
Asian Paints Alchemy 2026
Company Interview Questions for Freshers
- TCS Technical Interview Questions & Answers
- TCS Managerial Interview Questions & Answers
- TCS HR Interview Questions & Answers
- Overview of Cognizant Recruitment Process
- Cognizant Interview Questions: Technical
- Cognizant Interview Questions: HR Round
- Overview of Wipro Technologies Recruitment Rounds
- Wipro Interview Questions
- Technical Round
- HR Round
- Online Assessment Sample Questions
- Frequently Asked Questions
- Overview of Google Recruitment Process
- Google Interview Questions: Technical
- Google Interview Questions: HR round
- Interview Preparation Tips
- About Google
- Deloitte Technical Interview Questions
- Deloitte HR Interview Questions
- Deloitte Recruitment Process
- Technical Interview Questions and Answers
- Level 1 difficulty
- Level 2 difficulty
- Level 3 difficulty
- Behavioral Questions
- Eligibility Criteria for Mindtree Recruitment
- Mindtree Recruitment Process: Rounds Overview
- Skills required to crack Mindtree interview rounds
- Mindtree Recruitment Rounds: Sample Questions
- About Mindtree
- Preparing for Microsoft interview questions
- Microsoft technical interview questions
- Microsoft behavioural interview questions
- Aptitude Interview Questions
- Technical Interview Questions
- Easy
- Intermediate
- Hard
- HR Interview Questions
- Eligibility criteria
- Recruitment rounds & assessments
- Tech Mahindra interview questions - Technical round
- Tech Mahindra interview questions - HR round
- Hiring process at Mphasis
- Mphasis technical interview questions
- Mphasis HR interview questions
- About Mphasis
- Technical interview questions
- HR interview questions
- Recruitment process
- About Virtusa
- Goldman Sachs Interview Process
- Technical Questions for Goldman Sachs Interview
- Sample HR Question for Goldman Sachs Interview
- About Goldman Sachs
- Nagarro Recruitment Process
- Nagarro HR Interview Questions
- Nagarro Aptitude Test Questions
- Nagarro Technical Test Questions
- About Nagarro
- PwC Recruitment Process
- PwC Technical Interview Questions: Freshers and Experienced
- PwC Interview Questions for HR Rounds
- PwC Interview Preparation
- Frequently Asked Questions
- EY Technical Interview Questions (2023)
- EY Interview Questions for HR Round
- About EY
- Morgan Stanley Recruitment Process
- HR Questions for Morgan Stanley Interview
- HR Questions for Morgan Stanley Interview
- About Morgan Stanley
- Recruitment Process at Flipkart
- Technical Flipkart Interview Questions
- Code-Based Flipkart Interview Questions
- Sample Flipkart Interview Questions- HR Round
- Conclusion
- FAQs
- Recruitment Process at Paytm
- Technical Interview Questions for Paytm Interview
- HR Sample Questions for Paytm Interview
- About Paytm
- Most Probable Accenture Interview Questions
- Accenture Technical Interview Questions
- Accenture HR Interview Questions
- Amazon Recruitment Process
- Amazon Interview Rounds
- Common Amazon Interview Questions
- Amazon Interview Questions: Behavioral-based Questions
- Amazon Interview Questions: Leadership Principles
- Company-specific Amazon Interview Questions
- 43 Top Technical/ Coding Amazon Interview Questions
- Juspay Recruitment: Stages and Timeline
- Juspay Interview Questions and Answers
- How to prepare for Juspay interview questions
- Prepare for the Juspay Interview: Stages and Timeline
- Frequently Asked Questions
- Adobe Interview Questions - Technical
- Adobe Interview Questions - HR
- Recruitment Process at Adobe
- About Adobe
- Cisco technical interview questions
- Sample HR interview questions
- The recruitment process at Cisco
- About Cisco
- JP Morgan interview questions (Technical round)
- JP Morgan interview questions HR round)
- Recruitment process at JP Morgan
- About JP Morgan
- Wipro Elite NTH: Selection Process
- Wipro Elite NTH Technical Interview Questions
- Wipro Elite NTH Interview Round- HR Questions
- BYJU's BDA Interview Questions
- BYJU's SDE Interview Questions
- BYJU's HR Round Interview Questions
- A Quick Overview of the KPMG Recruitment Process
- Technical Questions for KPMG Interview
- HR Questions for KPMG Interview
- About KPMG
- DXC Technology Interview Process
- DCX Technical Interview Questions
- Sample HR Questions for DXC Technology
- About DXC Technology
- Recruitment Process at PayPal
- Technical Questions for PayPal Interview
- HR Sample Questions for PayPal Interview
- About PayPal
- Capgemini Recruitment Rounds
- Capgemini Interview Questions: Technical round
- Capgemini Interview Questions: HR round
- Preparation tips
- FAQs
- Technical interview questions for Siemens
- Sample HR questions for Siemens
- The recruitment process at Siemens
- About Siemens
- HCL Technical Interview Questions
- HR Interview Questions
- HCL Technologies Recruitment Process
- List of EPAM Interview Questions for Technical Interviews
- About EPAM
- Atlassian Interview Process
- Top Skills for Different Roles at Atlassian
- Atlassian Interview Questions: Technical Knowledge
- Atlassian Interview Questions: Behavioral Skills
- Atlassian Interview Questions: Tips for Effective Preparation
- Walmart Recruitment Process
- Walmart Interview Questions and Sample Answers (HR Round)
- Walmart Interview Questions and Sample Answers (Technical Round)
- Tips for Interviewing at Walmart and Interview Preparation Tips
- Frequently Asked Questions
- Uber Interview Questions For Engineering Profiles: Coding
- Technical Uber Interview Questions: Theoretical
- Uber Interview Question: HR Round
- Uber Recruitment Procedure
- About Uber Technologies Ltd.
- Intel Technical Interview Questions
- Computer Architecture Intel Interview Questions
- Intel DFT Interview Questions
- Intel Interview Questions for Verification Engineer Role
- Recruitment Process Overview
- Important Accenture HR Interview Questions
- Points to remember
- What is Selenium?
- What are the components of the Selenium suite?
- Why is it important to use Selenium?
- What's the major difference between Selenium 3.0 & Selenium 2.0?
- What is Automation testing and what are its benefits?
- What are the benefits of Selenium as an Automation Tool?
- What are the drawbacks to using Selenium for testing?
- Why should Selenium not be used as a web application or system testing tool?
- Is it possible to use selenium to launch web browsers?
- What does Selenese mean?
- What does it mean to be a locator?
- Identify the main difference between "assert", and "verify" commands within Selenium
- What does an exception test in Selenium mean?
- What does XPath mean in Selenium? Describe XPath Absolute & XPath Relation
- What is the difference in Xpath between "//"? and "/"?
- What is the difference between "type" and the "typeAndWait" commands within Selenium?
- Distinguish between findElement() & findElements() in context of Selenium
- How long will Selenium wait before a website is loaded fully?
- What is the difference between the driver.close() and driver.quit() commands in Selenium?
- Describe the different navigation commands that Selenium supports
- What is Selenium's approach to the same-origin policy?
- Explain the difference between findElement() in Selenium and findElements()
- Explain the pause function in SeleniumIDE
- Explain the differences between different frameworks and how they are connected to Selenium's Robot Framework
- What are your thoughts on the Page Object Model within the context of Selenium
- What are your thoughts on Jenkins?
- What are the parameters that selenium commands come with a minimum?
- How can you tell the differences in the Absolute pathway as well as Relative Path?
- What's the distinction in Assert or Verify declarations within Selenium?
- What are the points of verification that are in Selenium?
- Define Implicit wait, Explicit wait, and Fluent
- Can Selenium manage windows-based pop-ups?
- What's the definition of an Object Repository?
- What is the main difference between obtainwindowhandle() as well as the getwindowhandles ()?
- What are the various types of Annotations that are used in Selenium?
- What is the main difference in the setsSpeed() or sleep() methods?
- What is the way to retrieve the alert message?
- How do you determine the exact location of an element on the web?
- Why do we use Selenium RC?
- What are the benefits or advantages of Selenium RC?
- Do you have a list of the technical limitations when making use of Selenium RC? Selenium RC?
- What's the reason to utilize the TestNG together with Selenium?
- What Language do you prefer to use to build test case sets in Selenium?
- What are Start and Breakpoints?
- What is the purpose of this capability relevant in relation to Selenium?
- When do you use AutoIT?
- Do you have a reason why you require Session management in Selenium?
- Are you able to automatize CAPTCHA?
- How can we launch various browsers on Selenium?
- Why should you select Selenium rather than QTP (Quick Test Professional)?
- Airbus Interview Questions and Answers: HR/ Behavioral
- Industry/ Company-Specific Airbus Interview Questions
- Airbus Interview Questions and Answers: Aptitude
- Airbus Software Engineer Interview Questions and Answers: Technical
- Importance of Spring Framework
- Spring Interview Questions (Basic)
- Advanced Spring Interview Questions
- C++ Interview Questions and Answers: The Basics
- C++ Interview Questions: Intermediate
- C++ Interview Questions And Answers With Code Examples
- C++ Interview Questions and Answers: Advanced
- Test Your Skills: Quiz Time
- MBA Interview Questions: B.Com Economics
- B.Com Marketing
- B.Com Finance
- B.Com Accounting and Finance
- Business Studies
- Chartered Accountant
- Q1. Please tell us something about yourself/ Introduce yourself to us.
- Q2. Describe yourself in one word.
- Q3. Tell us about your strengths and weaknesses.
- Q4. Why did you apply for this job/ What attracted you to this role?
- Q5. What are your hobbies?
- Q6. Where do you see yourself in five years OR What are your long-term goals?
- Q7. Why do you want to work with this company?
- Q8. Tell us what you know about our organization
- Q9. Do you have any idea about our biggest competitors?
- Q10. What motivates you to do a good job?
- Q11. What is an ideal job for you?
- Q12. What is the difference between a group and a team?
- Q13. Are you a team player/ Do you like to work in teams?
- Q14. Are you good at handling pressure/ deadlines?
- Q15. When can you start?
- Q16. How flexible are you regarding overtime?
- Q17. Are you willing to relocate for work?
- Q18. Why do you think you are the right candidate for this job?
- Q19. How can you be an asset to the organization?
- Q20. What is your salary expectation?
- Q21. How long do you plan to remain with this company?
- Q22. What is your objective in life?
- Q23. Would you like to pursue your Master's degree anytime soon?
- Q24. How have you planned to achieve your career goal?
- Q25. Can you tell us about your biggest achievement in life?
- Q26. What was the most challenging decision you ever made?
- Q27. What kind of work environment do you prefer to work in?
- Q28. What is the difference between a smart worker and a hard worker?
- Q29. What will you do if you don't get hired?
- Q30. Tell us three things that are most important for you in a job.
- Q31. Who is your role model and what have you learned from him/her?
- Q32. In case of a disagreement, how do you handle the situation?
- Q33. What is the difference between confidence and overconfidence?
- Q34. If you have more than enough money in hand right now, would you still want to work?
- Q35. Do you have any questions for us?
- Interview Tips for Freshers
- Tell me about yourself
- What are your greatest strengths?
- What are your greatest weaknesses?
- Tell me about something you did that you now feel a little ashamed of
- Why are you leaving (or did you leave) this position??
- 15+ resources for preparing most-asked interview questions
- CoCubes Interview Process Overview
- Common CoCubes Interview Questions
- Key Areas to Focus on for CoCubes Interview Preparation
- Conclusion
- Frequently Asked Questions (FAQs)
- Data Analyst Interview Questions With Answers
- About Data Analyst
Wipro Elite NTH 2026 Interview Questions For Freshers

The Elite National Talent Hunt (NTH) is a program launched by Wipro, aimed at attracting the brightest engineering talents throughout the country. The goal of this program is to provide equal job opportunities to India's most worthy and capable engineering talent.
If you want to make your way into the company through this route, this article will help you get a gist of the selection process and provide you with a good idea about the technical questions you must prepare for the Wipro interview.
Wipro Elite NTH: Selection Process
Wipro Elite NTH has 4 rounds which are as follows:
| Round 1 | Online Assessment |
| Round 2 | Essay Writing Round |
| Round 3 | Technical Interview Process |
| Round 4 | HR Interview Round |
Note: There is no negative marking in the online assessment round
The details of these rounds are as follows:

Wipro Elite NTH Technical Interview Questions
The candidates who sail through the online assessment and essay writing round are called for the interview rounds. The first one is the technical interview round. To help understand the type of questions in Wipro Elite NTH technical interview rounds, here is a list of 3o questions:

Q1. What is Object-Oriented Programming?
Object-Oriented Programming (OOP) is a programming paradigm that uses objects and classes for organizing and structuring code. It's based on the concept of "objects," which represent real-world entities or concepts and the interactions between them. OOP is widely used in software development because it promotes modularity, reusability, and a more organized way of writing code.
Here are some key concepts and principles of Object-Oriented Programming:
-
Objects: Objects are instances of classes and represent individual entities or things. They encapsulate data (attributes or properties) and behaviors (methods or functions) that operate on that data.
-
Classes: Classes serve as blueprints or templates for creating objects. They define the structure and behavior of objects. A class contains attributes (data members) and methods (functions) that are common to all objects created from that class.
-
Encapsulation: Encapsulation is the practice of bundling data (attributes) and methods (functions) that operate on the data into a single unit, i.e., an object. It hides the internal details of an object from the outside and exposes a well-defined interface for interacting with it. This helps in data protection and abstraction.
-
Inheritance: Inheritance allows you to create a new class (derived or subclass) based on an existing class (base or superclass). The derived class inherits the attributes and methods of the base class and can extend or override them. Inheritance promotes code reuse and the creation of specialized classes.
-
Polymorphism: Polymorphism allows objects of different classes to be treated as objects of a common superclass. It enables the same method name to behave differently based on the specific class of the object. Polymorphism is often achieved through method overriding and interfaces in OOP.
-
Abstraction: Abstraction is the process of simplifying complex reality by modeling classes based on the essential properties and behaviors. It allows developers to focus on what an object does rather than how it does it. Abstraction is a fundamental principle in OOP, enabling the creation of high-level, user-friendly interfaces.
Q2. Why do we need OOPs?
Object-Oriented Programming (OOP) offers several advantages and benefits, which is why it is widely used in software development. Here are some of the reasons why OOP is important and why we need it:
-
Modularity: OOP promotes modular design by breaking a complex system into smaller, self-contained units (objects or classes). Each class encapsulates data and behavior related to a specific aspect of the system. This makes it easier to manage, maintain, and extend the codebase.
-
Reusability: OOP encourages code reuse through inheritance and composition. You can create new classes by extending existing ones, inheriting their attributes and behaviors. This reduces code duplication and leads to more efficient development.
-
Abstraction: Abstraction allows developers to focus on essential characteristics and behavior of objects, while hiding the unnecessary details. This simplifies problem-solving and leads to more understandable and maintainable code.
-
Encapsulation: Encapsulation protects the integrity of data by hiding the internal state of objects and providing controlled access through methods. This prevents unintended interference with an object's data, which is crucial for data security and consistency.
-
Flexibility and Extensibility: OOP enables you to modify and extend the system without affecting other parts of the code. You can add new classes and methods or override existing ones to change the behavior of objects. This makes the code more adaptable to changing requirements.
-
Polymorphism: Polymorphism allows objects of different classes to be treated as instances of a common superclass. This simplifies code that interacts with objects and supports dynamic dispatch, where the appropriate method is chosen at runtime based on the object's actual class.
-
Organization: OOP provides a natural way to organize code, as it mirrors the structure of real-world objects and their interactions. This makes the codebase more intuitive and easier to navigate, especially for large and complex systems.
-
Maintainability: OOP makes it easier to maintain and update software. When a change is needed, developers can modify or extend individual classes without affecting the entire system. This localized impact reduces the risk of introducing bugs.
-
Collaborative Development: OOP promotes collaboration among development teams because classes and objects can be developed independently and later integrated into the system. This parallel development approach can speed up the project.
-
Real-World Modeling: OOP allows developers to model software after real-world objects, entities, and relationships. This makes the software more intuitive and understandable, both for developers and stakeholders.
-
Code Documentation: OOP encourages self-documenting code. The structure of classes, their attributes, and methods, along with well-chosen names, can serve as effective documentation for the code.
-
Community and Resources: OOP is a well-established paradigm with a vast community and extensive resources, including libraries, frameworks, and tools. Developers can leverage existing OOP resources to expedite development.
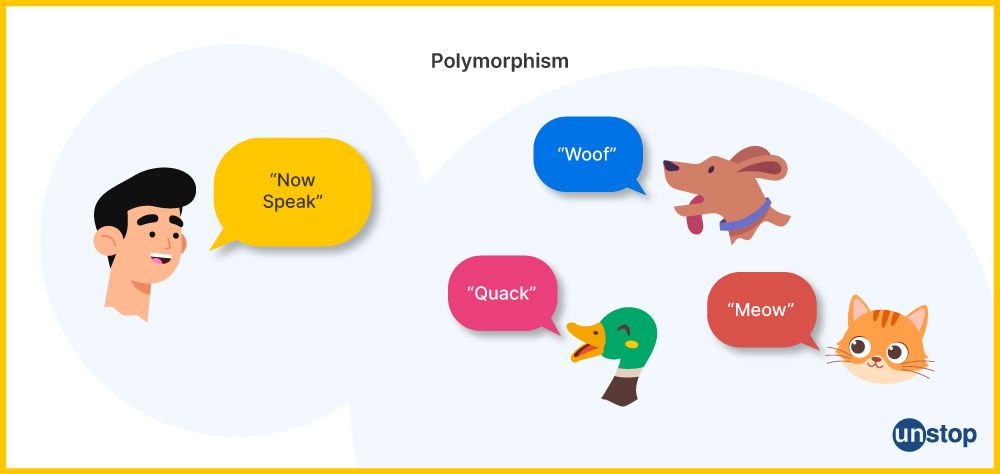
Q3. Explain polymorphism.
Polymorphism is a fundamental concept in Object-Oriented Programming (OOP) that allows objects of different classes to be treated as instances of a common superclass. It enables a single interface or method name to have different implementations based on the specific class of the object being operated upon.
In essence, polymorphism allows you to write more generic and reusable code because you can interact with objects in a uniform way, regardless of their specific types. This is typically achieved through method overriding and interfaces in OOP languages.
Example:
Consider a simple example using a superclass "Animal" and subclasses "Dog" and "Cat." Both "Dog" and "Cat" override the "makeSound" method, but each provides a different sound. When you interact with an "Animal" object, you can call the "makeSound" method without knowing whether it's a "Dog" or a "Cat" object. The specific implementation is determined at runtime.
Code:
#include <iostream>
class Animal {
public:
virtual void makeSound() {
std::cout << "Some generic animal sound" << std::endl;
}
};class Dog : public Animal {
public:
void makeSound() override {
std::cout << "Woof! Woof!" << std::endl;
}
};class Cat : public Animal {
public:
void makeSound() override {
std::cout << "Meow!" << std::endl;
}
};int main() {
Animal* myDog = new Dog();
Animal* myCat = new Cat();myDog->makeSound(); // Calls the Dog's makeSound method
myCat->makeSound(); // Calls the Cat's makeSound methoddelete myDog;
delete myCat;return 0;
}Output:
Woof! Woof!
Meow!
Q4. What exactly is NLP?
NLP stands for Natural Language Processing. It is a subfield of artificial intelligence (AI) that focuses on the interaction between computers and human language. NLP enables computers to understand, interpret, and generate human language in a way that is valuable and meaningful.
NLP techniques often involve machine learning and deep learning methods, including neural networks, to process and understand human language. The field of NLP has made significant advancements in recent years, driven by the availability of large datasets, powerful computing resources, and innovative algorithms.
NLP has practical applications in various domains, including healthcare, finance, e-commerce, education, and customer service, among others. NLP plays a crucial role in bridging the gap between human communication and computer systems, making it more accessible and useful for a wide range of applications.
Q5. What is paging in the context of virtual memory management in operating systems?
Paging is a memory management technique used in operating systems to implement virtual memory. It allows a computer to use more physical memory (RAM) than is physically available by temporarily transferring data from RAM to a secondary storage device, such as a hard drive. In paging, the logical address space of a process is divided into fixed-size blocks or pages, typically of the same size as the physical memory's frames.
The operating system keeps track of the mapping between pages in the logical address space and frames in physical memory, allowing pages to be loaded into memory as needed and swapped in and out to manage memory resources effectively.
Q6. What is normalisation?
Normalization, in the context of databases, refers to the process of organizing data in a relational database to reduce data redundancy and improve data integrity. The primary goal of normalization is to ensure that the data is structured efficiently and accurately, preventing anomalies and inconsistencies that can arise when data is duplicated or improperly stored.
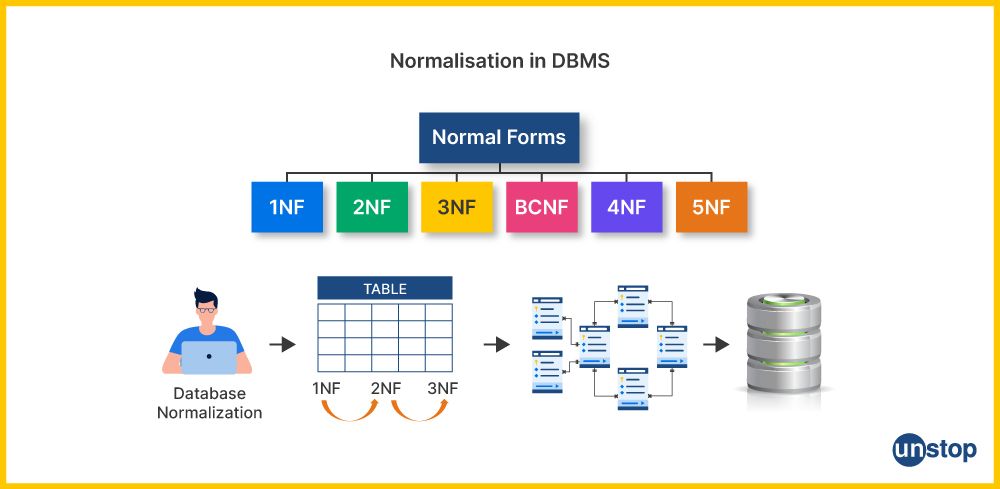
Normalization is typically done by breaking down a large table into smaller, related tables and establishing relationships between them. This process is guided by a set of rules or normal forms, each representing a different level of data organization and optimization. The most commonly used normal forms are:
-
First Normal Form (1NF): Ensures that each column in a table contains only atomic (indivisible) values and that all entries in a column are of the same data type. It eliminates repeating groups of data.
-
Second Normal Form (2NF): Extends 1NF by ensuring that each non-key column is fully functionally dependent on the entire primary key. This means that there are no partial dependencies where a portion of the primary key determines some columns.
-
Third Normal Form (3NF): Extends 2NF by eliminating transitive dependencies. In a 3NF table, non-key attributes are not dependent on other non-key attributes. It promotes data integrity by removing indirect relationships between columns.
-
Boyce-Codd Normal Form (BCNF): Further refines the concept of 3NF by stating that a table is in BCNF if, for every non-trivial functional dependency, the left-hand side (determinant) is a superkey. This ensures that there are no partial or transitive dependencies.
-
Fourth Normal Form (4NF) and higher normal forms: These are more advanced normal forms designed to handle complex multivalued dependencies and other special cases. They are used in situations where the standard forms are insufficient.
Q7. What is the name of the compiler used in Java?
Java uses a two-step process for executing code: compilation and interpretation. The Java compiler is called "javac." It is responsible for translating Java source code (files with a .java extension) into an intermediate form of bytecode. This bytecode is not machine code but is designed to be platform-independent.
After compilation, the Java Virtual Machine (JVM) interprets the bytecode and executes the program. The JVM is responsible for running the compiled Java code on various platforms, making Java a "write once, run anywhere" language. The specific JVM implementation can vary, with some popular JVMs being Oracle HotSpot, OpenJ9, and GraalVM, among others.
Q8. Tell me about threading in Java.
In Java, threading refers to the concurrent execution of multiple threads, allowing a program to perform multiple tasks or processes in parallel. Threads are lightweight sub-processes within a Java application that share the same memory space, but each thread has its own program counter, stack, and set of registers. Java provides robust support for multithreading, making it easier to develop concurrent and parallel applications.
Q9. What are the differences between C++ and Java?
| Feature | C++ | Java |
|---|---|---|
| Language Paradigm | Multi-paradigm (procedural, object-oriented, generic) | Primarily object-oriented |
| Memory Management | Manual memory management (with options for smart pointers) | Automatic garbage collection |
| Platform Independence | Platform-dependent (compiled to machine code) | Platform-independent (bytecode, runs on the JVM) |
| Compilation | Compiled directly to machine code | Compiled to bytecode, executed on the Java Virtual Machine (JVM) |
| Pointers | Supports pointers and direct memory manipulation | No pointers, only references |
| Exception Handling | Supports both checked and unchecked exceptions | Supports only checked exceptions |
| Multiple Inheritance | Supports multiple inheritance | Supports multiple inheritance through interfaces only |
| Operator Overloading | Supports operator overloading | Does not support operator overloading |
| Threading | Provides low-level threading and multithreading support | Provides built-in thread support through the Thread class |
| Standard Library | Standard Template Library (STL) for data structures and algorithms | Extensive built-in libraries for various tasks |
| Security | Potential for memory-related vulnerabilities | Provides security through the JVM |
| Compile-Time Errors | May result in compilation errors if not handled properly | Detects errors at compilation and requires exception handling |
| Garbage Collection | Manual memory management (except for smart pointers) | Automatic garbage collection |
| Performance | Generally faster due to direct memory access and optimization possibilities | Slower due to JVM overhead (but improving) |
| Community and Popularity | Popular for system programming and game development | Widely used for web and enterprise applications |
| Portability | Less portable due to platform-specific code | Highly portable due to the JVM |
| IDE Support | Multiple IDEs available (e.g., Visual Studio, Code::Blocks) | Primarily developed with IDEs like Eclipse and IntelliJ IDEA |
Q10. What are strong AI and weak AI?
Strong AI (Artificial General Intelligence, AGI) and Weak AI (Artificial Narrow Intelligence, ANI) represent two different levels of artificial intelligence capabilities:
Strong AI (Artificial General Intelligence, AGI)
Definition: Strong AI refers to a form of artificial intelligence that possesses human-level intelligence and cognitive abilities. It is capable of understanding, learning, and adapting to a wide range of tasks and domains, just like a human being.
Characteristics:
-
-
- Can perform any intellectual task that a human can.
- Possesses consciousness and self-awareness.
- Has the ability to reason, learn, and solve problems across different domains.
- Can engage in natural language conversations and understand context.
-
Examples: Currently, there are no existing examples of strong AI. It remains a theoretical concept and a goal for future AI development.
Weak AI (Artificial Narrow Intelligence, ANI)
Definition: Weak AI refers to artificial intelligence that is designed and trained for specific, limited tasks or domains. It excels in performing narrowly defined tasks but lacks general intelligence and the ability to transfer knowledge to other areas.
Characteristics:
-
-
- Specialized in a particular task or domain (e.g., image recognition, language translation, playing chess).
- Lacks consciousness, self-awareness, or general reasoning abilities.
- Operates within a pre-defined set of parameters and cannot generalize its knowledge.
-
Examples: Many of the AI systems in use today, such as virtual assistants (e.g., Siri, Alexa), recommendation algorithms (e.g., Netflix recommendations), and autonomous vehicles, are examples of weak AI. They excel in their specific domains but do not possess general intelligence.
Q11. Explain the difference between primary key and foreign key.
| Characteristic | Primary Key | Foreign Key |
|---|---|---|
| Definition | Uniquely identifies rows within a single table. | Establishes relationships between tables, ensuring referential integrity. |
| Uniqueness | Values must be unique within the table. No duplicates are allowed. | Values are not required to be unique within the referencing table. Multiple rows can reference the same value in the referenced table. |
| Null Values | No NULL values are allowed. Every row must have a valid, non-null value. | NULL values are allowed. They are often used to represent optional relationships. |
| Purpose | Used to identify individual records in the table uniquely. | Used to create relationships between tables and ensure data consistency. |
| Creation | Typically created when defining the table's schema, often implemented with the PRIMARY KEY constraint. | Explicitly defined by establishing relationships between tables using the FOREIGN KEY constraint. |
| Indexes | Automatically creates a unique index on the primary key column(s) to improve data retrieval. | Does not automatically create an index, but it is advisable to create an index on foreign key columns for performance. |
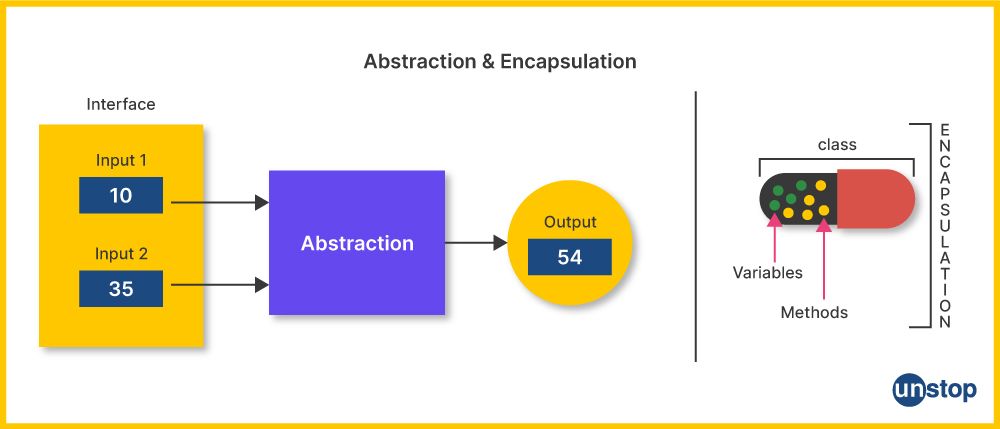
Q12. Explain Encapsulation and Abstraction.
Encapsulation is a fundamental concept in object-oriented programming (OOP) that plays a crucial role in designing well-structured and maintainable software. It involves bundling an object's data (attributes or properties) and methods (functions or operations) into a single unit, typically referred to as a "class." This encapsulated unit serves as a protective container that restricts direct access to an object's internal components.
The idea behind encapsulation is to hide the internal state of an object from external access, thereby safeguarding it from unauthorized or unintended modifications. In practice, data members are often declared as private or protected within a class, ensuring that only the methods defined within that class can interact with them. This mechanism enhances data security and integrity, reducing the risk of unintended data corruption.
Abstraction, in contrast, is another pivotal concept in OOP that complements encapsulation. It revolves around the process of simplifying complex real-world systems by modeling classes or objects based on their essential characteristics and behavior.
Abstraction involves identifying the most pertinent attributes and methods while omitting irrelevant or non-essential details. It serves to create a simplified, high-level model of an object or system. By doing so, abstraction significantly aids in managing complexity and understanding large software systems.
Q13. Differentiate between overloading and overriding.
| Characteristic | Method Overloading | Method Overriding |
|---|---|---|
| Definition | Multiple methods in the same class have the same name but different parameters (method signature). | A subclass provides a specific implementation of a method that is already defined in its superclass. |
| Based on | Differences in method parameters (number, type, or order) and return types are allowed. | Inheritance: It involves a superclass (parent class) and a subclass (child class) relationship. |
| Visibility Modifier | Overloaded methods can have different access modifiers (public, private, protected, package-private). | Overridden methods must not reduce the visibility of the method in the superclass. They can only increase visibility or keep it the same. |
| Static vs. Instance | Overloaded methods can be static or instance methods. | Overridden methods are typically instance methods. |
| Compile-Time Resolution | Overloaded methods are resolved at compile time based on the method signature and parameters. | Overridden methods are resolved at runtime based on the actual object's type (dynamic or late binding). |
| Return Type | Overloaded methods can have different return types, but the return type alone is not sufficient to differentiate them. | Overridden methods must have the same method signature, including the return type. |
| Usage | Commonly used for providing multiple methods with similar functionality but different input types or options. | Used to provide a specialized implementation in a subclass, replacing or extending the behavior of the superclass method. |
| Example | Multiple constructors in a class with different parameter lists. | Subclass implementing a specific behavior for a method inherited from the superclass. |
Q14. What are array and linked lists? Explain the differences between them.
Arrays and Linked Lists are both data structures used to store collections of elements in computer memory. However, they have different characteristics and offer distinct advantages and disadvantages.
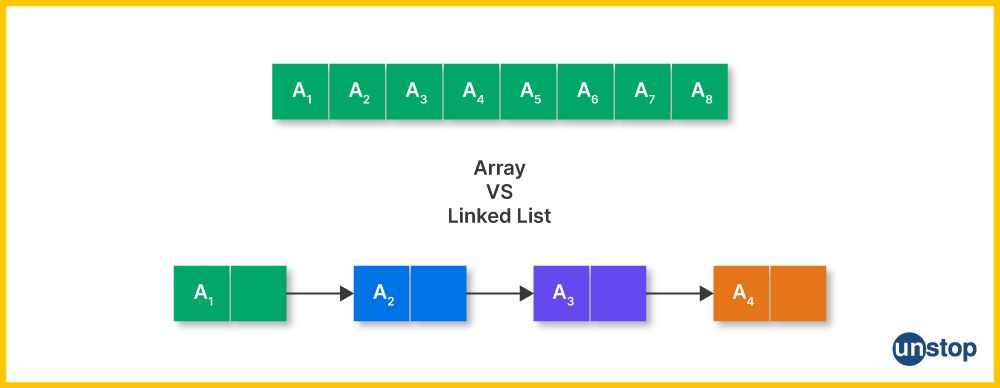
Arrays:
- Definition: An array is a fixed-size, contiguous data structure that stores elements of the same data type. Elements are accessed using an index that represents their position in the array.
- Memory Allocation: In most programming languages, arrays are allocated a contiguous block of memory, meaning all elements are stored in adjacent memory locations.
- Size: Arrays have a fixed size, meaning you need to know the number of elements in advance. If you need to resize an array, you typically need to create a new one and copy the elements.
- Random Access: Arrays allow for fast random access to elements. You can directly access any element by its index, making array access very efficient.
- Insertion and Deletion: Inserting or deleting elements within an array can be inefficient, especially when elements need to be shifted to accommodate changes.
Linked Lists:
- Definition: A linked list is a dynamic data structure consisting of nodes, where each node contains a value and a reference (link or pointer) to the next node in the sequence.
- Memory Allocation: Linked lists do not require contiguous memory allocation. Each node can be located anywhere in memory, connected by references.
- Size: Linked lists can dynamically grow or shrink as needed, making them flexible for managing changing data sizes.
- Random Access: Linked lists do not support direct random access to elements. To access a specific element, you must traverse the list sequentially, starting from the head (or tail) node. This makes access slower than arrays.
- Insertion and Deletion: Insertions and deletions are efficient in linked lists. You can add or remove elements by adjusting the references in constant time, as long as you have access to the node where the change should occur.
Differences:
- Memory Allocation: Arrays use contiguous memory allocation, while linked lists use non-contiguous memory allocation through references between nodes.
- Size: Arrays have a fixed size, whereas linked lists can dynamically grow or shrink based on the number of elements.
- Random Access: Arrays offer fast random access to elements using indexes, while linked lists require sequential traversal for access, making them slower.
- Insertion and Deletion: Linked lists excel at efficient insertions and deletions, as they only require adjustments to references. Arrays are less efficient for insertions and deletions, especially in the middle, as they may involve shifting elements.
- Flexibility: Linked lists are more flexible in terms of size, but they consume additional memory for the node references.
- Complexity: Arrays are generally simpler to work with due to their fixed size and direct access, while linked lists can be more complex to navigate due to their sequential access.
Stay ahead! Never miss out any trending job or internship opportunity!
Q15. What is the difference between AL and ML?
| Characteristic | Artificial Intelligence (AI) | Machine Learning (ML) |
|---|---|---|
| Definition | Broad field of computer science aiming to create intelligent systems that can perform tasks requiring human-like intelligence. | Subset of AI focused on the development of algorithms that allow computers to learn from and make predictions or decisions based on data. |
| Scope | Encompasses a wide range of techniques and approaches, including rule-based systems, expert systems, robotics, and more. | Primarily focuses on algorithms that can improve their performance through experience and data. |
| Learning | AI systems may or may not involve learning. Some AI systems are rule-based and do not learn from data. | Central to ML; it involves training algorithms on data to improve their performance and make predictions. |
| Human-Like | Aims to replicate or mimic human-like intelligence and decision-making in various domains. | Focuses on specific tasks and does not necessarily aim to mimic human intelligence but can achieve human-level performance in some cases. |
| Examples | Natural language understanding, robotics, expert systems, problem-solving, and decision-making in diverse domains. | Image recognition, speech recognition, recommendation systems, and predictive modeling. |
| Training Data | May or may not use training data. AI systems can rely on predefined rules and expert knowledge. | Requires training data for algorithm learning and improvement. |
| Adaptability | AI systems may or may not adapt over time; some are static rule-based systems. | ML systems continuously adapt and improve their performance with more data and experience. |
| Use Cases | Applies to a broad range of applications, from healthcare diagnosis to autonomous vehicles. | Particularly suited for pattern recognition, classification, regression, and data-driven decision-making tasks. |
| Development | May involve both manual rule-based programming and machine learning techniques. | Involves creating, training, and fine-tuning ML models using large datasets. |
To sum up, Artificial Intelligence (AI) is a broad field focused on creating intelligent systems, while Machine Learning (ML) is a subset of AI that concentrates on developing algorithms capable of learning from data to make predictions or decisions.
Q16. How can we dynamically allocate memory in C?
In C, you can dynamically allocate memory using the malloc, calloc, and realloc functions provided by the standard library. Dynamic memory allocation allows you to allocate memory at runtime. Here's how to use these functions:
1. malloc (Memory Allocation): malloc stands for "memory allocation." It is used to allocate a specified number of bytes of memory on the heap (dynamic memory). The allocated memory is uninitialized, and it returns a pointer to the first byte of the allocated block.
2. calloc (Contiguous Allocation): calloc allocates memory for an array of elements and initializes the allocated memory to zero. It takes two arguments: number of elements and the size of each element.
3. realloc (Reallocate Memory): realloc is used to resize an existing dynamically allocated memory block. It takes a pointer to the existing memory block, the new size, and returns a pointer to the new block. It can be used to increase or decrease the size of an existing allocation.
Q17. What are DDL and DML commands?
DDL (Data Definition Language) and DML (Data Manipulation Language) are two subsets of SQL (Structured Query Language) used to interact with relational databases. They serve different purposes and are used for distinct operations.
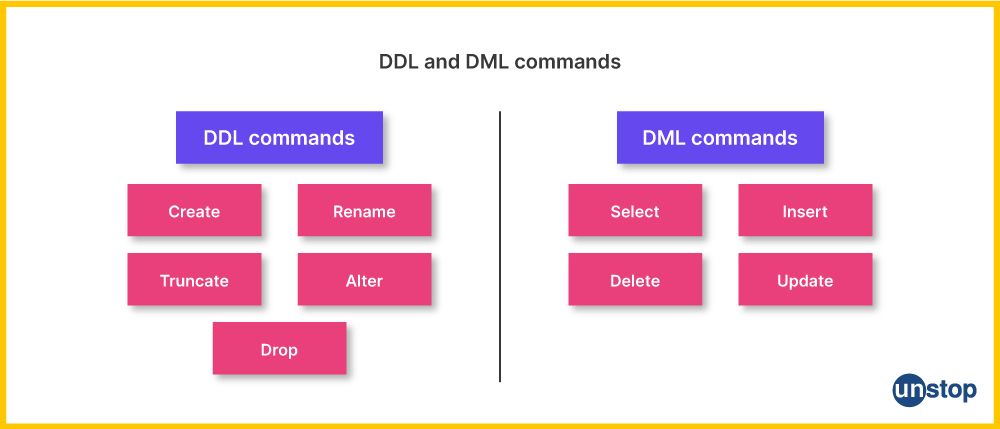
DDL (Data Definition Language):
- Definition: DDL is a subset of SQL used for defining and managing the structure of a database, including creating, altering, and deleting database objects like tables, indexes, and views.
- Key Commands: CREATE, ALTER, DROP, TRUNCATE, COMMENT, RENAME.
- Examples: CREATE TABLE, ALTER TABLE, DROP INDEX, COMMENT ON TABLE, RENAME TABLE.
DML (Data Manipulation Language):
- Definition: DML is a subset of SQL used for manipulating data within the database. It involves querying and modifying data stored in the database, such as inserting, updating, and deleting records.
- Key Commands: SELECT, INSERT, UPDATE, DELETE, MERGE.
- Examples: SELECT * FROM table_name, INSERT INTO table_name (column1, column2) VALUES (value1, value2), UPDATE table_name SET column1 = value1 WHERE condition, DELETE FROM table_name WHERE condition, MERGE INTO target_table USING source_table ON condition.
Q18. What is a pointer and how will you declare it?
A pointer in C and C++ is a variable that stores the memory address of another variable. Pointers are powerful features that allow you to manipulate and work with memory directly. They are used to access, modify, and manage data stored in memory locations. To declare a pointer, you need to specify the data type of the variable it points to.
Here's how you declare a pointer:
data_type *pointer_name;
- data_type: This is the data type of the variable that the pointer will point to. For example, if you want to create a pointer to an integer, use int as the data type. If you want a pointer to a character, use char, and so on.
- pointer_name: This is the name you give to the pointer variable. You can choose any valid variable name.
Here are some examples of pointer declarations:
int *int_ptr; // Pointer to an integer
char *char_ptr; // Pointer to a character
float *float_ptr; // Pointer to a floating-point number
Q19. Write a code for finding the factorial of a number.
#include <stdio.h>
// Function to calculate the factorial of a number
unsigned long long factorial(int n) {
if (n == 0 || n == 1) {
return 1; // Base case: 0! and 1! are both 1
} else {
return n * factorial(n - 1); // Recursive case
}
}int main() {
int num;
printf("Enter a non-negative integer: ");
scanf("%d", &num);
if (num < 0) {
printf("Factorial is undefined for negative numbers.\n");
} else {
unsigned long long result = factorial(num);
printf("The factorial of %d is %llu\n", num, result);
}
return 0;
}Output:
Enter a non-negative integer: 4
The factorial of 4 is 24
Q20. Explain memory allocation in Java.
In Java, memory allocation is a fundamental aspect of the language's runtime environment. Memory allocation in Java primarily involves the allocation and management of memory for objects and data structures. Java manages memory automatically through a process known as garbage collection, which helps ensure memory efficiency and eliminates the need for manual memory management. Here are the key aspects of memory allocation in Java:
Heap Memory:
- In Java, objects and data structures are allocated memory from a region called the "heap." The heap is a part of memory where objects are stored, and it's managed by the Java Virtual Machine (JVM).
- The heap memory is dynamically allocated at runtime to accommodate objects created during the execution of a Java program.
- Java objects in the heap can be of various types and sizes, and their lifetimes are managed by the JVM.
Automatic Memory Management:
- Java uses automatic memory management, which means developers do not need to explicitly allocate or deallocate memory as they would in languages like C or C++.
- The JVM automatically allocates memory for objects when they are created and reclaims memory when objects are no longer in use.
Garbage Collection:
- Java employs a garbage collector to identify and reclaim memory occupied by objects that are no longer reachable or referenced in the program.
- The garbage collector periodically scans the heap, identifies unreferenced objects, and frees up their memory for reuse.
- This process ensures that memory leaks are minimized, as objects that are no longer needed are automatically cleaned up.
Object Creation:
- In Java, objects are created using the new keyword. For example, MyClass obj = new MyClass(); allocates memory for an instance of MyClass on the heap.
- Memory allocation also involves initializing the object's instance variables and invoking its constructor.
Memory Efficiency:
- Java's automatic memory management helps ensure memory efficiency by reclaiming memory that is no longer in use.
- However, this process may introduce some overhead and can affect the application's performance. Developers should be aware of memory usage and object lifecycle to optimize memory allocation.
Memory Leaks:
- Although Java automates memory management, it is still possible to create memory leaks if references to objects are unintentionally retained. This can occur if objects are not properly dereferenced when they are no longer needed.
Q20. Explain the prime number code.
def is_prime(number):
if number <= 1:
return False # Numbers less than or equal to 1 are not primefor i in range(2, int(number**0.5) + 1):
if number % i == 0:
return False # If it has a divisor in this range, it's not primereturn True # If no divisors found, it's prime
# Get user input
num = int(input("Enter a number: "))if is_prime(num):
print(f"{num} is a prime number.")
else:
print(f"{num} is not a prime number.")Output:
Enter a number: 7
7 is a prime number.
Explanation
In the code:
- The is_prime function checks whether a given number is prime or not.
- It first checks if the number is less than or equal to 1, in which case it's not prime. Prime numbers are defined as greater than 1.
- It then iterates through numbers from 2 to the square root of the given number (using int(number**0.5) + 1) to check for divisors. This is an optimization, as you only need to check up to the square root to find all possible divisors.
- If the number is evenly divisible by any of the numbers in the range, it's not prime, and the function returns False.
- If no divisors are found in the loop, the function returns True, indicating that the number is prime.
The code takes a user-input number, calls the is_prime function to check if it's prime, and prints the result. If the number is prime, it will print that it's a prime number; otherwise, it will say it's not a prime number.
Q21. Write a program to swap two numbers without using the third variable.
#include <iostream>
int main() {
int num1, num2;// Input two numbers
std::cout << "Enter the first number: ";
std::cin >> num1;std::cout << "Enter the second number: ";
std::cin >> num2;// Swap the numbers without a third variable
num1 = num1 + num2;
num2 = num1 - num2;
num1 = num1 - num2;// Print the swapped numbers
std::cout << "After swapping:" << std::endl;
std::cout << "First number: " << num1 << std::endl;
std::cout << "Second number: " << num2 << std::endl;return 0;
}Output:
Enter the first number: 5
Enter the second number: 8
After swapping:
First number: 8
Second number: 5
Q22. What are the latest processors used in laptops?
The latest processors that are commonly used in laptops are:
Intel Processors:
-
Intel Core 11th and 12th Gen (Tiger Lake and Alder Lake): These processors, including the Core i9, i7, i5, and i3 variants, were popular choices for laptops. Tiger Lake, in particular, offered improved performance and efficiency.
-
Intel Core H-Series (10th and 11th Gen): The Core i9, i7, and i5 H-series processors are designed for high-performance laptops and gaming laptops.
-
Intel Core vPro: These processors are designed for business laptops and offer features like remote management and enhanced security.
AMD Processors:
-
AMD Ryzen 4000 and 5000 Series: These mobile processors brought significant competition to Intel's offerings, with excellent multi-core performance and power efficiency.
-
AMD Ryzen 5000U Series (Cezanne): Known for their strong performance, these processors were often used in ultrabooks and thin-and-light laptops.
-
AMD Ryzen 9 processors: These processors are commonly used in high-performance laptops and gaming laptops.
-
AMD Ryzen PRO processors: Similar to Intel vPro, these processors are aimed at business laptops and offer advanced security features.
Q23. If you want to insert a node between two linked lists, how will you approach the problem?
To insert a node between two nodes in a linked list, you will need to perform the following steps:
- Create a new node that you want to insert, and set its value to the data you want to insert.
- Locate the node that comes before the position where you want to insert the new node. This node will be the predecessor of the new node.
- Update the pointers to insert the new node between the predecessor node and its successor.
Here's a general approach with code examples in C++:
#include <iostream>
// Define a linked list node structure
struct Node {
int data;
Node* next;
Node(int value) : data(value), next(nullptr) {}
};// Function to insert a node between two nodes
void insertBetween(Node* predecessor, int dataToInsert) {
if (predecessor == nullptr) {
std::cout << "Predecessor node is null. Cannot insert." << std::endl;
return;
}
Node* newNode = new Node(dataToInsert);
newNode->next = predecessor->next;
predecessor->next = newNode;
}// Function to print the linked list
void printList(Node* head) {
Node* current = head;
while (current != nullptr) {
std::cout << current->data << " ";
current = current->next;
}
std::cout << std::endl;
}int main() {
// Create a sample linked list: 1 -> 3 -> 5
Node* head = new Node(1);
head->next = new Node(3);
head->next->next = new Node(5);std::cout << "Original linked list: ";
printList(head);// Insert 2 between 1 and 3
insertBetween(head, 2);std::cout << "Linked list after insertion: ";
printList(head);return 0;
}Output:
Original linked list: 1 3 5
Linked list after insertion: 1 2 3 5
In this code, the insertBetween function inserts a new node with the specified data between the predecessor node and its successor. It does so by adjusting the next pointers appropriately. The printList function is used to display the linked list before and after the insertion.
Q24. Explain cloud computing.
Cloud computing is a technology paradigm that involves delivering computing services and resources over the internet. Instead of hosting applications and data on local servers or personal devices, cloud computing allows businesses and individuals to access and use computing resources provided by cloud service providers. These resources are typically housed in large data centers and are made available on a pay-as-you-go or subscription basis. Cloud computing offers several key features and benefits:
-
On-Demand Services: Cloud computing provides on-demand access to a wide range of computing resources, such as virtual machines, storage, databases, and software. Users can provision and scale these resources as needed.
-
Scalability: Cloud services can easily scale up or down to accommodate changes in demand. This scalability is particularly valuable for businesses with fluctuating workloads.
-
Resource Pooling: Cloud providers serve multiple customers from the same physical resources, which are dynamically allocated and reassigned based on demand. This approach allows for efficient resource utilization.
-
Self-Service: Users can provision and manage cloud resources through web-based interfaces or APIs without the need for extensive IT expertise.
-
Broad Network Access: Cloud services are accessible over the internet from a variety of devices, including laptops, smartphones, and tablets.
-
Measured Service: Cloud computing resources are metered, and users are billed based on their actual usage. This pay-as-you-go model is cost-effective and eliminates the need for significant upfront investments.
-
Service Models: Cloud computing offers various service models, including Infrastructure as a Service (IaaS), Platform as a Service (PaaS), and Software as a Service (SaaS), each catering to different needs.
-
Deployment Models: Cloud services can be deployed in public, private, hybrid, or multi-cloud environments, providing flexibility in how organizations manage their computing resources.
Cloud computing can be further categorized into the following service models:
-
Infrastructure as a Service (IaaS): Offers virtualized computing resources over the internet, including virtual machines, storage, and networking.
-
Platform as a Service (PaaS): Provides a platform and environment for developing, testing, and deploying applications without worrying about the underlying infrastructure.
-
Software as a Service (SaaS): Delivers software applications over the internet on a subscription basis, eliminating the need for installation and maintenance.
Q25. How is a binary search tree implemented?
A binary search tree (BST) is a binary tree data structure where each node has at most two child nodes, and the nodes are organized in such a way that for each node:
- All nodes in its left subtree have values less than the node's value.
- All nodes in its right subtree have values greater than the node's value.
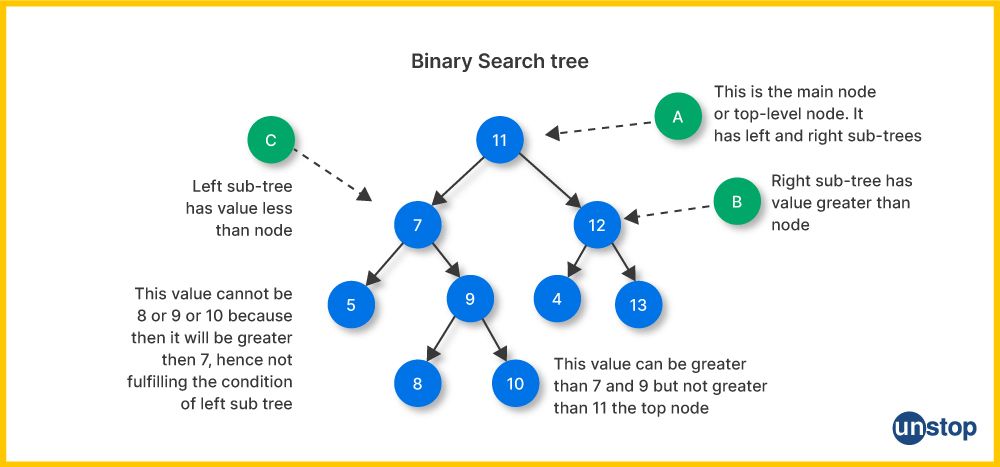
BSTs are typically used to perform efficient searching, insertion, and deletion operations. Here's how a binary search tree can be implemented in a simplified way in languages like C++ or Java:
#include <iostream>
// Define a node structure for the binary search tree
struct Node {
int data;
Node* left;
Node* right;Node(int value) : data(value), left(nullptr), right(nullptr) {}
};// Function to insert a new value into the BST
Node* insert(Node* root, int value) {
if (root == nullptr) {
return new Node(value);
}if (value < root->data) {
root->left = insert(root->left, value);
} else if (value > root->data) {
root->right = insert(root->right, value);
}return root;
}// Function to search for a value in the BST
bool search(Node* root, int value) {
if (root == nullptr) {
return false;
}if (value == root->data) {
return true;
} else if (value < root->data) {
return search(root->left, value);
} else {
return search(root->right, value);
}
}// Function to perform an in-order traversal of the BST
void inOrderTraversal(Node* root) {
if (root != nullptr) {
inOrderTraversal(root->left);
std::cout << root->data << " ";
inOrderTraversal(root->right);
}
}int main() {
Node* root = nullptr;// Insert values into the BST
root = insert(root, 50);
root = insert(root, 30);
root = insert(root, 70);
root = insert(root, 20);
root = insert(root, 40);
root = insert(root, 60);
root = insert(root, 80);std::cout << "In-order traversal of the BST: ";
inOrderTraversal(root);
std::cout << std::endl;// Search for a value
int valueToSearch = 40;
if (search(root, valueToSearch)) {
std::cout << valueToSearch << " found in the BST." << std::endl;
} else {
std::cout << valueToSearch << " not found in the BST." << std::endl;
}return 0;
}
In this simplified example, a Node structure is defined to represent the nodes of the BST. The insert function inserts a value into the BST while maintaining the binary search tree property. The search function is used to search for a value within the tree. The inOrderTraversal function performs an in-order traversal of the tree to display its elements in sorted order.
Q26. How do you design a vending machine?
Designing a vending machine involves various components and considerations, including hardware, software, user interface, and operational aspects. Below are the key steps and components involved in designing a vending machine:
1. Requirements Analysis: Understand the specific requirements of the vending machine, such as the types of products it will sell (e.g., snacks, beverages, tickets), payment methods (e.g., cash, credit card, mobile payments), and any special features (e.g., refrigeration, touch screen).
2. Hardware Components: Select and integrate the necessary hardware components, including:
-
-
- Product dispensing mechanism (solenoids, motors, conveyors).
- Payment system (bill acceptors, coin mechanisms, card readers).
- User interface (keypad, touch screen, display).
- Cash handling and storage.
- Product storage (shelves or slots).
- Sensors (e.g., product detection, temperature, security).
- Connectivity (for real-time monitoring and updates).
-
3. Software Design: Develop the software that controls the vending machine, including:
-
-
- User interface software for selecting products and making payments.
- Inventory management to track product availability.
- Transaction processing and payment handling.
- Remote monitoring and reporting for machine owners or operators.
- Security measures to prevent unauthorized access and tampering.
-
4. User Interface: Design a user-friendly interface that allows customers to easily select and purchase products. This typically involves a touch screen or keypad for product selection and payment, along with a display for feedback.
5. Product Inventory: Implement a system to manage product inventory, ensuring that stock levels are updated in real-time, and products are restocked as needed.
6. Payment Systems: Integrate various payment methods, such as cash, coins, credit cards, mobile wallets, or NFC payment options. Ensure secure payment processing and fraud prevention.
7. Security Measures: Implement security features to protect the machine from vandalism, theft, and unauthorized access. This may include surveillance cameras, alarms, and secure locks.
8. Remote Monitoring: Develop a remote monitoring system to allow operators to track machine status, sales data, and inventory remotely. This helps with maintenance and restocking.
9. Maintenance and Servicing: Plan for routine maintenance and servicing of the vending machine, including regular cleaning, product restocking, and hardware maintenance.
10. Compliance and Regulations: Ensure that the vending machine complies with local regulations, health and safety standards, and any specific requirements related to the products being sold.
11. Testing and Quality Assurance: Thoroughly test the vending machine for functionality, user-friendliness, and security. Ensure it works as expected under various conditions.
12. Deployment and Operation: Deploy the vending machine at appropriate locations, such as offices, schools, or public spaces. Establish an operational plan for restocking and servicing.
13. Marketing and Sales: Plan for marketing and promotions to attract customers to use the vending machine.
14. Customer Support: Provide customer support channels for addressing issues, refund requests, or product inquiries.
15. Data Analytics: Collect and analyze data related to product sales, customer preferences, and machine usage to make informed decisions about inventory and future offerings.
Q27. Name some different OS you know of.
Here's a list of some different operating systems, categorized by their intended use:
General-Purpose Operating Systems:
-
Microsoft Windows: Widely used in personal computers and servers.
-
macOS: Developed by Apple for Macintosh computers.
-
Linux: A Unix-like OS available in various distributions, such as Ubuntu, Fedora, and CentOS.
-
Unix: The foundation for many other operating systems, including Linux and macOS.
Mobile Operating Systems:
-
Android: Developed by Google for mobile devices.
-
iOS: Developed by Apple for iPhones and iPads.
-
KaiOS: A lightweight OS for feature phones.
Real-Time Operating Systems (RTOS):
-
FreeRTOS: An open-source real-time OS for embedded systems.
-
VxWorks: A commercial RTOS used in various industries, including aerospace and automotive.
-
QNX: Known for its reliability and used in automotive and medical devices.
Server Operating Systems:
-
Windows Server: Microsoft's OS for server environments.
-
Ubuntu Server: A popular Linux distribution for servers.
-
CentOS: A free, open-source Linux distribution based on the sources of Red Hat Enterprise Linux.
Specialized Operating Systems:
-
Raspberry Pi OS: A specialized OS for the Raspberry Pi single-board computer.
-
Chrome OS: Designed by Google for Chromebooks and primarily focused on web applications.
-
Tizen: An open-source OS primarily used in Samsung's smart TVs and wearable devices.
Embedded Operating Systems:
-
Embedded Linux: A version of Linux customized for embedded systems.
-
Micrium µC/OS: A real-time OS used in embedded and IoT devices.
-
Contiki: An open-source OS for the Internet of Things (IoT).
Supercomputing Operating Systems:
-
Cray Linux Environment (CLE): Used on Cray supercomputers.
-
AIX: IBM's proprietary OS used in supercomputing and enterprise systems.
Q28. What are the advantages of using paging in virtual memory systems?
Paging offers several advantages in virtual memory systems:
-
Simplified Memory Management: Paging simplifies memory management by dividing the address space into fixed-size pages, making it easier for the operating system to allocate and track memory.
-
Efficient Use of Memory: It enables efficient use of physical memory. Pages can be loaded into memory when needed and swapped out when not, allowing the system to maximize memory utilization.
-
Protection and Isolation: Paging provides memory protection and isolation between processes. Each process operates within its own virtual address space, preventing one process from accessing or modifying the memory of another.
-
Large Address Spaces: Paging allows for large, contiguous virtual address spaces even if the physical memory is limited. This is crucial for running multiple processes simultaneously.
-
Simplified Address Translation: The fixed page size simplifies the address translation process. A page table maps page numbers to frame numbers, enabling fast translation of virtual addresses to physical addresses.
-
Support for Demand Paging: Paging supports demand paging, where pages are loaded into memory on demand, reducing initial loading times and improving overall system performance.
-
Ease of Implementation: Paging is relatively easy to implement and is widely supported by modern operating systems.
Q29. What is the purpose of the Domain Name System (DNS) in networking, and how does it work?
The Domain Name System (DNS) is a critical component of the internet and computer networking. Its primary purpose is to translate human-readable domain names (like www.example.com) into IP addresses that computers use to locate and communicate with each other. DNS helps users access websites, send emails, and perform various network activities without needing to remember numerical IP addresses.
DNS operates as a distributed hierarchical system with multiple levels of authoritative servers. When a user enters a domain name into a web browser, their device sends a DNS query to a local DNS resolver. If the resolver has the IP address in its cache, it responds directly. If not, it forwards the request through a series of DNS servers, eventually reaching authoritative DNS servers responsible for the domain. These authoritative servers provide the correct IP address to the resolver, which then caches it for future use, and the user's request is fulfilled. DNS is a fundamental part of internet infrastructure, making it easier for users to access resources and services by name instead of complex numerical addresses.
Q30. What is the significance of "super" in Java when dealing with inheritance?
In Java, "super" is a keyword used to refer to the superclass or parent class. It is often used to call a method, access a field, or invoke a constructor of the parent class from a subclass. The "super" keyword is particularly useful in cases where the subclass overrides a method from the superclass but still needs to utilize the behavior of the overridden method. By using "super," you can avoid ambiguity and explicitly indicate that you are referring to the superclass's member or constructor.
For example, super.methodName() calls the method from the superclass, while super() invokes the constructor of the superclass.
Wipro Elite NTH Interview Round- HR Questions
The last round in Wipro Elite NTH is the HR interview round. Various aspects of your personality will be judged in this round. Here are some interview questions you must prepare for the Wipro Elite NTH HR round.
| S.No. | Questions |
| 1. | Tell me something about yourself. |
| 2. | Do you recall the topic you wrote the essay on? |
| 3. | Which is your dream company? |
| 4. | Do you plan to do a master’s degree in future? |
| 5. | Does any CEO or Chairperson’s life inspire you? How? |
| 6. | Why do you want to join Wipro? |
| 7. | Are you okay with relocation? Any preferred location? |
| 8. | Are you comfortable with the 15-month agreement with Wipro? |
| 9. | Where do you see yourself in next 5 years? |
| 10. | Tell me about your internships/projects. |
| 11 | How do you handle team conflicts? |
| 12. | Is there any gap in your studies, or do you have any backlogs? |
| 13. | What do you know about Wipro? |
| 14. | If you have a conflict with one of your colleagues, how would you de-escalate the situation? |
| 15. | Why do you want to work in the IT sector when you are from a non-CS branch? |
So, if you really want to make the best out of this opportunity being provided by Wipro, the above questions can help you get a fair idea of how to prepare for the interview rounds. So gear up and start preparing!

You might also be interested in reading:
Login to continue reading
And access exclusive content, personalized recommendations, and career-boosting opportunities.
Don't have an account? Sign up
Never miss an
Update

Featured Opportunities
Top-Rated Practice by Students





Subscribe
to our newsletter




Comments
Add comment