

Asian Paints Alchemy 2026
Company Interview Questions for Freshers
- TCS Technical Interview Questions & Answers
- TCS Managerial Interview Questions & Answers
- TCS HR Interview Questions & Answers
- Overview of Cognizant Recruitment Process
- Cognizant Interview Questions: Technical
- Cognizant Interview Questions: HR Round
- Overview of Wipro Technologies Recruitment Rounds
- Wipro Interview Questions
- Technical Round
- HR Round
- Online Assessment Sample Questions
- Frequently Asked Questions
- Overview of Google Recruitment Process
- Google Interview Questions: Technical
- Google Interview Questions: HR round
- Interview Preparation Tips
- About Google
- Deloitte Technical Interview Questions
- Deloitte HR Interview Questions
- Deloitte Recruitment Process
- Technical Interview Questions and Answers
- Level 1 difficulty
- Level 2 difficulty
- Level 3 difficulty
- Behavioral Questions
- Eligibility Criteria for Mindtree Recruitment
- Mindtree Recruitment Process: Rounds Overview
- Skills required to crack Mindtree interview rounds
- Mindtree Recruitment Rounds: Sample Questions
- About Mindtree
- Preparing for Microsoft interview questions
- Microsoft technical interview questions
- Microsoft behavioural interview questions
- Aptitude Interview Questions
- Technical Interview Questions
- Easy
- Intermediate
- Hard
- HR Interview Questions
- Eligibility criteria
- Recruitment rounds & assessments
- Tech Mahindra interview questions - Technical round
- Tech Mahindra interview questions - HR round
- Hiring process at Mphasis
- Mphasis technical interview questions
- Mphasis HR interview questions
- About Mphasis
- Technical interview questions
- HR interview questions
- Recruitment process
- About Virtusa
- Goldman Sachs Interview Process
- Technical Questions for Goldman Sachs Interview
- Sample HR Question for Goldman Sachs Interview
- About Goldman Sachs
- Nagarro Recruitment Process
- Nagarro HR Interview Questions
- Nagarro Aptitude Test Questions
- Nagarro Technical Test Questions
- About Nagarro
- PwC Recruitment Process
- PwC Technical Interview Questions: Freshers and Experienced
- PwC Interview Questions for HR Rounds
- PwC Interview Preparation
- Frequently Asked Questions
- EY Technical Interview Questions (2023)
- EY Interview Questions for HR Round
- About EY
- Morgan Stanley Recruitment Process
- HR Questions for Morgan Stanley Interview
- HR Questions for Morgan Stanley Interview
- About Morgan Stanley
- Recruitment Process at Flipkart
- Technical Flipkart Interview Questions
- Code-Based Flipkart Interview Questions
- Sample Flipkart Interview Questions- HR Round
- Conclusion
- FAQs
- Recruitment Process at Paytm
- Technical Interview Questions for Paytm Interview
- HR Sample Questions for Paytm Interview
- About Paytm
- Most Probable Accenture Interview Questions
- Accenture Technical Interview Questions
- Accenture HR Interview Questions
- Amazon Recruitment Process
- Amazon Interview Rounds
- Common Amazon Interview Questions
- Amazon Interview Questions: Behavioral-based Questions
- Amazon Interview Questions: Leadership Principles
- Company-specific Amazon Interview Questions
- 43 Top Technical/ Coding Amazon Interview Questions
- Juspay Recruitment: Stages and Timeline
- Juspay Interview Questions and Answers
- How to prepare for Juspay interview questions
- Prepare for the Juspay Interview: Stages and Timeline
- Frequently Asked Questions
- Adobe Interview Questions - Technical
- Adobe Interview Questions - HR
- Recruitment Process at Adobe
- About Adobe
- Cisco technical interview questions
- Sample HR interview questions
- The recruitment process at Cisco
- About Cisco
- JP Morgan interview questions (Technical round)
- JP Morgan interview questions HR round)
- Recruitment process at JP Morgan
- About JP Morgan
- Wipro Elite NTH: Selection Process
- Wipro Elite NTH Technical Interview Questions
- Wipro Elite NTH Interview Round- HR Questions
- BYJU's BDA Interview Questions
- BYJU's SDE Interview Questions
- BYJU's HR Round Interview Questions
- A Quick Overview of the KPMG Recruitment Process
- Technical Questions for KPMG Interview
- HR Questions for KPMG Interview
- About KPMG
- DXC Technology Interview Process
- DCX Technical Interview Questions
- Sample HR Questions for DXC Technology
- About DXC Technology
- Recruitment Process at PayPal
- Technical Questions for PayPal Interview
- HR Sample Questions for PayPal Interview
- About PayPal
- Capgemini Recruitment Rounds
- Capgemini Interview Questions: Technical round
- Capgemini Interview Questions: HR round
- Preparation tips
- FAQs
- Technical interview questions for Siemens
- Sample HR questions for Siemens
- The recruitment process at Siemens
- About Siemens
- HCL Technical Interview Questions
- HR Interview Questions
- HCL Technologies Recruitment Process
- List of EPAM Interview Questions for Technical Interviews
- About EPAM
- Atlassian Interview Process
- Top Skills for Different Roles at Atlassian
- Atlassian Interview Questions: Technical Knowledge
- Atlassian Interview Questions: Behavioral Skills
- Atlassian Interview Questions: Tips for Effective Preparation
- Walmart Recruitment Process
- Walmart Interview Questions and Sample Answers (HR Round)
- Walmart Interview Questions and Sample Answers (Technical Round)
- Tips for Interviewing at Walmart and Interview Preparation Tips
- Frequently Asked Questions
- Uber Interview Questions For Engineering Profiles: Coding
- Technical Uber Interview Questions: Theoretical
- Uber Interview Question: HR Round
- Uber Recruitment Procedure
- About Uber Technologies Ltd.
- Intel Technical Interview Questions
- Computer Architecture Intel Interview Questions
- Intel DFT Interview Questions
- Intel Interview Questions for Verification Engineer Role
- Recruitment Process Overview
- Important Accenture HR Interview Questions
- Points to remember
- What is Selenium?
- What are the components of the Selenium suite?
- Why is it important to use Selenium?
- What's the major difference between Selenium 3.0 & Selenium 2.0?
- What is Automation testing and what are its benefits?
- What are the benefits of Selenium as an Automation Tool?
- What are the drawbacks to using Selenium for testing?
- Why should Selenium not be used as a web application or system testing tool?
- Is it possible to use selenium to launch web browsers?
- What does Selenese mean?
- What does it mean to be a locator?
- Identify the main difference between "assert", and "verify" commands within Selenium
- What does an exception test in Selenium mean?
- What does XPath mean in Selenium? Describe XPath Absolute & XPath Relation
- What is the difference in Xpath between "//"? and "/"?
- What is the difference between "type" and the "typeAndWait" commands within Selenium?
- Distinguish between findElement() & findElements() in context of Selenium
- How long will Selenium wait before a website is loaded fully?
- What is the difference between the driver.close() and driver.quit() commands in Selenium?
- Describe the different navigation commands that Selenium supports
- What is Selenium's approach to the same-origin policy?
- Explain the difference between findElement() in Selenium and findElements()
- Explain the pause function in SeleniumIDE
- Explain the differences between different frameworks and how they are connected to Selenium's Robot Framework
- What are your thoughts on the Page Object Model within the context of Selenium
- What are your thoughts on Jenkins?
- What are the parameters that selenium commands come with a minimum?
- How can you tell the differences in the Absolute pathway as well as Relative Path?
- What's the distinction in Assert or Verify declarations within Selenium?
- What are the points of verification that are in Selenium?
- Define Implicit wait, Explicit wait, and Fluent
- Can Selenium manage windows-based pop-ups?
- What's the definition of an Object Repository?
- What is the main difference between obtainwindowhandle() as well as the getwindowhandles ()?
- What are the various types of Annotations that are used in Selenium?
- What is the main difference in the setsSpeed() or sleep() methods?
- What is the way to retrieve the alert message?
- How do you determine the exact location of an element on the web?
- Why do we use Selenium RC?
- What are the benefits or advantages of Selenium RC?
- Do you have a list of the technical limitations when making use of Selenium RC? Selenium RC?
- What's the reason to utilize the TestNG together with Selenium?
- What Language do you prefer to use to build test case sets in Selenium?
- What are Start and Breakpoints?
- What is the purpose of this capability relevant in relation to Selenium?
- When do you use AutoIT?
- Do you have a reason why you require Session management in Selenium?
- Are you able to automatize CAPTCHA?
- How can we launch various browsers on Selenium?
- Why should you select Selenium rather than QTP (Quick Test Professional)?
- Airbus Interview Questions and Answers: HR/ Behavioral
- Industry/ Company-Specific Airbus Interview Questions
- Airbus Interview Questions and Answers: Aptitude
- Airbus Software Engineer Interview Questions and Answers: Technical
- Importance of Spring Framework
- Spring Interview Questions (Basic)
- Advanced Spring Interview Questions
- C++ Interview Questions and Answers: The Basics
- C++ Interview Questions: Intermediate
- C++ Interview Questions And Answers With Code Examples
- C++ Interview Questions and Answers: Advanced
- Test Your Skills: Quiz Time
- MBA Interview Questions: B.Com Economics
- B.Com Marketing
- B.Com Finance
- B.Com Accounting and Finance
- Business Studies
- Chartered Accountant
- Q1. Please tell us something about yourself/ Introduce yourself to us.
- Q2. Describe yourself in one word.
- Q3. Tell us about your strengths and weaknesses.
- Q4. Why did you apply for this job/ What attracted you to this role?
- Q5. What are your hobbies?
- Q6. Where do you see yourself in five years OR What are your long-term goals?
- Q7. Why do you want to work with this company?
- Q8. Tell us what you know about our organization
- Q9. Do you have any idea about our biggest competitors?
- Q10. What motivates you to do a good job?
- Q11. What is an ideal job for you?
- Q12. What is the difference between a group and a team?
- Q13. Are you a team player/ Do you like to work in teams?
- Q14. Are you good at handling pressure/ deadlines?
- Q15. When can you start?
- Q16. How flexible are you regarding overtime?
- Q17. Are you willing to relocate for work?
- Q18. Why do you think you are the right candidate for this job?
- Q19. How can you be an asset to the organization?
- Q20. What is your salary expectation?
- Q21. How long do you plan to remain with this company?
- Q22. What is your objective in life?
- Q23. Would you like to pursue your Master's degree anytime soon?
- Q24. How have you planned to achieve your career goal?
- Q25. Can you tell us about your biggest achievement in life?
- Q26. What was the most challenging decision you ever made?
- Q27. What kind of work environment do you prefer to work in?
- Q28. What is the difference between a smart worker and a hard worker?
- Q29. What will you do if you don't get hired?
- Q30. Tell us three things that are most important for you in a job.
- Q31. Who is your role model and what have you learned from him/her?
- Q32. In case of a disagreement, how do you handle the situation?
- Q33. What is the difference between confidence and overconfidence?
- Q34. If you have more than enough money in hand right now, would you still want to work?
- Q35. Do you have any questions for us?
- Interview Tips for Freshers
- Tell me about yourself
- What are your greatest strengths?
- What are your greatest weaknesses?
- Tell me about something you did that you now feel a little ashamed of
- Why are you leaving (or did you leave) this position??
- 15+ resources for preparing most-asked interview questions
- CoCubes Interview Process Overview
- Common CoCubes Interview Questions
- Key Areas to Focus on for CoCubes Interview Preparation
- Conclusion
- Frequently Asked Questions (FAQs)
- Data Analyst Interview Questions With Answers
- About Data Analyst
Most Commonly Asked Wipro Interview Questions With Answers (2026)
Check out this exhaustive list of important Wipro interview questions and answers. Test where you stand and scale up your prep level!
Dreaming of a career at Wipro, one of India’s top multinational giants? You’re aiming for a future filled with innovation, global exposure, and limitless growth. Wipro offers incredible opportunities across IT, BPO, consulting, and product engineering.
But to land your dream role at this prestigious company, solid interview preparation is the key. Let’s help you get interview-ready and one step closer to becoming a part of the Wipro family.
About Wipro
Wipro Technologies Limited is one of the leading global consulting and information technology services companies. Wipro is recognized all over the world for its complete range of services, a strong commitment to sustainability, and good corporate social responsibility. It is ranked as the 9th largest company in terms of providing employment in India with 100 million-plus employees. For hiring freshers, the company launches Wipro Elite NTH every year which has various rounds of selections.
Overview of Wipro Technologies Recruitment Rounds
Wipro Elite National Talent Hunt (NTH) recruitment process is divided into three stages:
Pre-placement Talk
The pre-placement talk is a befitting opportunity for a candidate to be face to face with the Wipro Technologies recruitment team and chat about your ambitions, interests, and requirements for placement opportunities. Have a positive attitude while attending the pre-placement talk. It is also an opportunity to gain knowledge about Wipro Technologies, your job description, and how it is after placements there. This is the first step of the Wipro recruitment process.
Online Assessment
The questions asked in the quantitative aptitude round are usually from easy to medium levels. The coding round has 2 questions and is relatively easy if the candidate has basic knowledge of competitive programming concepts. The programming languages allowed are C, C++, Java and Python. The duration of this section is 60 minutes. The essay writing has to be done within the word limit of 100 to 400 words.
- Aptitude Test
- Total Questions - 16 Questions
- Total Time - 16 mins
- No Negative Marking
- Logical Ability Test
- Total Questions - 14 Questions
- Total Time - 14 mins
- Verbal Ability Test
- Total Questions - 22 Questions
- Total Time - 18 mins
- Essay Writing: There is no specific syllabus for essay writing. Any generic topic may be given.
- Coding Assessment: This consists of two coding questions.
Interview
There are two types of interview rounds - technical and HR. While the technical round assesses the subject knowledge of the candidate, the HR round is focused on interpersonal skills.

Wipro Interview Questions & Answers [Technical+HR]
Wipro interview can be bifurcated into the Wipro Technical interview round and HR interview round.
- Wipro Technical Interview revolves around your technical skills. Generally, questions from object-oriented programming languages (C, C++, and Java ), networking, DBMS, and operating systems are asked.
- Wipro HR Interview is the easiest of rounds. In this round, the interviewer will inquire about basics like your introduction, short-term goals, long-term goals, strengths, weaknesses and more. The round majorly focuses on your communication skills.
50 Most Asked Wipro Interview Questions for Technical Round
Here is a list of important and common Wipro interview questions that can be asked in the technical round:
Q1. What do you mean by dynamic memory allocation?
Dynamic memory allocation is a process in computer programming where memory is allocated during runtime or execution of a program, as opposed to static memory allocation, where memory is allocated at compile-time. In dynamic memory allocation, memory is allocated and deallocated as needed during the execution of a program, allowing for more flexibility in managing memory resources.
Dynamic memory allocation is typically used when the size of memory needed by a program cannot be determined at compile-time, or when memory needs to be allocated and deallocated dynamically based on program logic or user input. Dynamic memory allocation is commonly used in programming languages like C, C++, Java, and Python, among others.
Dynamic memory allocation allows programs to efficiently use memory resources and avoid wastage. It involves allocating memory from a pool of available memory at runtime, and deallocating or releasing memory when it is no longer needed, making it available for other parts of the program or for other programs to use. However, dynamic memory allocation also requires careful memory management to prevent issues like memory leaks or dangling pointers, which can lead to program crashes or other unexpected behavior if not handled properly. Properly managing dynamic memory allocation is an important skill in computer programming to ensure efficient memory usage and reliable program execution.
Q2. Which component class method is used in specifying the size and position of a component?
In Java Swing, a popular GUI (Graphical User Interface) library for building desktop applications, the setBounds() method of the Component class is used to specify the size and position of a component. The Component class is a base class for all the visual components in Swing, such as buttons, labels, text fields, and more.
The setBounds() method allows you to set the location (x, y coordinates) and size (width and height) of a component within its container. It takes four parameters:
x: An integer value representing the x-coordinate of the component's top-left corner.y: An integer value representing the y-coordinate of the component's top-left corner.width: An integer value representing the width of the component.height: An integer value representing the height of the component.
For example, the following code snippet sets the location of a JButton component to (100, 50) and its size to 200x100 pixels:
import javax.swing.JButton;
import javax.swing.JFrame;
public class ComponentBoundsExample {
public static void main(String[] args) {
// Create a JFrame
JFrame frame = new JFrame("Component Bounds Example");
// Create a JButton
JButton button = new JButton("Click me!");
// Set the bounds of the button
button.setBounds(100, 50, 200, 100);
// Add the button to the frame
frame.add(button);
// Set the size and layout of the frame
frame.setSize(400, 300);
frame.setLayout(null);
// Set default close operation and make the frame visible
frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
frame.setVisible(true);
}
} aW1wb3J0IGphdmF4LnN3aW5nLkpCdXR0b247CmltcG9ydCBqYXZheC5zd2luZy5KRnJhbWU7CgpwdWJsaWMgY2xhc3MgQ29tcG9uZW50Qm91bmRzRXhhbXBsZSB7CnB1YmxpYyBzdGF0aWMgdm9pZCBtYWluKFN0cmluZ1tdIGFyZ3MpIHsKLy8gQ3JlYXRlIGEgSkZyYW1lCkpGcmFtZSBmcmFtZSA9IG5ldyBKRnJhbWUoIkNvbXBvbmVudCBCb3VuZHMgRXhhbXBsZSIpOwoKLy8gQ3JlYXRlIGEgSkJ1dHRvbgpKQnV0dG9uIGJ1dHRvbiA9IG5ldyBKQnV0dG9uKCJDbGljayBtZSEiKTsKCi8vIFNldCB0aGUgYm91bmRzIG9mIHRoZSBidXR0b24KYnV0dG9uLnNldEJvdW5kcygxMDAsIDUwLCAyMDAsIDEwMCk7CgovLyBBZGQgdGhlIGJ1dHRvbiB0byB0aGUgZnJhbWUKZnJhbWUuYWRkKGJ1dHRvbik7CgovLyBTZXQgdGhlIHNpemUgYW5kIGxheW91dCBvZiB0aGUgZnJhbWUKZnJhbWUuc2V0U2l6ZSg0MDAsIDMwMCk7CmZyYW1lLnNldExheW91dChudWxsKTsKCi8vIFNldCBkZWZhdWx0IGNsb3NlIG9wZXJhdGlvbiBhbmQgbWFrZSB0aGUgZnJhbWUgdmlzaWJsZQpmcmFtZS5zZXREZWZhdWx0Q2xvc2VPcGVyYXRpb24oSkZyYW1lLkVYSVRfT05fQ0xPU0UpOwpmcmFtZS5zZXRWaXNpYmxlKHRydWUpOwp9Cn0=
Q3. What do you mean by a time slice? What are the advantages of time slicing technique?
In the context of computer systems and operating systems, a time slice, also known as a time quantum or time slot, refers to a fixed amount of time that is allocated to a process or thread for execution by the CPU (central processing unit). It is a time interval during which a process or thread is allowed to execute instructions before the CPU is switched to another process or thread. Time slicing is a technique used in multitasking or multi-threading systems to enable the concurrent execution of multiple processes or threads by allowing them to take turns utilizing the CPU in a time-shared manner.
The advantages of employing the time-slicing technique in operating systems include:
-
Fairness: Time slicing ensures that each process or thread gets a fair share of CPU time, regardless of their priority or resource requirements. This prevents a single process or thread from monopolizing the CPU and starving other processes or threads, leading to improved system responsiveness and fairness in resource allocation.
-
Concurrent execution: Time slicing enables concurrent execution of multiple processes or threads, allowing them to run concurrently and progress in parallel. This can result in better system throughput, as multiple processes or threads can make progress simultaneously, leading to improved system efficiency.
-
Responsiveness: Time slicing can help improve system responsiveness by allowing processes or threads to be quickly switched in and out of the CPU, minimizing delays and improving user experience. This is particularly important in interactive systems where responsiveness is a critical requirement, such as in desktop operating systems, web servers, and real-time systems.
-
Utilization of idle CPU time: Time slicing ensures that CPU time is efficiently utilized, even during periods of low CPU utilization. When there are no processes or threads that are ready to execute, the CPU can be utilized by other processes or threads in the system, preventing wasted CPU cycles and maximizing system utilization.
-
Priority-based scheduling: Time slicing can be combined with priority-based scheduling algorithms, where higher priority processes or threads are given longer time slices, and lower priority processes or threads are given shorter time slices. This allows for effective prioritization of processes or threads based on their importance, allowing critical tasks to be executed with higher priority, while still providing opportunities for lower-priority tasks to execute.
Q4. What are Java library functions?
Java library functions, also known as Java standard library functions or Java built-in functions, are pre-defined functions that are part of the Java Standard Library, a collection of classes and interfaces that come with the Java Development Kit (JDK). These functions are provided by Java's standard class library, which is a large collection of reusable code that can be used to perform common tasks in Java programming without having to implement them from scratch.
Java library functions cover a wide range of functionalities, including but not limited to:
-
String manipulation: Java provides built-in functions for tasks such as string concatenation, substring extraction, character encoding/decoding, regular expressions, and more, through classes like String, StringBuilder, and Pattern.
-
Input/output operations: Java offers functions for reading from and writing to files, streams, and consoles, as well as for performing serialization and deserialization of objects, through classes like File Management, InputStream, OutputStream, and ObjectInputStream/ObjectOutputStream.
-
Collection manipulation: Java provides a rich set of classes and interfaces for working with collections of objects, such as lists, sets, maps, and queues, through classes like ArrayList, HashSet, HashMap, and PriorityQueue, as well as utility classes like Collections for common operations on collections.
-
Date and time handling: Java includes classes for working with dates, times, and time zones, such as LocalDate, LocalDateTime, ZonedDateTime, and DateFormat, for tasks like parsing, formatting, and manipulating dates and times.
-
Math and numerical operations: Java provides functions for basic math operations like addition, subtraction, multiplication, and division, as well as more advanced mathematical functions like trigonometric, logarithmic, and exponential functions, through classes like Math.
-
Networking: Java includes classes for performing networking tasks such as creating sockets, establishing connections, sending and receiving data over networks, and working with protocols like TCP/IP and HTTP, through classes like Socket, URLConnection, and HttpURLConnection.
-
Concurrency: Java provides classes and interfaces for concurrent programming, including multi-threading, synchronization, and inter-thread communication, through classes like Thread, Runnable, Lock, and Condition, for writing concurrent and parallel programs.
Explore jobs and internships across 180+ categories!
Q5. What is a binary search tree?
A binary search tree (BST) is a binary tree data structure where each node has at most two child nodes, and the value of the node on the left is less than or equal to the parent node, while the value of the node on the right is greater than or equal to the parent node. In other words, a BST maintains a sorted order of elements, where elements with lower values are stored on the left subtree, and elements with higher values are stored on the right subtree.
A BST is commonly used for searching, insertion, and deletion operations on a collection of data that is organized in a hierarchical structure. It allows for efficient searching of elements in O(log n) time complexity on average, making it suitable for large datasets. BSTs can be used to implement various types of data structures such as sets, dictionaries, and priority queues.
There are different variations of BSTs, including the binary search tree, binary search tree with balanced properties (e.g., AVL tree, Red-Black tree), and binary search tree with additional features (e.g., B-tree, Trie), each with its own advantages and trade-offs in terms of performance, memory usage, and ease of implementation.
Q6. What is a string class? (answer in a sentence)
A string class is a programming data type or object that represents a sequence of characters or text in computer programming languages, allowing operations such as manipulation, concatenation, and comparison of strings.
Q7. What is Natural Language Processing?
Natural Language Processing (NLP) is a subfield of artificial intelligence (AI) that focuses on enabling computers to understand, interpret, and generate human language in a way that is both meaningful and contextually relevant. NLP involves the use of algorithms, techniques, and models to process, analyze, and derive insights from human language data, such as text and speech. Applications of NLP include language translation, sentiment analysis, speech recognition, text summarization, question answering, chatbots, and many other language-related tasks.
Q8. What is normalization? (answer in a sentence)
Normalization is the process of transforming data in a relational database to eliminate redundancy and ensure data consistency, integrity, and efficiency, typically through a set of rules that define how data is organized and stored in tables.
Q9. What are DDL and DML commands?
DDL and DML are two categories of SQL (Structured Query Language) commands used in relational databases:
-
DDL (Data Definition Language) commands: DDL commands are used to define and manage the structure of a database. They are used to create, modify, and delete database objects such as tables, views, indexes, schemas, and constraints. Examples of DDL commands include CREATE, ALTER, DROP, TRUNCATE, and RENAME. DDL commands are typically executed by database administrators or users with sufficient privileges to modify the database structure.
-
DML (Data Manipulation Language) commands: DML commands are used to manipulate data stored in a database. They are used to perform operations such as inserting, retrieving, updating, and deleting data in database tables. Examples of DML commands include SELECT, INSERT, UPDATE, DELETE, and MERGE. DML commands are typically executed by application developers or users with appropriate permissions to manipulate data in the database.
Q10. Name some of the popular OS in use today.
Some of the popular operating systems (OS) in use today, include:
-
Microsoft Windows: Microsoft Windows is a widely used OS with various versions, such as Windows 10, Windows 8, and Windows 7, which are popular among personal computers and laptops.
-
macOS: macOS is the operating system developed by Apple Inc. for its Macintosh computers, including the MacBook, iMac, and Mac Pro.
-
Linux: Linux is a popular open-source operating system that comes in various distributions (distros) such as Ubuntu, Fedora, Debian, and CentOS, and is widely used in servers, embedded systems, and as a platform for developers.
-
Android: Android is a popular operating system developed by Google for mobile devices, including smartphones and tablets, and is widely used in the mobile ecosystem.
-
iOS: iOS is the operating system developed by Apple Inc. exclusively for its mobile devices, including iPhones, iPads, and iPod Touch, and is known for its seamless integration with Apple's hardware and software ecosystem.
-
Chrome OS: Chrome OS is the operating system developed by Google for Chromebooks, which are lightweight laptops designed for web-based computing and are popular in the education and consumer markets.
-
FreeBSD: FreeBSD is a popular open-source operating system based on the Berkeley Software Distribution (BSD) Unix-like operating system, known for its stability, security, and scalability, and is widely used in servers and networking devices.
Q11. What is Char Array?
A char array is a sequence of characters stored in contiguous memory, commonly used in languages like C, C++, Java, and C#. It holds letters, digits, symbols, and special characters, often representing strings. Char arrays are mutable and widely used for handling text-based data. In many cases, they are null-terminated (ending with '\0') to mark the end of the string, enabling functions to process them efficiently through operations like concatenation, comparison, and substring extraction.
Q12. Give two examples of strong AI that are widely used.
Two examples of widely used artificial intelligence in day-to-day life are:
-
Virtual Personal Assistants: Virtual personal assistants such as Amazon's Alexa, Apple's Siri, Google Assistant, and Microsoft's Cortana are examples of AI applications that use natural language processing (NLP) and machine learning techniques to understand and respond to voice commands from users. These virtual personal assistants can perform tasks such as setting reminders, answering questions, providing recommendations, controlling smart home devices, and more, making them widely used in many households and businesses.
-
Image Recognition and Computer Vision Systems: Image recognition and computer vision systems, powered by AI, are widely used in applications such as facial recognition, object detection, and image analysis. These systems are used in various industries, including healthcare, automotive, surveillance, e-commerce, and social media. For example, facial recognition technology is used for biometric authentication in smartphones, surveillance cameras, and access control systems. Image recognition and computer vision systems are also used in autonomous vehicles for object detection and recognition to enhance safety on the road.
Q13. Describe the main differences between the LocalStorage and SessionStorage objects in context of HTML.
The localStorage and sessionStorage objects are two client-side storage mechanisms provided by web browsers in HTML5 that allow web developers to store data locally on the user's device. Both localStorage and sessionStorage are part of the Web Storage API, and they share some similarities but also have some key differences in their behavior and usage:
-
Scope of Data: The main difference between
localStorageandsessionStorageis the scope of data storage.localStoragestores data persistently on the user's device, even after the browser or the device is closed, and the data remains available until it is explicitly cleared by the user or by the web application. On the other hand,sessionStoragestores data only for the duration of the user's session with the website. Once the user closes the browser or the session ends, the data stored insessionStorageis automatically cleared. -
Sharing Data Across Tabs/Windows: Another key difference is in how
localStorageandsessionStoragehandle data sharing across multiple tabs or windows of the same domain. Data stored inlocalStorageis shared across all tabs and windows of the same domain, meaning that any JavaScript code running in one tab or window can access and modify the data stored inlocalStorageand changes will be reflected in other tabs or windows as well. On the other hand,sessionStorageis limited to the scope of the individual tab or window. Data stored insessionStorageis not accessible to JavaScript code running in other tabs or windows of the same domain. -
Data Persistence: As mentioned earlier,
localStoragedata persists even after the browser or the device is closed, and the data remains available until it is explicitly cleared by the user or by the web application. In contrast,sessionStoragedata is only available for the duration of the user's session with the website and is automatically cleared when the session ends or the browser is closed. -
Storage Limitations: Both
localStorageandsessionStoragehave storage limitations imposed by the browser, typically ranging from several megabytes to tens of megabytes, depending on the browser and device. However, the specific storage limit can vary among different browsers and devices. -
Usage:
localStorageis typically used for storing data that needs to persist across multiple sessions, such as user preferences, settings, or cached data.sessionStorage, on the other hand, is commonly used for storing data that needs to be available only during the current session, such as temporary session data or data that needs to be isolated across different tabs or windows.
Q14. Name the operators that cannot be overloaded.
In C++, there are a few operators that cannot be overloaded. These operators include:
-
Scope Resolution Operator (::): This operator is used to specify the scope of a class or namespace in C++. It cannot be overloaded.
-
Member Selection Operator (.): This operator is used to access the members (data members or member functions) of an object in C++. It cannot be overloaded.
-
Pointer-to-Member Operator (->): This operator is used to access the members of an object through a pointer to an object in C++. It cannot be overloaded.
-
Conditional Operator (?): This is the ternary conditional operator used for conditional expressions. It cannot be overloaded.
-
Sizeof Operator (sizeof): This operator is used to determine the size of an object or data type in bytes in C++. It cannot be overloaded.
-
Typecast Operator (typeid): This operator is used to get the type information of an object or data type in C++. It cannot be overloaded.
-
Scope Resolution Operator (.*): This is a pointer-to-member operator used to access the members of an object through a pointer to an object in C++. It cannot be overloaded.
Q16. What are the advantages and disadvantages of time slicing in CPU Scheduling in OS?
Time slicing, also known as time-sharing, is a CPU scheduling technique used in operating systems where the CPU is divided into small time intervals called time slices or time quanta, and each process is allocated a certain amount of time to execute before being preempted and replaced by another process. Time slicing allows a task to run for a set amount of time before returning to the pool of ready tasks. Time slicing has several advantages and disadvantages in CPU scheduling.
Advantages of Time Slicing:
-
Fairness and equity: Time slicing ensures that each process gets a fair share of CPU time, regardless of its priority or resource requirements. This prevents any single process from monopolizing the CPU and promotes fairness among multiple processes running concurrently.
-
Responsive and interactive system: Time slicing allows for quick context switching between processes, resulting in a more responsive and interactive system. Processes can quickly get CPU time to execute their tasks slice by slice, leading to better user experience in interactive systems, such as multi-user systems or systems with GUI interfaces.
-
Efficient utilization of CPU: Time slicing helps in the efficient utilization of the CPU by keeping it busy and preventing idle time. Even short bursts of CPU usage by processes can be accommodated, making efficient use of available CPU resources.
-
Support for multitasking: Time slicing enables multitasking, allowing multiple processes to run concurrently slice by slice on a single CPU. This allows for the concurrent execution of multiple tasks, improving system productivity and resource utilization.
Disadvantages of Time Slicing:
-
Overhead: Time slicing introduces overhead in terms of context switching, which is the process of saving and restoring the state of processes when they are preempted and resumed. Context switching overhead can reduce the overall efficiency of the system and increase CPU utilization.
-
Increased complexity: Time slicing requires additional logic and bookkeeping in the operating system to manage the time slices, handle context switching, and maintain scheduling queues. This adds complexity to the scheduling algorithm and the operating system itself.
-
Impact on real-time and performance-critical tasks: In systems with real-time or performance-critical tasks, time slicing may not be ideal as it can introduce unpredictable delays and affect the timing requirements of such tasks. Time slicing may need to be carefully managed or disabled in such cases.
-
Lower throughput: Time slicing can result in lower throughput compared to other scheduling techniques, such as priority-based scheduling or scheduling based on CPU burst times. This is because time slices may be very small, leading to frequent context switches and overhead, which can impact overall system throughput.
Q17. What do you understand by the software development life cycle?
Software Development Life Cycle (SDLC) is a systematic approach or a series of phases followed during the development of software, from its inception to its deployment and maintenance. It outlines the various stages and activities involved in the development process and provides a structured framework for software development projects.
The common phases or stages of the SDLC are:
-
Requirements Gathering and Analysis: In this phase, the requirements for the software are identified, collected, and analyzed. This involves understanding the needs and expectations of stakeholders, documenting requirements, and creating a blueprint for the software.
-
Design: In this phase, the software is designed based on the requirements gathered in the previous phase. This includes creating detailed design specifications, architecture design, database design, and user interface design.
-
Coding: In this phase, the actual coding or programming of the software is done. Developers write the code based on the design specifications, coding standards, and best practices.
-
Testing: In this phase, the software is tested to ensure that it meets the specified requirements and functions correctly. This includes various types of testing, such as unit testing, integration testing, system testing, and acceptance testing.
-
Deployment: In this phase, the software is deployed or released for production use. This involves installing the software on the target environment, configuring it, and making it available to end-users.
-
Maintenance: After the software is deployed, it may require ongoing maintenance and support. This includes fixing bugs, making updates or enhancements, and addressing issues that arise during the usage of the software.
-
Documentation: Throughout the SDLC, documentation is created to capture various aspects of the software, such as requirements, design, testing, and deployment. Proper documentation helps in understanding and maintaining the software over period of time.
The SDLC provides a structured approach to software development, helping to ensure that software is developed in a systematic and organized manner, meeting the requirements of stakeholders, and delivering a high-quality, reliable, and maintainable software product. Different SDLC models, such as Waterfall, Agile, Scrum, and DevOps, have different variations of these phases and may have different approaches to software development, depending on the project requirements and development methodology followed.
Q18. What are the differences between error and exception in Java?
| Criteria | Errors | Exceptions |
|---|---|---|
| Definition | Errors are unforeseen, critical problems that usually occur at runtime and are caused by factors such as system failures, hardware issues, or severe programming mistakes. | Exceptions are abnormal conditions or events that occur during the execution of a program and disrupt the normal flow of the program's execution and can be handled using try-catch blocks. |
| Type | Errors are classified as unchecked type exceptions, which means they are not required to be caught or handled by the programmer. | Exceptions are classified as either checked exceptions or unchecked type exceptions. Checked exceptions must be caught or declared in the method signature, while unchecked exceptions are not required to be caught or declared. |
| Impact | Errors usually result in termination of the program, as they indicate severe issues that cannot be recovered from. | unchecked exceptions can be caught and handled in the program, allowing for potential recovery or graceful degradation of the program's functionality. |
| Causes | Errors are typically caused by factors outside the control of the program, such as system failures or hardware issues. | Checked and unchecked exceptions are typically caused by factors within the control of the program, such as incorrect input, invalid operations, or unexpected conditions. |
| Handling | Errors are generally not handled by the programmer, as they usually require system-level or hardware-level interventions. | Exceptions are meant to be caught and handled by the programmer, either locally or propagated to higher levels of the program for appropriate handling. |
| Examples | Examples of errors include OutOfMemoryError, StackOverflowError, and VirtualMachineError. | Examples of exceptions include NullPointer IOException Unchecked, ArrayIndexOutOfBoundsException, and IOException Unchecked. |
Q19. Differentiate between strings and char arrays in Java.
Here are the main differences between strings and char arrays in Java:
| Criteria | Strings | Char Arrays |
|---|---|---|
| Data type | String is a class in Java's standard library and represents a sequence of characters as a single data type. | Char array is a primitive array type in Java and represents an array of char data types. |
| Mutable/Immutable | Strings are immutable, meaning the single data type values cannot be changed once they are created. Any modifications to a string result in a new string object being created. | Char data types arrays are mutable, meaning their values can be changed directly by modifying the elements in the array. |
| Length | String objects have a dynamic length, and their length can be obtained using the length() method. |
Char arrays have a fixed length, which is determined at the time of array creation and cannot be changed. |
| Syntax | Strings are enclosed in double quotes ("...") and can be written directly as a sequence of characters. | Char arrays are declared using square brackets ("[ ]") and initialized with a sequence of characters enclosed in single quotes ('...'). |
| Functions and methods | Strings have many built-in methods in Java's String class for string manipulation, such as substring, concatenation, and searching. | Char arrays have fewer built-in methods compared to strings, as they are primitive arrays and do not have the extensive methods available in the String class. |
| Memory management | String objects are managed by Java's String Pool, which is a special area of memory where string literals are stored and shared to conserve memory. | Char arrays are regular arrays in Java and are stored in the heap or the stack, depending on how they are created and used. |
| Nullability | Strings in Java can be null, meaning they can have a value of null to indicate the absence of a string object. |
Char arrays in Java cannot be null, as they are primitive arrays and cannot have a value of null. |
| Conversion | Strings can be converted to char arrays using the toCharArray() method of the String class. |
Char arrays can be converted to strings using the String(char[]) constructor or by passing them to the String.valueOf(char[]) method. |
It's important to understand the differences between strings and char arrays in Java and choose the appropriate one based on the requirements of your program. Strings are typically used for representing text that needs to be manipulated or processed in various ways, while char arrays are used for representing sequences of characters that need to be mutable or directly manipulated at the character level.
Q20. What is a delete operator in C++?

In C++, the delete operator is used to deallocate memory that was previously allocated using the new operator. It is used to explicitly release the memory allocated on the heap for objects or arrays to prevent memory leaks and manage memory dynamically. The syntax for using the delete operator in C++ is as follows:
delete pointer;
where the pointer is a pointer to the memory that was previously allocated using the new operator. The delete operator frees the memory associated with the object or array pointed to by the pointer and returns it back to the system. It's important to note that the delete operator should only be used to deallocate memory that was previously allocated using the new operator. Using delete on a pointer that was not allocated with new can result in undefined behavior, including crashes or memory corruption. Additionally, using delete on a pointer that has already been deleted or is a null pointer can also lead to errors. Therefore, it's crucial to use delete correctly and always pair it with a corresponding new operator to ensure proper memory management in C++ programs.
Q21. Explain copy constructor vs assignment operator in C++.

In C++, both the copy constructor and assignment operator are used to create or assign objects of a class. However, they differ in their functionality and usage.
Copy Constructor: A copy constructor is a special constructor that creates a new object by copying the contents of an existing object of the same class. It is invoked automatically when a new object is initialized with an existing object of the same class, or when an object is passed by value as a function argument, or when an object is returned by value from a function. The copy constructor is typically used for creating a deep copy of an object, which means that new memory is allocated for the copied object, and the contents of the original object are duplicated in the new object.
Syntax of a copy constructor in C++:
ClassName(const ClassName& other) {
// Copy the contents of 'other' object to the new object.
// Typically involves deep copying of data members.
}
Assignment Operator: The assignment operator, also known as the assignment operator overload, is a member function that assigns the contents of one object to another object of the same class. It is called when an object is assigned a new value using the assignment operator (=). It is typically used for modifying an existing object's value rather than creating a new object.
Syntax of an assignment operator in C++:
ClassName& operator=(const ClassName& other) {
// Assign the contents of 'other' object to the current object.
// Typically involves shallow copying of data members and freeing any
// resources that the current object may hold.
return *this; // Return a reference to the current object
}
Q22. What are the differences between an object-oriented and object-based language?
The main difference between an object-oriented and object-based language is that Object-oriented languages have no built-in objects, but object-based languages have them. JavaScript, for example, has a built-in window object.
Other differences are as follows:
-
Class vs. Prototype: In Object-oriented languages, classes are used to define the blueprint of objects, which are then instantiated to create objects. Objects are instances of classes and inherit properties and behavior from the class. In Object-based languages, there are no classes, but objects are created from prototypes, which are objects that serve as a template for creating new objects. Objects in Object-based language do not inherit from prototypes but rather copy the properties and behavior from the prototype.
-
Inheritance: Object-oriented languages generally support a rich inheritance model, where classes can inherit properties and behavior from other classes, allowing for program code reuse and promoting a hierarchical organization of program code that lack built-in window object. Object-based languages, on the other hand, often do not support inheritance or support limited forms of inheritance, such as delegation, where objects can delegate tasks to other objects, but do not inherit properties or behavior from other objects.
-
Encapsulation: Object-oriented language emphasizes encapsulation, which is the bundling of data and methods (functions) that operate on the data into a single unit called a class. Objects created from the class can then access and modify the data using methods. OBP languages may not have strict encapsulation, and data and methods may be directly accessed and modified by objects.
-
Polymorphism: Object-Oriented Programming languages typically support polymorphism but lack built-in objects, where objects of different classes can be treated as if they belong to a common type or interface, allowing for the interchangeable use of objects. Object-based languages may not support polymorphism, as there may not be a strict type or interface system.
Examples of popular Object-oriented languages include Java, C++, and Python. Examples of object-based languages include JavaScript and Lua, which support object-oriented features but have differences in how they handle inheritance, encapsulation, and polymorphism.
Q23. What do you understand about Stack Unwinding in C++?
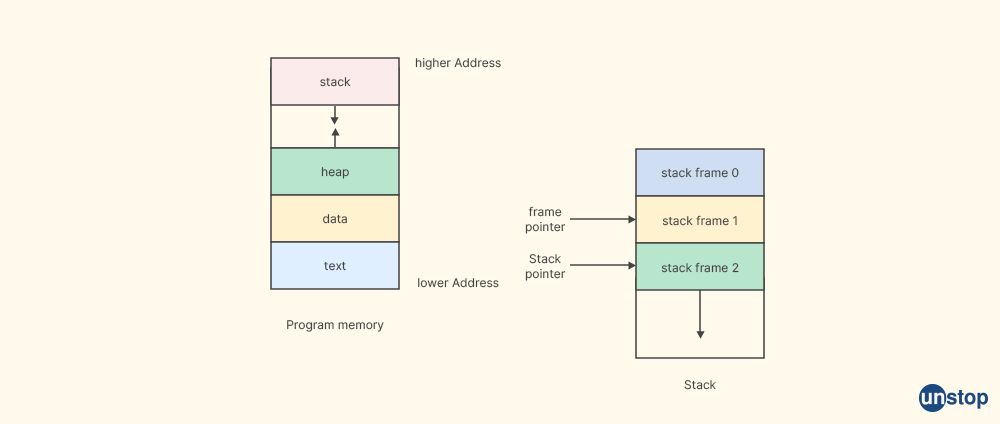
Stack unwinding is a process that occurs in C++ when an exception is thrown and not caught by an appropriate exception handler. It involves the orderly removal of objects and function entries that were created on the stack (i.e., local variables) in the reverse order of their construction until an appropriate exception handler is found or the program terminates. Stack Unwinding is the process of eliminating function entries from the function call stack at runtime.
In C++, when an exception is thrown, the normal flow of program execution is interrupted, and the C++ runtime system starts unwinding the stack, which means it begins to destruct objects and built-in function entries that were created on the stack in the current scope and in the call stack above the point where the exception was thrown. This process continues until an appropriate exception handler, specified by a catch block, is found, or until the stack is completely unwound if no appropriate handler is found. If the stack is unwound completely without finding an appropriate handler, the program terminates with an error message.
Stack unwinding is important for ensuring proper resource cleanup and preventing resource leaks, such as deallocating memory, releasing file handles, or closing database connections. C++ provides support for stack unwinding through destructors, which are special member built-in functions of classes that are automatically called when objects go out of scope, either due to normal program flow or due to stack unwinding during exception handling.
It's important to properly handle exceptions and ensure proper cleanup of resources to prevent memory leaks and other issues in C++ programs. This can be done using try-catch blocks to catch and handle exceptions, or by using RAII (Resource Acquisition Is Initialization) techniques, where resource cleanup is tied to the lifetime of objects using destructors, to ensure that resources are properly released even in the presence of exceptions and stack unwinding.
Q24. What are the different objects in DBMS?
In a database management system (DBMS), there are several different types of objects that are used to organize and store data. These objects are defined by the DBMS and provide the structure and functionality for managing data in a database. Some common objects in a DBMS include:
-
Tables: Tables are the most basic and common objects in a DBMS. They are used to store data in rows and columns, organized in a tabular format. Tables represent entities or concepts in the real world and are used to store data in a structured manner. Each table has a defined schema, which specifies the columns (also called fields or attributes) and their data types.
-
Views: Views are virtual tables that are defined by a query on one or more tables in the database. They provide a way to define and store a specific query or a subset of data from one or more tables as a virtual table. Views are used to simplify data access, provide data security, and encapsulate complex queries.
-
Indexes: Indexes are used to improve the performance of database queries by providing a fast access path to data. Indexes are data structures that are built on one or more columns of a table, and they allow for faster data retrieval based on the indexed columns. Common types of indexes include B-tree, hash, and bitmap indexes.
-
Stored Procedures: Stored procedures are database objects that encapsulate a set of SQL statements and are stored in the database for later execution. Stored procedures are typically used to encapsulate complex business logic, perform data manipulation or validation, and provide a way to modularize database functionality.
-
Triggers: Triggers are special types of stored procedures that are automatically executed in response to specific events, such as data changes (insert, update, delete) in a table. Triggers are used to enforce referential integrity, enforce business rules, and automate database actions based on events.
-
Sequences: Sequences are database objects that generate unique numeric values, typically used as primary key values in tables. Sequences provide a way to generate unique identifiers that are typically used for primary keys, without having to rely on auto-incrementing columns or other mechanisms.
-
Synonyms: Synonyms are database objects that provide an alternative name or alias for a table, view, sequence, or another database object. Synonyms are used to simplify object naming, provide abstraction, and improve security by allowing users to access objects with alternative names.
Q25. What is the difference between abstract classes and interfaces?
Abstract classes and interfaces are both important concepts in object-oriented programming, and they have some similarities and differences. While both provide a way to define a set of methods that a class must implement, abstract classes can also include implementation details and states, whereas interfaces contain only method signatures. Abstract classes are also used to define a class hierarchy, while interfaces are used for polymorphic behavior.
| Abstract Class | Interface |
|---|---|
| Contains state and behavior | Contains only method signatures |
| Can contain both abstract and non-abstract methods | Contains only abstract methods |
| Cannot be instantiated directly | Cannot be instantiated directly |
| Can be extended using inheritance | Can be implemented by any class |
| Can be used to define common behavior for a group of related classes | Can be used to define common behavior for unrelated classes |
| Provides a partial implementation of a class | Defines a contract that a class must implement |
| Can have constructors and destructors | Cannot have constructors or destructors |
| Can have access modifiers for its methods and properties | All methods are public and abstract by default |
| Used when creating a class hierarchy | Used for implementing polymorphic behavior |
Q26. What is the logic behind the reverse of a string in Java?

The logic behind reversing a string in Java typically involves iterating through the characters of the string and swapping the characters from the beginning and the end of the string until the entire string is reversed. Here's a step-by-step logic for reversing a string in Java:
- Convert the string to a character array for easier manipulation.
- Initialize two pointers, one at the beginning of the array (index 0) and one at the end of the array (index length-1).
- Swap the characters at the start and end pointers using a temporary variable, and then move the start pointer towards the end and the end pointer towards the start.
- After the loop completes, the characters in the charArray will be reversed.
- Convert the charArray back to a string using the String constructor that takes a char array as an argument.
Here's a sample Java code snippet that implements this logic:
public class StringReversal {
public static void main(String[] args) {
String inputString = "Hello World!";
String reversedString = reverseString(inputString);
System.out.println("Reversed String: " + reversedString);
}
public static String reverseString(String inputString) {
char[] charArray = inputString.toCharArray();
int start = 0;
int end = inputString.length() - 1;
while (start < end) {
char temp = charArray[start];
charArray[start] = charArray[end];
charArray[end] = temp;
start++;
end--;
}
return new String(charArray);
}
}
cHVibGljIGNsYXNzIFN0cmluZ1JldmVyc2FsIHsKcHVibGljIHN0YXRpYyB2b2lkIG1haW4oU3RyaW5nW10gYXJncykgewpTdHJpbmcgaW5wdXRTdHJpbmcgPSAiSGVsbG8gV29ybGQhIjsKU3RyaW5nIHJldmVyc2VkU3RyaW5nID0gcmV2ZXJzZVN0cmluZyhpbnB1dFN0cmluZyk7ClN5c3RlbS5vdXQucHJpbnRsbigiUmV2ZXJzZWQgU3RyaW5nOiAiICsgcmV2ZXJzZWRTdHJpbmcpOwp9CgpwdWJsaWMgc3RhdGljIFN0cmluZyByZXZlcnNlU3RyaW5nKFN0cmluZyBpbnB1dFN0cmluZykgewpjaGFyW10gY2hhckFycmF5ID0gaW5wdXRTdHJpbmcudG9DaGFyQXJyYXkoKTsKaW50IHN0YXJ0ID0gMDsKaW50IGVuZCA9IGlucHV0U3RyaW5nLmxlbmd0aCgpIC0gMTsKCndoaWxlIChzdGFydCA8IGVuZCkgewpjaGFyIHRlbXAgPSBjaGFyQXJyYXlbc3RhcnRdOwpjaGFyQXJyYXlbc3RhcnRdID0gY2hhckFycmF5W2VuZF07CmNoYXJBcnJheVtlbmRdID0gdGVtcDsKc3RhcnQrKzsKZW5kLS07Cn0KCnJldHVybiBuZXcgU3RyaW5nKGNoYXJBcnJheSk7Cn0KfQ==
Q27. What is DOM?
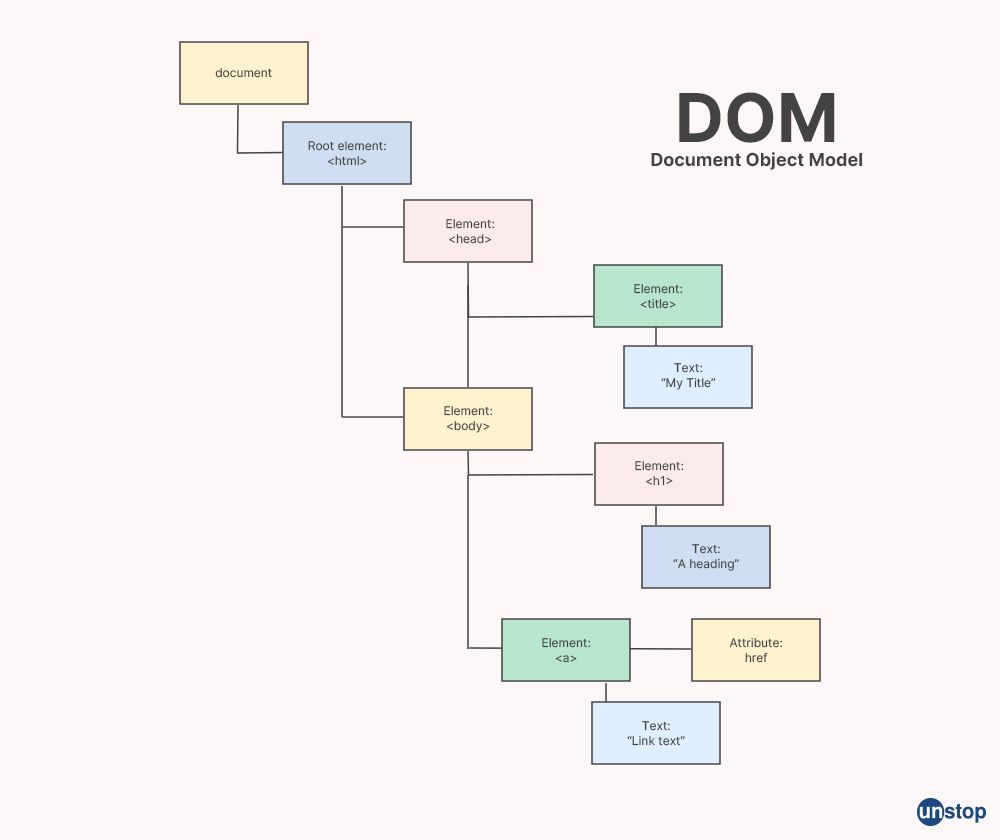
DOM stands for Document Object Model. It is a programming interface for web documents that represents the structure of an HTML or XML document as a tree of objects, where each object represents a part of the document, such as an element, an attribute, or a piece of text. DOM provides a standardized way to interact with web documents, allowing developers to manipulate the content, structure, and presentation of web pages dynamically.
DOM is typically used in client-side web development with scripting languages like JavaScript to dynamically manipulate web pages. It provides a set of methods and properties that allow developers to traverse and manipulate the tree-like structure of a document, including adding, modifying, or deleting elements and attributes, changing text content, and applying styles. DOM enables dynamic content creation, event handling, and interactivity in web pages, allowing developers to build rich and interactive web applications.
The DOM tree is created by the web browser when it loads an HTML or XML document, and it represents the current state of the document in the browser's memory. Changes made to the DOM tree are reflected in the rendered web page, allowing developers to create dynamic and interactive web applications that respond to user actions, update content, and modify the layout and appearance of web pages. DOM is an important concept in web development and is widely supported in modern web browsers, making it a fundamental tool for building web applications.
Q28. What are the benefits of Hybrid Clouds in Cloud Computing?
Hybrid cloud computing is a model that combines both private cloud and public cloud environments, allowing organizations to leverage the benefits of both in a flexible and scalable manner. Here are some benefits of hybrid clouds in cloud computing:
-
Flexibility: Hybrid clouds provide organizations with the flexibility to choose the best deployment model for their applications and workloads. The private cloud offers security and control for sensitive data and critical applications, while the public cloud provides scalability and cost-effectiveness for less sensitive workloads. Organizations can dynamically move workloads between private and public clouds based on their needs, allowing them to optimize resource utilization and cost efficiency.
-
Scalability: Hybrid clouds enable organizations to leverage the scalability of public cloud resources to handle peak workloads or sudden spikes in demand. This allows organizations to avoid over-provisioning their private cloud resources, resulting in cost savings and improved performance. Workloads can be seamlessly moved from private to public cloud and vice versa, providing on-demand scalability without the need for major infrastructure changes.
-
Cost Optimization: Hybrid clouds allow organizations to balance their IT costs by utilizing the cost-effective public cloud for non-critical workloads and sensitive data in the private cloud. Organizations can also take advantage of cloud bursting, where applications run in the private cloud but can scale into the public cloud during peak demand, reducing the need for additional private cloud resources. This helps optimize costs by paying for only the resources that are needed at a given period of time.
-
Security and Compliance: Hybrid clouds provide organizations with the ability to keep sensitive data and critical applications in the private cloud, which can offer higher levels of security, compliance, and control compared to the public cloud. This is especially important for industries with strict regulatory requirements, such as finance, healthcare, and government. Organizations can also implement security measures and compliance policies consistently across both private and public cloud environments, ensuring data protection and compliance with regulatory standards.
-
Agility and Innovation: Hybrid clouds enable organizations to quickly deploy and manage applications across different cloud environments, allowing for faster time-to-market and improved agility. Organizations can take advantage of the latest cloud-based technologies, services, and innovations from the public cloud, while also leveraging their existing investments in on-premises infrastructure. This provides opportunities for experimentation, innovation, and business agility, allowing organizations to stay competitive in the rapidly evolving digital landscape.
-
Disaster Recovery and Business Continuity: Hybrid clouds provide organizations with the ability to implement robust disaster recovery and business continuity strategies. Critical data and applications can be replicated and backed up in multiple cloud environments, providing redundancy and resilience. In case of an outage or disaster in one cloud environment, workloads can be quickly and seamlessly shifted to another cloud environment, ensuring business continuity and minimizing downtime.
Q29. What is polymorphism?
Polymorphism is a concept in object-oriented programming (OOPs) that allows objects of different classes to be treated as if they belong to a common type or interface. In other words, polymorphism allows objects of different types to be used interchangeably, as long as they share a common interface or have compatible behavior.
Polymorphism provides a level of abstraction and flexibility in object-oriented programming, allowing for code reusability and extensibility. It allows programmers to write more generic and flexible code that can operate on a variety of objects, without having to write code for each specific object type.
There are two main types of polymorphism:
-
Compile-time polymorphism (also known as static polymorphism or method overloading): In compile-time polymorphism, the compiler determines which version of a method or function to call based on the number or type of arguments passed to it. This is determined during the compilation phase of the program. Method overloading is an example of compile-time polymorphism, where multiple methods with the same name but different parameter lists are defined in the same class.
-
Run-time polymorphism (also known as dynamic polymorphism or method overriding): In run-time polymorphism, the method or function to be called is determined at runtime based on the actual type of the object that the method is called on. This allows objects of different classes to share a common interface and have their own implementations of the same method. Method overriding, where a subclass provides a new implementation of a method that is already defined in its superclass, is an example of run-time polymorphism.
Q30. Write a C program for Fibonacci series.
Here's a simple C program to generate the Fibonacci series up to a given number:
#include
int main() {
int num, i, term1 = 0, term2 = 1, nextTerm;
printf("Enter the number of terms: ");
scanf("%d", &num);
printf("Fibonacci Series: ");
for (i = 1; i <= num; ++i) {
printf("%d, ", term1);
nextTerm = term1 + term2;
term1 = term2;
term2 = nextTerm;
}
return 0;
}
I2luY2x1ZGUgPHN0ZGlvLmg+CgppbnQgbWFpbigpIHsKaW50IG51bSwgaSwgdGVybTEgPSAwLCB0ZXJtMiA9IDEsIG5leHRUZXJtOwoKcHJpbnRmKCJFbnRlciB0aGUgbnVtYmVyIG9mIHRlcm1zOiAiKTsKc2NhbmYoIiVkIiwgJm51bSk7CgpwcmludGYoIkZpYm9uYWNjaSBTZXJpZXM6ICIpOwoKZm9yIChpID0gMTsgaSA8PSBudW07ICsraSkgewpwcmludGYoIiVkLCAiLCB0ZXJtMSk7Cm5leHRUZXJtID0gdGVybTEgKyB0ZXJtMjsKdGVybTEgPSB0ZXJtMjsKdGVybTIgPSBuZXh0VGVybTsKfQoKcmV0dXJuIDA7Cn0=
This program takes input from the user for the number of terms to generate in the Fibonacci series. It then uses a for loop to generate and print the Fibonacci series up to the given number of terms. The program uses three variables - term1, term2, and nextTerm - to keep track of the current term, the next term, and the term to be printed, respectively. The series starts with 0 and 1, and each subsequent term is the sum of the two previous terms, as per the Fibonacci sequence definition.
Q31. List the important functionalities/features of an operating system.
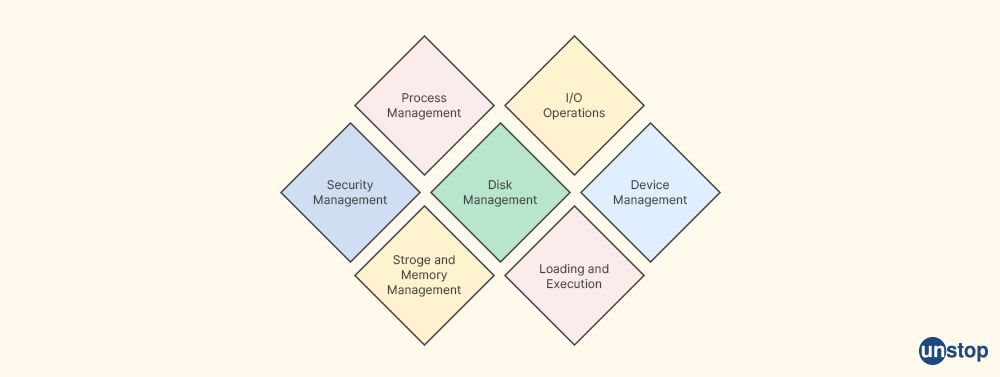
Operating systems are complex software that manages computer hardware and complete software resources, and provide an interface for users and applications to interact with the computer system. Some of the important functionalities/features of an operating system include:
-
Process management: Managing the creation, execution, scheduling, and termination of processes (programs) running on the computer system, including managing process priorities, inter-process communication, and synchronization.
-
Memory management: Managing the allocation and deallocation of system memory to processes, including virtual memory management, paging, swapping, and memory protection and central processing unit time.
-
File system management: Providing a hierarchical structure for organizing and storing files and directories, managing file access, permissions, and file I/O operations.
-
Device management: Managing the interaction with various input/output devices, including drivers, interrupt handling, and device scheduling.
-
User interface: Providing a user-friendly interface for users to interact with the computer system, including command-line interfaces, graphical user interfaces (GUI), and other user experience (UX) features.
-
Security and access control: Ensuring the integrity, confidentiality, and availability of system resources, managing user authentication, authorization, and access control to prevent unauthorized access and data breaches.
-
Networking and communication: Providing support for networking and communication protocols, managing network connections, and facilitating data transfer between different systems over a network.
-
File and data management: Managing the organization, storage, retrieval, and manipulation of data, including file systems, databases, and data caching.
-
System monitoring and performance management: Monitoring system performance, resource utilization, and system health, and managing system resources efficiently to optimize performance and reliability.
-
Error handling and fault tolerance: Detecting, handling, and recovering from system errors, exceptions, and failures to ensure system stability and fault tolerance.
-
Software and application management: Managing software installation, updates, and removal, and providing a platform for running applications and managing their resources.
-
Backup and recovery: Providing mechanisms for system backup and recovery to protect against data loss and system failures.
Q32. What are the advantages of a thread? What does multithreading look like?
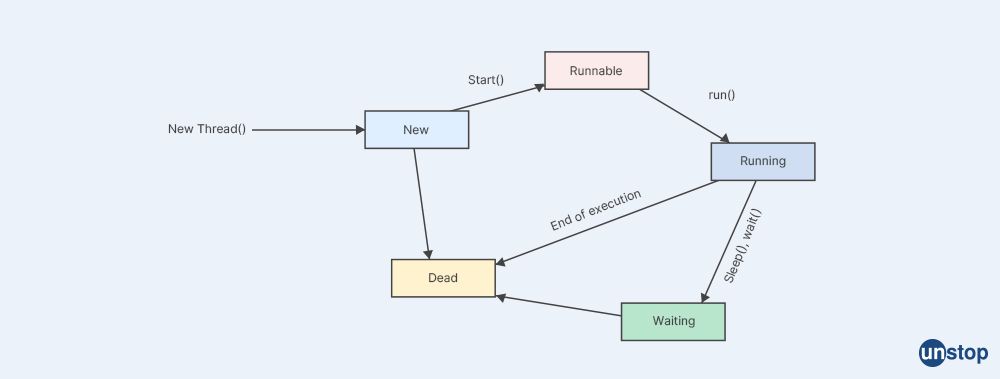
Threads are lightweight sub-process, the smallest units of processing within a process that share the same memory space, allowing them to communicate and interact with each other more efficiently than separate processes. Here are some advantages of using threads in a multithreaded application:
-
Improved parallelism: Threads can execute tasks concurrently, allowing for improved parallelism and efficient utilization of CPU resources and units of processing. This can lead to the faster and more efficient execution of tasks, especially in applications that involve multiple independent tasks that can be performed concurrently.
-
Enhanced responsiveness: Threads can be used to perform time-consuming or blocking operations in the background, allowing the main thread or user interface thread to remain responsive and interact with users or handle other tasks without being blocked.
-
Resource sharing: Threads within a process can share the same memory space, which allows for efficient communication and sharing of data between threads without the need for expensive inter-process communication (IPC) mechanisms. This can lead to more efficient memory utilization and reduced overhead in data sharing.
-
Simplified program structure: Using threads can simplify the structure of a program by allowing for more modular and organized code. Threads can be used to separate different tasks or functionalities of an application into separate threads, making the code more manageable and easier to maintain.
-
Scalability: Threads can help improve the scalability of an application by allowing it to efficiently utilize multi-core processors and take advantage of modern multi-core architectures, leading to improved performance and responsiveness.
Multithreading typically involves creating multiple threads within a single process, each of which can run concurrently and independently, sharing the same memory space. Threads can be managed and scheduled by the operating system or by the application itself using threading libraries or frameworks. Threads can communicate with each other by sharing memory or using synchronization mechanisms like mutexes, semaphores, and condition variables to ensure proper coordination and data integrity.
However, care must be taken to avoid issues like race conditions, deadlocks, and other concurrency-related problems when using multithreading in an application. Proper thread synchronization techniques and programming practices must be followed to ensure the correct and reliable behavior of multithreaded applications.
Q33. How do the commands DROP, TRUNCATE, and DELETE differ in SQL?
Here is a comparison table that highlights the differences between the SQL commands DROP, TRUNCATE, and DELETE:
| Command | Purpose | Description | Impact on Data | Transactional | Example |
|---|---|---|---|---|---|
| DROP | Deletes a database object | Deletes an entire database object, such as a table, view, or database itself | Irreversible, permanently removes the object and all its data | No | DROP TABLE employees; |
| TRUNCATE | Removes all data from a table | Deletes all rows from a table while retaining the structure and metadata of the table | Irreversible, permanently removes all data from the table, but retains the table structure and metadata | No | TRUNCATE TABLE employees; |
| DELETE | Removes specific rows from a table | Deletes specific rows from a table based on a condition | Reversible, only removes the specified rows, leaving other rows and table structure intact | Yes, can be part of a transaction | DELETE FROM employees WHERE age < 30; |
Here's a brief explanation of each command:
-
DROP: This command is used to permanently delete an entire database object, such as a table, view, or database itself. The object and all its data are irreversibly deleted. This command is not transactional, and the deleted data cannot be recovered. Example:
DROP TABLE employees;to delete the "employees" table. -
TRUNCATE: This command is used to remove all data from a table while retaining the structure and metadata of the table. The table structure, indexes, and metadata remain intact, but all data in the table is permanently deleted. This command is not transactional, and the deleted data cannot be recovered. Example:
TRUNCATE TABLE employees;to delete all data from the "employees" table. -
DELETE: This command is used to remove specific rows from a table based on a condition. The rows that match the condition are deleted, but the table structure, metadata, and other rows remain intact. This command is transactional, and it can be used as part of a larger transaction. Deleted data can be recovered if used within a transaction. Example:
DELETE FROM employees WHERE age < 30;to delete all rows from the "employees" table where the "age" column is less than 30.
Q34. What is EUCALYPTUS in cloud computing? List some of its functionalities.
EUCALYPTUS (Elastic Utility Computing Architecture for Linking Your Programs To Useful Systems) is an open-source cloud computing platform that provides an Infrastructure as a Service (IaaS) solution for building private and hybrid clouds. EUCALYPTUS allows organizations to create and manage their own cloud computing environment on their own hardware, providing a scalable and customizable cloud infrastructure for deploying and managing virtual machines (VMs) and other cloud resources. Some of the functionalities of EUCALYPTUS include:
-
Virtual machine management: EUCALYPTUS provides tools and APIs for creating, managing, and monitoring virtual machines (VMs) in a cloud environment. It supports popular hypervisors such as KVM, Xen, and VMware, allowing users to create and manage VMs with different operating systems and configurations.
-
Networking: EUCALYPTUS allows users to configure and manage virtual networks within the cloud environment. It provides features like virtual network segmentation, IP address management, and network security settings, allowing users to create and manage custom network topologies for their applications.
-
Storage management: EUCALYPTUS provides storage management capabilities, including block storage and object storage. Users can create and manage virtual disks for VMs, and also use object storage for storing and retrieving data objects in the cloud.
-
Security: EUCALYPTUS includes features for securing the cloud environment, such as user authentication and authorization, SSL encryption for communication, and integration with existing authentication systems like LDAP and Active Directory. It also provides tools for managing access controls, firewall settings, and security groups for VMs.
-
Elasticity and scalability: EUCALYPTUS allows users to dynamically scale their cloud environment by adding or removing resources based on demand. It provides auto-scaling features that automatically adjust the number of VMs based on predefined rules, allowing users to efficiently manage resources and optimize performance.
-
Hybrid cloud support: EUCALYPTUS allows organizations to build hybrid clouds by integrating with public cloud platforms like Amazon Web Services (AWS). This allows users to seamlessly migrate workloads between their private EUCALYPTUS cloud and public cloud, providing flexibility and scalability.
Q35. What do you understand about RAID in the context of Project Management?
In the context of Project Management, RAID stands for Risks, Assumptions, Issues, and Dependencies. RAID is a commonly used acronym to categorize and track project-related risks, assumptions, issues, and dependencies. RAID is used as a project management tool to proactively identify, assess, and manage potential risks and issues that may impact the successful completion of a project.
Here's what each component of RAID represents:
-
Risks: Risks are events or situations that may occur during the project lifecycle that can have a negative impact on the project's objectives. Risks may include potential problems, obstacles, uncertainties, or vulnerabilities that could affect project deliverables, timelines, costs, or quality. Risks are identified, assessed, and managed using risk management techniques, and appropriate risk mitigation strategies are put in place to minimize their impact on the project.
-
Assumptions: Assumptions are statements or conditions that are considered to be true, but have not been fully verified or validated. Assumptions are made during the project planning phase and are used as a basis for estimating resources, developing schedules, and making decisions. Assumptions should be documented and regularly reviewed to ensure that they still hold true throughout the project lifecycle, and any changes or deviations from assumptions should be addressed accordingly.
-
Issues: Issues are problems or challenges that arise during the course of the project that need to be addressed and resolved. Issues may include deviations from planned activities, unexpected events, conflicts, or obstacles that require attention and resolution to keep the project on track. Issues are typically logged, prioritized, and addressed in a timely manner to minimize their impact on project progress and outcomes.
-
Dependencies: Dependencies are relationships between project tasks, activities, or deliverables that are dependent on each other. Dependencies may include sequential or parallel relationships, where the completion of one single task or activity is dependent on the completion of another. Dependencies should be identified and managed to ensure that project tasks are completed in the right sequence and that any delays or changes in dependencies are properly communicated and addressed.
Q36. What is the use of a CSS preprocessor? When should a pre-processor be utilized in a project, according to you?
A CSS preprocessor is a scripting language that extends the capabilities of standard CSS (Cascading Style Sheets) by providing additional features, such as variables, nested rules, functions, and mixins, which help to streamline and optimize the process of writing and maintaining CSS code. CSS preprocessors like Sass, Less, and Stylus are widely used in web development projects to enhance the productivity and maintainability of CSS code.
Here are some key benefits of using a CSS preprocessor in a web development project:
-
Code organization and modularity: CSS preprocessors allow for better organization and modularity of CSS code through features like nested rules, variables, and mixins. This makes it easier to manage and maintain large and complex CSS codebases, as the code can be structured in a more modular and reusable way.
-
Reusability and maintainability: CSS preprocessors facilitate the creation of reusable code components through the use of mixins and functions. This allows for the creation of consistent styles across a project, making it easier to maintain and update the styles as needed.
-
Productivity and efficiency: CSS preprocessors enable the use of advanced features like variables, which can significantly reduce the amount of redundant code that needs to be written and maintained. This can result in increased productivity and faster development cycles, as changes can be made in one place and propagated throughout the project.
-
Dynamic and powerful styling capabilities: CSS preprocessors offer advanced features like conditionals, loops, and mathematical operations, which provide more dynamic and powerful styling capabilities. This allows for more flexibility in creating responsive designs, theming, and other dynamic styling requirements.
-
Browser compatibility: CSS preprocessors generate standard CSS code that is compatible with all modern browsers. The preprocessor code is compiled into standard CSS during the build process, ensuring that the resulting CSS code is supported across different browsers.
Q37. What is SQL Profiler?
SQL Profiler is a tool in Microsoft SQL Server that allows developers, database administrators, and other stakeholders to capture, analyze, and monitor the SQL Server Database Engine activity in real-time or from saved trace files. It provides detailed information about the SQL Server performance, query execution, and other database activities, allowing for in-depth analysis of SQL Server behavior.
SQL Profiler allows users to create and customize traces to capture specific events and data related to SQL Server activities. Some of the important functionalities of SQL Profiler include:
-
Capturing SQL Server events: SQL Profiler can capture a wide range of SQL Server events, such as SQL queries, stored procedure executions, database backups, login/logout events, and more. This allows users to analyze the performance and behavior of SQL Server in real-time or from saved trace files.
-
Filtering and sorting trace data: SQL Profiler provides options to filter and sort the captured trace data based on various criteria, such as database name, user name, duration, event type, and more. This allows users to focus on specific events or activities of interest and analyze them in detail.
-
Customizing trace templates: SQL Profiler allows users to create custom trace templates with specific events, data columns, and filters to capture the desired information. This enables users to tailor the trace to their specific requirements and capture only the relevant data.
-
Analyzing query performance: SQL Profiler provides detailed information about the execution of SQL queries, including the query text, execution time, query plans, and resource usage. This allows users to analyze the performance of SQL queries and identify any potential performance bottlenecks or optimization opportunities.
-
Monitoring real-time activity: SQL Profiler can capture SQL Server activity in real-time, allowing users to monitor the performance and behavior of SQL Server in real time and quickly identify any issues or anomalies.
Q38. What is the use of IP address?
An IP (Internet Protocol) address is a unique numerical label assigned to devices, such as computers, servers, and other network-enabled devices, that are connected to the Internet. IP addresses serve two main purposes:
-
Identifying and Locating Devices: IP addresses are used to uniquely identify devices on a network, allowing them to send and receive data to and from other devices on the Internet. Just like a physical address helps identify the location of a building, an IP address helps identify the location of a device on the Internet. IP addresses are essential for routing data packets across the Internet so that they reach their intended destination.
-
Enabling Communication: IP addresses are used for communication between devices over the Internet. When you send an email, browse a website, or stream a video, data packets containing the information are sent over the Internet using IP addresses as the source and destination addresses. IP addresses enable devices to send and receive data, facilitating communication and information exchange on the Internet.
Q39. Is XML case-sensitive?
Yes, XML (eXtensible Markup Language) is case-sensitive. This means that XML distinguishes between uppercase and lowercase letters in element names, attribute names, and other XML markup.
For example, in XML, the following are considered different:
<elementName>Some content</elementName>
<elementname>Some content</elementname>
<ELEMENTNAME>Some content</ELEMENTNAME>
All three examples are treated as distinct XML elements because they have different letter casing in their element names. XML parsers and processors are designed to be case-sensitive by default, so they will treat these as separate elements with potentially different meanings or behaviors.
It's important to be consistent with letter casing when working with XML documents to ensure that elements, attributes, and other markup are properly recognized and processed according to the intended XML structure and semantics.
Q40. How can you sort the elements of the array in descending order?
Sorting elements in an array in descending order can be achieved using various algorithms. Here's an example of how you can sort an array of numbers in descending order using a simple selection sort algorithm in Python:
def selection_sort_descending(arr):
n = len(arr)
for i in range(n-1):
max_idx = i
for j in range(i+1, n):
if arr[j] > arr[max_idx]:
max_idx = j
arr[i], arr[max_idx] = arr[max_idx], arr[i]
return arr
ZGVmIHNlbGVjdGlvbl9zb3J0X2Rlc2NlbmRpbmcoYXJyKToKbiA9IGxlbihhcnIpCmZvciBpIGluIHJhbmdlKG4tMSk6Cm1heF9pZHggPSBpCmZvciBqIGluIHJhbmdlKGkrMSwgbik6CmlmIGFycltqXSA+IGFyclttYXhfaWR4XToKbWF4X2lkeCA9IGoKYXJyW2ldLCBhcnJbbWF4X2lkeF0gPSBhcnJbbWF4X2lkeF0sIGFycltpXQpyZXR1cm4gYXJy
In this example, the selection_sort_descending function takes an input array arr and uses the selection sort algorithm to sort the elements in descending order. The outer loop iterates through each element in the array from the first element to the second-to-last element. The inner loop finds the index of the maximum element in the remaining unsorted part of the array, and then swaps it with the element at the current position in the outer loop, effectively sorting the array in descending order.
Q41. What makes a block-level element different from an inline element in HTML?
In HTML, elements are categorized into two main types: block-level elements and inline elements, which behave differently in terms of how they are rendered and their behavior within the HTML document.
-
Block-level elements: Block-level elements are those that take up the full width of their parent container and create a new block-level box in the layout. They start on a new line and stack vertically on top of each other. Block-level elements can contain other block-level and inline elements. Some examples of block-level elements in HTML include
<div>,<p>,<h1>to<h6>,<ul>,<ol>,<li>,<form>,<header>,<footer>, and many more. -
Inline elements: Inline elements, on the other hand, do not create a new line and do not take up the full width of their parent container. They only take up as much width as necessary to display their content, and they flow in line with other content within the same line. Inline elements cannot contain block-level elements, but they can contain other inline elements. Examples of inline elements in HTML include
<span>,<a>,<strong>,<em>,<img>,<input>,<button>, and others.
The main differences between block-level and inline elements in HTML are:
-
Width: Block-level elements take up the full width of their parent container, while inline elements only take up as much width as necessary for their content.
-
Layout: Block-level elements create a new block-level box in the layout, starting on a new line and stacking vertically, while inline elements flow in line with other content on the same line.
-
Nesting: Block-level elements can contain other block-level and inline elements, while inline elements cannot contain block-level elements, but they can contain other inline elements.
-
Display behavior: Block-level elements are typically used for larger sections of content or structural elements, while inline elements are used for smaller elements and for applying styles to parts of the content.
Q42. Write a program in C to add numbers using a function.
#include
// Function to add two numbers
int addNumbers(int num1, int num2) {
return num1 + num2;
}
int main() {
int num1, num2, sum;
// Input first number
printf("Enter first number: ");
scanf("%d", &num1);
// Input second number
printf("Enter second number: ");
scanf("%d", &num2);
// Call the addNumbers() function to add the two numbers
sum = addNumbers(num1, num2);
// Display the result
printf("Sum = %d\n", sum);
return 0;
}
I2luY2x1ZGUgPHN0ZGlvLmg+CgovLyBGdW5jdGlvbiB0byBhZGQgdHdvIG51bWJlcnMKaW50IGFkZE51bWJlcnMoaW50IG51bTEsIGludCBudW0yKSB7CnJldHVybiBudW0xICsgbnVtMjsKfQoKaW50IG1haW4oKSB7CmludCBudW0xLCBudW0yLCBzdW07CgovLyBJbnB1dCBmaXJzdCBudW1iZXIKcHJpbnRmKCJFbnRlciBmaXJzdCBudW1iZXI6ICIpOwpzY2FuZigiJWQiLCAmbnVtMSk7CgovLyBJbnB1dCBzZWNvbmQgbnVtYmVyCnByaW50ZigiRW50ZXIgc2Vjb25kIG51bWJlcjogIik7CnNjYW5mKCIlZCIsICZudW0yKTsKCi8vIENhbGwgdGhlIGFkZE51bWJlcnMoKSBmdW5jdGlvbiB0byBhZGQgdGhlIHR3byBudW1iZXJzCnN1bSA9IGFkZE51bWJlcnMobnVtMSwgbnVtMik7CgovLyBEaXNwbGF5IHRoZSByZXN1bHQKcHJpbnRmKCJTdW0gPSAlZFxuIiwgc3VtKTsKCnJldHVybiAwOwp9
In this program, we define a function addNumbers() that takes two integer arguments num1 and num2, and returns their sum. The main() function is the entry point of the program, where we take input for two numbers, call the addNumbers() function with these numbers as arguments, and store the result in a variable sum. Finally, we display the result using printf() function.
Q43. What is C#?
C# (pronounced as "C-sharp") is a modern, object-oriented programming language developed by Microsoft as part of its .NET framework. C# is designed for building a wide range of applications, including desktop applications, web applications, cloud-based applications, mobile apps, gaming, and more. It is a strongly typed, statically compiled language that provides a rich set of features for building robust and efficient software.
C# is influenced by C and C++ programming languages, but it also includes features from other modern programming languages, such as Java and Python. Some key features of C# include:
-
Object-oriented programming (OOP): C# supports object-oriented programming concepts, such as classes, objects, inheritance, polymorphism, and encapsulation, allowing developers to build modular and extensible code.
-
Garbage collection: C# includes automatic memory management through a garbage collector, which helps manage memory and reduce the risk of memory leaks and other memory-related issues.
-
Event-driven programming: C# provides support for event-driven programming, allowing developers to create responsive and interactive applications by handling events and event handlers.
-
Integrated development environment (IDE): C# is typically developed using Microsoft's Visual Studio IDE, which provides a rich set of tools and features for coding, debugging, testing, and deploying C# applications.
-
Platform independence: C# code is compiled into an intermediate language called Common Intermediate Language (CIL), which can be executed on any platform that has a Common Language Runtime (CLR), making C# code platform-independent.
-
Rich standard library: C# has a rich standard library that provides a wide range of classes and APIs for common programming tasks, such as file I/O, networking, database access, XML processing, and more.
-
Language interoperability: C# is designed to work seamlessly with other languages that are part of the .NET framework, allowing developers to write mixed-language applications.
C# is a widely used programming language, particularly in the Microsoft technology stack, and is commonly used for building various types of applications, including desktop applications, web applications, cloud-based services, games, and more.
Q44. Can the private methods be overridden?
Private methods cannot be overridden in derived classes. The private access modifier restricts the visibility of a method to the class in which it is defined. This means that private methods can only be accessed and called within the same class, and they are not visible to derived classes or any other classes outside of the defining class.
When a method is overridden in a derived class, it is intended to provide a new implementation for the method in the derived class that replaces the implementation in the base class. However, if the method in the base class is marked as private, it cannot be accessed or overridden in the derived class, as it is not visible outside of the base class.
Here's an example to illustrate this:
class BaseClass
{
private void PrivateMethod()
{
Console.WriteLine("Private method in BaseClass");
}
public void PublicMethod()
{
Console.WriteLine("Public method in BaseClass");
}
public virtual void VirtualMethod()
{
Console.WriteLine("Virtual method in BaseClass");
}
}
class DerivedClass : BaseClass
{
// This method is not visible in DerivedClass and cannot be overridden
// as it is marked as private in BaseClass
private void PrivateMethod()
{
Console.WriteLine("Private method in DerivedClass");
}
// This method can be overridden as it is marked as public in BaseClass
public override void VirtualMethod()
{
Console.WriteLine("Overridden virtual method in DerivedClass");
}
}
class Program
{
static void Main(string[] args)
{
BaseClass obj1 = new BaseClass();
obj1.PublicMethod(); // Output: "Public method in BaseClass"
obj1.VirtualMethod(); // Output: "Virtual method in BaseClass"
DerivedClass obj2 = new DerivedClass();
obj2.PublicMethod(); // Output: "Public method in BaseClass"
obj2.VirtualMethod(); // Output: "Overridden virtual method in DerivedClass"
// This will not compile as PrivateMethod is not visible in DerivedClass
// obj2.PrivateMethod();
}
}
Y2xhc3MgQmFzZUNsYXNzCnsKcHJpdmF0ZSB2b2lkIFByaXZhdGVNZXRob2QoKQp7CkNvbnNvbGUuV3JpdGVMaW5lKCJQcml2YXRlIG1ldGhvZCBpbiBCYXNlQ2xhc3MiKTsKfQoKcHVibGljIHZvaWQgUHVibGljTWV0aG9kKCkKewpDb25zb2xlLldyaXRlTGluZSgiUHVibGljIG1ldGhvZCBpbiBCYXNlQ2xhc3MiKTsKfQoKcHVibGljIHZpcnR1YWwgdm9pZCBWaXJ0dWFsTWV0aG9kKCkKewpDb25zb2xlLldyaXRlTGluZSgiVmlydHVhbCBtZXRob2QgaW4gQmFzZUNsYXNzIik7Cn0KfQoKY2xhc3MgRGVyaXZlZENsYXNzIDogQmFzZUNsYXNzCnsKLy8gVGhpcyBtZXRob2QgaXMgbm90IHZpc2libGUgaW4gRGVyaXZlZENsYXNzIGFuZCBjYW5ub3QgYmUgb3ZlcnJpZGRlbgovLyBhcyBpdCBpcyBtYXJrZWQgYXMgcHJpdmF0ZSBpbiBCYXNlQ2xhc3MKcHJpdmF0ZSB2b2lkIFByaXZhdGVNZXRob2QoKQp7CkNvbnNvbGUuV3JpdGVMaW5lKCJQcml2YXRlIG1ldGhvZCBpbiBEZXJpdmVkQ2xhc3MiKTsKfQoKLy8gVGhpcyBtZXRob2QgY2FuIGJlIG92ZXJyaWRkZW4gYXMgaXQgaXMgbWFya2VkIGFzIHB1YmxpYyBpbiBCYXNlQ2xhc3MKcHVibGljIG92ZXJyaWRlIHZvaWQgVmlydHVhbE1ldGhvZCgpCnsKQ29uc29sZS5Xcml0ZUxpbmUoIk92ZXJyaWRkZW4gdmlydHVhbCBtZXRob2QgaW4gRGVyaXZlZENsYXNzIik7Cn0KfQoKY2xhc3MgUHJvZ3JhbQp7CnN0YXRpYyB2b2lkIE1haW4oc3RyaW5nW10gYXJncykKewpCYXNlQ2xhc3Mgb2JqMSA9IG5ldyBCYXNlQ2xhc3MoKTsKb2JqMS5QdWJsaWNNZXRob2QoKTsgLy8gT3V0cHV0OiAiUHVibGljIG1ldGhvZCBpbiBCYXNlQ2xhc3MiCm9iajEuVmlydHVhbE1ldGhvZCgpOyAvLyBPdXRwdXQ6ICJWaXJ0dWFsIG1ldGhvZCBpbiBCYXNlQ2xhc3MiCgpEZXJpdmVkQ2xhc3Mgb2JqMiA9IG5ldyBEZXJpdmVkQ2xhc3MoKTsKb2JqMi5QdWJsaWNNZXRob2QoKTsgLy8gT3V0cHV0OiAiUHVibGljIG1ldGhvZCBpbiBCYXNlQ2xhc3MiCm9iajIuVmlydHVhbE1ldGhvZCgpOyAvLyBPdXRwdXQ6ICJPdmVycmlkZGVuIHZpcnR1YWwgbWV0aG9kIGluIERlcml2ZWRDbGFzcyIKCi8vIFRoaXMgd2lsbCBub3QgY29tcGlsZSBhcyBQcml2YXRlTWV0aG9kIGlzIG5vdCB2aXNpYmxlIGluIERlcml2ZWRDbGFzcwovLyBvYmoyLlByaXZhdGVNZXRob2QoKTsKfQp9
As you can see from the example, the private method PrivateMethod() in the base class BaseClass is not visible in the derived class DerivedClass and cannot be overridden. However, the public method VirtualMethod() in the base class is marked as virtual and can be overridden in the derived class using the override keyword.
Q45. Define inconsistent dependency.
In software development, an inconsistent dependency refers to a situation where different parts of a system or codebase depend on different versions or configurations of a particular software library, module, or component. This can result in conflicts, inconsistencies, and unexpected behavior in the system, leading to issues such as runtime errors, crashes, or incorrect results.
Inconsistent dependencies can occur in various scenarios, such as when different parts of a software system use different versions of the same library, when there are conflicting requirements or configurations for a dependency, or when there are mismatches in dependencies between different modules or components of a system.
Some common examples of inconsistent dependencies include:
-
Version conflicts: When different parts of a system or codebase use different versions of the same library or module, it can lead to conflicts in terms of function signatures, APIs, behavior, or bug fixes. This can result in runtime errors, crashes, or other unexpected behavior.
-
Configuration mismatches: When different parts of a system depend on different configurations or settings of a common dependency, it can lead to inconsistencies and conflicts. For example, if one part of a system relies on a specific configuration of a database library, while another part uses a different configuration, it can result in issues such as data corruption or incorrect results.
-
Circular dependencies: When different modules or components in a system have circular dependencies, it can lead to inconsistent dependencies. Circular dependencies can create a situation where changes in one module or component can affect other modules or components in unexpected ways, leading to issues such as unintended behavior or bugs.
Common Wipro Interview Questions for HR Round
Before you appear for the Wipro HR round, make sure you portray positive body language. Your soft skill sets will play a big part in how well you perform in this round and can put you in a good position.
Q1. Tell me about yourself / Introduce yourself.
Introducing yourself means briefly talking about yourself. Highlight your achievements, hobbies, and your family.
Q2. What are your weaknesses?
Be honest about your weaknesses and where you lack as a professional. Don’t be pompous and say that you don’t have any!
Q3. Where do you see yourself after 5 years?
The aim of this question is to understand how long you want to stay in the current company. So, answer accordingly. Explain how you want to progress in Wipro in these 5 years.
Q4. Why do you choose Wipro Technologies?
Explain your decision to choose Wipro. It can be an aspirational one or just a regular career move; whatever it is, be clear about it.
Q5. Why should we hire you?
This is where you need to use your understanding to explain how you can be a valuable employee and a team member. Align your answer with the company's values and vision.
Q6. What are your hobbies?
Explain your hobbies, showing how they help you learn new things and have a great time outside work.
Q7. Why did you choose Computer Science?
Sight your reasons for choosing computer science. If anyone has inspired you to come into this domain, talk about that as well. Talk about your aspirations and what you want to achieve during your journey with Wipro.
Q8. What are some famous things to know about your home town?
Talk about the best things to explore in your hometown, the right time to visit, how to get there, and other details.
Q9. Do you know the difference between smart work and hard work?
Provide a positive answer and back it up with a real-life example, if possible quote a scenario where you have been a smart worker and completed a task in less time and hassle.
Q10. What do you believe in, talent or hard work?
This is a tricky HR question. So whatever option you choose, you need to provide an elaborate answer that backs up your claim.
Q11. Have you ever wanted to quit something?
If you have ever, then be honest and clear about it. But also explain how you came back from that thought.
Q12. Are you a team player?
Answer affirmatively and explain why teamwork is vital with a real-life example.
Q13. Where do you find motivation from?
Explain your source of motivation and provide an example. For instance, if it is an individual, then talk about how and what he/she does that helps you.
Q14. Tell me about your groups of friends.
Talk about your friend circle, what they do, and what makes it thrive.
HR questions are mostly intended to assess your interpersonal skills. Hence, maintain positive body language, answer all the questions confidently, and give real-life examples wherever possible to add value to your replies.
Wipro Online Assessment Sample Questions with Solutions
To make your preparation easier, we have collected some important questions for the rest of the recruitment rounds as well. These will familiarize you with the type of questions asked in other rounds and help streamline your preparation. Let's begin!
Aptitude Test
Here are some topics that you must revise to prepare for the Aptitude Round:
|
Sample Aptitude Questions
Q1. Three friends Sia, Rahul, and Jeet can complete a task in 20, 30, and 60 days respectively. Suppose Sia does the task all by herself and is assisted by Rahul and Jeet every third day, then calculate the number of days required to finish the work completely.
A. 10 Days
B. 9 Days
C. 14 Days
D. 15 Days
Answer: Option D
Solution :
Amount of work P can complete in a day = 1/20
Amount of work Q can complete in a day = 1/30
Amount of work R can complete in a day = 1/60
P is doing all work by himself and every third day Q and R are working with him
Work finished in every three days = 2 × (1/20) + (1/20 + 1/30 + 1/60) = 1/5
So work finished in 15 days = 5 × 1/5 = 1
Q.2 A water tanker is provided by two pipes A and B. A can fill the tanker 5 hours quicker than B. If they both fill the tanker together in 6 hours, then the tanker will be filled by A alone in
A. 12 hours
B. 8 hours
C. 10 hours
D. 11 hours
Answer: Option C
Solution:
If x is the speed, then speed of A= x + 5 and B = x
Time taken by A and B will be x and x + 5 resp.
1/x + 1/x + 5 = 1/6 ; x2 – 7x - 30 = 0 x = -3 or x = 10.
Since time can’t be negative, x =10.
Q.3 A candidate scores 55% marks in 8 assessments of 100 marks each. He scores 15% of the total marks in Communication. How many marks does he score in Communication?
A. 55
B. 66
C. 77
D. 44
Answer: Option B
Solution:
We have to find the score in Communication.
Given that his score in Communication is 15% of his total marks. So let us first find the total score of the candidate on all 8 assessments.
He scored 55% on 8 assessments of 100 marks each.
Since each assessment is of 100 marks, the total marks of the assessment = (100 × 8) = 800
Thus, the total marks scored by him in all the 8 assessments = 55% of 800 = (55/100) × 800 = (55 × 8) = 440
Q.4 Arun walks 25 meters towards the north, then turns to his left and walks 10 meters, and then turns to his right and walks 15 meters. Again turning to his right, he walks 14 meters. What will be the shortest distance between his starting point and ending point?
A. 25.32
B. 40.12
C. 42.38
D. 41.48
Answer: Option B
Solution:
Firstly, we have to draw the diagram as per the requirements that are given in the question and see what is the relationship between the starting point and endpoint. From the below figure we can see that the Minimum distance will be the hypotenuse.
Where AC is hypotenuse, AB and BC are length and breadth
AB = 25 + 15 = 40 m, BC = 14 -10 = 4 m
Now, by Right angle triangle theorem,
AB^2 + BC^2 = AC^2
Therefore, by solving the above equation, AC = 40.12. So the correct answer is Option B
Logical Ability Test
The Wipro logical reasoning section is moderately difficult. The time provided for the section is less than usual. There are a lot of mind-ready tasks a candidate needs to perform in this section. The following topics are tested:
- Coding Deductive Logic
- Blood Relation
- Directional Sense
- Objective Reasoning
- Selection Decision Tables
- Seating Arrangements
- Mathematical Orders
- Inferred Meaning
- Logical Word Sequence
- Data Sufficiency
- Syllogism
- Data Arrangement
Number of Questions: 14
Total Time: 14 mins
Sample Logical Ability Questions
Q.1 If the animals that crawl are called flying, animals that walk are called swimmers, those which fly are called hunters, and those swimming in water are snakes, then what is a spider?
A. Swimmers
B. Flying
C. Snakes
D. Hunters
Answer: Option B
Solution:
Clearly, a spider crawls and the animals that crawl are called 'flying'. So, 'spider' is called 'flying'.
Q.2 If
- a * b means a is the brother of b.
- a@b means a is the daughter of b.
- a $ b means a is the sister of b.
then,
Which option shows the relationship "c is g’s paternal uncle"?
A. g@o$c
B. g@o*c
C. g$o@c
D. g*o@c
Answer: Option B
Solution:
g@o*c reads g is the o’s daughter and o is c’s brother. Hence, c becomes g's, paternal uncle.
Q.3 Statements: All men are toys. Some toys are animals.
Conclusions:
1. All men are animals
2. All animals are toys
3. Some toys are men
4. All toys are men
A. Only 4 follows
B. Only 2 follows
C. Only 3 follows
D. Only 1 follows
Answer: Option C
Verbal Ability Test
The Verbal section is bound to a restricted time limit and is usually of moderate difficulty. The topics given below are tested in the Wipro Elite NTH exam:
- Sentence Improvement & Construction
- Jumbled Sentence
- Sentence Formation
- Tenses & Articles
- Inferential and Literal Comprehension
- Error Identification
- Synonyms
- Antonyms
- Subject-Verb Agreement
- Preposition & Conjunctions
- Comprehension Ordering
- Speech & Voices
Number of Questions: 22
Total Time: 18 mins
Sample Verbal Ability Questions
Q.1 Find the order of sentence:
-
Rohan reached the office at 10 O'clock after sending the money.
-
Rohan's friends needed some money.
-
After that, he spent around 30 minutes at the Post Office.
-
So, he went to the bank for withdrawing some money.
-
However, he had no money with her.
A. 2→5→3→4→1
B. 2→5→4→3→1
C. 2→5→3→1→4
D. 2→5→4→1→3
Answer: Option B
Solution:
Rohan's friends needed some money. However, he had no money for her. So, he went to the bank to withdraw some money. After that, he spent around 30 minutes at the Post Office. He reached the office at 10 am after sending the money.
Q.9 Out of the four alternatives, choose the word which has the opposite meaning to the given word.
INVINCIBLE
A. Adamant
B. Certain
C. Arrogant
D. Cowardly
Answer: Option D
Q.10 Which of the following is the right form of indirect speech for the sentence given below?
Michael said, " they have been on medication since morning."
A. Michael said that they have been on medication since morning.
B. Michael said that they are on medication since morning.
C. Michael said that they had been on medication since morning.
D. Michael said that he has been on medication since morning.
Answer: Option C
Solution:
Present perfect continuous tense is changed into past perfect continuous tense in indirect speech.
Essay Writing
Wipro has an essay writing section in its exam for the NTH Wipro Elite hiring process. In this section, you are given a specific topic to write a short essay ranging from 200-250 words. This round is designed to check your fundamental understanding of the grammatical and vocabulary skills,
Steps to writing a good essay:
Step 1. Understand the topic
Step 2. Plan and outline
Step 3. Structure your essay
Step 4. Write the introduction
Step 5. Write the body
Step 6. Write a conclusion
Step 7. Finishing touches (revise and check the order)
Coding Questions
In the Wipro coding round, you are required to solve easy to difficult levels. There are two questions asked in this round, one basic question and the other from an intermediate level to test the fundamental understanding and basic concepts of coding. You need to answer 1 question at least to clear the cut-off. But in cases, when the majority of the candidates have successfully solved both the questions, then the cut-off might vary accordingly.
Points to Remember - Wipro Coding Round
- Implement the function signature provided by the editor.
- The signature calls other functions (the complete function call stack) defined by you.
- It may also use structure definitions, exception handlers, and other pre-processing directives such as macros.
- Use the function as provided as any deviation may result in an unsuccessful compilation of the code.
- You may include necessary libraries if required.
- Do not modify the pre-implemented main method.
Sample Coding Questions
Q1. Left Rotation
Problem Statement:
A left rotation operation on an array shifts each of the array’s elements unit to the left. For example, if 2 left rotations are performed on array [1, 2, 3, 4, 5], then the array would become [3, 4, 5, 1, 2]. Given an array of integers and a number, perform left rotations on the array. Return the updated array to be printed as a single line of space-separated integers.
Function Description
Complete the function rotateLeft() in the editor below. It should return the resulting array of integers.
rotLeft has the following parameter(s):
- An array of integers.
- An integer, the number of rotations.
Input Format
The first line contains two space-separated integers and the size of and the number of left rotations you must perform.
The second line contains space-separated integers a[i].
Constraints
- 1 <= n <= 10^5
- 1 <= d <= n
- 1 <= a[i] <= 10^8
Output Format
Print a single line of space-separated integers denoting the final state of the array after performing d left rotations.
Sample Input
5 4
1 2 3 4 5
Sample Output
5 1 2 3 4
Explanation When we perform d=4 left rotations, the array undergoes the following sequence of changes:
[1,2,3,4,5] → [2,3,4,5,1] → [3,4,5,1,2] → [4,5,1,2,3] → [5,1,2,3,4]
Test Case: 1
Input:
5 4
1 2 3 4 5
Output:
5 1 2 3 4
Test Case: 2
Input:
20 10
41 73 89 7 10 1 59 58 84 77 77 97 58 1 86 58 26 10 86 51
Output:
77 97 58 1 86 58 26 10 86 51 41 73 89 7 10 1 59 58 84 77
Code:
int rotateLeft(int arr[], int n, int d)
{
int i, j;
int first;
for(i=0; i<d; i++)
{
first = arr[0];
for(j=0; j<n-1; j++)
{
arr[j] = arr[j+1];
}
arr[j] = first;
}
return *arr;
}
bnQgcm90YXRlTGVmdChpbnQgYXJyW10sIGludCBuLCBpbnQgZCkKewogaW50IGksIGo7CiBpbnQgZmlyc3Q7CiBmb3IoaT0wOyBpPGQ7IGkrKykKIHsKIGZpcnN0ID0gYXJyWzBdOwogZm9yKGo9MDsgajxuLTE7IGorKykKIHsKIGFycltqXSA9IGFycltqKzFdOwogfQogYXJyW2pdID0gZmlyc3Q7CiB9CiByZXR1cm4gKmFycjsKfQog
Q2. Pythagorean Triplet
Problem Statement:
A Pythagorean triplet is a set of three integers a, b, and c such that $a^2+b^2=c^2$. Given a limit, generate all Pythagorean Triples with values smaller than the given limit.
Example:
Input:
limit = 30
Output:
3 4 5
8 6 10
5 12 13
15 8 17
12 16 20
7 24 25
24 10 26
21 20 29
Function Description
Complete the function pythagoreanTriplets() which will print all the triplets to the given limit.
pythagoreanTriplets() has the following parameter(s):
- An integer.
Input Format
The first line contains a single integer.
Output Format
Print all triplets in a separate line.
Sample Input
10
Sample Output
3 4 5
8 6 10
Explanation:
$3^2+4^2=5^2=>9+16=25$
$8^2+6^2=10^2 => 64 +36=100$
Test Case: 1
Input:
20
Output:
3 4 5
8 6 10
5 12 13
15 8 17
12 16 20
Test Case: 2
Input:
30
Output:
3 4 5
8 6 10
5 12 13
15 8 17
12 16 20
7 24 25
24 10 26
21 20 29
Code:
void pythagoreanTriplets (int limit)
{
// triplet: a^2 + b^2 = c^2
int a, b, c = 0;
// loop from 2 to max_limit
int i = 2;
// Limiting c would limit all a, b and c
while (c < limit)
{
// now loop on j from 1 to i-1
for (int n = 1; n < i; ++n)
{
// Evaluate and print triplets using
// the relation between a, b and c
a = i * i - n * n;
b = 2 * i * n;
c = i * i + n * n;
if (c > limit)
break;
cout<<a<<" "<<b<<" "<<c<<endl;
}
i++;
}
}
Frequently Asked Questions
Q1. What is Wipro Elite NTH?
Wipro Elite NTH or National Talent Hunt is a hiring program for freshers. Its objective is to draw the attention of the best talent in engineering from across the country.
Q2. How much time does the Wipro recruitment process take to complete?
It may vary, but a maximum of 1 month is expected.
Q3. What documents are needed to join Wipro?
Government ID (Aadhar Card), 10th-12th mark sheets, and mark sheets for all the semesters.
Q4. How many rounds of an interview are there in Wipro Elite NTH?
The Wipro interview round can be broken into technical and behavioral sub-rounds.
Q5. Is there any bond to be filled while joining Wipro?
Yes, usually 1-year bond is applicable for the offered job position.
Q6. Can I use Python language in the coding round?
Yes, you can use C, C++, Java, or Python.
Q7. How do I know the schedule of the Online Assessment and Interview?
If you have registered, you will receive an official mail from Wipro, or you can visit the official site of Wipro Elite.

You may also like to read:
Login to continue reading
And access exclusive content, personalized recommendations, and career-boosting opportunities.
Don't have an account? Sign up
Never miss an
Update

Featured Opportunities
Top-Rated Practice by Students





Subscribe
to our newsletter
Blogs you need to hog!

How To Write Finance Cover Letter For Morgan Stanley (+Free Sample!)
Unstop

55+ Data Structure Interview Questions For 2026 (Detailed Answers)
Muskaan Mishra

How To Negotiate Salary With HR: Tips And Insider Advice
Srishti Magan

80+ TCS NQT Interview Questions & Answers (2026) You Must Prepare
Urvashi Singhal
Comments
Add comment