
Asian Paints Alchemy 2026
Company Interview Questions for Freshers
- TCS Technical Interview Questions & Answers
- TCS Managerial Interview Questions & Answers
- TCS HR Interview Questions & Answers
- Overview of Cognizant Recruitment Process
- Cognizant Interview Questions: Technical
- Cognizant Interview Questions: HR Round
- Overview of Wipro Technologies Recruitment Rounds
- Wipro Interview Questions
- Technical Round
- HR Round
- Online Assessment Sample Questions
- Frequently Asked Questions
- Overview of Google Recruitment Process
- Google Interview Questions: Technical
- Google Interview Questions: HR round
- Interview Preparation Tips
- About Google
- Deloitte Technical Interview Questions
- Deloitte HR Interview Questions
- Deloitte Recruitment Process
- Technical Interview Questions and Answers
- Level 1 difficulty
- Level 2 difficulty
- Level 3 difficulty
- Behavioral Questions
- Eligibility Criteria for Mindtree Recruitment
- Mindtree Recruitment Process: Rounds Overview
- Skills required to crack Mindtree interview rounds
- Mindtree Recruitment Rounds: Sample Questions
- About Mindtree
- Preparing for Microsoft interview questions
- Microsoft technical interview questions
- Microsoft behavioural interview questions
- Aptitude Interview Questions
- Technical Interview Questions
- Easy
- Intermediate
- Hard
- HR Interview Questions
- Eligibility criteria
- Recruitment rounds & assessments
- Tech Mahindra interview questions - Technical round
- Tech Mahindra interview questions - HR round
- Hiring process at Mphasis
- Mphasis technical interview questions
- Mphasis HR interview questions
- About Mphasis
- Technical interview questions
- HR interview questions
- Recruitment process
- About Virtusa
- Goldman Sachs Interview Process
- Technical Questions for Goldman Sachs Interview
- Sample HR Question for Goldman Sachs Interview
- About Goldman Sachs
- Nagarro Recruitment Process
- Nagarro HR Interview Questions
- Nagarro Aptitude Test Questions
- Nagarro Technical Test Questions
- About Nagarro
- PwC Recruitment Process
- PwC Technical Interview Questions: Freshers and Experienced
- PwC Interview Questions for HR Rounds
- PwC Interview Preparation
- Frequently Asked Questions
- EY Technical Interview Questions (2023)
- EY Interview Questions for HR Round
- About EY
- Morgan Stanley Recruitment Process
- HR Questions for Morgan Stanley Interview
- HR Questions for Morgan Stanley Interview
- About Morgan Stanley
- Recruitment Process at Flipkart
- Technical Flipkart Interview Questions
- Code-Based Flipkart Interview Questions
- Sample Flipkart Interview Questions- HR Round
- Conclusion
- FAQs
- Recruitment Process at Paytm
- Technical Interview Questions for Paytm Interview
- HR Sample Questions for Paytm Interview
- About Paytm
- Most Probable Accenture Interview Questions
- Accenture Technical Interview Questions
- Accenture HR Interview Questions
- Amazon Recruitment Process
- Amazon Interview Rounds
- Common Amazon Interview Questions
- Amazon Interview Questions: Behavioral-based Questions
- Amazon Interview Questions: Leadership Principles
- Company-specific Amazon Interview Questions
- 43 Top Technical/ Coding Amazon Interview Questions
- Juspay Recruitment: Stages and Timeline
- Juspay Interview Questions and Answers
- How to prepare for Juspay interview questions
- Prepare for the Juspay Interview: Stages and Timeline
- Frequently Asked Questions
- Adobe Interview Questions - Technical
- Adobe Interview Questions - HR
- Recruitment Process at Adobe
- About Adobe
- Cisco technical interview questions
- Sample HR interview questions
- The recruitment process at Cisco
- About Cisco
- JP Morgan interview questions (Technical round)
- JP Morgan interview questions HR round)
- Recruitment process at JP Morgan
- About JP Morgan
- Wipro Elite NTH: Selection Process
- Wipro Elite NTH Technical Interview Questions
- Wipro Elite NTH Interview Round- HR Questions
- BYJU's BDA Interview Questions
- BYJU's SDE Interview Questions
- BYJU's HR Round Interview Questions
- A Quick Overview of the KPMG Recruitment Process
- Technical Questions for KPMG Interview
- HR Questions for KPMG Interview
- About KPMG
- DXC Technology Interview Process
- DCX Technical Interview Questions
- Sample HR Questions for DXC Technology
- About DXC Technology
- Recruitment Process at PayPal
- Technical Questions for PayPal Interview
- HR Sample Questions for PayPal Interview
- About PayPal
- Capgemini Recruitment Rounds
- Capgemini Interview Questions: Technical round
- Capgemini Interview Questions: HR round
- Preparation tips
- FAQs
- Technical interview questions for Siemens
- Sample HR questions for Siemens
- The recruitment process at Siemens
- About Siemens
- HCL Technical Interview Questions
- HR Interview Questions
- HCL Technologies Recruitment Process
- List of EPAM Interview Questions for Technical Interviews
- About EPAM
- Atlassian Interview Process
- Top Skills for Different Roles at Atlassian
- Atlassian Interview Questions: Technical Knowledge
- Atlassian Interview Questions: Behavioral Skills
- Atlassian Interview Questions: Tips for Effective Preparation
- Walmart Recruitment Process
- Walmart Interview Questions and Sample Answers (HR Round)
- Walmart Interview Questions and Sample Answers (Technical Round)
- Tips for Interviewing at Walmart and Interview Preparation Tips
- Frequently Asked Questions
- Uber Interview Questions For Engineering Profiles: Coding
- Technical Uber Interview Questions: Theoretical
- Uber Interview Question: HR Round
- Uber Recruitment Procedure
- About Uber Technologies Ltd.
- Intel Technical Interview Questions
- Computer Architecture Intel Interview Questions
- Intel DFT Interview Questions
- Intel Interview Questions for Verification Engineer Role
- Recruitment Process Overview
- Important Accenture HR Interview Questions
- Points to remember
- What is Selenium?
- What are the components of the Selenium suite?
- Why is it important to use Selenium?
- What's the major difference between Selenium 3.0 & Selenium 2.0?
- What is Automation testing and what are its benefits?
- What are the benefits of Selenium as an Automation Tool?
- What are the drawbacks to using Selenium for testing?
- Why should Selenium not be used as a web application or system testing tool?
- Is it possible to use selenium to launch web browsers?
- What does Selenese mean?
- What does it mean to be a locator?
- Identify the main difference between "assert", and "verify" commands within Selenium
- What does an exception test in Selenium mean?
- What does XPath mean in Selenium? Describe XPath Absolute & XPath Relation
- What is the difference in Xpath between "//"? and "/"?
- What is the difference between "type" and the "typeAndWait" commands within Selenium?
- Distinguish between findElement() & findElements() in context of Selenium
- How long will Selenium wait before a website is loaded fully?
- What is the difference between the driver.close() and driver.quit() commands in Selenium?
- Describe the different navigation commands that Selenium supports
- What is Selenium's approach to the same-origin policy?
- Explain the difference between findElement() in Selenium and findElements()
- Explain the pause function in SeleniumIDE
- Explain the differences between different frameworks and how they are connected to Selenium's Robot Framework
- What are your thoughts on the Page Object Model within the context of Selenium
- What are your thoughts on Jenkins?
- What are the parameters that selenium commands come with a minimum?
- How can you tell the differences in the Absolute pathway as well as Relative Path?
- What's the distinction in Assert or Verify declarations within Selenium?
- What are the points of verification that are in Selenium?
- Define Implicit wait, Explicit wait, and Fluent
- Can Selenium manage windows-based pop-ups?
- What's the definition of an Object Repository?
- What is the main difference between obtainwindowhandle() as well as the getwindowhandles ()?
- What are the various types of Annotations that are used in Selenium?
- What is the main difference in the setsSpeed() or sleep() methods?
- What is the way to retrieve the alert message?
- How do you determine the exact location of an element on the web?
- Why do we use Selenium RC?
- What are the benefits or advantages of Selenium RC?
- Do you have a list of the technical limitations when making use of Selenium RC? Selenium RC?
- What's the reason to utilize the TestNG together with Selenium?
- What Language do you prefer to use to build test case sets in Selenium?
- What are Start and Breakpoints?
- What is the purpose of this capability relevant in relation to Selenium?
- When do you use AutoIT?
- Do you have a reason why you require Session management in Selenium?
- Are you able to automatize CAPTCHA?
- How can we launch various browsers on Selenium?
- Why should you select Selenium rather than QTP (Quick Test Professional)?
- Airbus Interview Questions and Answers: HR/ Behavioral
- Industry/ Company-Specific Airbus Interview Questions
- Airbus Interview Questions and Answers: Aptitude
- Airbus Software Engineer Interview Questions and Answers: Technical
- Importance of Spring Framework
- Spring Interview Questions (Basic)
- Advanced Spring Interview Questions
- C++ Interview Questions and Answers: The Basics
- C++ Interview Questions: Intermediate
- C++ Interview Questions And Answers With Code Examples
- C++ Interview Questions and Answers: Advanced
- Test Your Skills: Quiz Time
- MBA Interview Questions: B.Com Economics
- B.Com Marketing
- B.Com Finance
- B.Com Accounting and Finance
- Business Studies
- Chartered Accountant
- Q1. Please tell us something about yourself/ Introduce yourself to us.
- Q2. Describe yourself in one word.
- Q3. Tell us about your strengths and weaknesses.
- Q4. Why did you apply for this job/ What attracted you to this role?
- Q5. What are your hobbies?
- Q6. Where do you see yourself in five years OR What are your long-term goals?
- Q7. Why do you want to work with this company?
- Q8. Tell us what you know about our organization
- Q9. Do you have any idea about our biggest competitors?
- Q10. What motivates you to do a good job?
- Q11. What is an ideal job for you?
- Q12. What is the difference between a group and a team?
- Q13. Are you a team player/ Do you like to work in teams?
- Q14. Are you good at handling pressure/ deadlines?
- Q15. When can you start?
- Q16. How flexible are you regarding overtime?
- Q17. Are you willing to relocate for work?
- Q18. Why do you think you are the right candidate for this job?
- Q19. How can you be an asset to the organization?
- Q20. What is your salary expectation?
- Q21. How long do you plan to remain with this company?
- Q22. What is your objective in life?
- Q23. Would you like to pursue your Master's degree anytime soon?
- Q24. How have you planned to achieve your career goal?
- Q25. Can you tell us about your biggest achievement in life?
- Q26. What was the most challenging decision you ever made?
- Q27. What kind of work environment do you prefer to work in?
- Q28. What is the difference between a smart worker and a hard worker?
- Q29. What will you do if you don't get hired?
- Q30. Tell us three things that are most important for you in a job.
- Q31. Who is your role model and what have you learned from him/her?
- Q32. In case of a disagreement, how do you handle the situation?
- Q33. What is the difference between confidence and overconfidence?
- Q34. If you have more than enough money in hand right now, would you still want to work?
- Q35. Do you have any questions for us?
- Interview Tips for Freshers
- Tell me about yourself
- What are your greatest strengths?
- What are your greatest weaknesses?
- Tell me about something you did that you now feel a little ashamed of
- Why are you leaving (or did you leave) this position??
- 15+ resources for preparing most-asked interview questions
- CoCubes Interview Process Overview
- Common CoCubes Interview Questions
- Key Areas to Focus on for CoCubes Interview Preparation
- Conclusion
- Frequently Asked Questions (FAQs)
- Data Analyst Interview Questions With Answers
- About Data Analyst
30+ Walmart Interview Questions With Answers (Technical + HR)

Did you know that the success rate of a Walmart interview can be as low as 2%? That's right, out of every hundred applicants, only two make it through the rigorous selection process. So if you're looking to land a job at Walmart, it's crucial to be prepared for their interview questions.
Walmart interview questions can vary depending on the position you're applying for. In this article, we will be covering the Walmart interview questions for software engineer roles.
By familiarizing yourself with these types of questions and practicing your responses, you'll increase your chances of acing your next Walmart interview.
Walmart Recruitment Process
Walmart conducts multi-stage recruitment process to hire candidates for engineering roles. The stages involve written rounds and interview rounds. Below is an overview of all the rounds:
Walmart uses a rigorous selection process to identify candidates who possess the right skills and fit well with their company culture. The selection criteria vary based on factors such as Walmart job requirements, qualifications, and experience. The hiring team carefully reviews applications and resumes to shortlist candidates who meet the necessary criteria.
The timeline for Walmart's hiring process can vary depending on several factors, such as the number of applicants and the urgency to fill a position. On average, it can take anywhere from a few weeks to a couple of months to complete all stages of the process. It's important to remain patient and proactive during this time.

Remember, each candidate's experience may differ based on their specific circumstances and role they're applying for. So stay positive, prepare well for each stage of the process, and give it your best shot!
Walmart Interview Questions and Sample Answers (HR Round)
It's essential to be prepared for the questions that may come your way.
Tell me about yourself
This question is often used as an icebreaker to get the conversation started. It's important to keep your response concise and focused on relevant information when answering the 'Tell me about yourself' question. You can start by giving a brief overview of your background, highlighting any previous work experience or education that is applicable to the position you are applying for. Remember to emphasize your skills, strengths, and achievements that make you a good fit for the role.
Why do you want to work for Walmart?
The interviewer wants to know what motivates you to join their team specifically. When answering this question, avoid generic responses such as "I need a job" or "I heard it pays well." Instead, focus on what attracts you to Walmart as a company. You could mention their commitment to providing affordable products and excellent customer service or their opportunities for career growth and development. Show enthusiasm for the company culture and values. (Read: Answering 'why do you want work here?')
How would you handle a difficult customer situation?
Customer service is crucial in any retail setting, including Walmart. This question aims to assess your ability to handle challenging situations professionally and calmly. In your response, emphasize the importance of active listening and empathy towards customers' concerns or complaints. Provide an example from past experience where you successfully resolved a difficult customer situation by remaining calm, finding a solution, and ensuring customer satisfaction.
Describe a time when you had to work as part of a team.
Working effectively in teams is vital at Walmart since collaboration plays an essential role in achieving goals efficiently. When responding to this question, choose an example from your previous experiences where teamwork was necessary for success. Highlight your ability to communicate effectively, cooperate with others, and contribute positively to the team's objectives. Mention any challenges you faced and how you overcame them through teamwork.
How do you keep up-to-date with industry best practices and emerging technologies?
To ensure that I am constantly learning and growing in my field, I utilize a variety of strategies. I make it a priority to attend industry conferences and workshops regularly. I actively participate in online forums and discussion boards dedicated to IT and technology. I also subscribe to industry-specific newsletters and publications, which deliver relevant and timely information straight to my inbox. These resources often include articles, case studies, and interviews with thought leaders, helping me stay informed about best practices and emerging technologies. In addition to external sources, I also engage in continuous learning through online courses and certifications.
Walmart Interview Questions and Sample Answers (Technical Round)
Programming and Coding
Q1. Write code to reverse a string in your preferred programming language.
CODE SNIPPET IS HEREI2luY2x1ZGUgPGJpdHMvc3RkYysrLmg+Cgp1c2luZyBuYW1lc3BhY2Ugc3RkOwoKaW50IG1haW4oKSB7CnN0cmluZyB4OwpjaW4gPj4geDsKc3RyaW5nIHJldmVyc2VfeDsKaW50IE4gPSB4LnNpemUoKTsKZm9yIChpbnQgaSA9IE4gLSAxOyBpID49IDA7IC0taSkgewpyZXZlcnNlX3ggKz0geFtpXTsKfQpjb3V0IDw8IHJldmVyc2VfeDsKcmV0dXJuIDA7Cn0=
This program takes an input string, reverses it, and prints the reversed string. It does so by reading the input (x), iterating through its characters in reverse order, and appending them to a new string (reverse_x), effectively reversing it.
Q2. Implement a binary search algorithm and explain its time complexity.
The binary search algorithm works by repeatedly dividing the search space in half. It starts with the entire array and compares the middle element to the target value. Depending on the comparison result, it narrows down the search space to the left or right half and continues this process until the target element is found or the search interval becomes empty.
CODE SNIPPET IS HEREI2luY2x1ZGUgPGlvc3RyZWFtPgojaW5jbHVkZSA8dmVjdG9yPgoKaW50IGJpbmFyeVNlYXJjaChjb25zdCBzdGQ6OnZlY3RvcjxpbnQ+ICZhcnIsIGludCB0YXJnZXQpIHsKaW50IGxlZnQgPSAwOwppbnQgcmlnaHQgPSBhcnIuc2l6ZSgpIC0gMTsKCndoaWxlIChsZWZ0IDw9IHJpZ2h0KSB7CmludCBtaWQgPSBsZWZ0ICsgKHJpZ2h0IC0gbGVmdCkgLyAyOwoKaWYgKGFyclttaWRdID09IHRhcmdldCkgewpyZXR1cm4gbWlkOwp9IGVsc2UgaWYgKGFyclttaWRdIDwgdGFyZ2V0KSB7CmxlZnQgPSBtaWQgKyAxOwp9IGVsc2UgewpyaWdodCA9IG1pZCAtIDE7Cn0KfQoKcmV0dXJuIC0xOyAvLyBFbGVtZW50IG5vdCBmb3VuZAp9CgppbnQgbWFpbigpIHsKc3RkOjp2ZWN0b3I8aW50PiBhcnIgPSB7MSwgMiwgMywgNCwgNSwgNiwgNywgOCwgOSwgMTB9OwppbnQgdGFyZ2V0ID0gNjsKCmludCBpbmRleCA9IGJpbmFyeVNlYXJjaChhcnIsIHRhcmdldCk7CgppZiAoaW5kZXggIT0gLTEpIHsKc3RkOjpjb3V0IDw8ICJFbGVtZW50IGZvdW5kIGF0IGluZGV4OiAiIDw8IGluZGV4IDw8IHN0ZDo6ZW5kbDsKfSBlbHNlIHsKc3RkOjpjb3V0IDw8ICJFbGVtZW50IG5vdCBmb3VuZCBpbiB0aGUgYXJyYXkuIiA8PCBzdGQ6OmVuZGw7Cn0KCnJldHVybiAwOwp9
At any Kth step, our search space would be at most N / (2^k), and ultimately, we are required to find the smallest value of K for which it's no longer possible to make further divisions in our search space.
N / (2^k) < 1 on taking log on both sides, we get k = log(N) + 1.
The time complexity of binary search is, therefore, O(logN), which is much more efficient than a linear search time complexity of O(N), especially for large values of N.
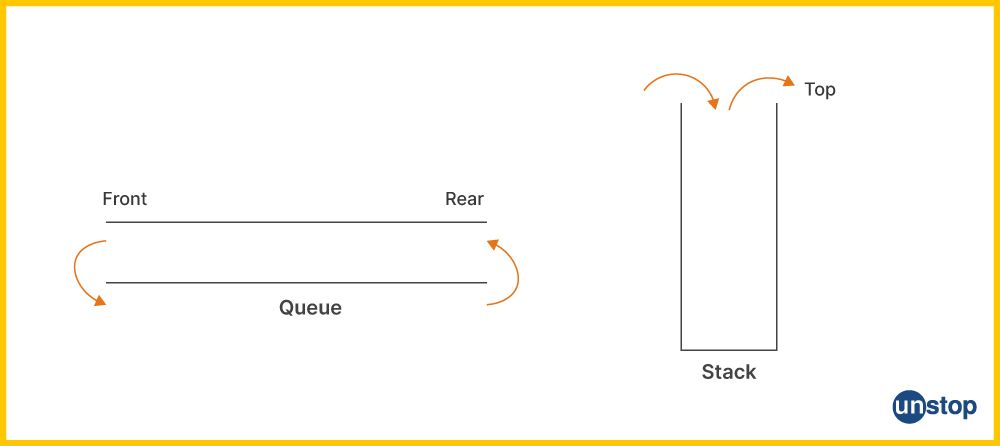
Q3. When would you use Stack over Queue?
The time complexity of insertion and removal of elements from both stack and queue takes O(1) time but we have differences in the use cases of both these data structures. We prefer to use a stack when we need to keep track of function calls, manage state changes, or reverse a sequence of elements.
Whereas, we prefer to use a queue when we need to manage tasks in a sequential order, handle items in the order they arrive (e.g., in a print queue or task processing system), or perform breadth-first traversal of data structures.
Q4. Explain the concept of recursion and provide an example.
Recursion is a programming concept where a function calls itself in order to solve a problem. The basic idea behind recursion is to keep breaking down a given problem into smaller and smaller problems so as to ultimately reach a point the original problem has been broken down to such an extent that we know the solution of smallest of sub-problems.
Based on the solution to small sub-problems, we keep building the solution for larger problems until the original problem(largest) is solved. Recursion involves two main components: a base case which is the termination condition of the recursion, when met, it stops the recursive calls and returns a value without further recursive calls. and a recursive case in which the function calls itself with modified parameters, moving closer to the base case. The concept of recursion can be understood with the help of a recursive function which calculated factorial of a number.
CODE SNIPPET IS HEREI2luY2x1ZGUgPGlvc3RyZWFtPgoKaW50IGZhY3RvcmlhbChpbnQgbikgewovLyBCYXNlIGNhc2U6IGlmIG4gaXMgMCBvciAxLCByZXR1cm4gMQppZiAobiA9PSAwIHx8IG4gPT0gMSkgewpyZXR1cm4gMTsKfSBlbHNlIHsKLy8gUmVjdXJzaXZlIGNhc2U6IGNvbXB1dGUgbiAqIGZhY3RvcmlhbChuLTEpCnJldHVybiBuICogZmFjdG9yaWFsKG4gLSAxKTsKfQp9CgppbnQgbWFpbigpIHsKaW50IG51bWJlciA9IDU7CmludCByZXN1bHQgPSBmYWN0b3JpYWwobnVtYmVyKTsKc3RkOjpjb3V0IDw8ICJGYWN0b3JpYWwgb2YgIiA8PCBudW1iZXIgPDwgIiBpcyAiIDw8IHJlc3VsdCA8PCBzdGQ6OmVuZGw7CnJldHVybiAwOwp9CgpPdXRwdXQ6IEZhY3RvcmlhbCBvZiA1IGlzIDEyMMKgIMKg
The factorial function uses recursion to calculate the factorial of a number n. The base case is when n is 0 or 1, in which case the function returns 1. In the recursive case, the function calls itself with n - 1 and multiplies the result by n. This continues until the base case is reached.
Q5. How do you handle null or undefined values in your code to prevent errors?
There are multiple ways by following which we can handle null or undefined values so as to prevent errors. These includes using conditional statements (such as if or switch) to check if a value is null or undefined before attempting to access or manipulate it, providing default fallback values to be used when a variable is null or undefined, using ternary operators to conditionally set a value based on whether a variable is null or undefined, and using try-catch or similar mechanisms to catch exceptions that may arise when working with null or undefined values.
We can also perform type checking to ensure that a value is of the expected type and not null or undefined. We can also use assertions to enforce expectations about values.
Q6. Describe the principles of object-oriented programming and provide an example of inheritance and encapsulation in your code.
The four main principles of OOP includes:
- Encapsulation which focuses on hiding the internal details of an object and providing a controlled interface for interacting with it hence maintaining data integrity and preventing unauthorised access.
- Inheritance which is the mechanism by which one class (subclass or derived class) can inherit the properties and behaviours of another class (super-class or base class) promoting code re-usability and allowing the creation of hierarchies of classes.
- Polymorphism which enables us to write code that can work with objects of multiple types, promoting flexibility and extensibility.
- Abstraction which involves simplifying complex reality by modelling classes based on the essential features and ignoring unnecessary details.
CODE SNIPPET IS HEREI2luY2x1ZGUgPGlvc3RyZWFtPgoKLy8gQmFzZSBjbGFzcyAoc3VwZXJjbGFzcykKY2xhc3MgU2hhcGUgewpwcm90ZWN0ZWQ6CmRvdWJsZSBhcmVhOwoKcHVibGljOgpTaGFwZSgpIDogYXJlYSgwLjApIHt9Cgp2b2lkIHNldEFyZWEoZG91YmxlIGEpIHsKYXJlYSA9IGE7Cn0KCmRvdWJsZSBnZXRBcmVhKCkgY29uc3QgewpyZXR1cm4gYXJlYTsKfQoKdmlydHVhbCB2b2lkIGRpc3BsYXlBcmVhKCkgewpzdGQ6OmNvdXQgPDwgIkFyZWE6ICIgPDwgYXJlYSA8PCBzdGQ6OmVuZGw7Cn0KfTsKCi8vIERlcml2ZWQgY2xhc3MgKHN1YmNsYXNzKQpjbGFzcyBDaXJjbGUgOiBwdWJsaWMgU2hhcGUgewpwcml2YXRlOgpkb3VibGUgcmFkaXVzOwoKcHVibGljOgpDaXJjbGUoZG91YmxlIHIpIDogcmFkaXVzKHIpIHsKY2FsY3VsYXRlQXJlYSgpOwp9Cgp2b2lkIGNhbGN1bGF0ZUFyZWEoKSB7CmFyZWEgPSAzLjE0MTU5ICogcmFkaXVzICogcmFkaXVzOwp9Cgp2b2lkIGRpc3BsYXlBcmVhKCkgb3ZlcnJpZGUgewpzdGQ6OmNvdXQgPDwgIkNpcmNsZSBBcmVhOiAiIDw8IGFyZWEgPDwgc3RkOjplbmRsOwp9Cn07CgppbnQgbWFpbigpIHsKQ2lyY2xlIG15Q2lyY2xlKDUuMCk7CgovLyBBY2Nlc3NpbmcgdGhlIGluaGVyaXRlZCBhcmVhIHByb3BlcnR5IGFuZCBvdmVycmlkZGVuIGRpc3BsYXlBcmVhIG1ldGhvZApzdGQ6OmNvdXQgPDwgIkNpcmNsZSdzIEFyZWE6ICIgPDwgbXlDaXJjbGUuZ2V0QXJlYSgpIDw8IHN0ZDo6ZW5kbDsKbXlDaXJjbGUuZGlzcGxheUFyZWEoKTsKCnJldHVybiAwOwp9
Output:
Circle's Area: 78.5397
Circle Area: 78.5397
In this example, we have two classes: Shape and Circle. Shape is the base class with an encapsulated area property and methods to set, get, and display the area. Circle is the derived class that inherits from Shape and adds a radius property and a calculateArea method. The displayArea method is overridden in the Circle class to provide a more specific implementation.
Q7. Discuss the differences between synchronous and asynchronous programming.
Synchronous and asynchronous programming are two different approaches to managing the execution of tasks and handling the concurrency in a software execution. In synchronous programming, tasks are executed one after the other in a sequential manner. When a task is being processed, it blocks the execution of the other tasks in queue until it's own execution is completed.
Whereas in asynchronous programming, tasks can be initiated and executed independently. When a task takes a long time to complete, the program doesn't wait and continues executing other tasks.
Asynchronous code allows for more effective utilisation of CPU resources, as multiple tasks can run concurrently, making it suitable for applications that require high concurrency, such as web servers and real-time applications. Synchronous code on the other hand do not support concurrency but is relatively easy to understand and predict because it follows a straightforward flow of execution.
Q8. How would you handle and validate user input in a web application?
Handling and validating user input in a web application is essential to ensure the security and reliability of our application. Validation can be achieved in following ways:
- We can employ client-side and server-side form validation to catch errors before they reach the server. HTML 5 provides built-in form validation features that can be utilized on the client side.
- Sanitising the user inputs by removing or escaping potentially harmful characters, such as SQL injection, HTML tags, and JavaScript code.
- When interacting with a database we should avoid embedding user inputs into the SQL queries instead we can use parameterised queries or prepared statements to prevent SQL injection attacks.
- We can employ CAPTCHA or other anti-bot techniques to differentiate between human users and automated scripts.
We can also implement security headers in your web application to mitigate certain attacks, such as Content Security Policy (CSP) headers.
Q9. What is your approach to debugging complex code issues?
Complex code issues are unavoidable and integral part of software development tackling which can be challenging. To reduce down efforts and efficiently eliminate issues we can:
- Understand the problem and attempt to reproduce it in a controlled environment to identify the specific inputs or conditions that trigger the issue and work accordingly.
- We can isolate the part of code causing the issue by executing different routines individually and disabling all the remaining to identify which block exactly is causing the issue.
- Employ debugging tools provided by your development environment, such as IDEs, debuggers, and profiling tools. Set breakpoints, inspect variables, and dry run through code to understand its execution flow.
- Use version control systems to compare the current code with a previous working version to pinpoint changes that might have introduced the issue.
- Collaborate with a colleague through pair programming to get a fresh perspective on the problem. Sometimes, a second set of eyes can provide valuable insights.
Q10. How can you optimize code performance?
- Code performance can be optimised through several ways:
- Selecting efficient data structures and algorithms according to the need of the problem.
- Minimising input/output operations (e.g., file reads/writes, network requests, database queries) to the best extent as possible as they constitute the slowest part during execution.
- Efficiently minimising the number of iterations and reducing work inside loops. Consider loop unrolling and loop fusion where appropriate.
- Implementing caching mechanisms to store frequently accessed data, reducing the need to recalculate or retrieve data from slower sources.
- Compiled languages tend to be faster than interpreted ones. Considering use of languages that compile to machine code for performance-critical parts of the application.
Data Structures and Algorithms
Q1. Explain the concept of a linked list and its advantages and disadvantages over an array.
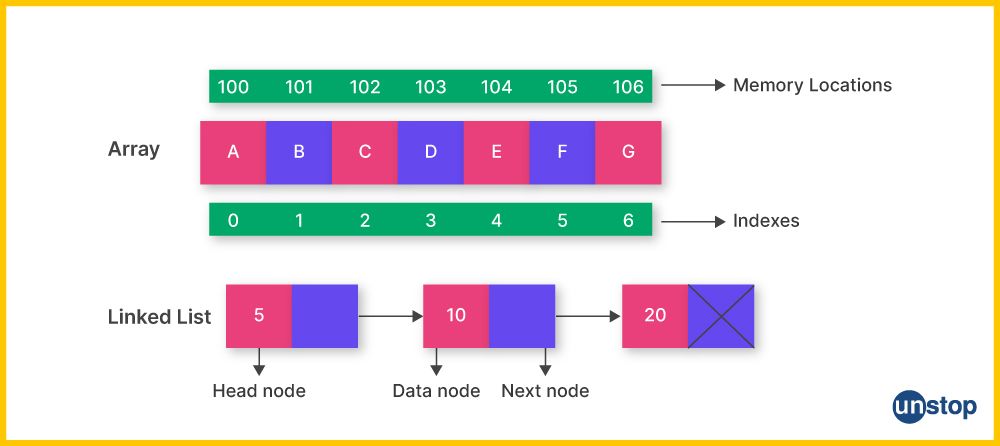
A linked list is a data structure that consists of a sequence of nodes where each node contains a value and one/two pointers which points to the adjacent nodes (previous/next). The first element in a linked list is called the head, and the last element typically points to a null reference.
Compared to array, linked lists can grow or shrink in size during runtime, making them suitable for situations where the number of elements is not known in advance. Apart from that insert and delete operations at any position can be done in O(1) time, whereas in an array it takes O(N) time.
A major drawback of linked list is that we cannot access an element without traversing the entire list up to that element so random access time is O(N) whereas it is O(1) in case of arrays. Linked list also has poorer cache performance than arrays due to their scattered memory locations.
Q2. What is a hash table and when is it useful in programming?
A hash table, also known as a hash map, is a data structure that provides efficient data retrieval and storage of key-value pairs. It uses a hash function to compute an index into an array of buckets or slots, from which the desired value can be found.
They are useful in programming for near-constant-time (O(1)) average-case complexity for key-value retrieval. This is faster than many other data structures, such as arrays or linked lists, which may require linear search. Hash tables can also quickly insert and delete key-value pairs, often in O(1) time. This is particularly advantageous for dynamic data structures that frequently change in size.
Q3. Implement a sorting algorithm (e.g., quicksort or mergesort) and analyze its time complexity.
QuickSort is a sorting algorithm that selects a pivot element and organises the array by placing the pivot in its correct sorted position, dividing the array into smaller parts, and recursively sorting them.
Quick sort algorithm can be implemented as follows:
CODE SNIPPET IS HEREI2luY2x1ZGUgPGlvc3RyZWFtPgojaW5jbHVkZSA8dmVjdG9yPgoKLy8gRnVuY3Rpb24gdG8gcGFydGl0aW9uIHRoZSBhcnJheSBhbmQgcGxhY2UgdGhlIHBpdm90IGVsZW1lbnQgaW4gaXRzIGNvcnJlY3QgcG9zaXRpb24KaW50IHBhcnRpdGlvbihzdGQ6OnZlY3RvcjxpbnQ+ICZhcnIsIGludCBsb3csIGludCBoaWdoKSB7CmludCBwaXZvdCA9IGFycltoaWdoXTsgLy8gQ2hvb3NlIHRoZSBsYXN0IGVsZW1lbnQgYXMgdGhlIHBpdm90CmludCBpID0gKGxvdyAtIDEpOyAvLyBJbmRleCBvZiB0aGUgc21hbGxlciBlbGVtZW50Cgpmb3IgKGludCBqID0gbG93OyBqIDw9IGhpZ2ggLSAxOyBqKyspIHsKaWYgKGFycltqXSA8IHBpdm90KSB7CmkrKzsKc3RkOjpzd2FwKGFycltpXSwgYXJyW2pdKTsKfQp9CgpzdGQ6OnN3YXAoYXJyW2kgKyAxXSwgYXJyW2hpZ2hdKTsKcmV0dXJuIChpICsgMSk7Cn0KCi8vIEZ1bmN0aW9uIHRvIHBlcmZvcm0gUXVpY2tTb3J0IG9uIHRoZSBhcnJheQp2b2lkIHF1aWNrU29ydChzdGQ6OnZlY3RvcjxpbnQ+ICZhcnIsIGludCBsb3csIGludCBoaWdoKSB7CmlmIChsb3cgPCBoaWdoKSB7CmludCBwaXZvdEluZGV4ID0gcGFydGl0aW9uKGFyciwgbG93LCBoaWdoKTsKCi8vIFJlY3Vyc2l2ZWx5IHNvcnQgZWxlbWVudHMgYmVmb3JlIGFuZCBhZnRlciB0aGUgcGl2b3QKcXVpY2tTb3J0KGFyciwgbG93LCBwaXZvdEluZGV4IC0gMSk7CnF1aWNrU29ydChhcnIsIHBpdm90SW5kZXggKyAxLCBoaWdoKTsKfQp9CgppbnQgbWFpbigpIHsKc3RkOjp2ZWN0b3I8aW50PiBhcnIgPSB7MTIsIDExLCAxMywgNSwgNiwgN307CgppbnQgbiA9IGFyci5zaXplKCk7CgpzdGQ6OmNvdXQgPDwgIk9yaWdpbmFsIGFycmF5OiAiOwpmb3IgKGludCBpID0gMDsgaSA8IG47IGkrKykgewpzdGQ6OmNvdXQgPDwgYXJyW2ldIDw8ICIgIjsKfQpzdGQ6OmNvdXQgPDwgc3RkOjplbmRsOwoKcXVpY2tTb3J0KGFyciwgMCwgbiAtIDEpOwoKc3RkOjpjb3V0IDw8ICJTb3J0ZWQgYXJyYXk6ICI7CmZvciAoaW50IGkgPSAwOyBpIDwgbjsgaSsrKSB7CnN0ZDo6Y291dCA8PCBhcnJbaV0gPDwgIiAiOwp9CnN0ZDo6Y291dCA8PCBzdGQ6OmVuZGw7CgpyZXR1cm4gMDsKfQ==
The time complexity of the QuickSort algorithm depends on the choice of the pivot and the distribution of data in the list to be sorted. On an average, it has an O(N * log(N)) time complexity similar to that of MergeSort.
Q4. Describe the difference between a breadth-first search (BFS) and a depth-first search (DFS) algorithm.
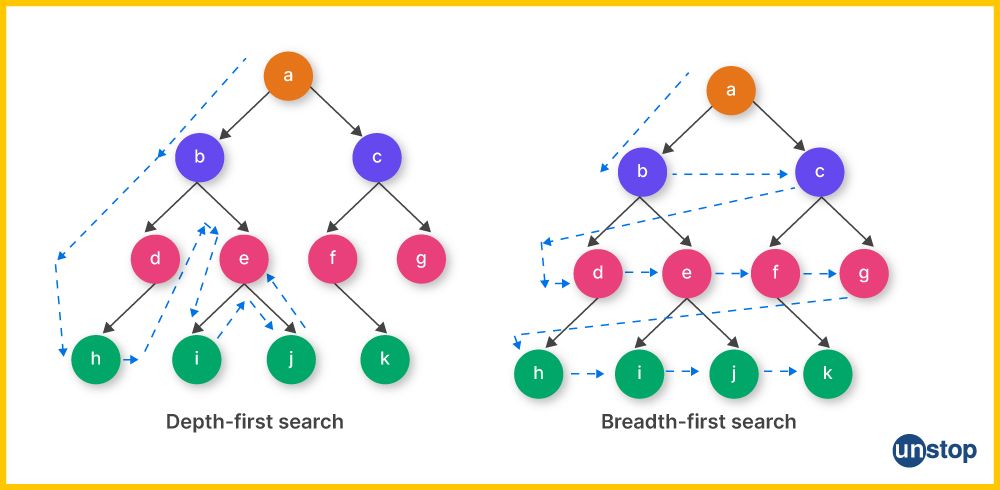
Breadth-First Search (BFS) and Depth-First Search (DFS) are both graph traversal algorithms used to explore and search through graph or tree structures. They differ in the strategies for visiting nodes and the order in which they explore the graph.
BFS explores the graph level by level, starting from the source node (or nodes) and moving outward to nodes at the same level before descending to the next level whereas DFS explores down a branch as far as possible before backtracking to explore other branches. It descends as deep as possible along each branch before backtracking.
BFS uses a queue data structure to maintain the order of nodes to be explored whereas DFS uses a stack. Since we are only iterating over the graph’s edges and vertices only once, the time complexity for both algorithms is linear O(V+E).
Q5. What is dynamic programming, and when would you use it?
Dynamic programming is a problem-solving technique that involves avoiding repetitive calculations by storing the result to be used in future. We break down the given problem into multiple sub-problems. We calculate answer for those sub-problems and store their results so as to avoid calculating it again.
Dynamic programming is helpful in case when the given problem has overlapping sub-problems i.e., there are common sub-problems that are solved multiple times and optimal substructure i.e. solution to a larger problem can be constructed from the solutions to its smaller sub-problems.
This technique can be applied to a wide range of problems, which includes Fibonacci Sequence, Shortest Path Problems, Longest Common Subsequence (LCS), Knapsack Problem, Matrix Chain Multiplication etc.
Software Design and Architecture
Q1. Explain the SOLID principles in software design and how they apply to your projects.
SOLID design principles are a set of 5 design principles which includes:
- The Single responsibility principle (S) states that a class should have only one reason to change that is a given class should take only one responsibility.
- The Open/Close principle suggests that software entities (such as classes, modules, or functions) should be open for extension but closed for modification.
- Liskov Substitution Principle (LSP) states that objects of derived class should be able to replace objects of the base class without affecting the correctness of the program.
- The Interface segregation principle encourages creating small, specific interfaces rather than large, general-purpose ones. The basic idea is that clients should not be forced to depend on interfaces they don't use.
- The Dependency inversion principle states that high-level modules should not depend on low-level modules, both should depend on abstractions. Additionally, abstractions should not depend on details rather details should depend on abstractions.
In my project on e-commerce application, separate classes that can handle user authentication, product catalogue management, order processing and payment handling has been made. The product catalogue system is open for extension as new products can be added without altering the core catalogue code.
Q2. Discuss the concept of design patterns and provide an example of when you've used one.
Design patterns are general solutions to some of the recurring problems in software design. They are basically a blue-print of approach to be followed for solving specific problems in such a way that is both efficient and maintainable.
Design patterns ensure that the product under design is structured in a clear, understandable and flexible manner making it easier to maintain and allow multiple developers to collaborate while working upon it. They are generally classified into three categories which are Creational patterns which deals with object creation mechanisms that increase flexibility and reuse of existing code, Structural patterns are concerned with how classes and objects are composed to form larger structures while keeping them efficient and flexible and Behavioral Patterns which focuses on communication and assignments of responsibilities between objects.
While working on one of the projects, I encountered a situation where I had to integrate with an external API that had a different interface from what my application expected. I used the adapter pattern (Structural Patterns) to create a wrapper class that translated the external API's interface into one that my application could work with seamlessly.
Q3. How do you handle version control in a team, and what are the benefits of using Git?
In a team setting, handling version control is essential for collaboration, code management, and tracking changes in the project. A central repository for the project is set up on platforms like GitHub, GitLab, or Bitbucket which serves as the master copy of the code. We define a branching strategy , such as Git Flow, where we have different branches for features, bug fixes, development, and release ensuring all the work is organised and do not interfere with each other.
Developers are able to clone the central repository to their local machines and work on their assigned tasks in feature branches, making regular commits as they make progress. Once a developer finish working on assigned feature or fix, they create a pull request (PR) to merge their changes into the development branch.
Git is a popular distributed version control system that offers several benefits for team collaboration. It allows every team member to have their local copy of the entire repository. This enables offline work and faster access to version history. It's branching and merging capabilities allows for work on multiple features or bug fixes concurrently and merge them back into a single codebase. It also allows us to track who made changes, when they were made, and what the changes were, which is essential for debugging and auditing.
Q4. What is the difference between monolithic and microservices architectures, and when would you choose one over the other?
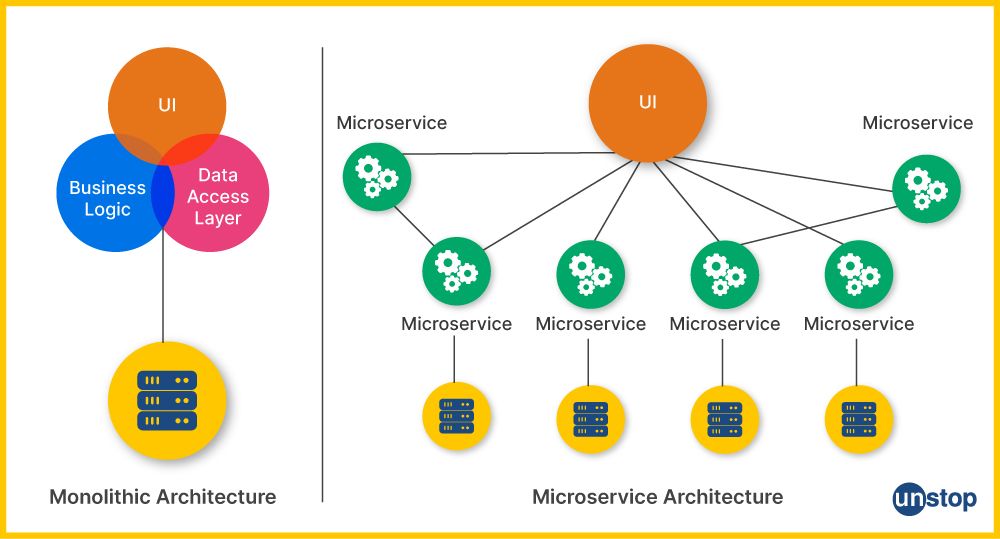
Monolithic and Microservices are two different architectural styles for designing and building software applications. Monolithic architecture is a traditional model of a software application where the entire application is developed as a single, tightly integrated codebase and entire application is deployed as a single unit. Any updates or changes require re-deploying the entire application.
Microservices architecture, on the other hand, decomposes the application into a series of independently deployable services, each responsible for a specific business capability.
They can be deployed and updated independently. Changes to one service don't require redeploying the entire application.
Scaling a monolithic application requires replicating the entire application, which can be inefficient and expensive whereas In microservices architecture the services can be individually scaled to handle variable loads, leading to better resource utilisation.
We should opt for microservices architecture when different parts of the application require distinct technologies, databases, or frameworks and we need to handle variable workloads on different sections, which demands the ability to scale individual components independently.
A monolith is a better choice in cases where a quick development cycle is more important than scalability and long-term maintainability.
Web Development
Q1. Explain the differences between HTTP and HTTPS and the importance of encryption.
HTTP (Hypertext Transfer Protocol) and HTTPS (Hypertext Transfer Protocol Secure) are two protocols which is used for communication between a web client (e.g. a browser) and a web server. The primary basis for distinction between two lies in the level of security they provide in context of data encryption.
HTTP does not provide data encryption or security to the data transferred by default. It is send over in the form of a plain text susceptible to interception by malicious actors. HTTPS on the other hand encrypts the data transferred between the client and server using encryption protocols like TLS (Transport Layer Security) or SSL (Secure Sockets Layer).
Encryption acts like a lock to the data. It makes our private information and messages unreadable to someone who doesn't have the right key to perform decryption, ensuring that even if someone gets hold of our data, they are not able to interpret it and hence prevent the associated misuse.
Q2. Discuss the basics of RESTful API design.
Designing a RESTful API (Representational State Transfer) involves creating a set of rules and conventions for building web services that are scalable, easy to understand, and work seamlessly with HTTP. Some of the basic principles to follow while designing RESTful APIs include:
- RESTful APIs should use JSON (JavaScript Object Notation) as the format for data exchange. JSON is lightweight, human-readable, and widely supported by programming languages and libraries.
- Endpoints should be logically nested to represent relationships between resources. For example, /users/123/orders would retrieve orders for the user with ID 123.
- RESTful endpoints should use nouns to represent resources rather than verbs. For example, instead of /createUser, we should use /users to represent a collection of users.
- API endpoints should handle errors gracefully and provide informative error responses. Standard HTTP status codes like 400 (Bad Request) and 404 (Not Found) should be used to indicate the outcome of the request to the client.
- RESTful APIs should provide query parameters to allow clients to filter, sort, and paginate data. For example, /products?category=electronics&sort=price&limit=10 could be used to retrieve the first 10 electronics products sorted by price.
- Caching can be employed to improve API performance. By setting appropriate caching headers (e.g. Cache-Control), clients and intermediaries can store responses and avoid redundant requests to the server.
Q3. How does a web server handle client requests and serve web pages?
The web server receives the HTTP request from the client and processes it which typically involves identifying the requested resource (e.g. a specific web page or file) and locating it on the server's file system. In some cases, the web server may need to perform server-side processing, such as running server-side scripts or interacting with a database to generate dynamic content. After the request processing is done the web server generates an HTTP response (can be static or dynamic), which includes an HTTP status code, response headers, and the content of the requested web page or resource. The web server sends the HTTP response back to the client over the established TCP connection. The response includes the requested web page's content and metadata. The client receives the HTTP response and parses the response, rendering the web page and any associated resources e.g. images, style sheets, and scripts.
Q4. What is cross-site scripting (XSS), and how can you prevent it in your web applications?
Cross-site scripting (XSS) is a form of cyber-attack in which an attacker injects malicious scripts (usually JavaScript) into web content that is then viewed by other users. The injected scripts run in the client's machine, potentially leading to various security issues, including data theft, session hijacking etc.
An XSS attack is typically initiated by sending a harmful link to a user and convincing them to click on it. If the application or website doesn't have adequate data sanitation measures in place, the malicious link will execute the attacker's code on the user's system eventually leading to acquisition of user's active session cookies.
For the prevention of XSS in our web application we can employ following methods:
- Input validation must be performed to ensure that it contains only expected and safe data. Any input that looks suspicious, contains HTML or script tags, or exceeds defined limits should be rejected.
- User generated content should be properly encoded before rendering it on web pages. HTML-encode user data to prevent it from being interpreted as code.
- Marking cookies as HTTP-only to prevent client-side scripts from accessing them. This can protect sensitive session data from being stolen.
Databases
Q1. Describe the differences between SQL and NoSQL databases and when would you use each.
SQL (Structured Query Language) and NoSQL (Not Only SQL) databases are two different types of database management systems which differ from each other on the organisation of data.
SQL databases use a structured, tabular format with predefined schemas. Data is organized into tables with rows and columns, and each column has a specific data type.
NoSQL databases do not has the restriction and support a variety of data models, including document, key-value, column-family, and graph. They are schema-flexible and allow storing unstructured or semi-structured data.
SQL databases are designed for vertical scalability whereas NoSQL databases are designed for horizontal scalability, making them well-suited for applications that need to handle large volumes of data and traffic.
We should use SQL databases when the data structure is well defined and is highly unlikely to change frequently but if there's any scope of evolution or there's need for flexibility we should use NoSQL databases.
Q2. Write a SQL query to retrieve data from a database table.
Let's suppose we have a table named products and where we have three columns denoting the name of the product (product_name), price (price), and the category to which it belongs (category). We can query the database to show all the products along with price which fall under the electronics category.
SELECT product_name, price
FROM products
WHERE category = 'Electronics';
Q3. Explain the concept of database indexing and its benefits.
Database indexing is a database optimisation technique used to enhance the speed and efficiency of data retrieval operations on a database at the cost of additional storage and maintenance overhead. It involves creation of a separate data structure consisting of a set of key-value pairs, with the key being the indexed column(s) and the value being a reference to the row in the table. The index is sorted based on the indexed column(s) which allows for efficient searching and retrieval of data.
Indexes can reduce the number of I/O (Input/Output) operations needed to access data, which can lead to substantial performance improvements, particularly when dealing with large datasets. They can also enforce constraints, such as unique constraints and primary key constraints, which ensure data integrity and accuracy in the database.
System Design
Q1. Can you design a simplified online shopping cart system, including database schema and key components?
A simplified design for an online shopping cart system can have following key components:
- User authentication so that users can create accounts, log in, and manage their profiles.
- Product catalogue for record of products each with a name, description, price, and availability status.
- A Shopping cart where users can add products to their shopping cart, view cart contents, update quantities, and remove items.
- Checkout process to enter shipping and payment information, and complete the purchase.
- View order history to view their order history, track shipments and previous purchases and order details.
Some of the essential table of simplified database schema would include:
- A user table (user_id (PK), username, password_hash, email, name, address)
- A product table (product_id (PK), name, description, price, availability_status)
- A Shopping Cart Table (cart_id (PK), user_id (FK), product_id (FK), quantity)
- An order table (order_id (Primary Key), user_id (FK), order_date, product_id, quantity, purchase_price)
How would you ensure high availability and fault tolerance in a distributed system?
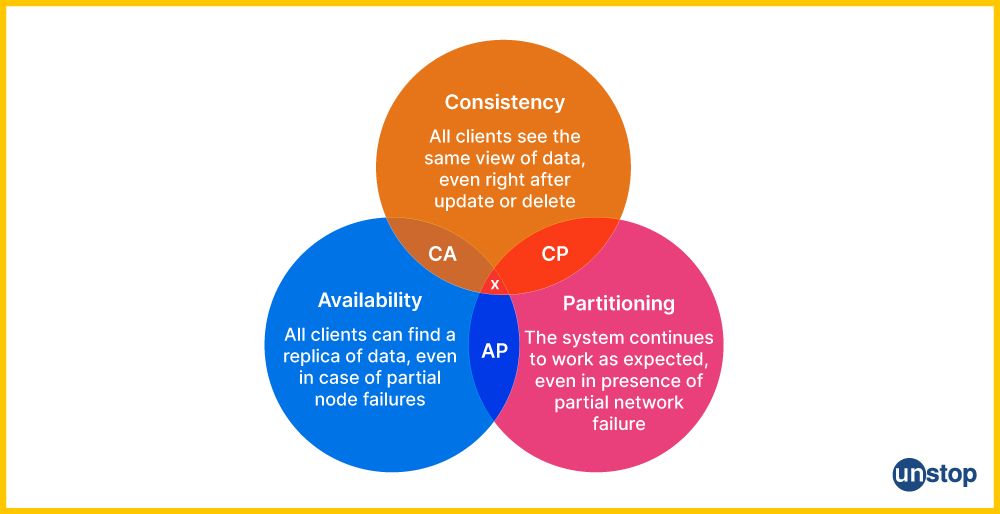
A highly available and fault tolerance system can be achieved through the following measures:
- Replicating critical components such as load balancers, databases and data across multiple servers or data centres so that if one instance fails, another can take over.
- Implementing load balancers to distribute incoming traffic across multiple servers. Load balancers can detect unhealthy servers and route traffic to healthy ones, ensuring even distribution and fault tolerance.
- Using microservices architecture to isolate components of your system so that if one microservice fails, it won't necessarily affect the entire system. We can also implement the circuit breaker pattern to handle transient failures of a given service.
Security
Q1. How do you prevent common security vulnerabilities, such as SQL injection and cross-site request forgery (CSRF), in your applications?
Preventing common security vulnerabilities, such as SQL injection and cross-site request forgery (CSRF), is essential to protect our applications from potential attacks. Some of the best practices which eliminates these vulnerabilities includes:
- Employing parameterized queries or prepared statements provided by specific programming language or database framework under use which automatically handles the input data and prevent it from being executed as SQL code.
- Validation of the inputs from the users to ensure that user provided data conforms to the expected formats and does not contain malicious SQL codes.
- Anti-CSRF tokens can be included in the forms which is generated per user session and verified on the server side when form submissions are received.
- Implementing the same origin policy helps to ensure that web pages can only make requests from the same origin from which they were loaded preventing unauthorised requests to other domains.
Q2. Describe the principles of least privilege and how they apply to software security.
The Principle of Least Privilege (POLP) is a fundamental concept in providing security to software applications that revolve around the idea of limiting access rights or permissions of users, processes, or systems to the bare minimum level that is both necessary and sufficient to perform the required task. The goal behind the principle is to minimize potential security risks and limit the impact of security breaches or vulnerabilities.
Along with limited rights, a default deny policy can also be implemented where no access is granted unless explicitly authorized forcing careful consideration of access requests.
Periodic reviews and audits must be conducted to ensure the permissions align with the principle of least privilege and should be changed according to the roles and responsibilities.
Tips for Interviewing at Walmart and Interview Preparation Tips
Preparing for a job interview can be nerve-wracking, but with the right approach and prior experience, you can increase your chances of success.There are a few key tips and tricks that can help you stand out from the competition. Let's dive in and explore some interview preparation tips specifically tailored to Walmart.
Research Walmart's Values, Mission, and Culture
Before heading into an interview at Walmart, it is crucial to research the company's values, mission, and culture. This will not only demonstrate your interest in the company but also give you valuable information to tailor your answers during the interview. Take some time to browse through their website or read up on recent news articles about Walmart. By doing so, you'll gain insights into what they prioritize as an organization.
Dress Appropriately for Success
First impressions matter! When attending a job interview at Walmart or any other company, dressing appropriately is essential. While each store may have its own dress code policy, it's generally recommended to dress in business casual attire for an interview. This means opting for clean and pressed clothes that are professional yet comfortable. Remember that dressing well not only shows respect for the opportunity but also boosts your confidence.
Practice Common Behavioral-Based Questions
Walmart often uses behavioral-based questions during interviews to assess candidates' customer service skills and problem-solving abilities. To prepare yourself effectively, take some time to practice answering these types of questions beforehand. Reflect on past experiences where you demonstrated excellent customer service or resolved a challenging situation successfully. By having specific examples ready, you'll be able to provide detailed responses that showcase your skills.
Align Past Experiences with Desired Qualities
During an interview at Walmart, it's important to highlight how your past experiences align with the qualities they seek in candidates. Beforehand, make a list of desired qualities mentioned in the job description or research. Then, think of specific examples from your previous work or personal life that demonstrate these qualities. This will help you provide concrete evidence of your capabilities and increase your chances of impressing the interviewer.
Pro Tips for Interview Success
Here are a few additional pointers to keep in mind when preparing for a Walmart interview:
-
Arrive on time: Punctuality is key. Make sure to plan ahead and arrive at least 10 minutes before your scheduled interview time.
-
Be courteous to everyone: Treat everyone you encounter during the interview process with respect, from the receptionist to the interviewer.
-
Show enthusiasm: Let your passion for the role and company shine through during the interview. Employers appreciate candidates who genuinely want to be part of their team.
-
Ask thoughtful questions: Prepare a list of questions about Walmart's operations, company culture, or future goals. Asking thoughtful questions shows your interest and engagement.
By following these tips and adequately preparing for your Walmart interview, you'll be well-positioned to make a positive impression on potential employers. Remember that practice makes perfect, so take some time to rehearse common interview questions and refine your responses. Good luck!
Frequently Asked Questions
How long does the Walmart interview process typically take?
The duration of the Walmart interview process can vary depending on factors such as the position applied for and the number of candidates being considered. On average, it may take anywhere from a few weeks to a couple of months from application submission to receiving an offer.
Are there any dress code guidelines for interviews at Walmart?
Walmart encourages candidates to dress professionally for interviews. It is recommended to wear business attire or smart casual clothing that reflects your professionalism and respect for the opportunity.
Can I expect behavioral questions during my Walmart interview?
Yes, behavioral questions are commonly asked during Walmart interviews. These questions aim to assess how you handle various situations based on past experiences. Prepare examples that demonstrate your problem-solving skills, teamwork abilities, adaptability, and customer service orientation.
Is having previous retail experience necessary for a software developer position at Walmart?
While having retail experience can be beneficial when applying for certain positions at Walmart, it is not always a requirement for software developer roles. Focus on highlighting your technical skills, problem-solving abilities, and relevant experience during the interview process.
What should I do if I don't know the answer to a technical question during my Walmart coding interview?
If you encounter a technical question that stumps you during your Walmart coding interview, remain calm and honest. It's better to admit that you don't know the answer than to provide incorrect information. Use this opportunity to showcase your problem-solving approach and willingness to learn by discussing how you would find the solution.
Suggested Reads:
Login to continue reading
And access exclusive content, personalized recommendations, and career-boosting opportunities.
Don't have an account? Sign up
Never miss an
Update

Featured Opportunities
Top-Rated Practice by Students





Subscribe
to our newsletter
Blogs you need to hog!

How To Write Finance Cover Letter For Morgan Stanley (+Free Sample!)
Unstop

55+ Data Structure Interview Questions For 2026 (Detailed Answers)
Muskaan Mishra

How To Negotiate Salary With HR: Tips And Insider Advice
Srishti Magan

80+ TCS NQT Interview Questions & Answers (2026) You Must Prepare
Urvashi Singhal
Comments
Add comment