
Asian Paints Alchemy 2026
Company Interview Questions for Freshers
- TCS Technical Interview Questions & Answers
- TCS Managerial Interview Questions & Answers
- TCS HR Interview Questions & Answers
- Overview of Cognizant Recruitment Process
- Cognizant Interview Questions: Technical
- Cognizant Interview Questions: HR Round
- Overview of Wipro Technologies Recruitment Rounds
- Wipro Interview Questions
- Technical Round
- HR Round
- Online Assessment Sample Questions
- Frequently Asked Questions
- Overview of Google Recruitment Process
- Google Interview Questions: Technical
- Google Interview Questions: HR round
- Interview Preparation Tips
- About Google
- Deloitte Technical Interview Questions
- Deloitte HR Interview Questions
- Deloitte Recruitment Process
- Technical Interview Questions and Answers
- Level 1 difficulty
- Level 2 difficulty
- Level 3 difficulty
- Behavioral Questions
- Eligibility Criteria for Mindtree Recruitment
- Mindtree Recruitment Process: Rounds Overview
- Skills required to crack Mindtree interview rounds
- Mindtree Recruitment Rounds: Sample Questions
- About Mindtree
- Preparing for Microsoft interview questions
- Microsoft technical interview questions
- Microsoft behavioural interview questions
- Aptitude Interview Questions
- Technical Interview Questions
- Easy
- Intermediate
- Hard
- HR Interview Questions
- Eligibility criteria
- Recruitment rounds & assessments
- Tech Mahindra interview questions - Technical round
- Tech Mahindra interview questions - HR round
- Hiring process at Mphasis
- Mphasis technical interview questions
- Mphasis HR interview questions
- About Mphasis
- Technical interview questions
- HR interview questions
- Recruitment process
- About Virtusa
- Goldman Sachs Interview Process
- Technical Questions for Goldman Sachs Interview
- Sample HR Question for Goldman Sachs Interview
- About Goldman Sachs
- Nagarro Recruitment Process
- Nagarro HR Interview Questions
- Nagarro Aptitude Test Questions
- Nagarro Technical Test Questions
- About Nagarro
- PwC Recruitment Process
- PwC Technical Interview Questions: Freshers and Experienced
- PwC Interview Questions for HR Rounds
- PwC Interview Preparation
- Frequently Asked Questions
- EY Technical Interview Questions (2023)
- EY Interview Questions for HR Round
- About EY
- Morgan Stanley Recruitment Process
- HR Questions for Morgan Stanley Interview
- HR Questions for Morgan Stanley Interview
- About Morgan Stanley
- Recruitment Process at Flipkart
- Technical Flipkart Interview Questions
- Code-Based Flipkart Interview Questions
- Sample Flipkart Interview Questions- HR Round
- Conclusion
- FAQs
- Recruitment Process at Paytm
- Technical Interview Questions for Paytm Interview
- HR Sample Questions for Paytm Interview
- About Paytm
- Most Probable Accenture Interview Questions
- Accenture Technical Interview Questions
- Accenture HR Interview Questions
- Amazon Recruitment Process
- Amazon Interview Rounds
- Common Amazon Interview Questions
- Amazon Interview Questions: Behavioral-based Questions
- Amazon Interview Questions: Leadership Principles
- Company-specific Amazon Interview Questions
- 43 Top Technical/ Coding Amazon Interview Questions
- Juspay Recruitment: Stages and Timeline
- Juspay Interview Questions and Answers
- How to prepare for Juspay interview questions
- Prepare for the Juspay Interview: Stages and Timeline
- Frequently Asked Questions
- Adobe Interview Questions - Technical
- Adobe Interview Questions - HR
- Recruitment Process at Adobe
- About Adobe
- Cisco technical interview questions
- Sample HR interview questions
- The recruitment process at Cisco
- About Cisco
- JP Morgan interview questions (Technical round)
- JP Morgan interview questions HR round)
- Recruitment process at JP Morgan
- About JP Morgan
- Wipro Elite NTH: Selection Process
- Wipro Elite NTH Technical Interview Questions
- Wipro Elite NTH Interview Round- HR Questions
- BYJU's BDA Interview Questions
- BYJU's SDE Interview Questions
- BYJU's HR Round Interview Questions
- A Quick Overview of the KPMG Recruitment Process
- Technical Questions for KPMG Interview
- HR Questions for KPMG Interview
- About KPMG
- DXC Technology Interview Process
- DCX Technical Interview Questions
- Sample HR Questions for DXC Technology
- About DXC Technology
- Recruitment Process at PayPal
- Technical Questions for PayPal Interview
- HR Sample Questions for PayPal Interview
- About PayPal
- Capgemini Recruitment Rounds
- Capgemini Interview Questions: Technical round
- Capgemini Interview Questions: HR round
- Preparation tips
- FAQs
- Technical interview questions for Siemens
- Sample HR questions for Siemens
- The recruitment process at Siemens
- About Siemens
- HCL Technical Interview Questions
- HR Interview Questions
- HCL Technologies Recruitment Process
- List of EPAM Interview Questions for Technical Interviews
- About EPAM
- Atlassian Interview Process
- Top Skills for Different Roles at Atlassian
- Atlassian Interview Questions: Technical Knowledge
- Atlassian Interview Questions: Behavioral Skills
- Atlassian Interview Questions: Tips for Effective Preparation
- Walmart Recruitment Process
- Walmart Interview Questions and Sample Answers (HR Round)
- Walmart Interview Questions and Sample Answers (Technical Round)
- Tips for Interviewing at Walmart and Interview Preparation Tips
- Frequently Asked Questions
- Uber Interview Questions For Engineering Profiles: Coding
- Technical Uber Interview Questions: Theoretical
- Uber Interview Question: HR Round
- Uber Recruitment Procedure
- About Uber Technologies Ltd.
- Intel Technical Interview Questions
- Computer Architecture Intel Interview Questions
- Intel DFT Interview Questions
- Intel Interview Questions for Verification Engineer Role
- Recruitment Process Overview
- Important Accenture HR Interview Questions
- Points to remember
- What is Selenium?
- What are the components of the Selenium suite?
- Why is it important to use Selenium?
- What's the major difference between Selenium 3.0 & Selenium 2.0?
- What is Automation testing and what are its benefits?
- What are the benefits of Selenium as an Automation Tool?
- What are the drawbacks to using Selenium for testing?
- Why should Selenium not be used as a web application or system testing tool?
- Is it possible to use selenium to launch web browsers?
- What does Selenese mean?
- What does it mean to be a locator?
- Identify the main difference between "assert", and "verify" commands within Selenium
- What does an exception test in Selenium mean?
- What does XPath mean in Selenium? Describe XPath Absolute & XPath Relation
- What is the difference in Xpath between "//"? and "/"?
- What is the difference between "type" and the "typeAndWait" commands within Selenium?
- Distinguish between findElement() & findElements() in context of Selenium
- How long will Selenium wait before a website is loaded fully?
- What is the difference between the driver.close() and driver.quit() commands in Selenium?
- Describe the different navigation commands that Selenium supports
- What is Selenium's approach to the same-origin policy?
- Explain the difference between findElement() in Selenium and findElements()
- Explain the pause function in SeleniumIDE
- Explain the differences between different frameworks and how they are connected to Selenium's Robot Framework
- What are your thoughts on the Page Object Model within the context of Selenium
- What are your thoughts on Jenkins?
- What are the parameters that selenium commands come with a minimum?
- How can you tell the differences in the Absolute pathway as well as Relative Path?
- What's the distinction in Assert or Verify declarations within Selenium?
- What are the points of verification that are in Selenium?
- Define Implicit wait, Explicit wait, and Fluent
- Can Selenium manage windows-based pop-ups?
- What's the definition of an Object Repository?
- What is the main difference between obtainwindowhandle() as well as the getwindowhandles ()?
- What are the various types of Annotations that are used in Selenium?
- What is the main difference in the setsSpeed() or sleep() methods?
- What is the way to retrieve the alert message?
- How do you determine the exact location of an element on the web?
- Why do we use Selenium RC?
- What are the benefits or advantages of Selenium RC?
- Do you have a list of the technical limitations when making use of Selenium RC? Selenium RC?
- What's the reason to utilize the TestNG together with Selenium?
- What Language do you prefer to use to build test case sets in Selenium?
- What are Start and Breakpoints?
- What is the purpose of this capability relevant in relation to Selenium?
- When do you use AutoIT?
- Do you have a reason why you require Session management in Selenium?
- Are you able to automatize CAPTCHA?
- How can we launch various browsers on Selenium?
- Why should you select Selenium rather than QTP (Quick Test Professional)?
- Airbus Interview Questions and Answers: HR/ Behavioral
- Industry/ Company-Specific Airbus Interview Questions
- Airbus Interview Questions and Answers: Aptitude
- Airbus Software Engineer Interview Questions and Answers: Technical
- Importance of Spring Framework
- Spring Interview Questions (Basic)
- Advanced Spring Interview Questions
- C++ Interview Questions and Answers: The Basics
- C++ Interview Questions: Intermediate
- C++ Interview Questions And Answers With Code Examples
- C++ Interview Questions and Answers: Advanced
- Test Your Skills: Quiz Time
- MBA Interview Questions: B.Com Economics
- B.Com Marketing
- B.Com Finance
- B.Com Accounting and Finance
- Business Studies
- Chartered Accountant
- Q1. Please tell us something about yourself/ Introduce yourself to us.
- Q2. Describe yourself in one word.
- Q3. Tell us about your strengths and weaknesses.
- Q4. Why did you apply for this job/ What attracted you to this role?
- Q5. What are your hobbies?
- Q6. Where do you see yourself in five years OR What are your long-term goals?
- Q7. Why do you want to work with this company?
- Q8. Tell us what you know about our organization
- Q9. Do you have any idea about our biggest competitors?
- Q10. What motivates you to do a good job?
- Q11. What is an ideal job for you?
- Q12. What is the difference between a group and a team?
- Q13. Are you a team player/ Do you like to work in teams?
- Q14. Are you good at handling pressure/ deadlines?
- Q15. When can you start?
- Q16. How flexible are you regarding overtime?
- Q17. Are you willing to relocate for work?
- Q18. Why do you think you are the right candidate for this job?
- Q19. How can you be an asset to the organization?
- Q20. What is your salary expectation?
- Q21. How long do you plan to remain with this company?
- Q22. What is your objective in life?
- Q23. Would you like to pursue your Master's degree anytime soon?
- Q24. How have you planned to achieve your career goal?
- Q25. Can you tell us about your biggest achievement in life?
- Q26. What was the most challenging decision you ever made?
- Q27. What kind of work environment do you prefer to work in?
- Q28. What is the difference between a smart worker and a hard worker?
- Q29. What will you do if you don't get hired?
- Q30. Tell us three things that are most important for you in a job.
- Q31. Who is your role model and what have you learned from him/her?
- Q32. In case of a disagreement, how do you handle the situation?
- Q33. What is the difference between confidence and overconfidence?
- Q34. If you have more than enough money in hand right now, would you still want to work?
- Q35. Do you have any questions for us?
- Interview Tips for Freshers
- Tell me about yourself
- What are your greatest strengths?
- What are your greatest weaknesses?
- Tell me about something you did that you now feel a little ashamed of
- Why are you leaving (or did you leave) this position??
- 15+ resources for preparing most-asked interview questions
- CoCubes Interview Process Overview
- Common CoCubes Interview Questions
- Key Areas to Focus on for CoCubes Interview Preparation
- Conclusion
- Frequently Asked Questions (FAQs)
- Data Analyst Interview Questions With Answers
- About Data Analyst
Most Important Capgemini Interview Questions With Detailed Answers
This guide covers the complete Capgemini interview process, including technical, coding, HR, and aptitude rounds, along with commonly asked interview questions and preparation tips for freshers.

If you're looking to start a career in the IT industry, Capgemini is one of the top companies to consider. The company has a rigorous interview process that assesses candidates' technical, communication, and problem-solving skills. To help you prepare, we have compiled a list of important Capgemini interview questions that you must not ignore. These questions will provide you with an insight into what the interviewers are looking for and help you make a lasting impression. Get ready to ace your Capgemini interview by preparing for these key questions!
Please note: To apply for a job at Capgemini, you first need to register yourself. After successful registration, the company sends exam links via mail.
Capgemini Recruitment Rounds
There are, in total, five to six rounds in Capgemini Assessment to hire engineering freshers. They are as follows:
|
1. Technical Psuedocode Round (30 mins) |
|
2. MCQ-based English Communication Round (30 mins) |
|
3. Game-based Aptitude Round (approx. 20-30 mins) |
|
4. Behavioural Questions Round (no time restriction) |
|
5. Coding Round (if qualified) (90 mins) |
|
6. Technical and HR Interview Round (approx. 20-30 mins) |
Capgemini Interview Questions: Technical Round
1. What do you mean by DBMS? Explain its purpose.
DBMS stands for Database Management System. It is a software application that facilitates the creation, organization, storage, retrieval, and management of data in a structured format. A DBMS serves as an intermediary between users and databases, providing an interface for users to interact with the data stored in the database.
The purpose of a DBMS is to effectively manage data in a database, ensuring data integrity, security, and efficiency. Some of the key purposes of a DBMS include:
-
Data organization: DBMS provides a structured way to organize data in a database. It defines the structure of the database, such as tables, fields, and relationships between tables, and enforces data integrity rules to ensure that data is stored in a consistent manner.
-
Data storage: It manages the physical storage of data in a database, determining how data is stored on disk or in memory. It optimizes storage and retrieval operations for efficient performance.
-
Data retrieval: It allows users to retrieve data from a database using various query languages, such as SQL (Structured Query Language). Users can retrieve data based on specific criteria or conditions, enabling efficient and flexible data retrieval.
-
Data manipulation: DBMS enables users to insert, update, and delete data in a database. It provides mechanisms for data manipulation, ensuring that changes made to data are properly handled, and maintaining data consistency.
-
Data security: DBMS provides security features to protect data from unauthorized access, ensuring that only authorized users can access, modify, or delete data. It includes authentication, authorization, and auditing mechanisms to safeguard data integrity and confidentiality.
-
Data concurrency: DBMS manages concurrent access to the database by multiple users, ensuring that multiple users can access and modify data simultaneously without conflicts. It provides mechanisms such as locks and transactions to maintain data consistency in a multi-user environment.
-
Data recovery: DBMS includes backup and recovery mechanisms to protect against data loss due to hardware failures, software failures, or human errors. It allows for data backup, restoration, and disaster recovery to ensure data durability and availability.
2. What is the difference between a stack and a queue data structure?
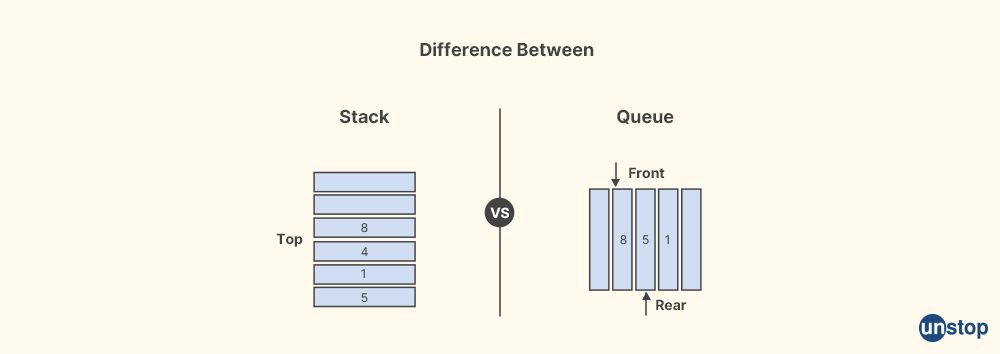
A stack and a queue are both linear data structures that store and organize collections of elements, but they differ in how elements are added and removed from the data structure.
- Stack: A stack follows the Last-In, First-Out (LIFO) principle, where the last element that is added to the stack is the first one to be removed. In other words, the element that is most recently added to the stack is at the top, and it is the first one to be removed when an operation is performed.
- Elements are added to the stack using the "push" operation, which adds an element to the top of the stack.
- Elements are removed from the stack using the "pop" operation, which removes the element from the top of the stack.
- Only the top element of the stack is accessible, and elements below the top are not directly accessible until the top element is removed.
- Queue: A queue follows the First-In, First-Out (FIFO) principle, where the first element that is added to the queue is the first one to be removed. In other words, the element that is least recently added to the queue is at the front, and it is the first one to be removed when an operation is performed.
- Elements are added to the queue using the "enqueue" operation, which adds an element to the back (or rear) of the queue.
- Elements are removed from the queue using the "dequeue" operation, which removes the element from the front (or head) of the queue.
- Both the front and rear of the queue are accessible, and elements in the queue maintain their relative order.
3. What is ACID in the context of databases?
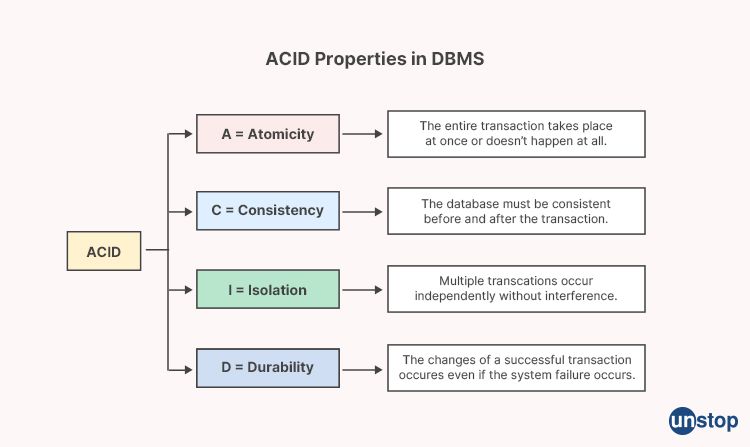
ACID stands for Atomicity, Consistency, Isolation, and Durability, which are the four essential properties that ensure the reliability, integrity, and consistency of database transactions. ACID is a set of principles that define the behavior of transactions in a Database Management System (DBMS) and ensure that database operations are performed reliably, even in the presence of failures or concurrent access by multiple users.
-
Atomicity: Atomicity guarantees that a transaction is treated as a single, indivisible unit of work. Either all the operations of a transaction are executed, or none of them are. If any operation within a transaction fails, the entire transaction is rolled back, and the database is returned to its original state. This ensures that the database remains in a consistent state even in the presence of failures.
-
Consistency: Consistency ensures that a database starts in a consistent state and ends in a consistent state after a transaction is executed. It enforces data integrity rules and constraints, ensuring that data is maintained in a valid state throughout the transaction. If a transaction violates consistency rules, it is not allowed to commit, and the database remains unchanged.
-
Isolation: Isolation ensures that concurrent execution of multiple transactions does not interfere with each other. Each transaction is isolated from other transactions, and their operations are executed in a way that they appear to be executed sequentially, without any interference. This prevents conflicts and maintains data integrity even in a multi-user environment.
-
Durability: Durability ensures that once a transaction is committed, its changes to the database are permanent and survive even in the event of system failures or crashes. Committed transactions are stored in a persistent state and cannot be undone, ensuring that the changes made by a transaction persist even in the face of failures.
ACID properties are essential for maintaining data integrity, consistency, and reliability in a database. They ensure that transactions are processed reliably, even in the presence of failures or concurrent access by multiple users, and they provide a solid foundation for building robust and reliable database systems.
4. What is the significance of a deadlock in the context of multi-threading, and how can it be prevented?
A deadlock is a situation in multi-threading where two or more threads are blocked and waiting for each other to release resources, resulting in a stalemate where none of the threads can proceed. Deadlocks can occur when multiple threads are competing for shared resources, such as locks or system resources, and each thread is holding a resource while waiting for another resource to be released, leading to a circular dependency.
Deadlocks can be significant in multi-threading as they can lead to a loss of system efficiency, performance degradation, and even system crashes. When threads are deadlocked, they are unable to make progress, resulting in wasted CPU cycles and resource utilization, which can negatively impact the overall performance and responsiveness of the system.
Preventing deadlocks in multi-threading involves careful design and coding practices. Some commonly used techniques for preventing deadlocks include:
-
Avoidance of circular dependencies: One of the primary causes of deadlocks is circular dependencies among threads competing for resources. To prevent deadlocks, it is essential to carefully design the interactions and dependencies among threads to avoid circular wait conditions.
-
Lock ordering: Ensuring that threads always acquire locks in the same order can prevent deadlocks. This requires establishing a consistent order for acquiring locks and ensuring that all threads follow that order consistently.
-
Resource allocation and deallocation: Ensuring that resources are properly allocated and deallocated can prevent deadlocks. For example, using techniques such as "resource hierarchy" or "resource request timeout" can help prevent deadlocks by ensuring that resources are released in a timely manner.
-
Use of timeouts and deadlock detection: Implementing timeouts for acquiring resources and detecting deadlocks can help prevent threads from being stuck indefinitely. Timeout mechanisms allow threads to give up on waiting for a resource after a certain period of time, preventing prolonged deadlocks.
-
Proper synchronization: Ensuring that threads properly synchronize their access to shared resources using appropriate synchronization primitives, such as locks, mutexes, or semaphores, can help prevent deadlocks. It is crucial to avoid improper synchronization practices, such as holding locks for extended periods or not releasing locks when they are no longer needed, which can lead to deadlocks.
-
Proper resource management: Ensuring that resources are properly managed, including the timely release of resources when they are no longer needed, can help prevent deadlocks. Proper resource management practices, such as resource pooling, can help reduce the chances of deadlocks.
-
Testing and debugging: Proper testing and debugging techniques can help identify and resolve potential deadlocks in multi-threaded code. Thorough testing, including stress testing and concurrency testing, can help identify potential deadlocks and ensure that the code is robust and free from deadlocks.
5. What is the significance of normalization in database management?
Normalization is a critical process in the context of database management that aims to organize and structure a database in an efficient and logical manner. It involves the decomposition of a relational database into smaller, well-structured tables, eliminating redundancy and minimizing data anomalies, to achieve a higher level of data integrity and maintainability.
The significance of normalization in database management includes:
-
Data integrity: Normalization helps ensure data integrity by eliminating redundant data and minimizing data anomalies, such as update anomalies, insertion anomalies, and deletion anomalies. Reducing redundancy and ensuring that data is stored in a consistent and normalized manner helps prevent inconsistencies and errors in the data, leading to a more reliable and accurate database.
-
Efficient data storage: Normalization helps reduce redundancy by breaking down the data into smaller, well-structured tables, which reduces the storage space required for the database. This can result in more efficient data storage, optimized database performance, and faster query execution times.
-
Improved maintainability: Normalization makes the database schema more modular and easier to understand, which makes the database easier to maintain and update. Changes to the database structure or data requirements can be made more efficiently without affecting other parts of the database, leading to improved maintainability and scalability of the database system.
-
Data consistency: Normalization helps enforce data consistency by ensuring that each piece of data is stored in only one place, eliminating redundant or conflicting data. This ensures that the data in the database is consistent and avoids inconsistencies that can arise from redundant or duplicate data.
-
Flexibility and extensibility: Normalization allows for easier modification and extension of the database schema. The modular and structured nature of normalized tables allows for more flexibility in adding, modifying, or removing data without disrupting the entire database structure. This makes the database system more adaptable to changing business requirements and future updates.
-
Query efficiency: Normalization can improve query efficiency by reducing the number of joins and the amount of redundant data that needs to be processed. Well-structured and normalized tables can lead to more efficient query execution plans, resulting in faster and more efficient queries.
6. What makes C and C++ different from one another?
Unlike the procedural programming language C, C++ is an object-oriented programming language. Classes, objects, inheritance, and polymorphism are features of C++ that increase its adaptability and power. Other applications, including game development, GUI programming, and the creation of extensive software, use C++. Mostly, low-level applications and system programming are made in C.
| Feature | C | C++ |
|---|---|---|
| Paradigm | Procedural programming | Object-oriented programming, procedural programming |
| Inheritance | Not supported | Supported |
| Polymorphism | Not supported | Supported (through classes and virtual functions and friend function) |
| Encapsulation | Not supported | Supported (through classes and access specifiers) |
| Constructors | Not supported | Supported (for object initialization) |
| Destructors | Not supported | Supported (for object cleanup) |
| Operator overloading | Not supported | Supported |
| Templates | Not supported | Supported (for generic programming) |
| Exception handling | Not supported | Supported |
| Namespace | Not supported | Supported (for organizing code and avoiding naming conflicts) |
| Standard Library | Minimal | Extensive |
| Memory Management | Manual (using pointers) | Automatic (using features like automatic memory allocation and deallocation, integrated garbage collector, etc.) |
| Function Overloading | Supported | Supported |
| Portability | Highly portable | Portable, but may require careful consideration of language features used |
| Usage | Widely used in system programming, embedded systems, and low-level programming | Widely used in application development, system programming, game development, and other domains |
| Syntax | Simpler syntax with fewer features | More complex syntax with extensive features and concepts |
| Legacy Code Compatibility | Better compatibility with older C code | May require modifications to C code for compatibility |
7. Explain the concept of object-oriented programming and how it is used in C++.
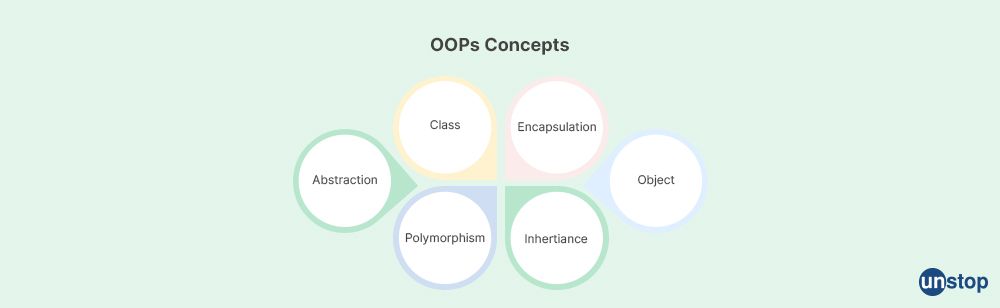
Object-oriented programming (OOP) is a programming paradigm that focuses on organizing code into objects, which are instances of classes that encapsulate data and behavior. OOP allows for the modeling of real-world entities, concepts, or systems as objects with their own properties (data members) and actions (member functions or methods).
C++ is a popular programming language that supports object-oriented programming along with other programming paradigms such as procedural programming. In C++, objects are created from classes, which are user-defined types that define the structure, behavior, and characteristics of objects.
The key concepts of object-oriented programming and how they are used in C++ are:
-
Classes: A class is a blueprint or template for creating objects. It defines the structure and behavior of objects. In C++, a class is defined using the
classkeyword, and it can contain data members (also known as attributes or properties) and member functions (also known as methods) that operate on the data members. -
Objects: An object is an instance of a class, created using the class blueprint. It represents a specific instance of the class with its own set of data members and their values. Objects can be created using the
newoperator for dynamic memory allocation or simply by declaring variables of the class type. -
Encapsulation: Encapsulation is the process of hiding the internal details of a class and exposing only the necessary interfaces to interact with the object. In C++, encapsulation is achieved using default access specifiers like
public,private, andprotected, which determine the visibility and accessibility of class members. -
Inheritance: Inheritance is a mechanism that allows a class to inherit properties and behavior from another class. In C++, classes can inherit from one or more base classes, forming a hierarchy of classes. Inheritance allows for code reuse and enables the creation of specialized classes (derived classes) from more general classes (base classes).
-
Polymorphism: Polymorphism allows objects of different classes to be treated as objects of a common type. In C++, polymorphism is supported through features such as function overloading, operator overloading, and virtual functions. Polymorphism enables writing generic code that can work with different objects of related classes, providing flexibility and extensibility.
-
Abstraction: Abstraction is the process of simplifying complex systems or concepts into abstract representations. In C++, abstraction can be achieved using abstract classes and pure virtual functions, which define common interfaces without providing implementations. Abstraction allows for defining common behavior that can be shared by multiple derived class.
8. Explain the difference between a dynamic array and a static array in C++.
Dynamic arrays and static arrays are two types of arrays in C++ that differ in their memory allocation and usage.
- Dynamic Array: A dynamic array is an array whose size can be changed during runtime. It is allocated on the heap memory using pointers and the
newoperator, and its size can be determined at runtime. Dynamic arrays are also known as "heap-allocated" or "dynamically-allocated" arrays. - Static Array: A static array is an array whose size is fixed during compilation and is determined at compile-time. It is allocated on the stack memory or as a global or static variable, and its size is known at the time of compilation. Static arrays are also known as "stack-allocated" or "fixed-size" arrays.
| Feature | Dynamic Array | Static Array |
|---|---|---|
| Size | Determined at runtime | Determined at compile-time |
| Memory Allocation | Heap memory (using pointers and new operator) |
Stack memory or as global/static variables |
| Memory Management | Manual (using new and delete operators) |
Automatic (managed by the compiler) |
| Resizability | Can be resized during runtime | Size is fixed during compilation, and cannot be resized during runtime |
In general, dynamic arrays are more flexible and allow for resizing during runtime, but require manual memory management. Static list arrays, on the other hand, are fixed in size during compilation, do not require manual memory management, but lack the flexibility of resizing during runtime. The choice between dynamic and static list arrays depends on the specific requirements of the program, such as the need for flexibility in suitable array size, memory management considerations, and performance requirements.
9. Write a C program to find the factorial of a given number.
#include
int factorial(int n) {
int result = 1; for (int i = 1; i <= n; i++) {
result *= i;
} return result;
}
int main() {
int n;
print("Enter a number: ");
scarf("%d", &n);
int result = factorial(n);
printf("Factorial of %d is %d", n, result);
return 0;
}
I2luY2x1ZGUgPHN0ZGlvLmg+CgppbnQgZmFjdG9yaWFsKGludCBuKSB7CgrCoMKgaW50IHJlc3VsdCA9IDE7wqAgZm9yIChpbnQgaSA9IDE7IGkgPD0gbjsgaSsrKSB7CgrCoMKgwqDCoHJlc3VsdCAqPSBpOwoKwqDCoH3CoCByZXR1cm4gcmVzdWx0OwoKfQoKaW50IG1haW4oKSB7CgrCoMKgaW50IG47CgrCoMKgcHJpbnQoIkVudGVyIGEgbnVtYmVyOiAiKTsKCsKgwqBzY2FyZigiJWQiLCAmbik7CgrCoMKgaW50IHJlc3VsdCA9IGZhY3RvcmlhbChuKTsKCsKgwqBwcmludGYoIkZhY3RvcmlhbCBvZiAlZCBpcyAlZCIsIG4sIHJlc3VsdCk7CgrCoMKgcmV0dXJuIDA7Cgp9
# Output (for input 5):
# Enter a number: 5
# Factorial of 5 is 120
10. Write a C++ program to reverse a string.
#include
#include
std::string reverse(const std::string& str) {
std::string result;
for (int i = str.length() - 1; i >= 0; i--) {
result += str[i];
}
return result;
}
int main() {
std::string str;
std::cout << "Enter a string: ";
std::cin >> str;
std::string result = reverse(str);
std::cout << "Reversed string: " << result << std::endl;
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgoKI2luY2x1ZGUgPHN0cmluZz4KCnN0ZDo6c3RyaW5nIHJldmVyc2UoY29uc3Qgc3RkOjpzdHJpbmcmIHN0cikgewoKwqDCoHN0ZDo6c3RyaW5nIHJlc3VsdDsKCsKgwqBmb3IgKGludCBpID0gc3RyLmxlbmd0aCgpIC0gMTsgaSA+PSAwOyBpLS0pIHsKCsKgwqDCoMKgcmVzdWx0ICs9IHN0cltpXTsKCsKgwqB9CgrCoMKgcmV0dXJuIHJlc3VsdDsKCn0KCmludCBtYWluKCkgewoKwqDCoHN0ZDo6c3RyaW5nIHN0cjsKCsKgwqBzdGQ6OmNvdXQgPDwgIkVudGVyIGEgc3RyaW5nOiAiOwoKwqDCoHN0ZDo6Y2luID4+IHN0cjsKCsKgwqBzdGQ6OnN0cmluZyByZXN1bHQgPSByZXZlcnNlKHN0cik7CgrCoMKgc3RkOjpjb3V0IDw8ICJSZXZlcnNlZCBzdHJpbmc6ICIgPDwgcmVzdWx0IDw8IHN0ZDo6ZW5kbDsKCsKgwqByZXR1cm4gMDsKCn0=
# Output (for input "hello"):
# Enter a string: hello
# Reversed string: olleh
11. What is a monad in functional programming?
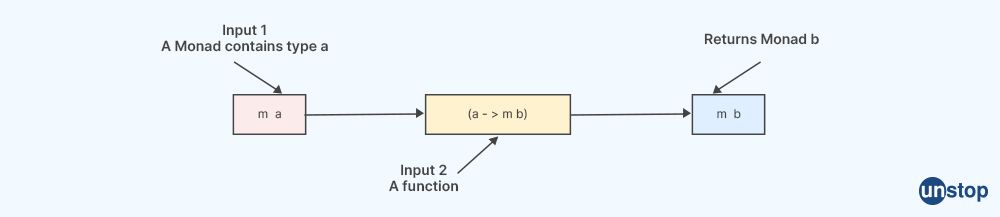
A monad is a programming concept that originated in functional programming languages and provides a way to encapsulate computations that involve side effects, such as I/O, state, or exceptions, in a purely functional way. It is a design pattern that allows for sequencing and chaining of operations in a clean and compositional manner.
In functional programming, immutability and referential transparency are emphasized, which means that functions do not have side effects and always produce the same output for the same input. However, in practical programming, there are often computations that involve side effects, such as reading from or writing to a file, performing I/O operations, or managing state. Monads provide a way to handle these side effects in a functional programming style while preserving the purity of functional programming.
12. Describe the concept of pointers in C and how they are used.
In C, a pointer is a variable that stores the memory address of another variable. Pointers provide a way to indirectly access and manipulate the memory locations where data is stored. Pointers are an important feature of C and are commonly used for tasks such as dynamic memory allocation, passing arguments to functions by reference, and working with arrays and strings.
Here are some key concepts related to pointers in C:
- Declaration and Initialization: Pointers are declared using the asterisk (*) symbol followed by the name of the pointer variable. For example:
int *ptr; // Declaration of an integer pointer
- Dereferencing: Dereferencing a pointer means accessing the value stored at the memory location pointed to by the pointer. This is done using the dereference operator (*) followed by the name of the pointer variable. For example:
int y = *ptr; // Dereferencing the pointer ptr to access the value stored at its memory location and storing it in a variable y
- Pointer Arithmetic: Pointers can be used for pointer arithmetic, which allows for the manipulation of memory addresses based on the size of the data type pointed to. For example:
int *ptr = /* ... */; // Declaration and initialization of an integer pointer
ptr++; // Incrementing the pointer to point to the next memory location
13. Write a C++ program to implement a stack data structure.
#include
using namespace std;
const int MAX = 100;
class Stack {
int top;
public:
int a[MAX]; // Maximum size of Stack
Stack() { top = -1; }
bool push(int x);
int pop();
bool isEmpty();
};
bool Stack::push(int x) {
if (top >= (MAX-1)) {
cout << "Stack Overflow";
return false;
}
else {
a[++top] = x;
cout << x << " pushed into stack\n";
return true;
}
}
int Stack::pop() {
if (top < 0) {
cout << "Stack Underflow";
return 0;
}
else {
int x = a[top--];
return x;
}
}
bool Stack::isEmpty() {
return (top < 0);
}
int main() {
Stack s;
s.push(10);
s.push(20);
s.push(30);
cout << s.pop() << " Popped from stack\n";
return 0;
}
I2luY2x1ZGU8aW9zdHJlYW0+Cgp1c2luZyBuYW1lc3BhY2Ugc3RkOwoKY29uc3QgaW50IE1BWCA9IDEwMDsKCmNsYXNzIFN0YWNrIHsKCsKgwqBpbnQgdG9wOwoKcHVibGljOgoKwqDCoGludCBhW01BWF07IC8vIE1heGltdW0gc2l6ZSBvZiBTdGFjawoKwqDCoFN0YWNrKCkgeyB0b3AgPSAtMTsgfQoKwqDCoGJvb2wgcHVzaChpbnQgeCk7CgrCoMKgaW50IHBvcCgpOwoKwqDCoGJvb2wgaXNFbXB0eSgpOwoKfTsKCmJvb2wgU3RhY2s6OnB1c2goaW50IHgpIHsKCsKgwqBpZiAodG9wID49IChNQVgtMSkpIHsKCsKgwqDCoMKgY291dCA8PCAiU3RhY2sgT3ZlcmZsb3ciOwoKwqDCoMKgwqByZXR1cm4gZmFsc2U7CgrCoMKgfQoKwqDCoGVsc2UgewoKwqDCoMKgwqBhWysrdG9wXSA9IHg7CgrCoMKgwqDCoGNvdXQgPDwgeCA8PCAiIHB1c2hlZCBpbnRvIHN0YWNrXG4iOwoKwqDCoMKgwqByZXR1cm4gdHJ1ZTsKCsKgwqB9Cgp9CgppbnQgU3RhY2s6OnBvcCgpIHsKCsKgwqBpZiAodG9wIDwgMCkgewoKwqDCoMKgwqBjb3V0IDw8ICJTdGFjayBVbmRlcmZsb3ciOwoKwqDCoMKgwqByZXR1cm4gMDsKCsKgwqB9CgrCoMKgZWxzZSB7CgrCoMKgwqDCoGludCB4ID0gYVt0b3AtLV07CgrCoMKgwqDCoHJldHVybiB4OwoKwqDCoH0KCn0KCmJvb2wgU3RhY2s6OmlzRW1wdHkoKSB7CgrCoMKgcmV0dXJuICh0b3AgPCAwKTsKCn0KCmludCBtYWluKCkgewoKwqDCoFN0YWNrIHM7CgrCoMKgcy5wdXNoKDEwKTsKCsKgwqBzLnB1c2goMjApOwoKwqDCoHMucHVzaCgzMCk7CgrCoMKgY291dCA8PCBzLnBvcCgpIDw8ICIgUG9wcGVkIGZyb20gc3RhY2tcbiI7CgrCoMKgcmV0dXJuIDA7Cgp9
# Output:
# 10 pushed into stack
# 20 pushed into stack
# 30 pushed into stack
# 30 Popped from stack
14. Write a C program to find the sum of all elements in a given array of integers.
#include
int main() {
int arr[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
int n = sizeof(arr)/sizeof(arr[0]);
int sum = 0;
for (int i = 0; i < n; i++) {
sum += arr[i];
}
printf("The sum of all elements in the array is: %d\n", sum);
return 0;
}
I2luY2x1ZGU8c3RkaW8uaD4KCmludCBtYWluKCkgewoKwqDCoGludCBhcnJbXSA9IHsxLCAyLCAzLCA0LCA1LCA2LCA3LCA4LCA5LCAxMH07CgrCoMKgaW50IG4gPSBzaXplb2YoYXJyKS9zaXplb2YoYXJyWzBdKTsKCsKgwqBpbnQgc3VtID0gMDsKCsKgwqBmb3IgKGludCBpID0gMDsgaSA8IG47IGkrKykgewoKwqDCoMKgwqBzdW0gKz0gYXJyW2ldOwoKwqDCoH0KCsKgwqBwcmludGYoIlRoZSBzdW0gb2YgYWxsIGVsZW1lbnRzIGluIHRoZSBhcnJheSBpczogJWRcbiIsIHN1bSk7CgrCoMKgcmV0dXJuIDA7Cgp9
# Output:
# The sum of all elements in the array is: 55
15. Write a C++ code to find the average of all elements in a given array of integers.
#include
int main() {
int arr[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
int n = sizeof(arr)/sizeof(arr[0]);
int sum = 0;
for (int i = 0; i < n; i++) {
sum += arr[i];
}
printf("The sum of all elements in the array is: %d\n", sum);
return 0;
}
I2luY2x1ZGU8c3RkaW8uaD4KCmludCBtYWluKCkgewoKwqDCoGludCBhcnJbXSA9IHsxLCAyLCAzLCA0LCA1LCA2LCA3LCA4LCA5LCAxMH07CgrCoMKgaW50IG4gPSBzaXplb2YoYXJyKS9zaXplb2YoYXJyWzBdKTsKCsKgwqBpbnQgc3VtID0gMDsKCsKgwqBmb3IgKGludCBpID0gMDsgaSA8IG47IGkrKykgewoKwqDCoMKgwqBzdW0gKz0gYXJyW2ldOwoKwqDCoH0KCsKgwqBwcmludGYoIlRoZSBzdW0gb2YgYWxsIGVsZW1lbnRzIGluIHRoZSBhcnJheSBpczogJWRcbiIsIHN1bSk7CgrCoMKgcmV0dXJuIDA7Cgp9
# Output:
# The average of all elements in the array is: 5.5
16. Explain the difference between a stack and a heap in C++.
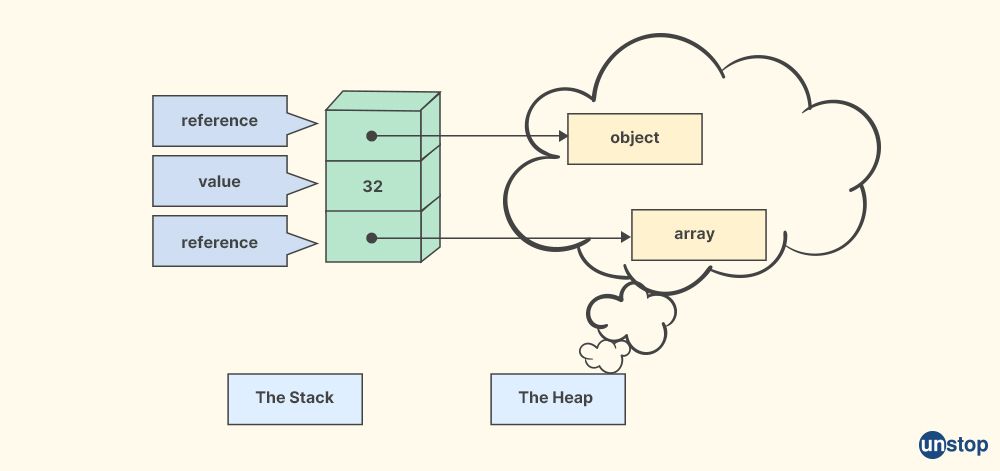
In C++, the stack and the heap are two different areas of memory used for storing data during program execution. They differ in how memory is allocated and deallocated, their size, and their accessibility. Here are the key differences between the stack and the heap in C++:
Stack:
- Memory Allocation: The stack is a region of memory that is automatically allocated and deallocated by the compiler as functions are called and return. Memory allocation on the stack is done in a last-in, first-out (LIFO) manner, similar to how items are stacked on top of each other.
- Size: The size of the stack is typically limited and smaller than the heap. The exact size of the stack is determined at compile-time and depends on the system's stack size limit.
- Allocation/Deallocation Speed: Memory allocation and deallocation on the stack are generally faster than on the heap because the stack is managed by the compiler and does not require explicit memory management operations.
- Scope: Variables declared on the stack have a limited scope and lifetime that is tied to the block or function in which they are declared. Once the block or function exits, the variables are automatically deallocated.
- Accessibility: Variables on the stack are typically local to the function or block in which they are declared and are not accessible outside of that scope.
- Memory Management: The stack is automatically managed by the compiler, and developers do not need to explicitly allocate or deallocate memory on the stack.
Heap:
- Memory Allocation: The heap is a region of memory that is allocated and deallocated manually by the programmer using dynamic memory allocation functions such as
new,delete,malloc, andfree. Memory allocation on the heap is done in a more flexible and arbitrary manner. - Size: The size of the heap is typically larger than the stack and is limited only by the available system memory.
- Allocation/Deallocation Speed: Memory allocation and deallocation on the heap are generally slower than on the stack because they require explicit memory management operations and are not automatically managed by the compiler.
- Scope: Variables allocated on the heap have a dynamic scope and lifetime that can span beyond the block or function in which they are created. It is the responsibility of the programmer to manage the memory and deallocate it when no longer needed to avoid memory leaks.
- Accessibility: Variables allocated on the heap can be accessed from anywhere in the program as long as a valid pointer to the memory is available.
- Memory Management: The heap requires explicit memory management operations by the programmer, and it is the responsibility of the programmer to allocate and deallocate memory on the heap properly to avoid memory leaks or other memory-related issues.
In summary, the stack and the heap are two different areas of memory used for storing data in C++, with differences in memory allocation, size, allocation/deallocation speed, scope, accessibility, and memory management. The stack is automatically managed by the compiler and used for the temporary storage of local variables, while the heap requires explicit memory management operations by the programmer and is used for dynamic memory allocation with a longer lifespan and wider accessibility.
Q17. What is heap memory?
Heap memory, also known as the "free store" in C++, is a region of memory that is used for dynamic memory allocation. In other words, heap memory allows a programmer to allocate and deallocate memory during runtime as needed, unlike stack memory which is automatically allocated and deallocated by the compiler.
Heap memory is used for storing data that needs to have a longer lifespan than the scope of the function or block in which it is created, or for data that needs to be accessed from multiple parts of a program. For example, objects created using the new operator in C++ are allocated on the heap, and the memory for these objects must be manually deallocated using the delete operator to avoid memory leaks.
Heap memory is allocated using dynamic memory allocation functions such as new, new[], malloc, or other platform-specific allocation functions, and the allocated memory remains reserved until it is explicitly deallocated by the programmer. Heap memory is not automatically reclaimed by the compiler when it goes out of scope, unlike stack memory which is automatically deallocated when a function or block exits.
It is important to manage heap memory carefully to avoid memory leaks, which occur when memory is allocated on the heap but not properly deallocated, leading to memory being consumed without being released, and eventually leading to program instability and crashes. Properly managing heap memory involves allocating memory when needed, deallocating it when it is no longer needed, and avoiding common issues such as double-free or use-after-free errors.
18. Can you explain SQL and its uses?
SQL stands for Structured Query Language, and it is a domain-specific language used for managing relational databases. SQL is used to define, manipulate, and retrieve data from relational databases, which are a common type of database used for organizing and storing data in a structured manner.
SQL is widely used in the field of database management and has become a standard language for working with relational databases. Some of the key uses of SQL include:
-
Database Creation: SQL is used to create databases, define their structure, and specify the data types and constraints for storing data. SQL provides commands such as CREATE DATABASE, CREATE TABLE, ALTER TABLE, and DROP TABLE, among others, for managing the structure of a relational database.
-
Data Insertion, Modification, and Deletion: SQL is used to insert new data into a database, update existing data, and delete data from a database. SQL provides commands such as INSERT, UPDATE, and DELETE for managing data stored in a relational database.
-
Data Retrieval: SQL is used to retrieve data from a database based on various conditions and criteria. SQL provides commands such as SELECT, FROM, WHERE, JOIN, GROUP BY, ORDER BY, and others for querying and retrieving data from a relational database.
-
Data Definition: SQL is used for defining the structure of a database, including defining tables, constraints, indexes, views, and other database objects. SQL provides commands such as CREATE, ALTER, and DROP for defining and modifying the structure of a relational database.
-
Data Management: SQL provides various features for managing data in a relational database, such as transactions, concurrency control, and access control. Transactions allow for atomic and consistent operations on a database, while concurrency control ensures that multiple users can access and modify a database simultaneously without conflicts. Access control allows for defining permissions and privileges for users to access and manipulate data in a database.
-
Data Analysis: SQL provides powerful programming tools for analyzing data stored in a relational database, including aggregate functions, subqueries, and advanced querying capabilities. SQL supports complex queries, joins, and calculations, which allow for data analysis, reporting, and decision-making tasks.
-
Database Administration: SQL is used for managing and administering relational databases, including tasks such as backup and recovery, database optimization, performance tuning, and security management. SQL provides commands and features for managing the overall health, performance, and security of a relational database.
19. What is a relational database, and why is SQL used with it?
A relational database is a type of database that organizes data in tables with rows and columns, where the data is stored in a structured and organized manner. Each table in a relational database represents a specific entity or concept, and the rows in the table represent individual instances of that entity, while the columns represent the attributes or properties of the entity. The relationships between the tables are established through keys, which are used to uniquely identify and link data across different tables.
SQL (Structured Query Language) is used with relational databases because it provides a standardized and powerful language for managing data in a structured and organized manner. SQL allows users to define, manipulate, and retrieve data from relational databases using a set of commands and features that are specifically designed for working with tables, rows, and columns.
20. Write a SQL query to select all columns and rows from a table named "students."
SELECT * FROM students;
21. Write a SQL query to find the second highest salary of employees.
SELECT MAX(salary)
FROM employees
WHERE salary NOT IN (
SELECT MAX(salary)
FROM employees
);
22. Write a SQL query to find the name and salary of the employee who has the highest salary.
SELECT name, salary
FROM employees
WHERE salary = (SELECT MAX(salary) FROM employees);
23. Write a SQL query to find the second highest salary from the "employees" table.
SELECT MAX(salary)
FROM employees
WHERE salary NOT IN (SELECT MAX(salary) FROM employees);
24. What is the difference between primary and foreign keys in SQL?
In SQL, primary keys and foreign keys are used to establish relationships between tables in a relational database. They are used to ensure data integrity and maintain consistency across tables. Here are the key differences between primary keys and foreign keys:
Primary Key:
-
Definition: A primary key is a column or set of columns in a table that uniquely identifies each row in the table. It must have a unique value for each row and cannot contain NULL values.
-
Purpose: The primary key is used to uniquely identify each row in a table and ensure that each row has a unique identity. It is used to uniquely identify a record in the table and serves as the reference point for other tables to establish relationships.
-
Constraints: A primary key enforces the uniqueness constraint, which means that no two rows in the table can have the same primary key value. It is also used as the default referencing column for foreign keys in other tables.
-
Declaration: In SQL, primary keys are declared using the PRIMARY KEY constraint when creating a table or altering a table.
Foreign Key:
-
Definition: A foreign key is a column or set of columns in a table that refers to the primary key of another table. It establishes a relationship between two tables, where the foreign key in one table refers to the primary key in another table.
-
Purpose: The foreign key is used to establish relationships between tables, usually for referencing data from one table to another. It represents a relationship between two tables where the foreign key table has a dependency on the primary key table.
-
Constraints: A foreign key enforces referential integrity, which means that the values in the foreign key column must match the values in the primary key column of the referenced table. It ensures that data in the referencing table is consistent with data in the referenced table.
-
Declaration: In SQL, foreign keys are declared using the FOREIGN KEY constraint when creating a table or altering a table. The foreign key column in one table refers to the primary key column in another table.
25. Explain Java and its various features.

Java is a widely used and popular programming language known for its portability, platform independence, and versatility. It is an object-oriented programming language that was initially developed by Sun Microsystems (now owned by Oracle) in the mid-1990s. Java has become one of the most widely used programming languages for developing a wide range of applications, including desktop applications, web applications, mobile apps, embedded systems, and more.
Some of the key features of Java include:
-
Platform independence: Java code is compiled into an intermediate form called bytecode, which is then interpreted by the Java Virtual Machine (JVM) at runtime. This allows Java applications to be run on any platform that has a JVM installed, making Java code platform-independent.
-
Object-oriented programming (OOP): Java is an object-oriented programming language, which means it follows the principles of OOP, such as encapsulation, inheritance, polymorphism, and abstraction. This allows for modular, scalable, and maintainable code.
-
Garbage collection: Java has automatic memory management through an integrated garbage collector, which helps in managing memory by automatically cleaning up unused objects, preventing memory leaks and reducing the risk of memory-related errors.
-
Exception handling: Java has built-in support for exception handling, which allows developers to write code to handle errors and exceptions gracefully, preventing the application from crashing due to unexpected situations.
-
Multi-threading: Java supports multi-threading, which allows for the concurrent execution of threads, enabling developers to write concurrent and parallel code for efficient utilization of system resources.
-
Rich class library: Java comes with a large standard class library, known as the Java Development Kit (JDK), which provides a wide range of pre-built classes and APIs for various tasks, such as I/O, networking, GUI, database access, and more, making it easier and faster to develop Java applications.
-
Security: Java has built-in security features, such as a security manager and a robust security architecture, which makes it suitable for developing secure applications, particularly for the web.
-
Portability: Java's "write once, run anywhere" (WORA) philosophy allows Java code to be compiled into bytecode that can run on any system with a JVM installed, making it highly portable across different platforms and operating systems.
-
Community and ecosystem: Java has a large and active community of developers, with a vast ecosystem of libraries, frameworks, programming tools, and resources that contribute to its rich development ecosystem.
26. What is inheritance in OOP? How is it used in Java?
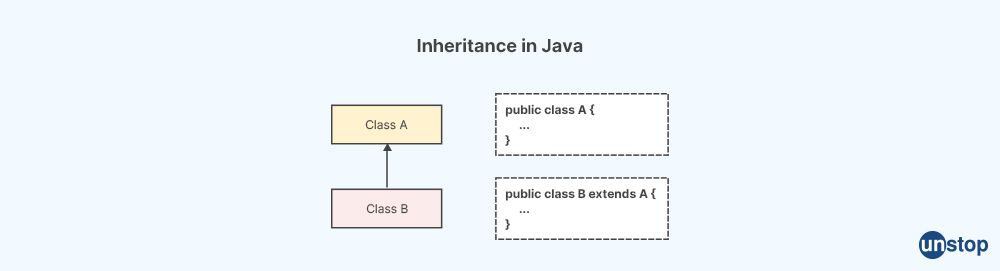
In object-oriented programming (OOP), inheritance is a mechanism that allows a class to inherit properties (fields) and behaviors (methods) from another class, known as a superclass or parent class. The class that inherits from the superclass is called a subclass or child class. Inheritance is a way to create a hierarchy of classes, where subclasses can inherit and extend the properties and behaviors of their parent class.
In Java, inheritance is a fundamental feature of the language and is used to establish relationships between classes. Java supports single inheritance, which means a subclass can inherit from only one superclass. However, Java supports multiple levels of inheritance, where a subclass can itself become a superclass for another subclass.
In Java, inheritance is achieved using the extends keyword. The syntax for inheriting a class in Java is as follows:
class Subclass extends Superclass {
// subclass members
}
The subclass can then access the public and protected members (fields and methods) of the superclass, as well as override or extend them as needed. Inherited members are treated as if they were defined in the subclass itself.
Java also supports access modifiers that control the visibility and accessibility of inherited members. For example, members marked as private in the superclass are not accessible in the subclass, while members marked as public or protected are accessible.
27. Write a Java program to check if a given number is even or odd.
import java. Util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
System. out.print("Enter a number: ");
int number = scan.next();
if (number % 2 == 0) {
System.out.println(number + " is even");
} else {
System.out.println(number + " is odd");
}
}
}
aW1wb3J0IGphdmEuIFV0aWwuU2Nhbm5lcjsKCnB1YmxpYyBjbGFzcyBNYWluIHsKCsKgwqBwdWJsaWMgc3RhdGljIHZvaWQgbWFpbihTdHJpbmdbXSBhcmdzKSB7CgrCoMKgwqDCoFNjYW5uZXIgc2NhbiA9IG5ldyBTY2FubmVyKFN5c3RlbS5pbik7CgrCoMKgwqDCoFN5c3RlbS4gb3V0LnByaW50KCJFbnRlciBhIG51bWJlcjogIik7CgrCoMKgwqDCoGludCBudW1iZXIgPSBzY2FuLm5leHQoKTsKCsKgwqDCoMKgaWYgKG51bWJlciAlIDIgPT0gMCkgewoKwqDCoMKgwqDCoMKgU3lzdGVtLm91dC5wcmludGxuKG51bWJlciArICIgaXMgZXZlbiIpOwoKwqDCoMKgwqB9IGVsc2UgewoKwqDCoMKgwqDCoMKgU3lzdGVtLm91dC5wcmludGxuKG51bWJlciArICIgaXMgb2RkIik7CgrCoMKgwqDCoH0KCsKgwqB9Cgp9
# Output (for input 4):
# Enter a number: 4
# 4 is even
28. Write a Java program to print the first 10 Fibonacci numbers.
public class Main {
public static void main(String[] args) {
int a = 0, b = 1, c, i;
System.out.print("First 10 Fibonacci numbers: ");
for (i = 0; i < 10; i++) {
System.out.print(a + " ");
c = a + b;
a = b;
b = c;
}
}
}
cHVibGljIGNsYXNzIE1haW4gewoKwqDCoHB1YmxpYyBzdGF0aWMgdm9pZCBtYWluKFN0cmluZ1tdIGFyZ3MpIHsKCsKgwqDCoMKgaW50IGEgPSAwLCBiID0gMSwgYywgaTsKCsKgwqDCoMKgU3lzdGVtLm91dC5wcmludCgiRmlyc3QgMTAgRmlib25hY2NpIG51bWJlcnM6ICIpOwoKwqDCoMKgwqBmb3IgKGkgPSAwOyBpIDwgMTA7IGkrKykgewoKwqDCoMKgwqDCoMKgU3lzdGVtLm91dC5wcmludChhICsgIiAiKTsKCsKgwqDCoMKgwqDCoGMgPSBhICsgYjsKCsKgwqDCoMKgwqDCoGEgPSBiOwoKwqDCoMKgwqDCoMKgYiA9IGM7CgrCoMKgwqDCoH0KCsKgwqB9Cgp9
# Output:
# First 10 Fibonacci numbers: 0 1 1 2 3 5 8 13 21 34
29. Write a Java program to reverse a string without using the built-in reverse function.
import java.util.Scanner;
public class Main {
public static String reverseString(String str) {
char[] strArray = str.toCharArray();
int i = 0;
int j = strArray.length - 1;
while (i < j) {
char temp = strArray[i];
strArray[i] = strArray[j];
strArray[j] = temp;
i++;
j--;
}
return new String(strArray);
}
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
System.out.print("Enter a string: ");
String str = scan.nextLine();
String reversed = reverseString(str);
System.out.println("The reversed string is: " + reversed);
}
}
aW1wb3J0IGphdmEudXRpbC5TY2FubmVyOwoKcHVibGljIGNsYXNzIE1haW4gewoKwqDCoHB1YmxpYyBzdGF0aWMgU3RyaW5nIHJldmVyc2VTdHJpbmcoU3RyaW5nIHN0cikgewoKwqDCoMKgwqBjaGFyW10gc3RyQXJyYXkgPSBzdHIudG9DaGFyQXJyYXkoKTsKCsKgwqDCoMKgaW50IGkgPSAwOwoKwqDCoMKgwqBpbnQgaiA9IHN0ckFycmF5Lmxlbmd0aCAtIDE7CgrCoMKgwqDCoHdoaWxlIChpIDwgaikgewoKwqDCoMKgwqDCoMKgY2hhciB0ZW1wID0gc3RyQXJyYXlbaV07CgrCoMKgwqDCoMKgwqBzdHJBcnJheVtpXSA9IHN0ckFycmF5W2pdOwoKwqDCoMKgwqDCoMKgc3RyQXJyYXlbal0gPSB0ZW1wOwoKwqDCoMKgwqDCoMKgaSsrOwoKwqDCoMKgwqDCoMKgai0tOwoKwqDCoMKgwqB9CgrCoMKgwqDCoHJldHVybiBuZXcgU3RyaW5nKHN0ckFycmF5KTsKCsKgwqB9CgrCoMKgcHVibGljIHN0YXRpYyB2b2lkIG1haW4oU3RyaW5nW10gYXJncykgewoKwqDCoMKgwqBTY2FubmVyIHNjYW4gPSBuZXcgU2Nhbm5lcihTeXN0ZW0uaW4pOwoKwqDCoMKgwqBTeXN0ZW0ub3V0LnByaW50KCJFbnRlciBhIHN0cmluZzogIik7CgrCoMKgwqDCoFN0cmluZyBzdHIgPSBzY2FuLm5leHRMaW5lKCk7CgrCoMKgwqDCoFN0cmluZyByZXZlcnNlZCA9IHJldmVyc2VTdHJpbmcoc3RyKTsKCsKgwqDCoMKgU3lzdGVtLm91dC5wcmludGxuKCJUaGUgcmV2ZXJzZWQgc3RyaW5nIGlzOiAiICsgcmV2ZXJzZWQpOwoKwqDCoH0KCn0=
# Output (for input "hello"):
# Enter a string: hello
# The reversed string is: olleh
30. Write a Java code to find the second-highest number in an array of integers.
import java.util.Scanner;
public class Main {
public static String reverseString(String str) {
char[] strArray = str.toCharArray();
int i = 0;
int j = strArray.length - 1;
while (i < j) {
char temp = strArray[i];
strArray[i] = strArray[j];
strArray[j] = temp;
i++;
j--;
}
return new String(strArray);
}
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
System.out.print("Enter a string: ");
String str = scan.nextLine();
String reversed = reverseString(str);
System.out.println("The reversed string is: " + reversed);
}
}
aW1wb3J0IGphdmEudXRpbC5TY2FubmVyOwoKcHVibGljIGNsYXNzIE1haW4gewoKwqDCoHB1YmxpYyBzdGF0aWMgU3RyaW5nIHJldmVyc2VTdHJpbmcoU3RyaW5nIHN0cikgewoKwqDCoMKgwqBjaGFyW10gc3RyQXJyYXkgPSBzdHIudG9DaGFyQXJyYXkoKTsKCsKgwqDCoMKgaW50IGkgPSAwOwoKwqDCoMKgwqBpbnQgaiA9IHN0ckFycmF5Lmxlbmd0aCAtIDE7CgrCoMKgwqDCoHdoaWxlIChpIDwgaikgewoKwqDCoMKgwqDCoMKgY2hhciB0ZW1wID0gc3RyQXJyYXlbaV07CgrCoMKgwqDCoMKgwqBzdHJBcnJheVtpXSA9IHN0ckFycmF5W2pdOwoKwqDCoMKgwqDCoMKgc3RyQXJyYXlbal0gPSB0ZW1wOwoKwqDCoMKgwqDCoMKgaSsrOwoKwqDCoMKgwqDCoMKgai0tOwoKwqDCoMKgwqB9CgrCoMKgwqDCoHJldHVybiBuZXcgU3RyaW5nKHN0ckFycmF5KTsKCsKgwqB9CgrCoMKgcHVibGljIHN0YXRpYyB2b2lkIG1haW4oU3RyaW5nW10gYXJncykgewoKwqDCoMKgwqBTY2FubmVyIHNjYW4gPSBuZXcgU2Nhbm5lcihTeXN0ZW0uaW4pOwoKwqDCoMKgwqBTeXN0ZW0ub3V0LnByaW50KCJFbnRlciBhIHN0cmluZzogIik7CgrCoMKgwqDCoFN0cmluZyBzdHIgPSBzY2FuLm5leHRMaW5lKCk7CgrCoMKgwqDCoFN0cmluZyByZXZlcnNlZCA9IHJldmVyc2VTdHJpbmcoc3RyKTsKCsKgwqDCoMKgU3lzdGVtLm91dC5wcmludGxuKCJUaGUgcmV2ZXJzZWQgc3RyaW5nIGlzOiAiICsgcmV2ZXJzZWQpOwoKwqDCoH0KCn0=
# Output:
# The reverse of the given string is: !dlroW ,olleH
31. Write a Java code to implement the Singleton design pattern.
import java.util.Scanner;
public class Main {
public static String reverseString(String str) {
char[] strArray = str.toCharArray();
int i = 0;
int j = strArray.length - 1;
while (i < j) {
char temp = strArray[i];
strArray[i] = strArray[j];
strArray[j] = temp;
i++;
j--;
}
return new String(strArray);
}
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
System.out.print("Enter a string: ");
String str = scan.nextLine();
String reversed = reverseString(str);
System.out.println("The reversed string is: " + reversed);
}
}
aW1wb3J0IGphdmEudXRpbC5TY2FubmVyOwoKcHVibGljIGNsYXNzIE1haW4gewoKwqDCoHB1YmxpYyBzdGF0aWMgU3RyaW5nIHJldmVyc2VTdHJpbmcoU3RyaW5nIHN0cikgewoKwqDCoMKgwqBjaGFyW10gc3RyQXJyYXkgPSBzdHIudG9DaGFyQXJyYXkoKTsKCsKgwqDCoMKgaW50IGkgPSAwOwoKwqDCoMKgwqBpbnQgaiA9IHN0ckFycmF5Lmxlbmd0aCAtIDE7CgrCoMKgwqDCoHdoaWxlIChpIDwgaikgewoKwqDCoMKgwqDCoMKgY2hhciB0ZW1wID0gc3RyQXJyYXlbaV07CgrCoMKgwqDCoMKgwqBzdHJBcnJheVtpXSA9IHN0ckFycmF5W2pdOwoKwqDCoMKgwqDCoMKgc3RyQXJyYXlbal0gPSB0ZW1wOwoKwqDCoMKgwqDCoMKgaSsrOwoKwqDCoMKgwqDCoMKgai0tOwoKwqDCoMKgwqB9CgrCoMKgwqDCoHJldHVybiBuZXcgU3RyaW5nKHN0ckFycmF5KTsKCsKgwqB9CgrCoMKgcHVibGljIHN0YXRpYyB2b2lkIG1haW4oU3RyaW5nW10gYXJncykgewoKwqDCoMKgwqBTY2FubmVyIHNjYW4gPSBuZXcgU2Nhbm5lcihTeXN0ZW0uaW4pOwoKwqDCoMKgwqBTeXN0ZW0ub3V0LnByaW50KCJFbnRlciBhIHN0cmluZzogIik7CgrCoMKgwqDCoFN0cmluZyBzdHIgPSBzY2FuLm5leHRMaW5lKCk7CgrCoMKgwqDCoFN0cmluZyByZXZlcnNlZCA9IHJldmVyc2VTdHJpbmcoc3RyKTsKCsKgwqDCoMKgU3lzdGVtLm91dC5wcmludGxuKCJUaGUgcmV2ZXJzZWQgc3RyaW5nIGlzOiAiICsgcmV2ZXJzZWQpOwoKwqDCoH0KCn0=
32. What is the difference between an abstract class and an interface in Java?
| Feature | Abstract Class | Interface |
|---|---|---|
| Definition | A class that cannot be instantiated and can contain both concrete and abstract methods. | A collection of abstract methods that can be implemented by any class. |
| Inheritance | Can be extended using the extends keyword, and a subclass can only extend one abstract class. |
Can be implemented using the implements keyword, and a class can implement multiple interfaces. |
| Constructor | Can have constructors, and they are called when a subclass is instantiated. | Cannot have constructors. |
| Fields | Can have instance variables and constants (static and non-static fields). | Can have only static final constants (by default) or static non-final fields. |
| Method Types | Can have both abstract and concrete methods. | Can have only abstract methods (prior to Java 8) or default and static methods (Java 8+). |
| Method Bodies | Can have method bodies (concrete methods) in addition to abstract methods. | Cannot have method bodies, all methods are abstract by default (prior to Java 8). |
| Multiple Inheritance | Does not support multiple inheritance, as a class can extend only one abstract class. | Supports multiple inheritance, as a class can implement multiple interfaces. |
| Usage | Used for creating a base class that provides common behavior and can be extended by subclasses. | Used for defining a contract of methods that can be implemented by unrelated classes. |
| Access Modifiers | Can have public, protected, default, and private members. | All members are public by default (prior to Java 9), or can have public, protected, default (package-private), or private members (Java 9+). |
33. What is the purpose of inheritance in object-oriented programming?
Inheritance is a fundamental concept in object-oriented programming (OOP) that allows one class to inherit properties and methods from another class. The main purpose of inheritance is to facilitate code reuse and promote modularity in the software development life cycle. Some of the key purposes of inheritance in OOP are:
-
Code Reusability: Inheritance allows a class to inherit properties and methods from another class, which promotes code reuse. A subclass can extend and inherit the characteristics of a superclass, reducing the need to duplicate code and resulting in more efficient and maintainable code.
-
Modularity: Inheritance promotes modularity by allowing the code to be organized into a hierarchical file structure of related classes. Common attributes and behaviors can be encapsulated in a base or parent class, and specific attributes and behaviors can be defined in derived or child classes. This enables better organization, maintenance, and understanding of the codebase.
-
Polymorphism: Inheritance enables polymorphism, which allows objects of different classes to be treated as if they were of the same type. Polymorphism provides flexibility and extensibility to the code, as objects of different classes that inherit from a common superclass can be used interchangeably in code that operates on the superclass, without needing to know the specific subclass.
-
Method Overriding: Inheritance allows subclasses to override methods of their superclass, which allows for customization and specialization of behavior. Subclasses can provide their own implementation of methods, which allows for customization of behavior based on specific requirements.
-
Code Organization: Inheritance provides a structured and organized way to represent relationships between classes. It promotes code organization by grouping related classes into a hierarchy based on their inheritance relationships, making the codebase easier to understand and manage.
34. What is the difference between a thread and a process in operating systems?
| Aspect | Threads | Processes |
|---|---|---|
| Concurrency | Lightweight, share memory space with parent process | Heavyweight, have separate memory space |
| Resource Overhead | Less resource overhead compared to processes | More resource overhead compared to threads |
| Isolation | Threads are not isolated from each other, share memory space | Processes are isolated from each other, have separate memory space |
| Parallelism | Designed for concurrent execution within the same process | Designed for independent execution |
| Communication | Can communicate through shared variables and data structures | Require inter-process communication (IPC) mechanisms |
| Fault Isolation | A bug or crash in one thread can potentially affect the entire process | A bug or crash in one process does not affect other processes |
35. What is the difference between an object and a class in OOP?
In object-oriented programming (OOP), an object and a class are related concepts but they are not the same. Here's a summary of the main differences between an object and a class:
| Aspect | Object | Class |
|---|---|---|
| Definition | An instance of a class, created from a class blueprint | A blueprint or template that defines the type of structure and behavior of objects |
| Usage | Represents a specific instance of a concept or entity in the real world | Represents a generalized concept or entity |
| Properties | Has state (values of attributes/fields) specific to the object | Defines attributes/fields that objects of that class will have |
| Methods | Has behavior (methods/functions) specific to the object | Defines methods/functions that objects of that class can perform |
| Memory | Takes up memory when instantiated | Does not take up memory, it's a blueprint |
| Relationship | Objects are instances of a class | Class is a blueprint or template used to create objects |
| Instantiation | Objects are created using the "new" keyword or by calling a default constructor | Classes are defined in the code and used to create objects |
36. What is the difference between a mutex and a semaphore in the context of multi-threading and synchronization?
In the context of multi-threading and synchronization, mutex and semaphore are two commonly used synchronization primitives that are used to coordinate access to shared resources among threads. Here's a summary of the main differences between mutex and semaphore:
| Aspect | Mutex | Semaphore |
|---|---|---|
| Usage | Used to provide exclusive access to a shared resource by only one thread at a time | Used to control access to a shared resource with a specified number of permits |
| Operation | Binary (2-state) synchronization primitive, with two states: locked/unlocked or acquired/released | Can be binary (2-state) or counting (n-state) synchronization primitive |
| Counting | Does not support counting, only allows one thread to hold the mutex at a time | Supports counting, allows multiple threads to acquire permits up to a specified limit |
| Ownership | Can be owned by only one thread at a time | Can be owned by multiple threads at the same time, up to the specified permit limit |
| Release | Must be released by the same thread that acquired it | Can be released by any thread |
| Wait/Notify | Does not support wait/notify mechanism | Supports wait/notify mechanism to signal between threads |
| Deadlock | Can lead to deadlock if not properly managed | Can lead to deadlock if not properly managed |
| Priority Inversion | Can lead to priority inversion, where a higher priority thread is blocked by a lower priority thread holding the mutex | Can be used with priority inheritance or priority ceiling protocols to avoid priority inversion |
37. What is the difference between an abstract class and an interface in Java?
In Java, both abstract classes and interfaces are used to define common behaviors and provide abstraction in object-oriented programming. However, there are some differences between abstract classes and interfaces. Here's a summary of the main differences:
| Aspect | Abstract Class | Interface |
|---|---|---|
| Definition | A class that cannot be instantiated and may have abstract methods | A collection of abstract methods, constants, and default methods |
| Implementation | Can have concrete methods (methods with implementation) in addition to abstract methods | Can only have abstract methods and constants, cannot have concrete methods |
| Multiple Inheritance | Does not support multiple inheritance (i.e., a class can only inherit from one abstract class) | Supports multiple inheritance (i.e., an interface can be implemented by multiple classes) |
| Constructor | Can have default constructors | Cannot have default constructors |
| Inheritance | Can be extended by other classes using "extends" keyword | Can be implemented by classes using "implements" keyword |
| Fields | Can have instance variables and non-constant fields | Can only have constants (static final fields) |
| Accessibility | Can have public, protected, and package-private members | All members are implicitly public |
| Method Overriding | Subclasses can override methods and provide their own implementation | Implementing classes must provide implementation for all abstract methods |
| Usage | Used to provide common implementation and state to subclasses | Used to provide common behavior to unrelated classes, or to achieve multiple inheritance-like behavior |
38. Can you explain the difference between static and dynamic polymorphism in the context of object-oriented programming?
In object-oriented programming, polymorphism is the ability of a single function or method to operate on different types of objects. Polymorphism can be classified into two main types: static polymorphism (also known as compile-time polymorphism) and dynamic polymorphism (also known as runtime polymorphism).
Here's a comparison of static and dynamic polymorphism:
| Aspect | Static Polymorphism | Dynamic Polymorphism |
|---|---|---|
| Definition | Polymorphism is resolved at compile-time | Polymorphism is resolved at runtime |
| Implementation | Achieved through function or method overloading | Achieved through function or method overriding |
| Binding | Occurs during compile-time (early binding or compile-time polymorphism) | Occurs during runtime (late binding or runtime polymorphism) |
| Syntax | Compiler determines the appropriate function or method based on the number or type of arguments | Compiler determines the appropriate function or method based on the type of object at runtime |
| Flexibility | Less flexible, as changes require recompilation | More flexible, as changes can be made at runtime without recompilation |
| Examples | Function overloading, operator overloading | Virtual functions, method overriding |
| Usage | Used when multiple functions or methods with different parameters need to be defined with the same name | Used when different objects of different classes need to respond to the same method call |
In summary, static polymorphism is resolved at compile-time, and it is achieved through function or method overloading, while dynamic polymorphism is resolved at runtime, and it is achieved through function or method overriding. Static polymorphism provides less flexibility, as changes require recompilation, whereas dynamic polymorphism provides more flexibility, as changes can be made at runtime without recompilation.
39. What is Python? Why is it a popular programming language?
Python is a high-level, interpreted, and dynamically-typed programming language that was created by Guido van Rossum and released in 1991. It is widely used for various applications, including web development, scientific computing, data analysis, artificial intelligence, machine learning, automation, and more.
Python has gained immense popularity as a programming language for several reasons:
-
Readability and Simplicity: Python has a clean and easy-to-read syntax, which makes it highly readable and accessible for both beginners and experienced professional programmers. Python's simple and concise syntax allows developers to write code quickly and with fewer lines of code compared to other programming languages, resulting in faster development and easier maintenance.
-
Large Standard Library: Python comes with an extensive standard library that provides a wide range of modules and packages for different tasks, such as handling file I/O, working with databases, networking, regular expressions, and more. This makes it easy to perform many common programming tasks without having to rely on third-party libraries.
-
Cross-Platform Compatibility: Python is a platform-independent language, which means that Python code can run on different operating systems, including Windows, macOS, Linux, and others, without requiring any platform-specific modifications. This makes Python a versatile language that can be used for developing applications on various platforms.
-
Strong Community and Ecosystem: Python has a large and active community of developers who contribute to its development, share libraries, and provide support through forums, mailing lists, and online communities. The Python ecosystem is vast, with numerous third-party libraries and frameworks available for different purposes, such as Django for web development, NumPy for scientific computing, Pandas for data analysis, TensorFlow for machine learning, and many more. This rich ecosystem makes Python a powerful and flexible language for diverse application development.
-
Extensibility and Integration: Python allows easy integration with other programming languages, and it provides interfaces to many external libraries and systems. Python has support for C/C++ integration, which allows developers to write performance-critical code in C/C++ and use it in Python programs, providing the best of both worlds - the simplicity and ease of Python, and the performance of C/C++.
-
Versatility: Python is a versatile language that can be used for a wide range of applications, from simple scripts to complex enterprise applications. Python is used in various domains, including web development, scientific computing, data analysis, machine learning, artificial intelligence, network programming, game development, embedded systems, and more, making it a popular choice for developers with diverse backgrounds and interests.
39. What is a function in Python, and why is it used?
In Python, a function is a named block of code that performs a specific task or set of tasks. Functions are used to encapsulate a sequence of statements into a single unit that can be called and executed from different parts of a program. Functions in Python are defined using the def keyword, followed by the function name, a pair of parentheses that may contain input parameters (arguments), a colon, and a suite of statements that make up the function body.
Functions are an important concept in programming because they allow for modular and reusable code. They provide a way to break down complex tasks into smaller, manageable pieces, which can be organized, tested, and maintained more easily. Functions can take input parameters, perform some computation or action, and return a result or perform a side-effect. Functions can also be used to group related code together, making the code more organized and easier to understand.
Here are some key reasons why functions are used in Python:
-
Code Reusability: Functions allow for the creation of reusable code blocks that can be called multiple times from different parts of a program or even from different programs. This helps to avoid code duplication and promotes efficient code management.
-
Modularity: Functions allow for the separation of complex tasks into smaller, more manageable functions. Each function can be designed to perform a specific task, making the code more organized and easier to understand.
-
Abstraction: Functions can provide abstraction, allowing users to use a function without needing to understand the details of how it works. Functions can be used as black boxes that hide the complexity of the underlying logic, making the code more modular and easier to maintain.
-
Encapsulation: Functions allow for the encapsulation of a specific piece of functionality into a self-contained unit. This can help in encapsulating sensitive logic, protecting it from being modified accidentally or unnecessarily.
-
Code Readability: Functions can improve the readability of code by encapsulating complex logic or repetitive tasks into well-named functions. This makes the code more modular and easier to understand, especially for larger programs or when collaborating with other developers.
-
Code Testing: Functions make it easier to test individual pieces of code in isolation, which helps in identifying and fixing bugs or issues more efficiently. Functions can be unit-tested, and their behavior can be verified independently, making it easier to identify and fix problems in the code.
40. Write a Python code to find the average of a list of numbers.
def average(numbers):
return sum(numbers) / len(numbers)
numbers = [1, 2, 3, 4, 5]
result = average(numbers)
print(result)
ZGVmIGF2ZXJhZ2UobnVtYmVycyk6CgrCoMKgwqAgcmV0dXJuIHN1bShudW1iZXJzKSAvIGxlbihudW1iZXJzKQoKbnVtYmVycyA9IFsxLCAyLCAzLCA0LCA1XQoKcmVzdWx0ID0gYXZlcmFnZShudW1iZXJzKQoKcHJpbnQocmVzdWx0KQ==
# Output:
# 3.0
41. Write a Python code to check if a given year is a leap year.
def is_leap_year(year):
if year % 400 == 0:
return True
elif year % 100 == 0:
return False
elif year % 4 == 0:
return True
else:
return False
year = 2020
result = is_leap_year(year)
print(result)
ZGVmIGlzX2xlYXBfeWVhcih5ZWFyKToKCsKgwqBpZiB5ZWFyICUgNDAwID09IDA6CgrCoMKgwqDCoHJldHVybiBUcnVlCgrCoMKgZWxpZiB5ZWFyICUgMTAwID09IDA6CgrCoMKgwqDCoHJldHVybiBGYWxzZQoKwqDCoGVsaWYgeWVhciAlIDQgPT0gMDoKCsKgwqDCoMKgcmV0dXJuIFRydWUKCsKgwqBlbHNlOgoKwqDCoMKgwqByZXR1cm4gRmFsc2UKCnllYXIgPSAyMDIwCgpyZXN1bHQgPSBpc19sZWFwX3llYXIoeWVhcikKCnByaW50KHJlc3VsdCk=
# Output:
# True
42. Write a Python code to implement a binary search algorithm.
def is_leap_year(year):
if year % 400 == 0:
return True
elif year % 100 == 0:
return False
elif year % 4 == 0:
return True
else:
return False
year = 2020
result = is_leap_year(year)
print(result)
ZGVmIGlzX2xlYXBfeWVhcih5ZWFyKToKCsKgwqBpZiB5ZWFyICUgNDAwID09IDA6CgrCoMKgwqDCoHJldHVybiBUcnVlCgrCoMKgZWxpZiB5ZWFyICUgMTAwID09IDA6CgrCoMKgwqDCoHJldHVybiBGYWxzZQoKwqDCoGVsaWYgeWVhciAlIDQgPT0gMDoKCsKgwqDCoMKgcmV0dXJuIFRydWUKCsKgwqBlbHNlOgoKwqDCoMKgwqByZXR1cm4gRmFsc2UKCnllYXIgPSAyMDIwCgpyZXN1bHQgPSBpc19sZWFwX3llYXIoeWVhcikKCnByaW50KHJlc3VsdCk=
# Output:
mid = 0
while low <= high:
mid = (high + low) // 2
if arr[mid] < x:
low = mid + 1
elif arr[mid] >
elif arr[mid] > x:
high = mid - 1
else:
return mid
return -1
arr = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
x = 4
result = binary_search(arr, x)
# Element is present at index 3
43. What is closure in Python?
In Python, a closure is a nested function that captures and remembers the values of the variables in the enclosing function's scope, even after the enclosing function has completed execution. In other words, a closure allows a nested function to "remember" the environment in which it was created, even if that environment is no longer in scope.
A closure is created when a nested function references a variable from its containing (enclosing) function, and that containing function returns the nested function. The nested function then retains access to the values of those variables, even after the containing function has completed execution.
Here's an example of a closure in Python:
def make_adder(x):
def add(y):
return x + y
return add
add5 = make_adder(5)
add10 = make_adder(10)
print(add5(3)) # prints 8
print(add10(3)) # prints 13
ZGVmIG1ha2VfYWRkZXIoeCk6CmRlZiBhZGQoeSk6CnJldHVybiB4ICsgeQpyZXR1cm4gYWRkCgphZGQ1ID0gbWFrZV9hZGRlcig1KQphZGQxMCA9IG1ha2VfYWRkZXIoMTApCgpwcmludChhZGQ1KDMpKSAjIHByaW50cyA4CnByaW50KGFkZDEwKDMpKSAjIHByaW50cyAxMw==
44. What is the difference between eager and lazy evaluation in functional programming?
Eager evaluation and lazy evaluation are two different approaches to evaluating expressions in functional programming languages. The main difference between them is the timing at which expressions are evaluated and their corresponding results are computed.
Here's a comparison of eager evaluation and lazy evaluation:
| Eager Evaluation | Lazy Evaluation |
|---|---|
| Expressions are evaluated immediately when they are encountered in the code. | Expressions are evaluated only when their results are actually needed. |
| All function arguments are evaluated before the function is called. | Function arguments are evaluated only when they are used inside the function. |
| All elements of a data structure are evaluated when the data structure is created. | Elements of a data structure are evaluated only when they are accessed or used. |
| All side effects of expressions, such as I/O operations, occur immediately. | Side effects of expressions are deferred until the results are needed. |
| Eager evaluation can lead to unnecessary computations, especially for large data sets or complex expressions. | Lazy evaluation can save computation time by avoiding unnecessary evaluations of unused expressions. |
| Eager evaluation is simpler to reason about and may be more intuitive for some programmers. | Lazy evaluation allows for more efficient and flexible computation in some cases. |
45. What is the difference between shallow and deep copying in Python?
In Python, shallow copying and deep copying are two different approaches to creating copies of objects or type of structure. The main difference between them is the level of copying, or the depth to which the copy is made.
Here's a comparison of shallow copying and deep copying in Python:
| Shallow Copy | Deep Copy |
|---|---|
| Creates a new object, but references the same memory location as the original object for mutable objects, and directly copies the value for immutable objects. | Creates a new object and recursively copies all objects referenced by the original object, including all nested objects. |
| Changes made to mutable objects in the copy will reflect in the original object, as they share the same memory location. | Changes made to mutable objects in the copy will not reflect in the original object, as they are stored in different memory locations. |
| Does not create independent copies of nested mutable object . Instead, the copied object references the same memory location as the original object for nested mutable objects. | Creates independent copies of all string objects referenced by the original object, including all nested mutable objects. |
| Shallow copy can be more efficient in terms of time and memory, as it creates references to the original object rather than making actual copies of nested objects. | Deep copy can be less efficient in terms of time and memory, as it recursively copies all objects, including all nested object creations. |
Uses the copy module's copy() function in Python. |
Uses the copy module's deepcopy() function in Python. |
Q46. What is the difference between range() and xrange()?
In Python , range() and xrange() are both built-in functions used to generate a sequence of numbers. However, there are some differences between them:
| range() | xrange() |
|---|---|
| Returns a list object containing a sequence of numbers. | Returns an xrange object which generates numbers on-the-fly and does not create a list. |
| Range function generates a list of numbers in memory manager, which can consume a lot of additional memory for large ranges. | Generates numbers on-the-fly and does not create a list, which is memory-efficient for large ranges. |
| Used in Python 2 for iterating over a sequence of numbers. | Used in Python 2 for iterating over a sequence of numbers. |
| Returns a list, so it can be used with all list methods and supports all list operations. | Returns an xrange object, which is not a list and does not support list methods or list operations. |
| Not suitable for large ranges due to additional memory consumption. | Suitable for large ranges as it does not consume unused memory for the entire range. |
Syntax: range([start], stop[, step]) |
Syntax: xrange([start], stop[, step]) |
Q47. Why do we need the Friend class and function?
In object-oriented programming, the concept of a Friend class or Friend function is used to grant special access privileges to certain classes or functions to access private or protected members of another class. It is a mechanism that allows a class or function to bypass the normal access restrictions and access private or protected members of another class.
The need for a Friend class or function arises in specific scenarios where there is a requirement for close interaction or coordination between classes, or when certain classes or functions need to access private or protected members of another class, which would not be possible otherwise due to access restrictions.
Q48. Briefly describe agile testing.

Agile testing is a software testing approach that is aligned with the principles and values of Agile software development methodology. It emphasizes collaboration, flexibility, and continuous improvement throughout the software development lifecycle (SDLC). Agile testing is based on the Agile Manifesto, which prioritizes individuals and interactions, working solutions, customer collaboration, and responding to change.
In Agile testing, testing activities are integrated into the Agile software development process, with testers working closely with developers, product owners, and other stakeholders. The focus is on early and frequent testing to identify defects as early as possible and address them promptly. Agile Testing promotes a collaborative approach, with testers actively participating in all phases of the software development process, from requirement gathering to deployment and beyond.
Some key principles of Agile Testing include:
-
Continuous Testing: Testing is done continuously throughout the software development, with testing activities integrated into each iteration or sprint of the Agile development process.
-
Collaborative Approach: Testers work closely with developers, product owners, and other stakeholders to understand requirements, develop test cases, and provide feedback on the quality of the software.
-
Test Automation: Agile Testing emphasizes the use of automation tools and techniques to efficiently execute tests and provide rapid feedback on the quality of the software.
-
Early and Frequent Feedback: Agile Testing focuses on providing feedback on the quality of the software as early and frequently as possible, to identify defects and address them promptly.
-
Adaptability: Agile Testing embraces change and encourages testers to be flexible and adaptable in their approach, as requirements and priorities may change during the course of the project.
-
Customer Collaboration: Agile Testing involves active collaboration with customers and other stakeholders to understand their needs, gather feedback, and ensure that the software meets their expectations.
-
Continuous Improvement: Agile Testing promotes a culture of continuous improvement, where testers regularly reflect on their practices, learn from their experiences, and make adjustments to improve the quality of the software and the testing process.
Capgemini Interview Questions: HR Round
1. Tell us about a time when you had to handle a difficult situation with a co-worker or supervisor.
The intention of this Capgemini interview question is to understand if the candidate is capable enough to handle stressful or tricky situations. The interviewee can narrate an incident where they dealt with a difficult situation in the past. An example is as follows.
I was working on a project with a team of developers and one of my team members was not meeting the expected quality standards. Despite numerous attempts to communicate with the team member and provide feedback on their work, their performance did not improve.
To handle this difficult situation, as a team leader, I first took the initiative to schedule a one-on-one meeting with the team member to discuss the issues and concerns. During the meeting, I made sure to actively listen to their perspective and understand any potential obstacles they were facing that might have contributed to their subpar performance.
After understanding their perspective, I clearly and constructively communicated the expectations and consequences of not meeting the quality standards. I also offered support and resources to help them improve their performance, such as additional training or mentorship. This way, through better team management, we were able to deliver the project on time.
2. How do you prioritize tasks and responsibilities in a fast-paced work environment?
Prioritizing tasks and responsibilities in a fast-paced work environment can be challenging, but there are a few strategies that I find helpful:
-
Identify urgent vs. important tasks
-
Make a to-do list
3. Mention one instance when you had to go above and beyond to meet a deadline or achieve a professional goal.
A sample answer to this Capgemini interview question is:
Once I was working on a project with a tight deadline which required us to work beyond office hours. Since the rest of my teammates had family obligations, I volunteered to work overtime and take up additional responsibilities to help other team members who were struggling with their workload. This way we managed to deliver the project on time.
It is suggested to improvise the sample answer by plugging in details of the project and other personalized facts.
4. How do you handle conflicts or disagreements with team members or coworkers?
In these types of Capgemini interview questions, interviewees should describe how they handle disagreements and how they can keep a composed and upbeat attitude under pressure. They should illustrate a circumstance in which they successfully resolved a dispute. They should also highlight their capacity to hear various viewpoints and come up with a decision that benefits the group.
Also read: Here is how you can respectfully disagree in a job interview
5. Tell us about a time when you had to adapt to a change in the workplace.
An example of a time the interviewee had to adjust to a change in the workplace, such as a new procedure or a new team member, should be provided. They should discuss how they successfully adjusted to and incorporated the change into their work. They should emphasize their adaptability and capacity to handle difficult circumstances.
6. Was there any situation when you had to handle multiple tasks or projects simultaneously?
The interviewee should provide an instance where they had to manage several tasks or projects simultaneously. They should describe how they set priorities for their tasks and efficiently complete each. They should also emphasize their capacity to stay organized and concentrated under pressure.
7. Have you ever dealt with a demanding customer or stakeholder?
A specific instance of a time when the interviewee had to deal with a challenging client or stakeholder should be given. They should describe how they approached the problem and found a solution. They should emphasize their capacity for professional and effective communication under trying conditions.
How to Prepare for Capgemini Interview Questions
Capgemini is a service-based company, so acing the interview is generally not too difficult. Below are the most valuable tips you can follow to qualify Capgemini interview (even for a senior analyst role):
- Learn about Object-Oriented Programming (OOPS), its four-pillar, and its real-time example.
- Mostly, they ask about the language you're comfortable with. So, make sure you know the basic features and definitions of the programming language.
- Learn DBMS keywords definition and its basic query.
- Since Capgemini does not take TR and HR interviews separately, make sure you know about the company well before attending the interview.
- Research some of the company's projects and discuss them with the interviewer. This would impart a good impression on the interviewer.
- Regarding coding questions, be thorough with the basics and arrays and strings questions. Mostly they ask questions about these topics only. Practice as much as possible. Understanding Programming Logic is the most critical factor here.
- Be ready for the HR questions, like why should we hire you, why you want to work with us, etc.
- Candidates often miss the chance to ask questions to interviewers at the end. It is an excellent opportunity to learn more about the company and recruiter mindset. So, clear your doubts at the end of your interview.
- If you need more confidence before attending the interview, try to attend mock interviews. It would boost your confidence.
- Communication skill is the key. Fluency in English would always work as a cherry on the cake.
Conclusion
Preparing for a Capgemini interview can be a daunting task, but with the right preparation, you can ace the interview and secure your dream job. The key is to familiarize yourself with the common Capgemini interview questions and come up with confident and relevant answers. The interview questions mentioned in this blog are just a few of the many that you may encounter during the interview process. Remember to stay calm, confident, and focused on your goals. With proper preparation and the right mindset, you can impress the interviewers and stand out as the ideal candidate for the job.
FAQs Regarding Capgemini Hiring Process
1. What is the Capgemini hiring process like?
The Capgemini hiring process typically involves an initial online application, followed by an online assessment test, an interview with a hiring manager, and a final interview with a senior manager. The specific steps may vary based on the position and location.
2. How to prepare for the Capgemini online assessment test?
You can prepare for the Capgemini online assessment test by studying relevant topics such as aptitude, logical reasoning, and verbal ability. Also, for senior positions, there are coding rounds. You can take practice tests and improve your time management skills to ensure that you are able to complete the test in the allotted time.
3. How long does the hiring process take?
The duration of the hiring process can vary depending on the position and the number of applicants. However, on average, the process takes 2-4 weeks.
4. What to expect in the Capgemini interview from a hiring manager?
The interview with a hiring manager is typically focused on your technical skills and experience, as well as your understanding of the company and the role you have applied for. You should be prepared to answer questions about your previous work experience, your education, and your technical skills.
5. Does Capgemini offer any training programs for new hires?
Yes, Capgemini offers training programs for new hires, including orientation and on-the-job training. The specific training opportunities available may vary based on the role and location, but the company is committed to helping its employees grow and develop professionally.
6. Does Capgemini sponsor work visas?
It depends on the specific location and role, but Capgemini may sponsor work visas for international candidates in some cases. It is best to inquire with the company during the hiring process to see if sponsorship is an option for your specific situation.
Login to continue reading
And access exclusive content, personalized recommendations, and career-boosting opportunities.
Don't have an account? Sign up
Never miss an
Update

Featured Opportunities
Top-Rated Practice by Students





Subscribe
to our newsletter
Blogs you need to hog!

How To Write Finance Cover Letter For Morgan Stanley (+Free Sample!)
Unstop

55+ Data Structure Interview Questions For 2026 (Detailed Answers)
Muskaan Mishra

How To Negotiate Salary With HR: Tips And Insider Advice
Srishti Magan

80+ TCS NQT Interview Questions & Answers (2026) You Must Prepare
Urvashi Singhal
Comments
Add comment