
Asian Paints Alchemy 2026
Company Interview Questions for Freshers
- TCS Technical Interview Questions & Answers
- TCS Managerial Interview Questions & Answers
- TCS HR Interview Questions & Answers
- Overview of Cognizant Recruitment Process
- Cognizant Interview Questions: Technical
- Cognizant Interview Questions: HR Round
- Overview of Wipro Technologies Recruitment Rounds
- Wipro Interview Questions
- Technical Round
- HR Round
- Online Assessment Sample Questions
- Frequently Asked Questions
- Overview of Google Recruitment Process
- Google Interview Questions: Technical
- Google Interview Questions: HR round
- Interview Preparation Tips
- About Google
- Deloitte Technical Interview Questions
- Deloitte HR Interview Questions
- Deloitte Recruitment Process
- Technical Interview Questions and Answers
- Level 1 difficulty
- Level 2 difficulty
- Level 3 difficulty
- Behavioral Questions
- Eligibility Criteria for Mindtree Recruitment
- Mindtree Recruitment Process: Rounds Overview
- Skills required to crack Mindtree interview rounds
- Mindtree Recruitment Rounds: Sample Questions
- About Mindtree
- Preparing for Microsoft interview questions
- Microsoft technical interview questions
- Microsoft behavioural interview questions
- Aptitude Interview Questions
- Technical Interview Questions
- Easy
- Intermediate
- Hard
- HR Interview Questions
- Eligibility criteria
- Recruitment rounds & assessments
- Tech Mahindra interview questions - Technical round
- Tech Mahindra interview questions - HR round
- Hiring process at Mphasis
- Mphasis technical interview questions
- Mphasis HR interview questions
- About Mphasis
- Technical interview questions
- HR interview questions
- Recruitment process
- About Virtusa
- Goldman Sachs Interview Process
- Technical Questions for Goldman Sachs Interview
- Sample HR Question for Goldman Sachs Interview
- About Goldman Sachs
- Nagarro Recruitment Process
- Nagarro HR Interview Questions
- Nagarro Aptitude Test Questions
- Nagarro Technical Test Questions
- About Nagarro
- PwC Recruitment Process
- PwC Technical Interview Questions: Freshers and Experienced
- PwC Interview Questions for HR Rounds
- PwC Interview Preparation
- Frequently Asked Questions
- EY Technical Interview Questions (2023)
- EY Interview Questions for HR Round
- About EY
- Morgan Stanley Recruitment Process
- HR Questions for Morgan Stanley Interview
- HR Questions for Morgan Stanley Interview
- About Morgan Stanley
- Recruitment Process at Flipkart
- Technical Flipkart Interview Questions
- Code-Based Flipkart Interview Questions
- Sample Flipkart Interview Questions- HR Round
- Conclusion
- FAQs
- Recruitment Process at Paytm
- Technical Interview Questions for Paytm Interview
- HR Sample Questions for Paytm Interview
- About Paytm
- Most Probable Accenture Interview Questions
- Accenture Technical Interview Questions
- Accenture HR Interview Questions
- Amazon Recruitment Process
- Amazon Interview Rounds
- Common Amazon Interview Questions
- Amazon Interview Questions: Behavioral-based Questions
- Amazon Interview Questions: Leadership Principles
- Company-specific Amazon Interview Questions
- 43 Top Technical/ Coding Amazon Interview Questions
- Juspay Recruitment: Stages and Timeline
- Juspay Interview Questions and Answers
- How to prepare for Juspay interview questions
- Prepare for the Juspay Interview: Stages and Timeline
- Frequently Asked Questions
- Adobe Interview Questions - Technical
- Adobe Interview Questions - HR
- Recruitment Process at Adobe
- About Adobe
- Cisco technical interview questions
- Sample HR interview questions
- The recruitment process at Cisco
- About Cisco
- JP Morgan interview questions (Technical round)
- JP Morgan interview questions HR round)
- Recruitment process at JP Morgan
- About JP Morgan
- Wipro Elite NTH: Selection Process
- Wipro Elite NTH Technical Interview Questions
- Wipro Elite NTH Interview Round- HR Questions
- BYJU's BDA Interview Questions
- BYJU's SDE Interview Questions
- BYJU's HR Round Interview Questions
- A Quick Overview of the KPMG Recruitment Process
- Technical Questions for KPMG Interview
- HR Questions for KPMG Interview
- About KPMG
- DXC Technology Interview Process
- DCX Technical Interview Questions
- Sample HR Questions for DXC Technology
- About DXC Technology
- Recruitment Process at PayPal
- Technical Questions for PayPal Interview
- HR Sample Questions for PayPal Interview
- About PayPal
- Capgemini Recruitment Rounds
- Capgemini Interview Questions: Technical round
- Capgemini Interview Questions: HR round
- Preparation tips
- FAQs
- Technical interview questions for Siemens
- Sample HR questions for Siemens
- The recruitment process at Siemens
- About Siemens
- HCL Technical Interview Questions
- HR Interview Questions
- HCL Technologies Recruitment Process
- List of EPAM Interview Questions for Technical Interviews
- About EPAM
- Atlassian Interview Process
- Top Skills for Different Roles at Atlassian
- Atlassian Interview Questions: Technical Knowledge
- Atlassian Interview Questions: Behavioral Skills
- Atlassian Interview Questions: Tips for Effective Preparation
- Walmart Recruitment Process
- Walmart Interview Questions and Sample Answers (HR Round)
- Walmart Interview Questions and Sample Answers (Technical Round)
- Tips for Interviewing at Walmart and Interview Preparation Tips
- Frequently Asked Questions
- Uber Interview Questions For Engineering Profiles: Coding
- Technical Uber Interview Questions: Theoretical
- Uber Interview Question: HR Round
- Uber Recruitment Procedure
- About Uber Technologies Ltd.
- Intel Technical Interview Questions
- Computer Architecture Intel Interview Questions
- Intel DFT Interview Questions
- Intel Interview Questions for Verification Engineer Role
- Recruitment Process Overview
- Important Accenture HR Interview Questions
- Points to remember
- What is Selenium?
- What are the components of the Selenium suite?
- Why is it important to use Selenium?
- What's the major difference between Selenium 3.0 & Selenium 2.0?
- What is Automation testing and what are its benefits?
- What are the benefits of Selenium as an Automation Tool?
- What are the drawbacks to using Selenium for testing?
- Why should Selenium not be used as a web application or system testing tool?
- Is it possible to use selenium to launch web browsers?
- What does Selenese mean?
- What does it mean to be a locator?
- Identify the main difference between "assert", and "verify" commands within Selenium
- What does an exception test in Selenium mean?
- What does XPath mean in Selenium? Describe XPath Absolute & XPath Relation
- What is the difference in Xpath between "//"? and "/"?
- What is the difference between "type" and the "typeAndWait" commands within Selenium?
- Distinguish between findElement() & findElements() in context of Selenium
- How long will Selenium wait before a website is loaded fully?
- What is the difference between the driver.close() and driver.quit() commands in Selenium?
- Describe the different navigation commands that Selenium supports
- What is Selenium's approach to the same-origin policy?
- Explain the difference between findElement() in Selenium and findElements()
- Explain the pause function in SeleniumIDE
- Explain the differences between different frameworks and how they are connected to Selenium's Robot Framework
- What are your thoughts on the Page Object Model within the context of Selenium
- What are your thoughts on Jenkins?
- What are the parameters that selenium commands come with a minimum?
- How can you tell the differences in the Absolute pathway as well as Relative Path?
- What's the distinction in Assert or Verify declarations within Selenium?
- What are the points of verification that are in Selenium?
- Define Implicit wait, Explicit wait, and Fluent
- Can Selenium manage windows-based pop-ups?
- What's the definition of an Object Repository?
- What is the main difference between obtainwindowhandle() as well as the getwindowhandles ()?
- What are the various types of Annotations that are used in Selenium?
- What is the main difference in the setsSpeed() or sleep() methods?
- What is the way to retrieve the alert message?
- How do you determine the exact location of an element on the web?
- Why do we use Selenium RC?
- What are the benefits or advantages of Selenium RC?
- Do you have a list of the technical limitations when making use of Selenium RC? Selenium RC?
- What's the reason to utilize the TestNG together with Selenium?
- What Language do you prefer to use to build test case sets in Selenium?
- What are Start and Breakpoints?
- What is the purpose of this capability relevant in relation to Selenium?
- When do you use AutoIT?
- Do you have a reason why you require Session management in Selenium?
- Are you able to automatize CAPTCHA?
- How can we launch various browsers on Selenium?
- Why should you select Selenium rather than QTP (Quick Test Professional)?
- Airbus Interview Questions and Answers: HR/ Behavioral
- Industry/ Company-Specific Airbus Interview Questions
- Airbus Interview Questions and Answers: Aptitude
- Airbus Software Engineer Interview Questions and Answers: Technical
- Importance of Spring Framework
- Spring Interview Questions (Basic)
- Advanced Spring Interview Questions
- C++ Interview Questions and Answers: The Basics
- C++ Interview Questions: Intermediate
- C++ Interview Questions And Answers With Code Examples
- C++ Interview Questions and Answers: Advanced
- Test Your Skills: Quiz Time
- MBA Interview Questions: B.Com Economics
- B.Com Marketing
- B.Com Finance
- B.Com Accounting and Finance
- Business Studies
- Chartered Accountant
- Q1. Please tell us something about yourself/ Introduce yourself to us.
- Q2. Describe yourself in one word.
- Q3. Tell us about your strengths and weaknesses.
- Q4. Why did you apply for this job/ What attracted you to this role?
- Q5. What are your hobbies?
- Q6. Where do you see yourself in five years OR What are your long-term goals?
- Q7. Why do you want to work with this company?
- Q8. Tell us what you know about our organization
- Q9. Do you have any idea about our biggest competitors?
- Q10. What motivates you to do a good job?
- Q11. What is an ideal job for you?
- Q12. What is the difference between a group and a team?
- Q13. Are you a team player/ Do you like to work in teams?
- Q14. Are you good at handling pressure/ deadlines?
- Q15. When can you start?
- Q16. How flexible are you regarding overtime?
- Q17. Are you willing to relocate for work?
- Q18. Why do you think you are the right candidate for this job?
- Q19. How can you be an asset to the organization?
- Q20. What is your salary expectation?
- Q21. How long do you plan to remain with this company?
- Q22. What is your objective in life?
- Q23. Would you like to pursue your Master's degree anytime soon?
- Q24. How have you planned to achieve your career goal?
- Q25. Can you tell us about your biggest achievement in life?
- Q26. What was the most challenging decision you ever made?
- Q27. What kind of work environment do you prefer to work in?
- Q28. What is the difference between a smart worker and a hard worker?
- Q29. What will you do if you don't get hired?
- Q30. Tell us three things that are most important for you in a job.
- Q31. Who is your role model and what have you learned from him/her?
- Q32. In case of a disagreement, how do you handle the situation?
- Q33. What is the difference between confidence and overconfidence?
- Q34. If you have more than enough money in hand right now, would you still want to work?
- Q35. Do you have any questions for us?
- Interview Tips for Freshers
- Tell me about yourself
- What are your greatest strengths?
- What are your greatest weaknesses?
- Tell me about something you did that you now feel a little ashamed of
- Why are you leaving (or did you leave) this position??
- 15+ resources for preparing most-asked interview questions
- CoCubes Interview Process Overview
- Common CoCubes Interview Questions
- Key Areas to Focus on for CoCubes Interview Preparation
- Conclusion
- Frequently Asked Questions (FAQs)
- Data Analyst Interview Questions With Answers
- About Data Analyst
30+ Important Data Analyst Interview Questions For 2026
Data analysts can help to derive meaningful business insights from data and, thus, are highly sought after in various industries. This article covers the top job interview questions for data analysts.

Data analysis is the methodical application of logical and statistical tools to describe, depict, summarize, and assess data. In short, it involves interacting with data to extract meaningful information that may be applied to decision-making.
The data is collected, cleaned, processed, and then analyzed using various data analysis techniques and tools to find trends, correlations, outliers, and variations that is very important in today’s time.
If you are preparing to join your dream company for a Data Analyst role, you must go through this blog and practice the questions mentioned below.
Data Analyst Interview Questions With Answers
Here are the top Data Analyst questions for revision:
Q1. What tasks does a data analyst perform?
The tasks that data analysts perform are:
- They extract data using special analysis tools and software.
- Responding to data-related queries.
- Conduct surveys and track visitor characteristics on the company website.
- Help in buying datasets from data collection specialists.
- Developing reports and troubleshooting data issues.
- Identify, analyze, and interpret trends from the data storage structure.
- Design and present data in a way that assists individuals, senior management, and business leaders in support of decision-making efforts.
Q2. List the essential abilities that a data analyst should have.
- Data cleaning and preparation
- Data analysis and exploration
- Statistical knowledge
- Creating data visualizations
- Creating dashboards and reports
- Writing and communication
- Domain knowledge
- Problem-solving
- SQL
- Microsoft Excel
- Critical thinking
- R or Python - Statistical Programming
- Data visualization
- Presentation skills
Q3. What procedure is involved in data analysis?
Data analysis involves the following process:
- Defining the question: The first step in the data analysis procedure is to identify the objective by formulating a hypothesis and determining how to test it.
- Collecting the data: The data is gathered from numerous sources after the question has been developed. This information may come from internal or external sources and can be structured or unstructured.
- Cleaning the data: The data that is collected is processed or organized for analysis. This includes organizing the data in a manner that is necessary for appropriate analytic tools. One might need to organize the information in proper rows and columns of a table within a statistical program or spreadsheet.
- Analyzing the data: After being gathered, processed, and cleansed, the data is prepared for analysis. There are numerous data analysis approaches accessible to comprehend, evaluate, and draw conclusions based on the needs.
- Sharing the results: The results obtained from the analysis are communicated and concluded, which helps in decision-making. Data visualization is often used to portray the data for the intended audience.
- Embracing failure: We should remember that data analysis is an iterative process, and one must embrace the possibility of failure. It is essential to learn from failed attempts and modify the approach accordingly.
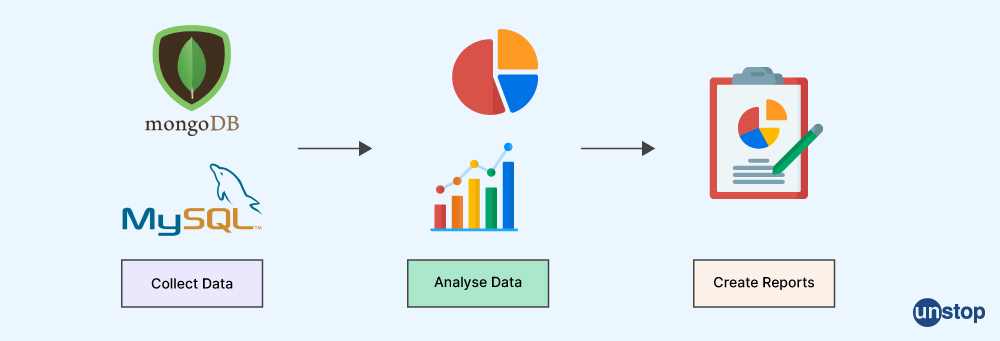
Q4. What kind of difficulties will you encounter when analyzing data?
Different challenges that we can face during data analysis are:
- Collecting meaningful data: Gathering relevant data can be a challenge because there is a vast amount of data available, and all of it may not be useful to us.
- Data from multiple sources: Data can come from multiple sources, and integrating it can be a challenge for us.
- Data analysis skill challenges: A shortage of professionals with essential analytical and other skills can pose a challenge for businesses.
- Constantly evolving data: In today’s time, data is constantly changing so keeping up with the changes can be a challenge.
- Pressure to make quick decisions: The pressure to make decisions may sometimes lead to wrong conclusions that are not based on accurate data.
- Inability to define user requirements properly: Failure to define the user requirements properly can also result in ineffective data analysis.
Q5. What do you mean by data cleansing?
Data cleaning, often known as data scrubbing, is the process of finding and fixing wrong or corrupt records in a record set, table, or database.
Data cleansing involves the following:
- Locating data that is insufficient or unclear.
- Changing, deleting, or replacing imperfect data.
- Checking for and correcting duplicates.
- Verifying its accuracy through proper data validation.
Q6. Name the major analysis tools.
Tools that we can use for data analysis are:
- Python: It is a popular programming language that is used for machine learning, data analysis, as well as data visualization.
- Dataddo: It is a data architecture tool that provides data integration, transformation, and automation.
- RapidMiner: It is a data science platform that provides machine learning and predictive analytics.
- Talend: It is an open-source data integration and data management tool.
- Airtable: It is a cloud-based database that is used for project management and collaboration.
- Google Data Studio: It is a free dashboarding and data visualization tool that integrates with other Google applications.
- SAP BusinessObjects: It is a business intelligence platform that provides data visualization and reporting.
- Sisense: It is a business intelligence software that provides data analytics and visualization.
- TIBCO Spotfire: It is a data analytics and visualization tool that provides interactive dashboards and visualizations.
- Thoughtspot: It is an analytics platform that provides search-driven analytics.
- Alteryx: It is a self-service data analytics platform that provides data preparation, blending, and analytics.
- QlikView: It is a business intelligence platform that provides data visualization and reporting.
Q7. Differentiate between data mining and data profiling.
|
Data Mining |
Data Profiling |
|
The process of data mining entails searching for patterns in extensive data sets to extract useful information. |
Data profiling is the process of identifying patterns, quality, and consistency of data through data analysis. |
|
It is used to derive valuable knowledge from unusual records or datasets for business intelligence. |
The purpose is to assess individual attributes of the data by identifying issues in the data set. |
|
It is used to extract valuable knowledge from large datasets. |
It is used to understand the structure and content of data. |
|
The goal of data mining is to extract actionable data using advanced mathematical algorithms. |
The goal of data profiling is to provide a summary of data by using analytical methods. |
Q8. Which types of validation methods are used by data analysts?
In data analytics, data validation is a critical phase that guarantees the validity and quality of the data. Different types of data validation that are used by data analysts are:
- Scripting method: This method involves using programming languages like Python to validate the data.
- Enterprise tools: These are specialized data validation tools like FME Data validation tools that are used by large organizations.
- Open-source tools: Open-source tools are cost-effective compared to enterprise tools. Examples of open-source tools are, OpenRefine and SourceForge, which are used for data validation.
- Type safety: It involves using tools like Amplitude Data to leverage type safety, unit testing, and linting (static code analysis) for client-side data validation.
- Range check: It involves checking whether the input data is within the expected range.
- Format check: It involves checking whether the input data is in the expected format.
- Consistency check: It involves checking the consistency of data across different sources.
- Uniqueness check: It involves checking whether the input data is unique.
Q9. What is Outlier?
An outlier, as the name suggests, is a data point that significantly differs from other observations in a set of data. In a population-based random sample, it is an observation that is abnormally distant from other values.
Outliers can happen due to disinformation by a subject, errors in a subject's responses, or in data entry. When outliers are present in a data set, statistical tests may overlook or underestimate the actual differences between groups or variables. Outliers can influence summary statistics such as means, standard deviations, and correlation coefficients, potentially leading to incorrect interpretations of the data.
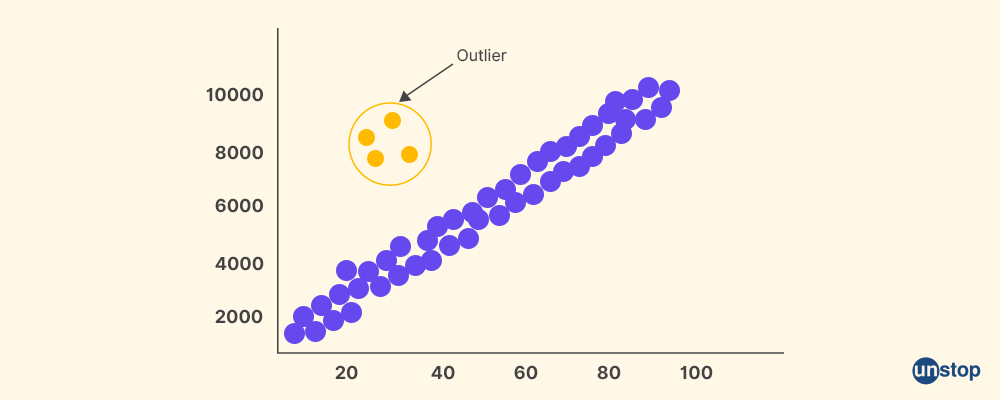
Q10. How will you detect outliers?
To detect outliers, we can use these methods:
- Statistical procedures method: Using statistical models like Grubb's test, generalized ESD, or Pierce's criterion, we can detect outliers. These tests involve processing data through equations to see whether it matches predicted results or not.
- Distance and density method: This method involves measuring the distance of each data point from its neighboring points and identifying any data points that are significantly farther away from their neighbors. Density-based methods like DBSCAN can also be used to detect outliers by identifying clusters of data points with low density.
- Sorting method: We can sort quantitative variables from low to high and scan for extremely low or extremely high values, and flag any extreme values that we find.
Q11. Tell me the difference between data analysis and data mining.
|
Data Analysis |
Data Mining |
|
Data analysis involves the process of cleaning, transforming, and modeling data, which aims to provide information that may be used for business decision-making. |
Large data sets are sorted through data mining in order to uncover patterns and relationships that might be useful in solving business problems through data analysis. |
|
A report or visualization that highlights the most important conclusions drawn from the data is frequently the result of data analysis. |
A set of rules or models that can be used to forecast future trends or make better business decisions are often the results of data mining. |
|
Data analysis involves subjecting data to operations to obtain precise conclusions to help achieve goals. |
It is the process of examining and analyzing vast blocks of data to discover significant patterns and trends. |
Q12. Describe the KNN imputation method.
KNN imputation is a machine learning algorithm used to fill in missing attribute values in datasets. It works by identifying the k-nearest neighbors to each missing value in the dataset and taking the average (or weighted average) of their values.
The KNN imputation method is very helpful for handling all types of missing attribute values because it can be used for discrete, continuous, ordinal, and categorical data.
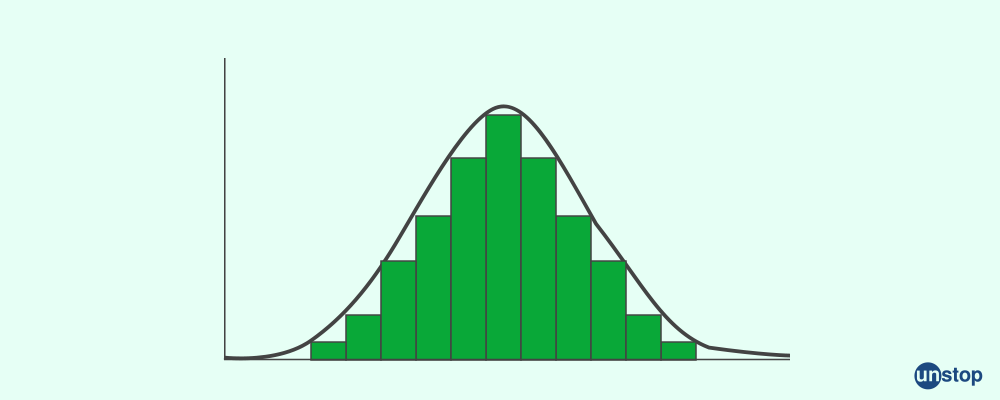
Q13. What is Normal Distribution?
A normal distribution is often known as the Gaussian distribution or bell curve. It refers to a continuous probability distribution that is symmetrical around its mean and is widely used in statistics. The key properties of the normal distribution are:
- There are two parameters that define a normal distribution, i.e., the mean and the standard deviation.
- Most observations cluster around the central peak, which is the mean of the distribution.
- The value of the mean, median, and mode will be the same in a distribution which is entirely normal.
- The standard normal distribution is a particular instance of the normal distribution. The value of its mean and standard deviation are 0 and 1, respectively. The normal distribution has zero skew and a kurtosis of 3.
Q14. Describe the term Data Visualization.
The graphical depiction of information and data using graphs, maps, and other visual tools is known as data visualization. It is a way to communicate complex information in a visual format thus making it easier to understand, interpret and derive insights from.
Q15. Name the Python libraries used for data analysis.
Some of the Python libraries used for data analysis are:
- Pandas
- NumPy
- SciPy
- Matplotlib
- Seaborn
- Scikit-learn
- TensorFlow
- PyTorch
- Keras
Q16. What do you know about hash table?
A data structure that associates keys with values is known as a hash table. Each data value in an array format is kept in a hash table with a distinct index value. So if we are aware of the index for the desired data, access to the data becomes relatively quick.
Q17. Explain the collisions in a hash table. How will you avoid it?
Hash table collisions occur when two or more keys are hashed to the same index in an array, which means that different keys will point to the same location in the array, and their associated values will be stored in that same location. Two common methods of avoiding hash collision are:
- Open addressing - Open addressing is a technique where the hash table searches for the next available slot in the array when a hash collision occurs.
- Separate chaining - In separate chaining, each slot in the hash table is linked to a linked list or chain of values that have the same hash index.
Q18. Explain the features of a good data model.
Features of a good data model are:
- Easily consumable: The data in a good model should be easily understood and consumed by the users.
- Scalable: Large data changes should be scalable in a good data model.
- Determined results: A good data model should provide good performance. This means that the performance of the model should not degrade significantly as more data is added.
- Adaptable: A good data model should be adaptable to changes in requirements.
- Clear understanding of business requirements: Before creating the data for the model, there should be a clear understanding of the requirements that the data model is trying to fulfill.
Q19. What are the disadvantages of data analysis?
Some disadvantages of data analysis are:
- Breach of privacy: Data analysis may breach the privacy of the customers, as their information, like purchases, online transactions, and other personal data, may be used for analysis.
- Limited sample size: Limited sample size or lack of reliable data includes self-reported data, missing data, in data measurements.
- Difficulty in understanding: People who are not familiar with the process of data analysis might sometimes have difficulty in understanding and implementing it. This can cause confusion and a lack of trust in the results.
- High cost: The data analysis process is time-consuming as well.
Q20. Explain Collaborative Filtering.
Collaborative filtering is a technique used in recommender systems to recommend items to users based on their previous behavior.
The key point of collaborative filtering are:
- AIt is a kind of recommender system called collaborative filtering which makes recommendations based on a user's prior actions.
- It focuses on relationships between the item and users, and items' similarity is determined by the rating given by customers who rated both items.
- All users are taken into account in collaborative filtering, and the users with similar tastes and preferences are used to offer new and specialized products to the target customer.
Q21. Explain the term time-series data analysis.
Time series analysis is a technique that is used to analyze data over time to understand trends and patterns. It deals with time-ordered datasets, which are stretched over a period of time.
The vital role of a time series model is divided into two parts:
- Understanding the underlying forces and structure that result in the observable data is the first step, and the second step involves fitting a model before moving on to forecasting, monitoring, and feedforward control.
- Time series analysis plays a vital role in many applications, such as economic forecasting, sales forecasting, budgetary analysis, stock market analysis, process and quality control, inventory studies, workload projections, utility studies, and census analysis.
Q22. What do you understand by the clustering algorithms?
The process of grouping elements based on similarities is called clustering or cluster analysis.
Some properties of clustering algorithms are:
- Interpretability: Clustering algorithms produces clusters that are meaningful and interpretable.
- Robustness: Clustering algorithms are robust to noise and outliers in the data.
- Hierarchical or flat: Clustering algorithms can be hierarchical or flat. Hierarchical algorithms induce a hierarchy of clusters of decreasing generality, but for flat algorithms, all clusters are the same.
- Iterative: Clustering algorithms can be iterative, which means that they start with an initial set of clusters and improve them by reassigning instances to clusters.
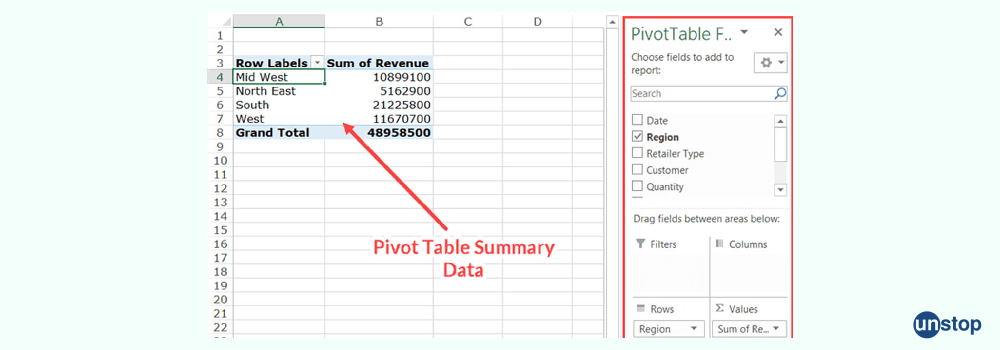
Q23. Define the Pivot Table and tell its usage.
A pivot table is a tool used to explore and summarize large amounts of data in a table. It enables users to change rows into columns and columns into rows.
Some uses of the pivot table are:
- Data grouping: Pivot tables are able to count the number of items in each category, add the values of the elements, or compute the average and identify the minimum or maximum value.
- Create summary tables: Pivot tables allow us to create summary tables that provide quick answers to questions about the original table with source data.
- Calculate fields: Pivot tables let us compute several fields, including the cost of goods sold, margin calculations, and percentage increase in sales.
Q24. Are you familiar with the terms: univariate, bivariate, and multivariate analysis?
Yes, univariate, bivariate, and multivariate analysis are different techniques that are used in statistics to analyze data:
1. Univariate analysis:
The most fundamental type of statistical analysis is known as a univariate analysis, which only considers one variable at a time. This analysis's primary goal is to explain the data and identify patterns.
Summarization, dispersion measurements, and measures of central tendency are all included in this form of analysis.
2. Bivariate analysis:
Two separate variables are used in bivariate analysis, and it focuses on relationships and causes of data.
Bivariate data analysis involves comparisons, relationships, causes, and explanations.
3. Multivariate analysis:
Multivariate analysis is the statistical procedure for analyzing data involving more than two variables, and it is a complex statistical analysis. The link between dependent and independent variables can be examined using multivariate analysis.
Q25. Do you know which tools are used in big data?
The big data analytics tools are:
- Apache Hadoop
- Apache Spark
- Cassandra
- MongoDB
- Apache Flink
- Google Cloud Platform
- Sisense
- RapidMiner
- Qubole
- Xplenty
Q26. Do you know about hierarchical clustering?
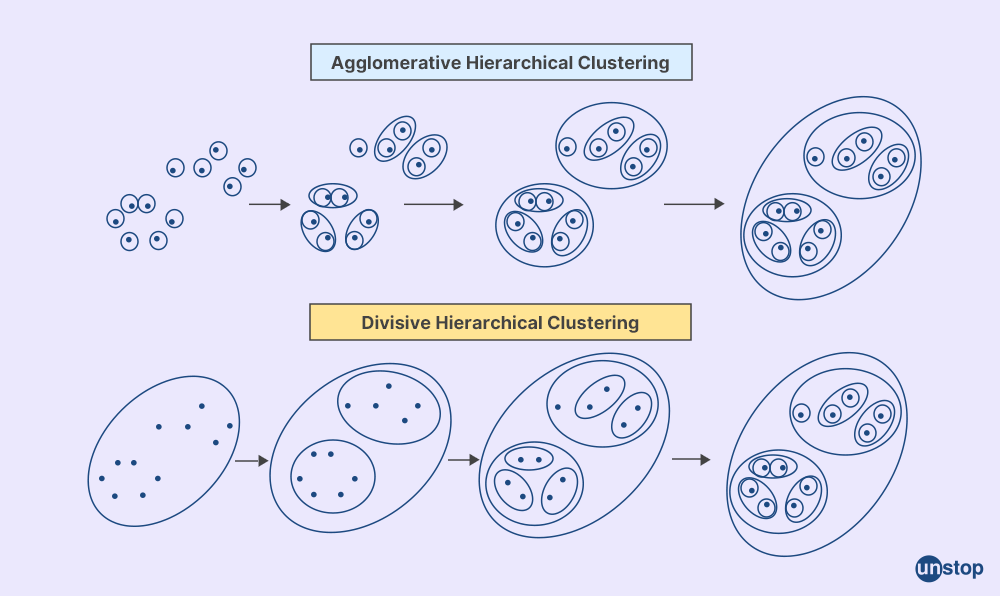
Hierarchical clustering is a method in which items are grouped into sets that are related to one another but are distinct from sets in other groups. A dendrogram is a type of hierarchical tree that shows clusters.
Using the previously specified clusters as a foundation, the hierarchical clustering approach builds subsequent clusters. This process starts by treating each object as a singleton cluster. Next, after merging each cluster into a single large cluster that contains all objects, pairs of clusters are gradually combined, which forms a hierarchical tree.
Q27. Do you know about logistic regression?
Logistic regression refers to a statistical method that is used to build machine learning models wherein the dependent variable is dichotomous. That is, it has only two possible values like true/false, yes/no, etc.
The logistic regression model calculates the possibility of the occurrence of the event, which is based on a collection of independent variables and a particular dataset. It is a useful analysis method, where we have to determine if a new sample fits best into a category.
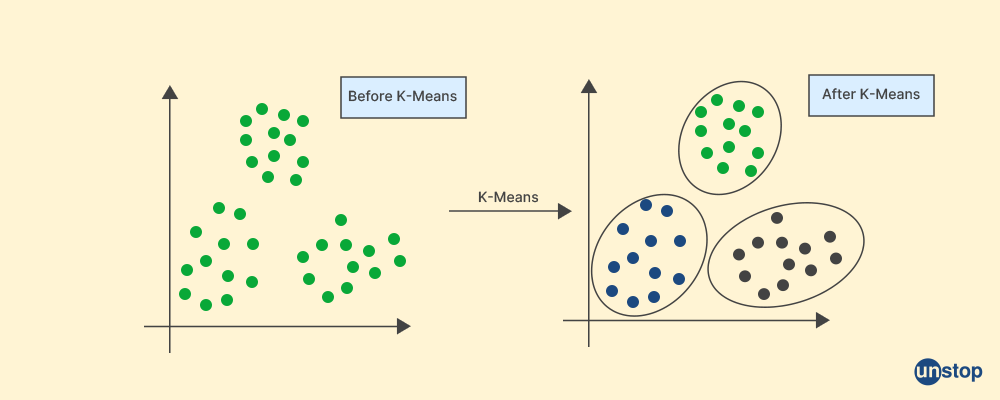
Q28. Explain the K-mean algorithm.
The K-mean algorithm is an unsupervised machine learning algorithm that is used for clustering data points. It divides n observations into k clusters and each observation belongs to the cluster which has the closest mean, which acts as a prototype for the cluster.
The iterative K-means technique divides the dataset into K pre-defined, separate, non-overlapping subgroups (clusters), with each data point belonging to a single group. The algorithm minimizes the variance within each cluster to iteratively partition the data points into K clusters.
Q29. What do you mean by variance and covariance?
Variance: Variance is the spread of a data collection around its mean value. It measures how much a quantity varies with respect to its mean. It also helps us in the standard deviation method, which is a measure of how spread out a set of data is.
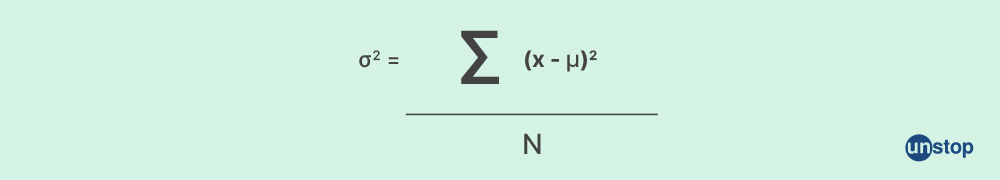
Covariance: The directional relationship between two random variables is measured by covariance. It measures the direction in which two quantities vary with each other. It helps in calculating correlation which shows the direction and magnitude of how two quantities vary with each other.
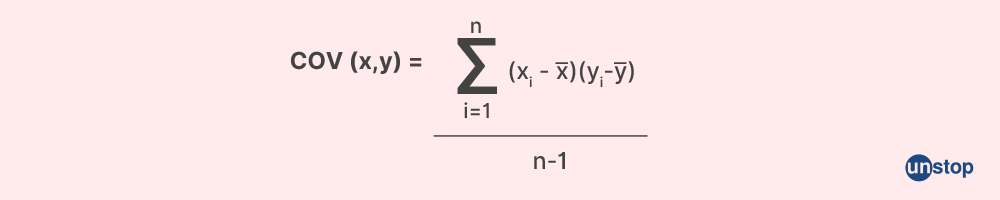
Q30. Tell the advantages of using version control/source control.
The advantages of using version control or source control are:
- Protecting the source code: Version control helps in protecting the source code or variants of code files from any unintended human error and consequences and ensuring that the code will always be recoverable in case of a disaster or data loss.
- Scalability: Version control or source control helps software teams to preserve efficiency and agility as the team scales to include more developers. It also helps developers to move faster and be more productive.
- Tracking changes: Version control has the ability to track changes in files and code which helps us in keeping an extensive history of all modifications made to the codebase over time.
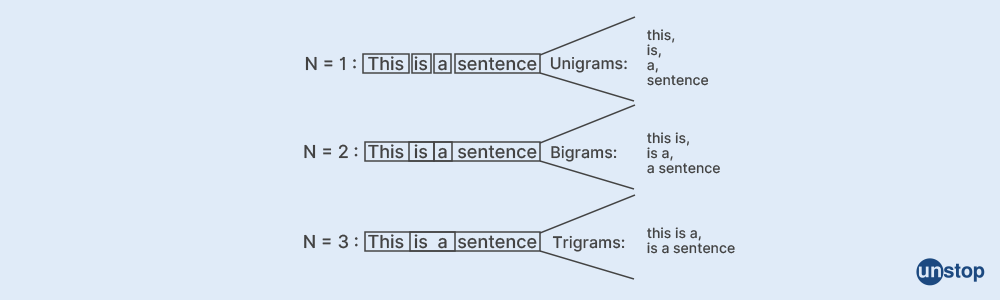
Q31. What do you mean by the term N-gram?
A contiguous group of N-words makes up an N-gram which is a probabilistic language model. NLP (Natural Language Processing) and data science both frequently use the concept of N-grams. N-gram is used to predict the next item in a sequence.
Q32. Tell me the name of some statistical techniques.
Some statistical techniques used in data analytics are:
- Descriptive statistics
- Linear regression
- Classification
- Resampling methods
- Tree-based methods
- Rank statistics
- Predictive analysis
- Hypothesis testing
- Exploratory data analysis
- Causal analysis
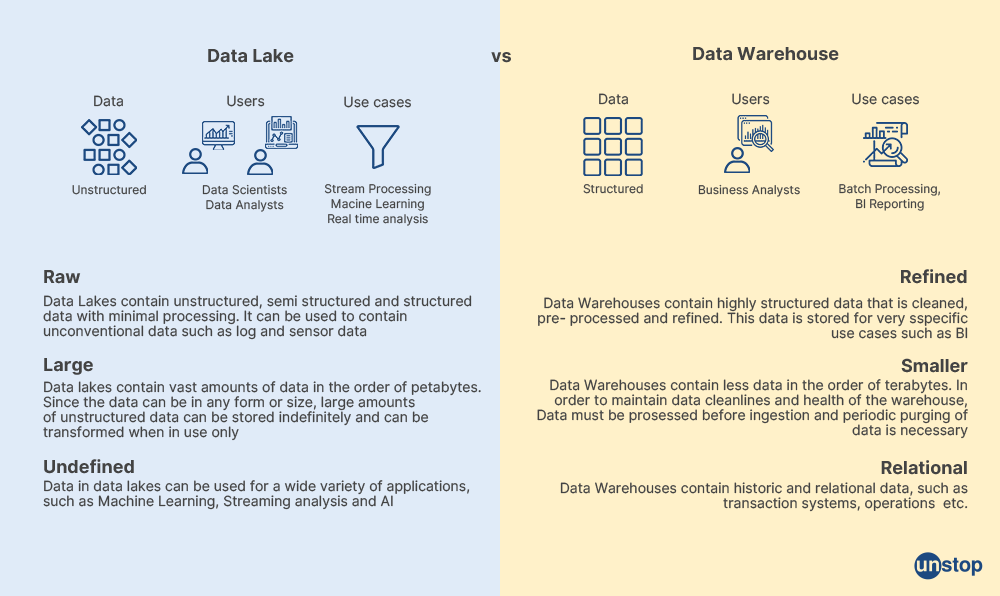
Q33. Explain the term Data Lake and Data Warehouse.
Data Lake
Data lakes are designed for storing raw data of any type, like structured, semi-structured, and unstructured data. It does not have a predefined structure or schema. A data lake is a large storage device that can store data at any scale. It is used by data scientists for machine learning model and advanced analytics.
Data Warehouse
Data warehouse stores processed data from varied sources for a specific purpose and the data is integrated, transformed, and optimized for querying. The schema for data warehouse is designed before data is loaded. A data warehouse is used by business analysts for reporting and analysis.
Data analysts can help to derive meaningful business insights from data and, thus, are highly sought after in a variety of fields. We hope the above questions helped you go through the critical topics of data analysis to boost up your preparation levels. All the best!
About Data Analyst
Data analysts are responsible for the collection, processing, and statistical examination of data, as well as the interpretation of numerical results into language that is more easily understood by the general public. They help businesses make sense of how they operate by spotting patterns and generating forecasts about the future.
Figuring out the statistics is normally accomplished by data analysts through the utilization of computer systems and various calculating programs. Data must be regulated, normalized, and calibrated before it can be extracted, used on its own, or combined with the other statistics while still maintaining its integrity.
The presentation of the data in an engaging manner, making use of graphs, charts, tables, and graphics, is of the utmost importance. While the facts and the statistics are an excellent place to begin, the most important thing is to comprehend what they imply.
Data analysts can help to derive meaningful business insights from data and, thus, are highly sought after in a variety of fields. We hope the above questions helped you go through the critical topics of data analysis to boost up your preparation levels. All the best!
Suggested reads:
- 50 MVC Interview Questions That You Can't Ignore!
- .NET Interview Questions That You 'WILL' Be Asked In The Technical Round
- Best MySQL Interview Questions With Answers For Revision
- 40+ Important Hibernate Interview Questions & Answers (2022)
- Don't Forget To Revise These AngularJS Interview Questions Before Facing Your Job Interview!
Login to continue reading
And access exclusive content, personalized recommendations, and career-boosting opportunities.
Don't have an account? Sign up
Never miss an
Update

Featured Opportunities
Top-Rated Practice by Students





Subscribe
to our newsletter
Blogs you need to hog!

This Is My First Hackathon, How Should I Prepare? (Tips & Hackathon Questions Inside)
D2C Admin

10 Best C++ IDEs That Developers Mention The Most!
D2C Admin

Advantages and Disadvantages of Cloud Computing That You Should Know!
D2C Admin

Is IoT Valuable? Advantages And Disadvantages Of IoT Explained
Shivangi Vatsal
Comments
Add comment