
Asian Paints Alchemy 2026
Table of content:
- Netflix Technical Interview Questions for Software Engineer Role
- Netflix SQL Interview Questions
- Netflix Design Interview Questions for SRE
- HR Interview Questions
Top Netflix Interview Questions For Software Engineer And SRE Roles

Netflix is a leading entertainment company with over 200 million subscribers globally that has revolutionized the way we watch movies and TV shows. With its global reach, a diverse range of content, and excellent customer service, Netflix has become a household name around the world for its video streaming services. The company has a reputation for being highly selective in its hiring process, and candidates can expect a rigorous interview process with different types of questions. Demonstrating your passion for the company, by going through its cultural values, and culture memo, having excellent problem-solving skills, and the ability to work in an environment of ambiguity will go a long way toward impressing your interviewers.
Usually, the interview panel comprises an engineering director, a partner engineer or previous project manager, and another engineering leader in a senior position along with the hiring manager. The Netflix interview process for the software engineer role consists of 3–4 rounds, as mentioned below:
- Initial phone screen interview
- Technical phone interview
- Onsite Interview
- Behavioral interview
In this article, we will explore some of the most common Netflix interview questions (technical questions and behavioral questions) asked during the hiring process and how you can prepare for them to get placed at Netflix.
Netflix Technical Interview Questions for Software Engineer Role
Q1. What are the documents involved in system designing?
System designing is a critical process in software development that involves creating a blueprint for a software system. The design phase involves a range of documents that provide detailed information about the system's architecture, functionality, and performance. Below are some of the documents typically involved in system designing:
-
Requirements Specification: This document outlines the functional and non-functional requirements of the system. It includes details about the system's features, user interface, performance, security, and other key aspects.
-
System Architecture: This document provides an overview of the system's structure and its components. It describes the system's modules, interfaces, and communication protocols.
-
Design Specification: This document contains detailed information about the system's design. It includes diagrams, flowcharts, and other graphical representations that illustrate the system's structure and operation.
-
User Interface Design: This document outlines the design of the user interface. It includes details about the layout, navigation, and functionality of the user interface.
-
Database Design: This document describes the design of the system's database. It includes details about the database schema, data storage, and access mechanisms.
-
Test Plan: This document outlines the plan for testing the system. It includes details about the test cases, test scenarios, and testing methodologies.
-
Technical Documentation: This document provides detailed information about the system's technical aspects. It includes information about the programming language, development tools, and other technical details.
Overall, the documents involved in system design provide a comprehensive blueprint for the software system. They are critical for ensuring that the system meets the requirements, performs optimally, and is maintainable over time.
Q2. How many ways are there to handle exceptions in JAVA?
In Java, there are two ways to handle exceptions:
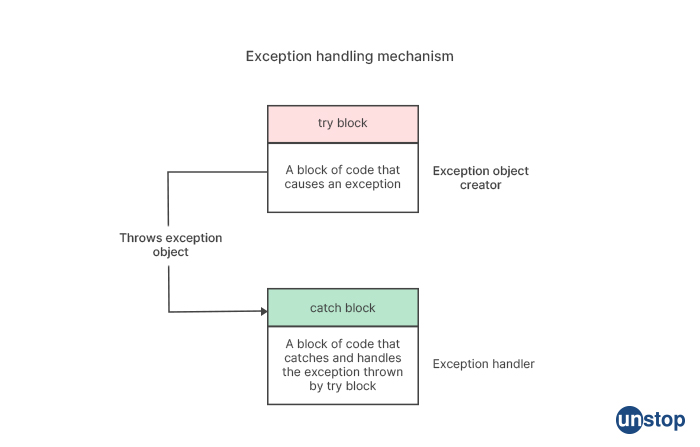
1. Using try-catch blocks: This method involves enclosing the code that could potentially throw an exception inside a try block. If an exception is thrown, the catch block is executed to handle the exception. Multiple catch blocks can be used to handle different types of exceptions that may be thrown. For example:
try {
// Code that may throw an exception
} catch (ExceptionType1 e) {
// Code to handle ExceptionType1
} catch (ExceptionType2 e) {
// Code to handle ExceptionType2
} finally {
// Code that is always executed, regardless of whether an exception is thrown or not
}
dHJ5IHsKLy8gQ29kZSB0aGF0IG1heSB0aHJvdyBhbiBleGNlcHRpb24KfSBjYXRjaCAoRXhjZXB0aW9uVHlwZTEgZSkgewovLyBDb2RlIHRvIGhhbmRsZSBFeGNlcHRpb25UeXBlMQp9IGNhdGNoIChFeGNlcHRpb25UeXBlMiBlKSB7Ci8vIENvZGUgdG8gaGFuZGxlIEV4Y2VwdGlvblR5cGUyCn0gZmluYWxseSB7Ci8vIENvZGUgdGhhdCBpcyBhbHdheXMgZXhlY3V0ZWQsIHJlZ2FyZGxlc3Mgb2Ygd2hldGhlciBhbiBleGNlcHRpb24gaXMgdGhyb3duIG9yIG5vdAp9
2. Using throws keyword: This method involves declaring that a method may throw an exception by using the throws keyword in the method signature. The caller of the method is then responsible for handling the exception by enclosing the method call in a try-catch block. For example:
public void myMethod() throws MyException {
// Code that may throw MyException
}
// Caller of myMethod must handle MyException
try {
myMethod();
} catch (MyException e) {
// Code to handle MyException
}
cHVibGljIHZvaWQgbXlNZXRob2QoKSB0aHJvd3MgTXlFeGNlcHRpb24gewovLyBDb2RlIHRoYXQgbWF5IHRocm93IE15RXhjZXB0aW9uCn0KCi8vIENhbGxlciBvZiBteU1ldGhvZCBtdXN0IGhhbmRsZSBNeUV4Y2VwdGlvbgp0cnkgewpteU1ldGhvZCgpOwp9IGNhdGNoIChNeUV4Y2VwdGlvbiBlKSB7Ci8vIENvZGUgdG8gaGFuZGxlIE15RXhjZXB0aW9uCn0=
Q3. Convert binary search tree into a doubly-linked list.
To convert a binary tree into a doubly-linked list, we can perform an in-order traversal of the tree and modify the pointers to create the links between the nodes. In an in-order traversal, we first visit the left subtree, then the current node, and finally the right subtree.
Here is an implementation of the algorithm in Java:
class TreeNode {
int val;
TreeNode left, right;
TreeNode(int val) {
this.val = val;
left = right = null;
}
}
class Solution {
TreeNode prev = null;
TreeNode head = null;
public TreeNode convertBSTtoDLL(TreeNode root) {
if (root == null) {
return null;
}
convertBSTtoDLL(root.left);
if (prev == null) { // First node
head = root;
} else { // Link nodes
root.left = prev;
prev.right = root;
}
prev = root;
convertBSTtoDLL(root.right);
return head;
}
}
Y2xhc3MgVHJlZU5vZGUgewppbnQgdmFsOwpUcmVlTm9kZSBsZWZ0LCByaWdodDsKVHJlZU5vZGUoaW50IHZhbCkgewp0aGlzLnZhbCA9IHZhbDsKbGVmdCA9IHJpZ2h0ID0gbnVsbDsKfQp9CgpjbGFzcyBTb2x1dGlvbiB7ClRyZWVOb2RlIHByZXYgPSBudWxsOwpUcmVlTm9kZSBoZWFkID0gbnVsbDsKCnB1YmxpYyBUcmVlTm9kZSBjb252ZXJ0QlNUdG9ETEwoVHJlZU5vZGUgcm9vdCkgewppZiAocm9vdCA9PSBudWxsKSB7CnJldHVybiBudWxsOwp9CmNvbnZlcnRCU1R0b0RMTChyb290LmxlZnQpOwppZiAocHJldiA9PSBudWxsKSB7IC8vIEZpcnN0IG5vZGUKaGVhZCA9IHJvb3Q7Cn0gZWxzZSB7IC8vIExpbmsgbm9kZXMKcm9vdC5sZWZ0ID0gcHJldjsKcHJldi5yaWdodCA9IHJvb3Q7Cn0KcHJldiA9IHJvb3Q7CmNvbnZlcnRCU1R0b0RMTChyb290LnJpZ2h0KTsKcmV0dXJuIGhlYWQ7Cn0KfQ==
In the above implementation, we maintain a prev pointer to keep track of the previously visited node and a head pointer to keep track of the head of the doubly-linked list. We perform an in-order traversal of the binary tree, and for each node, we update the left and right pointers to create the links between the nodes. Finally, we return the head of the doubly-linked list.
Q4. Segment a string into dictionary words.
Segmenting a string into dictionary words is a common problem in natural language processing and can be solved using dynamic programming. The goal is to find all possible ways to segment the input string into valid words from a given dictionary.
Here is an implementation of the algorithm in Java:
import java.util.*;
class Solution {
public List segmentString(String s, Set dict) {
List result = new ArrayList<>();
Map<Integer, List> dp = new HashMap<>();
dp.put(0, new ArrayList<>());
dp.get(0).add("");
for (int i = 1; i <= s.length(); i++) {
List temp = new ArrayList<>();
for (int j = i - 1; j >= 0; j--) {
if (dp.containsKey(j) && dict.contains(s.substring(j, i))) {
for (String str : dp.get(j)) {
if (str.equals("")) {
temp.add(s.substring(j, i));
} else {
temp.add(str + " " + s.substring(j, i));
}
}
}
}
dp.put(i, temp);
}
return dp.get(s.length());
}
}
aW1wb3J0IGphdmEudXRpbC4qOwoKY2xhc3MgU29sdXRpb24gewpwdWJsaWMgTGlzdDxTdHJpbmc+IHNlZ21lbnRTdHJpbmcoU3RyaW5nIHMsIFNldDxTdHJpbmc+IGRpY3QpIHsKTGlzdDxTdHJpbmc+IHJlc3VsdCA9IG5ldyBBcnJheUxpc3Q8PigpOwpNYXA8SW50ZWdlciwgTGlzdDxTdHJpbmc+PiBkcCA9IG5ldyBIYXNoTWFwPD4oKTsKZHAucHV0KDAsIG5ldyBBcnJheUxpc3Q8PigpKTsKZHAuZ2V0KDApLmFkZCgiIik7Cgpmb3IgKGludCBpID0gMTsgaSA8PSBzLmxlbmd0aCgpOyBpKyspIHsKTGlzdDxTdHJpbmc+IHRlbXAgPSBuZXcgQXJyYXlMaXN0PD4oKTsKZm9yIChpbnQgaiA9IGkgLSAxOyBqID49IDA7IGotLSkgewppZiAoZHAuY29udGFpbnNLZXkoaikgJiYgZGljdC5jb250YWlucyhzLnN1YnN0cmluZyhqLCBpKSkpIHsKZm9yIChTdHJpbmcgc3RyIDogZHAuZ2V0KGopKSB7CmlmIChzdHIuZXF1YWxzKCIiKSkgewp0ZW1wLmFkZChzLnN1YnN0cmluZyhqLCBpKSk7Cn0gZWxzZSB7CnRlbXAuYWRkKHN0ciArICIgIiArIHMuc3Vic3RyaW5nKGosIGkpKTsKfQp9Cn0KfQpkcC5wdXQoaSwgdGVtcCk7Cn0KcmV0dXJuIGRwLmdldChzLmxlbmd0aCgpKTsKfQp9
In the above implementation, we use dynamic programming to build a map dp where each key i represents the index of the last character in the current segment, and the corresponding value is a list of all possible segmentations up to that point. We initialize dp with an empty string at index 0 to represent the empty string. We then iterate over all possible segmentations by looping through the indices j from i-1 to 0 and checking if the substring s.substring(j, i) is a valid word in the dictionary. If it is, we add it to the list of possible segmentations for the current index i. Finally, we return the list of possible segmentations for the last index s.length().
This algorithm has a time complexity of O(n^2 * w) where n is the length of the input string and w is the number of words in the dictionary. The space complexity is also O(n^2 * w) because of the dynamic programming map.
Q5. What is MapReduce?
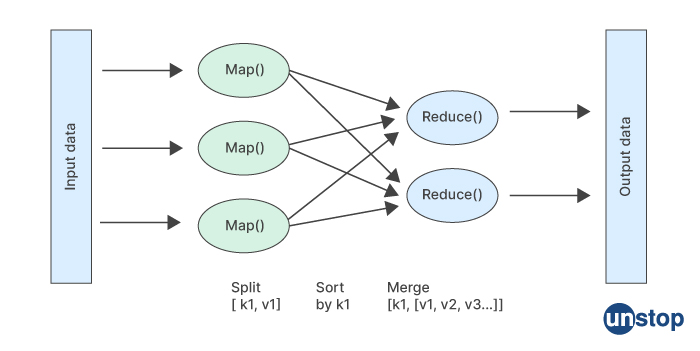
MapReduce is a programming model and a software framework used for processing large amounts of data in a distributed manner. It was initially introduced by Google, but now many other companies, including Apache, have implemented their own versions of the framework.
The MapReduce framework consists of two main phases: the Map phase and the Reduce phase. In the Map phase, the input data is divided into smaller chunks and processed in parallel by multiple map tasks. Each map task applies a user-defined function, called the Map function, to the input data and generates a set of intermediate key-value pairs.
In the Reduce phase, the intermediate key-value pairs are combined and processed by multiple reduce tasks in parallel. Each reduce task applies a user-defined function, called the Reduce function, to the intermediate key-value pairs and generates a set of output key-value pairs.
The MapReduce framework also provides built-in functions for sorting and shuffling the intermediate key-value pairs before they are passed to the reduce tasks. This helps to optimize the processing and reduce the amount of data that needs to be transferred between nodes.
MapReduce is used for a wide range of applications, including data processing, data analysis, machine learning, and more. It is particularly useful for processing large-scale datasets that cannot be processed on a single machine due to limitations in memory and processing power. Hadoop is an open-source implementation of the MapReduce framework and is widely used in the industry for big data processing. Other popular implementations include Apache Spark, Apache Flink, and Apache Storm.
Q6. Write an algorithm to merge two sorted linked list and return it as a new sorted list.
Here is an algorithm to merge two sorted linked lists and return a new sorted list:
- Create a new linked list called result.
- If either of the input linked lists is null, return the other linked list as the result.
- Set the head of the result list to the smaller of the heads of the two input lists.
- Set a current pointer for each input list and the result list.
- While both input lists have nodes: a. If the current node in the first list is smaller, add it to the result list and move the current pointer for the first list to the next node. b. If the current node in the second list is smaller, add it to the result list and move the current pointer for the second list to the next node. c. Otherwise, add the current node from either input list to the result list and move both current pointers to the next node.
- If one of the input lists still has nodes, append the remaining nodes to the end of the result list.
- Return the head of the result list.
Here is an implementation of the algorithm in Java:
import java.util.*;
class Solution {
public List segmentString(String s, Set dict) {
List result = new ArrayList<>();
Map<Integer, List> dp = new HashMap<>();
dp.put(0, new ArrayList<>());
dp.get(0).add("");
for (int i = 1; i <= s.length(); i++) {
List temp = new ArrayList<>();
for (int j = i - 1; j >= 0; j--) {
if (dp.containsKey(j) && dict.contains(s.substring(j, i))) {
for (String str : dp.get(j)) {
if (str.equals("")) {
temp.add(s.substring(j, i));
} else {
temp.add(str + " " + s.substring(j, i));
}
}
}
}
dp.put(i, temp);
}
return dp.get(s.length());
}
}
aW1wb3J0IGphdmEudXRpbC4qOwoKY2xhc3MgU29sdXRpb24gewpwdWJsaWMgTGlzdDxTdHJpbmc+IHNlZ21lbnRTdHJpbmcoU3RyaW5nIHMsIFNldDxTdHJpbmc+IGRpY3QpIHsKTGlzdDxTdHJpbmc+IHJlc3VsdCA9IG5ldyBBcnJheUxpc3Q8PigpOwpNYXA8SW50ZWdlciwgTGlzdDxTdHJpbmc+PiBkcCA9IG5ldyBIYXNoTWFwPD4oKTsKZHAucHV0KDAsIG5ldyBBcnJheUxpc3Q8PigpKTsKZHAuZ2V0KDApLmFkZCgiIik7Cgpmb3IgKGludCBpID0gMTsgaSA8PSBzLmxlbmd0aCgpOyBpKyspIHsKTGlzdDxTdHJpbmc+IHRlbXAgPSBuZXcgQXJyYXlMaXN0PD4oKTsKZm9yIChpbnQgaiA9IGkgLSAxOyBqID49IDA7IGotLSkgewppZiAoZHAuY29udGFpbnNLZXkoaikgJiYgZGljdC5jb250YWlucyhzLnN1YnN0cmluZyhqLCBpKSkpIHsKZm9yIChTdHJpbmcgc3RyIDogZHAuZ2V0KGopKSB7CmlmIChzdHIuZXF1YWxzKCIiKSkgewp0ZW1wLmFkZChzLnN1YnN0cmluZyhqLCBpKSk7Cn0gZWxzZSB7CnRlbXAuYWRkKHN0ciArICIgIiArIHMuc3Vic3RyaW5nKGosIGkpKTsKfQp9Cn0KfQpkcC5wdXQoaSwgdGVtcCk7Cn0KcmV0dXJuIGRwLmdldChzLmxlbmd0aCgpKTsKfQp9
The time complexity of this algorithm is O(m + n), where m and n are the lengths of the two input lists. The space complexity is O(1), since we only create a new linked list with a constant amount of memory.
Q7. Find the minimum spanning tree of a connected, undirected graph with weighted edges.
To find the minimum spanning tree of a connected, undirected graph with weighted edges, we can use Kruskal's algorithm or Prim's algorithm. Both algorithms guarantee to find the minimum spanning tree of a given graph.
Here is an overview of both algorithms:
Kruskal's algorithm
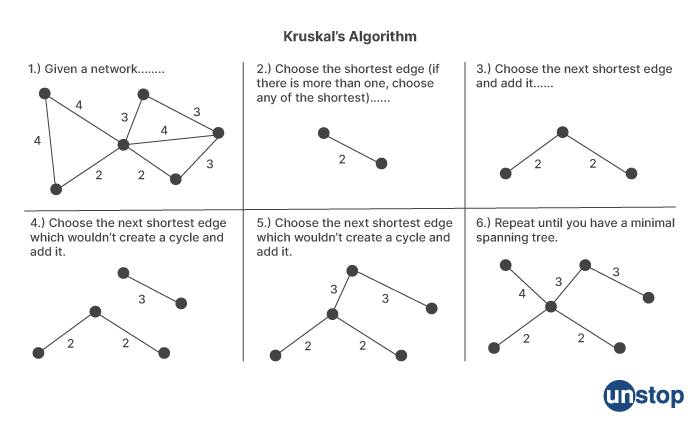
- Create a set for each vertex in the graph, initially containing only that vertex.
- Create a priority queue containing all the edges in the graph, sorted by increasing weight.
- While the priority queue is not empty:
- Dequeue the next smallest edge (u, v) from the priority queue.
- If u and v are not already in the same set, merge the sets containing u and v, and add the edge (u, v) to the minimum spanning tree.
- The minimum spanning tree is the set of edges added to the tree during the algorithm.
Prim's algorithm
-
- Choose any vertex as the starting vertex.
- Create a set containing only the starting vertex.
- Create a priority queue containing all the edges adjacent to the starting vertex, sorted by increasing weight.
- While the priority queue is not empty:
- Dequeue the next smallest edge (u, v) from the priority queue.
- If v is not already in the set of visited vertices, add v to the set, add the edge (u, v) to the minimum spanning tree, and add all edges adjacent to v to the priority queue.
- The minimum spanning tree is the set of edges added to the tree during the algorithm.
Both algorithms have a time complexity of O(E log E), where E is the number of edges in the graph. Kruskal's algorithm is often used for sparse graphs with few edges, while Prim's algorithm is often used for dense graphs with many edges.
Q8. Given a sentence (an array of characters), reverse the order of words.
To reverse the order of words in a given sentence (an array of characters), we can follow these steps:
- Reverse the order of all characters in the sentence.
- Reverse the order of characters in each individual word.
Here's how we can implement this approach in Java:
public static void reverseWords(char[] sentence) {
// Step 1: Reverse the order of all characters in the sentence.
reverse(sentence, 0, sentence.length - 1);
// Step 2: Reverse the order of characters in each individual word.
int start = 0;
for (int end = 0; end < sentence.length; end++) {
if (sentence[end] == ' ') {
reverse(sentence, start, end - 1);
start = end + 1;
}
}
// Reverse the last word.
reverse(sentence, start, sentence.length - 1);
}
private static void reverse(char[] sentence, int start, int end) {
while (start < end) {
char temp = sentence[start];
sentence[start++] = sentence[end];
sentence[end--] = temp;
}
}
cHVibGljIHN0YXRpYyB2b2lkIHJldmVyc2VXb3JkcyhjaGFyW10gc2VudGVuY2UpIHsKLy8gU3RlcCAxOiBSZXZlcnNlIHRoZSBvcmRlciBvZiBhbGwgY2hhcmFjdGVycyBpbiB0aGUgc2VudGVuY2UuCnJldmVyc2Uoc2VudGVuY2UsIDAsIHNlbnRlbmNlLmxlbmd0aCAtIDEpOwoKLy8gU3RlcCAyOiBSZXZlcnNlIHRoZSBvcmRlciBvZiBjaGFyYWN0ZXJzIGluIGVhY2ggaW5kaXZpZHVhbCB3b3JkLgppbnQgc3RhcnQgPSAwOwpmb3IgKGludCBlbmQgPSAwOyBlbmQgPCBzZW50ZW5jZS5sZW5ndGg7IGVuZCsrKSB7CmlmIChzZW50ZW5jZVtlbmRdID09ICcgJykgewpyZXZlcnNlKHNlbnRlbmNlLCBzdGFydCwgZW5kIC0gMSk7CnN0YXJ0ID0gZW5kICsgMTsKfQp9Ci8vIFJldmVyc2UgdGhlIGxhc3Qgd29yZC4KcmV2ZXJzZShzZW50ZW5jZSwgc3RhcnQsIHNlbnRlbmNlLmxlbmd0aCAtIDEpOwp9Cgpwcml2YXRlIHN0YXRpYyB2b2lkIHJldmVyc2UoY2hhcltdIHNlbnRlbmNlLCBpbnQgc3RhcnQsIGludCBlbmQpIHsKd2hpbGUgKHN0YXJ0IDwgZW5kKSB7CmNoYXIgdGVtcCA9IHNlbnRlbmNlW3N0YXJ0XTsKc2VudGVuY2Vbc3RhcnQrK10gPSBzZW50ZW5jZVtlbmRdOwpzZW50ZW5jZVtlbmQtLV0gPSB0ZW1wOwp9Cn0=
In the above implementation, we first reverse the order of all characters in the sentence using the reverse method. Then, we iterate through the sentence character by character and when we find a space, we reverse the characters in the word before the space using the reverse method. Finally, we reverse the last word in the sentence. Let's say we have the sentence "the sky is blue". After applying the reverse words method, the sentence would become "blue is sky the". The time complexity of this algorithm is O(n), where n is the length of the sentence.
Q9. Explain different types of Maps in JAVA.
In Java, there are three main types of maps: HashMap, TreeMap, and LinkedHashMap.
-
HashMap: A HashMap is an unordered map that uses a hash table to store key-value pairs. It provides constant time O(1) performance for basic operations such as get and put, making it an efficient choice for most use cases. However, iteration order is not guaranteed and may change over time as the map is modified.
-
TreeMap: A TreeMap is an ordered map that stores key-value pairs in a sorted tree structure. It provides guaranteed O(log n) performance for basic operations such as get and put, making it a good choice for large data sets. However, it may not be as efficient as a HashMap for smaller data sets, and the additional sorting overhead may affect performance.
-
LinkedHashMap: A LinkedHashMap is an ordered map that maintains the insertion order of key-value pairs. It provides guaranteed O(1) performance for get and put operations, and iteration order is predictable and consistent with insertion order. This makes it a good choice for use cases where iteration order is important, such as caching.
Each type of map has its own strengths and weaknesses, and the best choice depends on the specific use case. It is important to consider factors such as performance requirements, data size, and iteration order when choosing a map implementation in Java.
Q10. What is Flask? How does it compare with Django?
Flask is a lightweight web framework for Python that is often used for small to medium-sized web applications. It is designed to be flexible and modular, allowing developers to build custom applications using only the components they need. Flask provides a simple and intuitive API, making it easy to get started and quick to learn.
Django, on the other hand, is a more comprehensive web framework that provides a complete set of tools for building large-scale web applications. It is designed to be highly scalable and includes built-in features such as an ORM, a templating engine, and an administration interface. Django provides a higher level of abstraction and requires less manual configuration than Flask, making it a good choice for large and complex projects.
In terms of performance, Flask is generally faster than Django, as it has a smaller codebase and fewer built-in features. This can make it a good choice for applications where speed is a critical factor, such as APIs or microservices. However, Django's built-in features can make it faster to develop and deploy complex applications, which can be an advantage in some cases.
Overall, the choice between Flask and Django depends on the specific needs of the project. Flask is a good choice for small to medium-sized applications that require a lightweight and flexible framework with fewer lines of code, while Django is better suited for large and complex applications that require a comprehensive set of lines of code and built-in features.
Q11. Why do we use negative indexes in Python?
In Python, the negative index is used to access elements in a sequence (e.g. list, tuple, string) from the end instead of the beginning. The index -1 represents the last element in the sequence, -2 represents the second last element, and so on.
There are several reasons why negative indexing can be useful in Python:
-
Simplifies code: Negative indexing can make code more concise and easier to read, especially when you need to access elements from the end of the sequence.
-
Avoids errors: Negative indexing can help avoid errors that can occur when you need to calculate the index of the last element in the sequence. Using negative indexing, you can simply access the last element with -1, without having to calculate the index based on the length of the sequence.
-
Enables looping in reverse order: Negative indexing allows you to loop through a sequence in reverse order using a for loop with a step value of -1. This can be useful in certain cases, such as when you need to process data in reverse order.
However, it's important to note that negative indexing is not always the best choice, and it can sometimes make code less readable or harder to understand. It's important to use it judiciously and in a way that makes sense for the specific use case.
Q12. What is a bipartite graph?
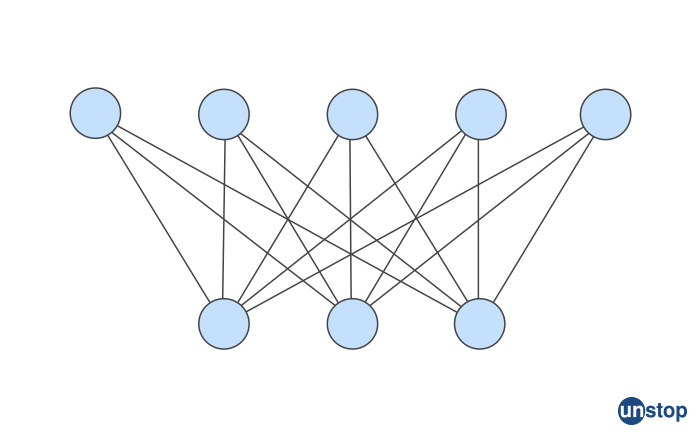
A bipartite graph is a type of graph in which the vertices can be divided into two non-overlapping sets, such that every edge connects a vertex from one set to a vertex in the other set. In other words, a bipartite graph is a graph that can be colored with two colors, such that no two adjacent vertices have the same color.
Formally, a graph G = (V, E) is bipartite if and only if its vertex set V can be partitioned into two sets V1 and V2, such that every edge in E connects a vertex in V1 to a vertex in V2.
These graphs have many interesting properties and applications in different fields. For example, they can be used to model two-sided markets, such as buyers and sellers, or to represent relationships between two different types of objects, such as people and books. Bipartite graphs can also be used to solve problems such as matching, scheduling, and resource allocation.
One important property of these graphs is that they do not contain any odd cycles. This means that if a graph contains an odd cycle, it cannot be bipartite. This property can be used to check if a graph is bipartite or not using algorithms such as the Depth-First Search (DFS) algorithm or the Breadth-First Search (BFS) algorithm.
Q13. Reverse a linked list using temporary variables.
To reverse a linked list using temporary variables, we need to iterate through the list and reverse the direction of the pointers. We can use three-pointers, prev, current, and next, to keep track of the current node, the previous node, and the next node in the list, respectively.
Here is the algorithm:
- Initialize three pointers prev, current, and next to null.
- Set current to the head of the linked list.
- While the current is not null, do the following: (a.) Set next to the next node of the current. (b.) Set the next pointer of current to prev. (c.) Set prev to current. (d.) Set current to next.
- Set the head of the linked list to prev.
Here is the Python code to implement this algorithm:
class Node:
def __init__(self, value):
self.value = value
self.next = None
def reverse_linked_list(head):
prev = None
current = head
while current is not None:
next = current.next
current.next = prev
prev = current
current = next
head = prev
return head
Y2xhc3MgTm9kZToKZGVmIF9faW5pdF9fKHNlbGYsIHZhbHVlKToKc2VsZi52YWx1ZSA9IHZhbHVlCnNlbGYubmV4dCA9IE5vbmUKCmRlZiByZXZlcnNlX2xpbmtlZF9saXN0KGhlYWQpOgpwcmV2ID0gTm9uZQpjdXJyZW50ID0gaGVhZAp3aGlsZSBjdXJyZW50IGlzIG5vdCBOb25lOgpuZXh0ID0gY3VycmVudC5uZXh0CmN1cnJlbnQubmV4dCA9IHByZXYKcHJldiA9IGN1cnJlbnQKY3VycmVudCA9IG5leHQKaGVhZCA9IHByZXYKcmV0dXJuIGhlYWQ=
In this code, we define a Node class to represent each node in the linked list. The reverse_linked_list function takes the head of the linked list as input and returns the new head of the reversed list.

Netflix SQL Interview Questions
Q14. Given a table of user behavior data, how would you find the top 10 most-watched movies on the platform in the last month?
To find the top 10 most watched movies on the platform in the last month, we can use SQL to query the user behavior data table and aggregate the data by movie title. Here's an example SQL query:
SELECT movie_title, COUNT(*) AS num_watches
FROM user_behavior_data
WHERE watch_date >= DATEADD(month, -1, GETDATE())
GROUP BY movie_title
ORDER BY num_watches DESC
LIMIT 10;
U0VMRUNUIG1vdmllX3RpdGxlLCBDT1VOVCgqKSBBUyBudW1fd2F0Y2hlcwpGUk9NIHVzZXJfYmVoYXZpb3JfZGF0YQpXSEVSRSB3YXRjaF9kYXRlID49IERBVEVBREQobW9udGgsIC0xLCBHRVREQVRFKCkpCkdST1VQIEJZIG1vdmllX3RpdGxlCk9SREVSIEJZIG51bV93YXRjaGVzIERFU0MKTElNSVQgMTA7
In this query, we use the COUNT() function to count the number of times each movie has been watched in the last month. We use the WHERE clause to filter the data to only include watches from the last month, which we calculate using the DATEADD() function in combination with the GETDATE() function to get the current date. We then group the data by movie_title and order it in descending order of the number of watches. Finally, we use the LIMIT clause to return only the top 10 results.
Also read: 51 Best PL/SQL Interview Questions With Answers
Q15. Given a table of user ratings, write a SQL query to calculate the average rating for each genre.
To calculate the average rating for each genre in a table of user ratings, we can use SQL to group the ratings by genre and calculate the average using the AVG() function. Here's an example SQL query:
SELECT genre, AVG(rating) AS avg_rating
FROM user_ratings
GROUP BY genre;
U0VMRUNUIGdlbnJlLCBBVkcocmF0aW5nKSBBUyBhdmdfcmF0aW5nCkZST00gdXNlcl9yYXRpbmdzCkdST1VQIEJZIGdlbnJlOw==
In this query, we use the AVG() function to calculate the average rating for each genre in the "user_ratings" table. We group the data by genre using the GROUP BY clause, and then select the "genre" column as well as the calculated average rating, which we alias as "avg_rating".
Q16. Netflix wants to better understand how users consume content on different devices. Write a SQL query to calculate the average viewing time per device type (e.g., smart TV, mobile phone, laptop).
To calculate the average viewing time per device type in a table of user viewing data, we can use SQL to group the viewing times by device type and calculate the average using the AVG() function. Here's an example SQL query:
SELECT device_type, AVG(viewing_time) AS avg_viewing_time
FROM user_viewing_data
GROUP BY device_type;
U0VMRUNUIGRldmljZV90eXBlLCBBVkcodmlld2luZ190aW1lKSBBUyBhdmdfdmlld2luZ190aW1lCkZST00gdXNlcl92aWV3aW5nX2RhdGEKR1JPVVAgQlkgZGV2aWNlX3R5cGU7
In this query, we use the AVG() function to calculate the average viewing time for each device type in the "user_viewing_data" table. We group the data by device type using the GROUP BY clause, and then select the "device_type" column as well as the calculated average viewing time, which we alias as "avg_viewing_time".
Q17. Write a SQL query to find all users who have watched more than 10 hours of content in a single day.
To find all users who have watched more than 10 hours of content in a single day, we can use SQL to group the viewing times by user and day, and then filter for those with a sum of viewing time greater than 10 hours. Here's an example SQL query:
SELECT user_id
FROM user_viewing_data
GROUP BY user_id, DATE(viewing_time)
HAVING SUM(viewing_duration) > 600; -- 10 hours = 600 minutes
U0VMRUNUIHVzZXJfaWQKRlJPTSB1c2VyX3ZpZXdpbmdfZGF0YQpHUk9VUCBCWSB1c2VyX2lkLCBEQVRFKHZpZXdpbmdfdGltZSkKSEFWSU5HIFNVTSh2aWV3aW5nX2R1cmF0aW9uKSA+IDYwMDsgLS0gMTAgaG91cnMgPSA2MDAgbWludXRlcw==
In this query, we group the user viewing data by both the user ID and the date portion of the viewing time using the DATE() function. We then use the HAVING clause to filter for those groups (i.e. user and day combinations) where the sum of viewing duration is greater than 10 hours, which is equivalent to 600 minutes.
Q18. Write a SQL query to identify users who are likely to cancel their subscription based on their viewing history and other relevant data.
To identify users who are likely to cancel their subscriptions based on their viewing history and other relevant data, we can use SQL to analyze various factors such as the user's viewing behavior, account status, and payment history. Here's an example SQL query:
SELECT user_id
FROM user_viewing_data
WHERE account_status = 'active' -- consider only active users
AND payment_status = 'paid' -- consider only users with paid subscriptions
AND last_payment_date <= DATEADD(month, -1, GETDATE()) -- consider only users who have paid within the last month
AND (
-- users who have not viewed any content in the past 30 days
last_viewing_date <= DATEADD(day, -30, GETDATE())
OR
-- users with high levels of buffering or low video quality
(SELECT AVG(buffering_time) FROM user_viewing_data WHERE user_id = u.user_id) >= 30
OR
(SELECT AVG(video_quality) FROM user_viewing_data WHERE user_id = u.user_id) <= 3
OR
-- users with a high number of incomplete views
(SELECT COUNT(*) FROM user_viewing_data WHERE user_id = u.user_id AND is_complete = 0) >= 10
)
U0VMRUNUIHVzZXJfaWQKRlJPTSB1c2VyX3ZpZXdpbmdfZGF0YQpXSEVSRSBhY2NvdW50X3N0YXR1cyA9ICdhY3RpdmUnIC0tIGNvbnNpZGVyIG9ubHkgYWN0aXZlIHVzZXJzCkFORCBwYXltZW50X3N0YXR1cyA9ICdwYWlkJyAtLSBjb25zaWRlciBvbmx5IHVzZXJzIHdpdGggcGFpZCBzdWJzY3JpcHRpb25zCkFORCBsYXN0X3BheW1lbnRfZGF0ZSA8PSBEQVRFQUREKG1vbnRoLCAtMSwgR0VUREFURSgpKSAtLSBjb25zaWRlciBvbmx5IHVzZXJzIHdobyBoYXZlIHBhaWQgd2l0aGluIHRoZSBsYXN0IG1vbnRoCkFORCAoCi0tIHVzZXJzIHdobyBoYXZlIG5vdCB2aWV3ZWQgYW55IGNvbnRlbnQgaW4gdGhlIHBhc3QgMzAgZGF5cwpsYXN0X3ZpZXdpbmdfZGF0ZSA8PSBEQVRFQUREKGRheSwgLTMwLCBHRVREQVRFKCkpCk9SCi0tIHVzZXJzIHdpdGggaGlnaCBsZXZlbHMgb2YgYnVmZmVyaW5nIG9yIGxvdyB2aWRlbyBxdWFsaXR5CihTRUxFQ1QgQVZHKGJ1ZmZlcmluZ190aW1lKSBGUk9NIHVzZXJfdmlld2luZ19kYXRhIFdIRVJFIHVzZXJfaWQgPSB1LnVzZXJfaWQpID49IDMwCk9SCihTRUxFQ1QgQVZHKHZpZGVvX3F1YWxpdHkpIEZST00gdXNlcl92aWV3aW5nX2RhdGEgV0hFUkUgdXNlcl9pZCA9IHUudXNlcl9pZCkgPD0gMwpPUgotLSB1c2VycyB3aXRoIGEgaGlnaCBudW1iZXIgb2YgaW5jb21wbGV0ZSB2aWV3cwooU0VMRUNUIENPVU5UKCopIEZST00gdXNlcl92aWV3aW5nX2RhdGEgV0hFUkUgdXNlcl9pZCA9IHUudXNlcl9pZCBBTkQgaXNfY29tcGxldGUgPSAwKSA+PSAxMAop
In this query, we select the user ID from the user viewing data table and filter for users who meet certain criteria that may indicate a likelihood to cancel their subscription.
Netflix Design Interview Questions for Site Reliability Engineer (SRE) Role
Q19. Design Web crawler.
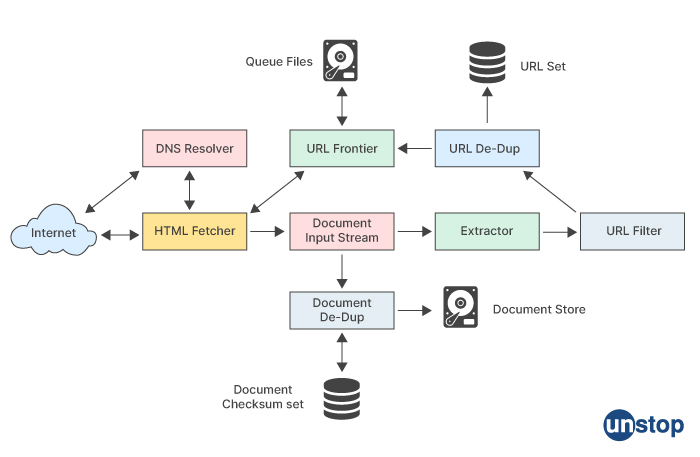
Designing a web crawler can be a complex task, but here is a high-level overview of the process:
-
Identify the scope of the design web crawler: Decide what websites you want to crawl, how deep you want to go into each website, and what types of data you want to collect.
-
Choose a programming language and web framework: Choose a programming language and web framework that you are comfortable with and that has good support for web scraping.
-
Build a crawler: Create a web crawler that can navigate the web and collect data. The crawler should be able to handle HTTP requests and responses, parse HTML and other web content, and store the collected data.
-
Optimize the crawler: Optimize the crawler to handle large volumes of data and avoid being blocked by websites. Implement techniques such as rate limiting, caching, and parallelization to make the crawler efficient and scalable.
-
Store the data: Decide how you want to store the data that is collected by the crawler. You can use a database or a file system to store the data.
Here are some of the key considerations in designing a web crawler:
-
Web scraping ethics: Make sure that your web crawler complies with web scraping ethics and does not violate any website's terms of service.
-
Crawl frequency: Be careful not to crawl a website too frequently as this can overload the website's servers and cause your IP address to be blocked.
-
Data storage: Choose a data storage solution that can handle large volumes of data and is easy to query and analyze.
-
Handling dynamic content: Websites that use dynamic content such as JavaScript can be challenging to crawl. You may need to use a headless browser or a JavaScript rendering service to scrape these websites.
-
Handling errors: Your crawler should be able to handle errors such as timeouts, server errors, and invalid URLs.
Overall, designing a web crawler requires careful planning, a solid understanding of web scraping technologies, and attention to detail.
Q20. Design a URL shortener.
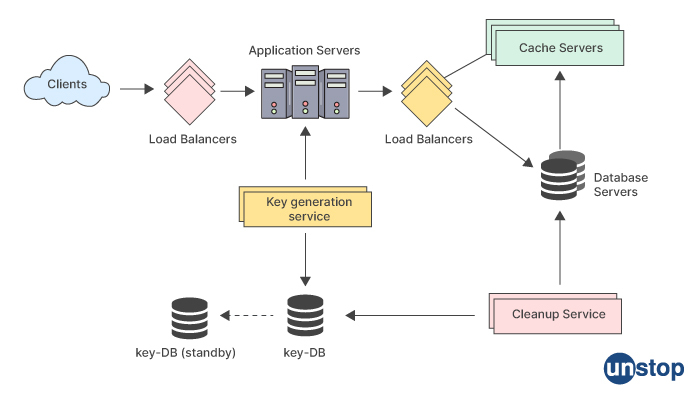
A URL shortener is a service that takes long URLs and generates short URLs that can be easily shared and accessed. Here is a high-level overview of how to design an URL shortener:
-
Decide on the scope of the URL shortener: Decide what features you want to include in the URL shortener. For example, you may want to include analytics to track clicks, a custom alias feature, and an API for programmatic access.
-
Choose a data storage solution: Choose a data storage solution to store the long URLs and their corresponding short URLs. You can use a relational database or a NoSQL database depending on the scale of the service.
-
Generate short URLs: Create a function to generate short URLs. You can use a hash function or encoding algorithm to generate short URLs. Make sure to check for collisions and handle them appropriately.
-
Redirect to long URLs: When a short URL is accessed, your service should redirect the user to the corresponding long URL. Make sure to handle cases where the short URL is invalid or has expired.
-
Track clicks: If you want to include analytics, you can track the number of clicks on each short URL and store this information in your database.
-
Create a custom alias feature: If you want to allow users to create custom aliases for their short URLs, you can create a form for users to enter their desired alias and validate it to ensure it is unique and does not conflict with any existing short URLs.
-
Create an API: If you want to provide programmatic access to your service, you can create an API that allows users to generate short URLs and access analytics.
Overall, designing an URL shortener requires careful planning, attention to security, and efficient data storage and retrieval.
Q21. Design Netflix.
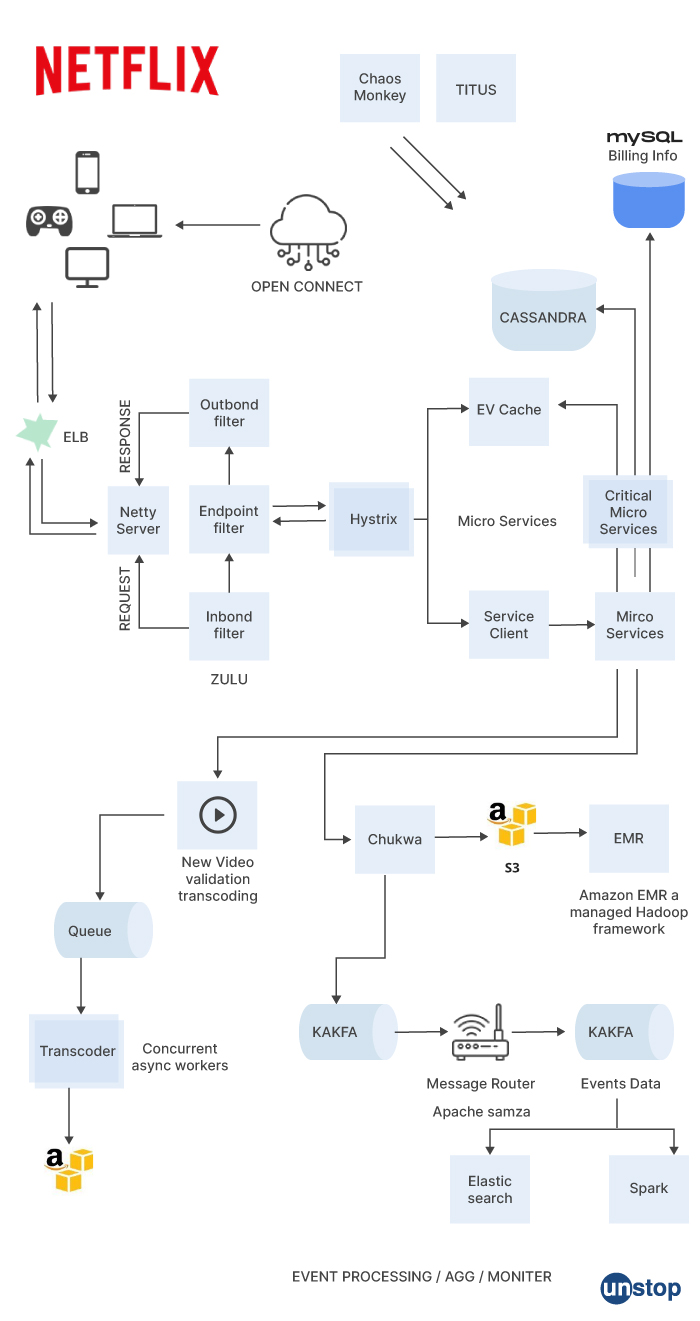
Designing Netflix can be a complex task, but here is a high-level overview of the process:
-
Identify the scope of Netflix: Decide what features you want to include in Netflix. For example, you may want to include a video player, user profiles, search functionality, and recommendations.
-
Choose a programming language and web framework: Choose a programming language and web framework that you are comfortable with and that has good support for video streaming and user authentication.
-
Build a video player: Create a video player that can stream video content from a content delivery network (CDN) and handle different video formats and resolutions. The video player should also have features such as playback controls, captions, and quality settings.
-
Build user profiles: Create user profiles that allow users to personalize their Netflix experience. Users should be able to create multiple profiles, manage their watchlist, and receive recommendations based on their viewing history.
-
Implement search functionality: Implement search functionality that allows users to search for movies and TV shows by title, genre, and cast.
-
Build a recommendation engine: Implement a recommendation engine that analyzes user viewing history and suggests relevant content. The recommendation engine can use machine learning algorithms such as collaborative filtering or content-based filtering.
-
Secure user data: Make sure to secure user data such as login credentials, viewing history, and payment information. Use encryption, secure communication protocols, and access controls to protect user data.
-
Optimize for performance: Optimize Netflix to handle large volumes of video content and user traffic. Use techniques such as caching, load balancing, and CDN to improve performance.
Overall, to design Netflix, one requires careful planning, a solid understanding of video streaming technologies and user experience design, and attention to security and performance.
Q22. Design API Rate Limiter.
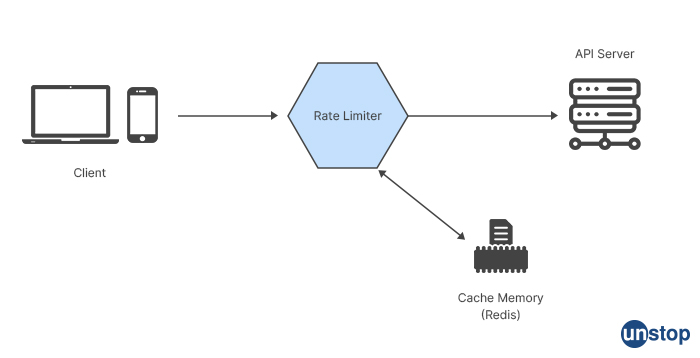
API rate limiting is a technique that allows an API to limit the number of requests made by a single client within a specified time period. This helps prevent abuse of the API and ensures fair access to resources for all clients. Here is a high-level design of an API rate limiter:
-
Identify the rate limit parameters: Determine the parameters that will be used to limit the API rate, such as the number of requests allowed per client per time period (e.g. 100 requests per hour), the time period for the limit (e.g. 1 hour), and the penalty for exceeding the limit (e.g. a 429 status code or a temporary ban).
-
Implement a data store: Set up a data store, such as a relational database or a key-value store, to store client request data, including the client ID, request count, and timestamp of the last request.
-
Write a middleware layer: Write a middleware layer that intercepts incoming requests and checks if the client has exceeded the rate limit. If the client has not exceeded the limit, the request is passed through to the API. If the client has exceeded the limit, the middleware returns a 429 status code or applies a penalty, such as a temporary ban.
-
Store client request data: When a request is made, the middleware layer retrieves the client's request data from the data store and checks if the request count exceeds the limit for the time period. If the request count exceeds the limit, the middleware layer returns a 429 status code or applies a penalty.
-
Update client request data: After a request is processed, the middleware layer updates the client's request data in the data store to reflect the new request count and timestamp.
-
Handle exceptions: Implement exception handling for cases where the data store is unavailable or when there is a problem with the rate limit parameters.
Overall, designing an API rate limiter requires careful consideration of the rate limit parameters, the implementation of a data store to store client request data, and the development of a middleware layer to intercept and check incoming requests. Proper exception handling and testing are also important to ensure the system operates as intended.
Netflix HR Interview Questions
Q23. What do you think sets Netflix apart from other streaming platforms?
This question is designed to assess your understanding of the company's values and vision. Before going into the interview, research the company's emphasis on culture fit, values, culture document, and mission statement to answer this question effectively. Highlight the aspects of the company that you find unique and appealing. Here are a few points that aspirants can mention:
-
Original Content: Netflix invests heavily in producing its own original content, which has helped it differentiate itself from other streaming platforms.
-
Personalized Recommendations: Netflix's recommendation algorithm is widely considered to be one of the most sophisticated and effective in the industry.
-
User-Friendly Interface: Netflix's interface is designed to be user-friendly and easy to navigate. The platform's simple and intuitive interface allows users to easily find and watch the content they want, which has contributed to its popularity.
-
Global Reach: Netflix operates in over 190 countries, making it one of the most widely available streaming platforms in the world. This global reach has allowed Netflix to become a household name and reach a massive audience.
-
Technological Innovations: Netflix has been at the forefront of technological innovation in the streaming industry. For example, the company was one of the first to introduce the concept of binge-watching and has also experimented with interactive content and virtual reality experiences.
Q24. How do you stay up-to-date with the latest trends in your industry?
Netflix is a company that prides itself on innovation and staying ahead of the curve. This question is designed to assess your passion for your work and your commitment to staying informed about industry developments. Staying up-to-date with the latest trends in any industry is important for professional growth and success. Here are some of the ways that you may mention:
-
Reading industry publications: Subscribing to industry-specific magazines, blogs, and newsletters to keep up-to-date with the latest news and developments.
-
Attending conferences and events: Attending conferences, seminars, and other events related to the industry of intrest. These events offer opportunities to learn from experts and network with other professionals.
-
Taking courses and certifications: Participating in online courses and certifications helps acquire new skills and knowledge in any particular field.
-
Following thought leaders and experts: Following influential people in your industry on social media platforms, like Twitter and LinkedIn, help to stay updated with the latest trends and insights.
-
Joining professional associations: Joining professional associations and organizations that represent your industry helps to stay updated with the latest developments and collaborate with other professionals.
-
Networking: Networking with peers, attending industry events, following industry influencers and experts, and attending online forums are all great ways to stay up-to-date on the latest trends in your industry.
Q25. How do you approach teamwork and collaboration?
I usually approach teamwork and collaboration by focusing on the following soft skills and qualities:
-
Communication: According to me communication is key in any collaborative effort. It's important to be clear and concise in your communication and to actively listen to your team members. Regular check-ins and updates can help ensure that everyone is on the same page.
-
Roles and Responsibilities: Clarifying roles and responsibilities is essential for successful collaboration and project management. Each team member should have a clear understanding of what they are responsible for and what their role is in the project and how they can demonstrate their problem-solving skills effectively.
-
Flexibility: It's important to be flexible and open to new ideas and approaches. Collaboration often requires compromise and adapting to different perspectives and working styles.
-
Trust: Trust is critical for effective collaboration. Each team member should be able to trust that their colleagues will fulfill their responsibilities and work towards the common goal.
-
Conflict Resolution: Conflicts are inevitable in any collaborative effort. It's important to approach conflicts with a focus on finding a solution that works for everyone, rather than placing blame or getting defensive.
Q26. What kind of work environment do you thrive in?
A work environment that is collaborative, supportive, flexible, positive, and challenging can be motivating and conducive to my productivity and job satisfaction.
(You may explain these with examples from your own experience. Here is the detailed description of each term to help you cut down to the chase.)
-
Collaborative: A work environment that fosters collaboration and team management can be motivating and inspiring. When team players work together, they can share ideas and knowledge, leading to more innovative solutions and better outcomes.
-
Supportive: A supportive work environment is one in which employees feel valued and respected. This can be achieved by providing regular feedback, recognizing employee achievements, and offering opportunities for career growth and team building.
-
Flexible: A flexible work environment is one that allows team players to balance work and personal life. Flexible work arrangements such as remote work or flexible hours can lead to increased job satisfaction and work-life balance as well as time management.
-
Positive: A positive work environment is one that promotes positivity and well-being. This can be achieved through open communication, providing opportunities for stress management, and time management, and fostering a culture of inclusivity and diversity.
-
Challenging: A challenging work environment is one that provides employees with opportunities to learn and grow. This can be achieved by encouraging the team to take on new responsibilities and offering opportunities for professional development.
Q27. What are your long-term career goals?
This question is designed to assess your career aspirations, and soft skills, and whether they align with the company's goals. Be honest about your career goals, but also emphasize how working at Netflix can help you achieve those goals. Talk about how the company's values and culture fit and align with your personal values and career objectives.
Here are some tips to keep in mind that will help you to get your dream job:
-
Be specific: Share your specific long-term goals, whether it's advancing to a certain position, developing a specific skill set, or working on a particular project.
-
Demonstrate a sense of purpose: Explain how your long-term goals align with your personal values and sense of purpose. This will show the interviewer that you are committed to your career and are driven by a sense of purpose.
-
Show that you are proactive: Explain how you plan to achieve your long-term goals, whether it's through further education, networking, or taking on new challenges and working with your dream team.
-
Be realistic: While it's important to aim high, make sure that your long-term goals are realistic and achievable. This will show the hiring manager that you have a clear understanding of your strengths and limitations.
Also read: Guide To Answer- "What Is Your Greatest Strength?" (Samples Inside)
Q28. Can you tell us about a project you worked on that you are particularly proud of?
This question is asked to assess your past work experience, your ability to work in a team, and your problem-solving skills. When answering this question during the interview process, it's important to provide a specific example and explain your thought process behind it. Make sure you highlight your role in the project, the challenges you faced, and how you overcame them.
Q29. How do you handle extreme stress?
Handling extreme stress can be challenging, but there are several strategies I try to manage it effectively:
-
Identifying the source of your stress: It's important to understand the source of your stress so you can address it directly. Once you know what's causing your stress, you can take steps to manage it.
-
Practicing self-care: Taking care of yourself is essential when dealing with stress. Get enough sleep, eat a healthy diet, and exercise regularly. You might also consider incorporating relaxation techniques, such as deep breathing or meditation, into your routine.
-
Prioritizing tasks: When you're under a lot of stress, it can be difficult to know where to start. Make a list of tasks and prioritize them based on importance and urgency. This will help you stay focused and avoid feeling overwhelmed.
-
Seeking support: Talking to someone you trust about your stress can help you feel less alone and more supported. This might be a friend, family member, or mental health professional.
-
Taking breaks: It's important to take regular breaks throughout the day to recharge and prevent burnout. Whether it's taking a walk, listening to music, or doing a quick meditation exercise, taking a few minutes to yourself can help you manage stress more effectively.
Practicing self-care, prioritizing tasks, seeking support, and taking breaks, helps me effectively manage extreme stress and maintain my well-being.
Q30. What inspired you to pursue a career in software engineering?
Software engineering is a rapidly evolving and exciting field that has a significant impact on modern society. Creating innovative solutions to complex problems that can transform the way we live and work drives me. This is why I landed in the field of software engineering - a field with endless possibilities for innovation, creativity, and impact!
We hope that these Netflix interview questions for software engineer and SRE roles will help you win that dream job! Good luck!
Some suggested reads:
- What Is GitHub? An Introduction, How-To Use It, Components & More!
- Netflix Recruitment Process 2023: Eligibility, Stages, Salary!
- D. E. Shaw Interview Questions For Coding, Technical & HR Round
- What Is Terminal In Linux? | Components, Types & Standard Commands
- History Of C++ | Detailed Explanation (With Timeline Infographic)
Login to continue reading
And access exclusive content, personalized recommendations, and career-boosting opportunities.
Don't have an account? Sign up
Never miss an
Update

Featured Opportunities
Top-Rated Practice by Students





Subscribe
to our newsletter




Comments
Add comment