
Asian Paints Alchemy 2026
Table of content:
- Overview Of Character Set In C
- Important Use Cases Of Character Set In C
- Alphabet Character Set In C
- Digit Character Set In C
- Special Character Set In C
- White Space Character Set In C
- The Evolution Of Character Sets In C
- The Unicode Era
- Categories Of Special Characters In C
- Character Equivalence & Character Set In C
- Conclusion
- Frequently Asked Questions
Character Set In C | The Ultimate Guide With Detailed Examples
A character set is a collection of all characters (like letters, digits, symbols, etc.) that can be used in code. It is classified into two main categories: the source character set and the execution character set in C.
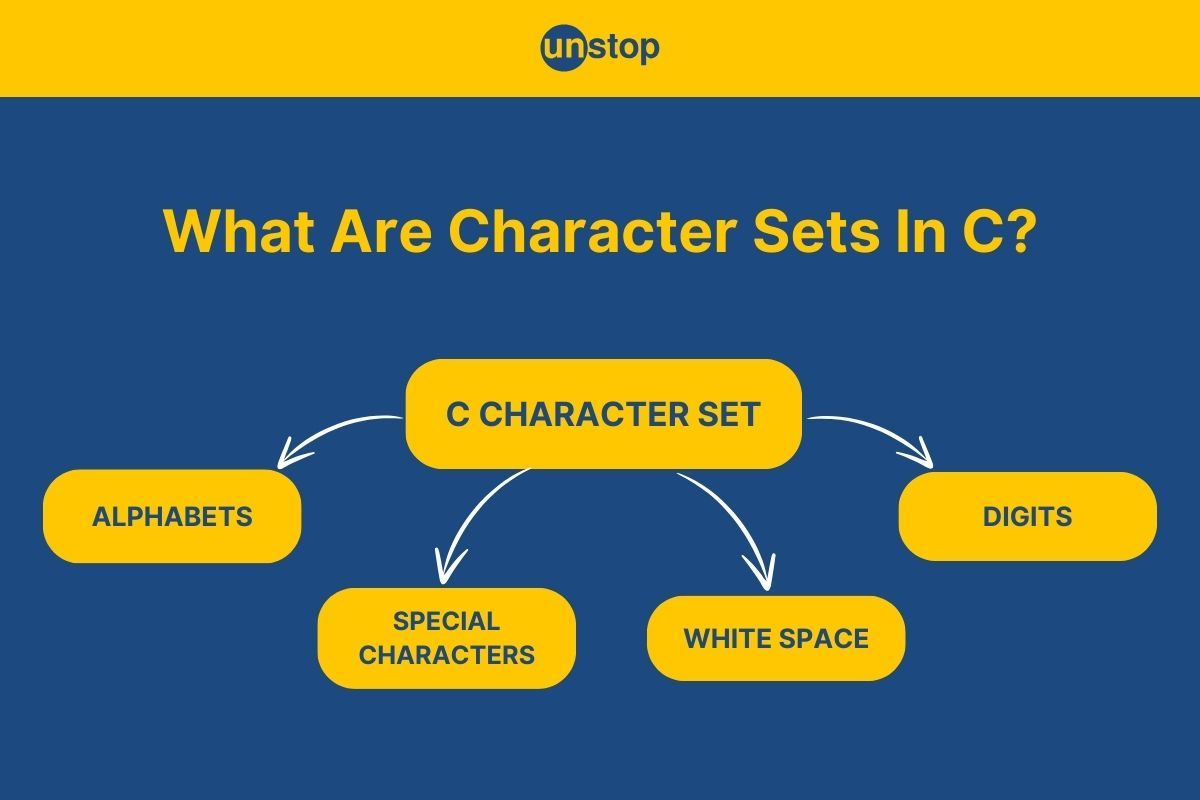
Character set in C programming language denotes any alphabet, digit, or special symbol used to represent information. Characters are the smallest unit of a string and take up the memory space of 1 byte each. They can be incorporated into the program both as a variable and as a constant.
In this article, we will explore the different types of C character sets, the utility functions available to interact with these characters, and code examples demonstrating their use. By mastering the character set of C language, you can enhance your programming skills and ensure your code adheres to the language's syntax rules.
Overview Of Character Set In C
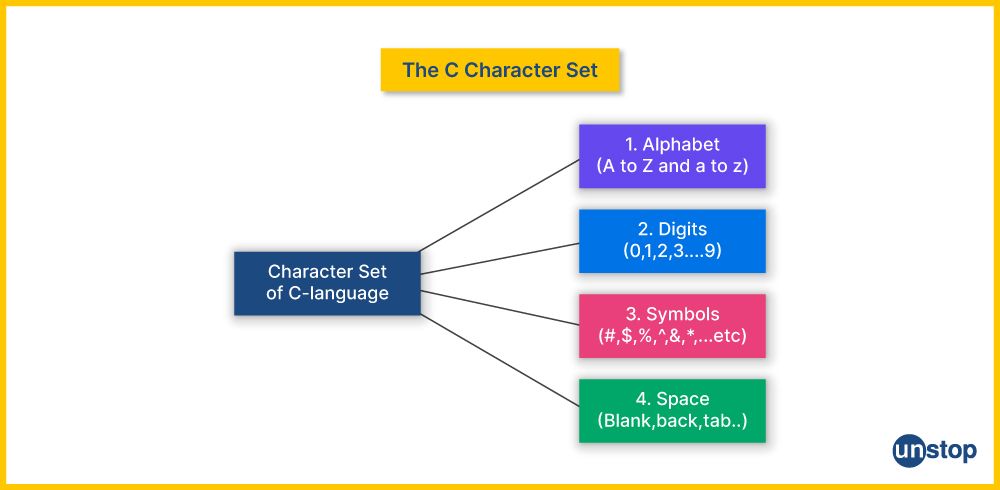
The character set in C encompasses all the valid characters that the language recognizes and can manipulate. This includes letters, special symbols, digits, and control characters. All of these are essential for writing clear, functional, and syntactically correct numeric code.
Types Of Character Sets In C
The C character set is divided into two main categories based on the character type:
- Source Character Set
- Execution Character Set
We will explore both these types of character set in detail in the sections ahead.
Source Character Set In C
The source character set in C consists of all the characters that can be used in the source code of the program. It allows programmers to write readable and maintainable code using familiar symbols and letters. It includes the following:
- Letters: Both uppercase (A-Z) and lowercase (a-z) alphabets.
- Digits: The numerals from 0 to 9.
- Special Characters: These include symbols like +, -, *, /, =, <, >, &, |, !, ^, ~, %, #, \, ;, :, ', " and more.
- Whitespace Characters: These include spaces, tabs, newlines, and form feeds.
- Escape Sequences: These are special meaning characters prefixed with a backslash, such as \n (newline), \t (tab), \\ (backslash character), \' (single quote), and \" (double quote).
Execution Character Set In C
The execution character set, also known as the control character set in C programming, comprises character sets that are used during the execution of a C program. Control characters are vital for managing the flow of the program, formatting output, and handling input. It includes:
- Control Characters: Characters that do not represent a printable symbol but rather perform a control function, such as \n (newline), \t (tab), \b (backspace), and \r (carriage return).
- Printable Characters: All characters that produce a visible output, including letters, digits, and special symbols.
Important Use Cases Of Character Set In C
The character sets play a crucial role in various aspects of the C programming language. Here are some of its key uses:
- Defining Identifiers: Letters and digits are used to create variable names, function names, and other valid identifier names.
- Writing Keywords: Use specific reserved words like int, return, if, and else to define the structure and flow of a program.
- Constructing Operators: Special characters like +, -, *, /, %, =, ==, !=, &&, and || make up the operators in C, including arithmetic operators, logical operators, relational operators, etc. They are used to perform mathematical operations, comparisons and other manipulations on data.
- Creating Constants: Digits and letters are used to define numeric character constants (e.g., 100, 3.14) and character constants (e.g., 'A', 'b').
- String Literals: Characters enclosed in double quotes (e.g., "Hello, World!") are used for internal representation of string literals.
- Formatting Output: Escape sequences like \n (newline), \t (tab), and \\ (backslash) are used within character string constants to format output.
- Writing Comments: Special character types like /* ... */ and // are used to mark comments in the code.
- Punctuating Code: Punctuation marks such as semicolon(;), comma or file separator (,), dot(.), colon(:), and braces({}) are used to optimize program structure by separating program statements, and defining code blocks.
- Managing Input and Output: Escape sequence character constants are used in functions like printf and scanf to handle input and output operations.
- Defining Control Structures: Keywords composed of characters, such as if, else, while, for, switch and case, are used to define control flow statements/ structures.
- Handling Data Types: Characters are used to specify data types like int, float, char, double, and void.
- Macro Definitions: Special characters like hashtag (#) and define are used in preprocessor directives to define macros.
- Managing Memory: Characters are used in functions like malloc, free, sizeof, and memcpy for dynamic memory management.
- Defining Arrays and Pointers: Characters such as [] (square brackets) and * (asterisk) are used to define arrays and pointers, respectively. They are crucial for managing collections of data and dynamic memory addresses.
Alphabet Character Set In C
The alphabet set is the collection of all letters used in writing systems. In other words, it is the ASCII character set in C with both uppercase and lowercase English letters.
- Uppercase Alphabets (A to Z): These are the capital letters used at the beginning of sentences, proper nouns, and for emphasis.
- Lowercase Alphabets (a to z): These are the small letters used in most of the text.
Utility Functions For Alphabet Characters In C
Utility functions are built-in library functions in the C programming language that are used to check for or manipulate the alphabet. These functions are a part of the <ctype.h> header file of the C programming language. Here’s a table comprising all the utility functions present in the alphabet characters set in C language:
| Function | Description |
|---|---|
| isalpha(int c) |
This function checks whether the passed character is an alphabet. It takes an integer value(ASCII code of the alphabet) as the parameter and returns a non-zero value if the integer represents an alphabet; otherwise, it returns zero. |
| toupper(int c) | This function checks whether the passed character is a lowercase alphabet. It takes an integer value(ASCII code of the alphabet) as the parameter and returns a non-zero value if the integer represents a lowercase letter; otherwise, it returns zero. |
| tolower(int c) | This function checks whether the passed character is an uppercase alphabet. It takes an integer value(ASCII code of the alphabet) as the parameter and returns a non-zero value if the integer value represents a uppercase letter; otherwise, it returns zero. |
| isupper(int c) | This function is a conversion function that converts the passed character to an uppercase alphabet. It takes an integer value(ASCII code of the alphabet) as the parameter and returns the letter in uppercase if the integer is in lowercase; otherwise, it remains unchanged. |
| islower(int c) | This function is a conversion function that converts the passed character to a lowercase alphabet. It takes an integer value(ASCII code of the alphabet) as the parameter and returns the letter in lowercase if the integer is in uppercase; otherwise, it remains unchanged. |
Table Of ASCII Values Of All Alphabets
The following table lists the ASCII values for each letter in the English alphabet character set in C.
| Upper Case Alphabet | Lower Case Alphabet | ||||||
| Alphabet | ASCII value | Alphabet | ASCII value | Alphabet | ASCII value | Alphabet | ASCII value |
| A | 65 | N | 78 | a | 97 | n | 110 |
| B | 66 | O | 79 | b | 98 | o | 111 |
| C | 67 | P | 80 | c | 99 | p | 112 |
| D | 68 | Q | 81 | d | 100 | q | 113 |
| E | 69 | R | 82 | e | 101 | r | 114 |
| F | 70 | S | 83 | f | 102 | s | 115 |
| G | 71 | T | 84 | g | 103 | t | 116 |
| H | 72 | U | 85 | h | 104 | u | 117 |
| I | 73 | V | 86 | i | 105 | v | 118 |
| J | 74 | W | 87 | j | 106 | w | 119 |
| K | 75 | X | 88 | k | 107 | x | 120 |
| L | 76 | Y | 89 | l | 108 | y | 121 |
| M | 77 | Z | 90 | m | 109 | z | 122 |
Code:
#include
#include
int main() {
char c = 'b'; // Character to test
// Check if character is an alphabet letter
if (isalpha(c)) {
printf("'%c' is an alphabet letter.\n", c);
}
// Check if character is uppercase or lowercase
if (isupper(c)) {
printf("'%c' is uppercase.\n", c);
} else if (islower(c)) {
printf("'%c' is lowercase.\n", c);
}
// Convert character to uppercase and lowercase
printf("Uppercase of '%c' is '%c'.\n", c, toupper(c));
printf("Lowercase of '%c' is '%c'.\n", c, tolower(c));
return 0;
}
I2luY2x1ZGUgPHN0ZGlvLmg+CiNpbmNsdWRlIDxjdHlwZS5oPgoKaW50IG1haW4oKSB7CmNoYXIgYyA9ICdiJzsgLy8gQ2hhcmFjdGVyIHRvIHRlc3QKCi8vIENoZWNrIGlmIGNoYXJhY3RlciBpcyBhbiBhbHBoYWJldCBsZXR0ZXIKaWYgKGlzYWxwaGEoYykpIHsKcHJpbnRmKCInJWMnIGlzIGFuIGFscGhhYmV0IGxldHRlci5cbiIsIGMpOwp9CgovLyBDaGVjayBpZiBjaGFyYWN0ZXIgaXMgdXBwZXJjYXNlIG9yIGxvd2VyY2FzZQppZiAoaXN1cHBlcihjKSkgewpwcmludGYoIiclYycgaXMgdXBwZXJjYXNlLlxuIiwgYyk7Cn0gZWxzZSBpZiAoaXNsb3dlcihjKSkgewpwcmludGYoIiclYycgaXMgbG93ZXJjYXNlLlxuIiwgYyk7Cn0KCi8vIENvbnZlcnQgY2hhcmFjdGVyIHRvIHVwcGVyY2FzZSBhbmQgbG93ZXJjYXNlCnByaW50ZigiVXBwZXJjYXNlIG9mICclYycgaXMgJyVjJy5cbiIsIGMsIHRvdXBwZXIoYykpOwpwcmludGYoIkxvd2VyY2FzZSBvZiAnJWMnIGlzICclYycuXG4iLCBjLCB0b2xvd2VyKGMpKTsKCnJldHVybiAwOwp9Cg==
Output:
'b' is an alphabet letter.
'b' is lowercase.
Uppercase of 'b' is 'B'.
Lowercase of 'b' is 'b'.
Explanation:
In the above simple C program example,
- We start by including the standard input-output header file <stdio.h>, and the character handling functions header file <ctype.h>.
- In the main function, we declare a character variable c and initialize it with the value 'b'. This is the character we will be testing.
- We now use if-else statements to check if c is an alphabet letter using the isalpha() function. If c is an alphabet letter, we print a message confirming this.
- Next, we check if c is an uppercase letter using the isupper() function. If it is, we print that it’s uppercase. If it’s not, we check if it’s a lowercase letter using the islower() function and print that it’s lowercase if true.
- After these checks, we use the toupper() function to convert c to uppercase and print the result. Similarly, we use the tolower() function to convert c to lowercase and print that result.
- Finally, the main function returns 0 to indicate that the program has been executed successfully.
Digit Character Set In C
Characters 0 through 9 make up the digital character set in C programming. They are used to represent/ write numeric expressions or values in source programs. The digital character set is widely applicable in arithmetic operations, data validation, and other programming tasks.
Utility Functions For Digit Characters In C
There are two primary utility functions that can be used to perform operations/ manipulations on digital character sets, in C programming. They belong to the <ctype.h> library and are described in the table below.
| Function | Description |
|---|---|
| int isdigit(int c) | This function checks whether the passed character is a decimal digit. It takes an integer value (ASCII code of the character) as the parameter and returns a non-zero value if the character is a digit ('0' to '9'). It returns zero if the character is not a digit. |
| int isalnum(int c) | This function checks whether the passed character is an alphanumeric character. It takes an integer value (ASCII code of the character) as the parameter and returns a non-zero value if it is an alphabet or a digit, and zero if it is neither. |
Note: An alphanumeric character can be a digit or an alphabet (both uppercase and lowercase characters). The isalnum() function is hence applicable to the alphabet character set, as well.
Table Of ASCII Values Of All Digits
| Digits | ASCII Code |
| 0 | 48 |
| 1 | 49 |
| 2 | 50 |
| 3 | 51 |
| 4 | 52 |
| 5 | 53 |
| 6 | 54 |
| 7 | 55 |
| 8 | 56 |
| 9 | 57 |
Code:
#include
#include // Include for isdigit() and isalnum() functions
int main() {
// Single test character
char c = '5'; // You can try running this code with various other characters by replacing it here
// Check if the character is a digit and if it is alphanumeric
printf("Character: '%c'\n", c);
printf("Is digit: %d\n", isdigit(c)); // Check if the character is a digit
printf("Is alnum: %d\n", isalnum(c)); // Check if the character is alphanumeric
return 0;
}
I2luY2x1ZGUgPHN0ZGlvLmg+CiNpbmNsdWRlIDxjdHlwZS5oPiAvLyBJbmNsdWRlIGZvciBpc2RpZ2l0KCkgYW5kIGlzYWxudW0oKSBmdW5jdGlvbnMKCmludCBtYWluKCkgewovLyBTaW5nbGUgdGVzdCBjaGFyYWN0ZXIKY2hhciBjID0gJzUnOyAvLyBZb3UgY2FuIHRyeSBydW5uaW5nIHRoaXMgY29kZSB3aXRoIHZhcmlvdXMgb3RoZXIgY2hhcmFjdGVycyBieSByZXBsYWNpbmcgaXQgaGVyZQoKLy8gQ2hlY2sgaWYgdGhlIGNoYXJhY3RlciBpcyBhIGRpZ2l0IGFuZCBpZiBpdCBpcyBhbHBoYW51bWVyaWMKcHJpbnRmKCJDaGFyYWN0ZXI6ICclYydcbiIsIGMpOwpwcmludGYoIklzIGRpZ2l0OiAlZFxuIiwgaXNkaWdpdChjKSk7IC8vIENoZWNrIGlmIHRoZSBjaGFyYWN0ZXIgaXMgYSBkaWdpdApwcmludGYoIklzIGFsbnVtOiAlZFxuIiwgaXNhbG51bShjKSk7IC8vIENoZWNrIGlmIHRoZSBjaGFyYWN0ZXIgaXMgYWxwaGFudW1lcmljCgpyZXR1cm4gMDsKfQo=
Output:
Character: '5'
Is digit: 2048
Is alnum: 8
Explanation:
In the above code example,
- We begin by declaring a character variable c and assign the value 5 to it. We print the value of c to the console.
- Then, we use the isdigit() function to check if c is a digit (i.e., a character between '0' and '9'). We print the result, where 1 indicates that c is a digit and 0 means it is not.
- Next, we use the isalnum() function to check if c is alphanumeric (i.e., either a digit or a letter). We print the result, where 1 means c is alphanumeric and 0 means it is not.
- Finally, we return 0 to indicate that the program executed successfully.
Special Character Set In C
Almost all characters that are not a part of the standard text in a traditional sense are contained in the special character set in C programming. This includes escape character sequences, control characters, and symbols that serve specific functions in code.
Utility Functions For Special Characters In C
C provides several functions in the <ctype.h> library to work with special characters. Here’s a table highlighting these functions along with their purposes:
| Function | Description |
|---|---|
| int iscntrl(int c) | This function checks if the character is a control character (non-printable). Returns a non-zero value if true. |
| int isspace(int c) | This function checks if the character is a white space character (space, tab, newline, etc.). Returns a non-zero value if true. |
| int ispunct(int c) | This function checks if the character is a punctuation character (special character like !, ?, etc.). Returns a non-zero value if true. |
| int isprint(int c) | This function checks if the character is a printable character, including space. Returns a non-zero value if true. |
| int isgraph(int c) | This function checks if the character is a printable character, excluding space. Returns a non-zero value if true. |
| int isalnum(int c) | This function checks if the character is an alphanumeric character (letter or digit). Returns a non-zero value if true. |
Table Of ASCII Values Of All Special Characters
| Special Characters | ASCII Code | Special Characters | ASCII Code |
| ! | 33 | ; | 59 |
| “ | 34 | < | 60 |
| # | 35 | = | 61 |
| $ | 36 | > | 62 |
| % | 37 | ? | 63 |
| & | 38 | @ | 64 |
| ‘ | 39 | [ | 91 |
| ( | 40 | / | 92 |
| ) | 41 | ] | 93 |
| * | 42 | ^ | 94 |
| =+ | 43 | _ | 95 |
| , | 44 | ` | 96 |
| - | 45 | { | 123 |
| . | 46 | | | 124 |
| / | 47 | } | 125 |
| : | 58 | ~ | 126 |
Code:
#include
#include // Include for ctype functions
int main() {
char testChar = '@'; // Test with an '@' character
// Check various properties of the character
printf("Character: %c\n", testChar);
printf("iscntrl: %d\n", iscntrl(testChar)); // Check if the character is a control character
printf("isspace: %d\n", isspace(testChar)); // Check if the character is a white space character
printf("ispunct: %d\n", ispunct(testChar)); // Check if the character is a punctuation character
printf("isprint: %d\n", isprint(testChar)); // Check if the character is a printable character
printf("isgraph: %d\n", isgraph(testChar)); // Check if the character is a graphical character
printf("isalnum: %d\n", isalnum(testChar)); // Check if the character is an alphanumeric character
return 0;
}
I2luY2x1ZGUgPHN0ZGlvLmg+CiNpbmNsdWRlIDxjdHlwZS5oPiAvLyBJbmNsdWRlIGZvciBjdHlwZSBmdW5jdGlvbnMKCmludCBtYWluKCkgewpjaGFyIHRlc3RDaGFyID0gJ0AnOyAvLyBUZXN0IHdpdGggYW4gJ0AnIGNoYXJhY3RlcgoKLy8gQ2hlY2sgdmFyaW91cyBwcm9wZXJ0aWVzIG9mIHRoZSBjaGFyYWN0ZXIKcHJpbnRmKCJDaGFyYWN0ZXI6ICVjXG4iLCB0ZXN0Q2hhcik7CnByaW50ZigiaXNjbnRybDogJWRcbiIsIGlzY250cmwodGVzdENoYXIpKTsgLy8gQ2hlY2sgaWYgdGhlIGNoYXJhY3RlciBpcyBhIGNvbnRyb2wgY2hhcmFjdGVyCnByaW50ZigiaXNzcGFjZTogJWRcbiIsIGlzc3BhY2UodGVzdENoYXIpKTsgLy8gQ2hlY2sgaWYgdGhlIGNoYXJhY3RlciBpcyBhIHdoaXRlIHNwYWNlIGNoYXJhY3RlcgpwcmludGYoImlzcHVuY3Q6ICVkXG4iLCBpc3B1bmN0KHRlc3RDaGFyKSk7IC8vIENoZWNrIGlmIHRoZSBjaGFyYWN0ZXIgaXMgYSBwdW5jdHVhdGlvbiBjaGFyYWN0ZXIKcHJpbnRmKCJpc3ByaW50OiAlZFxuIiwgaXNwcmludCh0ZXN0Q2hhcikpOyAvLyBDaGVjayBpZiB0aGUgY2hhcmFjdGVyIGlzIGEgcHJpbnRhYmxlIGNoYXJhY3RlcgpwcmludGYoImlzZ3JhcGg6ICVkXG4iLCBpc2dyYXBoKHRlc3RDaGFyKSk7IC8vIENoZWNrIGlmIHRoZSBjaGFyYWN0ZXIgaXMgYSBncmFwaGljYWwgY2hhcmFjdGVyCnByaW50ZigiaXNhbG51bTogJWRcbiIsIGlzYWxudW0odGVzdENoYXIpKTsgLy8gQ2hlY2sgaWYgdGhlIGNoYXJhY3RlciBpcyBhbiBhbHBoYW51bWVyaWMgY2hhcmFjdGVyCgpyZXR1cm4gMDsKfQ==
Output:
Character: @
iscntrl: 0
isspace: 0
ispunct: 4
isprint: 16384
isgraph: 32768
isalnum: 0
Explanation:
In the above source program,
- We begin by declaring a character variable testChar and initializing it with the value '@'. This character will be used to test different properties. We print the value of testChar to the console.
- We then use the iscntrl() function to check if testChar is a control character (like backspace or tab). The result is printed, where 1 means it is a control character and 0 means it is not.
- Next, we use the isspace() function to check if testChar is a whitespace character (such as space, tab, or newline). We print the result, where 1 means it is a whitespace character and 0 means it is not.
- We then use the ispunct() function to check if testChar is a punctuation character (like @, !, or ?). The result is printed, where 1 means it is a punctuation character and 0 means it is not.
- Next, we use the isprint() function to check if testChar is a printable character (any character that displays on the screen, including letters, digits, and punctuation). We print the result, where 1 means it is a printable character and 0 means it is not.
- We then use the isgraph() function to check if testChar is a graphical character (any printable character except for space). The result is printed, where 1 means it is a graphical character and 0 means it is not.
- Finally, we use the isalnum() function to check if testChar is an alphanumeric character (either a letter or a digit). We print the result, where 1 means it is alphanumeric and 0 means it is not.
- We return 0 to indicate that the program executed successfully.
White Space Character Set In C
The white spaces are characters that create space between words or symbols in the source code. They are essential for the readability of code and can affect how input is processed. White space character representations include spaces, tabs, and newlines, and are generally used to separate tokens in C programs.
The main types of white space characters in C are:
- Blank Space Character(' '): The most common white space character.
- Tab Character('\t'): Horizontal tab space.
- Vertical Tab Character('\v'): Moves the cursor down to the next vertical tab stop.
- Newline Character('\n'): Line feed moves the cursor to the next line.
- Carriage Return Character('\r'): Moves the cursor to the beginning of the line.
Utility Functions For White Spaces Character Set In C
| Function | Description |
|---|---|
| int isspace(char c): | This function checks whether the passed character is a white space character. It takes an integer value(ASCII code of the character) as the parameter and returns a non-zero value if it is a white space character and zero if it is false. |
Table Of ASCII Values Of All White Space Character
|
ASCII Code |
Technical Term |
Character |
|
32 |
Space |
<space> |
|
9 |
Horizontal Tab |
\t |
|
10 |
Newline |
\n |
|
11 |
Vertical Tab |
\v |
|
13 |
Carriage Return |
\r |
|
0 |
Null |
\0 |
Code:
#include
#include // Included for isspace() function
int main() {
char c = ' '; // You can change this to test other characters
// Check if the character is a white space
if (isspace(c)) {
printf("'%c' is a whitespace character.\n", c);
} else {
printf("'%c' is not a whitespace character.\n", c);
}
return 0;
}
I2luY2x1ZGUgPHN0ZGlvLmg+CiNpbmNsdWRlIDxjdHlwZS5oPiAvLyBJbmNsdWRlZCBmb3IgaXNzcGFjZSgpIGZ1bmN0aW9uCgppbnQgbWFpbigpIHsKY2hhciBjID0gJyAnOyAvLyBZb3UgY2FuIGNoYW5nZSB0aGlzIHRvIHRlc3Qgb3RoZXIgY2hhcmFjdGVycwoKLy8gQ2hlY2sgaWYgdGhlIGNoYXJhY3RlciBpcyBhIHdoaXRlIHNwYWNlCmlmIChpc3NwYWNlKGMpKSB7CnByaW50ZigiJyVjJyBpcyBhIHdoaXRlc3BhY2UgY2hhcmFjdGVyLlxuIiwgYyk7Cn0gZWxzZSB7CnByaW50ZigiJyVjJyBpcyBub3QgYSB3aGl0ZXNwYWNlIGNoYXJhY3Rlci5cbiIsIGMpOwp9CgpyZXR1cm4gMDsKfQ==
Output:
' ' is a whitespace character.
Explanation:
In the above source code:
- We begin by declaring a character variable c and initializing it with the value ' ' (a space character).
- As mentioned in the code comments, you can replace this character with others and run the code.
- Next, we use the isspace() function to check if c is a whitespace character (like a space, tab, or newline). If c is a whitespace character, we print a message saying so.
- If c is not a whitespace character, we print a different message indicating that it is not a whitespace character.
- Finally, we return 0 to indicate that the program executed successfully.
The Evolution Of C Character Set
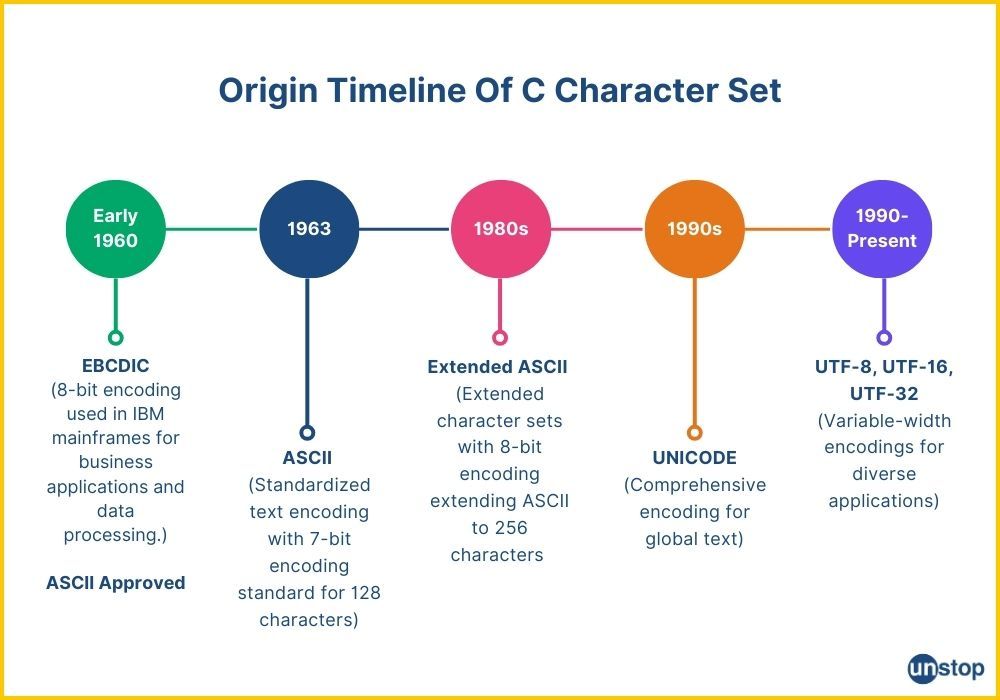
Character sets in C programming have their roots in a code called EBCDIC (Extended Binary Coded Decimal Interchange Code). Developed by IBM in the 1960s, EBCDIC assigned a unique 8-bit code to represent various characters like letters, numbers, and symbols. However, EBCDIC had some limitations:
- Non-standard: EBCDIC was not a universal code, and different versions existed for various IBM machines. This created compatibility issues when exchanging data.
- Focus on Punched Cards: The design of EBCDIC reflected the limitations of punched card technology, where certain characters were more efficiently encoded than others.
The need for a more standardized character set led to the development of ASCII (American Standard Code for Information Interchange) in 1963. ASCII aimed to create a universal code for information exchange, focusing on:
- Standardization: ASCII established a fixed set of 7-bit codes for representing 128 characters, including uppercase and lowercase letters (a-z, A-Z), numbers (0-9), punctuation marks, and control characters. This consistency ensured wider compatibility.
- Focus on Code Readability: ASCII prioritized constant encoding of commonly used characters like letters and numbers with lower codes, making them easier for humans to interpret.
Here are some key characteristics of the ASCII value system:
- 7-bit codes: Each character is represented by a unique 7-bit binary code (0s and 1s). The 8th bit was later added for extended character sets.
- Integer values: ASCII codes correspond to integer values between 0 and 127. Lower numeric values represent control characters (e.g., tab character, newline characters) and non-printing characters, while higher values represent printable characters like letters and numbers.
- Universality: ASCII's widespread adoption made it the foundation for the C language character set. C programs can represent and manipulate characters using their corresponding ASCII codes.
The C character set primarily utilizes ASCII, making it a fundamental element for working with text and character data in C programming. But nothing is perfect, right? (Well, almost nothing)
The Conflict With ASCII
The development and adoption of various character sets like EBCDIC and ASCII came with conflicts and challenges, particularly due to differences in encoding schemes and character representation. Some of these challenges are as follows:
- Data incompatibility: Existing data stored in EBCDIC format wasn't automatically compatible with ASCII. This meant that data conversion tools needed to translate EBCDIC files into ASCII for use on systems adopting the newer standard.
- Software modifications: Software applications that were designed for EBCDIC systems required some adjustments to handle ASCII character codes. It involved modifying code sections that relied on specific EBCDIC character representations.
- Limited character set: While ASCII offered a more universal standard, its 7-bit character set couldn't represent characters outside the English language or special symbols used in certain industries. This limitation was addressed by the extension of the character set (building upon ASCII).
The Unicode Era
The limitations of ASCII became apparent as the need for representing characters beyond the English language grew. This led to the development of Unicode, a character encoding standard that emerged in the late 1980s. Here are some key points about Unicode:
- Universal Character Set: Unicode assigns a unique code point (a number) to a vast number of characters, encompassing virtually all writing systems worldwide. This includes characters from languages like Arabic, Chinese, Japanese, Cyrillic, and many more.
- Superset of ASCII: Unicode incorporates the entire ASCII character set, ensuring compatibility with existing code. However, it extends far beyond ASCII to accommodate a much broader range of characters.
- 16-bit and Beyond: Initially, Unicode used 16-bit codes, allowing for over 65,000 characters. However, with the addition of even more characters, Unicode now utilizes a variable-width encoding scheme that can accommodate hundreds of thousands of characters.
The adoption of Unicode revolutionized how computers handle text data, enabling seamless communication and data exchange across languages and cultures.
Categories Of Special Characters In C
In C programming, special characters serve distinct purposes beyond representing standard letters, numbers, and punctuation. They can be broadly categorized into two main types:
1. Control Characters (Non-Printable Characters)
These characters do not produce visual output on the screen and are hence referred to as non-printable characters. They primarily influence formatting, program flow, or device control. Common examples of non-printable characters include:
| Control Character | Description | ASCII Code |
|---|---|---|
| \n | New Line | 10 |
| \r | Carriage Return Character | 13 |
| \t | Horizontal Tab | 9 |
| \b | Backspace Character | 8 |
| \f | Form Feed | 12 |
| \a | Alert or Beep Sound(Bell) | 7 |
| \v | Vertical Tab | 11 |
| \0 | Null Character | 0 |
2. Printable Characters
These characters do produce visual output on the screen. For eg: the dollar sign($), the percent sign(%), the exclamation mark(!), etc are all visible on the user screen. They encompass the standard character set used for text representation, including:
| Printable Character | Description | ASCII Code |
|---|---|---|
| A-Z | Uppercase Letters | 65-90 |
| a-z | Lowercase Letters | 97-122 |
| 0-9 | Digits | 48-57 |
| ! " # $ % & ' ( ) * + , - . / | Punctuation Symbols | 33-47 |
| : ; < = > ? @ | Punctuation Symbols | 58-64 |
| [ \ ] ^ _ | Punctuation Symbols | 91-96 |
| { } ~ | | Punctuation Symbols | Braces, pipe symbol, tilde |
Character Equivalence & Character Set In C
In C programming, character equivalence refers to the concept in which different characters can be treated as equivalent under certain conditions. This principle is important for various operations involving characters in C, such as comparisons, assignments, and string manipulations. This includes:
- Case Sensitivity: Characters might be considered equivalent if they are the same letter irrespective of the cases (e.g., 'A' and 'a').
- Normalization: Characters might be treated as equivalent if they represent the same concept but have different representations or source code encodings (e.g., 'é' and 'e' + accent).
- Collation: It deals with the ordering and comparison of characters based on linguistic rules and locale settings, considering aspects like letter casing and character equivalence. (e.g., 'é' and 'e' can be treated the same in certain locales).
Table Of Character Equivalence Values For All Characters
The table below lists all the characters along with their corresponding octal, decimal, and hexadecimal values.
|
Character |
Octal |
Decimal |
Hexadecimal |
|
\0 |
00 |
0 |
0х0 |
|
SOH |
01 |
1 |
0х1 |
|
STX |
02 |
2 |
0х2 |
|
ETX |
03 |
3 |
0х3 |
|
EOT |
04 |
4 |
0х4 |
|
ENQ |
05 |
5 |
0х5 |
|
ACK |
06 |
6 |
0х6 |
|
BEL |
07 |
7 |
0х7 |
|
BS |
010 |
8 |
0х8 |
|
HS |
011 |
9 |
0х9 |
|
LF |
012 |
10 |
0хA |
|
VT |
013 |
11 |
0хB |
|
FF |
014 |
12 |
0хC |
|
CR |
015 |
13 |
0хD |
|
SO |
016 |
14 |
0хE |
|
SI |
017 |
15 |
0хF |
|
DLE |
020 |
16 |
0х10 |
|
DC1 |
021 |
17 |
0х11 |
|
DC2 |
022 |
18 |
0х12 |
|
DC3 |
023 |
19 |
0х13 |
|
DC4 |
024 |
20 |
0х14 |
|
NAK |
025 |
21 |
0х15 |
|
SYN |
026 |
22 |
0х16 |
|
ETB |
027 |
23 |
0х17 |
|
CAN |
030 |
24 |
0х18 |
|
EM |
031 |
25 |
0х19 |
|
SUB |
032 |
26 |
0х1A |
|
ESC |
033 |
27 |
0х1B |
|
FS |
034 |
28 |
0х1C |
|
GS |
035 |
29 |
0х1D |
|
RS |
036 |
30 |
0х1E |
|
US |
037 |
31 |
0х1F |
|
<space> |
040 |
32 |
0х20 |
|
! |
041 |
33 |
0х21 |
|
“ |
042 |
34 |
0х22 |
|
# |
043 |
35 |
0х23 |
|
$ |
044 |
36 |
0х24 |
|
% |
045 |
37 |
0х25 |
|
& |
046 |
38 |
0х26 |
|
\ |
047 |
39 |
0х27 |
|
( |
050 |
40 |
0х28 |
|
) |
051 |
41 |
0х29 |
|
* |
052 |
42 |
0х2A |
|
+ |
053 |
43 |
0х2B |
|
, |
054 |
44 |
0х2C |
|
_ |
055 |
45 |
0х2D |
|
. |
056 |
46 |
0х2E |
|
/ |
057 |
47 |
0х2F |
|
0 |
060 |
48 |
0х30 |
|
1 |
061 |
49 |
0х31 |
|
2 |
062 |
50 |
0х32 |
|
3 |
063 |
51 |
0х33 |
|
4 |
064 |
52 |
0х34 |
|
5 |
065 |
53 |
0х35 |
|
6 |
066 |
54 |
0х36 |
|
7 |
067 |
55 |
0х37 |
|
8 |
070 |
56 |
0х38 |
|
9 |
071 |
57 |
0х39 |
|
| |
072 |
58 |
0х3A |
|
; |
073 |
59 |
0х3B |
|
< |
074 |
60 |
0х3C |
|
= |
075 |
61 |
0х3D |
|
> |
076 |
62 |
0х3E |
|
? |
077 |
63 |
0х3F |
|
__ |
0100 |
64 |
0х40 |
|
A |
0101 |
65 |
0х41 |
|
B |
0102 |
66 |
0х42 |
|
C |
0103 |
67 |
0х43 |
|
D |
0104 |
68 |
0х44 |
|
E |
0105 |
69 |
0х45 |
|
F |
0106 |
70 |
0х46 |
|
G |
0107 |
71 |
0х47 |
|
H |
0110 |
72 |
0х48 |
|
I |
0111 |
73 |
0х49 |
|
J |
0112 |
74 |
0х4A |
|
K |
0113 |
75 |
0х4B |
|
L |
0114 |
76 |
0х4C |
|
M |
0115 |
77 |
0х4D |
|
N |
0116 |
78 |
0х4E |
|
O |
0117 |
79 |
0х4F |
|
P |
0120 |
80 |
0х50 |
|
Q |
0121 |
81 |
0х51 |
|
R |
0122 |
82 |
0х52 |
|
S |
0123 |
83 |
0х53 |
|
T |
0124 |
84 |
0х54 |
|
U |
0125 |
85 |
0х55 |
|
V |
0126 |
86 |
0х56 |
|
W |
0127 |
87 |
0х57 |
|
X |
0130 |
88 |
0х58 |
|
Y |
0131 |
89 |
0х59 |
|
Z |
0132 |
90 |
0х5A |
|
[ |
0133 |
91 |
0х5B |
|
\ |
0134 |
92 |
0х5C |
|
] |
0135 |
93 |
0х5D |
|
^ |
0136 |
94 |
0х5E |
|
_ |
0137 |
95 |
0х5F |
|
‘ |
0140 |
96 |
0х60 |
|
a |
0141 |
97 |
0х61 |
|
b |
0142 |
98 |
0х62 |
|
c |
0143 |
99 |
0х63 |
|
d |
0144 |
100 |
0х64 |
|
e |
0145 |
101 |
0х65 |
|
f |
0146 |
102 |
0х66 |
|
g |
0147 |
103 |
0х67 |
|
h |
0150 |
104 |
0х68 |
|
i |
0151 |
105 |
0х69 |
|
j |
0152 |
106 |
0х6A |
|
k |
0153 |
107 |
0х6B |
|
l |
0154 |
108 |
0х6C |
|
m |
0155 |
109 |
0х6D |
|
n |
0156 |
110 |
0х6E |
|
o |
0157 |
111 |
0х6F |
|
p |
0160 |
112 |
0х70 |
|
q |
0161 |
113 |
0х71 |
|
r |
0162 |
114 |
0х72 |
|
s |
0163 |
115 |
0х73 |
|
t |
0164 |
116 |
0х74 |
|
u |
0165 |
117 |
0х75 |
|
v |
0166 |
118 |
0х76 |
|
w |
0167 |
119 |
0х77 |
|
x |
0170 |
120 |
0х78 |
|
y |
0171 |
121 |
0х79 |
|
z |
0172 |
122 |
0х7A |
|
{ |
0173 |
123 |
0х7B |
|
| |
0174 |
124 |
0х7C |
|
} |
0175 |
125 |
0х7D |
|
~ |
0176 |
126 |
0х7E |
|
DEL |
0177 |
127 |
0х7F |
Conclusion
The character set in C programming encompasses a variety of acceptable characters, including alphabets, digits, whitespace, special characters, and control characters. Each type from the <ctype.h> standard library offering functions that allow us to perform operations like checking character properties and converting characters. For example, functions such as isalpha(), isdigit(), isspace(), and ispunct() help determine if a character is a letter, digit, whitespace, or punctuation, respectively. Understanding these components and functions is crucial for performing a variety of tasks, from simple character conversions to complex text processing.
Frequently Asked Questions
Q. What are wide characters and how are they different from regular characters in C?
Wide characters are used to represent a larger set of characters beyond the ASCII range, including international character encoding and symbols in mathematics.
- In C, wide characters are represented by the wchar_t data type, which is typically 2 or 4 bytes in size, allowing for more extensive character encoding like Unicode.
- Functions dealing with wide characters are prefixed with w, such as wprintf and wscanf.
Q. What is the ASCII character set, and how is it used in C?
The ASCII character set is a standard that assigns numerical values to sets of characters, ranging from 0 to 127th characters. In C, ASCII is commonly used for the representation of characters, where each character corresponds to a specific ASCII value. For example, the ASCII value for the character 'A' is 65, and for 'a' it is 97.
Q. How does the C language represent characters?
In C, combinations of characters are represented using the char data type, which is typically 1 byte (8 bits) in size. Each effective character is associated with a unique numeric value defined by the ASCII (American Standard Code for Information Interchange) or Unicode encoding standards.
Q. What is a character set in C?
A character set in C programming language is a collection of characters that the C language recognizes and uses to represent data. It includes letters, symbols, digits, punctuation marks, and various special characters. It plays a crucial role in displaying text within a C program.
Q. How can you manipulate and print characters and their ASCII values in C?
You can manipulate and print individual character values and their ASCII values using simple C code. Here’s an example demonstrating how to read a character from the user, print its ASCII value, and convert an ASCII value back to a character:
Code:
#include
int main() {
char ch;
int asciiValue;
// Read a character from the user
printf("Enter a character: ");
scanf("%c", &ch);
// Print the ASCII value of the character
asciiValue = (int)ch;
printf("The ASCII value of '%c' is %d\n", ch, asciiValue);
// Convert an ASCII value to a character
printf("Enter an ASCII value (0-127): ");
scanf("%d", &asciiValue);
ch = (char)asciiValue;
printf("The character for ASCII value %d is '%c'\n", asciiValue, ch);
return 0;
}
I2luY2x1ZGUgPHN0ZGlvLmg+CgppbnQgbWFpbigpIHsKY2hhciBjaDsKaW50IGFzY2lpVmFsdWU7CgovLyBSZWFkIGEgY2hhcmFjdGVyIGZyb20gdGhlIHVzZXIKcHJpbnRmKCJFbnRlciBhIGNoYXJhY3RlcjogIik7CnNjYW5mKCIlYyIsICZjaCk7CgovLyBQcmludCB0aGUgQVNDSUkgdmFsdWUgb2YgdGhlIGNoYXJhY3Rlcgphc2NpaVZhbHVlID0gKGludCljaDsKcHJpbnRmKCJUaGUgQVNDSUkgdmFsdWUgb2YgJyVjJyBpcyAlZFxuIiwgY2gsIGFzY2lpVmFsdWUpOwoKLy8gQ29udmVydCBhbiBBU0NJSSB2YWx1ZSB0byBhIGNoYXJhY3RlcgpwcmludGYoIkVudGVyIGFuIEFTQ0lJIHZhbHVlICgwLTEyNyk6ICIpOwpzY2FuZigiJWQiLCAmYXNjaWlWYWx1ZSk7CmNoID0gKGNoYXIpYXNjaWlWYWx1ZTsKcHJpbnRmKCJUaGUgY2hhcmFjdGVyIGZvciBBU0NJSSB2YWx1ZSAlZCBpcyAnJWMnXG4iLCBhc2NpaVZhbHVlLCBjaCk7CgpyZXR1cm4gMDsKfQo=
Output:
Enter a character: f
The ASCII value of 'f' is 102
Enter an ASCII value (0-127): 123
The character for ASCII value 123 is '{'
This example helps illustrate basic character manipulation and ASCII value conversions in C.
Here are a few other interesting topics that you might be interested in:
- Compilation In C | A Step-By-Step Explanation & More (+Examples)
- Difference Between C And C++ Explained With Code Example
- Bitwise Operators In C Programming Explained With Code Examples
- Structure In C | Create, Access, Modify & More (+Code Examples)
- Dangling Pointer In C Language Demystified With Code Explanations
Login to continue reading
And access exclusive content, personalized recommendations, and career-boosting opportunities.
Don't have an account? Sign up
Never miss an
Update

Featured Opportunities
Top-Rated Practice by Students





Subscribe
to our newsletter



Comments
Add comment