
Asian Paints Alchemy 2026
C++ Programming Language
- A Brief Intro To C++ & Its History
- The Detailed History & Timeline Of C++ (With Infographic)
- Importance Of C++
- Versions Of C++ Language
- Structure Of A C++ Program
- Comparison With Other Popular Programming Languages
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Are Variables In C++?
- Declaration & Definition Of Variables In C++
- Variable Initialization In C++
- Rules & Regulations For Naming Variables In C++ Language
- Different Types Of Variables In C++
- Different Types of Variable Initialization In C++
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Are Primitive Data Types In C++?
- Derived Data Types In C++
- User-Defined Data Types In C++
- Abstract Data Types In C++
- Data Type Modifiers In C++
- Declaring Variables With Auto Keyword
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- Structure Of C++ Program: Components
- Segment 1: Documentation Section Of Structure Of C++ Program (With Example)
- Segment 2: Preprocessing & Namespace (Linking) Section Of CPP Program
- Segment 3: Definition Section In Structure of a C++ Program (With Examples)
- Segment 4: Main Function In Structure Of A C++ Program (With Example)
- Compilation & Execution Of C++ Programs | Step-by-Step Explanation
- Explaining Structure Of C++ Program With Suitable Example
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What is Typedef in C++?
- The Role & Applications of Typedef in C++
- Basic Syntax for typedef in C++
- How Does typedef Work in C++?
- How to Use Typedef in C++ With Examples? (Multiple Data Types)
- The Difference Between #define & Typedef in C++
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Are Strings In C++?
- Types Of Strings In C++
- How To Declare & Initialize C-Style Strings In C++ Programs?
- How To Declare & Initialize Strings In C++ Using String Keyword?
- List Of String Functions In C++
- Operations On Strings Using String Functions In C++
- Concatenation Of Strings In C++
- How To Convert Int To Strings In C++
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Is String Concatenation In C++?
- How To Concatenate Two Strings In C++ Using The ‘+' Operator?
- String Concatenation Using The strcat( ) Function
- Concatenation Of Two Strings In C++ Using Loops
- String Concatenation Using The append() Function
- C++ String Concatenation Using The Inheritance Of Class
- Concatenate Two Strings In C++ With The Friend and strcat() Functions
- Why Do We Need To Concatenate Two Strings?
- How To Reverse Concatenation Of Strings In C++?
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Is Find In String C++?
- What Is A Substring?
- How To Find A Substring In A String In C++?
- How To Find A Character In String C++?
- Find All Substrings From A Given String In C++
- Index Substring In String In C++ From A Specific Start To A Specific Length
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Are Pointers In C++?
- Pointer Declaration In C++
- How To Initialize And Use Pointers In C++?
- Different Types Of Pointers In C++
- References & Pointers In C++
- Arrays And Pointers In C++
- String Literals & Pointers In C++
- Pointers To Pointers In C++ (Double Pointers)
- Arithmetic Operation On Pointers In C++
- Advantages Of Pointers In C++
- Some Common Mistakes To Avoid With Pointers In Cpp
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- Understanding Pointers In C++
- What Is Pointer To Object In C++?
- Declaration And Use Of Object Pointers In C++
- Advantages Of Pointer To Object In C++
- Pointer To Objects In C++ With Arrow Operator
- An Array Of Objects Using Pointers In C++
- Base Class Pointer For Derived Class Object In C++
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Is 'This' Pointer In C++?
- Defining ‘this’ Pointer In C++
- Example Of 'this' Pointer In C++
- Describing The Constness Of 'this' Pointer In C++
- Important Uses Of 'this' Pointer In C++
- Method Chaining Using 'this' Pointer In C++
- C++ Programs To Show Application Of 'This' Pointer
- How To Delete The ‘this’ Pointer In C++?
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What is Reference?
- What is Pointer?
- Comparison Table Of C++ Pointer Vs. Reference
- Differences Between Reference And Pointer: A Detailed Explanation
- Why Are References Less Powerful Than Pointers?
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- How To Declare A 2D Array In C++?
- C++ Multi-Dimensional Arrays
- Ways To Initialize A 2D Array In C++
- Methods To Dynamically Allocate A 2D Array In C++
- Accessing/ Referencing Two-Dimensional Array Elements
- How To Initialize A Two-Dimensional Integer Array In C++?
- How To Initialize A Two-Dimensional Character Array?
- How To Enter Data In Two-Dimensional Array In C++?
- Conclusion
- Frequently Asked Questions
- What Are Arrays Of Strings In C++?
- Different Ways To Create String Arrays In C++
- How To Access The Elements Of A String Array In C++?
- How To Convert Char Array To String?
- Conclusion
- Frequently Asked Questions
- What is Memory Allocation in C++ & Why Do We Need It?
- How Does Dynamic Memory Allocation Work?
- The new Operator in C++
- The delete Operator in C++
- Dynamic Memory Allocation in C++ | Arrays
- Did You Know: Companies That Ask About Dynamic Memory Allocation
- Dynamic Memory Allocation in C++ | Objects
- Deallocation of Dynamic Memory in C++
- malloc(), calloc(), and free() Functions in C/C++
- Applications of Dynamic Memory Allocation in C++
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Is A Substring In C++ (Substr C++)?
- Example for substr() in C++ | Finding Substring Using Positive and Negative Indices
- Understanding substr() Basics with Examples
- Use Cases/ Examples of substr() in C++
- How to Get a Substring Before a Character Using substr() in C++?
- Use substr() in C++ to Print all Substrings of a Given String
- Print Sum of all Substrings of a String Representing a Number
- Minimum Value of all Substrings of a String Representing a Number
- Maximum Value of all Substrings of a String Representing a Number
- Points To Remember For Substr In C++
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Is Operator In C++?
- Types Of Operators In C++ With Examples
- What Are Arithmetic Operators In C++?
- What Are Assignment Operators In C++?
- What Are Relational Operators In C++?
- What Are Logical Operators In C++?
- What Are Bitwise Operators In C++?
- What Is Ternary/ Conditional Operator In C++?
- Miscellaneous Operators In C++
- Precedence & Associativity Of Operators In C++
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Is The New Operator In C++?
- Example To Understand New Operator In C++
- The Grammar Elements Of The New Operator In C++
- Storage Space Allocation
- How Does The C++ New Operator Works?
- What Happens When Enough Memory In The Program Is Not Available?
- Initializing Objects Allocated With New Operator In C++
- Lifetime Of Objects Allocated With The New Operator In C++
- What Is The Delete Operator In C++?
- Difference Between New And Delete Operator In C++
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- Types Of Overloading In C++
- What Is Operator Overloading In C++?
- How To Overload An Operator In C++?
- Overloadable & Non-overloadable Operators In C++
- Unary Operator Overloading In C++
- Binary Operator Overloading In C++
- Special Operator Overloading In C++
- Rules For Operator Overloading In C++
- Advantages And Disadvantages Of Operator Overloading In C++
- Function Overloading In C++
- What Is the Difference Between Operator Functions and Normal Functions?
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Are Operators In C++?
- Introduction To Logical Operators In C++
- Types Of Logical Operators In C++ With Example Program
- Logical AND (&&) Operator In C++
- Logical NOT(!) Operator In C++
- Logical Operator Precedence And Associativity In C++
- Relation Between Conditional Statements And Logical Operators In C++
- C++ Relational Operators
- Conclusion
- Frequently Asked Important Interview Questions:
- Test Your Skills: Quiz Time
- Different Type Of C++ Bitwise Operators
- C++ Bitwise AND Operator
- C++ Bitwise OR Operator
- C++ Bitwise XOR Operator
- Bitwise Left Shift Operator In C++
- Bitwise Right Shift Operator In C++
- Bitwise NOT Operator
- What Is The Meaning Of Set Bit In C++?
- What Does Clear Bit Mean?
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- Types of Comments in C++
- Single Line Comment In C++
- Multi-Line Comment In C++
- How Do Compilers Process Comments In C++?
- C- Style Comments In C++
- How To Use Comment In C++ For Debugging Purposes?
- When To Use Comments While Writing Codes?
- Why Do We Use Comments In Codes?
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Are Storage Classes In Cpp?
- What Is The Scope Of Variables?
- What Are Lifetime And Visibility Of Variables In C++?
- Types of Storage Classes in C++
- Automatic Storage Class In C++
- Register Storage Class In C++
- Static Storage Class In C++
- External Storage Class In C++
- Mutable Storage Class In C++
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- Decision Making Statements In C++
- Types Of Conditional Statements In C++
- If-Else Statement In C++
- If-Else-If Ladder Statement In C++
- Nested If Statements In C++
- Alternatives To Conditional If-Else In C++
- Switch Case Statement In C++
- Jump Statements & If-Else In C++
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Is A Switch Statement/ Switch Case In C++?
- Rules Of Switch Case In C++
- How Does Switch Case In C++ Work?
- The break Keyword In Switch Case C++
- The default Keyword In C++ Switch Case
- Switch Case Without Break And Default
- Advantages & Disadvantages of C++ Switch Case
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Is A For Loop In C++?
- Syntax Of For Loop In C++
- How Does A For Loop In C++ Work?
- Examples Of For Loop Program In C++
- Ranged Based For Loop In C++
- Nested For Loop In C++
- Infinite For Loop In C++
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Is A While Loop In C++?
- Parts Of The While Loop In C++
- C++ While Loop Program Example
- How Does A While Loop In C++ Work?
- What Is Pre-checking Process Or Entry-controlled Loop?
- When Are While Loops In C++ Useful?
- Example C++ While Loop Program
- What Are Nested While Loops In C++?
- Infinite While Loop In C++
- Alternatives To While Loop In C++
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Are Loops & Its Types In C++?
- What Is A Do-While Loop In C++?
- Do-While Loop Example In C++ To Print Numbers
- How Does A Do-While Loop In C++ Work?
- Various Components Of The Do-While Loop In C++
- Example 2: Adding User-Input Positive Numbers With Do-While Loop
- C++ Nested Do-While Loop
- C++ Infinitive Do-while Loop
- What is the Difference Between While Loop and Do While Loop in C++?
- When To Use A Do-While Loop?
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What are 2D Vectors in C++?
- How to Declare 2D Vectors in C++
- How to Initialize a 2D Vector in C++?
- Creating a 2D Vector in C++ with User Input for Column & Row Size
- Methods for Traversing 2D Vectors in C++
- Interview Spotlight: 2D Vectors in FAANG Interviews
- Printing 2D Vector in C++ Using Nested Loops
- Example C++ Programs for Creating 2D Vectors
- How to Access & Modify 2D Vector Elements in C++?
- Adding Elements to 2D Vector Using push_back() Function
- Removing Elements from Vector in C++ Using pop_back() Function
- Did You Know? Real-World Outage: Crash Cause Linked to 2D Vector Usage
- Advantages of 2D Vectors Over Traditional Arrays
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- How To Print A Vector In C++ By Overloading Left Shift (<<) Operator?
- How To Print Vector In C++ Using Range-Based For-Loop?
- Print Vector In C++ With Comma Separator
- Printing Vector In C++ Using Indices (Square Brackets/ Double Brackets & at() Function)
- How To Print A Vector In C++ Using std::copy?
- How To Print A Vector In C++ Using for_each() Function?
- Printing C++ Vector Using The Lambda Function
- How To Print Vector In C++ Using Iterators?
- Conclusion
- Frequently Asked Questions
- Definition Of C++ Find In Vector
- Using The std::find() Function
- How Does find() In Vector C++ Function Work?
- Finding An Element By Custom Comparator Using std::find_if() Function
- Use std::find_if() With std::distance()
- Element Find In Vector C++ Using For Loop
- Using The find_if_not Function
- Find Elements With The Linear Search Approach
- Conclusion
- Frequently Asked Questions
- What Is Sort() Function In C++?
- Sort() Function In C++ From Standard Template Library
- Exceptions Of Sort() Function/ Algorithm In C++
- The Stable Sort() Function In C++
- Partial Sort() Function In C++
- Sorting In Ascending Order With Sort() Function In C++
- Sorting In Descending Order With Sort Function In C++
- Sorting In Desired Order With Custom Comparator Function & Sort Function In C++
- Sorting Elements In Desired Order Using Lambda Expression & Sort Function In C++
- Types of Sorting Algorithms In C++
- Advanced Sorting Algorithms In C++
- How Does the Sort() Function Algorithm Work In C++?
- Conclusion
- Frequently Asked Questions
- What Is Function Overloading In C++?
- Ways Of Function Overloading In C++
- Function Overloading In C++ Using Different Types Of Parameters
- Function Overloading In C++ With Different Number Of Parameters
- Function Overloading In C++ Using Different Sequence Of Parameters
- How Does Function Overloading In C++ Work?
- Rules Of Function Overloading In C++
- Why Is Function Overloading Used?
- Types Of Function Overloading Based On Time Of Resolution
- Causes Of Function Overloading In C++
- Ambiguity & Function Overloading In C++
- Advantages Of Function Overloading In C++
- Disadvantages Of Function Overloading In C++
- Operator Overloading In C++
- Function Overriding In C++
- Difference Between Function Overriding & Function Overloading In C++
- Conclusion
- Frequently Asked Questions
- What Is An Inline Function In C++?
- How To Define The Inline Function In C++?
- How Does Inline Function In C++ Work?
- The Need For An Inline Function In C++
- Can The Compiler Ignore/ Reject Inline Function In C++ Programs?
- Normal Function Vs. Inline Function In C++
- Classes & Inline Function In C++
- Understanding Inline, __inline, And __forceinline Functions In C++
- When To Use An Inline Function In C++?
- Advantages Of Inline Function In C++
- Disadvantages Of Inline Function In C++
- Why Not Use Macros Instead Of An Inline Function In C++?
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Is Static Data Member In C++?
- How To Declare Static Data Members In C++?
- How To Initialize/ Define Static Data Member In C++?
- Ways To Access A Static Data Member In C++
- What Are Static Member Functions In C++?
- Example Of Member Function & Static Data Member In C++
- Practical Applications Of Static Data Member In C++
- Conclusion
- Frequently Asked Questions
- What Is A Constant In C++?
- Ways To Define Constant In C++
- What Are Literals In C++?
- Pointer To A Constant In C++
- Constant Function Arguments In C++
- Constant Member Function Of Class In C++
- Constant Data Members In C++
- Object Constant In C++
- Conclusion
- Frequently Asked Questions(FAQ)
- What is the Friend Function in C++?
- Declaration of Friend Function in C++ with Example
- Characteristics of Friend Function in C++
- Types/ Ways to Implement Friend Function in C++
- Global Friend Function in C++ (Global Function as Friend Function )
- Member Function of Another Class as a Friend Function in C++
- Function Overloading Using Friend Function in C++
- Advantages & Disadvantages of Friend Function in C++
- Interview Spotlight: Friend Functions in Cognizant Interview
- What is a C++ Friend Class?
- A Function Friendly to Multiple Classes
- C++ Friend Class vs. Friend Function in C++
- Some Important Points About Friend Functions and Classes in C++
- Conclusion
- Frequently Asked Questions
- What Is Function Overriding In C++?
- The Working Mechanism Of Function Overriding In C++
- Real-Life Example Of Function Overriding In C++
- Accessing Overriding Function In C++
- Accessing Overridden Function In C++
- Function Call Binding With Class Objects | Function Overriding In C++
- Function Call Binding With Base Class Pointers | Function Overriding In C++
- Advantages Of Function Overriding In C++
- Variations In Function Overriding In C++
- Function Overloading In C++
- Function Overloading Vs Function Overriding In C++
- Conclusion
- Frequently Asked Questions
- Errors In C++
- What Is Exception Handling In C++?
- Exception Handling In C++ Program Example
- C++ Exception Handling: Basic Keywords
- The Need For C++ Exception Handling
- C++ Standard Exceptions
- C++ Exception Classes
- User-Defined Exceptions In C++
- Advantages & Disadvantages Of C++ Exception Handling
- Conclusion
- Frequently Asked Questions
- What Are Templates In C++ & How Do They Work?
- Types Of Templates In C++
- What Are Function Templates In C++?
- C++ Template Functions With Multiple Parameters
- C++ Template Function Overloading
- What Are Class Templates In C++?
- Defining A Class Member Outside C++ Template Class
- C++ Template Class With Multiple Parameters
- What Is C++ Template Specialization?
- How To Specify Default Arguments For Templates In C++?
- Advantages Of C++ Templates
- Disadvantages Of C++ Templates
- Difference Between Function Overloading And Templates In C++
- Conclusion
- Frequently Asked Questions
- Structure
- Structure Declaration
- Initialization of Structure
- Copying and Comparing Structures
- Array of Structures
- Nested Structures
- Pointer to a Structure
- Structure as Function Argument
- Self Referential Structures
- Class
- Object Declaration
- Accessing Class Members
- Similarities between Structure and Class
- Which One Should You Choose?
- Key Difference Between a Structure and Class
- Summing Up
- Test Your Skills: Quiz Time
- What Is A Class And Object In C++?
- What Is An Object In C++?
- How To Create A Class & Object In C++? With Example
- Interview Spotlight: Classes & Objects In Adobe & Pixar Interviews
- Access Modifiers & Class/ Object In C++
- Member Functions Of A Class In C++
- How To Access Data Members And Member Functions?
- Significance Of Class & Object In C++
- Did You Know? The Concept of Classes & Object Powers Major Apps
- What Are Constructors In C++ & Its Types?
- What Is A Destructor Of Class In C++?
- An Array Of Objects In C++
- Object In C++ As Function Arguments
- The this (->) Pointer & Classes In C++
- The Need For Semicolons At The End Of A Class In C++
- Conclusion
- Frequently Asked Questions
- What Are Static Members In C++?
- Static Member Functions in C++
- Ways To Call Static Member Function In C++
- Properties Of Static Member Function In C++
- Need Of Static Member Functions In C++
- Regular Member Function Vs. Static Member Function In C++
- Limitations Of Static Member Functions In C++
- Conclusion
- Frequently Asked Questions
- What Is Constructor In C++?
- Characteristics Of A Constructor In C++
- Types Of Constructors In C++
- Default Constructor In C++
- Parameterized Constructor In C++
- Copy Constructor In C++
- Dynamic Constructor In C++
- Benefits Of Using Constructor In C++
- How Does Constructor In C++ Differ From Normal Member Function?
- Constructor Overloading In C++
- Constructor For Array Of Objects In C++
- Constructor In C++ With Default Arguments
- Initializer List For Constructor In C++
- Dynamic Initialization Using Constructor In C++
- Conclusion
- Frequently Asked Questions
- What Is A Constructor In C++?
- What Is Constructor Overloading In C++?
- Dеclaration Of Constructor Ovеrloading In C++
- Condition For Constructor Overloading In C++
- How Constructor Ovеrloading In C++ Works?
- Examples Of Constructor Overloading In C++
- Lеgal & Illеgal Constructor Ovеrloading In C++
- Types Of Constructors In C++
- Characteristics Of Constructors In C++
- Advantage Of Constructor Overloading In C++
- Disadvantage Of Constructor Overloading In C++
- Conclusion
- Frеquеntly Askеd Quеstions
- What Is A Destructor In C++?
- Rules For Defining A Destructor In C++
- When Is A Destructor in C++ Called?
- Order Of Destruction In C++
- Default Destructor & User-Defined Destructor In C++
- Virtual Destructor In C++
- Pure Virtual Destructor In C++
- Key Properties Of Destructor In C++ You Must Know
- Explicit Destructor Calls In C++
- Destructor Overloading In C++
- Difference Between Normal Member Function & Destructor In C++
- Important Uses Of Destructor In C++
- Conclusion
- Frequently Asked Questions
- What Is A Constructor In C++?
- What Is A Destructor In C++?
- Difference Between Constructor And Destructor In C++
- Constructor In C++ | A Brief Explanation
- Destructor In C++ | A Brief Explanation
- Difference Between Constructor And Destructor In C++ Explained
- Order Of Calling Constructor And Destructor In C++ Classes
- Conclusion
- Frequently Asked Questions
- Test Your Skills: Quiz Time
- What Is Type Conversion In C++?
- What Is Type Casting In C++?
- Types Of Type Conversion In C++
- Implicit Type Conversion (Coercion) In C++
- Explicit Type Conversion (Casting) In C++
- Advantages Of Type Conversion In C++
- Disadvantages Of Type Conversion In C++
- Difference Between Type Casting & Type Conversion In C++
- Application Of Type Casting In C++
- Conclusion
- Frequently Asked Questions
- What Is A Copy Constructor In C++?
- Characteristics Of Copy Constructors In C++
- Types Of Copy Constructors In C++
- When Do We Call The Copy Constructor In C++?
- When Is A User-Defined Copy Constructor Needed In C++?
- Types Of Constructor Copies In C++
- Can We Make The Copy Constructor In C++ Private?
- Assignment Operator Vs Copy Constructor In C++
- Example Of Class Where A Copy Constructor Is Essential
- Uses Of Copy Constructors In C++
- Conclusion
- Frequently Asked Questions
- Why Do You Need Object-Oriented Programming (OOP) In C++?
- OOPs Concepts In C++ With Examples
- The Class OOPs Concept In C++
- The Object OOPs Concept In C++
- The Inheritance OOPs Concept In C++
- Polymorphism OOPs Concept In C++
- Abstraction OOPs Concept In C++
- Encapsulation OOPs Concept In C++
- Other Features Of OOPs In C++
- Benefits Of OOP In C++ Over Procedural-Oriented Programming
- Disadvantages Of OOPS Concept In C++
- Why Is C++ A Partial OOP Language?
- Conclusion
- Frequently Asked Questions
- Introduction To Abstraction In C++
- Types Of Abstraction In C++
- What Is Data Abstraction In C++?
- Understanding Data Abstraction In C++ Using Real Life Example
- Ways Of Achieving Data Abstraction In C++
- What Is An Abstract Class?
- Advantages Of Data Abstraction In C++
- Use Cases Of Data Abstraction In C++
- Encapsulation Vs. Abstraction In C++
- Conclusion
- Frequently Asked Questions
- What Is Encapsulation In C++?
- How Does Encapsulation Work In C++?
- Types Of Encapsulation In C++
- Why Do We Need Encapsulation In C++?
- Implementation Of Encapsulation In C++
- Access Specifiers & Encapsulation In C++
- Role Of Access Specifiers In Encapsulation In C++
- Member Functions & Encapsulation In C++
- Data Hiding & Encapsulation In C++
- Features Of Encapsulation In C++
- Advantages & Disadvantages Of Encapsulation In C++
- Difference Between Abstraction and Encapsulation In C++
- Conclusion
- Frequently Asked Questions
- What Is Inheritance In C++?
- What Are Child And Parent Classes?
- Syntax And Structure Of Inheritance In C++
- Implementing Inheritance In C++
- Importance Of Inheritance In C++
- Types Of Inheritance In C++
- Visibility Modes Of Inheritance In C++
- Access Modifiers & Inheritance In C++
- How To Make A Private Member Inheritable?
- Member Function Overriding In Inheritance In C++
- The Diamond Problem | Inheritance In C++ & Ambiguity
- Ways To Avoid Ambiguity Inheritance In C++
- Why & When To Use Inheritance In C++?
- Advantages Of Inheritance In C++
- The Disadvantages Of Inheritance In C++
- Conclusion
- Frequently Asked Questions
- What Is Hybrid Inheritance In C++?
- Importance Of Hybrid Inheritance In Object Oriented Programming
- Example Of Hybrid Inheritance In C++: Using Single and Multiple Inheritance
- Example Of Hybrid Inheritance In C++: Using Multilevel and Hierarchical Inheritance
- Real-World Applications Of Hybrid Inheritance In C++
- Conclusion
- Frequently Asked Questions
- What Is Multiple Inheritance In C++?
- Examples Of Multiple Inheritance In C++
- Ambiguity Problem In Multiple Inheritance In C++
- Ambiguity Resolution In Multiple Inheritance In C++
- The Diamond Problem In Multiple Inheritance In C++
- Visibility Modes In Multiple Inheritance In C++
- Advantages & Disadvantages Of Multiple Inheritance In C++
- Multiple Inheritance Vs. Multilevel Inheritance In C++
- Conclusion
- Frequently Asked Questions
- What Is Multilevel Inheritance In C++?
- Block Diagram For Multilevel Inheritance In C++
- Multilevel Inheritance In C++ Example
- Constructor & Multilevel Inheritance In C++
- Use Cases Of Multilevel Inheritance In C++
- Multiple Vs Multilevel Inheritance In C++
- Advantages & Disadvantages Of Multilevel Inheritance In C++
- Conclusion
- Frequently Asked Questions
- What Is Hierarchical Inheritance In C++?
- Example 1: Hierarchical Inheritance In C++
- Example 2: Hierarchical Inheritance In C++
- Impact of Visibility Modes In Hierarchical Inheritance In C++
- Advantages And Disadvantages Of Hierarchical Inheritance In C++
- Use Cases Of Hierarchical Inheritance In C++
- Conclusion
- Frequently Asked Questions
- What Are Access Specifiers In C++?
- Types Of Access Specifiers In C++
- Public Access Specifiers In C++
- Private Access Specifier In C++
- Protected Access Specifier In C++
- The Need For Access Specifiers In C++
- Combined Example For All Access Specifiers In C++
- Best Practices For Using Access Specifiers In C++
- Why Can't Private Members Be Accessed From Outside A Class?
- Conclusion
- Frequently Asked Questions
- What Is The Diamond Problem In C++?
- Example Of The Diamond Problem In C++
- Resolution Of The Diamond Problem In C++
- Virtual Inheritance To Resolve Diamond Problem In C++
- Scope Resolution Operator To Resolve Diamond Problem In C++
- Conclusion
- Frequently Asked Questions
Function Overloading In C++ With Code Examples & Explanation
Function overloading in C++ is when we define multiple functions of the same name but different parameter lists. When called, the compiler determines which function to invoke depending on the arguments passed.

The process of using a single identifier to name multiple functions/ methods with different number of input or output parameters is known as function overloading in C++. In other words, we use overloading when we want similar behavior in multiple methods having different sets of input and output parameters.
There are two types of overloading, namely, operator overloading and function overloading. In this article, we will focus on function overloading in C++ programming and explore all related topics. The primary benefit of function overloading is that it helps write clear and concise code and eliminates complexity while improving runtime complexity.
Types Of Overloading In C++
Overloading enhances code readability and reusability by providing a consistent interface for different variations of a function or operator. As we've mentioned before, there are two main types of overloading in C++ programming language:
- Function Overloading: This is the most common type of overloading. It involves defining multiple functions with the same name (in the same scope) but different parameter lists. The compiler selects the appropriate function to call based on the number and types of arguments provided during the function call. Function overloading is determined at compile-time.
- Operator Overloading: In C++, you can also overload various operators to work with user-defined data types, like classes or structs. In other words, it allows you to define custom behaviors for operators to be applied on user-defined objects, making code more intuitive and readable.
What Is Function Overloading In C++?
The ability to declare numerous functions with the same name but different parameters (types of parameters) is known as function overloading in C++. In other words, the function name is the same, but the function definition differs.
- Meaning, when a function is overloaded with many different jobs but has the same name for all, it is called function overloaded in C++.
- This is a feature of object-oriented programming and is built on the idea of polymorphism. It allows using a single function name to denote many behaviors depending on the parameters given.
- The compiler distinguishes between functions based on the quantity, nature, and arrangement of the arguments/ other parameters.
- So we can have multiple functions with the same name, but distinct parameters and function overloading will resolve at build time based on the function signature.
- Note that the compiler invoked the best-fitting function based on the inputs given to the function call during compilation. Since this is done during compile time, function overloading helps to improve runtime.
All in all, function overlading in C++ enables users to design functions that carry out related tasks but use different input parameters or data types. By giving meaningful names to functions that carry out identical responsibilities, function overloading offers a technique to enhance the organization, reuse, and readability of code.
This way, instead of resorting to writing many functions with various names for the same operations, it enables you to construct function names that are more descriptive and intuitive. Let’s take a look at the syntax for function overloading in C++, followed by an example.
Syntax:
return_type function_name(parameter_list1) {
// Function implementation
}
return_type function_name(parameter_list2) {
// Function implementation
}
// Additional overloaded functions
Here,
- return_type represents the data type of the value returned by the respective function.
- function_name is the name of the function, which will remain the same for all functions.
- parameter_list1, parameter_list2, and so on are the parameter lists for each overloaded function. They specify the number and types of the function's parameters.
Function Overloading Example In C++: Let's look at a simple C++ program example illustrating the concept of function overloading.
Code Example:
#include
using namespace std;
// Function to add two integers
int add(int a, int b) {
return a + b;}
// Function to add three integers
int add(int a, int b, int c) {
return a + b + c;}
// Function to concatenate two strings
string add(const std::string& str1, const std::string& str2) {
return str1 + str2;}
int main() {
int sum1 = add(10, 20);
int sum2 = add(10, 20, 30);
string result = add("Hello, ", "Unstop!");
cout << "Sum 1: " << sum1 << endl;
cout << "Sum 2: " << sum2 << endl;
cout << "Concatenated String: " << result << endl;
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgp1c2luZyBuYW1lc3BhY2Ugc3RkOwoKLy8gRnVuY3Rpb24gdG8gYWRkIHR3byBpbnRlZ2VycwppbnQgYWRkKGludCBhLCBpbnQgYikgewpyZXR1cm4gYSArIGI7fQoKLy8gRnVuY3Rpb24gdG8gYWRkIHRocmVlIGludGVnZXJzCmludCBhZGQoaW50IGEsIGludCBiLCBpbnQgYykgewpyZXR1cm4gYSArIGIgKyBjO30KCi8vIEZ1bmN0aW9uIHRvIGNvbmNhdGVuYXRlIHR3byBzdHJpbmdzCnN0cmluZyBhZGQoY29uc3Qgc3RkOjpzdHJpbmcmIHN0cjEsIGNvbnN0IHN0ZDo6c3RyaW5nJiBzdHIyKSB7CnJldHVybiBzdHIxICsgc3RyMjt9CgppbnQgbWFpbigpIHsKCgppbnQgc3VtMSA9IGFkZCgxMCwgMjApOwppbnQgc3VtMiA9IGFkZCgxMCwgMjAsIDMwKTsKc3RyaW5nIHJlc3VsdCA9IGFkZCgiSGVsbG8sICIsICJVbnN0b3AhIik7Cgpjb3V0IDw8ICJTdW0gMTogIiA8PCBzdW0xIDw8IGVuZGw7CmNvdXQgPDwgIlN1bSAyOiAiIDw8IHN1bTIgPDwgZW5kbDsKY291dCA8PCAiQ29uY2F0ZW5hdGVkIFN0cmluZzogIiA8PCByZXN1bHQgPDwgZW5kbDsKCnJldHVybiAwOwp9
Output:
Sum 1: 30
Sum 2: 60
Concatenated String: Hello, Unstop!
Explanation:
In the simple C++ code example, we first include the <iostream> header file for input/ output operations and use namespace.
- Then, we define a function add() with two parameters of int type. It performs addition arithmetic operations on the input values and returns their sum.
- We then define a second add() function, which takes three int type parameters, calculates their sum and returns the same.
- Next, we define a third add() function which takes constant reference to two strings as parameters, concatenates the strings and returns the outome.
- In the main() function, we call the add() function three times with different lists of input arguments, as follows:
- First, we call add(10,20) and store the result in variable sum1. This invokes the first add function since it has two variables of int type.
- Next, we call add(10,20,30) and store the result in variable sum2. This invoked the second add function with three integers as arguments.
- Then, we called add with two strings as arguments and stored the output in the variable result. This invokes the third add function, which returns the concatenated strings.
- After that, we use a set of cout statements to print all three results, i.e., sum1, sum2, and result, to the console.
- Finally, the main() function terminates with a return 0 statement indicating successful execution.
Note: The example clearly shows how the compiler invokes the required function based on the number and the type of arguments automatically.
Ways Of Function Overloading In C++
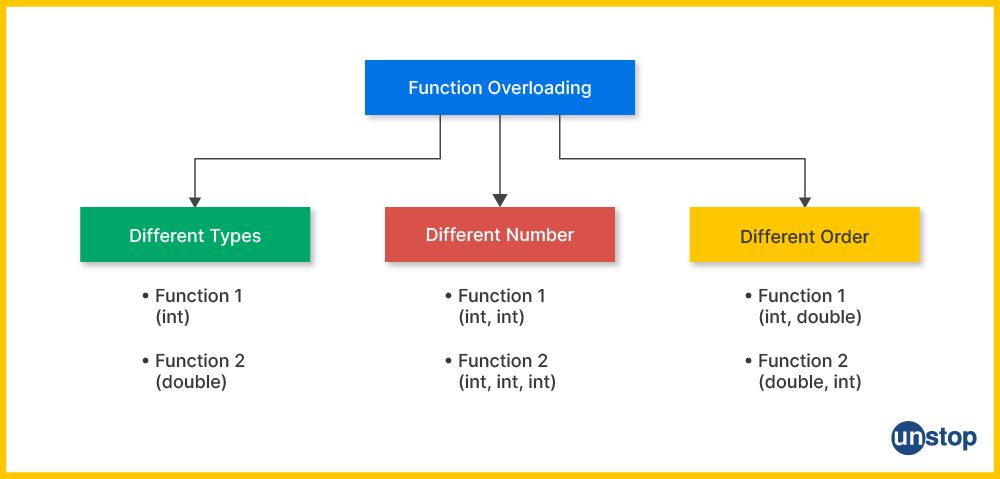
There are multiple ways to overload a function in C++ programming, including:
- Different types of parameter
- Different number of parameters
- Different sequences of parameters (i.e., different order)
You can use a method that meets the specific requirements. We will discuss each of these methods in greater detail and also look at examples in the section below.
Function Overloading In C++ Using Different Types Of Parameters
In this method, you define functions with the same name but multiple parameter types, i.e., you overload various types of parameters. This implies that you can design many functions that carry out comparable tasks but accept various data types of values as input. Based on the supplied argument types, the compiler determines which version of the function to call.
Syntax:
returnType functionName(parameterType1 parameter1) {
// Function implementation
}
returnType functionName(parameterType2 parameter2) {
// Function implementation
}
Here, syntax remains the same, but note that the parameter type will differ between the two function definitions. The term parameterType1 represents the data type of the 1st parameter, i.e., parameter1 itself.
Function Overloading Example In C++: The C++ program example below illustrates how to overload a function by defining it such that it takes different types.
Code Example:
#include
using namespace std;
void printValue(int A){
cout << endl << "Value of A : " << A;}
void printValue(char A){
cout << endl << "Value of A : " << A;
}
void printValue(float A){
cout << endl << "Value of A : " << A;
}
int main(){
printValue(10);
printValue('@');
printValue(3.14f);
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgp1c2luZyBuYW1lc3BhY2Ugc3RkOwoKdm9pZCBwcmludFZhbHVlKGludCBBKXsKY291dCA8PCBlbmRsIDw8ICJWYWx1ZSBvZiBBIDogIiA8PCBBO30KCnZvaWQgcHJpbnRWYWx1ZShjaGFyIEEpewpjb3V0IDw8IGVuZGwgPDwgIlZhbHVlIG9mIEEgOiAiIDw8IEE7Cn0KCnZvaWQgcHJpbnRWYWx1ZShmbG9hdCBBKXsKY291dCA8PCBlbmRsIDw8ICJWYWx1ZSBvZiBBIDogIiA8PCBBOwp9CgppbnQgbWFpbigpewpwcmludFZhbHVlKDEwKTsKcHJpbnRWYWx1ZSgnQCcpOwpwcmludFZhbHVlKDMuMTRmKTsKCnJldHVybiAwOwp9
Output:
Value of A : 10
Value of A : @
Value of A : 3.14
Explanation:
We begin the C++ code example by including the header for input and output stream operations and use namespace std to avoid having to write (std::) before every standard library function.
-
Then, we define three overloaded printValue() functions, each accepting a different data type of argument list, i.e., int type, char type, and float type, respectively.
-
All three functions print the value of the argument along with a descriptive message using the cout command.
-
In the main() function, we call the function three times where the type of arguments passed differ.
- The printValue(10) call invokes the function with an integer argument 10. This calls the printValue(int A) overload, and the output is 'Value of A : 10'.
- The printValue('@') call invokes the function with a character argument. This calls the second function, i.e., printValue(char A) overload, and the output is 'Value of A : @'.
- The printValue(3.14f) call invokes the function with a float argument type. This calls the third function, i.e., printValue(float A) overload, and the output is "Value of A : 3.14".
-
The return 0 statement in the main function indicates the successful execution of the program.
Function Overloading In C++ With Different Number Of Parameters
Overloading using a different number of parameters allows you to define multiple functions with the same name but a different number of parameters. The general syntax for function overloading remains the same, but the number of parameters that the function takes varies for each definition.
Syntax:
return_type function_name(parameter_type1 parameter1, parameter_type2 parameter2){
//function implementation
};
return_type function_name(parameter_type1 parameter1, parameter_type2 parameter2, ..., parameter_typeN parameterN){
//function implementation
};
Here, as you can see the functions parameter list differs in both the functions with the first function taking two parameters and the other one taking N function parameters. These numbers are just for referen, there is no foundation on the number of actual parameter you can include in your function definitions.
Function Overloading Example In C++: Below is an example illustrating this approach to function overloading in C++, followed by a detailed explanation.
Code Example:
#include
using namespace std;
// Function to calculate the sum of two integers
int add(int a, int b) {
return a + b;}
// Overloaded function to calculate the sum of three integers
int add(int a, int b, int c) {
return a + b + c;}
int main() {
int sum1 = add(10, 20);
int sum2 = add(10, 20, 30);
cout << "Sum 1: " << sum1 << endl;
cout << "Sum 2: " << sum2 << endl;
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgp1c2luZyBuYW1lc3BhY2Ugc3RkOwoKLy8gRnVuY3Rpb24gdG8gY2FsY3VsYXRlIHRoZSBzdW0gb2YgdHdvIGludGVnZXJzCmludCBhZGQoaW50IGEsIGludCBiKSB7CnJldHVybiBhICsgYjt9CgovLyBPdmVybG9hZGVkIGZ1bmN0aW9uIHRvIGNhbGN1bGF0ZSB0aGUgc3VtIG9mIHRocmVlIGludGVnZXJzCmludCBhZGQoaW50IGEsIGludCBiLCBpbnQgYykgewpyZXR1cm4gYSArIGIgKyBjO30KCmludCBtYWluKCkgewppbnQgc3VtMSA9IGFkZCgxMCwgMjApOwppbnQgc3VtMiA9IGFkZCgxMCwgMjAsIDMwKTsKCmNvdXQgPDwgIlN1bSAxOiAiIDw8IHN1bTEgPDwgZW5kbDsKY291dCA8PCAiU3VtIDI6ICIgPDwgc3VtMiA8PCBlbmRsOwoKcmV0dXJuIDA7Cn0=
Output:
Sum 1: 30
Sum 2: 60
Explanation:
- In the example above, we define two add() functions and overload them by changing the number of parameters they take.
- The first add() function takes two integer data type parameters, computes the sum and returns it.
- As mentioned in code comments, the second add() function takes three integer data type parameters, computes their sum and returns it.
- In the main() function, we declare a variable sum1 and assign it a value by calling add() function with arguments 10 and 20, i.e., add(10, 20).
- After receiving this function call the compiler will try to find a match between arguments given and the parameters in function definition. This call will invoke the first variation of the function which will calculate their sum.
- Similarly, the function call add(10, 20, 30) will invoke the second variation of the function with three parameters is invoked, and the outcome is saved in the variable sum2.
- We then print the final values of sum1 and sum2 using the cout statement.
Note: This example shows how the number and types of arguments supplied influence which version of the function the compiler calls.
Function Overloading In C++ Using Different Sequence Of Parameters
A function can be overloaded in C++ by altering the order of its parameters. As a result, you are able to define several functions with the same name but various parameter combinations. The types and order of the parameters help the compiler distinguish between these overloaded functions.
Syntax:
return_type function_name(type1 parameter, type2 parameter, etc.){
//Function Implementation
};return_type function_name(type2 parameter, type1 parameter, etc.){
//Function Implementation
};
Here, the general syntax syntax remains the same, but the parameter sequence in the function definition differs.
Function Overloading Example In C++:
#include
using namespace std;
void print(int a, double b) {
cout << "Printing int and double: " << a << ", " << b << endl;}
void print(double b, int a) {
cout << "Printing double and int: " << b << ", " << a << endl;}
int main() {
print(10, 3.14);
print(3.14, 10);
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgp1c2luZyBuYW1lc3BhY2Ugc3RkOwoKdm9pZCBwcmludChpbnQgYSwgZG91YmxlIGIpIHsKY291dCA8PCAiUHJpbnRpbmcgaW50IGFuZCBkb3VibGU6ICIgPDwgYSA8PCAiLCAiIDw8IGIgPDwgZW5kbDt9Cgp2b2lkIHByaW50KGRvdWJsZSBiLCBpbnQgYSkgewpjb3V0IDw8ICJQcmludGluZyBkb3VibGUgYW5kIGludDogIiA8PCBiIDw8ICIsICIgPDwgYSA8PCBlbmRsO30KCmludCBtYWluKCkgewpwcmludCgxMCwgMy4xNCk7CnByaW50KDMuMTQsIDEwKTsKcmV0dXJuIDA7Cn0=
Output:
Printing int and double: 10, 3.14
Printing double and int: 3.14, 10
Explanation:
- We begin by defining two overloaded functions named print(), both taking the same type of parameters by in the opposite sequence.
- The first print() function takes an int parameter first, followed by a double type parameter.
- The second print() function takes a double type for its first parameter and an integer type for the second.
- Note that both functions use the cout command. to print the values and do not return a value. They are, hence, declared with a void return type.
- In the main() function, we call the function twice with different formal argument lists. The compiler notes the arguments and calls a function with matching sequence.
- The call print(10, 3.14) invoked the first overloaded print function, printing the string message- 'Printing int and double: 10, 3.14'.
- The call print(3.14, 10) invokes the second overloaded print function, printing the string message- 'Printing double and int: 3.14, 10'.
- The program returns 0 to indicate successful execution.
How Does Function Overloading In C++ Work?
Function overloading in C++ allows you to define multiple functions with the same name but different parameter lists. This enables you to create a family of related functions that perform similar tasks but can handle different types or numbers of arguments.
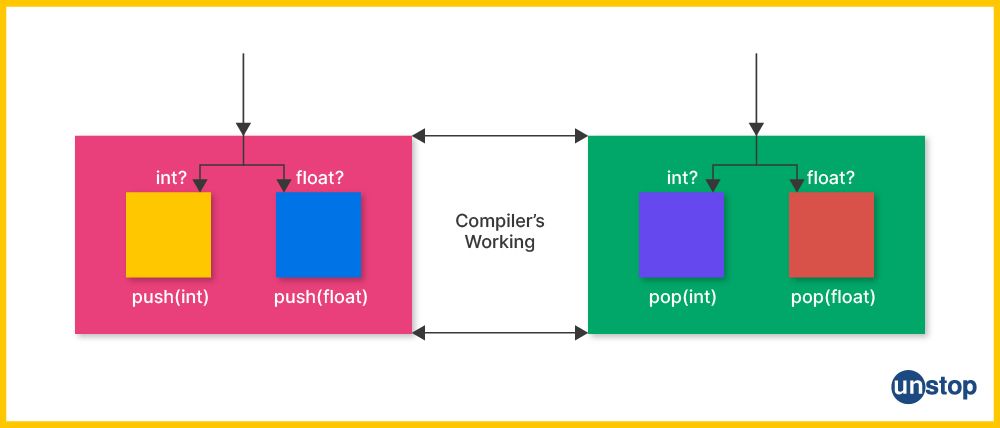
Also, function overloading is resolved by the compiler at compile time based on the arguments provided during a function call. Here is the step-by-step explanation of how function overloading in C++ works:
- Function Declaration: We declare multiple functions with the same name, performing similar tasks but differing in the number or sequence of parameters.
- Function Call: You can then call the function multiple times with a different set of arguments/ values of arguments.
- Matching Parameters: The compiler notes the arguments for matching functions with the parameter lists in overloaded function definitions and invokes the most appropriate function.
- Exact match: If the arguments match the parameters exactly in terms of number, type, and order, the compiler selects that function for execution. This is the ideal case where there is an exact match.
- Type conversion: If there is no exact match, the compiler looks for compatible types and performs type conversion.
- That is, it performs type conversions on the arguments to match the parameters of the overloaded functions.
- It tries to find the closest match as per the standard conversion rules, by converting the arguments to the required parameter types.
- Best match selection: The compiler selects the function with the best match. It considers the compatibility of types, the least number of conversions required, and the most specific parameter list.
- Function execution: The selected overloaded function is executed, and its corresponding code block is executed.
In conclusion, the compiler resolves function overloading in C++ at time of compilation based on the static types of the function arguments. The number of arguments, their types, and their appearance order are taken into account by the compiler when selecting the best match among the available overloaded functions. The most appropriate function with the best parameter list is chosen, and code is generated for just that function.
Rules Of Function Overloading In C++
We also have some rules to ensure proper function overloading in C++ programs. They are as follows:
- Function Name: Overloaded functions must have the same name.
- Parameter List: Overloaded functions must have different parameter lists. The parameters can differ in terms of number, type, or both. The order of the parameters is also significant.
- Return Type: The return type of the functions is not considered during function overloading. Overloaded functions can have the same or different return types.
- Function Signature: The function signature includes the function name and the parameter list. Overloaded functions must have different function signatures.
- Ambiguity: The overloaded functions should be distinguishable by the compiler. If the compiler cannot determine the best match during function call resolution due to ambiguous or conflicting overloaded functions, it will result in a compilation error.
- Default Arguments: Functions with default arguments can be overloaded. The presence or absence of default arguments is considered when resolving function calls.
Why Is Function Overloading Used?
There are multiple reasons of using function overloading in C++ such as to enhance code flexibility, readability, reusability, and make code maintenance easier.
- Readability and Intuitiveness: Using the same function name for related operations improves code clarity/ readability. Developers can easily understand the purpose of the function based on its name, regardless of the specific data types or arguments being used.
- Consistency: Function overloading in C++ allows you to provide a uniform interface for similar tasks. Users of the functions don't need to remember different function names for slight variations of the same operation.
- Code Reuse: Overloaded functions enable you to induce modularity in code design and make it reusable. That is, Once you have defined the core functionality, you can reuse the same function name across different parts of your codebase.
- Adaptation to Different Types: Overloading enables you to perform the same logical operation on different data types without needing to create distinct function names. This promotes code consistency and reduces redundancy.
- Default Arguments: Function overloading in C++ can be used in combination with default arguments. You can define multiple overloads of a function with varying numbers of arguments, and some of those arguments can have default values. This provides flexibility to callers who may not want to provide all arguments.
- Type Safety: Overloaded functions provide a way to enforce type safety without the need for complex runtime checks. The compiler ensures that the correct overload is selected based on the argument types used in the function call.
- Polymorphism: Function overloading in C++ is a form of static polymorphism, as the decision of which function to call is made at compile-time. This contrasts with dynamic polymorphism, which is achieved through virtual functions and is determined at runtime.
- Performance: Overloaded functions result in efficient code execution because the function resolution is determined at compile time. There's no need for runtime dispatch or lookups.
Function overloading in C++ hence allows you to define multiple functions with the same name but different parameter lists, providing a consistent interface for similar operations performed on different data types or with different numbers of arguments.
Types Of Function Overloading Based On Time Of Resolution
As we've mentioned before, function overloading in C++ is resolved at compile-time. That is the determination of which overloaded function to call is made before the program is executed.
- There is no explicit distinction between types of function overloading based on the time of resolution.
- The resolution process occurs during the compilation of the code, and the compiler selects the appropriate function based on the provided arguments and the available overloads.
- However, it's worth noting that C++ also supports runtime polymorphism through virtual functions and inheritance, which is achieved using features like function overriding and dynamic binding.
- This is a different concept from function overloading, as it involves selecting the appropriate function to call based on the runtime type of an object. This kind of polymorphism is based on the class hierarchy and is determined at runtime.
In summary, there is only one type of function overloading in C++, and it involves defining multiple functions with the same name but different parameter lists. The appropriate function to call is determined at compile-time based on the provided arguments and their types.
Causes Of Function Overloading In C++
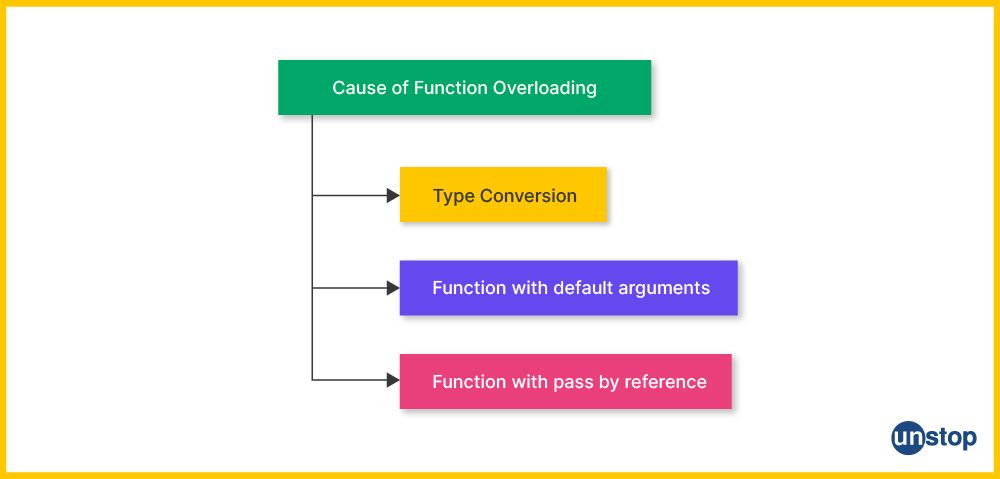
Function overloading provides developers with flexibility and ease of use by enabling them to define multiple versions of a function that perform similar tasks but on different data types or with different argument combinations. There are three primary causes of function overloading in C++ including:
- Type Conversion
- Function with default arguments
- Function with pass-by-reference
We will discuss each of these in the sections ahead.
Type Conversion & Function Overloading In C++
Function overloading can occur when there is a need to handle different types of input parameters by automatically converting them to the expected type of parameters.
- Type conversion in function overloading is done when there is no exact match between parameters and arguments in function declaration and call, respectively.
- In this situation, the compiler looks for compatible standard conversions that can be applied to the arguments to match the parameters of the overloaded functions.
- It tries to find the closest match by converting the arguments to the required parameter types.
For example, converting an integer to a floating-point number, float to double, or converting a string representation of a number to an actual numeric type, are standard type conversion scenarios.
Code Example:
#include
int main() {
int integerNum = 42;
double doubleNum = static_cast(integerNum); // Explicit casting
std::cout << "Integer: " << integerNum << std::endl;
std::cout << "Double: " << doubleNum << std::endl;
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgoKaW50IG1haW4oKSB7CmludCBpbnRlZ2VyTnVtID0gNDI7CmRvdWJsZSBkb3VibGVOdW0gPSBzdGF0aWNfY2FzdDxkb3VibGU+KGludGVnZXJOdW0pOyAvLyBFeHBsaWNpdCBjYXN0aW5nCgpzdGQ6OmNvdXQgPDwgIkludGVnZXI6ICIgPDwgaW50ZWdlck51bSA8PCBzdGQ6OmVuZGw7CnN0ZDo6Y291dCA8PCAiRG91YmxlOiAiIDw8IGRvdWJsZU51bSA8PCBzdGQ6OmVuZGw7CgpyZXR1cm4gMDsKfQ==
Output:
Integer: 42
Double: 42
Explanation:
In the code above-
- We declare an integer variable integerNum and initialize it with the value 42.
- Next, we declare a double variable doubleNum and use explicit type casting with static_cast<double>(integerNum) to convert the integer value to a double and assign it to doubleNum.
- We then print out the original integer value and the converted double value to the console using the std::cout command.
The output shows both the original integer value and the converted double value.
Function With Default Arguments & Function Overloading In C++
C++ allows function arguments to hold a default value that is used when no value is passed to the function argument in the function call. Often, when functions with a default value for their arguments are overloaded, it can lead to compilation errors, and we must pay extra attention to avoid such cases.
For example, consider a function that calculates the area of a rectangle. You could define default values for the width and the height but still allow the caller to provide different values when needed.
Code Example:
#include
int calculateArea(int width = 5, int height = 10) {
return width * height;
}
int main() {
int area1 = calculateArea(); // Uses default values
int area2 = calculateArea(8); // Uses default height
int area3 = calculateArea(6, 12); // Uses provided values
std::cout << "Area 1: " << area1 << std::endl;
std::cout << "Area 2: " << area2 << std::endl;
std::cout << "Area 3: " << area3 << std::endl;
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgoKaW50IGNhbGN1bGF0ZUFyZWEoaW50IHdpZHRoID0gNSwgaW50IGhlaWdodCA9IDEwKSB7CnJldHVybiB3aWR0aCAqIGhlaWdodDsKfQoKaW50IG1haW4oKSB7CmludCBhcmVhMSA9IGNhbGN1bGF0ZUFyZWEoKTsgLy8gVXNlcyBkZWZhdWx0IHZhbHVlcwppbnQgYXJlYTIgPSBjYWxjdWxhdGVBcmVhKDgpOyAvLyBVc2VzIGRlZmF1bHQgaGVpZ2h0CmludCBhcmVhMyA9IGNhbGN1bGF0ZUFyZWEoNiwgMTIpOyAvLyBVc2VzIHByb3ZpZGVkIHZhbHVlcwoKc3RkOjpjb3V0IDw8ICJBcmVhIDE6ICIgPDwgYXJlYTEgPDwgc3RkOjplbmRsOwpzdGQ6OmNvdXQgPDwgIkFyZWEgMjogIiA8PCBhcmVhMiA8PCBzdGQ6OmVuZGw7CnN0ZDo6Y291dCA8PCAiQXJlYSAzOiAiIDw8IGFyZWEzIDw8IHN0ZDo6ZW5kbDsKCnJldHVybiAwOwp9
Output:
Area 1: 50
Area 2: 80
Area 3: 72
Explanation:
- Here we first defined a function named calculateArea with two parameters of data type integer, named width and height.
- Both of these parameters have default values of 5 and 10, respectively.
- Then in the main() function:
-
- We first call the function without passing any arguments. This invokes the function with the default values being used.
- Next, we call the function with only the width argument specified, which invokes the function with the default height value.
- Lastly, we call the function with both width and height arguments specified. Here, none of the default values are used.
-
- Finally, we use the std:: cout to print the calculated areas for each case.
The output displays the calculated areas using different combinations of provided and default arguments.
Pass-By-Reference & Function Overloading In C++
As you might know, there are two ways to call a function, i.e., either by value or by reference. When parameters to a function are passed by their reference, such calls are referred to as a call by reference.
- When we try to overload functions that have parameters passed by reference, we should be extra careful because overloaded functions are often ambiguous.
- The compiler, in such cases, fails to differentiate between them and hence throws an error.
- Pass-by-reference can be more efficient than pass-by-value (making a copy of the data) for large data structures because it avoids unnecessary data duplication.
Code Example:
#include
void modifyValue(int &num) {
num *= 2;
}
int main() {
int value = 5;
std::cout << "Original Value: " << value << std::endl;
modifyValue(value);
std::cout << "Modified Value: " << value << std::endl;
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgoKdm9pZCBtb2RpZnlWYWx1ZShpbnQgJm51bSkgewpudW0gKj0gMjsKfQoKaW50IG1haW4oKSB7CmludCB2YWx1ZSA9IDU7CnN0ZDo6Y291dCA8PCAiT3JpZ2luYWwgVmFsdWU6ICIgPDwgdmFsdWUgPDwgc3RkOjplbmRsOwoKbW9kaWZ5VmFsdWUodmFsdWUpOwoKc3RkOjpjb3V0IDw8ICJNb2RpZmllZCBWYWx1ZTogIiA8PCB2YWx1ZSA8PCBzdGQ6OmVuZGw7CgpyZXR1cm4gMDsKfQ==
Output:
Original Value: 5
Modified Value: 10
Explanation:
- We begin by defining a function called modifyValue() which takes an interger parameter num by reference, i.e., int &num.
- Inside the function, the value of the parameter is doubled, i.e., it is multiplied by 2.
- Then inside the main() function-
- We declare an integer variable called value and initialize it with the value 5.
- We first print the original value of the variable using std::cout.
- Next, we call the modifyValue function by value as an argument.
- We once again print the modified value of the variable after calling the function.
The output shows the original value of the variable and then the value after it's modified within the function.
Ambiguity & Function Overloading In C++

As you must know by now, function overloading is a powerful tool in programming languages that allows you to define multiple functions with the same name but different parameter lists.
- This enables you to provide different implementations for various argument types or combinations.
- However, there are situations where function overloading can lead to ambiguity, making it challenging for the compiler to determine which function to call.
Ambiguity can arise if the compiler cannot clearly determine which overloaded function to call. This often happens when the arguments can be implicitly converted to multiple data types, leading to multiple potential function matches. Let's explore function overloading and ambiguity with a C++ code example.
Code Example:
#include
using namespace std;
void func(float f){
cout << "Overloaded Function with float parameter";}
void func(double d){
cout << "Overloaded Function with double parameter";}
int main(){
func('a');
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgp1c2luZyBuYW1lc3BhY2Ugc3RkOwoKdm9pZCBmdW5jKGZsb2F0IGYpewpjb3V0IDw8ICJPdmVybG9hZGVkIEZ1bmN0aW9uIHdpdGggZmxvYXQgcGFyYW1ldGVyIjt9Cgp2b2lkIGZ1bmMoZG91YmxlIGQpewpjb3V0IDw8ICJPdmVybG9hZGVkIEZ1bmN0aW9uIHdpdGggZG91YmxlIHBhcmFtZXRlciI7fQoKaW50IG1haW4oKXsKZnVuYygnYScpOwpyZXR1cm4gMDsKfQ==
Output:
ERROR!
g++ /tmp/26DShIzCDw.cpp
In function 'int main()':
error: call of overloaded 'func(char)' is ambiguous
25 | func('a');
| ~~~~^~~~~
/tmp/26DShIzCDw.cpp:5:6: note: candidate: 'void func(float)'
5 | void func(float f)
| ^~~~
/tmp/26DShIzCDw.cpp:13:6: note: candidate: 'void func(double)'
13 | void func(double d)
| ^~~~
Explanation:
In the above example-
- We define two functions called func, one with a float data type and the other with a data type double as parameters.
- Both functions print phrases using the cout command when called.
- Then, in the main() function, we call the function func with a character a.
- In this case, the compiler will first try to find an exact match, like a function func(char).
- When it does not find the exact match, it will try to auto-convert char to int. But we do not have a function with an interger type parameter either.
- This will lead the compiler to be confused between both implementations of func with type float and type double parameters.
- This ambiguity faced by the compiler gives rise to ambiguity errors in the code, as shown in the output.
Here are a few tips to help you avoid ambiguity in function overloading in C++:
- Use Different Parameter Types: Make sure that the parameter types for each overloaded function are distinct enough to prevent ambiguity. If you need similar behavior for different types, consider using a common base class or interface.
- Explicit Casting: If you want to call a specific overloaded function, you can explicitly cast the argument to the desired type to remove ambiguity.
- Avoid Implicit Conversions: Be cautious with implicit-type conversions. In some cases, it might be better to have separate function names rather than relying heavily on implicit conversions.
- Use Default Arguments: Instead of overloading with different types, you can use default arguments to achieve similar behavior without causing ambiguity.
Advantages Of Function Overloading In C++
Some of the most important advantages of function overloading in C++ are as follows:
- Improved Readability and Maintainability: Function overloading in C++ makes code easier to read and maintain. You can design expressive and understandable interfaces by offering multiple functions with the same name but various parameter lists. Based on the functions' names and parameter types, developers can quickly understand their intent and behavior. This makes code simpler to read, maintain, and troubleshoot.
- Code Reusability: Overloading functions encourage code reuse. Function overloading in C++ can be used to perform similar operations on various data types or different parameter combinations without having to create separate functions with unique names. It enables you to specify a single function name and offer multiple iterations that deal with various parameter arrangements. This lessens code duplication and enhances code structure, as well as reduces memory space.
- Polymorphism and Flexibility: One of the mechanisms that makes polymorphism possible in C++ is function overloading. Writing code that can handle various variations of parameters or operate on various types of data is made possible by polymorphism. By providing multiple implementations that cater to the various types or variations of parameters, you can overload functions and increase the flexibility and scenario-adjustability of your code.
- Type Safety: Function overloading makes your code more type-safe. For particular parameter types, you can impose type checking at compile time by defining overloaded functions. This encourages robust code execution and aids in the early detection of potential type-related errors. Overloaded functions provide a mechanism for handling various data types in a type-safe way.
- Compatibility and Scalability: By using function overloading in C++, you can increase the functionality of existing code without changing the way that it currently calls for functions. In the future, you can simply add overloaded versions of the function without changing the existing function calls to support new variations or types of parameters. This guarantees your codebase's scalability and backward compatibility.
Disadvantages Of Function Overloading In C++
Some of the most common disadvantages of function overloading, which act as an advisement to proceed with caution, are:
- Ambiguity: When multiple functions with the same name but different parameter lists are defined, it can sometimes be challenging for the compiler to determine the correct function to call. This can lead to compilation errors or unexpected behavior.
- Increased complexity: It becomes difficult to understand the code when there are too many overloaded functions with the same name. This makes debugging difficult.
- Maintenance: The maintenance of code also becomes difficult to manage. Moreover, when we change one particular function, and that change also needs to be applied to all overloaded functions, it becomes difficult.
Despite the disadvantages, function overloading overall is a very beneficial and powerful feature in C++.
Operator Overloading In C++
Operator overloading in C++ allows you to redefine the behavior of built-in operators when they are used with user-defined classes or types.
- This powerful feature enables you to use operators like arithmetic (+, -, *, /) and other operators like (==, !=, <, >), etc., with custom objects, making the code more intuitive and readable.
- Operator overloading is a key aspect of C++'s support for creating user-friendly and expressive classes.
By overloading operators, you can define how objects interact with these operators and control the behavior of expressions involving custom types. This concept is especially useful for creating domain-specific classes (e.g., matrices, complex numbers, strings) that need to adhere to their own rules for operations.
Syntax:
class ClassName {
public:
returnType operator@ (parameters) {
// Operator implementation
}
};
Here,
- The symbol @ represents the operator we want to overload.
- The operator keyword is followed by the overloaded operator or the operator being overloaded.
- Access specifier public determines the visibility of the class member, and the returnType refers to the type of return value of the overloaded operator.
For more, read- Operator Overloading In C++ And Related Concepts (With Examples)
Function Overriding In C++
Function overriding in C++ occurs when a derived class (or child class) provides its own implementation of a member function that is already defined in its base class (or parent class).
- The derived class overrides the behavior of the base class function with its own implementation.
- Function overriding is a fundamental concept in object-oriented programming and allows for polymorphism and dynamic binding.
It allows derived classes to provide specialized behavior while still adhering to the interface defined by the parent class. Function/ method overriding hence enables polymorphism, where objects of different types can be treated interchangeably through base class pointers or references.
Syntax:
class BaseClass {
public:
virtual returnType functionName(parameters) {
// Base class function implementation
}
};class DerivedClass : public BaseClass {
public:
returnType functionName(parameters) override {
// Derived class function implementation (override)
}
};
Here,
- BaseClass: Define the base class that contains the function you want to override.
- virtual: This keyword marks the function you intend to override. It tells the compiler that this function can be overridden in derived classes.
- returnType: Specifies the return type of the function.
- functionName: Refers to the name of the function you wish to override.
- parameters: Defines the same parameters as in the base class function.
- DerivedClass: Creates the derived class that inherits from the base class.
- override: In the derived class, we use the override keyword after the function declaration to explicitly indicate that you are intending to override a function from the base class. This helps catch errors at compile-time if the function signature doesn't match a base class function.
- function implementation: Inside the derived class, provide the implementation of the overridden function.
Remember that function/ method overriding involves maintaining the same function name and parameters while changing the implementation in the derived class. This enables dynamic polymorphism, where the appropriate version of the function is invoked at runtime based on the actual object type.
Read for more: Function Overriding In C++ | Working, Call Binding & More (+Codes)
Difference Between Function Overriding & Function Overloading In C++
Here are some of the differences between function overloading and function overriding:
|
Aspect |
Function Overloading |
Function Overriding |
|
Definition |
Multiple functions with the same name but different parameter lists. |
Redefining a base class's virtual function in a derived class. |
|
Occurs in |
In a single/ correct scope (or even class). |
Between a base class and its derived class. |
|
Return type |
It can either be same or different. |
It must be the same. |
|
Parameter list |
It must be different (number, type, or order of parameters). |
It must be the same (number, type, and order of parameters). |
|
Binding |
Compile-time (Static binding) |
Runtime (Dynamic binding) |
|
Usage |
Providing multiple functions with different behaviors |
Redefining the behavior of a base class's function in derived classes. |
|
Example |
void print(int x); |
Base class: Derived class: |
Conclusion
Function overloading in C++ allows developers to define multiple functions with a common name while accommodating diverse parameter lists. In this way, it enhances code readability, reusability, and consistency. This feature is particularly valuable when dealing with various data types, handling different argument counts, and performing similar operations across distinct scenarios.
By adhering to the rules of function overloading and carefully designing overloaded functions, developers can harness the full potential of this feature. They can also convey their intentions clealery with intuitive and consistent function names, thus facilitating an easier understanding of the codebase. The benefits of function overloading include, improved code organization, reduced redundancy, and enhanced adaptability, etc., which render it an indispensable technique for C++ programmers aiming to create high-quality software.
Also read- 51 C++ Interview Questions For Freshers & Experienced (With Answers)
Quiz Time!!!
Frequently Asked Questions
Q. What are the different types of overloading in C++?
Function Overloading: In function overloading, a scope (or class) can have multiple function (or member functions) with the same name but different parameter lists. These functions perform related tasks but can operate on different types of data or handle different variations of input. The compiler selects the appropriate function to call based on the arguments provided during the function call. For Example:
class MathOperations {
public:
int add(int a, int b);
double add(double a, double b);
};
In this example, the MathOperations class has two add functions with different parameter types. The compiler will choose the correct function to call based on the argument types used in the call.
Operator Overloading: Operator overloading allows you to redefine the behavior of operators (such as +, -, *, /, etc.) for user-defined classes. By overloading operators, you can make your class objects behave like built-in types when used with operators. For Example:
class Vector {
public:
int x, y;
Vector operator+(const Vector& other) {
Vector result;
result.x = this->x + other.x;
result.y = this->y + other.y;
return result;
}
};
In this example, the + operator is overloaded for the Vector class. This allows you to add two Vector objects using the + operator.
Q. What are the four rules of operator overloading in C++?
Operator overloading has many rules which should be taken care of. Some of these are:
- Overloading an operator cannot change its precedence.
- Overloading an operator cannot change its associativity.
- Overloading an operator cannot change its "arity" (i.e. number of operands).
- It is not possible to create new operators -- only new versions of existing ones are allowed.
- Some operators like assignment (=), address(&), and comma(,) are by default overloaded.
Q. Is function overloading in C++ an example of polymorphism?
Yes, function overloading can be considered an example of polymorphism. It is in fact a form of compile-time polymorphism where a single function name is used to perform many tasks.
- Function overloading in C++ allows programmers to offer various implementations of a function that carry out the same operations but have different sets of parameters.
- This give the flexibility to manage various situations or cases with ease and gives the user a more expressive and understandable interface.
- The number, kind, and order of the parameters supplied in the function call are used by the compiler to distinguish between the overloaded functions during compilation.
- Based on the matching parameter list, it decides which version of the function to be used while executing it.
Q. What is overloading in OOPS?
In object-oriented programming (OOP), overloading refers to the ability to define multiple functions or operators with the same name but different parameter lists.
- This allows us to provide different implementations of a function or operator based on the types or number of arguments provided.
- Function overloading and operator overloading are two common types of overloading in OOP.
Overloading is a powerful feature in OOP that enhances code readability and reusability. However, overloading should be used thoughtfully to provide consistent behavior and avoid confusion for the developers using the class.
Q. Can a function have two return types?
No, in C++, a function cannot have two distinct return types. Each function in C++ has a single specified return type, which is declared in the function's signature.
- When you declare a function, you define its return type using a specific data type, like int, double, char, void, or a user-defined class.
- This return type determines the type of value the function is expected to return to its caller.
- Attempting to have two different return types for a single function would lead to ambiguity and conflicts in the program's behavior.
Q. Can a function have 2 return statements in C++?
Yes, a function in C++ can have multiple return statements. Each return statement allows the function to return a value and terminate its execution. The use of multiple return statements can be particularly useful in cases where different conditions within the function might lead to different return values.
Here's an example:
int max(int a, int b) {
if (a > b) {
return a;
} else {
return b;
}
}
In this example, the function max takes two integers as arguments and returns the larger of the two. Depending on the comparison result, either the return a or the return b. It is important to note that once a return statement is executed, the function's execution is terminated, and no more code within the function will be executed.
So, in the example above, if a is indeed greater than b, the return a statement will execute, and the function will immediately return the value of a without considering the return b statement.
Q. Can a function be overloaded only by its return type?
No, in C++, a function cannot be overloaded based solely on its return type. Function overloading is determined by the function's signature, which includes the function name and its parameter list. The return type of a function is not considered when determining which overloaded function to call.
This rule is in place to avoid ambiguity in function calls. If the return type were used to differentiate overloaded functions, it could lead to situations where the compiler cannot uniquely determine which function to call based on the arguments and the desired return type.
For example, consider the following hypothetical scenario:
int add(int a, int b);
double add(int a, int b);
If overloading by return type were allowed, calling add(3, 5) would be ambiguous because both overloads could potentially match the function call. To differentiate between overloaded functions, you must vary the function's parameter list (including the types or number of parameters), but not just the return type.
This compiles the discussion on function overloading in C++. You might also be interested in reading the following:
- Dynamic Memory Allocation In C++ Explained In Detail (With Examples)
- Friend Function In C++ Classes | Types, Uses & More (+Examples)
- Inline Function In C++ | Declaration, Working, Examples & More!
- What is Function Prototype In C++ (Definition, Purpose, Examples)
- Array In C++ | Ultimate Guide On Creation, Types & More (Examples)
Login to continue reading
And access exclusive content, personalized recommendations, and career-boosting opportunities.
Don't have an account? Sign up
Never miss an
Update

Featured Opportunities
Top-Rated Practice by Students





Subscribe
to our newsletter



Comments
Add comment