing most-asked interview questions
- CoCubes Interview Process Overview
- Common CoCubes Interview Questions
- Key Areas to Focus on for CoCubes Interview Preparation
- Conclusion
- Frequently Asked Questions (FAQs)
- Data Analyst Interview Questions With Answers
- About Data Analyst
50+ Adobe Interview Questions With Detailed Answers (2026)
Whether you are a fresher or an experienced professional, tech giant Adobe is everyone's dream company to work with. However, to acquire a position at such a company, you have to clear an extensive interview process; that is why we have created this list of questions here.
List of Adobe Technical Interview Questions with Answers
Let’s check out some important technical interview questions that are asked during an Adobe interview, so you can be well prepared -
1. What are some ways to determine whether a binary tree is also a binary search tree?
To determine if a binary tree is a binary search tree, you can use the following approaches:
-
Inorder traversal: Traverse the tree in an inorder fashion, and maintain the previously visited node's value. Compare the current node's value with the previous one, and if the current node's value is less than or equal to the previous one, then it's not a binary search tree.
-
Recursive approach: Write a recursive function that checks if the left subtree is a binary search tree and the right subtree is also a binary search tree, and the current node's value is greater than all the values in the left subtree and less than all the values in the right subtree.
-
Min/Max approach: In this approach, we maintain a min and a max value for each node while traversing the tree. We initialize the root node's min and max value to negative infinity and positive infinity, respectively. Then we traverse the left subtree, updating the max value to the parent's value and the min value to negative infinity. Similarly, we traverse the right subtree, updating the min value to the parent's value and the max value to positive infinity. If a node's value is outside its min/max range, then it's not a binary search tree.
2. Explain in detail how the input string is utilized.
The way input strings are utilized depends on the context in which they are used. However, in general, an input string is a sequence of characters or symbols that are provided as input to a program, algorithm, or function. The program or function then processes the input string in some way and produces an output. For example, in Python, you can define a function that takes an input string as an argument and then processes it:
def count_vowels(input_string):
vowels = "aeiou"
count = 0
for char in input_string:
if char in vowels:
count += 1
return count
ZGVmIGNvdW50X3Zvd2VscyhpbnB1dF9zdHJpbmcpOgp2b3dlbHMgPSAiYWVpb3UiCmNvdW50ID0gMApmb3IgY2hhciBpbiBpbnB1dF9zdHJpbmc6CmlmIGNoYXIgaW4gdm93ZWxzOgpjb3VudCArPSAxCnJldHVybiBjb3VudA==
3. What are C++'s built-in functions or default functions?
C++ has several built-in functions or default functions that are part of the C++ Standard Library. These functions are included in the header files that come with the C++ compiler and can be used in C++ programs without the need to write additional code.
Here are some examples of the most commonly used built-in functions in C++:
- Input/Output Functions:
cin- reads input from the consolecout- writes output to the consolecerr- writes error output to the consolegetline()- reads a line of input from the console
- String Functions:
strlen()- returns the length of a stringstrcpy()- copies one string to anotherstrcat()- concatenates two stringsstrcmp()- compares two strings
- Math Functions:
abs()- returns the absolute value of a numbersqrt()- returns the square root of a numberpow()- returns a number raised to a powerrand()- generates a random number
- Memory Management Functions:
new- allocates memory dynamicallydelete- frees dynamically allocated memorymalloc()- allocates a block of memoryfree()- frees a block of memory
4. What is meant by the expression pointer addition?
Pointer addition is a concept in C++ and other programming languages that allows you to perform arithmetic operations on pointers. In C++, a pointer is a variable that stores the memory address of another variable. Pointer arithmetic allows you to manipulate these memory addresses in a way that is useful for a variety of programming tasks.
Pointer addition involves adding or subtracting an integer value to/from a pointer. The integer value is scaled by the size of the data type that the pointer points to. For example, if you have a pointer to an integer (which is typically 4 bytes in size), adding 1 to the pointer will increment it by 4 bytes (not 1 byte). Here's an example of pointer addition in C++:
int numbers[5] = {1, 2, 3, 4, 5};
int* p = numbers; // p points to the first element of the array
// Increment the pointer by 2, which moves it 2 integers forward in the array
p = p + 2;
// Print the value that the pointer now points to
std::cout << *p << std::endl; // Output: 3
aW50IG51bWJlcnNbNV0gPSB7MSwgMiwgMywgNCwgNX07CmludCogcCA9IG51bWJlcnM7IC8vIHAgcG9pbnRzIHRvIHRoZSBmaXJzdCBlbGVtZW50IG9mIHRoZSBhcnJheQoKLy8gSW5jcmVtZW50IHRoZSBwb2ludGVyIGJ5IDIsIHdoaWNoIG1vdmVzIGl0IDIgaW50ZWdlcnMgZm9yd2FyZCBpbiB0aGUgYXJyYXkKcCA9IHAgKyAyOwoKLy8gUHJpbnQgdGhlIHZhbHVlIHRoYXQgdGhlIHBvaW50ZXIgbm93IHBvaW50cyB0bwpzdGQ6OmNvdXQgPDwgKnAgPDwgc3RkOjplbmRsOyAvLyBPdXRwdXQ6IDM=
5. What is meant by the term deep copy when referring to linked lists?
In programming, a linked list is a data structure that consists of a sequence of nodes, where each node contains a value and a reference to the next node in the list. When you create a copy of a linked list, you can either create a shallow copy or a deep copy. A deep copy, on the other hand, creates a new copy of the entire linked list, including all its nodes and values. This means that the copy is completely independent of the original list, and any modifications made to one list will not affect the other list.
Deep copy is often used when you need to modify one copy of the linked list without affecting the other. In the context of linked lists, a deep copy involves traversing the entire original list and creating a new node for each node in the original list. Each new node is allocated its own memory space and its copy of the value stored in the original node. The new nodes are then linked together to form a new, independent copy of the original list.
Here is an example of how to perform a deep copy of a linked list in C++:
struct Node {
int data;
Node* next;
};
Node* deepCopy(Node* head) {
if (head == nullptr) {
return nullptr;
}
Node* newHead = new Node{head->data, nullptr};
Node* newTail = newHead;
Node* curr = head->next;
while (curr != nullptr) {
newTail->next = new Node{curr->data, nullptr};
newTail = newTail->next;
curr = curr->next;
}
return newHead;
}
c3RydWN0IE5vZGUgewppbnQgZGF0YTsKTm9kZSogbmV4dDsKfTsKCk5vZGUqIGRlZXBDb3B5KE5vZGUqIGhlYWQpIHsKaWYgKGhlYWQgPT0gbnVsbHB0cikgewpyZXR1cm4gbnVsbHB0cjsKfQpOb2RlKiBuZXdIZWFkID0gbmV3IE5vZGV7aGVhZC0+ZGF0YSwgbnVsbHB0cn07Ck5vZGUqIG5ld1RhaWwgPSBuZXdIZWFkOwpOb2RlKiBjdXJyID0gaGVhZC0+bmV4dDsKd2hpbGUgKGN1cnIgIT0gbnVsbHB0cikgewpuZXdUYWlsLT5uZXh0ID0gbmV3IE5vZGV7Y3Vyci0+ZGF0YSwgbnVsbHB0cn07Cm5ld1RhaWwgPSBuZXdUYWlsLT5uZXh0OwpjdXJyID0gY3Vyci0+bmV4dDsKfQpyZXR1cm4gbmV3SGVhZDsKfQ==
6. Do you have the capability of creating an array of integers?
The array's data type is determined based on the element type, which in turn is determined by the data type of each element that makes up the array. An array of user-defined data types can indeed be created in the same way as an array of integers can be created. Other primitive data types, such as char, float, double, and so on, can also be used (objects of a class).
For example, in C++, you can create an array of integers by declaring a variable of type int followed by square brackets containing the desired size of the array. Here's an example:
int myArray[5]; // creates an array of 5 integers
You can also initialize the elements of the array at the time of creation using curly braces {}. Here's an example:
int myArray[] = {10, 20, 30, 40, 50}; // creates an array of 5 integers and initializes it with the given values
7. When does the overflow of the stack take place?
The stack is a region of memory in a computer's RAM (random access memory) that is used to store data and metadata for the current execution context of a program. This includes things like function call frames, local variables, and other data that is necessary for the execution of the program.
Stack overflow occurs when the stack becomes full and there is no more space to store data. This can happen for a few different reasons:
-
Recursive functions: When a function calls itself repeatedly, each call creates a new stack frame on top of the previous one. If there are too many recursive calls, the stack can become full and cause a stack overflow.
-
Large stack allocations: If you allocate a large amount of memory on the stack for arrays, structs, or other data structures, it can quickly exhaust the available space on the stack and cause a stack overflow.
-
Infinite loops: If you have an infinite loop that keeps pushing data onto the stack without ever popping it off, the stack can eventually become full and cause a stack overflow.
When the stack overflows, it can cause unpredictable behavior and crash the program. In some cases, it can even cause a system-wide crash or hang. To prevent stack overflow, you should be mindful of your memory usage and avoid allocating too much memory on the stack.
-
What is the difference between a typedef and a macro?
Both typedef and macros are used in programming to create aliases for existing types or values, but they differ in their implementation and functionality.
A typedef creates a new name for an existing type. It is a keyword in C and C++ that allows you to define a new type based on an existing type. Here's an example in C++:
typedef int myInt; // creates a new type name "myInt" for the type "int"
A macro, on the other hand, is a preprocessor directive that replaces a certain sequence of code with another sequence of code before the compiler actually compiles the program. Macros can be used to define constants or to perform text substitution. Here's an example of a macro in C++:
#define PI 3.1415926 // defines a macro for the value of pi
-
How does one express a thing using binary representation?
Binary is a base-2 numeral system that uses only two symbols, typically "0" and "1", to represent numbers, letters, and other characters. To express a thing using binary representation, you need to convert its value into binary format. Here's how you can do that:
- Convert the thing's value into binary format: To do this, you need to divide the thing's value by 2 and keep track of the remainders until the quotient is zero. The remainders will be the binary digits of the thing's value.
-
Pad the binary representation: If the binary representation of the thing's value has fewer digits than you need, you need to pad it with zeros on the left until you have the desired number of digits. For example, if you want to represent the binary number 101 in 8-bit format, you need to pad it with three zeros on the left, so it becomes 00000101.
-
Represent the binary digits using the appropriate symbols: In most cases, binary digits are represented using the symbols "0" and "1". For example, the binary number 101010 can be represented using the symbols 101010 or 0b101010.
-
Key differences between the left subtree and the right subtree?
In a binary tree data structure, each node can have at most two children, which are referred to as the left child and the right child. The left and right subtrees of a binary tree refer to the sub-trees rooted at the left and right child of a given node, respectively. Here are some key differences between the left subtree and the right subtree:
-
Relative position: The left subtree of a node is located to the left of the node, while the right subtree is located to the right of the node.
-
Structure: The left subtree and the right subtree can have different structures. For example, the left subtree might be a complete binary tree, while the right subtree might be a degenerate tree.
-
Size: The left subtree and the right subtree can have different numbers of nodes. In some cases, one subtree might be much larger than the other.
-
Traversal order: When traversing a binary tree, the order in which the left and right subtrees are visited can affect the output of the traversal algorithm. For example, in a pre-order traversal, the left subtree is visited before the right subtree, while in a post-order traversal, the right subtree is visited before the left subtree.
-
Content: The left subtree and the right subtree can contain different values. In some cases, the values might be related in some way, such as in a binary search tree, where the values in the left subtree are smaller than the value of the root node, and the values in the right subtree are larger.
-
What does it imply when it says “static void main(String args[])”?
In Java, the entry point of a program is the main() method. When you write a Java program, you need to define a main() method that Java will run when the program starts. Here's what each part of the declaration static void main(String args[]) means:
public: This is an access modifier that indicates that the method can be called from anywhere in the program.static: This indicates that the method is a class method (also known as a static method) that belongs to the class rather than to a specific instance of the class.void: This indicates that the method does not return a value.main: This is the name of the method. By convention, the entry point method in Java is calledmain.String args[]: This is a parameter that the method takes. It is an array of strings that holds any command line arguments that were passed to the program when it was started. In other words, theargsparameter allows you to pass data to the program when it starts.
So, when you see the declaration static void main(String args[]), it means that you are defining the main() method for your Java program. The method is a static method that does not return a value, and it takes an array of strings as a parameter that can be used to pass data to the program.
-
How can one go about searching for anything inside a 2D bit matrix?
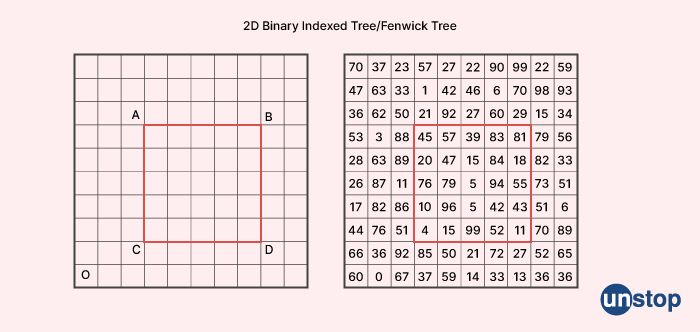
Searching for anything inside a 2D bit matrix involves finding a specific pattern of 0s and 1s within the matrix. Here are some general steps that you can follow to search for a pattern in a 2D bit matrix:
-
Define the pattern you want to search: To search for a pattern in a 2D bit matrix, you first need to define the pattern you want to search for. This pattern is typically represented as a 2D bit matrix as well.
-
Traverse the 2D bit matrix: Traverse the 2D bit matrix row by row, and for each row, traverse the columns from left to right.
-
Compare the pattern with the elements of the 2D bit matrix: At each position in the 2D bit matrix, compare the corresponding elements of the pattern with the elements of the 2D bit matrix. If the elements match, continue to the next position. If the elements do not match, move on to the next position in the 2D bit matrix.
-
Repeat until the end of the matrix is reached: Continue traversing the matrix until you have searched all of the rows and columns.
-
Return the position(s) of the match(es): If you find a match, return the position(s) where the match occurred. Depending on the specifics of the search problem, you may be looking for a single match, multiple matches, or some other criteria.
-
What does it mean for a subarray to be contiguous?
A subarray is a subset of an array that consists of consecutive elements of the original array. A subarray is said to be contiguous if the elements that make up the subarray are adjacent to each other in the original array and occur in sequential order. For example, consider the array arr = [1, 2, 3, 4, 5, 6]. The subarray [2, 3, 4] is contiguous because the elements 2, 3, and 4 appear next to each other in the original array and are in sequential order. However, the subarray [1, 3, 5] is not contiguous because the elements are not adjacent to each other in the original array and are not in sequential order.
The concept of a contiguous subarray is important in many programming problems, particularly those that involve searching for or manipulating subsets of an array. For example, many algorithms for finding the maximum subarray or calculating prefix sums require the subarray to be contiguous in order to work correctly.
-
Talk about the importance of shorthands in C++.

Shorthand operators in C++ provide a way to operate and an assignment in a single statement. They are a shorthand way to write expressions that involve arithmetic or logical operations.
The importance of shorthand operators in C++ includes the following:
-
Conciseness: Shorthand operators allow you to write expressions in a more concise manner, which can make your code easier to read and understand. For example, instead of writing
a = a + 1, you can writea += 1. -
Efficiency: Shorthand operators can be more efficient than writing out the full expression. This is because the shorthand operator can often be optimized by the compiler to generate faster machine code.
-
Clarity: Shorthand operators can make code more clear and concise. They allow you to express an operation and an assignment in a single statement, which can make the code more readable and easier to understand.
-
Expressiveness: Shorthand operators provide an expressive way to write code. By using shorthand operators, you can make your code more concise and more expressive.
Some examples of shorthand operators in C++ include:
+=(addition and assignment)-=(subtraction and assignment)*=(multiplication and assignment)/=(division and assignment)%=(modulus and assignment)&=(bitwise AND and assignment)|=(bitwise OR and assignment)^=(bitwise XOR and assignment)<<=(left shift and assignment)>>=(right shift and assignment)
One click. Endless opportunities. Land your dream job today!
-
How are typedef and #define differently from one another?
typedef and #define are both used to define aliases or synonyms for existing types, variables, or expressions in C++. However, they have some key differences in how they work and how they are used.
The main differences between typedef and #define are:
-
Syntax: typedef is a C++ keyword that is used to define new type names, whereas #define is a preprocessor directive that is used to define macro substitutions.
-
Scope: typedef declarations have scope limited to the current block, while #define macro definitions have global scope throughout the entire program.
-
Type safety: typedef declarations are type-safe, meaning that the compiler will check the type of the aliased symbol at compile-time, while #define macro definitions are not type-safe and simply perform textual substitution at compile-time.
-
Debugging: typedef declarations can be easily debugged because they are actual type declarations that can be traced through the code, while #define macro definitions can be difficult to debug because they are simply textual substitutions that occur before compilation.
Here is an example that demonstrates the difference between typedef and #define :
typedef int myint;
#define MYINT int
int main() {
myint a = 5; // a is an alias for int
MYINT b = 10; // b is replaced with int at compile-time
return 0;
}
aW50IG1haW4oKSB7Cm15aW50IGEgPSA1OyAvLyBhIGlzIGFuIGFsaWFzIGZvciBpbnQKTVlJTlQgYiA9IDEwOyAvLyBiIGlzIHJlcGxhY2VkIHdpdGggaW50IGF0IGNvbXBpbGUtdGltZQpyZXR1cm4gMDsKfQ==
-
What does synchronization mean?
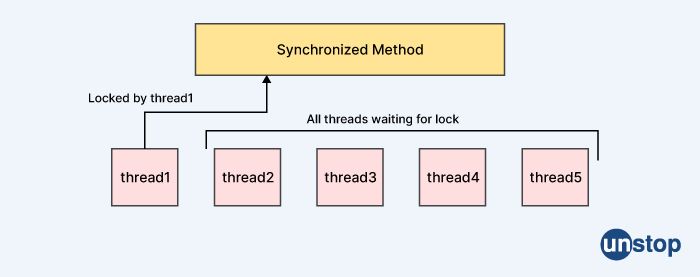
In computer science, synchronization refers to the coordination of multiple threads, processes, or tasks to achieve a specific goal. The goal of synchronization is to ensure that concurrent operations are executed in an orderly and predictable manner, to avoid conflicts or race conditions that can lead to incorrect results, data corruption, or other problems.
Synchronization is often necessary in multi-threaded or multi-process environments where multiple threads or processes are accessing shared resources, such as shared memory or files, and need to coordinate their actions to avoid conflicts. Without synchronization, multiple threads or processes may attempt to access the same resource simultaneously, leading to unpredictable behavior.
Synchronization mechanisms can take many forms, including locks, semaphores, monitors, barriers, and message passing. These mechanisms provide ways to control access to shared resources and to ensure that threads or processes execute in a coordinated manner.
-
What is a mutex?
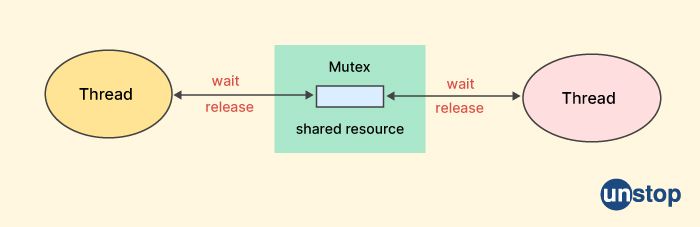
A mutex (short for mutual exclusion) is a synchronization object used to protect shared resources, such as shared memory, from simultaneous access by multiple threads or processes. It provides a way to ensure that only one thread or process can access the protected resource at a time, thus avoiding race conditions and data corruption.
A mutex works by providing a lock that a thread or process must acquire before accessing the protected resource. Once the lock is acquired, the thread or process can access the resource, and other threads or processes that try to acquire the lock will be blocked until the lock is released.
-
What's the difference between char a[]= and other characters?
In C and C++, the syntax char a[] = is used to declare an array of characters. The main difference between char a[] and other character types is that char a[] is an array that can hold multiple characters, while other character types can only hold a single character.
Here are some examples of different character types in C++:
char: A single characterwchar_t: A wide character, used for Unicode characterschar16_t: A 16-bit character, used for Unicode characterschar32_t: A 32-bit character, used for Unicode characters
In contrast, char a[] is an array of characters that can hold multiple characters. The size of the array is determined by the number of characters in the initializer, like this:
char a[] = "Hello, world!";
In this example, a is an array of characters that can hold the string "Hello, world!". The size of the array is automatically calculated by the compiler based on the length of the string.
Arrays of characters like char a[] are commonly used in C and C++ for representing strings, since strings are just sequences of characters. The char type is used because it is a single-byte type, which makes it efficient for working with strings in memory.
-
What is a static variable?
In C and C++, a static variable is a variable that is allocated for the entire duration of the program, rather than being allocated and deallocated each time the function that contains it is called. When a variable is declared as static, it retains its value between function calls and can only be accessed within the scope of the function in which it is declared.
Here's an example of a static variable in C++:
#include
void increment() {
static int count = 0; // Declare a static variable
count++; // Increment the count
std::cout << "Count is: " << count << std::endl;
}
int main() {
increment();
increment();
increment();
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgoKdm9pZCBpbmNyZW1lbnQoKSB7CnN0YXRpYyBpbnQgY291bnQgPSAwOyAvLyBEZWNsYXJlIGEgc3RhdGljIHZhcmlhYmxlCgpjb3VudCsrOyAvLyBJbmNyZW1lbnQgdGhlIGNvdW50CnN0ZDo6Y291dCA8PCAiQ291bnQgaXM6ICIgPDwgY291bnQgPDwgc3RkOjplbmRsOwp9CgppbnQgbWFpbigpIHsKaW5jcmVtZW50KCk7CmluY3JlbWVudCgpOwppbmNyZW1lbnQoKTsKcmV0dXJuIDA7Cn0=
In this example, count is declared as a static variable inside the increment() function. Each time increment() is called, count is incremented and its value is printed to the console.
-
In what way do static methods and variables serve a purpose?
Static methods and variables serve a purpose in several ways:
-
Global state: In some cases, it can be useful to have a variable or method that is accessible from anywhere in the program. By declaring a variable or method as static, it can be accessed from any part of the program without the need for passing it as an argument or including it as a member of a class. This can be useful for maintaining global state, such as counting the number of times a function is called, or storing configuration settings that are used throughout the program.
-
Memory management: Static variables are allocated once and retain their value throughout the entire lifetime of the program, which can help with memory management. By avoiding frequent allocation and deallocation of memory, static variables can help reduce the risk of memory leaks and improve performance.
-
Organization and encapsulation: Static methods and variables can be used to organize and encapsulate code. By grouping related functions and data together in a static class or namespace, it can be easier to understand and maintain the code. Additionally, static methods and variables can be used to hide implementation details and prevent other parts of the program from accessing them, improving the overall modularity and maintainability of the code.
-
Efficiency: In some cases, static methods and variables can be more efficient than their non-static counterparts. For example, in the case of static methods, there is no need to create an instance of a class to access the method, which can save memory and processing time. Additionally, in the case of static variables, there is no need to pass the variable as an argument or include it as a member of a class, which can save memory and improve performance.
-
What does it mean to talk about an "object"?
In programming, an object is a self-contained entity that contains both data and behavior. It is an instance of a class, which is a blueprint or template for creating objects.
An object can have one or more properties, which represent its data or state. For example, a person object might have properties such as name, age, and gender. These properties can be accessed and modified through methods or functions that are defined in the object's class.
In addition to data, an object can also have behavior, which is defined by methods. For example, a person object might have methods such as walk, talk, and eat, which define how the person behaves.
Objects can be created and manipulated dynamically during the execution of a program, and can interact with other objects in a variety of ways. Object-oriented programming (OOP) is a popular paradigm for programming that revolves around the concept of objects, and is widely used in languages such as Java, C++, Python, and Ruby.
-
What is a function object()?
A function object, also known as a functor, is an object that can be treated as a function. In other words, it's an instance of a class that has an overloaded operator() method, which allows the object to be called as if it were a function.
Using a function object can provide several advantages over a traditional function, such as allowing the function to maintain state between calls or allowing it to be passed as an argument to other functions.
Here's an example of a simple function object in C++:
class MyFunctor {
public:
int operator()(int x, int y) {
return x + y;
}
};
int main() {
MyFunctor adder;
int result = adder(3, 4); // result is now 7
return 0;
}
Y2xhc3MgTXlGdW5jdG9yIHsKcHVibGljOgppbnQgb3BlcmF0b3IoKShpbnQgeCwgaW50IHkpIHsKcmV0dXJuIHggKyB5Owp9Cn07CgppbnQgbWFpbigpIHsKTXlGdW5jdG9yIGFkZGVyOwppbnQgcmVzdWx0ID0gYWRkZXIoMywgNCk7IC8vIHJlc3VsdCBpcyBub3cgNwpyZXR1cm4gMDsKfQ==
-
In Java, what is the meaning of “keyword”?
In Java, a keyword is a reserved word that has a specific meaning and purpose within the programming language. These words cannot be used as identifiers (such as variable names or class names) because they are already predefined and have a specific functionality.
Java has a set of 50 keywords, some of which include:
public,private,protected: used to specify the access level of a class, method, or variableclass,interface: used to declare a new class or interfacestatic,final: used to declare static variables or constantsif,else,switch,case: used to control program flow and make decisionsfor,while,do-while: used to implement loopstry,catch,finally: used to handle exceptions
Using these keywords correctly is essential for writing correct and readable Java code. It's important to note that keywords are case-sensitive, meaning that public and Public are not the same thing in Java.
-
Why is it that Java does not enable multiple inheritances?
Java does not support multiple inheritances because it can lead to complex and ambiguous code.
Multiple inheritance allows a class to inherit from more than one superclass. This can lead to ambiguity when there are conflicts between the methods or variables inherited from different superclasses. For example, if two superclasses both have a method with the same name and signature, which method should the subclass inherit? This can lead to confusion and make the code difficult to maintain.
To avoid these issues, Java uses a different approach called interfaces. An interface defines a set of methods that a class must implement, but does not provide any implementation itself. This allows a class to inherit behavior from multiple interfaces without the risk of conflicts or ambiguity.
25. What is composition?
Composition is the practice of referencing a class within another class. Composition is the term used to describe when one thing includes another, and the contained object would be unable to exist without the container object. A more precise definition would be that composition is the process through which two or more things are grouped to create something more meaningful. Students in a class are an example. A student is not possible without a class. Students and teachers have a symbiotic relationship.
-
What does "super" mean in the Java programming language?
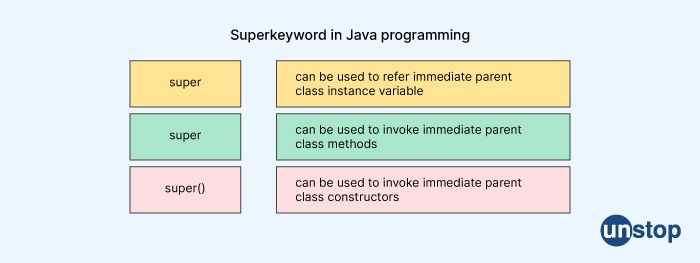
In Java, super is a keyword that is used to refer to the parent class or superclass of a class. It can be used to call a method or constructor of the parent class, or to refer to a variable or method defined in the parent class. When used with a method or constructor, super is used to call the corresponding method or constructor in the parent class.
For example, consider the following code:
public class Animal {
public Animal() {
System.out.println("Constructing an animal");
}
}
public class Dog extends Animal {
public Dog() {
super(); // call the constructor of the Animal class
System.out.println("Constructing a dog");
}
}
cHVibGljIGNsYXNzIEFuaW1hbCB7CnB1YmxpYyBBbmltYWwoKSB7ClN5c3RlbS5vdXQucHJpbnRsbigiQ29uc3RydWN0aW5nIGFuIGFuaW1hbCIpOwp9Cn0KCnB1YmxpYyBjbGFzcyBEb2cgZXh0ZW5kcyBBbmltYWwgewpwdWJsaWMgRG9nKCkgewpzdXBlcigpOyAvLyBjYWxsIHRoZSBjb25zdHJ1Y3RvciBvZiB0aGUgQW5pbWFsIGNsYXNzClN5c3RlbS5vdXQucHJpbnRsbigiQ29uc3RydWN0aW5nIGEgZG9nIik7Cn0KfQ==
-
What is object-oriented programming?
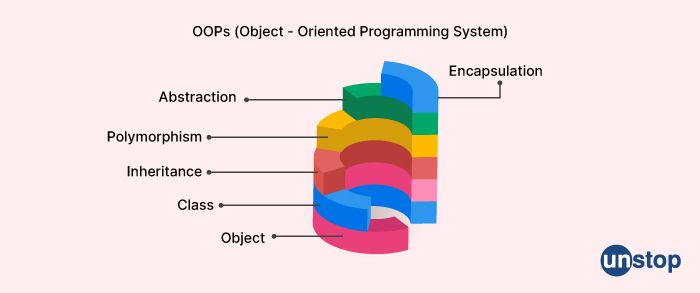
Object-oriented programming (OOP) is a programming paradigm that is based on the concept of "objects", which can contain data and code that operate on that data. In OOP, programs are designed by creating classes that define objects with certain properties and behaviors.
The main features of OOP include:
-
Encapsulation: the idea that objects should have their data and functionality hidden from other objects, and should only be accessed through well-defined interfaces.
-
Inheritance: the ability of classes to inherit properties and behaviors from other classes.
-
Polymorphism: the ability of objects to take on multiple forms, depending on the context in which they are used.
-
Abstraction: the process of simplifying complex systems by breaking them down into smaller, more manageable parts.
OOP is widely used in modern software development, especially for large-scale applications. Its benefits include improved code organization, reusability, and maintainability. By breaking down complex systems into smaller, more manageable objects, OOP makes it easier to understand and modify code over time.
-
What is a Java string pool?
The Java string pool is a special memory area in the Java Virtual Machine (JVM) that stores a pool of strings. Whenever a string is created in Java using a string literal, such as "Hello" , the JVM first checks the string pool to see if an identical string already exists in the pool. If it does, the JVM returns a reference to that string. If not, the JVM creates a new string in the pool and returns a reference to it.
The string pool is used to conserve memory by reducing the number of string objects that are created. Since strings are often used repeatedly in Java programs, it is more efficient to reuse existing string objects instead of creating new ones.
-
The term late binding is defined as what?
Late binding, also known as dynamic binding or run-time binding, is a programming technique in which the method or function to be called is determined at runtime, rather than at compile time.
In late binding, the specific implementation of a method or function is not known until the program is executed. This is in contrast to early binding, also known as static binding or compile-time binding, where the method or function to be called is determined at compile time based on the declared type of the object or variable.
Late binding is often used in object-oriented programming languages, where inheritance and polymorphism allow objects of different classes to be treated as instances of a common superclass.
-
Definition of dynamic method dispatch.
Dynamic method dispatch is a mechanism in object-oriented programming languages that allows a method call to be resolved at runtime rather than at compile time. This mechanism is used to implement polymorphism, which allows objects of different classes to be treated as instances of a common superclass.
In dynamic method dispatch, the specific implementation of a method is not determined at compile time, but rather at runtime based on the actual type of the object being used. When a method is called on an object, the runtime environment checks the type of the object to determine which implementation of the method to use.
-
Explain the daemon thread.
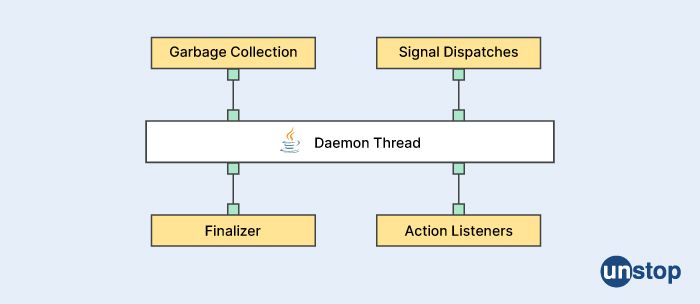
In computer programming, a daemon thread is a type of thread that runs in the background of an application, performing tasks that do not require user interaction or input. Daemon threads are typically used for background processes such as logging, monitoring, and maintenance tasks.
A daemon thread is a low-priority thread that runs in the background and is not associated with any specific user interaction. A daemon thread doesn't need to complete before the application terminates. Daemon threads are automatically terminated when all non-daemon threads have completed.
32. Session management in Java may be defined as?
There are several techniques to maintain a Java session, including the HTTP Sessions API, cookies, URL rewrites, and more. In a session, the server and the client are in a state that can manage several requests and answers. To handle sessions between the Web Server and HTTP, which are both stateless, a unique identifier, such as the session id, is given between the server and client in every request. Session IDs are commonly used between clients and servers in Java to keep track of active sessions.
-
What's the last thing we need to consider as the final variable in Java?
The final variable in Java is used to prevent a user from making changes to it. We can't modify the value of the final variable once it's been initialized. Finally, once the final variable has been set to a value, it cannot be modified. Only the class function Object() { [native code] } can assign the last variable that has no value.
-
What is encapsulation?
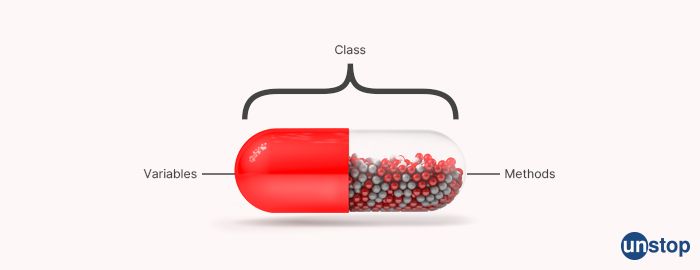
Encapsulation is a fundamental principle of object-oriented programming that refers to the idea of packaging data and methods that operate on that data within a single unit, called a class. Encapsulation provides several benefits, including improved code organization, security, and modularity.
In encapsulation, the variables and methods that manipulate that data are bundled together within a class and are hidden from the outside world. This means that the data cannot be accessed or modified directly by other parts of the program, but can only be accessed through the methods provided by the class.
-
In Java, what is inheritance?
Inheritance is a fundamental concept in object-oriented programming that allows a class to inherit properties and behaviors from another class. The class that inherits from another class is called the subclass or derived class, and the class that is inherited from is called the superclass or base class.
In Java, inheritance is implemented using the extends keyword. When a subclass extends a superclass, it inherits all the public and protected fields and methods of the superclass. The subclass can also override the methods of the superclass to provide its implementation.
-
In Java, what is the term "polymorphism"?
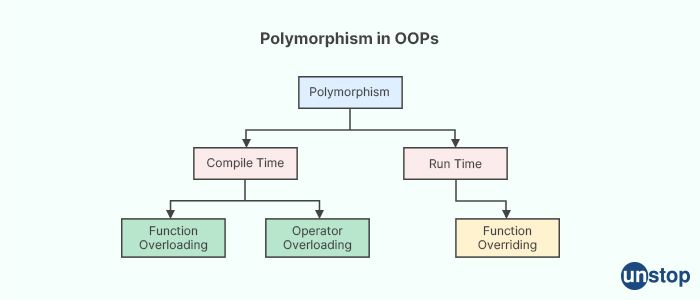
In Java, polymorphism is the ability of an object to take on many forms. Specifically, polymorphism refers to the ability of a variable, method, or object to have multiple forms.
There are two types of polymorphism in Java: compile-time polymorphism and runtime polymorphism.
Compile-time polymorphism, also known as method overloading, occurs when a class has two or more methods with the same name but different parameters. The compiler decides which method to call based on the arguments passed to the method at compile time.
Runtime polymorphism, also known as method overriding, occurs when a subclass provides a specific implementation of a method that is already defined in its superclass. When an object of the subclass is created and the method is called, the JVM decides which implementation to call based on the actual type of the object at runtime.
-
In Java, what is JCA?
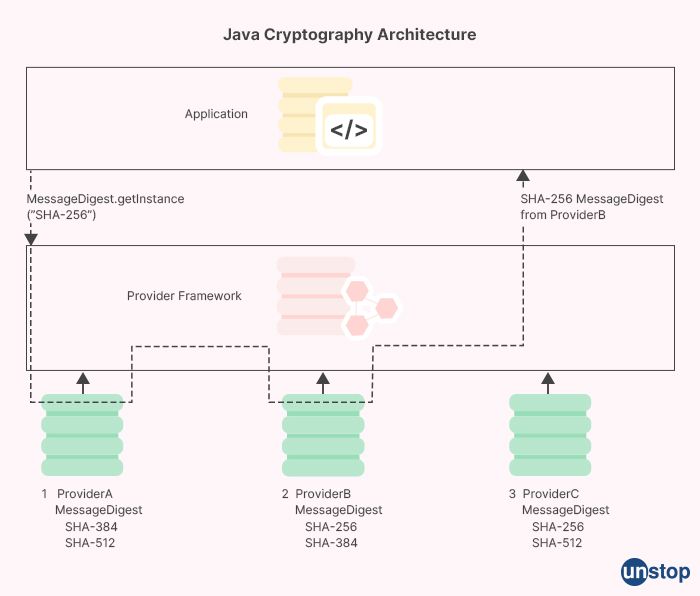
JCA stands for Java Cryptography Architecture. It is a framework that provides a set of APIs for working with cryptographic services in Java.
JCA includes a range of cryptographic services, including message digests, digital signatures, and encryption algorithms. These services are implemented as classes and interfaces in the javax.crypto and java.security packages, which are part of the Java Development Kit (JDK).
JCA provides a consistent and standard way of working with cryptography in Java, making it easier for developers to write secure and robust applications. It also supports a wide range of cryptographic algorithms and protocols, allowing developers to choose the most appropriate algorithm for their needs.
One of the key features of JCA is its support for cryptographic providers. A provider is a software module that implements a set of cryptographic services using a particular algorithm or protocol. JCA allows developers to use multiple providers and switch between them at runtime, providing greater flexibility and customization options.
-
What is the last unfilled field?
The term "final blank variable" refers to a variable that has not been initialized at the time of declaration. The final blank variable cannot be explicitly initialized. Instead, we must use the class function Object() { [native code] } to get it up and running. Useful if the user has sensitive data that cannot be altered by others.
-
What are the naming conventions in Java?
In Java, several naming conventions are widely followed by developers to make their code more readable and maintainable. Here are some of the most common naming conventions in Java:
-
Package names: Package names should be in lowercase and should be based on the company or organization's domain name, reversed. For example, if a company's domain name is "example.com", the package name should be "com.example".
-
Class names: Class names should be in CamelCase, starting with a capital letter. For example, "Person" or "BankAccount".
-
Interface names: Interface names should also be in CamelCase, starting with a capital letter. For example, "Runnable" or "Comparable".
-
Method names: Method names should be in camelCase, starting with a lowercase letter. For example, "calculateInterest" or "withdrawMoney".
-
Variable names: Variable names should also be in camelCase, starting with a lowercase letter. For example, "firstName" or "accountBalance".
-
Constant names: Constant names should be in ALL_CAPS, separated by underscores. For example, "MAX_VALUE" or "PI".
-
Is it possible to overload the function Object() { [native code] }?
No, it is not possible to overload the Object() function in JavaScript. The Object() function is a built-in constructor function in JavaScript, used to create a new object. It is a native function provided by the JavaScript runtime environment and cannot be modified or overloaded.
However, you can create your own constructor functions and overload them with different parameters or methods. This allows you to create custom objects with specific properties and behavior that suit your needs. For example:
function Person(name, age) {
this.name = name;
this.age = age;
}
Person.prototype.greet = function() {
console.log(`Hello, my name is ${this.name} and I am ${this.age} years old.`);
}
let john = new Person('John', 30);
john.greet(); // prints "Hello, my name is John and I am 30 years old."
ZnVuY3Rpb24gUGVyc29uKG5hbWUsIGFnZSkgewp0aGlzLm5hbWUgPSBuYW1lOwp0aGlzLmFnZSA9IGFnZTsKfQoKUGVyc29uLnByb3RvdHlwZS5ncmVldCA9IGZ1bmN0aW9uKCkgewpjb25zb2xlLmxvZyhgSGVsbG8sIG15IG5hbWUgaXMgJHt0aGlzLm5hbWV9IGFuZCBJIGFtICR7dGhpcy5hZ2V9IHllYXJzIG9sZC5gKTsKfQoKbGV0IGpvaG4gPSBuZXcgUGVyc29uKCdKb2huJywgMzApOwpqb2huLmdyZWV0KCk7IC8vIHByaW50cyAiSGVsbG8sIG15IG5hbWUgaXMgSm9obiBhbmQgSSBhbSAzMCB5ZWFycyBvbGQuIg==
-
Is there a way to make a function Object() { [native code] } permanent?
No, it is not possible to modify or make the built-in Object() function permanent in JavaScript, as it is a native function provided by the JavaScript runtime environment. Any attempt to modify or override the Object() function could result in unexpected behavior and could potentially break other parts of your code.
Instead, you should create your own custom functions and avoid using the same name as built-in functions to prevent any conflicts or unexpected results. If you need to add functionality to the Object prototype, you can do so by extending it with your own methods or properties, using the Object.prototype object. For example:
Object.prototype.myCustomMethod = function() {
console.log('This is my custom method!');
}
let myObject = {};
myObject.myCustomMethod(); // prints "This is my custom method!"
T2JqZWN0LnByb3RvdHlwZS5teUN1c3RvbU1ldGhvZCA9IGZ1bmN0aW9uKCkgewpjb25zb2xlLmxvZygnVGhpcyBpcyBteSBjdXN0b20gbWV0aG9kIScpOwp9CgpsZXQgbXlPYmplY3QgPSB7fTsKbXlPYmplY3QubXlDdXN0b21NZXRob2QoKTsgLy8gcHJpbnRzICJUaGlzIGlzIG15IGN1c3RvbSBtZXRob2QhIg==
-
Is it possible to designate an interface as "final"?
In Java, it is not possible to declare an interface as "final". The final keyword can be used to declare a class or method that cannot be subclassed or overridden, respectively, but it has no meaning when applied to an interface.
Interfaces in Java are meant to be implemented by classes, and any class that implements an interface must provide an implementation for all of its methods. This allows for flexibility and polymorphism, as multiple classes can implement the same interface and be used interchangeably in code that accepts objects of that interface type.
Since interfaces define a contract for the methods that implementing classes must provide, declaring an interface as "final" would defeat the purpose of interfaces and prevent any implementation or extension of the interface. Therefore, interfaces in Java cannot be marked as "final".
-
In Java, how do you define the method?
In Java, you can define a method by using the following syntax:
<access_modifier> <return_type> <method_name>(<parameter_list>) {
// method body
}
-
In Java, what is a "static block"?
In Java, a static block is a block of code enclosed in curly braces that is executed only once, when the class is first loaded into memory. It is also known as a static initialization block.
The syntax for a static block is as follows:
static {
// code to be executed
}
-
In Java, what is serialization?
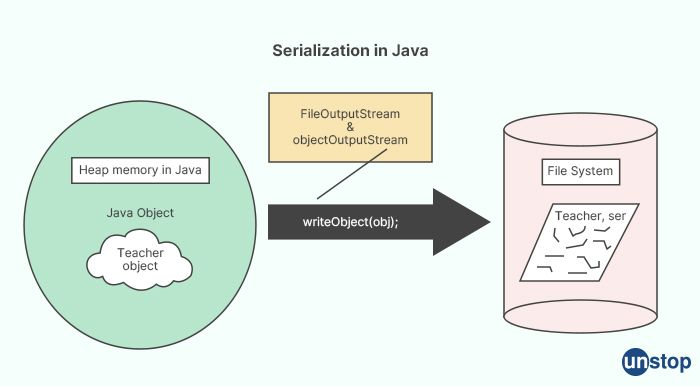
In Java, serialization is the process of converting an object into a stream of bytes, so that the object can be easily saved to a file, transferred over a network, or stored in a database. The reverse process of converting a stream of bytes back into an object is called deserialization.
To make an object serializable, it must implement the java.io.Serializable interface. This interface does not have any methods that need to be implemented; it simply serves as a marker interface to indicate that the object can be serialized.
Here's an example of a serializable class:
import java.io.Serializable;
public class MyClass implements Serializable {
private int myInt;
private String myString;
public MyClass(int myInt, String myString) {
this.myInt = myInt;
this.myString = myString;
}
public int getMyInt() {
return myInt;
}
public String getMyString() {
return myString;
}
}
aW1wb3J0IGphdmEuaW8uU2VyaWFsaXphYmxlOwoKcHVibGljIGNsYXNzIE15Q2xhc3MgaW1wbGVtZW50cyBTZXJpYWxpemFibGUgewpwcml2YXRlIGludCBteUludDsKcHJpdmF0ZSBTdHJpbmcgbXlTdHJpbmc7CgpwdWJsaWMgTXlDbGFzcyhpbnQgbXlJbnQsIFN0cmluZyBteVN0cmluZykgewp0aGlzLm15SW50ID0gbXlJbnQ7CnRoaXMubXlTdHJpbmcgPSBteVN0cmluZzsKfQoKcHVibGljIGludCBnZXRNeUludCgpIHsKcmV0dXJuIG15SW50Owp9CgpwdWJsaWMgU3RyaW5nIGdldE15U3RyaW5nKCkgewpyZXR1cm4gbXlTdHJpbmc7Cn0KfQ==
-
How do you use Java's spring framework?
The Spring Framework is a popular Java framework that provides a comprehensive programming and configuration model for building modern Java applications. Here are the basic steps to use the Spring Framework:
-
Add Spring dependencies to your project: To use Spring, you need to include the Spring dependencies in your project. The easiest way to do this is by using a build tool like Maven or Gradle, which will manage the dependencies for you.
-
Configure Spring: Spring provides several ways to configure your application, including XML-based configuration, Java-based configuration, and annotation-based configuration. The choice of configuration method depends on your preference and the requirements of your application.
-
Define Spring beans: In Spring, a bean is an object that is managed by the Spring container. To define a bean, you need to create a Java class and annotate it with the appropriate Spring annotations, such as
@Component,@Service, or@Repository. -
Inject dependencies: Spring supports dependency injection, which allows you to declare the dependencies of your beans and let Spring wire them together automatically. You can use annotations like
@Autowired,@Qualifier, and@Valueto inject dependencies into your beans. -
Use Spring features: Once you have configured your Spring application and defined your beans, you can start using Spring features, such as the Spring Data framework for database access, the Spring MVC framework for web development, and the Spring Security framework for authentication and authorization.
-
What is the difference between Java's checked and unchecked exceptions?

In Java, there are two types of exceptions: checked exceptions and unchecked exceptions.
Checked exceptions are exceptions that the Java compiler requires you to handle explicitly in your code. Examples of checked exceptions include IOException, SQLException, and ClassNotFoundException. When you call a method that can throw a checked exception, you must either catch the exception using a try-catch block or declare the exception in the method signature using the throws keyword. If you don't handle the checked exception, your code will not compile.
Unchecked exceptions, also known as runtime exceptions, are exceptions that the Java compiler does not require you to handle explicitly. Examples of unchecked exceptions include NullPointerException, ArrayIndexOutOfBoundsException, and ArithmeticException. Unchecked exceptions are typically caused by programming errors, such as null pointer dereferences or division by zero, and indicate a bug in your code. Because unchecked exceptions are not checked at compile time, you do not need to handle them explicitly. However, if you do not handle them, they will propagate up the call stack until they are caught or the program terminates.
-
In Java, what is a "singleton class?"
In Java, a singleton class is a class that can have only one instance in the entire application, and provides a global point of access to that instance. The singleton pattern is a design pattern that is used to ensure that a class has only one instance, and provides a way to access that instance globally.
To create a singleton class in Java, you need to follow these steps:
-
Make the constructor private: This prevents other classes from creating instances of the class directly.
-
Create a static instance of the class: This provides the global point of access to the singleton instance.
-
Create a static method to access the singleton instance: This method should check if the singleton instance has already been created, and create it if it has not.
Here's an example of a singleton class in Java:
public class Singleton {
private static Singleton instance = null;
private Singleton() {
// private constructor to prevent other classes from creating instances
}
public static Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
public void doSomething() {
// some code here
}
}
cHVibGljIGNsYXNzIFNpbmdsZXRvbiB7CnByaXZhdGUgc3RhdGljIFNpbmdsZXRvbiBpbnN0YW5jZSA9IG51bGw7Cgpwcml2YXRlIFNpbmdsZXRvbigpIHsKLy8gcHJpdmF0ZSBjb25zdHJ1Y3RvciB0byBwcmV2ZW50IG90aGVyIGNsYXNzZXMgZnJvbSBjcmVhdGluZyBpbnN0YW5jZXMKfQoKcHVibGljIHN0YXRpYyBTaW5nbGV0b24gZ2V0SW5zdGFuY2UoKSB7CmlmIChpbnN0YW5jZSA9PSBudWxsKSB7Cmluc3RhbmNlID0gbmV3IFNpbmdsZXRvbigpOwp9CnJldHVybiBpbnN0YW5jZTsKfQoKcHVibGljIHZvaWQgZG9Tb21ldGhpbmcoKSB7Ci8vIHNvbWUgY29kZSBoZXJlCn0KfQ==
-
What is a package in Java?
In Java, a package is a way to organize related classes and interfaces into a single namespace. A package provides a mechanism for grouping related classes, interfaces, and sub-packages, which can be useful for organizing large Java applications. A Java package is a directory that contains Java class files. The name of the directory corresponds to the name of the package, and the Java class files in the directory must be declared to be in that package using the package statement at the beginning of the file.
-
Is method overriding a common practice in Java, and if so, how?
Yes, method overriding is a common practice in Java, and it is used to provide a more specific implementation of a method in a subclass that is inherited from its superclass.
Method overriding occurs when a subclass provides a different implementation of a method that is already defined in its superclass. The method in the subclass must have the same name, return type, and parameter list as the method in the superclass. The access level of the method in the subclass must not be more restrictive than the access level of the method in the superclass.
To override a method in a subclass, you simply define a method with the same signature as the method in the superclass, and provide a different implementation. Here is an example:
public class Animal {
public void makeSound() {
System.out.println("The animal makes a sound");
}
}
public class Dog extends Animal {
@Override
public void makeSound() {
System.out.println("The dog barks");
}
}
cHVibGljIGNsYXNzIEFuaW1hbCB7CnB1YmxpYyB2b2lkIG1ha2VTb3VuZCgpIHsKU3lzdGVtLm91dC5wcmludGxuKCJUaGUgYW5pbWFsIG1ha2VzIGEgc291bmQiKTsKfQp9CgpwdWJsaWMgY2xhc3MgRG9nIGV4dGVuZHMgQW5pbWFsIHsKQE92ZXJyaWRlCnB1YmxpYyB2b2lkIG1ha2VTb3VuZCgpIHsKU3lzdGVtLm91dC5wcmludGxuKCJUaGUgZG9nIGJhcmtzIik7Cn0KfQ==
HR Interview Questions for Adobe
Here are some of the frequently asked HR interview questions that you should prepare to crack the Adobe HR interview round successfully, with confidence.
-
Why do you want to become a member of Adobe?
-
Describe your ideal workplace
-
Share some information about your family's professional history.
-
Name some of the recent objectives you've set for yourself and the steps you've taken to reach them.
-
What are some of your more immediate objectives?
-
Where do you see yourself in the not-too-distant future?
-
Where do you envision yourself, and what do you want to be doing in the next five years?
-
Tell us a difficult situation from the past when you had to take leadership responsibilities and manage a team.
-
What is the best way to handle a tough deadline?
-
Is delegation a good leadership trait?
-
List your top strengths and weaknesses.
-
You are at work managing a team of 5 people. 3 out of the 5 do not show up for work. How do you manage to meet their deadlines when they do not respond to your calls asking for work updates?
Recruitment Process at Adobe
Adobe hires college grads through either the more usual off-campus methods or campus recruitment initiatives. Candidates with relevant experience can submit their applications through Adobe's online career center. When deciding which applicants to invite for interviews, Adobe uses a set of predetermined criteria. It has a preference for:
- A solid educational foundation in computer science
- Developed problem-solving skills
- Competence in the use of several coding systems
- Proven practical experience
Rounds of interviews and tests
- Evaluation of the candidate's curriculum vitae for the Adobe position
- Communication through phone interview (pre-technical assessment round)
- A coding exercise to be completed online
- Interviews conducted by Adobe for their technical staff
- A roundtable discussion with HR
You shouldn't be shocked if the hiring manager or recruiting manager wants you to demonstrate that you are familiar with Adobe's core values (Genuine, Exceptional, Innovative, Involved). To ensure that you do well in the initial interview, it is important to review company policies and customs in advance.

About Adobe
Adobe Systems is well-known for the multimedia & creativity software products that it develops and sells. Adobe's Photoshop, Acrobat Reader, and Creative Cloud are some of the company's most popular products.
Adobe was established by John Warnock & Charles Geschke in 1982 in the city of San Jose, which is located in the state of California. The origin of the term Adobe can be traced back to a creek in California known as Adobe Creek, which was located behind the homes where the firm was initially established.
When Adobe initially entered the market for consumer software in the 1980s, one of its company's earliest offerings was a collection of downloadable digital typefaces. The first product that Adobe released to the general public was called Adobe Illustrator, and it was a drawing application that used vectors and was designed for the Mac.
Final Thoughts
On the list of the Great Places to Work For, Adobe comes in at number 21, making it one of the most employee-friendly multinational companies. Adobe Inc. takes care of its employees by providing them with generous benefits and making significant investments in their health and happiness. The company takes its time for candidates' selection and puts them through an exhaustive screening process to ensure that they are suitable for the best possible workforce. You will easily pass the interview if you prepare well, place particular emphasis on DS and Algo, and engage in a substantial amount of practice.
Hope this article helps you with Adobe's multiple interview rounds like the phone interview, onsite interviews (face-to-face), and the technical assessment round!
Suggested reads:
- 50+ Siemens Interview Questions And Answers You Must Practice
- Top Cognizant Interview Questions and Answers (Prepare Yourself For The D-Day!)
- Top 50+ TCS Interview Questions And Answers (Bookmark Them!)
- Top 10 Algorithms Every Coding Student Should Know To Crack Competitive Interviews
- What is Coding & Decoding? | Coding-Decoding Questions
Login to continue reading
And access exclusive content, personalized recommendations, and career-boosting opportunities.
Don't have an account? Sign up
Never miss an
Update

Featured Opportunities
Top-Rated Practice by Students





Subscribe
to our newsletter
Blogs you need to hog!

This Is My First Hackathon, How Should I Prepare? (Tips & Hackathon Questions Inside)
D2C Admin

10 Best C++ IDEs That Developers Mention The Most!
D2C Admin

Advantages and Disadvantages of Cloud Computing That You Should Know!
D2C Admin

Is IoT Valuable? Advantages And Disadvantages Of IoT Explained
Shivangi Vatsal
Comments
Add comment