

Asian Paints Alchemy 2026
Company Interview Questions for Freshers
- TCS Technical Interview Questions & Answers
- TCS Managerial Interview Questions & Answers
- TCS HR Interview Questions & Answers
- Overview of Cognizant Recruitment Process
- Cognizant Interview Questions: Technical
- Cognizant Interview Questions: HR Round
- Overview of Wipro Technologies Recruitment Rounds
- Wipro Interview Questions
- Technical Round
- HR Round
- Online Assessment Sample Questions
- Frequently Asked Questions
- Overview of Google Recruitment Process
- Google Interview Questions: Technical
- Google Interview Questions: HR round
- Interview Preparation Tips
- About Google
- Deloitte Technical Interview Questions
- Deloitte HR Interview Questions
- Deloitte Recruitment Process
- Technical Interview Questions and Answers
- Level 1 difficulty
- Level 2 difficulty
- Level 3 difficulty
- Behavioral Questions
- Eligibility Criteria for Mindtree Recruitment
- Mindtree Recruitment Process: Rounds Overview
- Skills required to crack Mindtree interview rounds
- Mindtree Recruitment Rounds: Sample Questions
- About Mindtree
- Preparing for Microsoft interview questions
- Microsoft technical interview questions
- Microsoft behavioural interview questions
- Aptitude Interview Questions
- Technical Interview Questions
- Easy
- Intermediate
- Hard
- HR Interview Questions
- Eligibility criteria
- Recruitment rounds & assessments
- Tech Mahindra interview questions - Technical round
- Tech Mahindra interview questions - HR round
- Hiring process at Mphasis
- Mphasis technical interview questions
- Mphasis HR interview questions
- About Mphasis
- Technical interview questions
- HR interview questions
- Recruitment process
- About Virtusa
- Goldman Sachs Interview Process
- Technical Questions for Goldman Sachs Interview
- Sample HR Question for Goldman Sachs Interview
- About Goldman Sachs
- Nagarro Recruitment Process
- Nagarro HR Interview Questions
- Nagarro Aptitude Test Questions
- Nagarro Technical Test Questions
- About Nagarro
- PwC Recruitment Process
- PwC Technical Interview Questions: Freshers and Experienced
- PwC Interview Questions for HR Rounds
- PwC Interview Preparation
- Frequently Asked Questions
- EY Technical Interview Questions (2023)
- EY Interview Questions for HR Round
- About EY
- Morgan Stanley Recruitment Process
- HR Questions for Morgan Stanley Interview
- HR Questions for Morgan Stanley Interview
- About Morgan Stanley
- Recruitment Process at Flipkart
- Technical Flipkart Interview Questions
- Code-Based Flipkart Interview Questions
- Sample Flipkart Interview Questions- HR Round
- Conclusion
- FAQs
- Recruitment Process at Paytm
- Technical Interview Questions for Paytm Interview
- HR Sample Questions for Paytm Interview
- About Paytm
- Most Probable Accenture Interview Questions
- Accenture Technical Interview Questions
- Accenture HR Interview Questions
- Amazon Recruitment Process
- Amazon Interview Rounds
- Common Amazon Interview Questions
- Amazon Interview Questions: Behavioral-based Questions
- Amazon Interview Questions: Leadership Principles
- Company-specific Amazon Interview Questions
- 43 Top Technical/ Coding Amazon Interview Questions
- Juspay Recruitment: Stages and Timeline
- Juspay Interview Questions and Answers
- How to prepare for Juspay interview questions
- Prepare for the Juspay Interview: Stages and Timeline
- Frequently Asked Questions
- Adobe Interview Questions - Technical
- Adobe Interview Questions - HR
- Recruitment Process at Adobe
- About Adobe
- Cisco technical interview questions
- Sample HR interview questions
- The recruitment process at Cisco
- About Cisco
- JP Morgan interview questions (Technical round)
- JP Morgan interview questions HR round)
- Recruitment process at JP Morgan
- About JP Morgan
- Wipro Elite NTH: Selection Process
- Wipro Elite NTH Technical Interview Questions
- Wipro Elite NTH Interview Round- HR Questions
- BYJU's BDA Interview Questions
- BYJU's SDE Interview Questions
- BYJU's HR Round Interview Questions
- A Quick Overview of the KPMG Recruitment Process
- Technical Questions for KPMG Interview
- HR Questions for KPMG Interview
- About KPMG
- DXC Technology Interview Process
- DCX Technical Interview Questions
- Sample HR Questions for DXC Technology
- About DXC Technology
- Recruitment Process at PayPal
- Technical Questions for PayPal Interview
- HR Sample Questions for PayPal Interview
- About PayPal
- Capgemini Recruitment Rounds
- Capgemini Interview Questions: Technical round
- Capgemini Interview Questions: HR round
- Preparation tips
- FAQs
- Technical interview questions for Siemens
- Sample HR questions for Siemens
- The recruitment process at Siemens
- About Siemens
- HCL Technical Interview Questions
- HR Interview Questions
- HCL Technologies Recruitment Process
- List of EPAM Interview Questions for Technical Interviews
- About EPAM
- Atlassian Interview Process
- Top Skills for Different Roles at Atlassian
- Atlassian Interview Questions: Technical Knowledge
- Atlassian Interview Questions: Behavioral Skills
- Atlassian Interview Questions: Tips for Effective Preparation
- Walmart Recruitment Process
- Walmart Interview Questions and Sample Answers (HR Round)
- Walmart Interview Questions and Sample Answers (Technical Round)
- Tips for Interviewing at Walmart and Interview Preparation Tips
- Frequently Asked Questions
- Uber Interview Questions For Engineering Profiles: Coding
- Technical Uber Interview Questions: Theoretical
- Uber Interview Question: HR Round
- Uber Recruitment Procedure
- About Uber Technologies Ltd.
- Intel Technical Interview Questions
- Computer Architecture Intel Interview Questions
- Intel DFT Interview Questions
- Intel Interview Questions for Verification Engineer Role
- Recruitment Process Overview
- Important Accenture HR Interview Questions
- Points to remember
- What is Selenium?
- What are the components of the Selenium suite?
- Why is it important to use Selenium?
- What's the major difference between Selenium 3.0 & Selenium 2.0?
- What is Automation testing and what are its benefits?
- What are the benefits of Selenium as an Automation Tool?
- What are the drawbacks to using Selenium for testing?
- Why should Selenium not be used as a web application or system testing tool?
- Is it possible to use selenium to launch web browsers?
- What does Selenese mean?
- What does it mean to be a locator?
- Identify the main difference between "assert", and "verify" commands within Selenium
- What does an exception test in Selenium mean?
- What does XPath mean in Selenium? Describe XPath Absolute & XPath Relation
- What is the difference in Xpath between "//"? and "/"?
- What is the difference between "type" and the "typeAndWait" commands within Selenium?
- Distinguish between findElement() & findElements() in context of Selenium
- How long will Selenium wait before a website is loaded fully?
- What is the difference between the driver.close() and driver.quit() commands in Selenium?
- Describe the different navigation commands that Selenium supports
- What is Selenium's approach to the same-origin policy?
- Explain the difference between findElement() in Selenium and findElements()
- Explain the pause function in SeleniumIDE
- Explain the differences between different frameworks and how they are connected to Selenium's Robot Framework
- What are your thoughts on the Page Object Model within the context of Selenium
- What are your thoughts on Jenkins?
- What are the parameters that selenium commands come with a minimum?
- How can you tell the differences in the Absolute pathway as well as Relative Path?
- What's the distinction in Assert or Verify declarations within Selenium?
- What are the points of verification that are in Selenium?
- Define Implicit wait, Explicit wait, and Fluent
- Can Selenium manage windows-based pop-ups?
- What's the definition of an Object Repository?
- What is the main difference between obtainwindowhandle() as well as the getwindowhandles ()?
- What are the various types of Annotations that are used in Selenium?
- What is the main difference in the setsSpeed() or sleep() methods?
- What is the way to retrieve the alert message?
- How do you determine the exact location of an element on the web?
- Why do we use Selenium RC?
- What are the benefits or advantages of Selenium RC?
- Do you have a list of the technical limitations when making use of Selenium RC? Selenium RC?
- What's the reason to utilize the TestNG together with Selenium?
- What Language do you prefer to use to build test case sets in Selenium?
- What are Start and Breakpoints?
- What is the purpose of this capability relevant in relation to Selenium?
- When do you use AutoIT?
- Do you have a reason why you require Session management in Selenium?
- Are you able to automatize CAPTCHA?
- How can we launch various browsers on Selenium?
- Why should you select Selenium rather than QTP (Quick Test Professional)?
- Airbus Interview Questions and Answers: HR/ Behavioral
- Industry/ Company-Specific Airbus Interview Questions
- Airbus Interview Questions and Answers: Aptitude
- Airbus Software Engineer Interview Questions and Answers: Technical
- Importance of Spring Framework
- Spring Interview Questions (Basic)
- Advanced Spring Interview Questions
- C++ Interview Questions and Answers: The Basics
- C++ Interview Questions: Intermediate
- C++ Interview Questions And Answers With Code Examples
- C++ Interview Questions and Answers: Advanced
- Test Your Skills: Quiz Time
- MBA Interview Questions: B.Com Economics
- B.Com Marketing
- B.Com Finance
- B.Com Accounting and Finance
- Business Studies
- Chartered Accountant
- Q1. Please tell us something about yourself/ Introduce yourself to us.
- Q2. Describe yourself in one word.
- Q3. Tell us about your strengths and weaknesses.
- Q4. Why did you apply for this job/ What attracted you to this role?
- Q5. What are your hobbies?
- Q6. Where do you see yourself in five years OR What are your long-term goals?
- Q7. Why do you want to work with this company?
- Q8. Tell us what you know about our organization
- Q9. Do you have any idea about our biggest competitors?
- Q10. What motivates you to do a good job?
- Q11. What is an ideal job for you?
- Q12. What is the difference between a group and a team?
- Q13. Are you a team player/ Do you like to work in teams?
- Q14. Are you good at handling pressure/ deadlines?
- Q15. When can you start?
- Q16. How flexible are you regarding overtime?
- Q17. Are you willing to relocate for work?
- Q18. Why do you think you are the right candidate for this job?
- Q19. How can you be an asset to the organization?
- Q20. What is your salary expectation?
- Q21. How long do you plan to remain with this company?
- Q22. What is your objective in life?
- Q23. Would you like to pursue your Master's degree anytime soon?
- Q24. How have you planned to achieve your career goal?
- Q25. Can you tell us about your biggest achievement in life?
- Q26. What was the most challenging decision you ever made?
- Q27. What kind of work environment do you prefer to work in?
- Q28. What is the difference between a smart worker and a hard worker?
- Q29. What will you do if you don't get hired?
- Q30. Tell us three things that are most important for you in a job.
- Q31. Who is your role model and what have you learned from him/her?
- Q32. In case of a disagreement, how do you handle the situation?
- Q33. What is the difference between confidence and overconfidence?
- Q34. If you have more than enough money in hand right now, would you still want to work?
- Q35. Do you have any questions for us?
- Interview Tips for Freshers
- Tell me about yourself
- What are your greatest strengths?
- What are your greatest weaknesses?
- Tell me about something you did that you now feel a little ashamed of
- Why are you leaving (or did you leave) this position??
- 15+ resources for preparing most-asked interview questions
- CoCubes Interview Process Overview
- Common CoCubes Interview Questions
- Key Areas to Focus on for CoCubes Interview Preparation
- Conclusion
- Frequently Asked Questions (FAQs)
- Data Analyst Interview Questions With Answers
- About Data Analyst
Top 50+ IBM Interview Questions For Aptitude, Technical & HR Round

The Computing-Tabulating-Recording company (CTR) was founded in the United States area in 1911 and was renamed "International Business Machines" (IBM) in 1924. The IBM United States, is a leader in artificial intelligence, machine learning, and cloud computing, employing over 345,000 people and generating over USD 13 billion in operating profits.
As a Software Developer at IBM, you might work on product development, software development, or client consulting. However, the concepts of innovating, cooperating, and the building will underpin everything you do. When answering IBM interview questions, it's critical to keep this in mind. You could be asked logical reasoning questions along with numbered questions.
In order to hire a fresher Software Developer, IBM holds three to four rounds of interviews:
- Aptitude Test
- Technical Interview
- Human Resources Interview, Behavioral Interview Questions

IBM Interview Questions: Aptitude
1. If 20 men can build a division of 112 meters in 6 days, how long can 25 men work on a divider of a similar length in 3 days?
A. 69 meters.
B. 58 meters.
C. 70 meters.
D. 76 meters.
Answer: C
Solution: In just six days, 20 workers can construct 112 meters.
In 30 days, 25 guys can build a total of 112*(25/20)*(3/6) = 70 meters.
Let's assume that the rate at which work is done is constant and that the amount of work to be done is the same in both scenarios.
Given: 20 men can build a division of 112 meters in 6 days.
Let's calculate the total amount of work done by 20 men in 6 days: Work = Rate × Time 112 meters = Rate × 6 days Rate = 112 meters / 6 days Rate = 18.67 meters/day (approx.)
Now, we can use the concept of "man-days" to compare the work done by different numbers of men working for different durations. A "man-day" represents the amount of work done by one man in one day.
So, if 20 men working for 6 days can complete 112 meters, then they can complete 112 meters / 20 men = 5.6 meters in one day.
Now, we can use this rate to calculate how much work can be done by 25 men in 3 days: Work = Rate × Time Work = 5.6 meters/day × 3 days Work = 16.8 meters
Therefore, 25 men can complete a divider of similar length (112 meters) in 3 days.
2. What would be the primary interest if the cumulative dividends on a certain sum of money over a lengthy period of time at a rate of 10% per year were Rs. 993?
A. 840
B. 590
C. 695
D. 900
Answer: D
Solution: Let P = Principal, A - Amount
We have a = P (1 + R/100)3 and CI = A - P
ATQ 993 = P (1 + R/100)
3 - P
∴ P = Rs. 3000/ -
Presently SI @ 10% on Rs. 3000/ - for 3 yrs = (3000 x 10 x 3)/100
= Rs. 900/ -
3. By six years, Teena is younger than Rani. If the ratio of their ages is 6:8, figure out when Teena was born:
A. 18 years
B. 16 years
C. 17 years
D. 19 years
Answer: A
Solution:
Let's denote Teena's current age as "t" and Rani's current age as "r".
Given:
- Teena is younger than Rani by six years, which can be expressed as t = r - 6
- The ratio of their ages is 6:8, which can be expressed as t/r = 6/8
We can use these two equations to solve for Teena's current age and Rani's current age, and then determine when Teena was born.
Substituting t = r - 6 in the second equation: (r - 6)/r = 6/8
Cross-multiplying: 8(r - 6) = 6r
Expanding: 8r - 48 = 6r
Bringing all the "r" terms to one side: 8r - 6r = 48
Simplifying: 2r = 48
Dividing both sides by 2: r = 24
So, Rani's current age (r) is 24 years.
Substituting r = 24 in the equation t = r - 6: t = 24 - 6 t = 18
So, Teena's current age (t) is 18 years.
4. Take a look at the following series: A4, __, C16, D32, and E64. Which number should be used to fill in the blank?
A. B16
B. D4
C. B8
D. B10
Answer: C
Solution: The letters are multiplied by one, and the numbers are multiplied by two.
5. A man pushes 30 kilometers downstream and 18 kilometers upstream in 5 hours. What is the current speed of the stream?
A. 2 KM/HR
B. 7 KM/HR
C. 8 KM/HR
D. 8 KM/HR
Answer: A
Solution: Let x=speed of boat and
y=speed of current
=30/ (x+y)=18/(x-y)=5 by solving y=1.2 km/hr
6. (A) The triangular connection between Asia's countries, India, China, and Japan, will determine Asia's predetermination.
(B) India, China, and Japan, which have had remarkable development, particularly in the last decade, have emerged as the world's southern engine of development.
- If statement (A) is the cause and statement (B) is its effect.
- If statement (B) is the cause and statement (A) is its effect.
- If both the statements (A) and (B) are independent clauses.
- If both the statements (A) and (B) are effects of independent causes.
Answer: 2
Solution: The three countries will influence Asia's predetermination because they are driving the world's monetary development. As a result, (B) is the cause, and (A) is the result.
7. Event (A): During the floods, Mr. X was murdered.
Event (B): It was drizzling heavily.
-
If 'A' is the effect and 'B' is its immediate and principal cause.
- If 'B' is the effect and 'A' is its immediate and principal cause.
- If 'A' is the effect but 'B' is not its immediate and principal cause.
- If 'B' is the effect but 'A' is not its immediate and principal cause.
- None of these.
Answer: 5
Solution: Based on the information provided, it is not possible to determine a clear cause-and-effect relationship between events A and B. Event A, which is the murder of Mr. X during the floods, could potentially have multiple causes, and it is not explicitly stated that event B, heavy drizzling, directly caused event A. Similarly, event B, heavy drizzling, could potentially have multiple effects, and it is not explicitly stated that event A directly caused event B. Therefore, without further information, it is not possible to definitively determine the cause-and-effect relationship between events A and B, and none of the given options accurately describe the relationship between the two events.
8. VISIONARY
- Harbinger
- Pragmatist
- Extremist
- Dreamer
Answer: 2
Solution: An antonym of the word pragmatic is (visionary, dreamer).
IBM Interview Questions: Technical
Only after clearing round 1 of the interview process, you are eligible for IBM Technical Interview round. To go through this round, you'll need to brush up on the solid fundamentals of dynamic programming language. The types of questions asked here are are divide into three difficulty levels - easy, medium, and hard.
Level: Easy
9. What is Machine's Address?

A machine address is used to specify the exact location of data or instructions in the memory hierarchy, which includes various levels of cache memory, main memory (RAM), and secondary storage (e.g., hard disk). The machine address is used by the CPU to fetch, store, or modify data or instructions in memory during the execution of computer programs.
Machine addresses are generated by the CPU or MMU based on the memory addressing scheme used by the computer system, such as physical addressing or virtual addressing. Physical addressing directly refers to the physical location of data or instructions in the physical memory, while virtual addressing uses a translation mechanism to map virtual addresses used by the software to physical addresses in the physical memory.
10. What is the purpose of a memory address?
The purpose of a memory address is to uniquely identify the location of a specific piece of data or instruction in the memory of a computer system. Memory addresses serve as a reference or pointer to the location of stored data or instructions, allowing the computer's hardware (e.g., CPU, memory management unit) to read, write, or modify the data or instructions as needed during the execution of a computer user programs.
Memory addresses are used by the computer system to manage and manipulate data and instructions stored in memory. They allow the CPU to fetch instructions, read or write data, and transfer information between different parts of the computer system. Memory addresses are used in various memory-related operations, such as instruction fetch, data fetch, data store, and memory allocation.
Memory addresses can be represented as binary numbers, typically consisting of multiple bits that specify a unique location in the computer's memory hierarchy, including various levels of cache memory, main memory (RAM), and secondary storage (e.g., hard disk).
11. What is a Systems Virtual Memory?
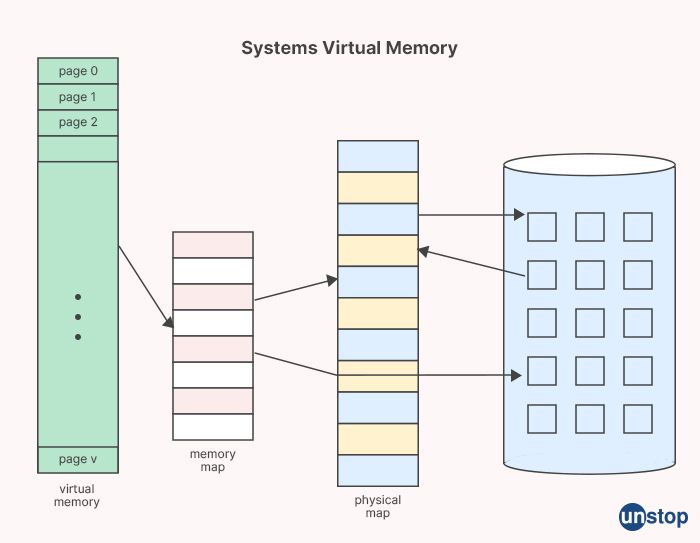
System virtual memory, also known as virtual memory, is a memory management technique used by modern computer operating systems to provide each process with a virtual address space that is independent of the physical memory (RAM) available in the system. It allows processes to access more memory than is physically installed in the computer, and provides various memory management features, such as memory protection, memory sharing, and demand paging.
In a system with virtual memory, each process is given its own private virtual address space that appears as a contiguous block of memory, regardless of the actual physical memory available in the system. The virtual address space is divided into smaller units called virtual pages, and these virtual pages are mapped to physical pages in the physical memory (RAM) using a page table maintained by the operating system.
12. What is an example of a Void Function?
An example of a void function is as follows: >>> def sayhello(who): void print 'Hello,', who + '! ' void print ' What a lovely day.
In computer programming, a void function (sometimes referred to as a "procedural programming" or "subroutine") is a type of function that does not return any value. Void functions are typically used to perform actions or operations that do not require a return value, such as printing output to the console, modifying global variables, or performing other side effects.
13. What exactly is a database?
A database is a collection of structured data that is organized, stored, and managed in a computer system. It is designed to efficiently store, retrieve, and manage large amounts of data in a structured and organized manner, allowing for easy and efficient data manipulation and retrieval.
A database typically consists of one or more tables, where each table contains a collection of related data organized in rows and columns. Each row in a table represents a single record or data item, and each column represents a specific attribute or field of the data. The columns in a table are defined by a set of attributes or fields, and each row in the table contains values corresponding to those attributes or fields.
A database system provides various operations and functionalities for managing data, such as inserting new data, updating existing data, deleting data, and retrieving data based on specific conditions or criteria. It also provides mechanisms for ensuring data integrity, consistency, and security, such as enforcing data constraints, supporting transactions, and providing access controls.
Databases are widely used in various applications and industries, including business, finance, healthcare, education, e-commerce, and more. They are essential for storing and managing large volumes of data efficiently, and provide a foundation for many software applications and systems that rely on data management and manipulation.
14. What is a stream procedure?

A stream procedure, in the context of computer programming, typically refers to a way of processing data that is continuously flowing or streaming, rather than being stored in its entirety in memory before processing. Streams are sequences of data elements made available over time, and they can be used to handle large datasets, real-time data, or data that is generated or consumed in a continuous manner.
In a stream procedure, data is processed incrementally, typically one piece at a time, as it becomes available, rather than loading the entire dataset into memory upfront. This allows for efficient processing of large datasets without consuming excessive memory resources. Stream procedures are commonly used in scenarios where data is generated or consumed continuously, such as reading data from a sensor, processing data from a network connection, or handling data from a log file.
Stream procedures are often implemented using libraries or APIs that provide stream processing capabilities, and they typically involve operations such as reading data from a stream, processing the data element by element, and producing output or taking actions based on the streamed data. Stream procedures can be used in various programming languages and frameworks, such as Java, Python, Node.js, Apache Kafka, Apache Flink, and Apache Spark, among others.
15. What is SQL?
SQL stands for Structured Query Language. It is a domain-specific programming language that is primarily used for managing and querying relational databases. SQL provides a standardized way to communicate with and manipulate databases, which are used to store and manage structured data.
Relational databases are a type of database management system (DBMS) that organizes data into tables with rows and columns, and establishes relationships between the tables using keys. SQL is used to define the structure of a relational database, insert, update, and delete data in the database, as well as retrieve data from the database using queries.
SQL is a powerful and widely used language in the field of data management and is commonly used in various database management systems, such as MySQL, PostgreSQL, Oracle Database, Microsoft SQL Server, SQLite, and others. SQL is a declarative language, meaning that users specify what they want to do with the data (e.g., querying, updating, deleting) without specifying how to do it. SQL is also a data manipulation language (DML) as it provides commands for modifying the data in a database.
Some common SQL operations include:
-
Creating, modifying, and deleting tables: SQL provides commands for creating, altering, and dropping tables, which define the structure of a database and its data.
-
Inserting, updating, and deleting data: SQL allows users to insert new data into tables, update existing data, and delete data from tables.
-
Retrieving data with queries: SQL provides powerful query capabilities to retrieve data from one or more tables using commands such as SELECT, WHERE, JOIN, GROUP BY, ORDER BY, and others.
-
Managing database schema and security: SQL provides commands for managing the schema of a database, including creating and modifying views, indexes, constraints, and managing user permissions and security.
SQL is a widely used language in the field of data management, and it is an essential skill for developers, data analysts, and database administrators who work with relational databases.
Stay ahead! Never miss out any trending job or internship opportunity!
16. What are SQL Constraints?
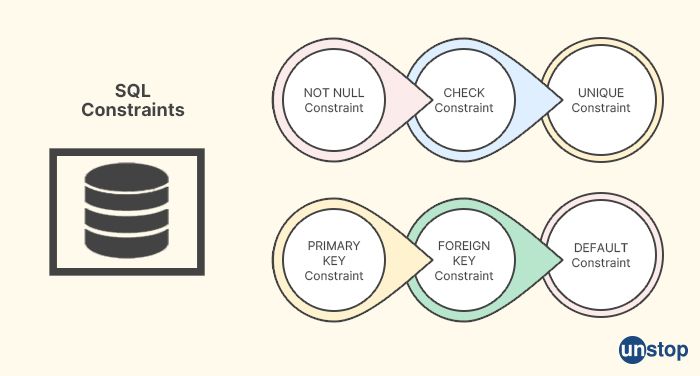
SQL constraints are rules or conditions that are applied to the data stored in a relational database to ensure its integrity and consistency. Constraints are used to define and enforce rules on the data that can be inserted, updated, or deleted from a database table. They help maintain the integrity of the data by preventing invalid or inconsistent data from being stored in the database.
There are several types of SQL constraints that can be defined on database tables, including:
- Primary Key: A primary key is a unique identifier for a table, and it ensures that each row in the table is uniquely identified. A primary key constraint enforces the uniqueness and non-nullness of the key column(s) in a table, and it is used to uniquely identify rows in the table. Only one primary key can be defined for a table.
-
Foreign Key: A foreign key is a column or a set of columns in a table that refers to the primary key of another table. It establishes a relationship between two tables, where the foreign key in one table refers to the primary key of another table. A foreign key constraint enforces the referential integrity between the tables, ensuring that data in the foreign key column(s) of one table matches the primary key values of another table.
-
Unique: A unique constraint ensures that the values in the specified column(s) of a table are unique, i.e., no duplicate values are allowed. Unlike a primary key constraint, a unique constraint can allow null values.
-
Check: A check constraint defines a condition that must be met for the data in a column or a set of columns in a table. It ensures that only data that satisfies the specified condition is allowed to be inserted or updated in the table.
-
Not Null: A not null constraint ensures that a column in a table cannot have null values, i.e., it must always contain a value.
-
Default: A default constraint specifies a default value for a column in a table, which is used when a value is not provided during an insert operation.
17. Give examples of data structures in C++ as a question.
- Arrays: An array is a collection of elements of the same data type that are stored in contiguous memory locations. Arrays can be of fixed size or dynamic size and can be used to store and manipulate collections of values, such as integers, floating-point numbers, characters, or user-defined data types.
Example question: How do you declare and initialize an integer array of size 5 in C++?
- Linked Lists: A linked list is a data structure that consists of a sequence of nodes, where each node stores a value and a pointer/reference to the next node in the list. Linked lists can be singly linked (where each node points to the next node) or doubly linked (where each node points to both the next and previous nodes), and they can be used to implement various data manipulation operations, such as inserting, deleting, or searching for elements.
Example question: How do you define a singly linked list node with an integer value in C++?
- Stacks: A stack is a linear data structure that follows the Last-In-First-Out (LIFO) principle, where the most recently added element is the first one to be removed. Stacks can be implemented using arrays or linked lists, and they are commonly used for tasks that require maintaining a particular order of elements, such as parsing expressions, evaluating expressions, or managing function call frames in computer programs.
Example question: How do you implement a stack using an array in C++?
- Queues: A queue is a linear data structure that follows the First-In-First-Out (FIFO) principle, where the element that is added first is the first one to be removed. Queues can be implemented using arrays or linked lists, and they are commonly used for tasks that involve processing elements in a sequential manner, such as managing job queues, handling requests, or managing resources with limited capacity.
Example question: How do you implement a circular queue using a linked list in C++?
- Trees: A tree is a hierarchical data structure that consists of nodes connected by edges, where each node can have zero or more child nodes. Trees can be used to represent hierarchical relationships, such as file systems, organization structures, or decision trees, and they can be used for various operations, such as searching, inserting, or deleting elements efficiently.
Example question: How do you define a binary search tree node with an integer value in C++?
18. What are the different types of modifiers in Java?
In Java, there are several types of modifiers that can be used to control the visibility, accessibility, and behavior of classes, variables, and methods. The main types of modifiers in Java are:
- Access Modifiers: These modifiers control the visibility and accessibility of classes, variables, and methods from different parts of the program. There are four access modifiers in Java:
-
public: Public members are accessible from any part of the user program, including other packages.
-
private: Private members are accessible only within the same class and not accessible from other classes or packages.
-
protected: Protected members are accessible within the same class, same package, and subclasses in other packages.
-
default (no modifier): Members with no explicit access modifier are accessible within the same package only.
- Non-Access Modifiers: These modifiers provide additional behavior to classes, variables, and methods. Some commonly used non-access modifiers in Java are:
-
static: Static members belong to the class itself rather than an instance of the class. They can be accessed without creating an object of the class.
-
final: Final members cannot be modified after their initial value is assigned. Classes marked as final cannot be subclassed.
-
abstract: Abstract classes and methods cannot be instantiated. Abstract methods do not have an implementation and must be overridden in a subclass.
-
synchronized: Synchronized methods or blocks are used for achieving thread-safety in multi-threaded environments.
-
transient: Transient members are not serialized when an object is serialized.
-
volatile: Volatile members are used for synchronization and ensure that changes to the variable are visible across threads.
- Others: There are some other modifiers in Java, such as strictfp (used for ensuring precise floating-point calculations), native (used for calling native code written in other languages), and interface (used for defining interfaces).
These are the main types of modifiers in Java that provide various levels of visibility, accessibility, and behavior control to classes, variables, and methods in Java programs.
19. What are the differences between Strut and Spring?
The difference between Strut and Spring architecture is:
Struts and Spring are both popular Java frameworks used for building web applications, but they have some key differences in terms of their architecture, features, and usage. Here are some of the main differences between Struts and Spring:
-
Architecture: Struts follows the Model-View-Controller (MVC) architecture, where the application logic is divided into three components - Model (data), View (user interface), and Controller (handles user requests and manages the flow of control). Spring, on the other hand, is a more comprehensive framework that provides a wide range of features, including dependency injection, aspect-oriented programming, and transaction management, among others. Spring does not enforce a specific architecture like Struts, but it can be used in conjunction with various design patterns and architectural styles, including MVC.
-
Features: Struts is primarily focused on providing a framework for building web applications using the MVC architecture. It includes features such as built-in support for form handling, validation, and error handling, as well as a tag library for generating HTML forms. Spring, on the other hand, provides a broader range of features beyond web application development, including dependency injection (DI) and inversion of control (IoC) container, aspect-oriented programming (AOP), data access (JDBC, ORM, etc.), security, caching, and more. Spring is known for its modular and extensible architecture, allowing developers to choose and use only the features they need.
-
Configuration: In Struts, the configuration is typically done through XML configuration files, where developers define actions, forms, mappings, and other application settings. Spring, on the other hand, uses XML or Java-based configuration to define beans (objects) and their relationships, which are managed by the Spring IoC container. Spring also provides annotations-based configuration, which allows developers to define beans and their dependencies directly in Java code.
-
Flexibility: Struts provides a more prescriptive approach to building web applications, with a specific robust architecture and predefined components. Spring, on the other hand, provides more flexibility and allows developers to choose and integrate different components based on their specific needs. Spring follows the principle of "coding to interfaces," promoting loose coupling and easier unit testing, whereas Struts is more tightly coupled.
-
Learning Curve: Struts has a steeper learning curve compared to Spring, as it requires developers to learn its specific robust architecture, configuration, and tag libraries. Spring, on the other hand, provides a more modular and flexible approach, allowing developers to gradually adopt and use its features based on their familiarity with Java and other related technologies.
-
Community and Ecosystem: Both Struts and Spring have large and active communities of developers, but Spring has a larger ecosystem and a wider range of tools, libraries, and integrations with other frameworks and technologies. Spring has extensive documentation, tutorials, and community support, making it relatively easier for developers to get started and find help when needed.
20. What is a class sample?
A class is a blueprint or template that defines the structure, behavior, and properties of objects in a programming language. It serves as a blueprint for creating objects, which are instances of that class. A class defines the attributes (data members) and methods (functions) that objects of that class can have.
A class sample or example would typically be a code snippet or a piece of code that demonstrates the syntax and usage of a class in a programming language. It may include the declaration of class members (such as attributes and methods), instantiation of objects, and invocation of methods on those objects. Class samples or examples are often used as learning resources or references for understanding how classes are used in a particular programming language.
Here is an example of a class in Python:
class Rectangle:
def __init__(self, width, height):
self.width = width
self.height = height
def area(self):
return self.width * self.height
# Creating objects of the Rectangle class
rect1 = Rectangle(5, 10)
rect2 = Rectangle(3, 7)
# Invoking methods on objects
print(rect1.area()) # Output: 50
print(rect2.area()) # Output: 21
Y2xhc3MgUmVjdGFuZ2xlOgpkZWYgX19pbml0X18oc2VsZiwgd2lkdGgsIGhlaWdodCk6CnNlbGYud2lkdGggPSB3aWR0aApzZWxmLmhlaWdodCA9IGhlaWdodAoKZGVmIGFyZWEoc2VsZik6CnJldHVybiBzZWxmLndpZHRoICogc2VsZi5oZWlnaHQKCiMgQ3JlYXRpbmcgb2JqZWN0cyBvZiB0aGUgUmVjdGFuZ2xlIGNsYXNzCnJlY3QxID0gUmVjdGFuZ2xlKDUsIDEwKQpyZWN0MiA9IFJlY3RhbmdsZSgzLCA3KQoKIyBJbnZva2luZyBtZXRob2RzIG9uIG9iamVjdHMKcHJpbnQocmVjdDEuYXJlYSgpKSAjIE91dHB1dDogNTAKcHJpbnQocmVjdDIuYXJlYSgpKSAjIE91dHB1dDogMjE=
21. What are contiguous memory spaces?
Contiguous memory spaces refer to a block of memory in a computer's memory (RAM) where multiple memory addresses are sequentially allocated without any gaps or fragmentation. In other words, contiguous memory spaces are consecutive memory locations that are allocated in a sequential and continuous manner.
Contiguous memory allocation is a memory management technique used in operating systems and programming languages where memory blocks are allocated in a continuous manner to store data structures, such as arrays, linked lists, or other data types. It means that the memory addresses assigned to these data structures are consecutive and do not have any gaps or holes between them.
One of the main advantages of contiguous memory spaces is that they allow for efficient memory access, as data elements can be accessed using simple pointer arithmetic. This can lead to faster data retrieval and processing times.
22. In programming, what is the difference between Variable Declaration and Function Declaration?
In programming, variable declaration and function declaration are two different concepts related to defining and using variables and functions within a programming language. Here are the key differences:
- Variable Declaration: Variable declaration is the process of defining a variable and allocating memory for it in the computer's memory. It involves specifying the variable's name, data type, and optional initial value, if any. The variable declaration typically occurs before the variable is used in the program to store and manipulate data. Once a variable is declared, it can be assigned a value, and its value can be modified during program execution.
Example of variable declaration in C++:
int num; // Declaration of an integer variable named 'num'
- Function Declaration: Function declaration is the process of defining a function, which is a named sequence of instructions that performs a specific task or computation in a program. A function declaration typically involves specifying the function's name, return type, parameters (if any), and the function's body or implementation. Function declarations are used to inform the compiler about the existence, return type, and parameters of a function, so that it can be used in other parts of the program before its actual implementation.
Example of function declaration in C++:
int add(int a, int b); // Declaration of a function named 'add' with two integer parameters and integer return type
23. What is Secondary Memory?

Secondary memory, also known as auxiliary memory or external memory, is a type of computer memory that is used for long-term storage of data and programs even when the computer is powered off. It is a non-volatile form of memory that retains its stored information even when the computer's power is turned off.
Secondary memory is used to store data and programs that are not currently being used by the computer's central processing unit (CPU) or main memory (RAM). It provides persistent storage for large amounts of data, such as operating systems, software applications, documents, multimedia files, and other types of data that need to be stored for long-term use or retrieval.
Common examples of secondary memory devices include hard disk drives (HDDs), solid-state drives (SSDs), optical disks (such as CDs, DVDs, and Blu-ray discs), USB flash drives, memory cards, magnetic tapes, and network-attached storage (NAS) devices.
Secondary memory is typically slower in terms of access speed compared to primary memory (RAM), but it offers much larger storage capacity and non-volatile storage, meaning the data stored in secondary memory is retained even when the computer is powered off. This makes secondary memory suitable for long-term storage and retrieval of data and programs, while primary memory (RAM) is used for short-term storage of data and programs during the computer's active operation.
24. What is the largest size data measurement unit?
The largest size data measurement unit commonly used in computing is the yottabyte (YB).
In the International System of Units (SI), the prefix "yotta" represents 10^24, which is equivalent to 1,000,000,000,000,000,000,000,000 bytes.
In the context of computing and digital storage, the yottabyte is an extremely large unit of data storage and is typically used to represent massive amounts of data, such as in big data applications, data centers, and high-performance computing environments.
To put it into perspective, a yottabyte of data is equivalent to 1 trillion gigabytes (GB) or 1,000,000,000 terabytes (TB). It is currently beyond the storage capacity of consumer-grade hard drives or solid-state drives and is typically used to represent hypothetical or theoretical scenarios involving immense amounts of data.
25. What is the purpose of the WebSphere Portal?
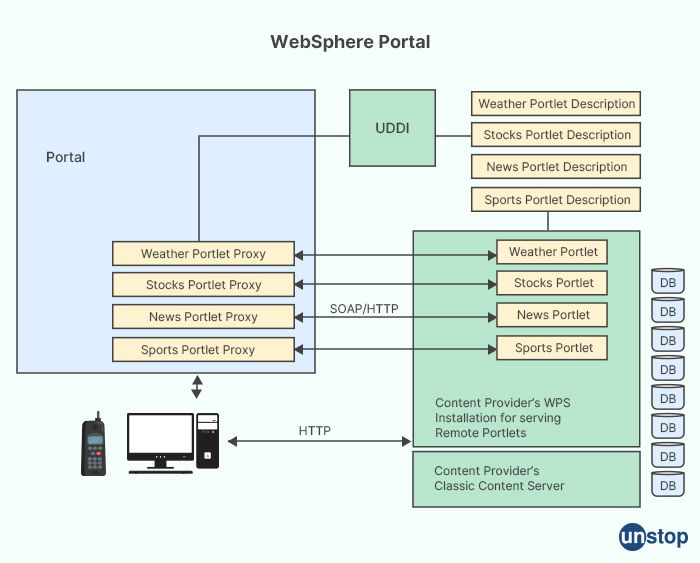
WebSphere Portal is a software platform developed by IBM that provides a framework for building and managing web portals and digital experiences. It is designed to create and deploy web-based applications that enable organizations to deliver personalized content, applications, and services to their users in a unified and customizable interface.
The main purpose of WebSphere Portal is to facilitate the creation and management of web portals, which are websites that serve as a gateway or entry point for users to access information, applications, and services from various sources in a unified and personalized manner. Some of the key purposes of WebSphere Portal include:
-
Content management: WebSphere Portal provides tools and features for creating, organizing, and managing content, such as documents, images, videos, and other types of digital assets. Content can be published, categorized, and presented in a personalized manner based on user roles, permissions, and preferences.
-
Application integration: WebSphere Portal allows integration of various applications and services into a unified portal interface. This includes integration with backend systems, databases, web services, and other third-party applications, enabling users to access and interact with different applications and services from a single portal.
-
Personalization and customization: WebSphere Portal supports personalized experiences for users based on their roles, profiles, preferences, and behaviors. Users can customize their portal layout, content, and appearance to suit their individual needs and preferences, resulting in a personalized and user-centric experience.
-
Collaboration and social features: WebSphere Portal provides collaborative features, such as discussion forums, wikis, blogs, and social networking tools, to facilitate communication, collaboration, and knowledge sharing among users within the portal environment.
-
Security and access control: WebSphere Portal offers robust security features to protect portal content, applications, and data. It includes authentication, authorization, and role-based access control mechanisms to ensure that users can only access authorized resources based on their roles and permissions.
-
Scalability and performance: WebSphere Portal is designed to handle large-scale deployments and can support high levels of concurrent users, content, and applications. It includes performance optimization features to optimize the performance and responsiveness of the portal for efficient user experience.
26. What is the difference between Staging Server and a Production Server?
The staging server and production server are two different environments in the software development and deployment process. Here are the key differences between them:
-
Purpose: The staging server is typically used as an intermediate environment between development and production environments for testing and quality assurance purposes. It serves as a pre-production environment where software changes, updates, and configurations are tested before they are deployed to the production server, which is the live environment where the software is used by end-users.
-
Usage: The staging server is used for testing, validation, and verification of software changes, updates, and configurations before they are deployed to the production environment. It allows for thorough testing of new features, bug fixes, and other changes in a controlled environment to identify and fix any issues or bugs before they are released to production. On the other hand, the production server is the live environment where the software is used by end-users to access and interact with the application or service.
-
Data: The staging server typically uses test data, sample data, or simulated data for testing and validation purposes. It may not contain real or live data that is used in the production environment. In contrast, the production server contains live data that is used by end-users to access and interact with the software in a real-world production environment.
-
Configuration: The staging server may have similar configuration settings and environment setup as the production server, but it may also have additional testing-related configurations, such as logging, debugging, and monitoring settings, to facilitate testing and validation. The production server, on the other hand, is typically configured with the settings and configurations that are optimized for performance, security, and production use.
-
Access and permissions: Access to the staging server is usually limited to a select group of users, such as testers, quality assurance personnel, and developers, who are responsible for testing and validation. In contrast, the production server is accessible to end-users or the intended audience of the software.
-
Stability and downtime: The staging server may experience frequent changes, updates, and configurations as part of the testing and validation process, and it may not be as stable or reliable as the production server. The production server, on the other hand, is expected to be stable, reliable, and highly available for end-users, and downtime is minimized to ensure uninterrupted access to the software.
27. List a few platforms that IBM WebSphere Portal Application Server (WAS) supports.
IBM WebSphere Portal Application Server (WAS) is a Java-based application server that provides a platform for developing and deploying web applications and portals. It supports various platforms, including:
-
IBM AIX (Advanced Interactive eXecutive): This is IBM's proprietary UNIX operating system for IBM Power Systems, which includes IBM Power servers and IBM PowerPC-based systems.
-
IBM i (formerly known as IBM AS/400, iSeries, System i): This is IBM's proprietary operating system for IBM Power Systems, which includes IBM Power servers and is designed for business computing.
-
Linux: WAS supports various distributions of Linux, including Red Hat Enterprise Linux (RHEL), SUSE Linux Enterprise Server (SLES), and others.
-
Microsoft Windows: WAS supports various versions of Microsoft Windows, including Windows Server 2012, Windows Server 2016, Windows Server 2019, and Windows 10, among others.
-
Solaris: WAS supports Oracle Solaris, which is a UNIX operating system developed by Oracle Corporation.
-
z/OS: This is IBM's mainframe operating system, and WAS provides support for running on IBM zSeries mainframe hardware.
28. What are function signatures?
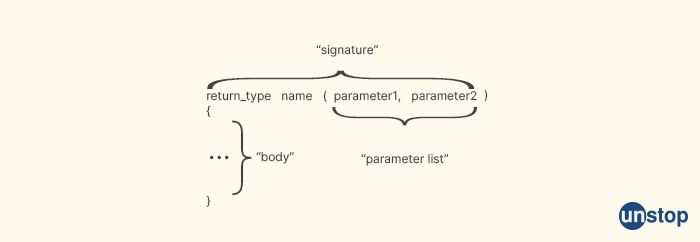
Function signatures in programming refer to the combination of a function's name, return type, and parameter list. It specifies the function's interface, which includes the function's name, the type of data it returns (if any), and the types and order of the parameters it accepts (if any).
Function signatures are used to uniquely identify a function in a program, and they serve as a way to define and declare functions in programming languages. A function's signature must be consistent across all its declarations and definitions within a program. Function signatures are important for function overloading, where multiple functions in a program have the same name but different parameter lists. The function signature helps the compiler or interpreter differentiate between the overloaded functions and determine which function to call based on the number, types, and order of the arguments.
29. What are Overloaded Functions?
In programming, overloaded functions are functions that have the same name but different parameter lists or signatures. They are used to define multiple functions with the same name but different behavior based on the arguments or parameters they accept. Overloaded functions provide a way to define multiple variations of a function that perform similar tasks but operate on different types of data or have different behavior based on the arguments passed to them.
The main characteristics of overloaded functions are:
-
Same function name: Overloaded functions have the same name. This allows programmers to use the same name for different functions that perform similar tasks.
-
Different parameter lists: Overloaded functions have different parameter lists, which can differ in the number, types, or order of parameters. This allows the compiler or interpreter to differentiate between the overloaded functions based on the arguments passed to them.
-
Same or different return types: Overloaded functions can have the same or different return types. The return type is not considered as part of the function signature for the purpose of function overloading, so overloaded functions can have the same name and parameter list but different return types.
-
Similar functionality: Overloaded functions are typically used to define functions that perform similar tasks but operate on different types of data or have different behavior based on the arguments passed to them.
Example of overloaded functions in C++:
In programming, overloaded functions are functions that have the same name but different parameter lists or signatures. They are used to define multiple functions with the same name but different behavior based on the arguments or parameters they accept. Overloaded functions provide a way to define multiple variations of a function that perform similar tasks but operate on different types of data or have different behavior based on the arguments passed to them.
The main characteristics of overloaded functions are:
Same function name: Overloaded functions have the same name. This allows programmers to use the same name for different functions that perform similar tasks.
Different parameter lists: Overloaded functions have different parameter lists, which can differ in the number, types, or order of parameters. This allows the compiler or interpreter to differentiate between the overloaded functions based on the arguments passed to them.
Same or different return types: Overloaded functions can have the same or different return types. The return type is not considered as part of the function signature for the purpose of function overloading, so overloaded functions can have the same name and parameter list but different return types.
Similar functionality: Overloaded functions are typically used to define functions that perform similar tasks but operate on different types of data or have different behavior based on the arguments passed to them.
Example of overloaded functions in C++:
// Example of overloaded functions in C++
#include
// Function that adds two integers
int add(int a, int b) {
return a + b;
}
// Function that adds two floats
float add(float a, float b) {
return a + b;
}
int main() {
int result1 = add(2, 3); // Calls the int version of the function
float result2 = add(2.5, 3.7); // Calls the float version of the function
std::cout << "Result 1: " << result1 << std::endl;
std::cout << "Result 2: " << result2 << std::endl;
return 0;
}
SW4gcHJvZ3JhbW1pbmcsIG92ZXJsb2FkZWQgZnVuY3Rpb25zIGFyZSBmdW5jdGlvbnMgdGhhdCBoYXZlIHRoZSBzYW1lIG5hbWUgYnV0IGRpZmZlcmVudCBwYXJhbWV0ZXIgbGlzdHMgb3Igc2lnbmF0dXJlcy4gVGhleSBhcmUgdXNlZCB0byBkZWZpbmUgbXVsdGlwbGUgZnVuY3Rpb25zIHdpdGggdGhlIHNhbWUgbmFtZSBidXQgZGlmZmVyZW50IGJlaGF2aW9yIGJhc2VkIG9uIHRoZSBhcmd1bWVudHMgb3IgcGFyYW1ldGVycyB0aGV5IGFjY2VwdC4gT3ZlcmxvYWRlZCBmdW5jdGlvbnMgcHJvdmlkZSBhIHdheSB0byBkZWZpbmUgbXVsdGlwbGUgdmFyaWF0aW9ucyBvZiBhIGZ1bmN0aW9uIHRoYXQgcGVyZm9ybSBzaW1pbGFyIHRhc2tzIGJ1dCBvcGVyYXRlIG9uIGRpZmZlcmVudCB0eXBlcyBvZiBkYXRhIG9yIGhhdmUgZGlmZmVyZW50IGJlaGF2aW9yIGJhc2VkIG9uIHRoZSBhcmd1bWVudHMgcGFzc2VkIHRvIHRoZW0uCgpUaGUgbWFpbiBjaGFyYWN0ZXJpc3RpY3Mgb2Ygb3ZlcmxvYWRlZCBmdW5jdGlvbnMgYXJlOgoKU2FtZSBmdW5jdGlvbiBuYW1lOiBPdmVybG9hZGVkIGZ1bmN0aW9ucyBoYXZlIHRoZSBzYW1lIG5hbWUuIFRoaXMgYWxsb3dzIHByb2dyYW1tZXJzIHRvIHVzZSB0aGUgc2FtZSBuYW1lIGZvciBkaWZmZXJlbnQgZnVuY3Rpb25zIHRoYXQgcGVyZm9ybSBzaW1pbGFyIHRhc2tzLgoKRGlmZmVyZW50IHBhcmFtZXRlciBsaXN0czogT3ZlcmxvYWRlZCBmdW5jdGlvbnMgaGF2ZSBkaWZmZXJlbnQgcGFyYW1ldGVyIGxpc3RzLCB3aGljaCBjYW4gZGlmZmVyIGluIHRoZSBudW1iZXIsIHR5cGVzLCBvciBvcmRlciBvZiBwYXJhbWV0ZXJzLiBUaGlzIGFsbG93cyB0aGUgY29tcGlsZXIgb3IgaW50ZXJwcmV0ZXIgdG8gZGlmZmVyZW50aWF0ZSBiZXR3ZWVuIHRoZSBvdmVybG9hZGVkIGZ1bmN0aW9ucyBiYXNlZCBvbiB0aGUgYXJndW1lbnRzIHBhc3NlZCB0byB0aGVtLgoKU2FtZSBvciBkaWZmZXJlbnQgcmV0dXJuIHR5cGVzOiBPdmVybG9hZGVkIGZ1bmN0aW9ucyBjYW4gaGF2ZSB0aGUgc2FtZSBvciBkaWZmZXJlbnQgcmV0dXJuIHR5cGVzLiBUaGUgcmV0dXJuIHR5cGUgaXMgbm90IGNvbnNpZGVyZWQgYXMgcGFydCBvZiB0aGUgZnVuY3Rpb24gc2lnbmF0dXJlIGZvciB0aGUgcHVycG9zZSBvZiBmdW5jdGlvbiBvdmVybG9hZGluZywgc28gb3ZlcmxvYWRlZCBmdW5jdGlvbnMgY2FuIGhhdmUgdGhlIHNhbWUgbmFtZSBhbmQgcGFyYW1ldGVyIGxpc3QgYnV0IGRpZmZlcmVudCByZXR1cm4gdHlwZXMuCgpTaW1pbGFyIGZ1bmN0aW9uYWxpdHk6IE92ZXJsb2FkZWQgZnVuY3Rpb25zIGFyZSB0eXBpY2FsbHkgdXNlZCB0byBkZWZpbmUgZnVuY3Rpb25zIHRoYXQgcGVyZm9ybSBzaW1pbGFyIHRhc2tzIGJ1dCBvcGVyYXRlIG9uIGRpZmZlcmVudCB0eXBlcyBvZiBkYXRhIG9yIGhhdmUgZGlmZmVyZW50IGJlaGF2aW9yIGJhc2VkIG9uIHRoZSBhcmd1bWVudHMgcGFzc2VkIHRvIHRoZW0uCgpFeGFtcGxlIG9mIG92ZXJsb2FkZWQgZnVuY3Rpb25zIGluIEMrKzoKCi8vIEV4YW1wbGUgb2Ygb3ZlcmxvYWRlZCBmdW5jdGlvbnMgaW4gQysrCgojaW5jbHVkZSA8aW9zdHJlYW0+CgovLyBGdW5jdGlvbiB0aGF0IGFkZHMgdHdvIGludGVnZXJzCmludCBhZGQoaW50IGEsIGludCBiKSB7CnJldHVybiBhICsgYjsKfQoKLy8gRnVuY3Rpb24gdGhhdCBhZGRzIHR3byBmbG9hdHMKZmxvYXQgYWRkKGZsb2F0IGEsIGZsb2F0IGIpIHsKcmV0dXJuIGEgKyBiOwp9CgppbnQgbWFpbigpIHsKaW50IHJlc3VsdDEgPSBhZGQoMiwgMyk7IC8vIENhbGxzIHRoZSBpbnQgdmVyc2lvbiBvZiB0aGUgZnVuY3Rpb24KZmxvYXQgcmVzdWx0MiA9IGFkZCgyLjUsIDMuNyk7IC8vIENhbGxzIHRoZSBmbG9hdCB2ZXJzaW9uIG9mIHRoZSBmdW5jdGlvbgoKc3RkOjpjb3V0IDw8ICJSZXN1bHQgMTogIiA8PCByZXN1bHQxIDw8IHN0ZDo6ZW5kbDsKc3RkOjpjb3V0IDw8ICJSZXN1bHQgMjogIiA8PCByZXN1bHQyIDw8IHN0ZDo6ZW5kbDsKCnJldHVybiAwOwp9
30. Tell me about one disadvantage of utilizing C++.
One disadvantage of utilizing C++ as a programming language is its complexity and steep learning curve compared to some other programming languages.
-
Complexity: C++ is a complex language with a large number of features, including pointers, memory management, and manual memory allocation/deallocation. This complexity can make C++ code more difficult to read, write, and maintain, especially for beginner or inexperienced programmers.
-
Steep Learning Curve: Learning C++ can be challenging, particularly for programmers who are new to programming or have experience with simpler languages. C++ has a steeper learning curve compared to some other popular programming languages due to its syntax, object-oriented concepts, and low-level features.
31. Give me examples of real-life applications of C++.
C++ is a versatile programming language that is used in a wide range of real-life applications, including:
-
Operating Systems: C++ is commonly used in the development of operating systems like Windows, Linux, macOS, and many embedded operating systems due to its low-level capabilities and performance.
-
Game Development: C++ is widely used in the game development industry due to its high performance, low-level system access, and ability to optimize for graphics-intensive applications.
-
Embedded Systems: C++ is commonly used in embedded systems development, such as in automotive systems, aerospace applications, IoT (Internet of Things) devices, and other embedded platforms where system resources are limited and performance is critical.
32. What exactly is a circular linked list?
A circular linked list is a type of linked list in which the tail node points back to the head node, creating a circular structure. In other words, the last node in a circular linked list points to the first node, forming a loop.
Unlike a regular singly linked list where the last node's "next" pointer points to NULL, in a circular linked list, the last node's "next" pointer points back to the first node in the list, creating a circular reference.
A circular linked list can be singly circular linked list, where each node has a single "next" pointer pointing to the next node in the list, or it can be doubly circular linked list, where each node has two pointers - "next" and "prev" - pointing to the next and previous nodes in the list, respectively.
33. What is/are scanf disadvantage/s and how may they be mitigated (if any)?
scanf() is a standard input function in C/C++ programming that is used to read input from the console or standard input. It allows the programmer to specify format specifiers to read data of different types, such as integers, floating-point numbers, characters, and strings, from the input stream. However, scanf() has some potential disadvantages, including:
-
Buffer overflow: If the input data provided by the user is longer than the buffer size specified in the
scanf()format specifier, it can result in buffer overflow, leading to undefined behavior and potential security vulnerabilities, such as stack smashing attacks. -
Input validation:
scanf()does not perform thorough input validation by default. If the input data does not match the format specifier, it can result in incorrect data being read or cause the program to hang in an infinite loop. -
Limited error handling:
scanf()does not provide detailed error messages or return values that indicate the specific type of input error. This makes it challenging to handle and recover from input errors gracefully in the code.
To mitigate these potential issues with scanf(), the following best practices can be followed:
-
Specify buffer size: Always specify the buffer size to avoid buffer overflow. For example, use
%sformat specifier with a maximum field width to limit the number of characters read, like%10sto read at most 10 characters into a buffer of size 10. -
Validate input: After reading input using
scanf(), perform input validation to ensure that the input data matches the expected format. For example, check the return value ofscanf()to determine the number of successful conversions, and compare it with the expected number of conversions. Additionally, use functions likefgets()or other methods to read input line by line, and then parse and validate the input as needed. -
Handle errors: Check the return value of
scanf()and other input functions for errors, and handle them appropriately. For example, prompt the user for correct input, display informative error messages, or exit the program gracefully if input errors are critical. -
Use safer alternatives: Consider using safer alternatives to
scanf()such asfgets()or platform-specific input functions that provide better error handling and input validation capabilities. Additionally, consider using libraries or frameworks that provide safer input handling features, such asgetline()in C++ or using input validation libraries likelibinputorBoost.Inputin C++.
34. What exactly do you mean by 2D arrays?
A 2D array, also known as a two-dimensional array, is a type of data structure that stores elements in a two-dimensional matrix-like structure with rows and columns. It can be thought of as an array of arrays, where each element in the array is itself an array. In other words, it is an array of arrays, where elements are organized in rows and columns.
In C++, a 2D array is declared using a combination of square brackets [][] to specify the number of rows and columns. For example:
// Declaration of a 2D array with 3 rows and 4 columns
int myArray[3][4];
This declares a 2D array myArray with 3 rows and 4 columns, creating a matrix-like structure with a total of 12 elements.
35. How do make an array return?
n C++, arrays cannot be directly returned from a function. When an array is passed as an argument to a function or used as a return type, it decays into a pointer to its first element. Therefore, directly returning an array from a function is not possible.
However, you can achieve similar functionality by using pointers or other data structures like std::vector or std::array, which can be returned from a function. Here's an example using a pointer:
// Function that returns a pointer to an array
int* createArray() {
int* myArray = new int[5]; // Allocate memory byte for an array of 5 integers
// Initialize the array
myArray[0] = 1;
myArray[1] = 2;
myArray[2] = 3;
myArray[3] = 4;
myArray[4] = 5;
return myArray; // Return the pointer to the array
}
// Usage
int* returnedArray = createArray(); // Call the function and get the returned pointer
// Use the returned array as needed
// Remember to free the dynamically allocated memory to avoid memory leaks
delete[] returnedArray;
Ly8gRnVuY3Rpb24gdGhhdCByZXR1cm5zIGEgcG9pbnRlciB0byBhbiBhcnJheQppbnQqIGNyZWF0ZUFycmF5KCkgewppbnQqIG15QXJyYXkgPSBuZXcgaW50WzVdOyAvLyBBbGxvY2F0ZSBtZW1vcnkgYnl0ZSBmb3IgYW4gYXJyYXkgb2YgNSBpbnRlZ2VycwovLyBJbml0aWFsaXplIHRoZSBhcnJheQpteUFycmF5WzBdID0gMTsKbXlBcnJheVsxXSA9IDI7Cm15QXJyYXlbMl0gPSAzOwpteUFycmF5WzNdID0gNDsKbXlBcnJheVs0XSA9IDU7CnJldHVybiBteUFycmF5OyAvLyBSZXR1cm4gdGhlIHBvaW50ZXIgdG8gdGhlIGFycmF5Cn0KCi8vIFVzYWdlCmludCogcmV0dXJuZWRBcnJheSA9IGNyZWF0ZUFycmF5KCk7IC8vIENhbGwgdGhlIGZ1bmN0aW9uIGFuZCBnZXQgdGhlIHJldHVybmVkIHBvaW50ZXIKLy8gVXNlIHRoZSByZXR1cm5lZCBhcnJheSBhcyBuZWVkZWQKLy8gUmVtZW1iZXIgdG8gZnJlZSB0aGUgZHluYW1pY2FsbHkgYWxsb2NhdGVkIG1lbW9yeSB0byBhdm9pZCBtZW1vcnkgbGVha3MKZGVsZXRlW10gcmV0dXJuZWRBcnJheTs=
36. How do you calculate a given matrix of size?
To calculate the size of a given matrix, you need to determine its dimensions, which typically refer to the number of rows and columns in the matrix.
In general, the size of a matrix is denoted as "m x n", where "m" represents the number of rows and "n" represents the number of columns. The size of a matrix can be calculated by counting the number of rows and columns in the matrix.
For example, consider a matrix A with 3 rows and 4 columns:
A = [a11, a12, a13, a14; a21, a22, a23, a24; a31, a32, a33, a34]
In this case, the matrix A has 3 rows and 4 columns, so its size is 3 x 4.
Alternatively, you can also use built-in functions or methods in programming languages or mathematical software packages to calculate the size of a given matrix. For example, in Python using the NumPy library, you can use the shape attribute to get the dimensions of a matrix:
import numpy as np
A = np.array([[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]])
m, n = A.shape
print("Matrix size: {} x {}".format(m, n))
aW1wb3J0IG51bXB5IGFzIG5wCgpBID0gbnAuYXJyYXkoW1sxLCAyLCAzLCA0XSwKWzUsIDYsIDcsIDhdLApbOSwgMTAsIDExLCAxMl1dKQoKbSwgbiA9IEEuc2hhcGUKcHJpbnQoIk1hdHJpeCBzaXplOiB7fSB4IHt9Ii5mb3JtYXQobSwgbikp
Output: "Matrix size: 3 x 4", indicating that the matrix A has 3 rows and 4 columns.
37. Find the mid-1 element or middle element of a linked list.
To find the middle element of a linked list, you can use the "slow and fast pointers" technique. Here's how it works:
- Initialize two pointers, one called
slowand another calledfast, to point to the head of the linked list. - Move
slowone step at a time, andfasttwo steps at a time. - Keep advancing
slowandfastpointers untilfastreaches the end of the linked list or the node just before the end (if the linked list has an even number of nodes). - At this point,
slowwill be pointing to the middle element (if the linked list has an odd number of nodes) or the mid-1 element (if the linked list has an even number of nodes).
Here's an example implementation in Python:
class ListNode:
def __init__(self, val=0, next=None):
self.val = val
self.next = next
def find_middle_element(head):
slow = head
fast = head
while fast is not None and fast.next is not None:
slow = slow.next
fast = fast.next.next
return slow.val
# Example usage
# Given the linked list: 1 -> 2 -> 3 -> 4 -> 5
# The middle element is 3
head = ListNode(1, ListNode(2, ListNode(3, ListNode(4, ListNode(5)))))
middle_element = find_middle_element(head)
print("Middle element:", middle_element)
IGNsYXNzIExpc3ROb2RlOgpkZWYgX19pbml0X18oc2VsZiwgdmFsPTAsIG5leHQ9Tm9uZSk6CnNlbGYudmFsID0gdmFsCnNlbGYubmV4dCA9IG5leHQKCmRlZiBmaW5kX21pZGRsZV9lbGVtZW50KGhlYWQpOgpzbG93ID0gaGVhZApmYXN0ID0gaGVhZAoKd2hpbGUgZmFzdCBpcyBub3QgTm9uZSBhbmQgZmFzdC5uZXh0IGlzIG5vdCBOb25lOgpzbG93ID0gc2xvdy5uZXh0CmZhc3QgPSBmYXN0Lm5leHQubmV4dAoKcmV0dXJuIHNsb3cudmFsCgojIEV4YW1wbGUgdXNhZ2UKIyBHaXZlbiB0aGUgbGlua2VkIGxpc3Q6IDEgLT4gMiAtPiAzIC0+IDQgLT4gNQojIFRoZSBtaWRkbGUgZWxlbWVudCBpcyAzCmhlYWQgPSBMaXN0Tm9kZSgxLCBMaXN0Tm9kZSgyLCBMaXN0Tm9kZSgzLCBMaXN0Tm9kZSg0LCBMaXN0Tm9kZSg1KSkpKSkKbWlkZGxlX2VsZW1lbnQgPSBmaW5kX21pZGRsZV9lbGVtZW50KGhlYWQpCnByaW50KCJNaWRkbGUgZWxlbWVudDoiLCBtaWRkbGVfZWxlbWVudCkg
38. What is a virtual storage example of physical storage sites?
Virtual storage is a concept in computer systems where a layer of abstraction is introduced between the physical storage devices and the software applications or operating system. Virtual storage allows for more efficient and flexible allocation of storage resources, and it can be implemented in various ways depending on the specific system or technology being used. Here are some examples of virtual storage and their corresponding physical storage sites:
-
Virtual Memory: In modern computer systems, virtual memory is a technique that uses a combination of physical RAM (Random Access Memory) and secondary storage (such as hard disk drives) to create an illusion of a larger addressable memory space for applications. Virtual memory allows processes to access more memory than is physically available in RAM, and it manages the transfer of data between RAM and disk storage as needed. In this case, the physical storage sites would be the RAM modules and the hard disk drives used for secondary storage.
-
Virtual Disks: Virtual disks are virtual storage devices that can be created and managed by software, and they are presented to the operating system or applications as if they were physical disks. Virtual disks can be implemented using various technologies, such as disk virtualization, software-defined storage, or virtual storage area networks (SANs). The physical storage sites for virtual disks would typically be physical disk drives or storage arrays that provide the underlying storage capacity.
-
Cloud Storage: Cloud storage is a type of virtual storage that allows users to store and retrieve data over the internet from remote servers. Cloud storage providers typically use large-scale data centers with distributed storage systems to provide virtual storage resources that can be accessed by users from anywhere with an internet connection. The physical storage sites for cloud storage would be the data centers and the physical storage devices (such as servers, disk drives, and storage arrays) used to store the data in the cloud.
Level: Intermediate
39. What is RDBMS?
RDBMS stands for Relational Database Management System. It is a type of software used for managing relational databases, which are a type of database that organizes data into tables with rows and columns, and establishes relationships between tables based on common data elements. RDBMS is a widely used technology for managing structured data in a variety of applications, ranging from business and finance to scientific and research fields.
In an RDBMS, data is stored in tables, which are organized into databases. Tables consist of rows, also known as records or tuples, which represent individual instances of data, and columns, also known as attributes or fields, which define the types of data that can be stored in each row. The relationships between tables are defined through keys, which are unique identifiers that link data across tables.
40. What is 'null,' and how is memory allocated for null objects handled?
In computer programming and databases, 'null' typically represents the absence of a value or the lack of a valid reference to an object or memory location. It is often used to indicate that a variable, pointer, or object does not currently have a value assigned to it, or that it points to no memory location.
In some programming languages and databases, 'null' is a special value or keyword that is used to represent the absence of a value. For example, in Java, C++, C#, and many other programming languages, 'null' is used to indicate that an object reference does not point to any valid object in memory. Similarly, in SQL databases, 'null' is used to represent the absence of a value in a database column.
Memory allocation for 'null' objects depends on the programming language and implementation. In some programming languages, when a variable or object reference is set to 'null', it simply means that the variable or object reference does not point to any memory location. No memory is allocated for 'null' objects, and accessing or dereferencing a 'null' object typically results in an error or exception being raised.
41. Develop a program that swaps two numbers or two words in the English language.
int temp = 0;
temp = number1;
number1 = number2;
number2 = temp;
Level: Hard
42. Write a program to check if a number is prime.
Pass the number let us say int number = 47;
// set default to not prime
boolean flag = false;
// prime numbers are divisible only by themselves and 1
for(int i = 2; i <= number/2; ++i)
{
// if no remainder
if(number % i == 0)
{
// number is divisible by i, so it is not prime.
flag = true;
// break the loop if the number is not prime
break;
}
}
// if flag is not equal to true
if (!flag)
System.out.println(number + " is prime.");
else
System.out.println(number + " is not prime.");
UGFzcyB0aGUgbnVtYmVyIGxldCB1cyBzYXkgaW50IG51bWJlciA9IDQ3OwoKLy8gc2V0IGRlZmF1bHQgdG8gbm90IHByaW1lCgpib29sZWFuIGZsYWcgPSBmYWxzZTsKCi8vIHByaW1lIG51bWJlcnMgYXJlIGRpdmlzaWJsZSBvbmx5IGJ5IHRoZW1zZWx2ZXMgYW5kIDEKCmZvcihpbnQgaSA9IDI7IGkgPD0gbnVtYmVyLzI7ICsraSkKCnsKCi8vIGlmIG5vIHJlbWFpbmRlcgoKaWYobnVtYmVyICUgaSA9PSAwKQoKewoKLy8gbnVtYmVyIGlzIGRpdmlzaWJsZSBieSBpLCBzbyBpdCBpcyBub3QgcHJpbWUuCgpmbGFnID0gdHJ1ZTsKCi8vIGJyZWFrIHRoZSBsb29wIGlmIHRoZSBudW1iZXIgaXMgbm90IHByaW1lCgpicmVhazsKCn0KCn0KCi8vIGlmIGZsYWcgaXMgbm90IGVxdWFsIHRvIHRydWUKCmlmICghZmxhZykKClN5c3RlbS5vdXQucHJpbnRsbihudW1iZXIgKyAiIGlzIHByaW1lLiIpOwoKZWxzZQoKU3lzdGVtLm91dC5wcmludGxuKG51bWJlciArICIgaXMgbm90IHByaW1lLiIpOw==
IFBhc3MgdGhlIG51bWJlciBsZXQgdXMgc2F5IGludCBudW1iZXIgPSA0NzsKCi8vIHNldCBkZWZhdWx0IHRvIG5vdCBwcmltZQoKYm9vbGVhbiBmbGFnID0gZmFsc2U7CgovLyBwcmltZSBudW1iZXJzIGFyZSBkaXZpc2libGUgb25seSBieSB0aGVtc2VsdmVzIGFuZCAxCgpmb3IoaW50IGkgPSAyOyBpIDw9IG51bWJlci8yOyArK2kpCgp7CgovLyBpZiBubyByZW1haW5kZXIKCmlmKG51bWJlciAlIGkgPT0gMCkKCnsKCi8vIG51bWJlciBpcyBkaXZpc2libGUgYnkgaSwgc28gaXQgaXMgbm90IHByaW1lLgoKZmxhZyA9IHRydWU7CgovLyBicmVhayB0aGUgbG9vcCBpZiB0aGUgbnVtYmVyIGlzIG5vdCBwcmltZQoKYnJlYWs7Cgp9Cgp9CgovLyBpZiBmbGFnIGlzIG5vdCBlcXVhbCB0byB0cnVlCgppZiAoIWZsYWcpCgpTeXN0ZW0ub3V0LnByaW50bG4obnVtYmVyICsgIiBpcyBwcmltZS4iKTsKCmVsc2UKClN5c3RlbS5vdXQucHJpbnRsbihudW1iZXIgKyAiIGlzIG5vdCBwcmltZS4iKTsg
43. In Python, how is memory managed?
Memory management is handled via Python's own heap space. The programmer does not have access to the private heap, which holds all Python objects and data structures. On the other hand, the Python interpreter takes care of this.
- In Python, the memory manager is responsible for allocating heap space for Python objects.
- The core API then provides access to a few dynamic programming tools to the programmer.
- It also has an embedded garbage collector, which recycles all unused memory and makes it available to the heap space, as the name implies.
- This is especially true if you're working with a machine that requires a lot of memory, such as a phone, because range will utilize as much RAM as possible to generate your array return of numbers, resulting in a memory problem and crashing your program.
IBM Interview Questions: HR Round
Technical question round is followed by Behavioral Interview round.
This is the last screening procedure. If selected, you will be welcomed for salary negotiations.
44. Tell us a little bit about yourself.
You can begin answering this question by stating your name, family background, educational background, and previous experiences (if any). Do not say that all the information is already mentioned in your process application form.
45. Tell me something about your past projects.
After systematically answering about your projects and internships, show interest in providing more details. You can expect some follow-up questions post this.
46. What has been the most difficult challenge you've faced as part of a team or project?
This could be a code problem you've been working on for a few days, or a issue in project related to online assessment, such as receiving approval for a project.
47. What are your long-term career objectives?
Describe where you envision yourself in five or ten years. It could be as easy as purchasing a new home or envisioning yourself as the Head Software Developer for a project in Amsterdam working on a speech recognition project. This allows the interviewer to learn more about your personal goals.
48. What are your strengths and weaknesses?
Be truthful. Provide instances of how you have displayed the stated strength or weakness in your answers.
49. What makes you think IBM is a good career choice for you?
After doing some homework on the International Business Machines website, learn about what it does and discuss how your career ambitions align with its mission. Tell the interviewer how you can develop as a person in the organization while offering the best services possible.
For a better understanding of this IBM interview question, click here.
50. What is the relationship between your education and training and the position you are seeking?
The ideal technique is to emphasize education and training background that is relevant to the job description.
Sample answer:
"Like my family background, I have a bachelor's degree in computer engineering. I received on-the-job training supporting servers, printers, desktop computers, routers, firewalls, switches, cellphones, security updates, software deployment, patches, and personal digital assistants in my prior employment as a system administrator. If given the opportunity, I will apply all of my technical skills and experiences to succeed in this position."
51. What are some of the responsibilities you believe you will have if you are hired for this position?
Highlight some of the roles in relevance to the position you're applying for in your response.
Sample answer:
"Having worked as a system administrator for the past five years, I am familiar with the roles that await me here at IBM." They include the following, but are not limited to:
- Leading projects that require upgrades or patches
- Implementing existing or new technology solutions
- Facilitating and overseeing the IT change management process
- Conducting performance troubleshooting and tuning
- Monitoring and managing back-ups as well as installing cumulative PTFs and upgrading packages
International Business Machines, IBM, United States, is primarily a research organization. It invented ATMs, the floppy disc, the hard disc, the SQL programming language, UPC barcodes, and dynamic random-access memory between 1924 and 2020, among other world-changing inventions (DRAM). It holds the record for the most patents issued by a company in the United States area and United Kingdom area in 2020.
Begin your preparation for the IBM interview process by learning about the firm and the position you're looking for. Personalize your comments according to the IBM values.

Good Luck!
Suggested reads:
- Top Netflix Interview Questions For Software Engineer And SRE Roles
- D. E. Shaw Interview Questions For Coding, Technical & HR Round
- Answering Accenture HR Interview Questions Like a Pro!
- Top 50+ TCS HR Interview Questions And Answers 2026
- 35+ Airbus Interview Questions With Answers To Help Get The Job!
Login to continue reading
And access exclusive content, personalized recommendations, and career-boosting opportunities.
Don't have an account? Sign up
Never miss an
Update

Featured Opportunities
Top-Rated Practice by Students





Subscribe
to our newsletter




Comments
Add comment