
Asian Paints Alchemy 2026
C++ Programming Language
- A Brief Intro To C++ & Its History
- The Detailed History & Timeline Of C++ (With Infographic)
- Importance Of C++
- Versions Of C++ Language
- Structure Of A C++ Program
- Comparison With Other Popular Programming Languages
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Are Variables In C++?
- Declaration & Definition Of Variables In C++
- Variable Initialization In C++
- Rules & Regulations For Naming Variables In C++ Language
- Different Types Of Variables In C++
- Different Types of Variable Initialization In C++
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Are Primitive Data Types In C++?
- Derived Data Types In C++
- User-Defined Data Types In C++
- Abstract Data Types In C++
- Data Type Modifiers In C++
- Declaring Variables With Auto Keyword
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- Structure Of C++ Program: Components
- Segment 1: Documentation Section Of Structure Of C++ Program (With Example)
- Segment 2: Preprocessing & Namespace (Linking) Section Of CPP Program
- Segment 3: Definition Section In Structure of a C++ Program (With Examples)
- Segment 4: Main Function In Structure Of A C++ Program (With Example)
- Compilation & Execution Of C++ Programs | Step-by-Step Explanation
- Explaining Structure Of C++ Program With Suitable Example
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What is Typedef in C++?
- The Role & Applications of Typedef in C++
- Basic Syntax for typedef in C++
- How Does typedef Work in C++?
- How to Use Typedef in C++ With Examples? (Multiple Data Types)
- The Difference Between #define & Typedef in C++
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Are Strings In C++?
- Types Of Strings In C++
- How To Declare & Initialize C-Style Strings In C++ Programs?
- How To Declare & Initialize Strings In C++ Using String Keyword?
- List Of String Functions In C++
- Operations On Strings Using String Functions In C++
- Concatenation Of Strings In C++
- How To Convert Int To Strings In C++
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Is String Concatenation In C++?
- How To Concatenate Two Strings In C++ Using The ‘+' Operator?
- String Concatenation Using The strcat( ) Function
- Concatenation Of Two Strings In C++ Using Loops
- String Concatenation Using The append() Function
- C++ String Concatenation Using The Inheritance Of Class
- Concatenate Two Strings In C++ With The Friend and strcat() Functions
- Why Do We Need To Concatenate Two Strings?
- How To Reverse Concatenation Of Strings In C++?
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Is Find In String C++?
- What Is A Substring?
- How To Find A Substring In A String In C++?
- How To Find A Character In String C++?
- Find All Substrings From A Given String In C++
- Index Substring In String In C++ From A Specific Start To A Specific Length
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Are Pointers In C++?
- Pointer Declaration In C++
- How To Initialize And Use Pointers In C++?
- Different Types Of Pointers In C++
- References & Pointers In C++
- Arrays And Pointers In C++
- String Literals & Pointers In C++
- Pointers To Pointers In C++ (Double Pointers)
- Arithmetic Operation On Pointers In C++
- Advantages Of Pointers In C++
- Some Common Mistakes To Avoid With Pointers In Cpp
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- Understanding Pointers In C++
- What Is Pointer To Object In C++?
- Declaration And Use Of Object Pointers In C++
- Advantages Of Pointer To Object In C++
- Pointer To Objects In C++ With Arrow Operator
- An Array Of Objects Using Pointers In C++
- Base Class Pointer For Derived Class Object In C++
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Is 'This' Pointer In C++?
- Defining ‘this’ Pointer In C++
- Example Of 'this' Pointer In C++
- Describing The Constness Of 'this' Pointer In C++
- Important Uses Of 'this' Pointer In C++
- Method Chaining Using 'this' Pointer In C++
- C++ Programs To Show Application Of 'This' Pointer
- How To Delete The ‘this’ Pointer In C++?
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What is Reference?
- What is Pointer?
- Comparison Table Of C++ Pointer Vs. Reference
- Differences Between Reference And Pointer: A Detailed Explanation
- Why Are References Less Powerful Than Pointers?
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- How To Declare A 2D Array In C++?
- C++ Multi-Dimensional Arrays
- Ways To Initialize A 2D Array In C++
- Methods To Dynamically Allocate A 2D Array In C++
- Accessing/ Referencing Two-Dimensional Array Elements
- How To Initialize A Two-Dimensional Integer Array In C++?
- How To Initialize A Two-Dimensional Character Array?
- How To Enter Data In Two-Dimensional Array In C++?
- Conclusion
- Frequently Asked Questions
- What Are Arrays Of Strings In C++?
- Different Ways To Create String Arrays In C++
- How To Access The Elements Of A String Array In C++?
- How To Convert Char Array To String?
- Conclusion
- Frequently Asked Questions
- What is Memory Allocation in C++ & Why Do We Need It?
- How Does Dynamic Memory Allocation Work?
- The new Operator in C++
- The delete Operator in C++
- Dynamic Memory Allocation in C++ | Arrays
- Did You Know: Companies That Ask About Dynamic Memory Allocation
- Dynamic Memory Allocation in C++ | Objects
- Deallocation of Dynamic Memory in C++
- malloc(), calloc(), and free() Functions in C/C++
- Applications of Dynamic Memory Allocation in C++
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Is A Substring In C++ (Substr C++)?
- Example for substr() in C++ | Finding Substring Using Positive and Negative Indices
- Understanding substr() Basics with Examples
- Use Cases/ Examples of substr() in C++
- How to Get a Substring Before a Character Using substr() in C++?
- Use substr() in C++ to Print all Substrings of a Given String
- Print Sum of all Substrings of a String Representing a Number
- Minimum Value of all Substrings of a String Representing a Number
- Maximum Value of all Substrings of a String Representing a Number
- Points To Remember For Substr In C++
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Is Operator In C++?
- Types Of Operators In C++ With Examples
- What Are Arithmetic Operators In C++?
- What Are Assignment Operators In C++?
- What Are Relational Operators In C++?
- What Are Logical Operators In C++?
- What Are Bitwise Operators In C++?
- What Is Ternary/ Conditional Operator In C++?
- Miscellaneous Operators In C++
- Precedence & Associativity Of Operators In C++
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Is The New Operator In C++?
- Example To Understand New Operator In C++
- The Grammar Elements Of The New Operator In C++
- Storage Space Allocation
- How Does The C++ New Operator Works?
- What Happens When Enough Memory In The Program Is Not Available?
- Initializing Objects Allocated With New Operator In C++
- Lifetime Of Objects Allocated With The New Operator In C++
- What Is The Delete Operator In C++?
- Difference Between New And Delete Operator In C++
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- Types Of Overloading In C++
- What Is Operator Overloading In C++?
- How To Overload An Operator In C++?
- Overloadable & Non-overloadable Operators In C++
- Unary Operator Overloading In C++
- Binary Operator Overloading In C++
- Special Operator Overloading In C++
- Rules For Operator Overloading In C++
- Advantages And Disadvantages Of Operator Overloading In C++
- Function Overloading In C++
- What Is the Difference Between Operator Functions and Normal Functions?
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Are Operators In C++?
- Introduction To Logical Operators In C++
- Types Of Logical Operators In C++ With Example Program
- Logical AND (&&) Operator In C++
- Logical NOT(!) Operator In C++
- Logical Operator Precedence And Associativity In C++
- Relation Between Conditional Statements And Logical Operators In C++
- C++ Relational Operators
- Conclusion
- Frequently Asked Important Interview Questions:
- Test Your Skills: Quiz Time
- Different Type Of C++ Bitwise Operators
- C++ Bitwise AND Operator
- C++ Bitwise OR Operator
- C++ Bitwise XOR Operator
- Bitwise Left Shift Operator In C++
- Bitwise Right Shift Operator In C++
- Bitwise NOT Operator
- What Is The Meaning Of Set Bit In C++?
- What Does Clear Bit Mean?
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- Types of Comments in C++
- Single Line Comment In C++
- Multi-Line Comment In C++
- How Do Compilers Process Comments In C++?
- C- Style Comments In C++
- How To Use Comment In C++ For Debugging Purposes?
- When To Use Comments While Writing Codes?
- Why Do We Use Comments In Codes?
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Are Storage Classes In Cpp?
- What Is The Scope Of Variables?
- What Are Lifetime And Visibility Of Variables In C++?
- Types of Storage Classes in C++
- Automatic Storage Class In C++
- Register Storage Class In C++
- Static Storage Class In C++
- External Storage Class In C++
- Mutable Storage Class In C++
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- Decision Making Statements In C++
- Types Of Conditional Statements In C++
- If-Else Statement In C++
- If-Else-If Ladder Statement In C++
- Nested If Statements In C++
- Alternatives To Conditional If-Else In C++
- Switch Case Statement In C++
- Jump Statements & If-Else In C++
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Is A Switch Statement/ Switch Case In C++?
- Rules Of Switch Case In C++
- How Does Switch Case In C++ Work?
- The break Keyword In Switch Case C++
- The default Keyword In C++ Switch Case
- Switch Case Without Break And Default
- Advantages & Disadvantages of C++ Switch Case
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Is A For Loop In C++?
- Syntax Of For Loop In C++
- How Does A For Loop In C++ Work?
- Examples Of For Loop Program In C++
- Ranged Based For Loop In C++
- Nested For Loop In C++
- Infinite For Loop In C++
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Is A While Loop In C++?
- Parts Of The While Loop In C++
- C++ While Loop Program Example
- How Does A While Loop In C++ Work?
- What Is Pre-checking Process Or Entry-controlled Loop?
- When Are While Loops In C++ Useful?
- Example C++ While Loop Program
- What Are Nested While Loops In C++?
- Infinite While Loop In C++
- Alternatives To While Loop In C++
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Are Loops & Its Types In C++?
- What Is A Do-While Loop In C++?
- Do-While Loop Example In C++ To Print Numbers
- How Does A Do-While Loop In C++ Work?
- Various Components Of The Do-While Loop In C++
- Example 2: Adding User-Input Positive Numbers With Do-While Loop
- C++ Nested Do-While Loop
- C++ Infinitive Do-while Loop
- What is the Difference Between While Loop and Do While Loop in C++?
- When To Use A Do-While Loop?
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What are 2D Vectors in C++?
- How to Declare 2D Vectors in C++
- How to Initialize a 2D Vector in C++?
- Creating a 2D Vector in C++ with User Input for Column & Row Size
- Methods for Traversing 2D Vectors in C++
- Interview Spotlight: 2D Vectors in FAANG Interviews
- Printing 2D Vector in C++ Using Nested Loops
- Example C++ Programs for Creating 2D Vectors
- How to Access & Modify 2D Vector Elements in C++?
- Adding Elements to 2D Vector Using push_back() Function
- Removing Elements from Vector in C++ Using pop_back() Function
- Did You Know? Real-World Outage: Crash Cause Linked to 2D Vector Usage
- Advantages of 2D Vectors Over Traditional Arrays
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- How To Print A Vector In C++ By Overloading Left Shift (<<) Operator?
- How To Print Vector In C++ Using Range-Based For-Loop?
- Print Vector In C++ With Comma Separator
- Printing Vector In C++ Using Indices (Square Brackets/ Double Brackets & at() Function)
- How To Print A Vector In C++ Using std::copy?
- How To Print A Vector In C++ Using for_each() Function?
- Printing C++ Vector Using The Lambda Function
- How To Print Vector In C++ Using Iterators?
- Conclusion
- Frequently Asked Questions
- Definition Of C++ Find In Vector
- Using The std::find() Function
- How Does find() In Vector C++ Function Work?
- Finding An Element By Custom Comparator Using std::find_if() Function
- Use std::find_if() With std::distance()
- Element Find In Vector C++ Using For Loop
- Using The find_if_not Function
- Find Elements With The Linear Search Approach
- Conclusion
- Frequently Asked Questions
- What Is Sort() Function In C++?
- Sort() Function In C++ From Standard Template Library
- Exceptions Of Sort() Function/ Algorithm In C++
- The Stable Sort() Function In C++
- Partial Sort() Function In C++
- Sorting In Ascending Order With Sort() Function In C++
- Sorting In Descending Order With Sort Function In C++
- Sorting In Desired Order With Custom Comparator Function & Sort Function In C++
- Sorting Elements In Desired Order Using Lambda Expression & Sort Function In C++
- Types of Sorting Algorithms In C++
- Advanced Sorting Algorithms In C++
- How Does the Sort() Function Algorithm Work In C++?
- Conclusion
- Frequently Asked Questions
- What Is Function Overloading In C++?
- Ways Of Function Overloading In C++
- Function Overloading In C++ Using Different Types Of Parameters
- Function Overloading In C++ With Different Number Of Parameters
- Function Overloading In C++ Using Different Sequence Of Parameters
- How Does Function Overloading In C++ Work?
- Rules Of Function Overloading In C++
- Why Is Function Overloading Used?
- Types Of Function Overloading Based On Time Of Resolution
- Causes Of Function Overloading In C++
- Ambiguity & Function Overloading In C++
- Advantages Of Function Overloading In C++
- Disadvantages Of Function Overloading In C++
- Operator Overloading In C++
- Function Overriding In C++
- Difference Between Function Overriding & Function Overloading In C++
- Conclusion
- Frequently Asked Questions
- What Is An Inline Function In C++?
- How To Define The Inline Function In C++?
- How Does Inline Function In C++ Work?
- The Need For An Inline Function In C++
- Can The Compiler Ignore/ Reject Inline Function In C++ Programs?
- Normal Function Vs. Inline Function In C++
- Classes & Inline Function In C++
- Understanding Inline, __inline, And __forceinline Functions In C++
- When To Use An Inline Function In C++?
- Advantages Of Inline Function In C++
- Disadvantages Of Inline Function In C++
- Why Not Use Macros Instead Of An Inline Function In C++?
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Is Static Data Member In C++?
- How To Declare Static Data Members In C++?
- How To Initialize/ Define Static Data Member In C++?
- Ways To Access A Static Data Member In C++
- What Are Static Member Functions In C++?
- Example Of Member Function & Static Data Member In C++
- Practical Applications Of Static Data Member In C++
- Conclusion
- Frequently Asked Questions
- What Is A Constant In C++?
- Ways To Define Constant In C++
- What Are Literals In C++?
- Pointer To A Constant In C++
- Constant Function Arguments In C++
- Constant Member Function Of Class In C++
- Constant Data Members In C++
- Object Constant In C++
- Conclusion
- Frequently Asked Questions(FAQ)
- What is the Friend Function in C++?
- Declaration of Friend Function in C++ with Example
- Characteristics of Friend Function in C++
- Types/ Ways to Implement Friend Function in C++
- Global Friend Function in C++ (Global Function as Friend Function )
- Member Function of Another Class as a Friend Function in C++
- Function Overloading Using Friend Function in C++
- Advantages & Disadvantages of Friend Function in C++
- Interview Spotlight: Friend Functions in Cognizant Interview
- What is a C++ Friend Class?
- A Function Friendly to Multiple Classes
- C++ Friend Class vs. Friend Function in C++
- Some Important Points About Friend Functions and Classes in C++
- Conclusion
- Frequently Asked Questions
- What Is Function Overriding In C++?
- The Working Mechanism Of Function Overriding In C++
- Real-Life Example Of Function Overriding In C++
- Accessing Overriding Function In C++
- Accessing Overridden Function In C++
- Function Call Binding With Class Objects | Function Overriding In C++
- Function Call Binding With Base Class Pointers | Function Overriding In C++
- Advantages Of Function Overriding In C++
- Variations In Function Overriding In C++
- Function Overloading In C++
- Function Overloading Vs Function Overriding In C++
- Conclusion
- Frequently Asked Questions
- Errors In C++
- What Is Exception Handling In C++?
- Exception Handling In C++ Program Example
- C++ Exception Handling: Basic Keywords
- The Need For C++ Exception Handling
- C++ Standard Exceptions
- C++ Exception Classes
- User-Defined Exceptions In C++
- Advantages & Disadvantages Of C++ Exception Handling
- Conclusion
- Frequently Asked Questions
- What Are Templates In C++ & How Do They Work?
- Types Of Templates In C++
- What Are Function Templates In C++?
- C++ Template Functions With Multiple Parameters
- C++ Template Function Overloading
- What Are Class Templates In C++?
- Defining A Class Member Outside C++ Template Class
- C++ Template Class With Multiple Parameters
- What Is C++ Template Specialization?
- How To Specify Default Arguments For Templates In C++?
- Advantages Of C++ Templates
- Disadvantages Of C++ Templates
- Difference Between Function Overloading And Templates In C++
- Conclusion
- Frequently Asked Questions
- Structure
- Structure Declaration
- Initialization of Structure
- Copying and Comparing Structures
- Array of Structures
- Nested Structures
- Pointer to a Structure
- Structure as Function Argument
- Self Referential Structures
- Class
- Object Declaration
- Accessing Class Members
- Similarities between Structure and Class
- Which One Should You Choose?
- Key Difference Between a Structure and Class
- Summing Up
- Test Your Skills: Quiz Time
- What Is A Class And Object In C++?
- What Is An Object In C++?
- How To Create A Class & Object In C++? With Example
- Interview Spotlight: Classes & Objects In Adobe & Pixar Interviews
- Access Modifiers & Class/ Object In C++
- Member Functions Of A Class In C++
- How To Access Data Members And Member Functions?
- Significance Of Class & Object In C++
- Did You Know? The Concept of Classes & Object Powers Major Apps
- What Are Constructors In C++ & Its Types?
- What Is A Destructor Of Class In C++?
- An Array Of Objects In C++
- Object In C++ As Function Arguments
- The this (->) Pointer & Classes In C++
- The Need For Semicolons At The End Of A Class In C++
- Conclusion
- Frequently Asked Questions
- What Are Static Members In C++?
- Static Member Functions in C++
- Ways To Call Static Member Function In C++
- Properties Of Static Member Function In C++
- Need Of Static Member Functions In C++
- Regular Member Function Vs. Static Member Function In C++
- Limitations Of Static Member Functions In C++
- Conclusion
- Frequently Asked Questions
- What Is Constructor In C++?
- Characteristics Of A Constructor In C++
- Types Of Constructors In C++
- Default Constructor In C++
- Parameterized Constructor In C++
- Copy Constructor In C++
- Dynamic Constructor In C++
- Benefits Of Using Constructor In C++
- How Does Constructor In C++ Differ From Normal Member Function?
- Constructor Overloading In C++
- Constructor For Array Of Objects In C++
- Constructor In C++ With Default Arguments
- Initializer List For Constructor In C++
- Dynamic Initialization Using Constructor In C++
- Conclusion
- Frequently Asked Questions
- What Is A Constructor In C++?
- What Is Constructor Overloading In C++?
- Dеclaration Of Constructor Ovеrloading In C++
- Condition For Constructor Overloading In C++
- How Constructor Ovеrloading In C++ Works?
- Examples Of Constructor Overloading In C++
- Lеgal & Illеgal Constructor Ovеrloading In C++
- Types Of Constructors In C++
- Characteristics Of Constructors In C++
- Advantage Of Constructor Overloading In C++
- Disadvantage Of Constructor Overloading In C++
- Conclusion
- Frеquеntly Askеd Quеstions
- What Is A Destructor In C++?
- Rules For Defining A Destructor In C++
- When Is A Destructor in C++ Called?
- Order Of Destruction In C++
- Default Destructor & User-Defined Destructor In C++
- Virtual Destructor In C++
- Pure Virtual Destructor In C++
- Key Properties Of Destructor In C++ You Must Know
- Explicit Destructor Calls In C++
- Destructor Overloading In C++
- Difference Between Normal Member Function & Destructor In C++
- Important Uses Of Destructor In C++
- Conclusion
- Frequently Asked Questions
- What Is A Constructor In C++?
- What Is A Destructor In C++?
- Difference Between Constructor And Destructor In C++
- Constructor In C++ | A Brief Explanation
- Destructor In C++ | A Brief Explanation
- Difference Between Constructor And Destructor In C++ Explained
- Order Of Calling Constructor And Destructor In C++ Classes
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Is Type Conversion In C++?
- What Is Type Casting In C++?
- Types Of Type Conversion In C++
- Implicit Type Conversion (Coercion) In C++
- Explicit Type Conversion (Casting) In C++
- Advantages Of Type Conversion In C++
- Disadvantages Of Type Conversion In C++
- Difference Between Type Casting & Type Conversion In C++
- Application Of Type Casting In C++
- Conclusion
- Frequently Asked Questions
- What Is A Copy Constructor In C++?
- Characteristics Of Copy Constructors In C++
- Types Of Copy Constructors In C++
- When Do We Call The Copy Constructor In C++?
- When Is A User-Defined Copy Constructor Needed In C++?
- Types Of Constructor Copies In C++
- Can We Make The Copy Constructor In C++ Private?
- Assignment Operator Vs Copy Constructor In C++
- Example Of Class Where A Copy Constructor Is Essential
- Uses Of Copy Constructors In C++
- Conclusion
- Frequently Asked Questions
- Why Do You Need Object-Oriented Programming (OOP) In C++?
- OOPs Concepts In C++ With Examples
- The Class OOPs Concept In C++
- The Object OOPs Concept In C++
- The Inheritance OOPs Concept In C++
- Polymorphism OOPs Concept In C++
- Abstraction OOPs Concept In C++
- Encapsulation OOPs Concept In C++
- Other Features Of OOPs In C++
- Benefits Of OOP In C++ Over Procedural-Oriented Programming
- Disadvantages Of OOPS Concept In C++
- Why Is C++ A Partial OOP Language?
- Conclusion
- Frequently Asked Questions
- Introduction To Abstraction In C++
- Types Of Abstraction In C++
- What Is Data Abstraction In C++?
- Understanding Data Abstraction In C++ Using Real Life Example
- Ways Of Achieving Data Abstraction In C++
- What Is An Abstract Class?
- Advantages Of Data Abstraction In C++
- Use Cases Of Data Abstraction In C++
- Encapsulation Vs. Abstraction In C++
- Conclusion
- Frequently Asked Questions
- What Is Encapsulation In C++?
- How Does Encapsulation Work In C++?
- Types Of Encapsulation In C++
- Why Do We Need Encapsulation In C++?
- Implementation Of Encapsulation In C++
- Access Specifiers & Encapsulation In C++
- Role Of Access Specifiers In Encapsulation In C++
- Member Functions & Encapsulation In C++
- Data Hiding & Encapsulation In C++
- Features Of Encapsulation In C++
- Advantages & Disadvantages Of Encapsulation In C++
- Difference Between Abstraction and Encapsulation In C++
- Conclusion
- Frequently Asked Questions
- What Is Inheritance In C++?
- What Are Child And Parent Classes?
- Syntax And Structure Of Inheritance In C++
- Implementing Inheritance In C++
- Importance Of Inheritance In C++
- Types Of Inheritance In C++
- Visibility Modes Of Inheritance In C++
- Access Modifiers & Inheritance In C++
- How To Make A Private Member Inheritable?
- Member Function Overriding In Inheritance In C++
- The Diamond Problem | Inheritance In C++ & Ambiguity
- Ways To Avoid Ambiguity Inheritance In C++
- Why & When To Use Inheritance In C++?
- Advantages Of Inheritance In C++
- The Disadvantages Of Inheritance In C++
- Conclusion
- Frequently Asked Questions
- What Is Hybrid Inheritance In C++?
- Importance Of Hybrid Inheritance In Object Oriented Programming
- Example Of Hybrid Inheritance In C++: Using Single and Multiple Inheritance
- Example Of Hybrid Inheritance In C++: Using Multilevel and Hierarchical Inheritance
- Real-World Applications Of Hybrid Inheritance In C++
- Conclusion
- Frequently Asked Questions
- What Is Multiple Inheritance In C++?
- Examples Of Multiple Inheritance In C++
- Ambiguity Problem In Multiple Inheritance In C++
- Ambiguity Resolution In Multiple Inheritance In C++
- The Diamond Problem In Multiple Inheritance In C++
- Visibility Modes In Multiple Inheritance In C++
- Advantages & Disadvantages Of Multiple Inheritance In C++
- Multiple Inheritance Vs. Multilevel Inheritance In C++
- Conclusion
- Frequently Asked Questions
- What Is Multilevel Inheritance In C++?
- Block Diagram For Multilevel Inheritance In C++
- Multilevel Inheritance In C++ Example
- Constructor & Multilevel Inheritance In C++
- Use Cases Of Multilevel Inheritance In C++
- Multiple Vs Multilevel Inheritance In C++
- Advantages & Disadvantages Of Multilevel Inheritance In C++
- Conclusion
- Frequently Asked Questions
- What Is Hierarchical Inheritance In C++?
- Example 1: Hierarchical Inheritance In C++
- Example 2: Hierarchical Inheritance In C++
- Impact of Visibility Modes In Hierarchical Inheritance In C++
- Advantages And Disadvantages Of Hierarchical Inheritance In C++
- Use Cases Of Hierarchical Inheritance In C++
- Conclusion
- Frequently Asked Questions
- What Are Access Specifiers In C++?
- Types Of Access Specifiers In C++
- Public Access Specifiers In C++
- Private Access Specifier In C++
- Protected Access Specifier In C++
- The Need For Access Specifiers In C++
- Combined Example For All Access Specifiers In C++
- Best Practices For Using Access Specifiers In C++
- Why Can't Private Members Be Accessed From Outside A Class?
- Conclusion
- Frequently Asked Questions
- What Is The Diamond Problem In C++?
- Example Of The Diamond Problem In C++
- Resolution Of The Diamond Problem In C++
- Virtual Inheritance To Resolve Diamond Problem In C++
- Scope Resolution Operator To Resolve Diamond Problem In C++
- Conclusion
- Frequently Asked Questions
Data Abstraction In C++ | How-To, Types, Uses & More (+Examples)
Data abstraction refers to hiding technical (or functional) details of code from the outside world/ end-user. It is achieved by using access specifiers or header files to separate the interface from implementation.

Data abstraction is a fundamental concept in computer science and programming, especially in the context of object-oriented programming languages like C++. It plays a crucial role in designing and developing complex software systems by allowing programmers to hide the implementation details of a data type or a class while exposing only the essential features and functionalities. In this article, we will explore what data abstraction in C++ programming is, its advantages and use cases, and how it is implemented.
Introduction To Abstraction In C++
Abstraction in C++ language is a fundamental concept in reference to object-oriented programming (OOP). It involves simplifying complex systems by breaking them down into smaller, more manageable parts while hiding unnecessary details. It is one of the four key principles of OOP, along with encapsulation, inheritance, and polymorphism.
Abstraction allows you to create abstract classes and interfaces that define a common set of methods and properties that subclasses must implement. These abstract classes and interfaces provide a blueprint for other classes to follow, ensuring consistency in the way objects are constructed and used in a program.
Types Of Abstraction In C++

In C++, there are two primary types of abstraction, namely, control abstraction and data abstraction. These concepts are an integral part of programming and writing efficient code.
What Is Control Abstraction In C++? With Example
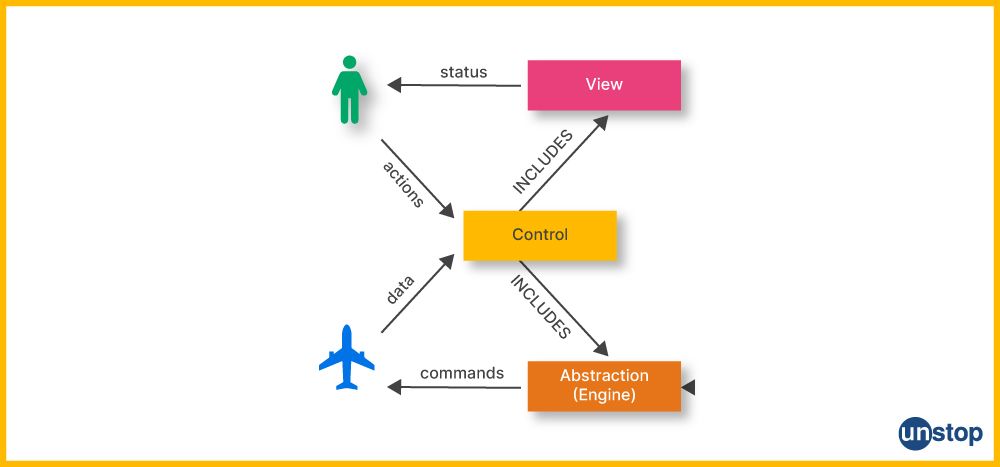
Control abstraction refers to the process of hiding the details of control flow (like loops, conditional statements, and recursion) or the logic behind an algorithm. It allows you to encapsulate a sequence of operations into a higher-level function or method, effectively abstracting away the specific steps required to achieve a task.
Common examples of control abstraction in C++ include functions and procedures. When you call a function, you're using control abstraction to perform a specific operation without needing to know the internal implementation details.
Code Example:
#include
// Function to calculate the factorial of a number
int factorial(int n) {
if (n <= 1) {
return 1;
} else {
return n * factorial(n - 1);}
}
int main() {
int num = 5; // Number for which we want to calculate the factorial
// Using control abstraction to calculate factorial
int result = factorial(num);
std::cout << "Factorial of " << num << " is " << result << std::endl;
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgoKLy8gRnVuY3Rpb24gdG8gY2FsY3VsYXRlIHRoZSBmYWN0b3JpYWwgb2YgYSBudW1iZXIKaW50IGZhY3RvcmlhbChpbnQgbikgewppZiAobiA8PSAxKSB7CnJldHVybiAxOwp9IGVsc2UgewpyZXR1cm4gbiAqIGZhY3RvcmlhbChuIC0gMSk7fQp9CgppbnQgbWFpbigpIHsKaW50IG51bSA9IDU7IC8vIE51bWJlciBmb3Igd2hpY2ggd2Ugd2FudCB0byBjYWxjdWxhdGUgdGhlIGZhY3RvcmlhbAoKLy8gVXNpbmcgY29udHJvbCBhYnN0cmFjdGlvbiB0byBjYWxjdWxhdGUgZmFjdG9yaWFsCmludCByZXN1bHQgPSBmYWN0b3JpYWwobnVtKTsKCnN0ZDo6Y291dCA8PCAiRmFjdG9yaWFsIG9mICIgPDwgbnVtIDw8ICIgaXMgIiA8PCByZXN1bHQgPDwgc3RkOjplbmRsOwpyZXR1cm4gMDsKfQ==
Output:
Factorial of 5 is 120
Explanation:
In the above code example-
- We define a function factorial() to calculate the factorial of an integer n using recursion
- Inside the function, we use an if-else statement:
- If the base condition is true i.e n is less than or equal to 1, it returns 1(base case).
- Otherwise, if the base condition is not true it returns n multiplied by the factorial of n - 1(recursive case).
- In the main() function, we set num to 5 and call the factorial() function with this value( demonstrating control abstraction).
- We then print the result to the console, showing the factorial of 5.
When we run the above program, it calculates the factorial of 5 (5!) using the factorial function and displays the result as 'Factorial of 5 is 120' on the console.
What Is Data Abstraction In C++?

Data abstraction in C++ focuses on hiding the internal representation of data while exposing only the essential properties and operations. It allows you to define custom data types (classes) that encapsulate data and provide controlled access through member functions, effectively separating the 'what' (the interface) from the 'how' (the implementation).
We use classes and access specifiers (like public, private, and protected) to implement data abstraction in C++ programs. This means that the private data members store the data, and public member functions provide controlled access and manipulation of that data. Let's take a look at an example of the same.
Code Example:
#include
class BankAccount {
private:
double balance; // Private data member
public:
// Constructor to initialize balance
BankAccount(double initialBalance) {
balance = initialBalance;}
// Function to deposit money
void deposit(double amount) {
balance += amount;}
// Function to withdraw money
bool withdraw(double amount) {
if (amount <= balance) {
balance -= amount;
return true;
} else {
std::cout << "Insufficient funds!" << std::endl;
return false;}
}
// Function to check the balance
double getBalance() {
return balance;}
};
int main() {
// Creating a BankAccount object
BankAccount account(1000.0);
// Using data abstraction to deposit and withdraw money
account.deposit(500.0);
account.withdraw(200.0);
// Checking the balance
double currentBalance = account.getBalance();
std::cout << "Current Balance: $" << currentBalance << std::endl;
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgoKY2xhc3MgQmFua0FjY291bnQgewpwcml2YXRlOgpkb3VibGUgYmFsYW5jZTsgLy8gUHJpdmF0ZSBkYXRhIG1lbWJlcgoKcHVibGljOgovLyBDb25zdHJ1Y3RvciB0byBpbml0aWFsaXplIGJhbGFuY2UKQmFua0FjY291bnQoZG91YmxlIGluaXRpYWxCYWxhbmNlKSB7CmJhbGFuY2UgPSBpbml0aWFsQmFsYW5jZTt9CgovLyBGdW5jdGlvbiB0byBkZXBvc2l0IG1vbmV5CnZvaWQgZGVwb3NpdChkb3VibGUgYW1vdW50KSB7CmJhbGFuY2UgKz0gYW1vdW50O30KCi8vIEZ1bmN0aW9uIHRvIHdpdGhkcmF3IG1vbmV5CmJvb2wgd2l0aGRyYXcoZG91YmxlIGFtb3VudCkgewppZiAoYW1vdW50IDw9IGJhbGFuY2UpIHsKYmFsYW5jZSAtPSBhbW91bnQ7CnJldHVybiB0cnVlOwp9IGVsc2UgewpzdGQ6OmNvdXQgPDwgIkluc3VmZmljaWVudCBmdW5kcyEiIDw8IHN0ZDo6ZW5kbDsKcmV0dXJuIGZhbHNlO30KfQoKLy8gRnVuY3Rpb24gdG8gY2hlY2sgdGhlIGJhbGFuY2UKZG91YmxlIGdldEJhbGFuY2UoKSB7CnJldHVybiBiYWxhbmNlO30KfTsKCmludCBtYWluKCkgewovLyBDcmVhdGluZyBhIEJhbmtBY2NvdW50IG9iamVjdApCYW5rQWNjb3VudCBhY2NvdW50KDEwMDAuMCk7CgovLyBVc2luZyBkYXRhIGFic3RyYWN0aW9uIHRvIGRlcG9zaXQgYW5kIHdpdGhkcmF3IG1vbmV5CmFjY291bnQuZGVwb3NpdCg1MDAuMCk7CmFjY291bnQud2l0aGRyYXcoMjAwLjApOwoKLy8gQ2hlY2tpbmcgdGhlIGJhbGFuY2UKZG91YmxlIGN1cnJlbnRCYWxhbmNlID0gYWNjb3VudC5nZXRCYWxhbmNlKCk7CnN0ZDo6Y291dCA8PCAiQ3VycmVudCBCYWxhbmNlOiAkIiA8PCBjdXJyZW50QmFsYW5jZSA8PCBzdGQ6OmVuZGw7CgpyZXR1cm4gMDsKfQ==
Output:
Current Balance: $1300
Explanation:
In the above C++ program-
-
We define a class named BankAccount to represent a bank account. It encapsulates the data and operations related to a bank account, demonstrating the concept of data abstraction. Inside the class:
- There is a private data member balance of double data type to store the account balance.
- It also has a constructor that initializes the balance data member when a BankAccount object is created.
- We then define a void deposit() function that allows us to add money to the account's balance using the compound assignment operator.
- Next, we define a withdraw() function, which represents the act of withdrawing money. It contains an if-else statement that checks if the requested amount is less than or equal to the current balance.
- If there is enough balance, the if-block deducts the amount, updates the balance, and returns true.
- If there are insufficient funds, it returns false and prints the string message- "Insufficient funds!".
- Lastly, we define the getBalance() function, which retrieves and returns the current balance.
-
After that, inside the main() function, we create an object of the BankAccount class called account and initialize it with an initial balance of $1000.0. This action triggers the constructor, which sets the balance to $1000.0.
- The concept of data abstraction in C++ is demonstrated through the use of deposit() and withdraw() methods of the account object to interact with the bank account data.
- First, we call the deposit() function on the object account, using the dot operator. Here, we deposit an amount of $500.0 into the account increasing the balance to $1500.0.
- Similarly, we call the withdraw() function on the object and attempt to withdraw $200.0 from the account. Since there is sufficient balance, the withdrawal is successful, and the balance is reduced by $200.0, leaving us with $1300.0.
- Then, we call the getBalance() method on the account object to retrieve the current balance and store it in the variable currentBalance.
- Finally, we print the current balance using the std::cout statement, and the program terminates with a return 0 statement.
When the program is executed, it creates a bank account object, performs deposit and withdrawal operations, and displays the updated balance, which, in this case, is $1300.
Understanding Data Abstraction In C++ Using Real Life Example
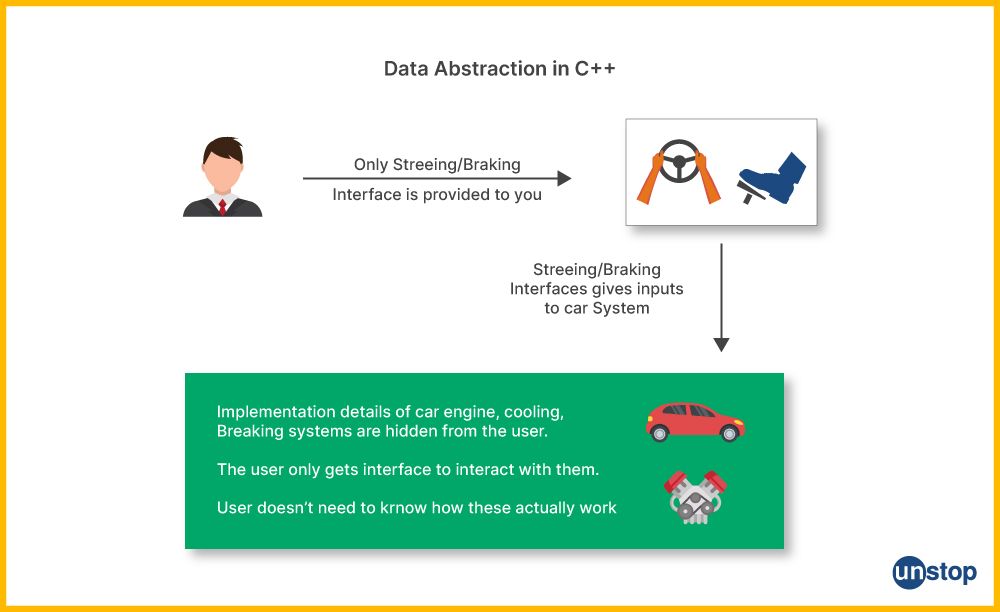
As mentioned before, data abstraction in C++ is the process of simplifying complex systems by breaking them down into smaller, more manageable parts and hiding unnecessary details. In programming, data abstraction refers to the practice of representing the essential characteristics of an object while concealing unnecessary or irrelevant details.
This not only helps in reducing complexity but also enhances the maintainability and scalability of software systems. Imagine a television remote control as an analogy for data abstraction in C++ programming.
- When you use a remote control to operate your TV, you don't need to know how intricate electronic components inside the TV work or how the remote control's buttons translate to specific commands.
- Instead, you interact with a simplified interface, i.e., the buttons on the remote control, to achieve desired actions like changing channels or adjusting the volume.
In this analogy:
- The TV remote control represents the abstraction, offering a simplified way to interact with the TV.
- The TV's internal circuitry and mechanisms represent the underlying complexity, which is hidden from the user.
Below is an example of data abstraction in C++ for the television remote control analogy given above.
Code Example:
#include
// Abstract class representing the TV remote control
class RemoteControl {
public:
// Abstract methods for actions like changing channels and adjusting volume
virtual void changeChannel(int channel) = 0;
virtual void adjustVolume(int volume) = 0;
};
// Concrete implementation of a TV remote control
class ConcreteRemoteControl : public RemoteControl {
public:
// Constructor
ConcreteRemoteControl() {
// Initialize some default values
currentChannel = 1;
currentVolume = 50;}
// Implementation of changing the channel
void changeChannel(int channel) override {
currentChannel = channel;
std::cout << "Changed to channel " << channel << std::endl;}
// Implementation of adjusting the volume
void adjustVolume(int volume) override {
currentVolume = volume;
std::cout << "Adjusted volume to " << volume << std::endl;}
private:
int currentChannel;
int currentVolume;
};
int main() {
// Create a TV remote control object
ConcreteRemoteControl remote;
// Use the remote control to interact with the TV
remote.changeChannel(5);
remote.adjustVolume(60);
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgoKLy8gQWJzdHJhY3QgY2xhc3MgcmVwcmVzZW50aW5nIHRoZSBUViByZW1vdGUgY29udHJvbApjbGFzcyBSZW1vdGVDb250cm9sIHsKcHVibGljOgovLyBBYnN0cmFjdCBtZXRob2RzIGZvciBhY3Rpb25zIGxpa2UgY2hhbmdpbmcgY2hhbm5lbHMgYW5kIGFkanVzdGluZyB2b2x1bWUKdmlydHVhbCB2b2lkIGNoYW5nZUNoYW5uZWwoaW50IGNoYW5uZWwpID0gMDsKdmlydHVhbCB2b2lkIGFkanVzdFZvbHVtZShpbnQgdm9sdW1lKSA9IDA7Cn07CgovLyBDb25jcmV0ZSBpbXBsZW1lbnRhdGlvbiBvZiBhIFRWIHJlbW90ZSBjb250cm9sCmNsYXNzIENvbmNyZXRlUmVtb3RlQ29udHJvbCA6IHB1YmxpYyBSZW1vdGVDb250cm9sIHsKcHVibGljOgovLyBDb25zdHJ1Y3RvcgpDb25jcmV0ZVJlbW90ZUNvbnRyb2woKSB7Ci8vIEluaXRpYWxpemUgc29tZSBkZWZhdWx0IHZhbHVlcwpjdXJyZW50Q2hhbm5lbCA9IDE7CmN1cnJlbnRWb2x1bWUgPSA1MDt9CgovLyBJbXBsZW1lbnRhdGlvbiBvZiBjaGFuZ2luZyB0aGUgY2hhbm5lbAp2b2lkIGNoYW5nZUNoYW5uZWwoaW50IGNoYW5uZWwpIG92ZXJyaWRlIHsKY3VycmVudENoYW5uZWwgPSBjaGFubmVsOwpzdGQ6OmNvdXQgPDwgIkNoYW5nZWQgdG8gY2hhbm5lbCAiIDw8IGNoYW5uZWwgPDwgc3RkOjplbmRsO30KCi8vIEltcGxlbWVudGF0aW9uIG9mIGFkanVzdGluZyB0aGUgdm9sdW1lCnZvaWQgYWRqdXN0Vm9sdW1lKGludCB2b2x1bWUpIG92ZXJyaWRlIHsKY3VycmVudFZvbHVtZSA9IHZvbHVtZTsKc3RkOjpjb3V0IDw8ICJBZGp1c3RlZCB2b2x1bWUgdG8gIiA8PCB2b2x1bWUgPDwgc3RkOjplbmRsO30KCnByaXZhdGU6CmludCBjdXJyZW50Q2hhbm5lbDsKaW50IGN1cnJlbnRWb2x1bWU7Cn07CgppbnQgbWFpbigpIHsKLy8gQ3JlYXRlIGEgVFYgcmVtb3RlIGNvbnRyb2wgb2JqZWN0CkNvbmNyZXRlUmVtb3RlQ29udHJvbCByZW1vdGU7CgovLyBVc2UgdGhlIHJlbW90ZSBjb250cm9sIHRvIGludGVyYWN0IHdpdGggdGhlIFRWCnJlbW90ZS5jaGFuZ2VDaGFubmVsKDUpOwpyZW1vdGUuYWRqdXN0Vm9sdW1lKDYwKTsKCnJldHVybiAwOwp9
Output:
Changed to channel 5
Adjusted volume to 60
Explanation:
The above code example is structured around the concept of a TV remote control, with an abstract base class and a concrete derived class-
- We define an abstract class, RemoteControl, as the base class representing the TV remote control. Inside the class-
- We declare two pure virtual functions changeChannel() and adjustVolume(), which represent the actions the remote control can perform.
- Being pure virtual functions (indicated by = 0), these methods do not have implementations in the RemoteControl class itself, making it an abstract class that cannot be instantiated directly.
- Next, we create a concrete implementation (derived class) of the TV remote control called ConcreteRemoteControl. This derived class contains a constructor for creating an object of the class.
- It has two private integer data members, currentChannel and currentVolume which are initialized with default values 1 and 50, respectively.
- It also provides actual implementations for changing channels and adjusting the volume. Both implementations use std::cout to print a message to the console.
- In the main() function, we create an instance of ConcreteRemoteControl named remote and use it to change the channel and adjust the volume.
- We call the changeChannel() method on the remote object to change the channel to 5.
- Similarly, we call the adjustVolume() method to adjust the volume to 60.
The code demonstrates the principles of data abstraction, encapsulation, and polymorphism in C++. It allows users to interact with the TV remote control through a high-level interface (RemoteControl) without needing to understand the internal workings of the TV or the remote control.
Ways Of Achieving Data Abstraction In C++
Here are the primary ways to achieve data abstraction in C++. We have explained both these methods in proper detail, with examples.
Data Abstraction In C++ Using Classes & Access Specifiers
Abstraction using classes and access specifiers is a fundamental aspect of object-oriented programming (OOP) that allows you to define custom abstract data types with attributes (data members) and behaviors (member functions) while encapsulating the internal details. Classes provide a blueprint for creating objects, and access specifiers (public, private, protected) control the visibility of members.
Public Specifier:
Members declared as public are accessible from anywhere in the program, including outside the class.
- This is the interface through which external code interacts with the class.
- Public members typically represent the intended behavior or functionality of the class.
class MyClass {
public:
int publicData; // Public data member
void publicMethod() {
// Public member function
}
};
Private Specifier:
Members declared as private are only accessible within the class itself.
- This hides the internal implementation details of the class from external code.
- Private members are used to store and manage the state of the object.
class MyClass {
private:
int privateData; // Private data member
public:
void setPrivateData(int value) {
// Public member function to set privateData
privateData = value;
}
int getPrivateData() const {
// Public member function to retrieve privateData
return privateData;
}
};
Protected Specifier:
Members declared as protected are similar to private members but are accessible within derived classes. In other words, protected members are used to allow derived classes to inherit and manipulate the base class's behavior and data.
class BaseClass {
protected:
int protectedData; // Protected data member
public:
void setProtectedData(int value) {
protectedData = value;
}
};
class DerivedClass : public BaseClass {
public:
void modifyBaseData() {
protectedData = 42; // Accessible in derived class
}
};
Let's see an example to understand how data abstraction is done using classes and access specifiers in C++.
Code Example:
#include
#include
class Person {
private:
std::string name;
int age;
public:
Person(const std::string& n, int a) : name(n), age(a) {}
std::string getName() const {
return name;}
void setAge(int a) {
if (a >= 0) {
age = a;}
}
void displayInfo() const {
std::cout << "Name: " << name << std::endl;
std::cout << "Age: " << age << std::endl;}
};
int main() {
Person person("Alia", 25);
std::cout << "Person's Name: " << person.getName() << std::endl;
person.setAge(26);
person.displayInfo();
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgojaW5jbHVkZSA8c3RyaW5nPgoKY2xhc3MgUGVyc29uIHsKcHJpdmF0ZToKc3RkOjpzdHJpbmcgbmFtZTsKaW50IGFnZTsKCnB1YmxpYzoKUGVyc29uKGNvbnN0IHN0ZDo6c3RyaW5nJiBuLCBpbnQgYSkgOiBuYW1lKG4pLCBhZ2UoYSkge30KCnN0ZDo6c3RyaW5nIGdldE5hbWUoKSBjb25zdCB7CnJldHVybiBuYW1lO30KCnZvaWQgc2V0QWdlKGludCBhKSB7CmlmIChhID49IDApIHsKYWdlID0gYTt9Cn0KCnZvaWQgZGlzcGxheUluZm8oKSBjb25zdCB7CnN0ZDo6Y291dCA8PCAiTmFtZTogIiA8PCBuYW1lIDw8IHN0ZDo6ZW5kbDsKc3RkOjpjb3V0IDw8ICJBZ2U6ICIgPDwgYWdlIDw8IHN0ZDo6ZW5kbDt9Cn07CgppbnQgbWFpbigpIHsKUGVyc29uIHBlcnNvbigiQWxpYSIsIDI1KTsKCnN0ZDo6Y291dCA8PCAiUGVyc29uJ3MgTmFtZTogIiA8PCBwZXJzb24uZ2V0TmFtZSgpIDw8IHN0ZDo6ZW5kbDsKcGVyc29uLnNldEFnZSgyNik7CnBlcnNvbi5kaXNwbGF5SW5mbygpOwoKcmV0dXJuIDA7Cn0=
Output:
Person's Name: Alia
Name: Alia
Age: 26
Explanation:
The code includes two header files: <iostream> for input/output operations and <string> for string manipulation.
- We then define a Person class with two private data members- name (a string type) and age (an integer type).
- It also has a public constructor that initializes the name and age attributes when an object of the Person class is created, accepting name (n) and age (a) as parameters.
- Next, we define a getName() function, which is a getter method that retrieves the person's name.
- We also define a public setter method, setAge(), to modify the person's age. It contains an if-statement, which only allows age modification if the provided value is non-negative.
- Lastly, we define a constant member function, displayInfo(), that displays the person's name and age using the std::cout stream. It is marked as const because it displays information without altering the object's state.
- In the main() function, we create an instance of the Person class named person, with the attributes name and age initialized with values Alia and 25 respectively.
- Next, we call the getName() function (using the person object and dot operator to retrieve the person's name) inside std::cout statement to print the information.
- Similarly, we call the setAge() to update the person's age to 26. This update is conditional, verifying that the provided age is non-negative.
- Finally, we call the displayInfo() member function to display the person's updated information, including their name and age.
Data Abstraction In C++ Using Header Files
Abstraction in header files involves separating the interface (declarations) of a class or functions from their implementations (definitions). Typically, you create a header file (.h) containing class declarations, function prototypes, necessary include guards, and a source file (.cpp) containing the actual code. Let's understand the above concept using an example.
Code Example:
#include
#include
// Header File (Person.h): Class Declaration
// Define the Person class with private data members and public member functions
class Person {
private:
std::string name;
int age;
public:
// Constructor
Person(const std::string& name, int age);
// Getter and setter methods for name and age
std::string getName() const;
void setName(const std::string& name);
int getAge() const;
void setAge(int age);
// Display person information
void displayInfo() const;
};
// Source File (Person.cpp): Class Implementation
// Constructor implementation
Person::Person(const std::string& name, int age) : name(name), age(age) {}
// Getter method implementations
std::string Person::getName() const {
return name;}
int Person::getAge() const {
return age;}
// Setter method implementations
void Person::setName(const std::string& name) {
this->name = name;}
void Person::setAge(int age) {
this->age = age;}
// Display person information
void Person::displayInfo() const {
std::cout << "Name: " << name << std::endl;
std::cout << "Age: " << age << std::endl;}
// Main Program (main.cpp)
int main() {
// Create a Person object
Person person("Alia", 25);
// Display person information
std::cout << "Original Information:" << std::endl;
person.displayInfo();
// Update person information
person.setName("Bhaskar");
person.setAge(30);
// Display updated information
std::cout << "\nUpdated Information:" << std::endl;
person.displayInfo();
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgojaW5jbHVkZSA8c3RyaW5nPgoKLy8gSGVhZGVyIEZpbGUgKFBlcnNvbi5oKTogQ2xhc3MgRGVjbGFyYXRpb24KCi8vIERlZmluZSB0aGUgUGVyc29uIGNsYXNzIHdpdGggcHJpdmF0ZSBkYXRhIG1lbWJlcnMgYW5kIHB1YmxpYyBtZW1iZXIgZnVuY3Rpb25zCmNsYXNzIFBlcnNvbiB7CnByaXZhdGU6CnN0ZDo6c3RyaW5nIG5hbWU7CmludCBhZ2U7CgpwdWJsaWM6Ci8vIENvbnN0cnVjdG9yClBlcnNvbihjb25zdCBzdGQ6OnN0cmluZyYgbmFtZSwgaW50IGFnZSk7CgovLyBHZXR0ZXIgYW5kIHNldHRlciBtZXRob2RzIGZvciBuYW1lIGFuZCBhZ2UKc3RkOjpzdHJpbmcgZ2V0TmFtZSgpIGNvbnN0Owp2b2lkIHNldE5hbWUoY29uc3Qgc3RkOjpzdHJpbmcmIG5hbWUpOwppbnQgZ2V0QWdlKCkgY29uc3Q7CnZvaWQgc2V0QWdlKGludCBhZ2UpOwoKLy8gRGlzcGxheSBwZXJzb24gaW5mb3JtYXRpb24Kdm9pZCBkaXNwbGF5SW5mbygpIGNvbnN0Owp9OwoKLy8gU291cmNlIEZpbGUgKFBlcnNvbi5jcHApOiBDbGFzcyBJbXBsZW1lbnRhdGlvbgoKLy8gQ29uc3RydWN0b3IgaW1wbGVtZW50YXRpb24KUGVyc29uOjpQZXJzb24oY29uc3Qgc3RkOjpzdHJpbmcmIG5hbWUsIGludCBhZ2UpIDogbmFtZShuYW1lKSwgYWdlKGFnZSkge30KCi8vIEdldHRlciBtZXRob2QgaW1wbGVtZW50YXRpb25zCnN0ZDo6c3RyaW5nIFBlcnNvbjo6Z2V0TmFtZSgpIGNvbnN0IHsKcmV0dXJuIG5hbWU7fQoKaW50IFBlcnNvbjo6Z2V0QWdlKCkgY29uc3QgewpyZXR1cm4gYWdlO30KCi8vIFNldHRlciBtZXRob2QgaW1wbGVtZW50YXRpb25zCnZvaWQgUGVyc29uOjpzZXROYW1lKGNvbnN0IHN0ZDo6c3RyaW5nJiBuYW1lKSB7CnRoaXMtPm5hbWUgPSBuYW1lO30KCnZvaWQgUGVyc29uOjpzZXRBZ2UoaW50IGFnZSkgewp0aGlzLT5hZ2UgPSBhZ2U7fQoKLy8gRGlzcGxheSBwZXJzb24gaW5mb3JtYXRpb24Kdm9pZCBQZXJzb246OmRpc3BsYXlJbmZvKCkgY29uc3QgewpzdGQ6OmNvdXQgPDwgIk5hbWU6ICIgPDwgbmFtZSA8PCBzdGQ6OmVuZGw7CnN0ZDo6Y291dCA8PCAiQWdlOiAiIDw8IGFnZSA8PCBzdGQ6OmVuZGw7fQoKLy8gTWFpbiBQcm9ncmFtIChtYWluLmNwcCkKCmludCBtYWluKCkgewovLyBDcmVhdGUgYSBQZXJzb24gb2JqZWN0ClBlcnNvbiBwZXJzb24oIkFsaWEiLCAyNSk7CgovLyBEaXNwbGF5IHBlcnNvbiBpbmZvcm1hdGlvbgpzdGQ6OmNvdXQgPDwgIk9yaWdpbmFsIEluZm9ybWF0aW9uOiIgPDwgc3RkOjplbmRsOwpwZXJzb24uZGlzcGxheUluZm8oKTsKCi8vIFVwZGF0ZSBwZXJzb24gaW5mb3JtYXRpb24KcGVyc29uLnNldE5hbWUoIkJoYXNrYXIiKTsKcGVyc29uLnNldEFnZSgzMCk7CgovLyBEaXNwbGF5IHVwZGF0ZWQgaW5mb3JtYXRpb24Kc3RkOjpjb3V0IDw8ICJcblVwZGF0ZWQgSW5mb3JtYXRpb246IiA8PCBzdGQ6OmVuZGw7CnBlcnNvbi5kaXNwbGF5SW5mbygpOwoKcmV0dXJuIDA7Cn0=
Output:
Original Information:
Name: Alia
Age: 25Updated Information:
Name: Bhaskar
Age: 30
Explanation:
The above C++ code example demonstrates data abstraction using header files by encapsulating the person's details (name and age) within the Person class.
-
As evident from the code comments, the program is divided into three sections, i.e., a header file (Person.h), a source file (Person.cpp), and the main program (main.cpp).
-
Inside the header file (Person.h):
- We declare a Person class, which has two private data members- name (of string type) and age (of integer type), and a public constructor to initialize object members.
- It also has five public member functions— the getter methods (getName, getAge) to get the name and age, the setter methods (setName, setAges) to change the name and age, and a function to display (displayInfo) person information.
- Inside the source file (Person.cpp)-
- We have the constructor implementation to initialize name and age data members when a Person object is created, using initializer lists.
- Then, the implementation of getName() and getAge() methods that access and return the values of private members name and age of the person, respectively.
- The implementation of setName() and setAge() methods enable modificationof name and age data members of person object. Here, we use the 'this' pointer to differentiate between the parameter and the member variable with the same name.
- After that, we have the implementation of displayInfo() method that retrives and prints the person's name and age to the console using std::cout.
-
Lastly, there is the main program (main.cpp), i.e., the main() function, which serves as the entry point of program's execution.
-
Inside main, we create a Person object named person with the name variable initialized with Alia and an age variable with the value of 25.
- Then, we call the displayInfo() function using the person object and dot operator. We use the std::cout stream to print the original information of the object.
- Next, we call the setName() and setAge() methods to update the attribute (name and age) values to Bhaskar and age 30.
- Once again, we call the displayInfo() method to print the updated information.
- Finally, the main() function returns 0, indicating successful execution.
The code demonstrates data abstraction using header files by encapsulating the person's details (name and age) within the Person class
Check this out: Boosting Career Opportunities For Engineers Through E-School Competitions
What Is An Abstract Class?

An abstract class in C++ is a class that cannot be instantiated on its own and is designed to serve as a base or blueprint for other classes. It is a key concept in object-oriented programming and is used to define a common interface or set of methods that must be implemented by its derived (sub) classes. Abstract classes provide a way to enforce a specific structure and behavior among a group of related classes.
Syntax Of Abstract Class
class AbstractClass {
public:
virtual void pureVirtualFunction() = 0; // Pure virtual function
// Other member functions and data members (if needed)
};
The syntax of an abstract class in C++ mandates the declaration of at least one pure virtual function in the class. A pure virtual function is a function without any implementation in the base class and is marked with (= 0). Now, let's take a look at an example to see how an abstract class works in a code/ program.
Code Example:
#include
// Abstract class
class Shape {
public:
virtual void draw() const = 0; // Pure virtual function
virtual double area() const = 0; // Another pure virtual function
void printInfo() const {
std::cout << "This is a shape." << std::endl;}
};
// Concrete derived class: Circle
class Circle : public Shape {
private:
double radius;
public:
Circle(double r) : radius(r) {}
void draw() const override {
std::cout << "Drawing a circle." << std::endl;}
double area() const override {
return 3.14159 * radius * radius;}
};
// Concrete derived class: Rectangle
class Rectangle : public Shape {
private:
double length;
double width;
public:
Rectangle(double l, double w) : length(l), width(w) {}
void draw() const override {
std::cout << "Drawing a rectangle." << std::endl;}
double area() const override {
return length * width;}
};
int main() {
Circle circle(5.0);
Rectangle rectangle(4.0, 6.0);
Shape* shapes[] = { &circle, &rectangle };
for (const auto shape : shapes) {
shape->draw();
std::cout << "Area: " << shape->area() << std::endl;
shape->printInfo();
std::cout << std::endl;}
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgoKLy8gQWJzdHJhY3QgY2xhc3MKY2xhc3MgU2hhcGUgewpwdWJsaWM6CnZpcnR1YWwgdm9pZCBkcmF3KCkgY29uc3QgPSAwOyAvLyBQdXJlIHZpcnR1YWwgZnVuY3Rpb24KdmlydHVhbCBkb3VibGUgYXJlYSgpIGNvbnN0ID0gMDsgLy8gQW5vdGhlciBwdXJlIHZpcnR1YWwgZnVuY3Rpb24KCnZvaWQgcHJpbnRJbmZvKCkgY29uc3QgewpzdGQ6OmNvdXQgPDwgIlRoaXMgaXMgYSBzaGFwZS4iIDw8IHN0ZDo6ZW5kbDt9Cn07CgovLyBDb25jcmV0ZSBkZXJpdmVkIGNsYXNzOiBDaXJjbGUKY2xhc3MgQ2lyY2xlIDogcHVibGljIFNoYXBlIHsKcHJpdmF0ZToKZG91YmxlIHJhZGl1czsKCnB1YmxpYzoKQ2lyY2xlKGRvdWJsZSByKSA6IHJhZGl1cyhyKSB7fQoKdm9pZCBkcmF3KCkgY29uc3Qgb3ZlcnJpZGUgewpzdGQ6OmNvdXQgPDwgIkRyYXdpbmcgYSBjaXJjbGUuIiA8PCBzdGQ6OmVuZGw7fQoKZG91YmxlIGFyZWEoKSBjb25zdCBvdmVycmlkZSB7CnJldHVybiAzLjE0MTU5ICogcmFkaXVzICogcmFkaXVzO30KfTsKCi8vIENvbmNyZXRlIGRlcml2ZWQgY2xhc3M6IFJlY3RhbmdsZQpjbGFzcyBSZWN0YW5nbGUgOiBwdWJsaWMgU2hhcGUgewpwcml2YXRlOgpkb3VibGUgbGVuZ3RoOwpkb3VibGUgd2lkdGg7CgpwdWJsaWM6ClJlY3RhbmdsZShkb3VibGUgbCwgZG91YmxlIHcpIDogbGVuZ3RoKGwpLCB3aWR0aCh3KSB7fQoKdm9pZCBkcmF3KCkgY29uc3Qgb3ZlcnJpZGUgewpzdGQ6OmNvdXQgPDwgIkRyYXdpbmcgYSByZWN0YW5nbGUuIiA8PCBzdGQ6OmVuZGw7fQoKZG91YmxlIGFyZWEoKSBjb25zdCBvdmVycmlkZSB7CnJldHVybiBsZW5ndGggKiB3aWR0aDt9Cn07CgppbnQgbWFpbigpIHsKQ2lyY2xlIGNpcmNsZSg1LjApOwpSZWN0YW5nbGUgcmVjdGFuZ2xlKDQuMCwgNi4wKTsKClNoYXBlKiBzaGFwZXNbXSA9IHsgJmNpcmNsZSwgJnJlY3RhbmdsZSB9OwoKZm9yIChjb25zdCBhdXRvIHNoYXBlIDogc2hhcGVzKSB7CnNoYXBlLT5kcmF3KCk7CnN0ZDo6Y291dCA8PCAiQXJlYTogIiA8PCBzaGFwZS0+YXJlYSgpIDw8IHN0ZDo6ZW5kbDsKc2hhcGUtPnByaW50SW5mbygpOwpzdGQ6OmNvdXQgPDwgc3RkOjplbmRsO30KCnJldHVybiAwOwp9
Output:
Drawing a circle.
Area: 78.5398
This is a shape.Drawing a rectangle.
Area: 24
This is a shape.
Explanation:
-
We define an abstract class named Shape, which serves as a base class for geometric shapes.
- The class contains two pure virtual functions and a non-virtual function-
- The draw() and area() are pure virtual functions that represent the action of drawing a shape and calculating the shape's area, respectively.
- These functions are declared without implementation (i.e., as = 0), making Shape an abstract class. This means we cannot instantiate Shape class directly and must create derived classes that provide implementations for these functions.
-
The non-virtual function (non-abstract method) printInfo() prints a message to the console indicating that it's a shape.
-
Next, we define two concrete derived classes, Circle and Rectangle, that publically inherit from the base class Shape.
- The Circle class has a private member variable radius of type double and implementations of the draw() and area() functions. The area() method calculates the area of a circle based on its radius using the formula π*radius*radius.
- Similarly, the Rectangle class has private member variables length and width and implementations of the draw() and area() functions. The area() method calculates the area of a rectangle using the formula length * width.
-
Inside the main() function-
- We create an instance of the Circle class, named circle, and initialize it with a radius of 5.0. Similarly, we create an instance of the Rectangle class, named rectangle, and initialize it with dimensions 4.0 x 6.0, respectively.
- Next, we create an array of Shape pointers called shapes[] to store pointers to the class objects. This demonstrates polymorphism, where objects of derived classes can be treated as objects of the base class Shape.
- Then, we initiate a for loop to iterate through the shape[] array. It first calls the draw() method on each shape, using the arrow operator. This prints a message indicating the type of shape (circle or rectangle).
- The loop then calls the area() method to calculate and print the area of each shape.
- We terminate the loop after calling the printInfo() method on each shape, which prints a general message indicating that it's a shape.
- Each shape is printed with its respective information, followed by an empty line for separation.
-
Finally, the program returns 0, indicating successful execution.
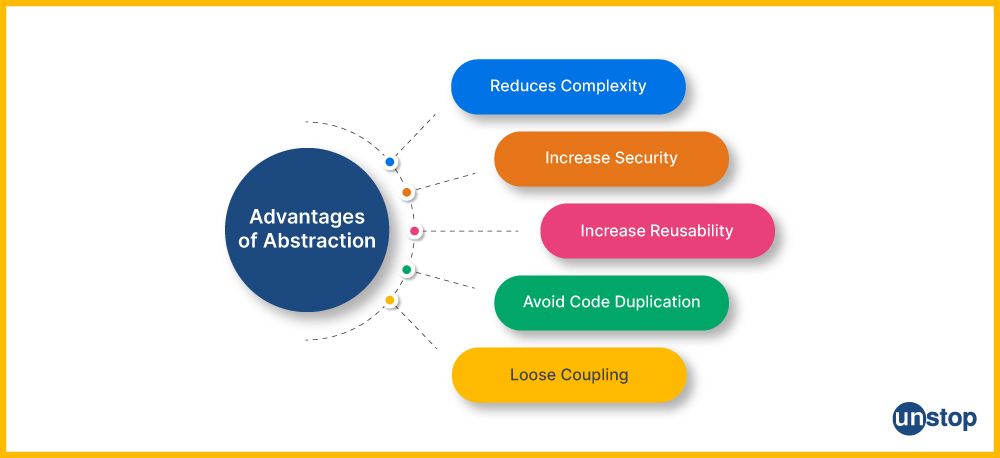
Advantages Of Data Abstraction In C++
Here are some key advantages of abstraction/ data abstraction in C++:
-
Simplification of Complexity: One of the primary purposes of abstraction is to simplify complex systems. It allows developers to focus on high-level structures and concepts while ignoring the lower-level background details. This simplification makes it easier to understand and manage complex systems, reducing cognitive load and the potential for errors, hence making the application secure.
-
Modularity: Data abstraction in C++ encourages the creation of modular code. By breaking down a system into smaller, self-contained components (such as classes or modules), you can work on one piece at a time, which is easier to design, develop, test, and maintain. This modular approach enhances code reusability and collaboration among team members.
-
Encapsulation: Abstraction is closely related to encapsulation, another core concept in object-oriented programming. Encapsulation hides the internal state and implementation details of an object from the outside world. Data abstraction in C++ makes the interface independent of interacting with the object, allowing you to change the implementation without affecting the code that uses it. This separation of concerns enhances security, maintainability, and flexibility.
-
Security: By exposing only the necessary interfaces and hiding implementation details, abstraction helps improve security. It reduces the risk of unintended access to sensitive data or functionality.
-
Reusability: Abstraction promotes code reusability. Abstract classes, interfaces, and generic constructs provide blueprints that multiple classes or components can implement or extend. This reduces low-level code duplication and allows developers to leverage existing abstractions to build new functionality.
-
Flexibility and Extensibility: Abstraction allows for the creation of flexible and extensible systems. By defining abstract classes or interfaces, you can establish contracts that other classes must adhere to. This makes it easier to add new features or functionality by creating new classes that implement the same abstraction. Existing code that depends on the data abstraction in C++ can remain unchanged.
-
Maintenance and Debugging: Abstracting complex systems makes debugging and maintenance more manageable. When issues arise, you can focus on specific components or abstractions rather than having to navigate through a convoluted, monolithic codebase. This saves time and effort in identifying and fixing problems.
-
Communication and Collaboration: Abstraction serves as a common language for communication among developers. It provides a clear and agreed-upon way to describe the structure and behavior of a system. This common understanding is essential for effective collaboration on software projects, especially in larger teams.
-
Adaptation to Change: Data abstraction in C++ and other languages helps software systems adapt to changing requirements. When requirements evolve, or new features are needed, you can often extend or modify existing abstractions rather than rewriting large portions of the codebase. This reduces the risk of introducing errors during changes.
-
Testing and Quality Assurance: Abstraction in C++ code makes it easier to design and conduct tests. You can test individual components or abstractions in isolation, ensuring that each part of the system behaves as expected. This granularity enhances the quality and reliability of the software.
Use Cases Of Data Abstraction In C++
Data abstraction is a fundamental concept in software development and has various use cases across different domains. Here are some common use cases of data abstraction in C++:
-
Database Abstraction:
- In database management systems, data abstraction layers provide a consistent and simplified interface for interacting with various database engines (e.g., MySQL, PostgreSQL, MongoDB).
- Developers can work with a unified API, abstracting the underlying database-specific details.
-
Graphics and UI Libraries:
- Graphics libraries like OpenGL provide an abstraction layer for hardware-accelerated rendering.
- User Interface (UI) libraries abstract the complexities of creating graphical user interfaces, allowing developers to design interfaces using high-level components.
-
File I/O Abstraction:
- Data abstraction in C++ can simplify file input/output operations by providing a consistent interface to read and write files, regardless of their actual storage medium or format.
-
Networking Abstraction:
- Network libraries and protocols (e.g., HTTP, TCP/IP) abstract the complexities of network communication, enabling developers to build networked applications without dealing with low-level networking details.
-
Hardware Abstraction:
- Hardware abstraction layers (HALs) provide a consistent interface for interacting with hardware devices such as sensors, GPUs, and peripherals.
- This simplifies the development of hardware-dependent software, including embedded systems and device drivers.
-
Operating System Abstraction:
- Operating systems abstract the underlying hardware and provide a uniform environment for running applications.
- Developers can write software that runs on different operating systems without worrying about specific OS details.
-
Data Structures and Algorithms:
- Data abstraction in C++ allows developers to work with high-level data structures (e.g., arrays, lists, trees) and algorithmic concepts (e.g., sorting, searching) without needing to implement them from scratch.
-
Object-Oriented Programming (OOP):
- In OOP, the abstraction concept is a core principle, allowing developers to define classes and objects with abstract interfaces (e.g., methods) that hide internal implementation details.
- Inheritance and polymorphism are used to create abstract base classes and concrete derived classes.
-
APIs and SDKs:
- Software development kits (SDKs) and application programming interfaces (APIs) provide abstraction layers for external services, libraries, and platforms.
- Developers can integrate third-party functionality into their applications using well-defined interfaces.
-
Distributed Systems:
- Abstraction is essential in designing and implementing distributed systems, as it allows developers to work with remote services and data sources as if they were local.
- Technologies like Remote Procedure Calls (RPC) and Representational State Transfer (REST) provide abstractions for distributed communication.
-
- Cloud service providers abstract infrastructure and resources, allowing users to deploy and manage applications without dealing with the underlying hardware or data center operations.
-
Database ORMs (Object-Relational Mapping):
- ORMs abstract database tables and queries into high-level object-oriented representations, making database interactions more intuitive for developers.
-
Game Development:
- Game engines abstract the complexities of real-time graphics rendering, physics simulations, and audio processing, enabling game developers to focus on gameplay and content creation.
-
AI and Machine Learning:
- Data abstraction in C++ is used to create high-level machine-learning frameworks that allow developers to build and train complex models without delving into the mathematical details of algorithms and neural networks.
-
Testing and Test Abstraction:
- Test frameworks provide an abstraction for writing and executing tests, making it easier to automate testing processes and evaluate software quality.
In each of these use cases, data abstraction in C++ simplifies the interaction between complex systems and end-users or developers. It enhances code maintainability, modularity, and reusability, and it allows for better management of software complexity in various domains.
Encapsulation Vs. Abstraction In C++
In this section, we will discuss the difference between the two key pillars of OOPs programming- encapsulation and abstraction/ data abstraction in C++. To begin with, let's see what we understand by the term encapsulation.
Encapsulation
Encapsulation in C++ is one of the four fundamental concepts of object-oriented programming (OOP) and involves bundling data (attributes) and the methods (functions) that operate on that data into a single unit called a class. The key idea behind encapsulation is to hide the internal state of an object and provide controlled access to it.
In other words, it restricts direct access to an object's data and requires clients to use accessor and mutator methods to interact with the object's state. Encapsulation helps ensure data integrity and promotes the principle of information hiding.
Key Points About Encapsulation:
- Data members (attributes) of a class are often declared as private to prevent direct access from outside the class.
- Public methods (member functions) are provided to manipulate and access the data safely.
- It enforces the principle of access control, allowing the class to decide what parts of its internal state are exposed to the outside world.
Difference Between Encapsulation & Abstraction In C++
Here's a table summarizing the differences between encapsulation and data abstraction in C++:
| Aspect | Abstraction | Encapsulation |
|---|---|---|
| Definition | Simplifies complex systems by focusing on high-level details and hiding low-level implementation details. | Bundles data and methods into a single unit (class) and controls access to the data. |
| Primary Purpose | Reduces complexity, provides a clear and concise interface, and hides unnecessary implementation details. | Protects an object's internal state from unauthorized access and modification while allowing controlled access through methods. |
| Implementation | Often implemented using abstract classes and interfaces. Defines a contract for derived classes. | Implemented within a class by declaring data members as private (or protected) and providing public methods (getters and setters) to access or modify the data. |
| Access Control | Focuses on providing abstract interfaces with no specific access control. | Emphasizes access control by using private and protected access specifiers for data members and public methods for controlled access. |
| Example Syntax (C++) |
class AbstractBase { // Pure virtual function |
class MyClass { public: int getPrivateData() const { |
Conclusion
Data abstraction is a cornerstone of software engineering and plays a crucial role in managing complexity, improving code quality, and facilitating code reuse. In C++, it is achieved through classes and access specifiers or by using header files to declare class interfaces. Real-life examples demonstrate how data abstraction simplifies complex systems. In a world where software systems are growing increasingly intricate, data abstraction remains a valuable tool for software developers. It enables us to build robust, scalable, and maintainable software solutions while keeping the underlying complexity under control. By embracing data abstraction in C++, developers can unlock new possibilities and elevate the quality of their code.
Also read- 51 C++ Interview Questions For Freshers & Experienced (With Answers)
Frequently Asked Questions
Q. What are the three levels of data abstraction in C++?
In computer science and database management, data abstraction typically consists of three levels:
-
Physical Level:
- This is the lowest level of abstraction.
- It focuses on the physical representation of data on storage devices.
- It is concerned with details like data structures, file organization, and access methods.
- In databases, it deals with how data is stored on disk, including file formats, indexing, and data storage structures.
-
Logical Level:
- This is the middle level of data abstraction in C++ and programming in general.
- It provides a conceptual view of the data without being concerned with physical storage details.
- It defines the structure and organization of data without specifying how it is physically implemented.
- In databases, it involves defining tables, relationships, constraints, and views without detailing how data is stored on disk.
-
View Level (or External Interface Level):
- It is the highest level of data abstraction.
- The focus here is on the user's perspective and how data is presented to applications and end-users.
- It defines user-specific views of the data, hiding the complexities of the logical and physical levels.
- In databases, it includes defining user interfaces, query languages, and access rights for different user roles.
Q. How do access specifiers help achieve data abstraction in C++?
Access specifiers help in data abstraction in C++ by controlling the accessibility of class members. This means that we can hide the implementation details of a class from the user and only expose the essential details.
For example, we can declare a class member as private to make it inaccessible to the user. This means that the user cannot directly access the member, and they must use the public member functions of the class to access it.
This helps to achieve data abstraction by hiding the implementation details of the class from the user. This makes the class more reusable and maintainable, as the user does not need to know how the class works in order to use it.
Here are the three access specifiers in C++ and their meanings:
- Public: The members declared as public can be accessed from anywhere in the program.
- Private: The members declared as private can only be accessed from within the class.
- Protected: The members declared as protected can be accessed from within the class and from its derived classes.
The access specifiers are an important part of data abstraction in C++. By using access specifiers, we can hide the implementation details of a class from the user and only expose the essential details. This makes the class more reusable and maintainable.
Q. What is abstraction vs. abstract class in C++?
Abstraction and abstract class are two different concepts in C++.
- Abstraction is a process of hiding the implementation details of an object or data structure from the user. This allows the user to focus on the essential features of the object or data structure without having to worry about how it works.
- An abstract class is a class that has one or more pure virtual functions. A pure virtual function is a function that has no implementation. This means that any class that inherits from an abstract class must override the pure virtual functions.
Abstraction is a broader concept than abstract class. Data abstraction in C++ can be achieved in many ways, such as using access specifiers, interfaces, and abstract classes. Abstract class is a specific way to achieve abstraction.
Q. What is data abstraction in C++ with example?
Data abstraction in C++ is an object-oriented programming technique that focuses on hiding the implementation details of an object and exposing only the necessary features or interfaces to the user. The goal is to reduce complexity and allow the user to interact with objects at a higher level, without needing to know the underlying implementation.
Here’s a simple example of data abstraction in C++:
#include
class Circle {
private:
double radius; // Private data member
public:
// Constructor to initialize the circle
Circle(double r) : radius(r) {}
// Public method to calculate the area
double getArea() const {
return 3.14 * radius * radius;
}
};
int main() {
Circle circle(5.0); // Create a Circle object with radius 5.0
// Use the public method to get the area
std::cout << "Area: " << circle.getArea() << std::endl;
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgoKY2xhc3MgQ2lyY2xlIHsKcHJpdmF0ZToKZG91YmxlIHJhZGl1czsgLy8gUHJpdmF0ZSBkYXRhIG1lbWJlcgoKcHVibGljOgovLyBDb25zdHJ1Y3RvciB0byBpbml0aWFsaXplIHRoZSBjaXJjbGUKQ2lyY2xlKGRvdWJsZSByKSA6IHJhZGl1cyhyKSB7fQoKLy8gUHVibGljIG1ldGhvZCB0byBjYWxjdWxhdGUgdGhlIGFyZWEKZG91YmxlIGdldEFyZWEoKSBjb25zdCB7CnJldHVybiAzLjE0ICogcmFkaXVzICogcmFkaXVzOwp9Cn07CgppbnQgbWFpbigpIHsKQ2lyY2xlIGNpcmNsZSg1LjApOyAvLyBDcmVhdGUgYSBDaXJjbGUgb2JqZWN0IHdpdGggcmFkaXVzIDUuMAoKLy8gVXNlIHRoZSBwdWJsaWMgbWV0aG9kIHRvIGdldCB0aGUgYXJlYQpzdGQ6OmNvdXQgPDwgIkFyZWE6ICIgPDwgY2lyY2xlLmdldEFyZWEoKSA8PCBzdGQ6OmVuZGw7CgpyZXR1cm4gMDsKfQ==
Explanation:
In this example, the Circle class uses data abstraction to hide the internal detail of the radius while exposing a public method getArea() that calculates and returns the area of the circle. The user interacts with the Circle object through this simple interface, without needing to know how the area is computed internally.
Q. Why is abstraction used in a class?
Abstraction is used in a class to hide the implementation details from the user. This allows the user to focus on the essential features of the class without having to worry about how it works. Here are some reasons why abstraction is used in a class:
- To reduce complexity: Data abstraction in C++ classes can help to reduce the complexity of a class by hiding the implementation details. This makes the class easier to understand and use.
- To improve reusability: Abstraction can help to improve the reusability of a class by defining the common behavior of a group of classes. This allows us to create concrete classes that inherit from the abstract class and override the behavior as needed.
- To improve maintainability: Data abstraction can help to improve the maintainability of a class by isolating the implementation details from the user. This makes it easier to change the implementation without affecting the user of the class.
- To improve flexibility: Data abstraction in C++ programs can help to improve the flexibility of a class by allowing the user to customize the behavior of the class. This can be done by overriding the pure virtual functions in the abstract class.
Quiz Time!!!
You might also be interested in reading the following:
- Function Overloading In C++ With Code Examples & Explanation
- New Operator In C++ | Syntax, Usage, Working & More (With Examples)
- Static Member Function In C++ Explained With Proper Examples
- C++ Type Conversion & Type Casting Demystified (With Examples)
- Sort() Function In C++ & Algorithms Explained (+Code Examples)
Login to continue reading
And access exclusive content, personalized recommendations, and career-boosting opportunities.
Don't have an account? Sign up
Never miss an
Update

Featured Opportunities
Top-Rated Practice by Students





Subscribe
to our newsletter



Comments
Add comment