
Asian Paints Alchemy 2026
Data Structures & Algorithms
- What Is Data Structure?
- Key Features Of Data Structures
- Basic Terminologies Related To Data Structures
- Types Of Data Structures
- What Are Linear Data Structures & Its Types?
- What Are Non-Linear Data Structures & Its Types?
- Importance Of Data Structure In Programming
- Basic Operations On Data Structures
- Applications Of Data Structures
- Real-Life Applications Of Data Structures
- Linear Vs. Non-linear Data Structures
- What Are Algorithms? The Difference Between Data Structures & Algorithms
- Conclusion
- Frequently Asked Questions
- What Is Asymptotic Notation?
- How Asymptotic Notation Helps In Analyzing Performance
- Types Of Asymptotic Notation
- Big-O Notation (O)
- Omega Notation (Ω)
- Theta Notation (Θ)
- Little-O Notation (o)
- Little-Omega Notation (ω)
- Summary Of Asymptotic Notations
- Real-World Applications Of Asymptotic Notation
- Conclusion
- Frequently Asked Questions
- Understanding Big O Notation
- Types Of Time Complexity
- Space Complexity In Big O Notation
- How To Determine Big O Complexity
- Best, Worst, And Average Case Complexity
- Applications Of Big O Notation
- Conclusion
- Frequently Asked Questions
- What Is Time Complexity?
- Why Do You Need To Calculate Time Complexity?
- The Time Complexity Algorithm Cases
- Time Complexity: Different Types Of Asymptotic Notations
- How To Calculate Time Complexity?
- Time Complexity Of Sorting Algorithms
- Time Complexity Of Searching Algorithms
- Writing And optimizing An algorithm
- What Is Space Complexity And Its Significance?
- Relation Between Time And Space Complexity
- Conclusion
- What Is Linear Data Structure?
- Key Characteristics Of Linear Data Structures
- What Are The Types Of Linear Data Structures?
- What Is An Array Linear Data Structure?
- What Are Linked Lists Linear Data Structure?
- What Is A Stack Linear Data Structure?
- What Is A Queue Linear Data Structure?
- Most Common Operations Performed in Linear Data Structures
- Advantages Of Linear Data Structures
- What Is Nonlinear Data Structure?
- Difference Between Linear & Non-Linear Data Structures
- Who Uses Linear Data Structures?
- Conclusion
- Frequently Asked Questions
- What is a linear data structure?
- What is a non-linear data structure?
- Difference between linear data structure and non-linear data structure
- FAQs about linear and non-linear data structures
- What Is Search?
- What Is Linear Search In Data Structure?
- What Is Linear Search Algorithm?
- Working Of Linear Search Algorithm
- Complexity Of Linear Search Algorithm In Data Structures
- Implementations Of Linear Search Algorithm In Different Programming Languages
- Real-World Applications Of Linear Search In Data Structure
- Advantages & Disadvantages Of Linear Search
- Best Practices For Using Linear Search Algorithm
- Conclusion
- Frequently Asked Questions
- What Is The Binary Search Algorithm?
- Conditions For Using Binary Search
- Steps For Implementing Binary Search
- Iterative Method For Binary Search With Implementation Examples
- Recursive Method For Binary Search
- Complexity Analysis Of Binary Search Algorithm
- Iterative Vs. Recursive Implementation Of Binary Search
- Advantages & Disadvantages Of Binary Search
- Practical Applications & Real-World Examples Of Binary Search
- Conclusion
- Frequently Asked Questions
- Understanding The Jump Search Algorithm
- How Jump Search Works?
- Code Implementation Of Jump Search Algorithm
- Time And Space Complexity Analysis
- Advantages Of Jump Search
- Disadvantages Of Jump Search
- Applications Of Jump Search
- Conclusion
- Frequently Asked Questions
- What Is Sorting In Data Structures?
- What Is Bubble Sort?
- What Is Selection Sort?
- What Is Insertion Sort?
- What Is Merge Sort?
- What Is Quick Sort?
- What Is Heap Sort?
- What Is Radix Sort?
- What Is Bucket Sort?
- What Is Counting Sort?
- What Is Shell Sort?
- Choosing The Right Sorting Algorithm
- Applications Of Sorting
- Conclusion
- Frequently Asked Questions
- Understanding Bubble Sort Algorithm
- Bubble Sort Algorithm
- Implementation Of Bubble Sort In C++
- Time And Space Complexity Analysis Of Bubble Sort Algorithm
- Advantages Of Bubble Sort Algorithm
- Disadvantages Of Bubble Sort Algorithm
- Applications of Bubble Sort Algorithms
- Conclusion
- Frequently Asked Questions
- Understanding The Merge Sort Algorithm
- Algorithm For Merge Sort
- Implementation Of Merge Sort In C++
- Time And Space Complexity Analysis Of Merge Sort
- Advantages And Disadvantages Of Merge Sort
- Applications Of Merge Sort
- Conclusion
- Frequently Asked Questions
- Understanding The Selection Sort Algorithm
- Algorithmic Approach To Selection Sort
- Implementation Of Selection Sort Algorithm
- Complexity Analysis Of Selection Sort
- Comparison Of Selection Sort With Other Sorting Algorithms
- Advantages And Disadvantages Of Selection Sort
- Application Of Selection Sort
- Conclusion
- Frequently Asked Questions
- What Is Insertion Sort Algorithm?
- How Does Insertion Sort Work? (Step-by-Step Explanation)
- Implementation of Insertion Sort in C++
- Time And Space Complexity Of Insertion Sort
- Applications Of Insertion Sort Algorithm
- Comparison With Other Sorting Algorithms
- Conclusion
- Frequently Asked Questions
- Understanding Quick Sort Algorithm
- Step-By-Step Working Of Quick Sort
- Implementation Of Quick Sort Algorithm
- Time Complexity Analysis Of Quick Sort
- Advantages Of Quick Sort Algorithm
- Disadvantages Of Quick Sort Algorithm
- Applications Of Quick Sort Algorithm
- Conclusion
- Frequently Asked Questions
- Understanding The Heap Data Structure
- Working Of Heap Sort Algorithm
- Implementation Of Heap Sort Algorithm
- Advantages Of Heap Sort
- Disadvantages Of Heap Sort
- Real-World Applications Of Heap Sort
- Conclusion
- Frequently Asked Questions
- Understanding The Counting Sort Algorithm
- Conditions For Using Counting Sort Algorithm
- How Counting Sort Algorithm Works?
- Implementation Of Counting Sort Algorithm
- Time And Space Complexity Analysis Of Counting Sort
- Comparison Of Counting Sort With Other Sorting Algorithms
- Advantages Of Counting Sort Algorithm
- Disadvantages Of Counting Sort Algorithm
- Applications Of Counting Sort Algorithm
- Conclusion
- Frequently Asked Questions
- Understanding Shell Sort Algorithm
- Working Of Shell Sort Algorithm
- Implementation Of Shell Sort Algorithm
- Time Complexity Analysis Of Shell Sort Algorithm
- Advantages Of Shell Sort Algorithm
- Disadvantages Of Shell Sort Algorithm
- Applications Of Shell Sort Algorithm
- Conclusion
- Frequently Asked Questions
- What Is Linked List In Data Structures?
- Types Of Linked Lists In Data Structures
- Linked List Operations In Data Structures
- Advantages And Disadvantages Of Linked Lists In Data Structures
- Comparison Of Linked Lists And Arrays
- Applications Of Linked Lists
- Conclusion
- Frequently Asked Questions
- What Is A Singly Linked List In Data Structure?
- Insertion Operations On Singly Linked Lists
- Deletion Operation On Singly Linked List
- Searching For Elements In Single Linked List
- Calculating Length Of Single Linked List
- Practical Applications Of Singly Linked Lists In Data Structure
- Common Problems With Singly Linked Lists
- Conclusion
- Frequently Asked Questions (FAQ)
- What Is A Linked List?
- Reverse A Linked List
- How To Reverse A Linked List? (Approaches)
- Recursive Approach To Reverse A Linked List
- Iterative Approach To Reverse A Linked List
- Using Stack To Reverse A Linked List
- Complexity Analysis Of Different Approaches To Reverse A Linked List
- Conclusion
- Frequently Asked Questions
- What Is A Stack In Data Structure?
- Understanding Stack Operations
- Stack Implementation In Data Structures
- Stack Implementation Using Arrays
- Stack Implementation Using Linked Lists
- Comparison: Array vs. Linked List Implementation
- Applications Of Stack In Data Structures
- Advantages And Disadvantages Of Stack Data Structure
- Conclusion
- Frequently Asked Questions
- What Is A Graph Data Structure?
- Importance Of Graph Data Structures
- Types Of Graphs In Data Structure
- Types Of Graph Algorithms
- Application Of Graphs In Data Structures
- Challenges And Complexities In Graphs
- Conclusion
- Frequently Asked Questions
- What Is Tree Data Structure?
- Terminologies Of Tree Data Structure:
- Different Types Of Tree Data Structures
- Basic Operations On Tree Data Structure
- Applications Of Tree Data Structures
- Comparison Of Trees, Graphs, And Linear Data Structures
- Advantages Of Tree Data Structure
- Disadvantages Of Tree Data Structure
- Conclusion
- Frequently Asked Questions
- What Is Dynamic Programming?
- Real-Life Example: The Jigsaw Puzzle Analogy
- How To Solve A Problem Using Dynamic Programming?
- Dynamic Programming Algorithm Techniques
- Advantages Of Dynamic Programming
- Disadvantages Of Dynamic Programming
- Applications Of Dynamic Programming
- Conclusion
- Frequently Asked Questions
- Understanding The Sliding Window Algorithm
- How Does The Sliding Window Algorithm Works?
- How To Identify Sliding Window Problems?
- Fixed-Size Sliding Window Example: Maximum Sum Subarray Of Size k
- Variable-Size Sliding Window Example: Smallest Subarray With A Given Sum
- Advantages Of Sliding Window Technique
- Disadvantages Of Sliding Window Technique
- Conclusion
- Frequently Asked Questions
- Introduction To Data Structures
- Data Structures Interview Questions: Basics
- Data Structures Interview Questions: Intermediate
- Data Structures Interview Questions: Advanced
- Conclusion
Single Linked List In Data Structure | All Operations (+Examples)
Discover everything about singly linked lists in data structures—understand their structure, learn insertion and deletion methods, and explore real-world applications in programming.
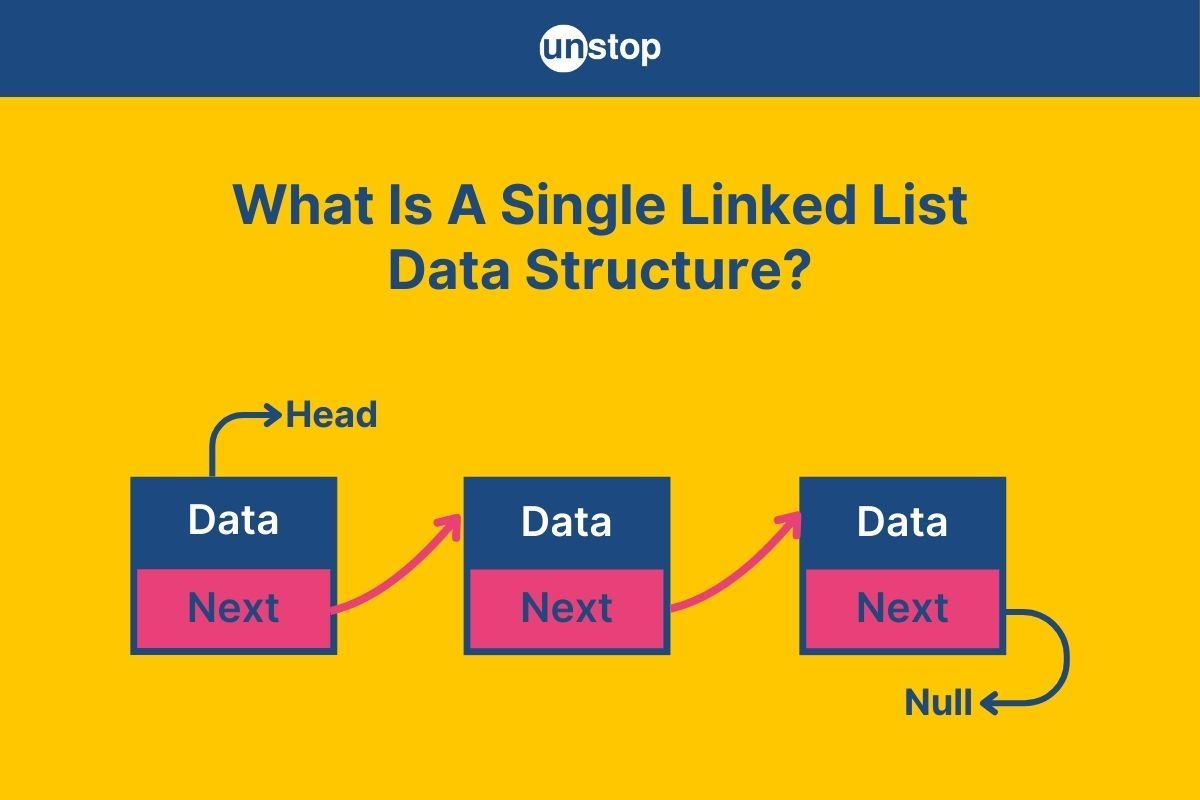
Picture this: you’re organizing a line of tasks to complete one after another. You can only see the current task and the next one ahead, and each task knows only the one that follows. This concept is the essence of a singly linked list, a fundamental data structure in programming.
In this article, we’ll explore singly linked lists, including what they are, how they work, and why they’re essential for storing and managing data. Whether you’re coding a to-do list, building a navigation system, or designing a queue for processing, singly linked lists are here to make your life easier.
What Is A Singly Linked List In Data Structure?
A singly linked list is a linear data structure where each element, called a node, points to the next node in the sequence. Unlike arrays, linked lists don’t require a contiguous block of memory. Instead, each node contains two parts:
- Data: Stores the actual information.
- Pointer (or link): Holds the address of the next node in the list.
The first node in the list is called the head, and the last node’s pointer is set to NULL, indicating the end of the list.
Key Features Of Singly Linked Lists
- Dynamic Size: They grow or shrink as needed, making them memory-efficient compared to arrays.
- Sequential Access: Nodes can only be accessed sequentially, starting from the head.
- Efficient Insertion/Deletion: Adding or removing elements doesn’t require shifting data, unlike arrays.
Think of a singly linked list as a treasure hunt. Each clue (node) points to the location of the next clue until you reach the final treasure (end of the list). Now that you know the basics of single-linked lists in data structures, let’s take a look at the internal structure of these lists and how they work.
Structure Of A Singly Linked List
To truly understand how a singly linked list operates, let’s break down its structure and components step-by-step:
- Node: The basic building block of a singly linked list is a node, which consists of two main parts:
- Data: Holds the actual information (e.g., a number, string, or object).
- Next: A pointer or reference to the next node in the sequence. For the last node, this is set to NULL.
- Head: The head is a special pointer that points to the first node in the list. Without the head, the list would be inaccessible.
- Tail: The tail is the last node in the list, where the Next pointer is NULL, signaling the end of the list.
- Traversal: Starting from the head, the list is traversed node by node using the Next pointer. This sequential nature means you can only access elements in order.
Diagram Of Singly Linked List
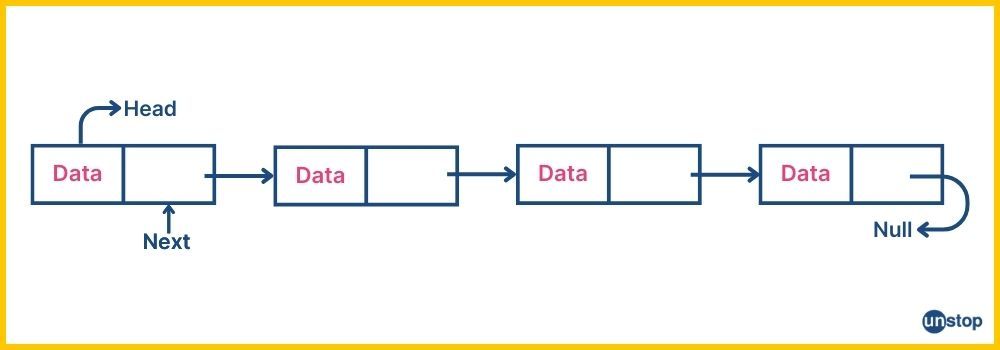
Here:
- The Head points to the first node.
- Each node points to the next one.
- The final node points to NULL.
Example Of Singly Linked List Program In Data Structure (Basic Node Structure)
Let’s look at an example of how the single linked list creation works in C++ programming language.
#include
using namespace std;
class Node {
public:
int data; // To store data
Node* next; // Pointer to the next node
// Constructor
Node(int value) {
data = value;
next = nullptr; // Initialize next as NULL
}
};
int main() {
// Creating nodes
Node* node1 = new Node(10);
Node* node2 = new Node(20);
// Linking nodes
node1->next = node2;
// Accessing data
cout << "Data in Node 1: " << node1->data << endl;
cout << "Data in Node 2: " << node1->next->data << endl;
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgp1c2luZyBuYW1lc3BhY2Ugc3RkOwoKY2xhc3MgTm9kZSB7CnB1YmxpYzoKaW50IGRhdGE7IC8vIFRvIHN0b3JlIGRhdGEKTm9kZSogbmV4dDsgLy8gUG9pbnRlciB0byB0aGUgbmV4dCBub2RlCgovLyBDb25zdHJ1Y3RvcgpOb2RlKGludCB2YWx1ZSkgewpkYXRhID0gdmFsdWU7Cm5leHQgPSBudWxscHRyOyAvLyBJbml0aWFsaXplIG5leHQgYXMgTlVMTAp9Cn07CgppbnQgbWFpbigpIHsKLy8gQ3JlYXRpbmcgbm9kZXMKTm9kZSogbm9kZTEgPSBuZXcgTm9kZSgxMCk7Ck5vZGUqIG5vZGUyID0gbmV3IE5vZGUoMjApOwoKLy8gTGlua2luZyBub2Rlcwpub2RlMS0+bmV4dCA9IG5vZGUyOwovLyBBY2Nlc3NpbmcgZGF0YQpjb3V0IDw8ICJEYXRhIGluIE5vZGUgMTogIiA8PCBub2RlMS0+ZGF0YSA8PCBlbmRsOwpjb3V0IDw8ICJEYXRhIGluIE5vZGUgMjogIiA8PCBub2RlMS0+bmV4dC0+ZGF0YSA8PCBlbmRsOwoKcmV0dXJuIDA7Cn0=
Output:
Data in Node 1: 10
Data in Node 2: 20
Code Explanation:
- We create a class called Node containing two data members: data (an integer data type variable to store the value of the node.) and next (a pointer variable of type Node* to store the address of the next node in the list).
- Both members are defined using the public access specifier, meaning they can be accessed directly throughout the program.
- We then define a class constructor (also public) to initialize the data member with the given value and set next to nullptr.
- In the main() function, we create two nodes, node1 and node2. Each node is an instance of the Node class, initialized with a data value and a next pointer set to nullptr by default.
- Next, we update the next pointer of node1 to point to node2, creating a link between the two nodes.
- We can then traverse the list starting from node1 and access the data values stored in each node.
Next, we’ll explore insertion operations in single linked lists in data structures to see how nodes are added at different positions.

Insertion Operations On Singly Linked Lists
Insertion is one of the most fundamental operations performed on a single linked list. Depending on where the new node is added, there are three types of insertion operations: at the beginning, at the end, or at a specific position. We’ll explore all these with examples.
Insertion At Beginning Of Singly Linked List
Inserting a node at the beginning of a singly linked list involves adding a new node such that it becomes the first node (head) of the list. The next pointer of this new node is updated to point to the previous head node. Here is how this works:
- Create a new node and assign the data.
- Update the next pointer of the new node to point to the current head node.
- Update the head pointer to point to the new node.
Code Example:
#include
using namespace std;
class Node {
public:
int data;
Node* next;
Node(int value) {
data = value;
next = nullptr;
}
};
void insertAtBeginning(Node*& head, int newData) {
// Step 1: Create a new node
Node* newNode = new Node(newData);
// Step 2: Point newNode->next to the current head
newNode->next = head;
// Step 3: Update the head to the new node
head = newNode;
}
void printList(Node* head) {
while (head != nullptr) {
cout << head->data << " -> ";
head = head->next;}
cout << "NULL" << endl;
}
int main() {
Node* head = nullptr; // Initially, the list is empty
insertAtBeginning(head, 30);
insertAtBeginning(head, 20);
insertAtBeginning(head, 10);
printList(head); // Output: 10 -> 20 -> 30 -> NULL
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgp1c2luZyBuYW1lc3BhY2Ugc3RkOwoKY2xhc3MgTm9kZSB7CnB1YmxpYzoKaW50IGRhdGE7Ck5vZGUqIG5leHQ7Ck5vZGUoaW50IHZhbHVlKSB7CmRhdGEgPSB2YWx1ZTsKbmV4dCA9IG51bGxwdHI7Cn0KfTsKCnZvaWQgaW5zZXJ0QXRCZWdpbm5pbmcoTm9kZSomIGhlYWQsIGludCBuZXdEYXRhKSB7Ci8vIFN0ZXAgMTogQ3JlYXRlIGEgbmV3IG5vZGUKTm9kZSogbmV3Tm9kZSA9IG5ldyBOb2RlKG5ld0RhdGEpOwovLyBTdGVwIDI6IFBvaW50IG5ld05vZGUtPm5leHQgdG8gdGhlIGN1cnJlbnQgaGVhZApuZXdOb2RlLT5uZXh0ID0gaGVhZDsKLy8gU3RlcCAzOiBVcGRhdGUgdGhlIGhlYWQgdG8gdGhlIG5ldyBub2RlCmhlYWQgPSBuZXdOb2RlOwp9Cgp2b2lkIHByaW50TGlzdChOb2RlKiBoZWFkKSB7CndoaWxlIChoZWFkICE9IG51bGxwdHIpIHsKY291dCA8PCBoZWFkLT5kYXRhIDw8ICIgLT4gIjsKaGVhZCA9IGhlYWQtPm5leHQ7fQpjb3V0IDw8ICJOVUxMIiA8PCBlbmRsOwp9CgppbnQgbWFpbigpIHsKTm9kZSogaGVhZCA9IG51bGxwdHI7IC8vIEluaXRpYWxseSwgdGhlIGxpc3QgaXMgZW1wdHkKCmluc2VydEF0QmVnaW5uaW5nKGhlYWQsIDMwKTsKaW5zZXJ0QXRCZWdpbm5pbmcoaGVhZCwgMjApOwppbnNlcnRBdEJlZ2lubmluZyhoZWFkLCAxMCk7CgpwcmludExpc3QoaGVhZCk7IC8vIE91dHB1dDogMTAgLT4gMjAgLT4gMzAgLT4gTlVMTApyZXR1cm4gMDsKfQ==
Output:
10 -> 20 -> 30 -> NULL
Code Explanation:
Just like in the previous example, we begin by importing the iostream header file for input/output operations. We then define a Node class with two data members and a constructor.
- Helper Functions: We define two functions: insertAtBeginning(, which adds a new node at the start of the list, and printList() to traverse the list and print the content.
- Here, the printList() function uses a while loop to check if the pointer is not null, in which case it prints the content.
- Dynamic Node Creation: Inside insertAtBeginning(), a new node is dynamically created using the Node constructor and initialized with newData.
- Pointer Update: Then, the next pointer of the newly created node is assigned the current head node, effectively linking it to the existing list.
- Head Update: After that, the head pointer is updated to point to the new node, making it the first node in the list.
- As a result, the new node becomes the head of the list, and the previous nodes are shifted down in sequence.
Insertion At End Of Singly Linked List
Inserting a node at the end of a singly linked list involves adding a new node as the last element. The next pointer of the current last node is updated to point to the new node, and the new node's next pointer is set to nullptr. Here is how this works:
- Create a new node and assign the data.
- If the list is empty (head is nullptr), set the head pointer to the new node.
- Otherwise, traverse the list to find the last node (whose next is nullptr).
- Update the next pointer of the last node to point to the new node.
- Set the next pointer of the new node to nullptr.
Code Example:
#include
using namespace std;
class Node {
public:
int data;
Node* next;
Node(int value) {
data = value;
next = nullptr;
}
};
void insertAtEnd(Node*& head, int newData) {
// Step 1: Create a new node
Node* newNode = new Node(newData);
// Step 2: Check if the list is empty
if (head == nullptr) {
head = newNode; // Make the new node the head
return;
}
// Step 3: Traverse to the last node
Node* temp = head;
while (temp->next != nullptr) {
temp = temp->next;
}
// Step 4: Update the last node's next pointer
temp->next = newNode;
}
void printList(Node* head) {
while (head != nullptr) {
cout << head->data << " -> ";
head = head->next;}
cout << "NULL" << endl;
}
int main() {
Node* head = nullptr; // Initially, the list is empty
insertAtEnd(head, 10);
insertAtEnd(head, 20);
insertAtEnd(head, 30);
printList(head); // Output: 10 -> 20 -> 30 -> NULL
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgp1c2luZyBuYW1lc3BhY2Ugc3RkOwoKY2xhc3MgTm9kZSB7CnB1YmxpYzoKaW50IGRhdGE7Ck5vZGUqIG5leHQ7Ck5vZGUoaW50IHZhbHVlKSB7CmRhdGEgPSB2YWx1ZTsKbmV4dCA9IG51bGxwdHI7Cn0KfTsKCnZvaWQgaW5zZXJ0QXRFbmQoTm9kZSomIGhlYWQsIGludCBuZXdEYXRhKSB7Ci8vIFN0ZXAgMTogQ3JlYXRlIGEgbmV3IG5vZGUKTm9kZSogbmV3Tm9kZSA9IG5ldyBOb2RlKG5ld0RhdGEpOwovLyBTdGVwIDI6IENoZWNrIGlmIHRoZSBsaXN0IGlzIGVtcHR5CmlmIChoZWFkID09IG51bGxwdHIpIHsKaGVhZCA9IG5ld05vZGU7IC8vIE1ha2UgdGhlIG5ldyBub2RlIHRoZSBoZWFkCnJldHVybjsKfQovLyBTdGVwIDM6IFRyYXZlcnNlIHRvIHRoZSBsYXN0IG5vZGUKTm9kZSogdGVtcCA9IGhlYWQ7CndoaWxlICh0ZW1wLT5uZXh0ICE9IG51bGxwdHIpIHsKdGVtcCA9IHRlbXAtPm5leHQ7Cn0KLy8gU3RlcCA0OiBVcGRhdGUgdGhlIGxhc3Qgbm9kZSdzIG5leHQgcG9pbnRlcgp0ZW1wLT5uZXh0ID0gbmV3Tm9kZTsKfQoKdm9pZCBwcmludExpc3QoTm9kZSogaGVhZCkgewp3aGlsZSAoaGVhZCAhPSBudWxscHRyKSB7CmNvdXQgPDwgaGVhZC0+ZGF0YSA8PCAiIC0+ICI7CmhlYWQgPSBoZWFkLT5uZXh0O30KY291dCA8PCAiTlVMTCIgPDwgZW5kbDsKfQoKaW50IG1haW4oKSB7Ck5vZGUqIGhlYWQgPSBudWxscHRyOyAvLyBJbml0aWFsbHksIHRoZSBsaXN0IGlzIGVtcHR5CgppbnNlcnRBdEVuZChoZWFkLCAxMCk7Cmluc2VydEF0RW5kKGhlYWQsIDIwKTsKaW5zZXJ0QXRFbmQoaGVhZCwgMzApOwoKcHJpbnRMaXN0KGhlYWQpOyAvLyBPdXRwdXQ6IDEwIC0+IDIwIC0+IDMwIC0+IE5VTEwKcmV0dXJuIDA7Cn0=
Output:
10 -> 20 -> 30 -> NULL
Code Explanation:
Similar to the previous example, we have a Node class with two data members, a constructor and a printList() function to traverse and print the list contents.
- Function to Add Node: We also define an insertAtEnd() function to insert a new node at the end of the list.
- Node Creation: Inside insertAtEnd(), a new node is dynamically created using the Node constructor and initialized with newData.
- Empty List Check: Then, we use an if-statement to check if the list is empty (i.e.,the head is nullptr). If it is true (the list is empty), the head pointer is set to the new node.
- Traverse to Last Node: If the list is not empty, a temporary pointer (temp) traverses the list until it reaches the last node (where temp->next == nullptr).
- Linking New Node: We then update the next pointer of the last node to point to the new node, linking it to the end of the list.
- Pointer Update: The next pointer of the new node is set to nullptr, indicating that it is the last node.
Insertion At A Specific Position In Singly Linked List
Inserting a node at a specific position in a singly linked list involves placing the new node at a user-defined position. The list can be traversed until the desired position is reached, and then the new node is inserted between two existing nodes. This operation requires updating the next pointer of the node just before the insertion point. Here is how it works:
- Create a new node and assign the data.
- If the position is 0, insert the node at the beginning (this is handled in a similar way to the insertion at the beginning operation).
- Otherwise, traverse the list to find the node just before the desired position.
- Update the next pointer of the node at the previous position to point to the new node.
- Set the next pointer of the new node to point to the next node in the list.
Code Example:
#include
using namespace std;
class Node {
public:
int data;
Node* next;
Node(int value) {
data = value;
next = nullptr;
}
};
void insertAtPosition(Node*& head, int newData, int position) {
Node* newNode = new Node(newData);
// Insert at the beginning (position 0)
if (position == 0) {
newNode->next = head;
head = newNode;
return;
}
Node* temp = head;
int currentPos = 0;
// Traverse to the node just before the specified position
while (temp != nullptr && currentPos < position - 1) {
temp = temp->next;
currentPos++;
}
// If the position is valid, insert the node
if (temp != nullptr) {
newNode->next = temp->next;
temp->next = newNode;
} else {
cout << "Position is out of bounds!" << endl;
}
}
void printList(Node* head) {
while (head != nullptr) {
cout << head->data << " -> ";
head = head->next;
}
cout << "NULL" << endl;
}
int main() {
Node* head = new Node(10); // Starting with a linked list containing a single node
head->next = new Node(20); // Adding another node
cout << "Initial list: ";
printList(head); // Output: 10 -> 20 -> NULL
insertAtPosition(head, 15, 1); // Insert 15 at position 1
cout << "List after insertion: ";
printList(head); // Output: 10 -> 15 -> 20 -> NULL
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgp1c2luZyBuYW1lc3BhY2Ugc3RkOwoKY2xhc3MgTm9kZSB7CnB1YmxpYzoKaW50IGRhdGE7Ck5vZGUqIG5leHQ7Ck5vZGUoaW50IHZhbHVlKSB7CmRhdGEgPSB2YWx1ZTsKbmV4dCA9IG51bGxwdHI7Cn0KfTsKCnZvaWQgaW5zZXJ0QXRQb3NpdGlvbihOb2RlKiYgaGVhZCwgaW50IG5ld0RhdGEsIGludCBwb3NpdGlvbikgewpOb2RlKiBuZXdOb2RlID0gbmV3IE5vZGUobmV3RGF0YSk7Ci8vIEluc2VydCBhdCB0aGUgYmVnaW5uaW5nIChwb3NpdGlvbiAwKQppZiAocG9zaXRpb24gPT0gMCkgewpuZXdOb2RlLT5uZXh0ID0gaGVhZDsKaGVhZCA9IG5ld05vZGU7CnJldHVybjsKfQoKTm9kZSogdGVtcCA9IGhlYWQ7CmludCBjdXJyZW50UG9zID0gMDsKLy8gVHJhdmVyc2UgdG8gdGhlIG5vZGUganVzdCBiZWZvcmUgdGhlIHNwZWNpZmllZCBwb3NpdGlvbgp3aGlsZSAodGVtcCAhPSBudWxscHRyICYmIGN1cnJlbnRQb3MgPCBwb3NpdGlvbiAtIDEpIHsKdGVtcCA9IHRlbXAtPm5leHQ7CmN1cnJlbnRQb3MrKzsKfQoKLy8gSWYgdGhlIHBvc2l0aW9uIGlzIHZhbGlkLCBpbnNlcnQgdGhlIG5vZGUKaWYgKHRlbXAgIT0gbnVsbHB0cikgewpuZXdOb2RlLT5uZXh0ID0gdGVtcC0+bmV4dDsKdGVtcC0+bmV4dCA9IG5ld05vZGU7Cn0gZWxzZSB7CmNvdXQgPDwgIlBvc2l0aW9uIGlzIG91dCBvZiBib3VuZHMhIiA8PCBlbmRsOwp9Cn0KCnZvaWQgcHJpbnRMaXN0KE5vZGUqIGhlYWQpIHsKd2hpbGUgKGhlYWQgIT0gbnVsbHB0cikgewpjb3V0IDw8IGhlYWQtPmRhdGEgPDwgIiAtPiAiOwpoZWFkID0gaGVhZC0+bmV4dDsKfQpjb3V0IDw8ICJOVUxMIiA8PCBlbmRsOwp9CgppbnQgbWFpbigpIHsKTm9kZSogaGVhZCA9IG5ldyBOb2RlKDEwKTsgLy8gU3RhcnRpbmcgd2l0aCBhIGxpbmtlZCBsaXN0IGNvbnRhaW5pbmcgYSBzaW5nbGUgbm9kZQpoZWFkLT5uZXh0ID0gbmV3IE5vZGUoMjApOyAvLyBBZGRpbmcgYW5vdGhlciBub2RlCgpjb3V0IDw8ICJJbml0aWFsIGxpc3Q6ICI7CnByaW50TGlzdChoZWFkKTsgLy8gT3V0cHV0OiAxMCAtPiAyMCAtPiBOVUxMCgppbnNlcnRBdFBvc2l0aW9uKGhlYWQsIDE1LCAxKTsgLy8gSW5zZXJ0IDE1IGF0IHBvc2l0aW9uIDEKY291dCA8PCAiTGlzdCBhZnRlciBpbnNlcnRpb246ICI7CnByaW50TGlzdChoZWFkKTsgLy8gT3V0cHV0OiAxMCAtPiAxNSAtPiAyMCAtPiBOVUxMCgpyZXR1cm4gMDsKfQ==
Output:
10 -> 15 -> 20 -> NULL
Code Explanation:
We begin with defining the Node class and then two functions: printList() to traverse and display the list, and insertAtPosition() to add a node at a specific position.
- Insertion at Position 0: Inside the insertAtPosition() function, we first check if the specified position is 0. If it is, we treat that as insertion at the beginning of the list.
- Insertion at Other Positions: If the specified position is greater than 0, we traverse the list to find the node just before the specified position.
- We start from the head and use a while loop to move through the list until we reach the node at the position position - 1.
- This is done by incrementing the currentPos and updating temp to point to the next node in each iteration.
- Inserting the New Node: Once we find the node just before the desired position, we:
- Set newNode->next to temp->next, which points to the node that will come after the new node.
- Update temp->next to point to the new node, effectively inserting it into the list at the specified position.
- Out of Bounds Check: If we reach the end of the list (i.e., temp is nullptr before reaching the desired position), it indicates that the position is out of bounds. In this case, a message is printed: "Position is out of bounds!".
- In the main() function, we create a new node using the constructor of the Node class, which initializes the new node with the data newData. The next pointer of this new node is set to nullptr by default.
- Initial List: We start with a linked list containing two nodes: 10 -> 20 -> NULL.
- Insert at Position 1: The insertAtPosition() function inserts the new node with value 15 between 10 and 20. It achieves this by traversing the list until it reaches the node just before position 1, and then adjusting the next pointers accordingly.
This example shows how to start with an existing linked list and insert a new node at a specific position. It gives a clearer picture of how insertion works in a more realistic scenario.
Boost your learning curve with one-on-one mentorship from industry professionals.
Deletion Operation On Singly Linked List
In a singly linked list, deletion operations involve removing a node from a specific location—either the beginning, end or a specified position within the list. Deleting a node requires careful handling of pointers to ensure the integrity of the list.
Deletion From Beginning Of Singly Linked List
To delete the first node (head node), we update the head pointer to point to the second node in the list, effectively removing the first node from the list.
Code Example:
#include
using namespace std;
class Node {
public:
int data;
Node* next;
Node(int value) {
data = value;
next = nullptr;
}
};
void deleteFromBeginning(Node*& head) {
if (head == nullptr) {
cout << "List is empty!" << endl;
return;
}
Node* temp = head; // Store the current head
head = head->next; // Update head to point to the next node
delete temp; // Delete the old head node
}
void printList(Node* head) {
while (head != nullptr) {
cout << head->data << " -> ";
head = head->next;
}
cout << "NULL" << endl;
}
int main() {
Node* head = new Node(10);
head->next = new Node(20);
head->next->next = new Node(30);
cout << "Initial list: ";
printList(head); // Output: 10 -> 20 -> 30 -> NULL
deleteFromBeginning(head); // Deleting the first node (10)
cout << "List after deletion: ";
printList(head); // Output: 20 -> 30 -> NULL
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgp1c2luZyBuYW1lc3BhY2Ugc3RkOwoKY2xhc3MgTm9kZSB7CnB1YmxpYzoKaW50IGRhdGE7Ck5vZGUqIG5leHQ7Ck5vZGUoaW50IHZhbHVlKSB7CmRhdGEgPSB2YWx1ZTsKbmV4dCA9IG51bGxwdHI7Cn0KfTsKCnZvaWQgZGVsZXRlRnJvbUJlZ2lubmluZyhOb2RlKiYgaGVhZCkgewppZiAoaGVhZCA9PSBudWxscHRyKSB7CmNvdXQgPDwgIkxpc3QgaXMgZW1wdHkhIiA8PCBlbmRsOwpyZXR1cm47Cn0KTm9kZSogdGVtcCA9IGhlYWQ7wqAgLy8gU3RvcmUgdGhlIGN1cnJlbnQgaGVhZApoZWFkID0gaGVhZC0+bmV4dDvCoCAvLyBVcGRhdGUgaGVhZCB0byBwb2ludCB0byB0aGUgbmV4dCBub2RlCmRlbGV0ZSB0ZW1wO8KgIMKgIMKgIMKgIC8vIERlbGV0ZSB0aGUgb2xkIGhlYWQgbm9kZQp9Cgp2b2lkIHByaW50TGlzdChOb2RlKiBoZWFkKSB7CndoaWxlIChoZWFkICE9IG51bGxwdHIpIHsKY291dCA8PCBoZWFkLT5kYXRhIDw8ICIgLT4gIjsKaGVhZCA9IGhlYWQtPm5leHQ7Cn0KY291dCA8PCAiTlVMTCIgPDwgZW5kbDsKfQoKaW50IG1haW4oKSB7Ck5vZGUqIGhlYWQgPSBuZXcgTm9kZSgxMCk7CmhlYWQtPm5leHQgPSBuZXcgTm9kZSgyMCk7CmhlYWQtPm5leHQtPm5leHQgPSBuZXcgTm9kZSgzMCk7Cgpjb3V0IDw8ICJJbml0aWFsIGxpc3Q6ICI7CnByaW50TGlzdChoZWFkKTsgLy8gT3V0cHV0OiAxMCAtPiAyMCAtPiAzMCAtPiBOVUxMCgpkZWxldGVGcm9tQmVnaW5uaW5nKGhlYWQpOyAvLyBEZWxldGluZyB0aGUgZmlyc3Qgbm9kZSAoMTApCmNvdXQgPDwgIkxpc3QgYWZ0ZXIgZGVsZXRpb246ICI7CnByaW50TGlzdChoZWFkKTsgLy8gT3V0cHV0OiAyMCAtPiAzMCAtPiBOVUxMCgpyZXR1cm4gMDsKfQ==
Output:
Initial list: 10 -> 20 -> 30 -> NULL
List after deletion: 20 -> 30 -> NULL
Code Explanation:
- Delete from the Beginning:
- We check if the list is empty (i.e., head == nullptr). If so, we print an error message and exit the function.
- If the list is not empty, we store the current head node in the temp pointer.
- We update the head pointer to point to the next node in the list (head = head->next), effectively removing the first node.
- Finally, we delete the original head node using delete temp.
This operation is O(1) in terms of time complexity, as it only involves updating the head pointer and deleting the first node.
Deletion From End Of Singly Linked List
Deleting the last node requires traversing the list to find the second-last node, updating its next pointer to nullptr, and then deleting the last node.
Code Example:
#include
using namespace std
class Node {
public:
int data;
Node* next;
Node(int value) {
data = value;
next = nullptr;}
};
void deleteFromEnd(Node*& head) {
if (head == nullptr) {
cout << "List is empty!" << endl;
return;
}
// If there's only one node
if (head->next == nullptr) {
delete head;
head = nullptr;
return;
}
Node* temp = head;
// Traverse to the second-last node
while (temp->next != nullptr && temp->next->next != nullptr) {
temp = temp->next;
}
// Delete the last node
Node* lastNode = temp->next;
temp->next = nullptr;
delete lastNode;
}
void printList(Node* head) {
while (head != nullptr) {
cout << head->data << " -> ";
head = head->next;
}
cout << "NULL" << endl;
}
int main() {
Node* head = new Node(10);
head->next = new Node(20);
head->next->next = new Node(30);
cout << "Initial list: ";
printList(head); // Output: 10 -> 20 -> 30 -> NULL
deleteFromEnd(head); // Deleting the last node (30)
cout << "List after deletion: ";
printList(head); // Output: 10 -> 20 -> NULL
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgp1c2luZyBuYW1lc3BhY2Ugc3RkCgpjbGFzcyBOb2RlIHsKcHVibGljOgppbnQgZGF0YTsKTm9kZSogbmV4dDsKTm9kZShpbnQgdmFsdWUpIHsKZGF0YSA9IHZhbHVlOwpuZXh0ID0gbnVsbHB0cjt9Cn07Cgp2b2lkIGRlbGV0ZUZyb21FbmQoTm9kZSomIGhlYWQpIHsKaWYgKGhlYWQgPT0gbnVsbHB0cikgewpjb3V0IDw8ICJMaXN0IGlzIGVtcHR5ISIgPDwgZW5kbDsKcmV0dXJuOwp9CgovLyBJZiB0aGVyZSdzIG9ubHkgb25lIG5vZGUKaWYgKGhlYWQtPm5leHQgPT0gbnVsbHB0cikgewpkZWxldGUgaGVhZDsKaGVhZCA9IG51bGxwdHI7CnJldHVybjsKfQoKTm9kZSogdGVtcCA9IGhlYWQ7Ci8vIFRyYXZlcnNlIHRvIHRoZSBzZWNvbmQtbGFzdCBub2RlCndoaWxlICh0ZW1wLT5uZXh0ICE9IG51bGxwdHIgJiYgdGVtcC0+bmV4dC0+bmV4dCAhPSBudWxscHRyKSB7CnRlbXAgPSB0ZW1wLT5uZXh0Owp9CgovLyBEZWxldGUgdGhlIGxhc3Qgbm9kZQpOb2RlKiBsYXN0Tm9kZSA9IHRlbXAtPm5leHQ7CnRlbXAtPm5leHQgPSBudWxscHRyOwpkZWxldGUgbGFzdE5vZGU7Cn0KCnZvaWQgcHJpbnRMaXN0KE5vZGUqIGhlYWQpIHsKd2hpbGUgKGhlYWQgIT0gbnVsbHB0cikgewpjb3V0IDw8IGhlYWQtPmRhdGEgPDwgIiAtPiAiOwpoZWFkID0gaGVhZC0+bmV4dDsKfQpjb3V0IDw8ICJOVUxMIiA8PCBlbmRsOwp9CgppbnQgbWFpbigpIHsKTm9kZSogaGVhZCA9IG5ldyBOb2RlKDEwKTsKaGVhZC0+bmV4dCA9IG5ldyBOb2RlKDIwKTsKaGVhZC0+bmV4dC0+bmV4dCA9IG5ldyBOb2RlKDMwKTsKCmNvdXQgPDwgIkluaXRpYWwgbGlzdDogIjsKcHJpbnRMaXN0KGhlYWQpOyAvLyBPdXRwdXQ6IDEwIC0+IDIwIC0+IDMwIC0+IE5VTEwKCmRlbGV0ZUZyb21FbmQoaGVhZCk7IC8vIERlbGV0aW5nIHRoZSBsYXN0IG5vZGUgKDMwKQpjb3V0IDw8ICJMaXN0IGFmdGVyIGRlbGV0aW9uOiAiOwpwcmludExpc3QoaGVhZCk7IC8vIE91dHB1dDogMTAgLT4gMjAgLT4gTlVMTAoKcmV0dXJuIDA7Cn0=
Output:
Initial list: 10 -> 20 -> 30 -> NULL
List after deletion: 10 -> 20 -> NULL
Code Explanation:
We define the Node class and the printList() function just like before. Then, we define the deleteFromEnd() function:
- Delete from the End Function: The deleteFromEnd() function first checks if the list is empty or contains only one node.
- If the list contains only one node, it deletes the head node and sets the head to nullptr.
If the list contains more than one node: - We traverse the list to find the second-last node (temp->next->next == nullptr).
- Once the second-last node is found, we update its next pointer to nullptr, effectively removing the last node.
- Finally, we delete the last node.
- In the main() function, we create a list with three linked nodes and print it to the console.
- Then, we call the deleteFromEnd() function, passing the head as an argument. The function deletes the last node, and we print the new list to the console for comparison.
Deletion From Specific Position Of Singly Linked List
To delete a node from a specific position, we traverse the list to find the node just before the target node, update its next pointer to skip the target node, and then delete the target node.
Code Example:
#include
using namespace std
class Node {
public:
int data;
Node* next;
Node(int value) {
data = value;
next = nullptr;}
};
void deleteAtPosition(Node*& head, int position) {
if (head == nullptr) {
cout << "List is empty!" << endl;
return;
}
// Special case: Delete the first node (position 0)
if (position == 0) {
Node* temp = head;
head = head->next;
delete temp;
return;
}
Node* temp = head;
int currentPos = 0;
// Traverse to the node just before the specified position
while (temp != nullptr && currentPos < position - 1) {
temp = temp->next;
currentPos++;
}
// If the position is valid, delete the node
if (temp != nullptr && temp->next != nullptr) {
Node* nodeToDelete = temp->next;
temp->next = temp->next->next;
delete nodeToDelete;
} else {
cout << "Position is out of bounds!" << endl;
}
}
void printList(Node* head) {
while (head != nullptr) {
cout << head->data << " -> ";
head = head->next;
}
cout << "NULL" << endl;
}
int main() {
Node* head = new Node(10);
head->next = new Node(20);
head->next->next = new Node(30);
head->next->next->next = new Node(40);
cout << "Initial list: ";
printList(head); // Output: 10 -> 20 -> 30 -> 40 -> NULL
deleteAtPosition(head, 2); // Deleting the node at position 2 (30)
cout << "List after deletion: ";
printList(head); // Output: 10 -> 20 -> 40 -> NULL
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgp1c2luZyBuYW1lc3BhY2Ugc3RkCgpjbGFzcyBOb2RlIHsKcHVibGljOgppbnQgZGF0YTsKTm9kZSogbmV4dDsKTm9kZShpbnQgdmFsdWUpIHsKZGF0YSA9IHZhbHVlOwpuZXh0ID0gbnVsbHB0cjt9Cn07Cgp2b2lkIGRlbGV0ZUF0UG9zaXRpb24oTm9kZSomIGhlYWQsIGludCBwb3NpdGlvbikgewppZiAoaGVhZCA9PSBudWxscHRyKSB7CmNvdXQgPDwgIkxpc3QgaXMgZW1wdHkhIiA8PCBlbmRsOwpyZXR1cm47Cn0KCi8vIFNwZWNpYWwgY2FzZTogRGVsZXRlIHRoZSBmaXJzdCBub2RlIChwb3NpdGlvbiAwKQppZiAocG9zaXRpb24gPT0gMCkgewpOb2RlKiB0ZW1wID0gaGVhZDsKaGVhZCA9IGhlYWQtPm5leHQ7CmRlbGV0ZSB0ZW1wOwpyZXR1cm47Cn0KCk5vZGUqIHRlbXAgPSBoZWFkOwppbnQgY3VycmVudFBvcyA9IDA7Ci8vIFRyYXZlcnNlIHRvIHRoZSBub2RlIGp1c3QgYmVmb3JlIHRoZSBzcGVjaWZpZWQgcG9zaXRpb24Kd2hpbGUgKHRlbXAgIT0gbnVsbHB0ciAmJiBjdXJyZW50UG9zIDwgcG9zaXRpb24gLSAxKSB7CnRlbXAgPSB0ZW1wLT5uZXh0OwpjdXJyZW50UG9zKys7Cn0KCi8vIElmIHRoZSBwb3NpdGlvbiBpcyB2YWxpZCwgZGVsZXRlIHRoZSBub2RlCmlmICh0ZW1wICE9IG51bGxwdHIgJiYgdGVtcC0+bmV4dCAhPSBudWxscHRyKSB7Ck5vZGUqIG5vZGVUb0RlbGV0ZSA9IHRlbXAtPm5leHQ7CnRlbXAtPm5leHQgPSB0ZW1wLT5uZXh0LT5uZXh0OwpkZWxldGUgbm9kZVRvRGVsZXRlOwp9IGVsc2Ugewpjb3V0IDw8ICJQb3NpdGlvbiBpcyBvdXQgb2YgYm91bmRzISIgPDwgZW5kbDsKfQp9Cgp2b2lkIHByaW50TGlzdChOb2RlKiBoZWFkKSB7CndoaWxlIChoZWFkICE9IG51bGxwdHIpIHsKY291dCA8PCBoZWFkLT5kYXRhIDw8ICIgLT4gIjsKaGVhZCA9IGhlYWQtPm5leHQ7Cn0KY291dCA8PCAiTlVMTCIgPDwgZW5kbDsKfQoKaW50IG1haW4oKSB7Ck5vZGUqIGhlYWQgPSBuZXcgTm9kZSgxMCk7CmhlYWQtPm5leHQgPSBuZXcgTm9kZSgyMCk7CmhlYWQtPm5leHQtPm5leHQgPSBuZXcgTm9kZSgzMCk7CmhlYWQtPm5leHQtPm5leHQtPm5leHQgPSBuZXcgTm9kZSg0MCk7Cgpjb3V0IDw8ICJJbml0aWFsIGxpc3Q6ICI7CnByaW50TGlzdChoZWFkKTsgLy8gT3V0cHV0OiAxMCAtPiAyMCAtPiAzMCAtPiA0MCAtPiBOVUxMCgpkZWxldGVBdFBvc2l0aW9uKGhlYWQsIDIpOyAvLyBEZWxldGluZyB0aGUgbm9kZSBhdCBwb3NpdGlvbiAyICgzMCkKY291dCA8PCAiTGlzdCBhZnRlciBkZWxldGlvbjogIjsKcHJpbnRMaXN0KGhlYWQpOyAvLyBPdXRwdXQ6IDEwIC0+IDIwIC0+IDQwIC0+IE5VTEwKCnJldHVybiAwOwp9
Output:
Initial list: 10 -> 20 -> 30 -> 40 -> NULL
List after deletion: 10 -> 20 -> 40 -> NULL
Code Explanation:
We have a Node class to create nodes, and a printList() function to traverse an print the contents of a linked list.
- Delete from a Specific Position: We also define a function to delete the node from a specific position.
- The deleteAtPosition() function first checks if the list is empty. If the position is 0, it deletes the head node in the same way as the deletion at the beginning.
- If the position is greater than 0:
- We traverse the list to find the node just before the specified position.
- Once the node before the target is found, we update its next pointer to skip the node at the target position.
- We then delete the node at the target position.
- If the position is invalid (greater than the number of nodes), an out-of-bounds message is printed.
- In the main() function, we create a linked list with four nodes and then print the same.
- Next, we call the deleteAtPosition() function with arguments head and 2, i.e., to delete the node at position 2.
- The function deletes the respective node and shifts the previous one ahead. We display the new list for comparison.
Want to become an expert? Dive into this curated course on DSA and advance your career.
Searching For Elements In Single Linked List
Searching in a singly linked list involves looking for a specific node that contains a given value. The search operation typically starts from the head node and traverses the list node by node until it finds the target value or reaches the end of the list.
How It Works:
- Start from the Head: We begin at the head node and check if it contains the desired value.
- Traverse the List: If the current node does not contain the desired value, we move to the next node and repeat the process until we either find the value or reach the end of the list (when the next pointer is nullptr).
- Return Result: If the value is found, we return the node or a true indication. If the end of the list is reached and the value isn't found, we return false or an appropriate message.
Code Example:
#include
using namespace std
class Node {
public:
int data;
Node* next;
Node(int value) {
data = value;
next = nullptr;}
};
bool search(Node* head, int target) {
Node* temp = head;
while (temp != nullptr) {
if (temp->data == target) {
return true; // Element found
}
temp = temp->next;
}
return false; // Element not found
}
void printList(Node* head) {
while (head != nullptr) {
cout << head->data << " -> ";
head = head->next;
}
cout << "NULL" << endl;
}
int main() {
Node* head = new Node(10);
head->next = new Node(20);
head->next->next = new Node(30);
cout << "List: ";
printList(head); // Output: 10 -> 20 -> 30 -> NULL
int target = 20;
if (search(head, target)) {
cout << target << " found in the list!" << endl; // Output: 20 found in the list!
} else {
cout << target << " not found in the list." << endl;
}
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgp1c2luZyBuYW1lc3BhY2Ugc3RkCgpjbGFzcyBOb2RlIHsKcHVibGljOgppbnQgZGF0YTsKTm9kZSogbmV4dDsKTm9kZShpbnQgdmFsdWUpIHsKZGF0YSA9IHZhbHVlOwpuZXh0ID0gbnVsbHB0cjt9Cn07Cgpib29sIHNlYXJjaChOb2RlKiBoZWFkLCBpbnQgdGFyZ2V0KSB7Ck5vZGUqIHRlbXAgPSBoZWFkOwoKd2hpbGUgKHRlbXAgIT0gbnVsbHB0cikgewppZiAodGVtcC0+ZGF0YSA9PSB0YXJnZXQpIHsKcmV0dXJuIHRydWU7IC8vIEVsZW1lbnQgZm91bmQKfQp0ZW1wID0gdGVtcC0+bmV4dDsKfQpyZXR1cm4gZmFsc2U7IC8vIEVsZW1lbnQgbm90IGZvdW5kCn0KCnZvaWQgcHJpbnRMaXN0KE5vZGUqIGhlYWQpIHsKd2hpbGUgKGhlYWQgIT0gbnVsbHB0cikgewpjb3V0IDw8IGhlYWQtPmRhdGEgPDwgIiAtPiAiOwpoZWFkID0gaGVhZC0+bmV4dDsKfQpjb3V0IDw8ICJOVUxMIiA8PCBlbmRsOwp9CgppbnQgbWFpbigpIHsKTm9kZSogaGVhZCA9IG5ldyBOb2RlKDEwKTsKaGVhZC0+bmV4dCA9IG5ldyBOb2RlKDIwKTsKaGVhZC0+bmV4dC0+bmV4dCA9IG5ldyBOb2RlKDMwKTsKCmNvdXQgPDwgIkxpc3Q6ICI7CnByaW50TGlzdChoZWFkKTsgLy8gT3V0cHV0OiAxMCAtPiAyMCAtPiAzMCAtPiBOVUxMCgppbnQgdGFyZ2V0ID0gMjA7CmlmIChzZWFyY2goaGVhZCwgdGFyZ2V0KSkgewpjb3V0IDw8IHRhcmdldCA8PCAiIGZvdW5kIGluIHRoZSBsaXN0ISIgPDwgZW5kbDsgLy8gT3V0cHV0OiAyMCBmb3VuZCBpbiB0aGUgbGlzdCEKfSBlbHNlIHsKY291dCA8PCB0YXJnZXQgPDwgIiBub3QgZm91bmQgaW4gdGhlIGxpc3QuIiA8PCBlbmRsOwp9CgpyZXR1cm4gMDsKfQ==
Output:
List: 10 -> 20 -> 30 -> NULL
20 found in the list!
Code Explanation:
Just like before, we define a class Node for node creation and a printList() function to traverse and print the linked list.
- Search Function: We also define a search() function that takes the head of the list and the target value as arguments. It iterates over each node in the list.
- If the value of the current node (temp->data) matches the target, the function returns true, indicating the element is found.
- If the loop reaches the end of the list (temp == nullptr) without finding the target, it returns false.
- In the main() function, we create a linked list with values 10, 20, and 30, and then search for the element 20.
- The program will output that the value is found.
This search operation has a time complexity of O(n), where n is the number of nodes in the list.
Calculating Length Of Single Linked List
The length of a singly linked list refers to the number of nodes it contains. To calculate the length, we need to traverse the entire list and count how many nodes exist before we reach the end (when the next pointer is nullptr).
How It Works:
- Initialize Counter: We start by initializing a counter to 0.
- Traverse the List: We traverse the list starting from the head node. For each node we visit, we increment the counter.
- Return the Counter: Once the traversal is complete (i.e., we reach the end of the list), the counter will hold the total number of nodes in the list, which is the length.
Code Example:
#include
using namespace std
class Node {
public:
int data;
Node* next;
Node(int value) {
data = value;
next = nullptr;}
};
int calculateLength(Node* head) {
int length = 0;
Node* temp = head;
while (temp != nullptr) {
length++; // Increment length for each node
temp = temp->next; // Move to the next node
}
return length; // Return the total length
}
void printList(Node* head) {
while (head != nullptr) {
cout << head->data << " -> ";
head = head->next;
}
cout << "NULL" << endl;
}
int main() {
Node* head = new Node(10);
head->next = new Node(20);
head->next->next = new Node(30);
cout << "List: ";
printList(head); // Output: 10 -> 20 -> 30 -> NULL
int length = calculateLength(head);
cout << "Length of the list: " << length << endl; // Output: 3
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgp1c2luZyBuYW1lc3BhY2Ugc3RkCgpjbGFzcyBOb2RlIHsKcHVibGljOgppbnQgZGF0YTsKTm9kZSogbmV4dDsKTm9kZShpbnQgdmFsdWUpIHsKZGF0YSA9IHZhbHVlOwpuZXh0ID0gbnVsbHB0cjt9Cn07CgppbnQgY2FsY3VsYXRlTGVuZ3RoKE5vZGUqIGhlYWQpIHsKaW50IGxlbmd0aCA9IDA7Ck5vZGUqIHRlbXAgPSBoZWFkOwoKd2hpbGUgKHRlbXAgIT0gbnVsbHB0cikgewpsZW5ndGgrKzvCoCAvLyBJbmNyZW1lbnQgbGVuZ3RoIGZvciBlYWNoIG5vZGUKdGVtcCA9IHRlbXAtPm5leHQ7wqAgLy8gTW92ZSB0byB0aGUgbmV4dCBub2RlCn0KcmV0dXJuIGxlbmd0aDvCoCAvLyBSZXR1cm4gdGhlIHRvdGFsIGxlbmd0aAp9Cgp2b2lkIHByaW50TGlzdChOb2RlKiBoZWFkKSB7CndoaWxlIChoZWFkICE9IG51bGxwdHIpIHsKY291dCA8PCBoZWFkLT5kYXRhIDw8ICIgLT4gIjsKaGVhZCA9IGhlYWQtPm5leHQ7Cn0KY291dCA8PCAiTlVMTCIgPDwgZW5kbDsKfQoKaW50IG1haW4oKSB7Ck5vZGUqIGhlYWQgPSBuZXcgTm9kZSgxMCk7CmhlYWQtPm5leHQgPSBuZXcgTm9kZSgyMCk7CmhlYWQtPm5leHQtPm5leHQgPSBuZXcgTm9kZSgzMCk7Cgpjb3V0IDw8ICJMaXN0OiAiOwpwcmludExpc3QoaGVhZCk7wqAgLy8gT3V0cHV0OiAxMCAtPiAyMCAtPiAzMCAtPiBOVUxMCgppbnQgbGVuZ3RoID0gY2FsY3VsYXRlTGVuZ3RoKGhlYWQpOwpjb3V0IDw8ICJMZW5ndGggb2YgdGhlIGxpc3Q6ICIgPDwgbGVuZ3RoIDw8IGVuZGw7wqAgLy8gT3V0cHV0OiAzCgpyZXR1cm4gMDsKfQ==
Output:
List: 10 -> 20 -> 30 -> NULL
Length of the list: 3
Code Explanation:
We have the Node class for node creation and printList() to display the linked list.
- Calculate Length Function: Then, we define the calculateLength() function, which initializes a length variable to 0 and starts at the head node.
- It traverses the list node by node, incrementing the length for each node it encounters.
- Once the end of the list is reached (i.e., temp == nullptr), it returns the length of the list.
- In the main() function, we create a linked list with three nodes, and then calculate the length using the calculateLength() function.
- The result is 3, since there are three nodes in the list.
This operation has a time complexity of O(n), where n is the number of nodes in the list.
Practical Applications Of Singly Linked Lists In Data Structure
Singly Linked Lists (SLLs) are one of the most fundamental data structures in computer science and have numerous practical applications. They are particularly useful in situations where dynamic memory allocation is required, and fast insertion and deletion of elements are needed.
- Implementing Stacks and Queues: These data structures can be implemented efficiently using singly linked lists. The dynamic nature of SLLs allows easy push and pop operations (for stacks) or enqueue and dequeue operations (for queues) without worrying about resizing, as you would with arrays.
- Memory Management: In memory management, linked lists are used to represent free blocks of memory. When a block of memory is freed, it is added to a free list (a linked list), and when memory is allocated, it is taken from the free list.
- Dynamic Data Allocation: In applications where the size of the data cannot be determined in advance or changes frequently, single linked lists (SLLs) provide an efficient way to handle this. They allow for adding or removing data dynamically without the need to allocate or resize a contiguous block of memory.
- Polynomials: They are often represented using linked lists, where each node contains a coefficient and an exponent. This allows for efficient addition, subtraction, and multiplication of polynomials, especially when the number of terms varies.
- Graph Representation: Singly linked lists are often used to represent adjacency lists in graph data structures. Each vertex in the graph has a linked list of adjacent vertices, making it easy to store and traverse a sparse graph.
- Implementing Hash Tables: In hash table implementation using chaining, each bucket can be implemented using a linked list. This helps in handling collisions efficiently when multiple keys hash to the same bucket.
- Sparse Matrices: Singly linked lists are useful for storing sparse matrices, where most of the elements are zero. Rather than allocating memory for every element, linked lists allow efficient storage of only non-zero elements.
- Undo Mechanism: In software applications like text editors or drawing tools, linked lists can be used to store a history of operations. By using a linked list to represent actions, the system can easily undo or redo previous operations.
Common Problems With Singly Linked Lists
While singly linked lists are a powerful data structure, they come with certain challenges and potential pitfalls. Understanding these common issues helps in building robust solutions and avoiding common mistakes.
- Memory Leaks: Failing to properly deallocate memory when nodes are removed can lead to memory leaks.
Solution: Always ensure that you free memory when nodes are deleted or no longer needed. In C++, this can be done using delete for each node that is removed. - Traversal Time Complexity: Accessing elements in a singly linked list requires traversal from the head to the desired position, leading to O(n) time complexity for searches, insertions, and deletions.
Solution: For more efficient access, consider using other data structures like arrays or doubly linked lists, where backward traversal is also possible. - Difficulty with Backtracking: Singly linked lists only allow traversal in one direction. Once you move past a node, you cannot go back to it without restarting from the head.
Solution: If you need frequent backward traversal, a doubly linked list may be more appropriate, as it allows traversal in both directions. - Insertion at Specific Positions: Inserting an element at a specific position in a singly linked list requires traversal to that position, which can be inefficient if the position is near the end of the list.
Solution: If insertion at specific positions is a frequent operation, consider using other data structures like a doubly linked list or an array-based structure for faster access. - Difficulty in Reversing the List: Reversing a singly linked list involves changing the direction of the pointers for each node, which requires an additional traversal and careful handling of pointers to avoid breaking the list.
Solution: Use a well-defined algorithm for reversing the list. For instance, iteratively reverse the list by updating the pointers from the head to the end. - Limited Use of Indexing: Unlike arrays, linked lists don’t support indexing, meaning direct access to a node by position is not possible.
Solution: If you need frequent random access to elements, an array or vector might be more efficient. - Complicated Deletion: Deleting nodes in a singly linked list, especially when dealing with deletion at the middle or end of the list, can be tricky as it requires keeping track of the previous node in order to update the next pointer.
Solution: Properly manage pointers during deletion to ensure the list remains intact. When deleting from the middle or end, handle the previous node’s next pointer carefully.
Stay ahead of the curve—practice with hands-on coding problems designed to level up your abilities.
Conclusion
In this article, we have explored the fundamentals of singly linked lists, including their structure, insertion and deletion operations, and common applications. We’ve also covered some practical aspects, such as best practices for managing linked lists efficiently and tackling challenges.
By understanding the core concepts and operations on single linked lists, you'll be better equipped to use them effectively in real-world applications, whether it's for managing dynamic data or solving complex problems. Remember to follow best practices, handle memory efficiently, and use iterative approaches when working with linked lists to avoid common pitfalls.
Frequently Asked Questions
Q1. What is the difference between a singly linked list and a doubly linked list?
In a singly linked list, each node has a pointer to the next node, and traversal can only be done in one direction (forward). In contrast, a doubly linked list has two pointers in each node—one pointing to the next node and another pointing to the previous node, allowing traversal in both directions.
Q2. Can we have a singly linked list with no nodes?
Yes, a singly linked list can be empty. This occurs when the head pointer is set to nullptr, meaning there are no nodes in the list.
Q3. How do we traverse a singly linked list?
To traverse a singly linked list, start from the head node and continue to the next node until you reach a node whose next pointer is nullptr. At each step, you can process or access the data in the current node.
Node* current = head;
while (current != nullptr) {
// Process current->data
current = current->next;
}
Q4. How can I find the length of a singly linked list?
The length of a singly linked list can be calculated by traversing the list and counting the number of nodes.
int length = 0;
Node* current = head;
while (current != nullptr) {
Length++;
current = current->next;
}
Q5. What happens if I try to delete a node in an empty linked list?
If you try to delete a node when the list is empty (i.e., the head pointer is nullptr), it will have no effect, as there are no nodes to delete. It's essential to first check if the list is empty before performing deletion.
if (head != nullptr) {
// Perform deletion
}
Q6. Can I add elements at the end of a singly linked list efficiently?
Yes, you can add elements at the end, but if you don’t maintain a tail pointer, you’ll need to traverse the entire list to reach the last node. This results in an O(n) time complexity for insertion at the end. Maintaining a tail pointer allows for O(1) insertion at the end.
By now, you must be able to understand the theory as well as implement, modify, and troubleshoot single linked lists like a pro. Here are a few more interesting articles you must explore:
- Difference Between Linear Search And Binary Search (+Code Example)
- 53 Frequently Asked Linked List Interview Questions With Answers
- 55+ Data Structure Interview Questions For 2026 (Detailed Answers)
- Arrays In C | Declare, Initialize, Manipulate & More (+Code Examples)
- Operators In C++ | Types, Precedence & Associativity (+ Examples)
Login to continue reading
And access exclusive content, personalized recommendations, and career-boosting opportunities.
Don't have an account? Sign up
Never miss an
Update

Featured Opportunities
Top-Rated Practice by Students





Subscribe
to our newsletter



Comments
Add comment