


Asian Paints Alchemy 2026
Company Interview Questions for Freshers
- TCS Technical Interview Questions & Answers
- TCS Managerial Interview Questions & Answers
- TCS HR Interview Questions & Answers
- Overview of Cognizant Recruitment Process
- Cognizant Interview Questions: Technical
- Cognizant Interview Questions: HR Round
- Overview of Wipro Technologies Recruitment Rounds
- Wipro Interview Questions
- Technical Round
- HR Round
- Online Assessment Sample Questions
- Frequently Asked Questions
- Overview of Google Recruitment Process
- Google Interview Questions: Technical
- Google Interview Questions: HR round
- Interview Preparation Tips
- About Google
- Deloitte Technical Interview Questions
- Deloitte HR Interview Questions
- Deloitte Recruitment Process
- Technical Interview Questions and Answers
- Level 1 difficulty
- Level 2 difficulty
- Level 3 difficulty
- Behavioral Questions
- Eligibility Criteria for Mindtree Recruitment
- Mindtree Recruitment Process: Rounds Overview
- Skills required to crack Mindtree interview rounds
- Mindtree Recruitment Rounds: Sample Questions
- About Mindtree
- Preparing for Microsoft interview questions
- Microsoft technical interview questions
- Microsoft behavioural interview questions
- Aptitude Interview Questions
- Technical Interview Questions
- Easy
- Intermediate
- Hard
- HR Interview Questions
- Eligibility criteria
- Recruitment rounds & assessments
- Tech Mahindra interview questions - Technical round
- Tech Mahindra interview questions - HR round
- Hiring process at Mphasis
- Mphasis technical interview questions
- Mphasis HR interview questions
- About Mphasis
- Technical interview questions
- HR interview questions
- Recruitment process
- About Virtusa
- Goldman Sachs Interview Process
- Technical Questions for Goldman Sachs Interview
- Sample HR Question for Goldman Sachs Interview
- About Goldman Sachs
- Nagarro Recruitment Process
- Nagarro HR Interview Questions
- Nagarro Aptitude Test Questions
- Nagarro Technical Test Questions
- About Nagarro
- PwC Recruitment Process
- PwC Technical Interview Questions: Freshers and Experienced
- PwC Interview Questions for HR Rounds
- PwC Interview Preparation
- Frequently Asked Questions
- EY Technical Interview Questions (2023)
- EY Interview Questions for HR Round
- About EY
- Morgan Stanley Recruitment Process
- HR Questions for Morgan Stanley Interview
- HR Questions for Morgan Stanley Interview
- About Morgan Stanley
- Recruitment Process at Flipkart
- Technical Flipkart Interview Questions
- Code-Based Flipkart Interview Questions
- Sample Flipkart Interview Questions- HR Round
- Conclusion
- FAQs
- Recruitment Process at Paytm
- Technical Interview Questions for Paytm Interview
- HR Sample Questions for Paytm Interview
- About Paytm
- Most Probable Accenture Interview Questions
- Accenture Technical Interview Questions
- Accenture HR Interview Questions
- Amazon Recruitment Process
- Amazon Interview Rounds
- Common Amazon Interview Questions
- Amazon Interview Questions: Behavioral-based Questions
- Amazon Interview Questions: Leadership Principles
- Company-specific Amazon Interview Questions
- 43 Top Technical/ Coding Amazon Interview Questions
- Juspay Recruitment: Stages and Timeline
- Juspay Interview Questions and Answers
- How to prepare for Juspay interview questions
- Prepare for the Juspay Interview: Stages and Timeline
- Frequently Asked Questions
- Adobe Interview Questions - Technical
- Adobe Interview Questions - HR
- Recruitment Process at Adobe
- About Adobe
- Cisco technical interview questions
- Sample HR interview questions
- The recruitment process at Cisco
- About Cisco
- JP Morgan interview questions (Technical round)
- JP Morgan interview questions HR round)
- Recruitment process at JP Morgan
- About JP Morgan
- Wipro Elite NTH: Selection Process
- Wipro Elite NTH Technical Interview Questions
- Wipro Elite NTH Interview Round- HR Questions
- BYJU's BDA Interview Questions
- BYJU's SDE Interview Questions
- BYJU's HR Round Interview Questions
- A Quick Overview of the KPMG Recruitment Process
- Technical Questions for KPMG Interview
- HR Questions for KPMG Interview
- About KPMG
- DXC Technology Interview Process
- DCX Technical Interview Questions
- Sample HR Questions for DXC Technology
- About DXC Technology
- Recruitment Process at PayPal
- Technical Questions for PayPal Interview
- HR Sample Questions for PayPal Interview
- About PayPal
- Capgemini Recruitment Rounds
- Capgemini Interview Questions: Technical round
- Capgemini Interview Questions: HR round
- Preparation tips
- FAQs
- Technical interview questions for Siemens
- Sample HR questions for Siemens
- The recruitment process at Siemens
- About Siemens
- HCL Technical Interview Questions
- HR Interview Questions
- HCL Technologies Recruitment Process
- List of EPAM Interview Questions for Technical Interviews
- About EPAM
- Atlassian Interview Process
- Top Skills for Different Roles at Atlassian
- Atlassian Interview Questions: Technical Knowledge
- Atlassian Interview Questions: Behavioral Skills
- Atlassian Interview Questions: Tips for Effective Preparation
- Walmart Recruitment Process
- Walmart Interview Questions and Sample Answers (HR Round)
- Walmart Interview Questions and Sample Answers (Technical Round)
- Tips for Interviewing at Walmart and Interview Preparation Tips
- Frequently Asked Questions
- Uber Interview Questions For Engineering Profiles: Coding
- Technical Uber Interview Questions: Theoretical
- Uber Interview Question: HR Round
- Uber Recruitment Procedure
- About Uber Technologies Ltd.
- Intel Technical Interview Questions
- Computer Architecture Intel Interview Questions
- Intel DFT Interview Questions
- Intel Interview Questions for Verification Engineer Role
- Recruitment Process Overview
- Important Accenture HR Interview Questions
- Points to remember
- What is Selenium?
- What are the components of the Selenium suite?
- Why is it important to use Selenium?
- What's the major difference between Selenium 3.0 & Selenium 2.0?
- What is Automation testing and what are its benefits?
- What are the benefits of Selenium as an Automation Tool?
- What are the drawbacks to using Selenium for testing?
- Why should Selenium not be used as a web application or system testing tool?
- Is it possible to use selenium to launch web browsers?
- What does Selenese mean?
- What does it mean to be a locator?
- Identify the main difference between "assert", and "verify" commands within Selenium
- What does an exception test in Selenium mean?
- What does XPath mean in Selenium? Describe XPath Absolute & XPath Relation
- What is the difference in Xpath between "//"? and "/"?
- What is the difference between "type" and the "typeAndWait" commands within Selenium?
- Distinguish between findElement() & findElements() in context of Selenium
- How long will Selenium wait before a website is loaded fully?
- What is the difference between the driver.close() and driver.quit() commands in Selenium?
- Describe the different navigation commands that Selenium supports
- What is Selenium's approach to the same-origin policy?
- Explain the difference between findElement() in Selenium and findElements()
- Explain the pause function in SeleniumIDE
- Explain the differences between different frameworks and how they are connected to Selenium's Robot Framework
- What are your thoughts on the Page Object Model within the context of Selenium
- What are your thoughts on Jenkins?
- What are the parameters that selenium commands come with a minimum?
- How can you tell the differences in the Absolute pathway as well as Relative Path?
- What's the distinction in Assert or Verify declarations within Selenium?
- What are the points of verification that are in Selenium?
- Define Implicit wait, Explicit wait, and Fluent
- Can Selenium manage windows-based pop-ups?
- What's the definition of an Object Repository?
- What is the main difference between obtainwindowhandle() as well as the getwindowhandles ()?
- What are the various types of Annotations that are used in Selenium?
- What is the main difference in the setsSpeed() or sleep() methods?
- What is the way to retrieve the alert message?
- How do you determine the exact location of an element on the web?
- Why do we use Selenium RC?
- What are the benefits or advantages of Selenium RC?
- Do you have a list of the technical limitations when making use of Selenium RC? Selenium RC?
- What's the reason to utilize the TestNG together with Selenium?
- What Language do you prefer to use to build test case sets in Selenium?
- What are Start and Breakpoints?
- What is the purpose of this capability relevant in relation to Selenium?
- When do you use AutoIT?
- Do you have a reason why you require Session management in Selenium?
- Are you able to automatize CAPTCHA?
- How can we launch various browsers on Selenium?
- Why should you select Selenium rather than QTP (Quick Test Professional)?
- Airbus Interview Questions and Answers: HR/ Behavioral
- Industry/ Company-Specific Airbus Interview Questions
- Airbus Interview Questions and Answers: Aptitude
- Airbus Software Engineer Interview Questions and Answers: Technical
- Importance of Spring Framework
- Spring Interview Questions (Basic)
- Advanced Spring Interview Questions
- C++ Interview Questions and Answers: The Basics
- C++ Interview Questions: Intermediate
- C++ Interview Questions And Answers With Code Examples
- C++ Interview Questions and Answers: Advanced
- Test Your Skills: Quiz Time
- MBA Interview Questions: B.Com Economics
- B.Com Marketing
- B.Com Finance
- B.Com Accounting and Finance
- Business Studies
- Chartered Accountant
- Q1. Please tell us something about yourself/ Introduce yourself to us.
- Q2. Describe yourself in one word.
- Q3. Tell us about your strengths and weaknesses.
- Q4. Why did you apply for this job/ What attracted you to this role?
- Q5. What are your hobbies?
- Q6. Where do you see yourself in five years OR What are your long-term goals?
- Q7. Why do you want to work with this company?
- Q8. Tell us what you know about our organization
- Q9. Do you have any idea about our biggest competitors?
- Q10. What motivates you to do a good job?
- Q11. What is an ideal job for you?
- Q12. What is the difference between a group and a team?
- Q13. Are you a team player/ Do you like to work in teams?
- Q14. Are you good at handling pressure/ deadlines?
- Q15. When can you start?
- Q16. How flexible are you regarding overtime?
- Q17. Are you willing to relocate for work?
- Q18. Why do you think you are the right candidate for this job?
- Q19. How can you be an asset to the organization?
- Q20. What is your salary expectation?
- Q21. How long do you plan to remain with this company?
- Q22. What is your objective in life?
- Q23. Would you like to pursue your Master's degree anytime soon?
- Q24. How have you planned to achieve your career goal?
- Q25. Can you tell us about your biggest achievement in life?
- Q26. What was the most challenging decision you ever made?
- Q27. What kind of work environment do you prefer to work in?
- Q28. What is the difference between a smart worker and a hard worker?
- Q29. What will you do if you don't get hired?
- Q30. Tell us three things that are most important for you in a job.
- Q31. Who is your role model and what have you learned from him/her?
- Q32. In case of a disagreement, how do you handle the situation?
- Q33. What is the difference between confidence and overconfidence?
- Q34. If you have more than enough money in hand right now, would you still want to work?
- Q35. Do you have any questions for us?
- Interview Tips for Freshers
- Tell me about yourself
- What are your greatest strengths?
- What are your greatest weaknesses?
- Tell me about something you did that you now feel a little ashamed of
- Why are you leaving (or did you leave) this position??
- 15+ resources for preparing most-asked interview questions
- CoCubes Interview Process Overview
- Common CoCubes Interview Questions
- Key Areas to Focus on for CoCubes Interview Preparation
- Conclusion
- Frequently Asked Questions (FAQs)
- Data Analyst Interview Questions With Answers
- About Data Analyst
HCL Technologies Interview Questions & Answers | HCL Recruitment 2026
By familiarizing yourself with these technical and HR questions, you can adequately prepare for your HCL interview and increase your chances of success on the big day.
HCL Technologies is India's one of the leading technology consulting companies. It is headquartered in Noida, India; however, it operates in over 40 countries. Its services include analytics, cloud, automation and IoT, cybersecurity and infrastructure management, etc. In addition, HCL is among India's top 20 public companies and provides banking, automotive, healthcare, entertainment, and engineering services.
In this article, you can get in-depth knowledge of HCL interview questions. These questions will give you an idea of how HCL conducts its interviews and can prepare you well for D-Day!
HCL Interview Questions: Technical Round
These questions will assess your knowledge of computer-related topics such as programming language and data structure. You may have to write programs and answer questions that will show your expertise in technical matters. The interviewer may ask about your project; so ensure that you highlight your skills while describing it.
1. Differentiate between constant and global variables.
In computer programming, constant and global variables are two types of variables that are used to store data. Here's the difference between them:
-
Constant Variables:
- A constant is a value that cannot be changed after it has been initialized.
- Constants are typically used to store values that should not be modified during the execution of a program.
- In many programming languages, constant variables are declared using the keyword "const".
- Constant variables are typically local to a function or a class, and their scope is limited to the block of code where they are defined.
-
Global Variables:
- A global variable is a variable that is accessible from any part of a program.
- Global variables are typically used to store values that need to be accessed by multiple functions or modules within a program.
- Global variables are declared outside of any function or class, and their scope is not limited to a particular block of code.
- Global variables can be accessed and modified from any part of the program, which makes them a powerful but potentially risky tool to use, especially in larger programs.
2. Explain the input and output streams in C++.
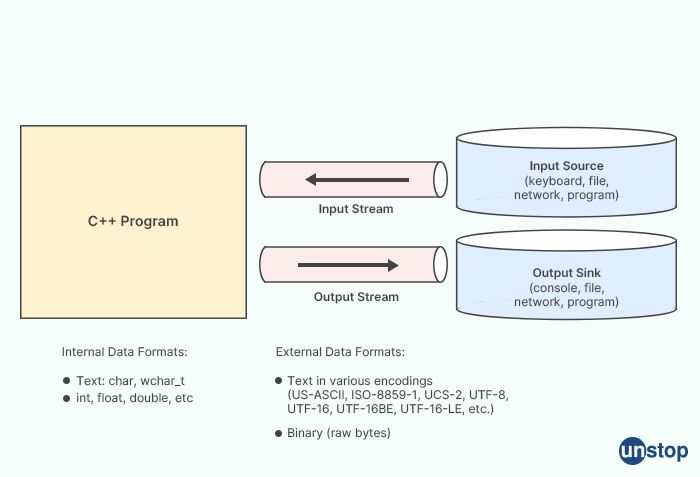
#include<iostream.h> //importing header file
void main()
{ int a;
cin>>a; //getting input from the user
count<<In C++, an input stream is a source of data, and an output stream is a destination for data. These streams are used to read and write data to and from different sources and destinations, such as the console, files, and network sockets.
In C++, input streams and output streams are represented by the classes istream and ostream, respectively. These classes provide a rich set of methods for reading and writing data to and from the streams.
3. Explain the concept of nested class.
In C++, a nested class is a class that is defined within another class. The nested class is then considered a member of the outer class and can access the private members of the outer class.
Here's an example of a nested class in C++:
class OuterClass {
public:
class InnerClass {
public:
void doSomething() {
// Can access OuterClass's private members
outerClassPrivateMember = 42;
}
};
private:
int outerClassPrivateMember;
};
Y2xhc3MgT3V0ZXJDbGFzcyB7CnB1YmxpYzoKY2xhc3MgSW5uZXJDbGFzcyB7CnB1YmxpYzoKdm9pZCBkb1NvbWV0aGluZygpIHsKLy8gQ2FuIGFjY2VzcyBPdXRlckNsYXNzJ3MgcHJpdmF0ZSBtZW1iZXJzCm91dGVyQ2xhc3NQcml2YXRlTWVtYmVyID0gNDI7Cn0KfTsKcHJpdmF0ZToKaW50IG91dGVyQ2xhc3NQcml2YXRlTWVtYmVyOwp9Ow==
In this example, InnerClass is defined inside OuterClass. InnerClass can access the private outerClassPrivateMember variable of OuterClass
4. What do you mean by virtual functions?
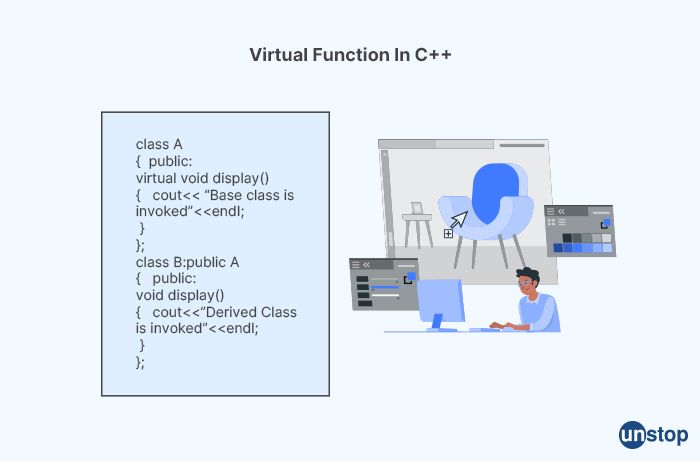
In C++, a virtual function is a function that can be overridden by a subclass. Virtual functions are declared in a base class and are marked with the virtual keyword. They allow a subclass to provide its own implementation of the function, which will be called instead of the implementation in the base class when the function is called on an instance of the subclass.
Here's an example of a virtual function in C++:
class Shape {
public:
virtual void draw() {
// Default implementation of the draw function
}
};
class Circle : public Shape {
public:
void draw() override {
// Implementation of the draw function for circles
}
};
Y2xhc3MgU2hhcGUgewpwdWJsaWM6CnZpcnR1YWwgdm9pZCBkcmF3KCkgewovLyBEZWZhdWx0IGltcGxlbWVudGF0aW9uIG9mIHRoZSBkcmF3IGZ1bmN0aW9uCn0KfTsKCmNsYXNzIENpcmNsZSA6IHB1YmxpYyBTaGFwZSB7CnB1YmxpYzoKdm9pZCBkcmF3KCkgb3ZlcnJpZGUgewovLyBJbXBsZW1lbnRhdGlvbiBvZiB0aGUgZHJhdyBmdW5jdGlvbiBmb3IgY2lyY2xlcwp9Cn07
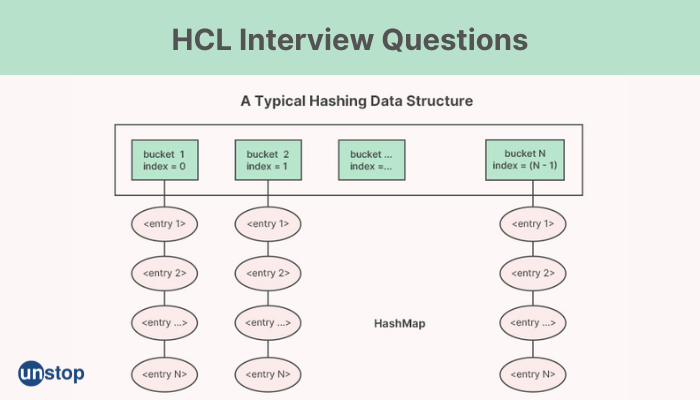
5. Describe a HashMap.
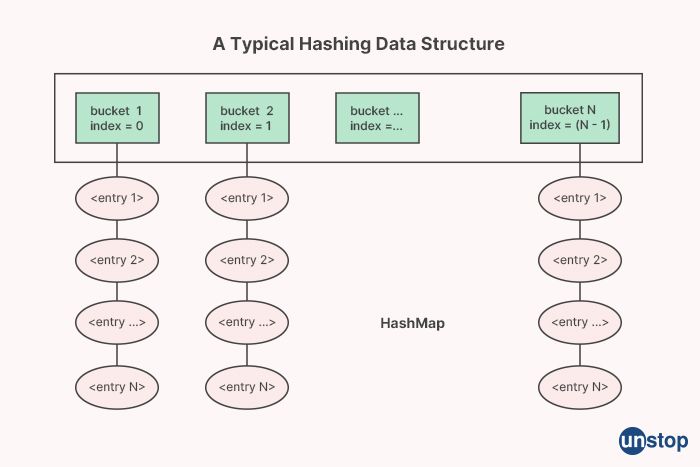
In C++, a HashMap (also known as an unordered map) is a data structure that allows us to store key-value pairs in a way that provides constant-time access to the values based on their keys. A HashMap uses a hash table to store the key-value pairs, where the key is hashed to a bucket index in the table, and the value is stored at that index.
Here's an example of a HashMap in C++:
#include
#include
int main() {
std::unordered_map<std::string, int> myMap;
myMap["one"] = 1;
myMap["two"] = 2;
myMap["three"] = 3;
std::cout << "Value of key 'two': " << myMap["two"] << std::endl;
return 0;
}
I2luY2x1ZGUgPHVub3JkZXJlZF9tYXA+CiNpbmNsdWRlIDxpb3N0cmVhbT4KCmludCBtYWluKCkgewpzdGQ6OnVub3JkZXJlZF9tYXA8c3RkOjpzdHJpbmcsIGludD4gbXlNYXA7Cm15TWFwWyJvbmUiXSA9IDE7Cm15TWFwWyJ0d28iXSA9IDI7Cm15TWFwWyJ0aHJlZSJdID0gMzsKCnN0ZDo6Y291dCA8PCAiVmFsdWUgb2Yga2V5ICd0d28nOiAiIDw8IG15TWFwWyJ0d28iXSA8PCBzdGQ6OmVuZGw7CgpyZXR1cm4gMDsKfQ==
In this example, we create a HashMap called myMap that stores int values with std::string keys. We insert three key-value pairs into the map using the [] operator, and then we retrieve the value associated with the key "two" using the [] operator as well. The output of the program will be Value of key 'two': 2.
6. What are object-oriented programming languages?
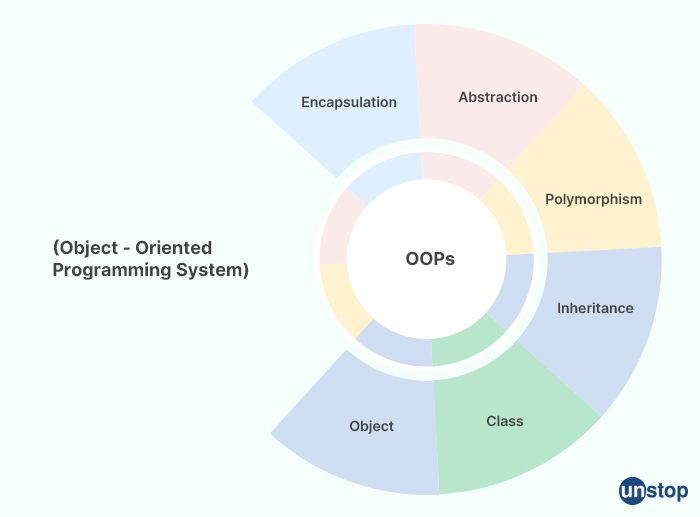
Object-oriented programming (OOP) languages are programming languages that support the principles of object-oriented programming, which is a programming paradigm that emphasizes the concept of objects.
In OOP, objects are instances of classes that encapsulate data (attributes) and behavior (methods) into a single unit. The objects interact with each other by sending messages to each other, which triggers the execution of methods.
Some popular object-oriented programming languages include:
- Java: a high-level language that is widely used for developing enterprise applications, mobile apps, and games.
- C++: a general-purpose language that is often used for systems programming, game development, and scientific computing.
- Python: a high-level language that is known for its simplicity and ease of use, and is used in data science, machine learning, web development, and other areas.
- Ruby: a dynamic language that is often used for web development and automation scripting.
- Swift: a language developed by Apple for iOS, macOS, and other Apple platforms.
- C#: a language developed by Microsoft for developing Windows applications, games, and web applications.
OOP languages provide features that allow developers to create reusable and modular code, and to write programs that are easier to maintain and understand. Some of the key features of OOP languages include inheritance, encapsulation, and polymorphism.
7. What are the kinds of kernel threads?
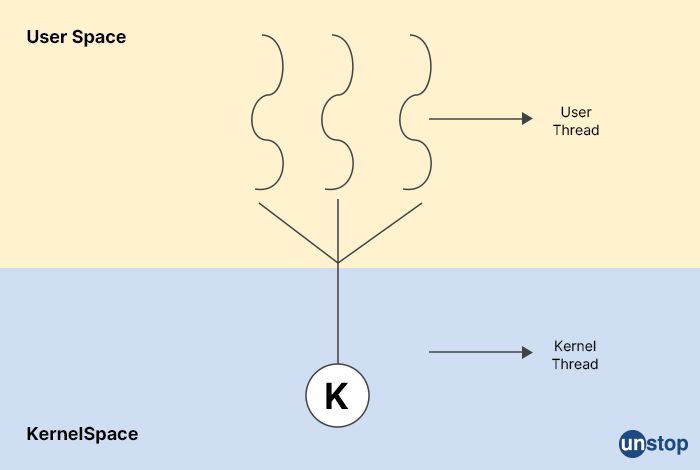
In operating systems, there are generally two types of kernel threads: user-level threads and kernel-level threads.
-
User-level threads: User-level threads are managed by a user-level library, and the kernel is unaware of their existence. These threads are scheduled by the thread library, which maps them to one or more kernel-level threads. User-level threads are fast and lightweight, but they have some drawbacks. For example, if the user-level thread blocks, the entire process may block, including all of the other threads in that process.
-
Kernel-level threads: Kernel-level threads are managed by the operating system's kernel. Each kernel-level thread is scheduled and managed independently by the kernel. Kernel-level threads are slower and more heavyweight than user-level threads, but they have some advantages. For example, if one kernel-level thread blocks, other threads in the same process can continue to execute. Additionally, kernel-level threads can take advantage of multiprocessing capabilities, such as running on multiple CPU cores.
Most modern operating systems use a combination of user-level and kernel-level threads to achieve a balance between performance and functionality.
8. What is a function pointer?
In C++, a function pointer is a variable that holds the memory address of a function. A function pointer can be used to call a function indirectly, without knowing the name of the function at compile time.
Here's an example:
#include
void say_hello() {
std::cout << "Hello, world!" << std::endl;
}
int main() {
void (*function_ptr)() = &say_hello;
function_ptr();
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgoKdm9pZCBzYXlfaGVsbG8oKSB7CnN0ZDo6Y291dCA8PCAiSGVsbG8sIHdvcmxkISIgPDwgc3RkOjplbmRsOwp9CgppbnQgbWFpbigpIHsKdm9pZCAoKmZ1bmN0aW9uX3B0cikoKSA9ICZzYXlfaGVsbG87CmZ1bmN0aW9uX3B0cigpOwoKcmV0dXJuIDA7Cn0=
Function pointers are commonly used in C++ for a variety of purposes, such as callbacks, event handling, and dynamic dispatch. They are particularly useful in situations where the exact function to be called is not known until runtime, or where multiple functions with the same signature are used interchangeably.
9. Explain constructor types.
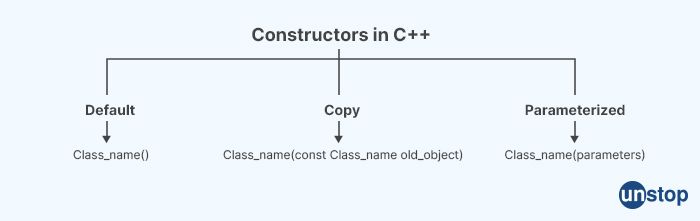
In C++, a constructor is a special member function that is called when an object is created. A constructor initializes the object's data members and prepares the object for use. There are three types of constructors in C++, including:
-
Default constructor: A default constructor is a constructor that takes no arguments. If no constructor is defined for a class, the compiler generates a default constructor automatically. The default constructor initializes the object's data members to default values (e.g., 0 for numeric types, and nullptr for pointers).
-
Parameterized constructor: A parameterized constructor is a constructor that takes one or more arguments. A parameterized constructor is used to initialize the object's data members to specific values. For example, a class that represents a point in 2D space might have a constructor that takes two arguments (x and y coordinates).
-
Copy constructor: A copy constructor is a constructor that takes a reference to an object of the same class as its argument. The copy constructor is used to create a new object that is a copy of an existing object. The copy constructor initializes the new object's data members to the same values as the existing object's data members.
Constructors are an important feature of object-oriented programming and are used to ensure that objects are properly initialized and ready for use. By defining different types of constructors, you can customize the behavior of object creation and initialization to suit your needs.
10. Explain SQL Joins.
In SQL, a join is used to combine rows from two or more tables based on a related column between them. There are several types of SQL joins:
1. Inner join: An inner join returns only the rows from both tables that have matching values in the join condition. It is the most commonly used type of join. Here's an example:
SELECT *
FROM table1
INNER JOIN table2 ON table1.column = table2.column;
2. Left join: A left join returns all the rows from the left table, and the matching rows from the right table. If there is no match in the right table, NULL values are returned. Here's an example:
SELECT *
FROM table1
LEFT JOIN table2 ON table1.column = table2.column;
3. Right join: A right join returns all the rows from the right table, and the matching rows from the left table. If there is no match in the left table, NULL values are returned. Here's an example:
SELECT *
FROM table1
RIGHT JOIN table2 ON table1.column = table2.column;
4. Full outer join: A full outer join returns all the rows from both tables, and NULL values are returned for non-matching rows. Here's an example:
SELECT *
FROM table1
FULL OUTER JOIN table2 ON table1.column = table2.column;
Joins are an essential feature of SQL, as they allow you to combine data from different tables and retrieve only the information you need. By using the appropriate join type, you can control the behavior of the join and ensure that you get the results you expect.
11. What do you mean by the access specifiers?
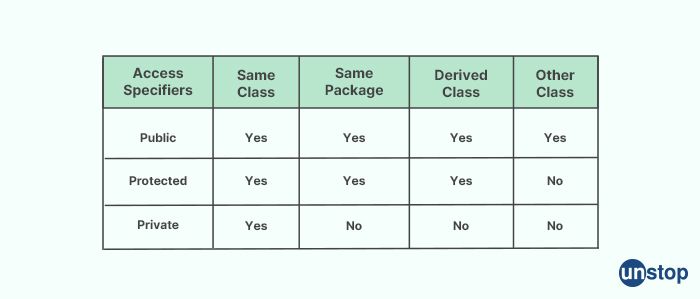
In object-oriented programming, access specifiers (access modifiers) are keywords that determine the visibility and accessibility of class members (e.g., data members and member functions) to the outside world. There are three access modifiers in C++:
-
Public: Members declared as public are accessible from anywhere, both inside and outside the class. This means that any function or object can access public members of a class.
-
Private: Members declared as private are only accessible from within the class. This means that no outside function or object can access private members of a class.
-
Protected: Members declared as protected are accessible from within the class and its subclasses (i.e., derived classes). This means that no outside function or object can access protected members of a class, but subclasses can.
Access specifiers allow you to control the level of abstraction and encapsulation in your code.
12. Explain the concepts of threads.
Threads are essential for parallel processing. Often in an operating system, you run multiple applications. These processes are split into multiple execution units that the process executes separately; this makes the computer fast. All the threads have individual memory space and resources for execution. There are mainly three types of threads: user threads, kernel threads, and kernel-only threads.
13. Differentiate between the public and private cloud.
The public cloud and private cloud are two deployment models for cloud computing, with different characteristics and use cases.
Public Cloud: A public cloud is a cloud infrastructure that is provided and managed by a third-party cloud service provider, such as Amazon Web Services (AWS), Microsoft Azure, or Google Cloud. The public cloud is accessible to anyone over the internet, and customers pay for the cloud resources they use on a pay-as-you-go basis.
In a public cloud, resources such as servers, storage, and networking are shared by multiple customers, and the cloud provider is responsible for managing and maintaining the infrastructure. Public clouds are generally more affordable, flexible, and scalable than private clouds, but they can also have higher security risks, limited customization options, and potential performance issues due to shared resources.
Private Cloud: A private cloud, on the other hand, is a cloud infrastructure that is dedicated to a single organization or business. It is usually deployed on-premises or in a private data center, and it is managed by the organization's IT department or a third-party vendor. In a private cloud, the resources are not shared with other organizations, and the cloud provider has full control over the infrastructure, including security, compliance, and customization options.
Private clouds are generally more secure, reliable, and customizable than public clouds, but they can also be more expensive and less flexible due to the need for dedicated resources.
14. Differentiate between abstract class and interface.
In object-oriented programming, both abstract classes and interfaces are used to define common behavior that can be implemented by different classes. However, there are some differences between the two concepts.
-
Definition: An abstract class is a class that cannot be instantiated and is meant to be subclassed. It can contain both abstract and concrete methods, as well as fields, constructors, and other members. An interface, on the other hand, is a collection of abstract methods and constants that define a contract for the behavior of classes that implement the interface.
-
Implementation: An abstract class can provide a partial implementation of its methods, which means that it can contain both abstract and concrete methods. A concrete class that extends an abstract class must implement all its abstract methods, but can also override its concrete methods. An interface, however, only contains abstract methods and constants, and does not provide any implementation. A class that implements an interface must provide an implementation for all its methods.
-
Multiple inheritance: A class can extend only one abstract class, but it can implement multiple interfaces. This is because an abstract class is a concrete implementation of a class hierarchy, while an interface defines a contract for behavior that can be implemented by multiple classes.
-
Access modifiers: An abstract class can have public, protected, and private members, while an interface can only have public members. This is because an interface is meant to be a public contract for behavior that can be implemented by different classes, while an abstract class is a concrete implementation of a class hierarchy.
15. Differentiate between a static method and an instance method.
In object-oriented programming, there are two types of methods: static methods and instance methods. Here are the differences between the two:
-
Definition: A static method is a method that belongs to a class and not to a specific instance of that class. It can be called using the class name, without creating an instance of the class. An instance method, on the other hand, is a method that belongs to a specific instance of a class. It can be called only on an instance of the class, and not on the class itself.
-
Access to class members: A static method can only access static members (fields or other methods) of the class, while an instance method can access both static and non-static members of the class.
-
Access to "this": A static method does not have access to the "this" keyword, as it does not operate on a specific instance of the class. An instance method, however, has access to the "this" keyword, which refers to the current instance of the class.
-
Method invocation: A static method is invoked using the class name, while an instance method is invoked using an instance of the class.
-
Overriding: Static methods cannot be overridden, as they are associated with the class itself and not with a specific instance of the class. Instance methods, on the other hand, can be overridden by a subclass.
16. Write a program to reverse a string using the Strrev Method.
In C++, the strrev() method is not a part of the standard library. Instead, it is a function provided by the string.h header file in the C standard library. Here's an example program that demonstrates how to reverse a string using the strrev() function:
#include
#include
using namespace std;
int main() {
char str[] = "hello world";
cout << "Original string: " << str << endl;
strrev(str);
cout << "Reversed string: " << str << endl;
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgojaW5jbHVkZSA8c3RyaW5nLmg+CnVzaW5nIG5hbWVzcGFjZSBzdGQ7CgppbnQgbWFpbigpIHsKY2hhciBzdHJbXSA9ICJoZWxsbyB3b3JsZCI7CmNvdXQgPDwgIk9yaWdpbmFsIHN0cmluZzogIiA8PCBzdHIgPDwgZW5kbDsKCnN0cnJldihzdHIpOwoKY291dCA8PCAiUmV2ZXJzZWQgc3RyaW5nOiAiIDw8IHN0ciA8PCBlbmRsOwpyZXR1cm4gMDsKfQ==
int main()
{
char charac[100]
printf(17. Differentiate between interpreter, compiler, and assembler.
Interpreter, compiler, and assembler are three different types of software used in computer programming. Here are the differences between the three:
-
Interpreter: An interpreter is a type of software that directly executes the source code of a program, line by line. It reads the program code, interprets it, and executes it on the fly. The output is generated immediately after each line is executed. Interpreters are often used for programming languages like Python, Ruby, and Perl.
-
Compiler: A compiler is a type of software that translates the source code of a program into machine code (binary code) that can be directly executed by the computer. The entire program is first compiled, and the output is a binary file that can be executed many times without recompiling. Compilers are often used for programming languages like C, C++, and Java.
-
Assembler: An assembler is a type of software that translates assembly language code into machine code. Assembly language is a low-level programming language that is specific to a particular computer architecture. An assembler is used to convert the assembly code into machine code that can be executed by the computer.
18. Differentiate between application context and bean factory.
In the Spring Framework, both Application Context and Bean Factory are used for managing the lifecycle of Spring beans. However, there are some differences between the two:
-
Initialization time: Bean Factory is a basic container that provides the configuration framework and basic functionality, but it is not fully loaded at startup. The beans are created when requested for the first time. On the other hand, Application Context preloads all the beans at the time of initialization.
-
Configuration: Bean Factory provides basic configuration support, while Application Context provides advanced configuration support, including support for internationalization, event propagation, and support for different scopes of beans.
-
Functionality: Application Context provides a richer set of features and services than Bean Factory, including support for AOP, JDBC, JNDI, and JMS. It also supports annotation-based configuration and provides a unified expression language.
-
Performance: Bean Factory is faster to start up than Application Context since it does not need to create all beans during initialization. However, Application Context provides faster access to beans since all beans are preloaded.
19. Describe the importance of the finalize() method in Java.
The finalize() method in Java is a method that is called by the garbage collector when an object is about to be destroyed. The purpose of the finalize() method is to allow an object to perform any necessary cleanup operations before it is destroyed. Here are some points that describe the importance of the finalize() method:
-
Resource cleanup: The finalize() method can be used to release resources that an object may be holding, such as file handles, database connections, or network sockets. By releasing these resources in the finalize() method, we can ensure that they are properly cleaned up before the object is destroyed.
-
Error handling: The finalize() method can be used to catch and handle any exceptions that may occur during the destruction of an object. This allows the object to gracefully handle any errors that may occur during cleanup.
-
Object finalization: The finalize() method is also used to perform any necessary cleanup operations on an object before it is finalized. For example, an object may need to close any open files or release any locks before it is destroyed.
-
Memory management: The finalize() method plays an important role in memory management in Java. When an object is no longer needed, the garbage collector is responsible for reclaiming its memory. By using the finalize() method, we can ensure that any necessary cleanup operations are performed before the memory is reclaimed.
20. Explain the role of polymorphism in Java.
Polymorphism is a core concept in object-oriented programming and refers to the ability of an object to take on many forms. In Java, polymorphism allows objects of different classes to be treated as if they were objects of the same class, which can greatly simplify code and improve maintainability.
The role of polymorphism in Java can be described in the following ways:
-
Code reusability: Polymorphism enables code reusability by allowing multiple objects of different classes to be treated as if they were objects of the same class.
-
Flexibility: Polymorphism allows objects to be created that can work with many different types of data.
-
Overriding: Polymorphism allows methods in a subclass to override methods in a superclass or interface.
-
Dynamic binding: Polymorphism enables dynamic binding, which means that the correct method implementation is chosen at runtime, based on the actual type of the object being referred to.
21. How helpful is cloud computing?
Cloud computing has become increasingly popular in recent years, and for good reason. It offers numerous benefits and advantages to businesses and individuals alike. Here are some ways in which cloud computing can be helpful:
-
Cost-effective: Cloud computing can help reduce costs associated with IT infrastructure and maintenance, as it eliminates the need for companies to invest in and maintain their own hardware and software.
-
Scalability: Cloud computing provides the ability to scale resources up or down as needed, allowing businesses to adjust their computing capacity based on changing demands.
-
Flexibility: Cloud computing allows users to access their data and applications from anywhere with an internet connection, providing greater flexibility and enabling remote work.
-
Disaster recovery: Cloud computing can provide an effective disaster recovery solution, as data is stored remotely and can be easily recovered in the event of a disaster.
-
Collaboration: Cloud computing enables real-time collaboration among teams, regardless of their physical location, as they can access shared files and applications from anywhere.
-
Security: Cloud computing providers often have dedicated security teams and resources to protect data and applications from potential threats.
Overall, cloud computing can be extremely helpful for businesses and individuals, providing cost savings, scalability, flexibility, disaster recovery, collaboration, and security.
22. List various cloud computing service models.
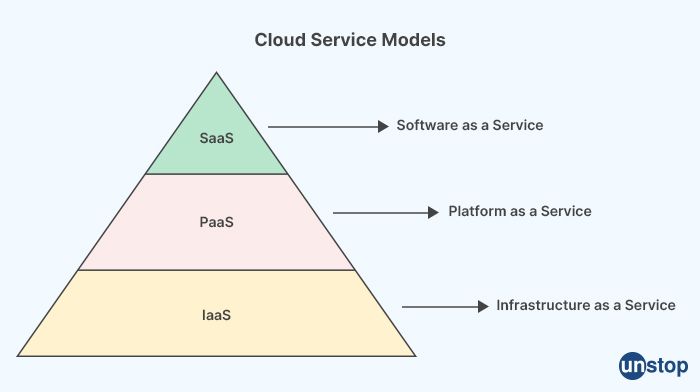
There are three main cloud computing service models:
-
Infrastructure as a Service (IaaS): IaaS provides the basic infrastructure resources, such as virtual machines, storage, and network components, needed to run and manage applications. With IaaS, the cloud provider is responsible for managing the infrastructure, while the user is responsible for managing the operating system, applications, and data.
-
Platform as a Service (PaaS): PaaS provides a platform for building, deploying, and managing applications, without the need for the user to manage the underlying infrastructure. The cloud provider provides the hardware, operating system, and runtime environment, while the user is responsible for developing and deploying the applications.
-
Software as a Service (SaaS): SaaS provides software applications that are hosted and managed by the cloud provider, and are accessed by users through a web browser or other client application. With SaaS, the cloud provider is responsible for managing the infrastructure, operating system, and application, while the user only needs to use the application.
23. List the features of Big Data
The features of big data can be summarized as follows:
-
Volume: Big data is characterized by its large volume, often measured in terabytes or petabytes. It includes massive amounts of data generated from various sources such as social media, internet traffic, and sensor data.
-
Velocity: Big data is generated at a high velocity, with data being created and collected at an unprecedented rate. This real-time data is used for immediate decision-making, for example in financial trading or cybersecurity.
-
Variety: Big data comes in various formats such as structured, semi-structured, and unstructured data. Structured data includes data from traditional databases, semi-structured data includes data such as XML and JSON, and unstructured data includes emails, videos, images, and social media posts.
-
Veracity: Big data is often messy and inconsistent, with varying levels of accuracy and completeness. It requires data cleaning and preprocessing before analysis can be performed.
-
Value: Big data has the potential to create significant value for organizations, such as identifying new revenue opportunities, improving customer experience, and optimizing business processes.
-
Variability: Big data can be highly variable in terms of the volume, velocity, and variety of data that is generated. This variability can create challenges for storing, processing, and analyzing big data.
-
Complexity: Big data can be highly complex due to the vast amount of data generated, the variety of data sources, and the need for sophisticated analytical tools and techniques to extract meaningful insights.
24. What does a pointer do in C++?
In C++, a pointer is a variable that stores the memory address of another variable. Pointers are used to manipulate data stored in memory directly, instead of copying the data to a new location.
Using pointers, it is possible to perform operations such as passing arguments to functions by reference, dynamic memory allocation, and implementing data structures such as linked lists, trees, and graphs.
The main advantage of using pointers is that they allow efficient manipulation of data in memory, particularly when working with large datasets. However, working with pointers requires careful management of memory, as incorrect use of pointers can lead to memory leaks and other programming errors.
In C++, pointers are denoted by the use of the asterisk (*) symbol. For example, to declare a pointer to an integer variable named "x", we would use the syntax:
int x = 10;
int *p = &x; // declare a pointer to x
25. What are constraints in SQL?
In SQL, constraints are rules that can be applied to tables to enforce data integrity and ensure that the data conforms to certain conditions or rules. Constraints can be applied at the column level or at the table level, and are used to ensure that data is consistent and accurate.
There are several types of constraints that can be applied in SQL, including:
-
NOT NULL: This constraint ensures that a column cannot have a null value.
-
UNIQUE: This constraint ensures that a column or set of columns contains only unique values.
-
PRIMARY KEY: This constraint specifies a column or set of columns that uniquely identify each row in a table.
-
FOREIGN KEY: This constraint establishes a link between two tables by specifying that a column in one table must match a primary key in another table.
-
CHECK: This constraint specifies a condition that must be met for a column to be valid.
-
DEFAULT: This constraint specifies a default value for a column if no value is provided.
Constraints are an important part of database design, as they ensure that data is consistent and accurate, which is critical for maintaining the integrity of the database. By enforcing constraints on the data, SQL provides a way to ensure that the data conforms to the desired structure and business rules.
26. Explain DBMS
DBMS stands for Database Management System, which is a software system that enables users to manage, organize, and access data stored in a database. A database is a collection of data that is organized in a specific way to make it easy to search, manage, and retrieve information.
A DBMS provides a set of tools and features that allow users to create, update, and maintain the database. This includes creating tables to store data, defining relationships between tables, defining constraints to ensure data integrity, and creating queries to retrieve data.
DBMS systems provide a wide range of benefits to organizations, including:
- Improved data sharing: A DBMS enables multiple users to access the same data simultaneously, which improves collaboration and data sharing across teams and departments.
- Improved data security: DBMS systems provide security features such as user authentication, access control, and encryption, which helps to protect sensitive data from unauthorized access.
- Improved data integrity: DBMS systems enforce constraints to ensure that data is consistent and accurate, which improves the reliability and quality of the data.
- Improved data management: DBMS systems provide tools for data backup and recovery, which helps to prevent data loss in the event of a system failure or other disaster.
- Improved data accessibility: DBMS systems provide tools for creating queries to retrieve data, which enables users to quickly and easily access the data they need.
27. How can you implement multiple inheritances in Java?
In Java, multiple inheritance is not directly supported, which means that a class cannot inherit from multiple classes at the same time. This was done deliberately to avoid the problems that can arise from multiple inheritance, such as the diamond problem.
However, Java provides an alternative approach to multiple inheritance using interfaces. An interface in Java is similar to a class, but it defines only abstract methods and constants. A class can implement multiple interfaces, which allows it to inherit the abstract methods and constants defined in those interfaces.
Here's an example:
interface A {
void methodA();
}
interface B {
void methodB();
}
class C implements A, B {
public void methodA() {
System.out.println("Implementing method A");
}
public void methodB() {
System.out.println("Implementing method B");
}
}
public class Main {
public static void main(String[] args) {
C obj = new C();
obj.methodA();
obj.methodB();
}
}
In this example, we have two interfaces A and B, each with a single abstract method. We then define a class C that implements both interfaces by providing implementations for both methods. Finally, in the main method, we create an object of class C and call both methods on it.
28. What is init?
In computer programming, "init" is a shorthand for "initialize" and usually refers to a function or method that performs initialization of some kind. Initialization is the process of setting up variables, objects, or other resources before they are used in a program.
In some programming languages, such as Python, the __init__ method is a special method that is automatically called when an object is created. This method is used to initialize the object's properties and can accept arguments that are passed in when the object is created.
For example, in Python, the __init__ method is used to initialize the properties of a class:
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
person1 = Person("John", 30)
Y2xhc3MgUGVyc29uOgpkZWYgX19pbml0X18oc2VsZiwgbmFtZSwgYWdlKToKc2VsZi5uYW1lID0gbmFtZQpzZWxmLmFnZSA9IGFnZQoKcGVyc29uMSA9IFBlcnNvbigiSm9obiIsIDMwKQ==
29. Why do we need a Domain Name System?
We need a Domain Name System (DNS) to translate human-readable domain names, such as www.example.com, into machine-readable IP addresses, such as 192.168.1.1.
DNS provides a distributed and hierarchical database that allows computers to look up the IP address associated with a domain name. When a user types a domain name into their web browser, the browser sends a request to a DNS resolver (usually provided by their internet service provider) to look up the IP address for that domain. The resolver then sends a series of queries to different DNS servers to find the authoritative DNS server for that domain. Once the authoritative server is found, the resolver can obtain the IP address associated with the domain name and return it to the user's browser.
Without DNS, users would have to remember the IP address of every website they wanted to visit, which would be difficult and impractical. DNS also allows websites to change their IP addresses without requiring users to update their bookmarks or memorize new IP addresses.
30. List languages based on OOPs concepts.
There are many programming languages that are based on Object-Oriented Programming (OOP) concepts. Some of the most popular ones include:
- Java
- C++
- Python
- Ruby
- PHP
- Objective-C
- Swift
- Kotlin
- Smalltalk
- Scala
- C#
- Perl
- JavaScript
- Lua
All of these languages share the core concepts of OOP, such as objects, classes, inheritance, encapsulation, and polymorphism. However, they may differ in syntax, implementation, and additional features.
31. Explain a collection framework.
In Java, a collection framework is a group of classes and interfaces that provide a way to store, organize, and manipulate groups of objects. It provides a unified architecture for working with different types of collections such as lists, sets, maps, and queues.
The collection framework consists of several core interfaces and classes that serve as the foundation for collections:
-
Collection: It is the root interface for all the collections. It defines the basic operations that are common to all collections, such as adding, removing, and iterating over elements.
-
List: It is an ordered collection that allows duplicate elements. It provides positional access to elements and supports operations such as adding, removing, and searching for elements.
-
Set: It is a collection that does not allow duplicate elements. It provides operations for adding, removing, and checking if an element is present in the set.
-
Map: It is a collection that stores key-value pairs. It provides operations for adding, removing, and retrieving values based on their keys.
-
Queue: It is a collection that represents a queue data structure. It provides operations for adding, removing, and inspecting elements in the queue.
Each of these interfaces has multiple implementations that provide different performance characteristics and behavior.
32. Explain the concept of String Buffer.
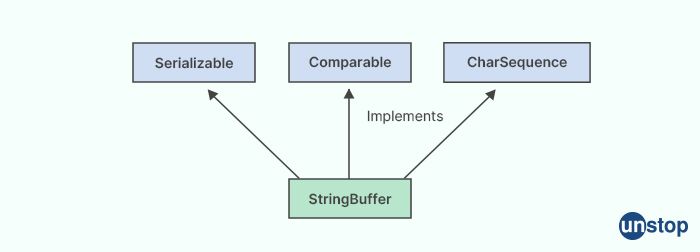
In Java, String Buffer is a class that is used to represent mutable strings. It provides a way to create a string object that can be modified, appended, or deleted without creating a new object each time. The String Buffer class is part of the Java String handling classes, which also include the String class and the StringBuilder class.
The main advantage of the String Buffer class over the String class is that it is mutable, while the String class is immutable. This means that once a string object is created with the String class, it cannot be modified. However, with the String Buffer class, a string object can be modified, allowing for more flexibility in programming.
Some of the main methods of the String Buffer class include:
- append(): This method is used to add text to the end of the buffer.
- insert(): This method is used to insert text into the buffer at a specific position.
- delete(): This method is used to delete text from the buffer.
- replace(): This method is used to replace text in the buffer with new text.
33. Does an Indexed Sequential file have any disadvantages?
Yes, Indexed Sequential File (ISAM) has some disadvantages as follows:
-
Limited size: Indexed Sequential File has a limited size because the index takes up a significant amount of space. If the file becomes too large, the index may not fit in memory, causing performance issues.
-
Index maintenance overhead: Since the index is maintained alongside the data, any modification to the data may require changes to the index. This can be a time-consuming process, especially for large files.
-
Inflexibility: Indexed Sequential File is not as flexible as other file organization methods. It cannot support dynamic allocation of records, and the file size is limited to the size of the pre-allocated space.
-
Performance: ISAM has a slower performance compared to other file organization methods such as direct access or hashing because of the need to maintain the index.
-
Complex implementation: ISAM requires complex implementation as it requires both a sequential and index file. The implementation is complex and requires expertise in programming.
-
Not suitable for real-time applications: ISAM is not suitable for real-time applications as the response time is unpredictable due to the overhead of maintaining the index.
-
Not suitable for distributed systems: ISAM is not suitable for distributed systems because maintaining the index across multiple systems can be complex and time-consuming.
HCL Interview Questions: HR Round
34. Tell us about yourself.
Almost all interviewers ask this question. It would help if you tell them about yourself as an individual, such as your goals, ambitions, passions, inspirations, and achievements. The answers must be truthful, and they should not feel like a recitation.
35. What are your long-term and short-term goals?
This question aims to determine your planning ability. You must have dreams and aspirations, and they are your long-term goals. Short-term goals include the things you need to complete in the short term to achieve those dreams.
36. Do you have leadership qualities?
An interviewer might ask this question to know what you expect from superiors and what you will offer your subordinate. Not everyone is a leader or a follower, so answer this question as truthfully as possible. Because you may get tasks depending on this answer, and you don't want to get a job you don't like.
37. Why do you want to join HCL?
Almost all companies want to ask - Why do you want to work here? They want to know if you have researched well. While answering, try to tell them how you can contribute to HCL; you can also tell them how you want to develop your career.
38. What are your strengths and weaknesses?
This question is almost a cliché, and here, interviewers want to know what type of tasks they can assign you. Moreover, these questions are critical as your professional strengths and weaknesses may determine if you are a good fit. Try to answer this question as a story; this can grab his/her attention.
HCL Technologies Recruitment Process
HCL seeks employees who have solid technical knowledge and the ability to work independently. In addition, you must be able to understand concepts and learn from your mistakes quickly. The company frequently conducts on-campus and off-campus drives. The HCL recruitment process contains four steps.
- Written Test: This test will have choice-based questions. The questions will test your qualitative and quantitative ability and verbal reasoning. Experienced professionals usually don't have this round; however, they may have more technical interview rounds. This 60-minute test will have 15 questions each on qualitative aptitude, reasoning, verbal ability, and technical ability.
- Group Discussion: This round assesses your ability to work in a group. You must be able to think quickly and communicate well in groups, and your success will depend on your contribution to the group discussion. To practice group discussion, you must get together with your friends and discuss various topics related to the job role. This practice will boost your confidence.
- Technical Interview: Technical interview tests your technical knowledge and expertise. You will get questions requiring coding skills and computer knowledge. The questions can come from the core services provided by HCL. So, ensure that you understand their benefits.
- HR Interview: In this round, the interviewer will mostly ask questions to assess your personality. He/she will evaluate your communication skills and confidence, determining if you can work in a stressful environment. You can expect questions about strengths, weaknesses, regrets, achievements, etc.
HCL believes that employees must be a part of the innovations inside the company. Its culture is people-first. Therefore, working at HCL would be a great experience for your career. Diligent preparation and a positive attitude can get you your dream job at HCL. Good Luck!
Stay ahead! Never miss out on any trending job or internship opportunity!
Suggested reads:
Login to continue reading
And access exclusive content, personalized recommendations, and career-boosting opportunities.
Don't have an account? Sign up
Never miss an
Update

Featured Opportunities
Top-Rated Practice by Students





Subscribe
to our newsletter
Blogs you need to hog!

How To Write Finance Cover Letter For Morgan Stanley (+Free Sample!)
Unstop

55+ Data Structure Interview Questions For 2026 (Detailed Answers)
Muskaan Mishra

How To Negotiate Salary With HR: Tips And Insider Advice
Srishti Magan

80+ TCS NQT Interview Questions & Answers (2026) You Must Prepare
Urvashi Singhal
Comments
Add comment