


Asian Paints Alchemy 2026
Company Interview Questions for Freshers
- TCS Technical Interview Questions & Answers
- TCS Managerial Interview Questions & Answers
- TCS HR Interview Questions & Answers
- Overview of Cognizant Recruitment Process
- Cognizant Interview Questions: Technical
- Cognizant Interview Questions: HR Round
- Overview of Wipro Technologies Recruitment Rounds
- Wipro Interview Questions
- Technical Round
- HR Round
- Online Assessment Sample Questions
- Frequently Asked Questions
- Overview of Google Recruitment Process
- Google Interview Questions: Technical
- Google Interview Questions: HR round
- Interview Preparation Tips
- About Google
- Deloitte Technical Interview Questions
- Deloitte HR Interview Questions
- Deloitte Recruitment Process
- Technical Interview Questions and Answers
- Level 1 difficulty
- Level 2 difficulty
- Level 3 difficulty
- Behavioral Questions
- Eligibility Criteria for Mindtree Recruitment
- Mindtree Recruitment Process: Rounds Overview
- Skills required to crack Mindtree interview rounds
- Mindtree Recruitment Rounds: Sample Questions
- About Mindtree
- Preparing for Microsoft interview questions
- Microsoft technical interview questions
- Microsoft behavioural interview questions
- Aptitude Interview Questions
- Technical Interview Questions
- Easy
- Intermediate
- Hard
- HR Interview Questions
- Eligibility criteria
- Recruitment rounds & assessments
- Tech Mahindra interview questions - Technical round
- Tech Mahindra interview questions - HR round
- Hiring process at Mphasis
- Mphasis technical interview questions
- Mphasis HR interview questions
- About Mphasis
- Technical interview questions
- HR interview questions
- Recruitment process
- About Virtusa
- Goldman Sachs Interview Process
- Technical Questions for Goldman Sachs Interview
- Sample HR Question for Goldman Sachs Interview
- About Goldman Sachs
- Nagarro Recruitment Process
- Nagarro HR Interview Questions
- Nagarro Aptitude Test Questions
- Nagarro Technical Test Questions
- About Nagarro
- PwC Recruitment Process
- PwC Technical Interview Questions: Freshers and Experienced
- PwC Interview Questions for HR Rounds
- PwC Interview Preparation
- Frequently Asked Questions
- EY Technical Interview Questions (2023)
- EY Interview Questions for HR Round
- About EY
- Morgan Stanley Recruitment Process
- HR Questions for Morgan Stanley Interview
- HR Questions for Morgan Stanley Interview
- About Morgan Stanley
- Recruitment Process at Flipkart
- Technical Flipkart Interview Questions
- Code-Based Flipkart Interview Questions
- Sample Flipkart Interview Questions- HR Round
- Conclusion
- FAQs
- Recruitment Process at Paytm
- Technical Interview Questions for Paytm Interview
- HR Sample Questions for Paytm Interview
- About Paytm
- Most Probable Accenture Interview Questions
- Accenture Technical Interview Questions
- Accenture HR Interview Questions
- Amazon Recruitment Process
- Amazon Interview Rounds
- Common Amazon Interview Questions
- Amazon Interview Questions: Behavioral-based Questions
- Amazon Interview Questions: Leadership Principles
- Company-specific Amazon Interview Questions
- 43 Top Technical/ Coding Amazon Interview Questions
- Juspay Recruitment: Stages and Timeline
- Juspay Interview Questions and Answers
- How to prepare for Juspay interview questions
- Prepare for the Juspay Interview: Stages and Timeline
- Frequently Asked Questions
- Adobe Interview Questions - Technical
- Adobe Interview Questions - HR
- Recruitment Process at Adobe
- About Adobe
- Cisco technical interview questions
- Sample HR interview questions
- The recruitment process at Cisco
- About Cisco
- JP Morgan interview questions (Technical round)
- JP Morgan interview questions HR round)
- Recruitment process at JP Morgan
- About JP Morgan
- Wipro Elite NTH: Selection Process
- Wipro Elite NTH Technical Interview Questions
- Wipro Elite NTH Interview Round- HR Questions
- BYJU's BDA Interview Questions
- BYJU's SDE Interview Questions
- BYJU's HR Round Interview Questions
- A Quick Overview of the KPMG Recruitment Process
- Technical Questions for KPMG Interview
- HR Questions for KPMG Interview
- About KPMG
- DXC Technology Interview Process
- DCX Technical Interview Questions
- Sample HR Questions for DXC Technology
- About DXC Technology
- Recruitment Process at PayPal
- Technical Questions for PayPal Interview
- HR Sample Questions for PayPal Interview
- About PayPal
- Capgemini Recruitment Rounds
- Capgemini Interview Questions: Technical round
- Capgemini Interview Questions: HR round
- Preparation tips
- FAQs
- Technical interview questions for Siemens
- Sample HR questions for Siemens
- The recruitment process at Siemens
- About Siemens
- HCL Technical Interview Questions
- HR Interview Questions
- HCL Technologies Recruitment Process
- List of EPAM Interview Questions for Technical Interviews
- About EPAM
- Atlassian Interview Process
- Top Skills for Different Roles at Atlassian
- Atlassian Interview Questions: Technical Knowledge
- Atlassian Interview Questions: Behavioral Skills
- Atlassian Interview Questions: Tips for Effective Preparation
- Walmart Recruitment Process
- Walmart Interview Questions and Sample Answers (HR Round)
- Walmart Interview Questions and Sample Answers (Technical Round)
- Tips for Interviewing at Walmart and Interview Preparation Tips
- Frequently Asked Questions
- Uber Interview Questions For Engineering Profiles: Coding
- Technical Uber Interview Questions: Theoretical
- Uber Interview Question: HR Round
- Uber Recruitment Procedure
- About Uber Technologies Ltd.
- Intel Technical Interview Questions
- Computer Architecture Intel Interview Questions
- Intel DFT Interview Questions
- Intel Interview Questions for Verification Engineer Role
- Recruitment Process Overview
- Important Accenture HR Interview Questions
- Points to remember
- What is Selenium?
- What are the components of the Selenium suite?
- Why is it important to use Selenium?
- What's the major difference between Selenium 3.0 & Selenium 2.0?
- What is Automation testing and what are its benefits?
- What are the benefits of Selenium as an Automation Tool?
- What are the drawbacks to using Selenium for testing?
- Why should Selenium not be used as a web application or system testing tool?
- Is it possible to use selenium to launch web browsers?
- What does Selenese mean?
- What does it mean to be a locator?
- Identify the main difference between "assert", and "verify" commands within Selenium
- What does an exception test in Selenium mean?
- What does XPath mean in Selenium? Describe XPath Absolute & XPath Relation
- What is the difference in Xpath between "//"? and "/"?
- What is the difference between "type" and the "typeAndWait" commands within Selenium?
- Distinguish between findElement() & findElements() in context of Selenium
- How long will Selenium wait before a website is loaded fully?
- What is the difference between the driver.close() and driver.quit() commands in Selenium?
- Describe the different navigation commands that Selenium supports
- What is Selenium's approach to the same-origin policy?
- Explain the difference between findElement() in Selenium and findElements()
- Explain the pause function in SeleniumIDE
- Explain the differences between different frameworks and how they are connected to Selenium's Robot Framework
- What are your thoughts on the Page Object Model within the context of Selenium
- What are your thoughts on Jenkins?
- What are the parameters that selenium commands come with a minimum?
- How can you tell the differences in the Absolute pathway as well as Relative Path?
- What's the distinction in Assert or Verify declarations within Selenium?
- What are the points of verification that are in Selenium?
- Define Implicit wait, Explicit wait, and Fluent
- Can Selenium manage windows-based pop-ups?
- What's the definition of an Object Repository?
- What is the main difference between obtainwindowhandle() as well as the getwindowhandles ()?
- What are the various types of Annotations that are used in Selenium?
- What is the main difference in the setsSpeed() or sleep() methods?
- What is the way to retrieve the alert message?
- How do you determine the exact location of an element on the web?
- Why do we use Selenium RC?
- What are the benefits or advantages of Selenium RC?
- Do you have a list of the technical limitations when making use of Selenium RC? Selenium RC?
- What's the reason to utilize the TestNG together with Selenium?
- What Language do you prefer to use to build test case sets in Selenium?
- What are Start and Breakpoints?
- What is the purpose of this capability relevant in relation to Selenium?
- When do you use AutoIT?
- Do you have a reason why you require Session management in Selenium?
- Are you able to automatize CAPTCHA?
- How can we launch various browsers on Selenium?
- Why should you select Selenium rather than QTP (Quick Test Professional)?
- Airbus Interview Questions and Answers: HR/ Behavioral
- Industry/ Company-Specific Airbus Interview Questions
- Airbus Interview Questions and Answers: Aptitude
- Airbus Software Engineer Interview Questions and Answers: Technical
- Importance of Spring Framework
- Spring Interview Questions (Basic)
- Advanced Spring Interview Questions
- C++ Interview Questions and Answers: The Basics
- C++ Interview Questions: Intermediate
- C++ Interview Questions And Answers With Code Examples
- C++ Interview Questions and Answers: Advanced
- Test Your Skills: Quiz Time
- MBA Interview Questions: B.Com Economics
- B.Com Marketing
- B.Com Finance
- B.Com Accounting and Finance
- Business Studies
- Chartered Accountant
- Q1. Please tell us something about yourself/ Introduce yourself to us.
- Q2. Describe yourself in one word.
- Q3. Tell us about your strengths and weaknesses.
- Q4. Why did you apply for this job/ What attracted you to this role?
- Q5. What are your hobbies?
- Q6. Where do you see yourself in five years OR What are your long-term goals?
- Q7. Why do you want to work with this company?
- Q8. Tell us what you know about our organization
- Q9. Do you have any idea about our biggest competitors?
- Q10. What motivates you to do a good job?
- Q11. What is an ideal job for you?
- Q12. What is the difference between a group and a team?
- Q13. Are you a team player/ Do you like to work in teams?
- Q14. Are you good at handling pressure/ deadlines?
- Q15. When can you start?
- Q16. How flexible are you regarding overtime?
- Q17. Are you willing to relocate for work?
- Q18. Why do you think you are the right candidate for this job?
- Q19. How can you be an asset to the organization?
- Q20. What is your salary expectation?
- Q21. How long do you plan to remain with this company?
- Q22. What is your objective in life?
- Q23. Would you like to pursue your Master's degree anytime soon?
- Q24. How have you planned to achieve your career goal?
- Q25. Can you tell us about your biggest achievement in life?
- Q26. What was the most challenging decision you ever made?
- Q27. What kind of work environment do you prefer to work in?
- Q28. What is the difference between a smart worker and a hard worker?
- Q29. What will you do if you don't get hired?
- Q30. Tell us three things that are most important for you in a job.
- Q31. Who is your role model and what have you learned from him/her?
- Q32. In case of a disagreement, how do you handle the situation?
- Q33. What is the difference between confidence and overconfidence?
- Q34. If you have more than enough money in hand right now, would you still want to work?
- Q35. Do you have any questions for us?
- Interview Tips for Freshers
- Tell me about yourself
- What are your greatest strengths?
- What are your greatest weaknesses?
- Tell me about something you did that you now feel a little ashamed of
- Why are you leaving (or did you leave) this position??
- 15+ resources for preparing most-asked interview questions
- CoCubes Interview Process Overview
- Common CoCubes Interview Questions
- Key Areas to Focus on for CoCubes Interview Preparation
- Conclusion
- Frequently Asked Questions (FAQs)
- Data Analyst Interview Questions With Answers
- About Data Analyst
50+ JP Morgan Interview Questions (Technical and HR) for 2026

JPMorgan Chase & Co. is among the largest banks and tech companies, with its headquarters located in New York. If you wish to get a desirable job in this company, then you must crack its recruitment rounds by answering all the interview questions correctly. Here we are sharing all the information along with a list of JPMorgan interview questions:
JP Morgan interview questions: Technical round
Here is a list of JPMorgan interview questions that you must check out before you appear for D-day:
1. What is the fundamental difference between an array and an array list?

| Feature | Arrays | ArrayLists |
|---|---|---|
| Size | Fixed size | Dynamic size |
| Type of data | Single data type | Any data type |
| Underlying implementation | Simple contiguous memory | Java Collection framework |
| Flexibility | Static size | Dynamic resizing |
| Performance | Efficient in memory and access time | May have some performance overhead |
| Ability to resize | Not resizable | Resizable |
| Insertion/Deletion | Requires copying elements | Provides methods for adding/removing elements |
| Memory usage | More efficient | May have some overhead |
| Access time | Direct access using indices | Access using methods |
| Java standard library | Yes | Yes |
2. What is the difference between collections and a single collection?
The term "collections" in programming usually refers to data structures or classes that are used to store and manipulate groups of related objects or elements. On the other hand, "a single collection" may refer to a specific instance or object of a collection data structure.
Here's a comparison between "collections" and "a single collection" in programming:
Collections:
- Refers to a general concept or category of data structures or classes used to store and manipulate groups of related objects or elements.
- Collections are typically designed to provide various methods and functionalities for adding, removing, searching, sorting, and manipulating elements within the collection.
- Examples of collections in programming include arrays, lists, sets, maps, stacks, queues, and more.
- Collections can be used to store and manage collections of data elements in a structured way, making it easier to perform operations on the entire group of elements collectively.
A Single Collection:
- Refers to a specific instance or object of a collection data structure.
- Represents a particular occurrence or instantiation of a collection data structure with its own set of elements, properties, and state.
- A single collection object typically has its own specific data and behavior, which can be accessed and manipulated through its methods and properties.
- Single collections are used to store and manage a particular set of data elements that are related and need to be processed together as a whole.
3. What is the key distinction between reading from files and reading from buffers?
The key distinction between reading from files and reading from buffers is the source of data (external storage vs. in-memory), the data transfer mechanism (I/O operations vs. direct memory access), buffering, and the flexibility in handling different data sources and formats. Reading from files involves reading data from external storage devices while reading from buffers involves reading data that is already in memory, typically resulting in faster access and processing.
4. What explains the difference between TestNG and grid?
TestNG and Selenium Grid are two different tools commonly used in the field of automated testing for software applications. Here are the key differences between TestNG and Selenium Grid:
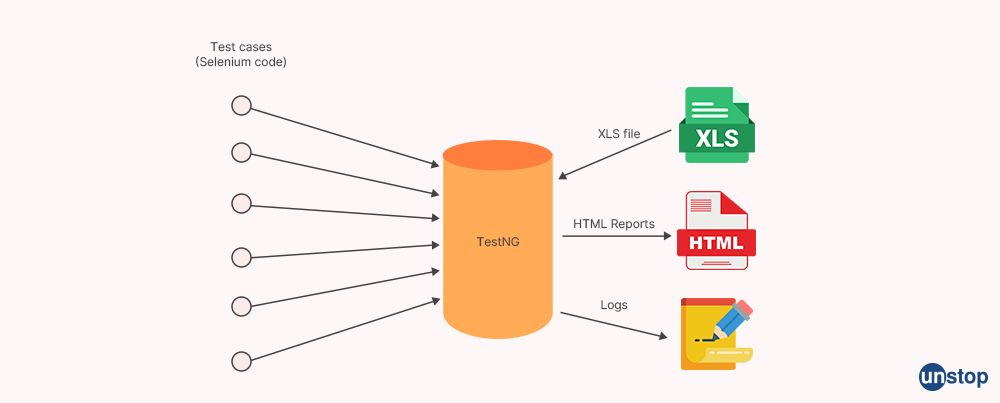
-
TestNG: TestNG is a testing framework for Java applications that provides advanced features for test configuration, test execution, and reporting. It is widely used for unit testing, integration testing, and end-to-end testing of Java applications. TestNG supports various annotations, test configurations, data-driven testing, parallel test execution, and advanced reporting. It also provides features like test configuration through XML files, test grouping, and test parameterization. TestNG is typically used for test automation at the code level, allowing developers and testers to write tests as code using Java, and it can be integrated with popular build tools like Maven and Gradle.
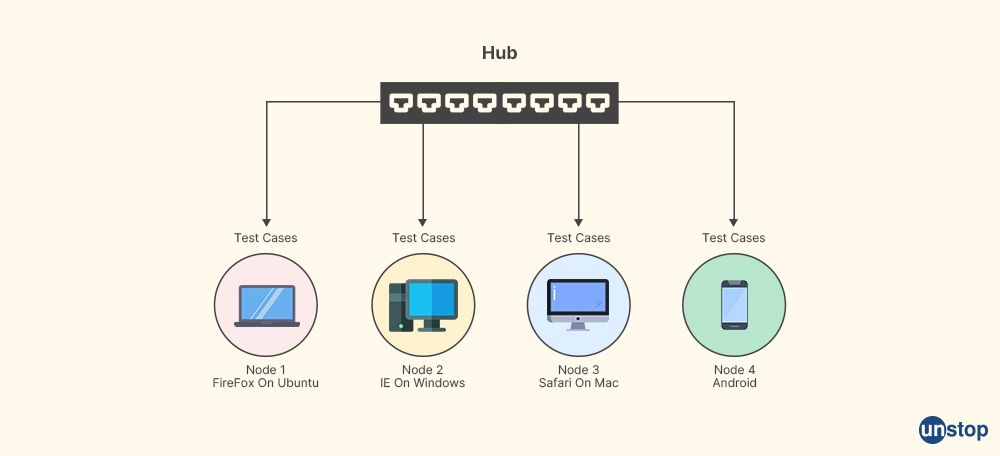
- Selenium Grid: Grid is a tool in the Selenium suite that enables distributed test execution across multiple machines and browsers. It allows you to create a Selenium test infrastructure that can run tests in parallel on different browsers, operating systems, and machines. Selenium Grid uses a hub-node architecture where the hub acts as a central point that controls the test execution on multiple nodes (machines) running Selenium WebDriver instances. Selenium Grid provides a way to scale your test execution by distributing tests across multiple machines and browsers, enabling faster execution and increased test coverage.
5. In a setting that makes use of several threads, what is the problem with utilizing the HashMap data structure? When does the get() function transition into an endless loop?
HashMap is not thread-safe in Java, which means that concurrent access to HashMap by multiple threads without proper synchronization can result in unexpected behavior, including data corruption and infinite loops. When multiple threads access and modify a HashMap concurrently without proper synchronization, the following problems can occur:
-
Concurrent modifications: If multiple threads modify a
HashMapconcurrently, such as adding or removing entries, the internal state of theHashMapcan become corrupted. For example, one thread may be in the middle element of adding an entry while another thread is trying to resize theHashMap, resulting in inconsistent or lost data. -
Inconsistent view: If one thread modifies
HashMapwhile another thread is reading from it concurrently, the reading thread may see an inconsistent or partial view of theHashMapstate. This can lead to unexpected behavior, such as missing or stale data. -
Infinite loop in
get(): In rare cases, concurrent modifications to aHashMapcan cause theget()function to enter into an infinite loop. This can happen when one thread is modifying theHashMapwhile another thread is trying to perform aget()operation. Theget()operation relies on the internal structure ofHashMap, such as the bucket index and linked list of entries, which can become inconsistent due to concurrent modifications, leading to an infinite loop.
To avoid these problems, when using a HashMap in a multi-threaded environment, it is important to use proper synchronization mechanisms, such as synchronized blocks or other concurrent data structures, to ensure that access to the HashMap is properly serialized and coordinated among threads. Alternatively, you can use thread-safe alternatives to HashMap, such as ConcurrentHashMap, which is designed to be used in concurrent environments and provides built-in thread-safety mechanisms to avoid these issues.
8. Why is it that Java's String object cannot be changed?
In Java, the String object is immutable, which means that its value cannot be changed after it is created. Once a String object is created, its state remains constant, and any operation that appears to modify a String actually creates a new String object with the desired value. There are several reasons why String objects are designed to be immutable in Java:
-
String Pool: Java maintains a special area in the heap memory called the "String pool" where it stores literal string values to conserve memory. Since strings are commonly used in Java programs, making
Stringobjects immutable allows them to be safely stored in the string pool and shared by multiple references, without the need for redundant copies. This helps to reduce memory usage and improve performance. -
Security: Strings in Java are often used to store sensitive information such as passwords or encryption keys. Making
Stringobjects immutable ensures that once a string is created with sensitive information, its value cannot be changed inadvertently or maliciously by other parts of the code. This helps to improve the security of the sensitive data. -
Thread-safety: Immutable objects, including
Stringobjects, are inherently thread-safe. Since their state cannot be changed after creation, they can be safely shared among multiple threads without the need for explicit synchronization. This simplifies concurrent programming and helps to prevent potential thread-safety issues. -
Predictable behavior: Immutable objects, including
Stringobjects, have predictable behavior because their state does not change. This makes them easier to reason about and avoids potential bugs that can arise from unexpected changes in the object state. - Performance optimizations: Immutable objects, including
Stringobjects, enable performance optimizations in Java compilers and runtime environments. For example, Java compilers can perform compile-time concatenation of string literals, and JVMs can optimize string concatenation operations for performance, knowing thatStringobjects are immutable.
7. When does the checkpoint event in DBMS take place?
In a database management system (DBMS), a checkpoint event refers to the process of saving the current state of modified data from memory to stable storage, typically disk, in order to ensure data durability and recoverability. The checkpoint event typically takes place at specific points in time or under certain conditions, depending on the implementation and configuration of the DBMS.
The exact timing of a checkpoint event may vary depending on the DBMS and its settings, but it typically occurs in one or more of the following scenarios:
-
Periodic checkpoints: Some DBMS systems are configured to perform periodic checkpoints at regular intervals. For example, a DBMS may be set to perform a checkpoint every 5 minutes, 30 minutes, or any other time interval specified by the database administrator. This ensures that changes made to the database are periodically saved to stable storage, reducing the amount of data that may be lost in the event of a system failure.
-
System shutdown: When a DBMS is shut down in an orderly manner, it may perform a checkpoint to ensure that any modified data in memory is saved to stable storage before the system is shut down. This helps to maintain data integrity and recoverability in case of a planned shutdown, such as during system maintenance or upgrades.
-
Transaction log size or time threshold: Some DBMS systems perform a checkpoint when the transaction log reaches a certain size or time threshold. The transaction log is a record of changes made to the database and is typically used for recovery purposes. When the transaction log grows too large or reaches a certain age, a checkpoint may be triggered to save the modified data to stable storage.
-
Database backup: When performing a database backup, some DBMS systems may include a checkpoint to ensure that the most recent state of the database is saved to stable storage as part of the backup process. This helps to ensure that the backup contains up-to-date data that can be used for recovery purposes.
8. How is Structured Query Language (SQL) designed?
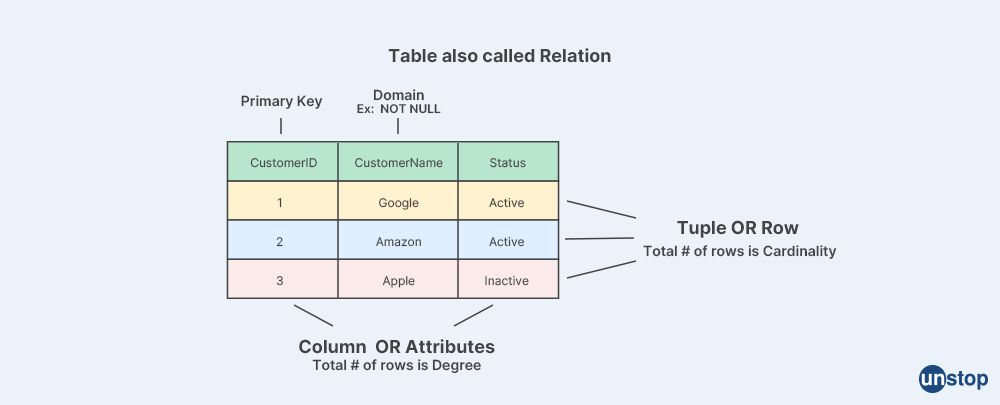
Structured Query Language (SQL) is a domain-specific programming language designed for managing relational databases. SQL is based on the relational model, which was introduced by Dr. Edgar F. Codd in the 1970s, and it provides a standardized way to communicate with relational databases to store, retrieve, update, and manage data.
SQL is designed with the following key features:
-
Declarative language: SQL is a declarative language, which means that users specify what they want to do with the data, rather than how to do it. Users define the desired outcome, and the database management system (DBMS) takes care of how to execute the query or operation.
-
Set-based operations: SQL is optimized for working with sets of data, rather than individual rows or records. SQL provides powerful set-based operations, such as SELECT, INSERT, UPDATE, DELETE, and others, which allow users to manipulate data in batches, making it efficient for working with large datasets.
-
Data definition and data manipulation: SQL provides both data definition language (DDL) and data manipulation language (DML) capabilities. DDL allows users to define and manage the structure of a database, including creating tables, defining constraints, and managing indexes. DML allows users to query, insert, update, and delete data in the database.
-
Schema and data integrity: SQL allows users to define a database schema, which is a logical structure that defines the relationships between tables and the constraints that must be satisfied by the data. SQL provides mechanisms for enforcing data integrity, such as primary keys, foreign keys, unique constraints, check constraints, and triggers.
-
Transaction management: SQL supports transaction management, allowing users to perform multiple operations as part of a single transaction that can be committed or rolled back as a unit. This ensures data consistency and integrity in multi-user environments.
-
Client-Server architecture: SQL is designed to work in a client-server architecture, where a client application communicates with a server-based database management system (DBMS) to perform operations on the database. SQL provides mechanisms for connecting to databases, managing connections, and executing queries and operations from client applications.
-
Extensibility and standardization: SQL provides a rich set of standard features that are supported by most relational database management systems (RDBMS). SQL also allows for extensibility through vendor-specific extensions, stored procedures, functions, and triggers, which provide additional functionality beyond the standard SQL features.
9. What is the difference between the main key and the unique constraints?
In the context of databases, both primary keys and unique constraints are used to ensure data integrity and enforce uniqueness of values. However, there are some key differences between the two:
-
Definition: A primary key is a special type of unique constraint that uniquely identifies each row in a table. It is used to uniquely identify a specific row in a table and must have a unique value for each row. A table can have only one primary key. On the other hand, a unique constraint is used to ensure that a column or a combination of columns in a table contains unique values. A table can have multiple unique constraints.
-
Null values: Primary keys cannot contain null values, meaning that every row in a table must have a value for the primary key column. Unique constraints, on the other hand, can allow null values, meaning that multiple rows in a table can have null values for the columns with unique constraints.
-
Relationship with foreign keys: Primary keys are often used as references in other tables, creating relationships between tables in a database. Foreign keys in other tables refer to the primary key of a table, establishing relationships and enforcing referential integrity. Unique constraints can also be used as references in other tables as foreign keys, but they are not as commonly used for this purpose.
-
Number of columns: A primary key is typically defined on a single column in a table, although it can also be defined on multiple columns as a composite key. Unique constraints, on the other hand, can be defined on a single column or on multiple columns as well, providing flexibility in ensuring uniqueness based on different combinations of columns.
-
Modification: Primary keys are typically immutable and should not be modified once they are assigned to a row. Changing the value of a primary key is generally not recommended as it can lead to data integrity issues and can also affect relationships with foreign keys in other tables. Unique constraints, on the other hand, can be modified as long as the new value is unique, allowing for more flexibility in data modification.
10. What is the meaning of the term functional dependency?
Functional dependency, in the context of database management systems (DBMS), refers to a relationship between attributes or columns in a table, where the value of one or more attributes determines the value of another attribute(s). It is a concept used in database design and normalization to describe the relationship between attributes within a table.
A functional dependency is denoted by a notation A -> B, where A is the set of attributes that functionally determine B. This means that for every unique combination of values in A, there is only one possible value for B. In other words, the value of B is uniquely determined by the value(s) of A.
For example, let's consider a table called "Employees" with attributes "EmployeeID", "FirstName", "LastName", and "DepartmentID". If it is observed that for every unique value of "EmployeeID", there is only one possible value for "FirstName" and "LastName", then we can say that "EmployeeID" functionally determines "FirstName" and "LastName", which can be denoted as "EmployeeID -> FirstName, LastName".
11. What is denormalization and how does it work?
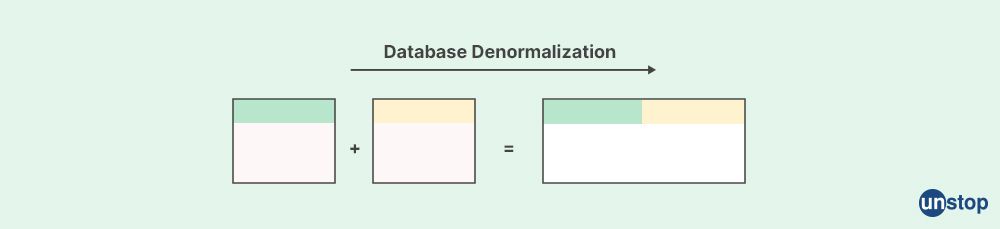
Denormalization is a database design technique in which redundant or duplicated data is intentionally added to a relational database in order to improve query performance or simplify data retrieval. It involves deliberately deviating from the normalization principles, which are a set of rules that guide the organization of data in relational databases to minimize redundancy and ensure data integrity.
The process of denormalization involves combining or duplicating data across multiple tables, usually by adding redundant columns or duplicating data from related tables, to create a flatter or more compact data structure. This can eliminate the need for complex joins or calculations at query time, which can improve query performance and reduce the overhead of database operations.
Denormalization can be used strategically in certain situations where the trade-offs of redundant data are deemed acceptable for the benefits of improved query performance, simplified data retrieval, or other specific requirements.
12. Within the realm of DBMS, what is meant by the term "correlated subquery"?
In the context of database management systems (DBMS), a correlated subquery refers to a type of SQL (Structured Query Language) subquery that is evaluated for each row of the outer query. It is called "correlated" because the subquery is dependent on the values of the outer query, and the values from the outer query are used as parameters or references in the subquery.
A correlated subquery is typically enclosed in parentheses and appears within a larger SQL query. It can reference columns from tables in the outer query, and the subquery's results are used in the evaluation of the outer query. The subquery is executed repeatedly, once for each row in the outer query, and the results of the subquery are used in the evaluation of the outer query's condition or expression.
Correlated subqueries are used to perform complex queries that involve data from multiple tables or require calculations or comparisons with data from the outer query. They can be used in various SQL clauses such as SELECT, WHERE, FROM, and HAVING to filter or retrieve data based on related data in other tables or based on conditions that depend on values from the outer query.
13. Describe what a relation schema is and mention what a relation is under it.
A relation, also known as a table, is a fundamental concept in relational databases. It represents a collection of related data organized in rows and columns. Each row in a relation represents a single instance or record, and each column represents a specific attribute or property of that record. The relation schema defines the structure of the table, including the names of the columns, their data types, and any constraints that apply to the data.
For example, let's consider a simple relation schema for a "Customer" table in a hypothetical e-commerce database:
Relation Schema for "Customer" Table:
- CustomerID (Primary Key): Integer
- FirstName: String
- LastName: String
- Email: String
- Phone: String
- Address: String
In this case, the "Customer" table has five attributes: CustomerID, FirstName, LastName, Email, Phone, and Address. The data type of CustomerID is Integer, while the data types of FirstName, LastName, Email, Phone, and Address are String. The CustomerID attribute is designated as the primary key, which uniquely identifies each record in the table. This relation schema defines the structure of the "Customer" table, but it does not contain any actual data. The data will be stored in the "Customer" table as rows, with each row representing a specific customer record with values for the attributes defined in the relation schema.
14. What is meant by the entity-relationship model?
The Entity-Relationship (ER) model is a conceptual data modeling technique used in software engineering and database design to represent the relationships between entities (objects or things) in a system and how they are related to each other. It is a graphical representation that helps in understanding and visualizing the structure of a database system.
In the ER model, entities are represented as rectangles, and relationships between entities are represented as diamonds or lines connecting the rectangles. Attributes (properties or characteristics) of entities are represented as ovals or ellipses, and they provide additional information about the entities.
The ER model helps in defining the structure and organization of data in a database system, including entities, attributes, relationships, and cardinality (the number of instances of one entity that can be associated with instances of another entity). It provides a high-level view of the data requirements of a system, and it serves as a foundation for creating a physical database schema, which is the actual implementation of the database system.
The ER model is widely used in database design and is considered a standard technique for modeling and representing the structure of data in relational databases. It helps in identifying entities, their relationships, and attributes, and provides a clear and concise way of representing the complex relationships between different entities in a system.
One click. Endless opportunities. Land your dream job today!
15. Describe an architecture with two levels.
An architecture with two levels typically refers to a design or structure with two distinct layers or tiers. Each tier has a specific purpose and functionality, and they interact with each other to achieve a particular goal. Here are some examples of architectures with two levels:
-
Client-Server Architecture: This is a common architecture where clients, typically user interfaces or applications running on end-user devices, interact with servers, which are responsible for processing requests and providing services. The client layer handles user interactions and user interface rendering, while the server layer handles business logic, data processing, and storage. Communication between the client and server occurs over a network, often using standard protocols such as HTTP, TCP/IP, or other custom protocols.
-
Presentation-Logic Architecture: This architecture involves separating the presentation (UI/UX) layer from the business logic layer. The presentation layer handles the user interface, user experience, and user interaction, while the logic layer handles the business rules, processing, and data manipulation. This separation allows for independent development and maintenance of the UI and business logic, making it easier to update or modify each layer without affecting the other.
-
Database Application Architecture: In this architecture, there are two main layers: the database layer and the application layer. The database layer is responsible for managing data storage, retrieval, and manipulation, while the application layer handles the business logic, data processing, and user interface. The application layer communicates with the database layer to perform CRUD (Create, Read, Update, Delete) operations on the data.
-
Two-Tier Web Application Architecture: This architecture involves a client layer (usually a web browser) that communicates directly with a server layer (which includes a web server and a database server). The client layer handles the user interface and user experience, while the server layer handles the business logic, data processing, and data storage. The client sends requests to the server, which processes the requests and returns responses to the client.
-
Message-Queue Architecture: In this architecture, there are typically two main layers: the sender layer and the receiver layer. The sender layer is responsible for generating and sending messages, while the receiver layer is responsible for processing and consuming those messages. The sender and receiver layers communicate through a message queue, which acts as an intermediary for exchanging messages between the two layers.
16. How does the process of exchanging data work?
The process of exchanging data typically involves transferring data between two or more entities, such as software applications, systems, devices, or users. The exchange of data can occur through various methods, protocols, and formats depending on the context and requirements of the data exchange.
Here is a general overview of the process of exchanging data:
-
Data Generation: The data to be exchanged is generated or created by the source entity. This can include user input, sensor readings, data processing results, or any other form of data that needs to be exchanged.
-
Data Representation: The data is represented in a format that can be understood by both the source and destination entities. This can involve converting data into a common data format, such as XML, JSON, CSV, or binary formats, that is agreed upon by both parties.
-
Data Transmission: The data is transmitted from the source entity to the destination entity over a communication channel or network. This can be done using various communication protocols, such as HTTP, FTP, TCP/IP, or custom protocols, depending on the nature of the data exchange and the communication medium being used.
-
Data Reception: The destination entity receives the transmitted data and decodes it to understand the original data format. This may involve parsing the data, decrypting it if necessary, and converting it into a format that can be processed by the destination entity.
-
Data Processing: The destination entity processes the received data according to its intended purpose. This can involve storing the data in a database, performing calculations, updating system states, or triggering actions based on the received data.
-
Data Acknowledgment: The destination entity may send an acknowledgment or response back to the source entity to confirm the successful receipt and processing of the data. This can be done using acknowledgment messages, response codes, or other means of communication to ensure data integrity and reliability.
-
Error Handling: If any errors or exceptions occur during the data exchange process, error handling mechanisms may be implemented to handle exceptions, retries, or notifications to ensure data integrity and reliability.
-
Security Considerations: Data exchange may involve sensitive or private information, and therefore security measures such as encryption, authentication, and authorization may be implemented to protect the data from unauthorized access or tampering.
The act of taking data that has been formatted according to a source schema and transforming it into information that has been structured according to a target schema in such a way that the dataset is an accurate representation of something like the source data, is known as data exchange. The ability to transmit data across applications on a computer makes it possible to share data.
17. What is the purpose of Java's abstract class?
In Java, an abstract class is a class that cannot be instantiated, meaning you cannot create objects of that class directly. It is meant to be subclassed by other classes, which are then used to create objects. The main purpose of an abstract class in Java is to provide a common template or blueprint for other classes to inherit from and share common properties, methods, and behavior.
The key purposes of using an abstract class in Java are:
-
Providing a common interface: An abstract class can define common attributes and methods that are shared by its subclasses. Subclasses that inherit from the abstract class can access these attributes and methods, providing a common interface for objects of those classes.
-
Enforcing a contract: An abstract class can define abstract methods, which are methods without an implementation in the abstract class. Subclasses that inherit from the abstract class must provide implementations for these abstract methods, thus enforcing a contract that specifies what methods must be implemented by the subclasses.
-
Encapsulating common behavior: An abstract class can encapsulate common behavior that can be shared by its subclasses. This can include default implementations of methods, common data members, or utility methods that are used by the subclasses.
-
Allowing for future expansion: An abstract class can serve as a base class that can be extended in the future to add more functionality or behavior. It provides a foundation for creating more specialized subclasses that can inherit and extend the common properties and behavior defined in the abstract class.
-
Polymorphism: An abstract class can be used as a type to create references or variables that can hold objects of its subclasses. This allows for polymorphism, where objects of different classes that inherit from the same abstract class can be treated as objects of the same type and used interchangeably.
18. What is class?
A class serves as a blueprint for creating objects, which are concrete instances of the class. It defines the attributes (data members) and methods (member functions) that objects of that class can have.
A class is a user-defined data type that encapsulates data and behavior, allowing for the creation of objects with specific characteristics and functionality. It acts as a template that describes the common properties and behavior that objects of that class will possess. Classes define the structure and behavior of objects, and objects are the concrete instances of classes that can be created and used in a software program.
public class Circle {
// Data members or attributes
private double radius;
// Constructor
public Circle(double radius) {
this.radius = radius;
}
// Methods or member functions
public double calculateArea() {
return Math.PI * radius * radius;
}
public double calculatePerimeter() {
return 2 * Math.PI * radius;
}
}
19. What does empty class refer to?
In the context of object-oriented programming (OOP), an "empty class" typically refers to a class that does not have any attributes (data members) or methods (member functions) defined in it. It is also known as a "blank class" or "skeleton class".
An empty class serves as a basic template or starting point for creating more complex classes by adding attributes and methods as needed. It may contain only the class declaration, which includes the class name, access modifiers (e.g., public, private, protected), and any interfaces or parent classes it inherits from. However, it does not contain any additional code or logic for data manipulation or behavior implementation.
Here is an example of an empty class in Java:
public class EmptyClass {
// Empty class declaration with no attributes or methods
}
20. What is an object?
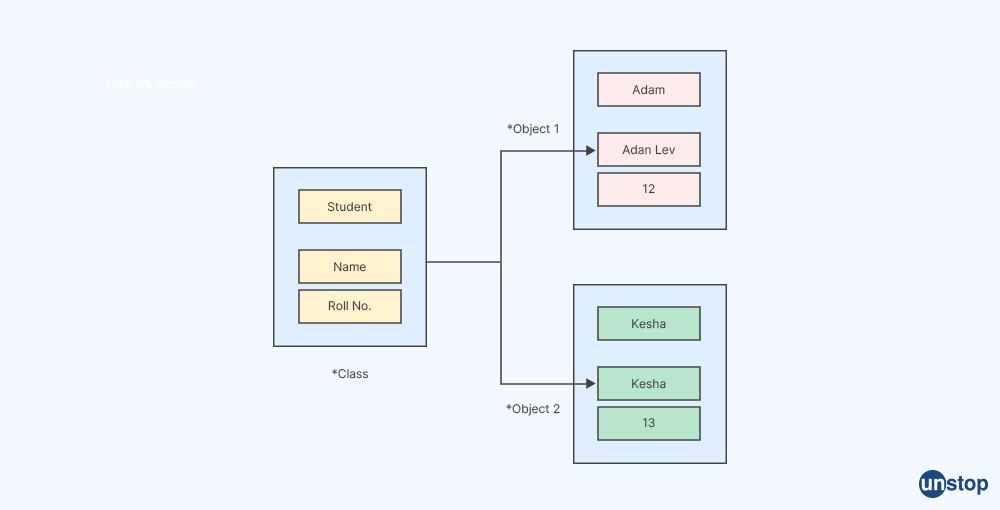
In the context of object-oriented programming (OOP), an object is a concrete instance of a class, which is a blueprint or template that defines the structure and behavior of objects. An object represents a specific entity or thing in a software program and can be used to model real-world objects, such as a person, a car, a bank account, or any other concept that can be represented as data with associated behavior.
An object is created from a class, and it can have its own state (data) and behavior (methods) defined by the class. The state of an object is represented by its attributes or properties, which are variables that hold data specific to that object. The behavior of an object is represented by its methods, which are functions or procedures that perform actions or operations on the object's data.
Objects in OOP can interact with one another by sending messages or invoking methods on each other. They can also have relationships with other objects, such as composition, aggregation, or association, which represent how objects are connected or related to each other in the software system.
Objects provide a way to model complex systems and represent real-world entities in a software program. They encapsulate data and behavior, allowing for modular, reusable, and maintainable code. Objects are the building blocks of an OOP program, and their interactions form the basis for the behavior and functionality of the software system.
21. What are the notions of OOP?
The notions of Object-Oriented Programming (OOP) are the fundamental concepts and principles that form the basis of the OOP paradigm. OOP is a programming paradigm that uses objects, which are instances of classes, to represent and manipulate data and behavior in a software program. The main notions of OOP include:
-
Classes and Objects: Classes are blueprints or templates that define the structure and behavior of objects, while objects are instances of classes that represent individual entities with their own state (data) and behavior (methods).
-
Encapsulation: Encapsulation is the process of hiding the internal details and implementation of objects and exposing only the necessary information through well-defined interfaces. It helps in achieving data abstraction and information hiding.
-
Inheritance: Inheritance is a mechanism that allows a class to inherit properties and behavior from another class, called the superclass or base class. It enables code reuse and promotes code organization and modularity.
-
Polymorphism: Polymorphism allows objects of different classes to be treated as if they were of the same class, providing a common interface for interacting with objects of different types. It enables code flexibility, extensibility, and reusability.
-
Abstraction: Abstraction is the process of simplifying complex systems by breaking them down into smaller, more manageable parts. It involves defining abstract classes, interfaces, and methods that provide common behavior and characteristics to a group of related classes.
-
Message Passing: In OOP, objects communicate with each other by sending messages, which are requests for invoking methods on objects. Message passing is a way of achieving communication and interaction among objects in an OOP program.
-
Polymorphic Relationships: Polymorphic relationships allow objects to be associated with one another through a common interface or abstract class, rather than through concrete classes. This promotes flexibility and extensibility in the design of software systems.
-
Overloading and Overriding: Overloading is the ability to define multiple methods in a class with the same name but different parameter lists, while overriding is the ability of a subclass to provide a new implementation for a method that is already defined in its superclass.
22. What does normalization mean?
Normalization is the process of organizing and structuring data in a database to eliminate redundancy and improve data integrity and consistency. It involves applying a set of rules or guidelines to design and structure the database tables in a way that minimizes data redundancy and ensures that each piece of data is stored in only one place.
The goal of normalization is to prevent anomalies and inconsistencies in the database that can arise from redundant data storage or data duplication. Normalization helps maintain data integrity and consistency by reducing redundancy and ensuring that data is stored in a well-structured and organized manner.
Normalization is typically done according to a set of normalization rules or normal forms, which are guidelines that specify the requirements for organizing data in a relational database. The most commonly used normal forms are:
-
First Normal Form (1NF): Ensures that each column in a table contains atomic (indivisible) values, and there are no repeating groups or arrays.
-
Second Normal Form (2NF): Builds on 1NF and requires that each non-primary key column is fully dependent on the primary key, eliminating partial dependencies.
-
Third Normal Form (3NF): Builds on 2NF and requires that each non-primary key column is independent of other non-primary key columns, eliminating transitive dependencies.
There are higher normal forms such as Boyce-Codd Normal Form (BCNF) and Fourth Normal Form (4NF) that further eliminate redundancies, but they are less commonly used.
By normalizing the data, redundant data is eliminated, and the database becomes more efficient in terms of storage space, data retrieval, and data modification operations. Normalization helps maintain data integrity, consistency, and accuracy, which are critical aspects of database design and data management.
23. Are you able to specify insertion into a binary tree?
A binary tree is a data structure composed of nodes, where each node has at most two child nodes, and it has the following properties:
- The left subtree of a node contains only nodes with values less than the node's value.
- The right subtree of a node contains only nodes with values greater than the node's value.
- Both the left and right subtrees are also binary trees.
To insert a node into a binary tree, you typically follow these steps:
- Start at the root of the binary tree.
- Compare the value of the node to be inserted with the value of the current node.
- If the value of the node to be inserted is less than the value of the current node, move to the left child of the current node.
- If the value of the node to be inserted is greater than the value of the current node, move to the right child of the current node.
- Repeat steps 2-4 until you reach an empty spot in the binary tree, where the node can be inserted as a leaf node.
- Insert the node into the empty spot.
Here's an example of inserting a node into a binary tree in Java:
public class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int val) { this.val = val; }
}
public TreeNode insert(TreeNode root, int val) {
if (root == null) {
return new TreeNode(val);
}
if (val < root.val) {
root.left = insert(root.left, val);
} else if (val > root.val) {
root.right = insert(root.right, val);
}
return root;
}
cHVibGljIGNsYXNzIFRyZWVOb2RlIHsKaW50IHZhbDsKVHJlZU5vZGUgbGVmdDsKVHJlZU5vZGUgcmlnaHQ7ClRyZWVOb2RlKGludCB2YWwpIHsgdGhpcy52YWwgPSB2YWw7IH0KfQoKcHVibGljIFRyZWVOb2RlIGluc2VydChUcmVlTm9kZSByb290LCBpbnQgdmFsKSB7CmlmIChyb290ID09IG51bGwpIHsKcmV0dXJuIG5ldyBUcmVlTm9kZSh2YWwpOwp9CmlmICh2YWwgPCByb290LnZhbCkgewpyb290LmxlZnQgPSBpbnNlcnQocm9vdC5sZWZ0LCB2YWwpOwp9IGVsc2UgaWYgKHZhbCA+IHJvb3QudmFsKSB7CnJvb3QucmlnaHQgPSBpbnNlcnQocm9vdC5yaWdodCwgdmFsKTsKfQpyZXR1cm4gcm9vdDsKfQ==
24. Who is responsible for handling data looping?
In computer programming, data looping is typically handled by the software developer who writes the code. The responsibility for handling data looping lies with the programmer, who designs and implements the logic for iterating over data elements in a loop.
Data looping is a fundamental concept in programming and is used to iterate over collections of data, such as arrays, lists, or other data structures. The programmer is responsible for designing the loop structure, specifying the loop condition, and defining the loop body, which contains the code to be executed for each iteration of the loop.
The loop structure typically includes the loop initialization, loop condition, and loop update or increment. The programmer defines the loop condition, which determines when the loop should continue iterating, and the loop body, which contains the code to be executed for each iteration of the loop. The loop update or increment is used to modify the loop control variable, which determines the progression of the loop.
Here's an example of a simple loop in Java:
for (int i = 0; i < 10; i++) {
System.out.println("Iteration: " + i);
}
25. What do nested loops stand for?
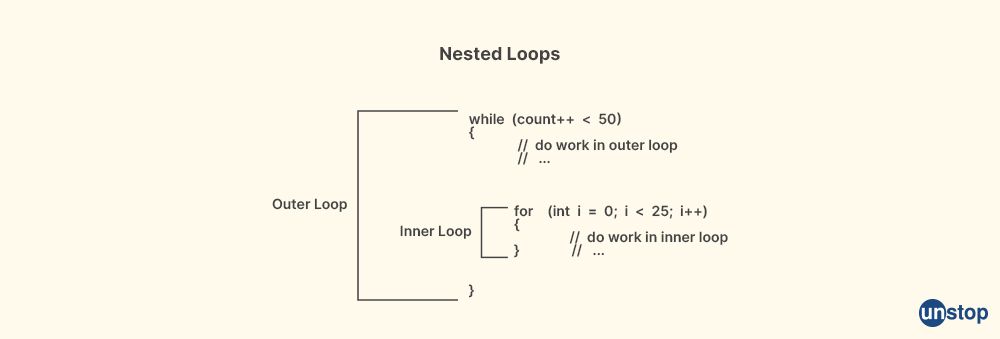
A nested loop in computer programming refers to a loop that is placed inside another loop. In other words, it's a loop that is contained within another loop. The outer loop is executed once, and for each iteration of the outer loop, the inner loop is executed multiple times.
The purpose of using nested loops is to perform repetitive tasks or iterate over elements in multi-dimensional data structures, such as arrays or matrices. The outer loop provides the broader iteration, while the inner loop provides the finer-grained iteration within the outer loop.
Nested loops are commonly used in programming when you need to perform operations that require multiple levels of iteration. For example, if you have a two-dimensional array representing a grid of data, you might use nested loops to iterate over the rows and columns of the array.
Here's an example of a nested loop in Java that prints the multiplication table:
for (int i = 1; i <= 10; i++) {
for (int j = 1; j <= 10; j++) {
System.out.print(i * j + "\t");
}
System.out.println();
}
26. What is inherited wealth?
In Java, inheritance is a concept related to object-oriented programming (OOP) that allows one class to inherit properties and methods from another class. Inheritance enables code reuse and promotes code organization and modularity.
In Java, a class that inherits properties and methods from another class is called a "subclass" or "derived class", and the class from which properties and methods are inherited is called the "superclass" or "base class". The subclass inherits the public and protected properties and methods of the superclass, and can override or extend them as needed.
Inheritance in Java allows for the creation of a class hierarchy, where classes can be organized in a hierarchical manner based on their relationships. The superclass can provide common properties and methods that are inherited by its subclasses, and subclasses can provide specialized implementations or additional functionality.
27. What is polymorphism?
Polymorphism is a concept in computer programming and object-oriented programming (OOP) that allows objects of different classes or types to be treated as if they were of the same type. It allows for the same code to work with different types of objects interchangeably, providing flexibility and extensibility in software design.
Polymorphism enables a single function or method to operate on different types of objects, without needing to know the specific type of each object at compile-time. Instead, the type of the object is determined at runtime, based on the actual object that is being operated upon. This allows for code to be written in a more general and reusable way, as it can work with objects of different types as long as they conform to a common interface or behavior.
Polymorphism is typically achieved through the use of interfaces or inheritance in OOP languages. Interfaces define a common set of methods that objects must implement, while inheritance allows objects of a derived class to be treated as objects of a base class. This allows objects of different classes to be used interchangeably if they implement the same interface or inherit from the same base class.
28. What precisely is the destructor?

In object-oriented programming (OOP), a destructor is a special member function of a class that is called automatically when an object of that class is destroyed or goes out of scope. It is used for releasing resources, such as memory or file handles, that were acquired by the object during its lifetime.
In some programming languages, such as C# and C++, destructors are defined using a special syntax, typically with the same name as the class preceded by a tilde (~) character. For example, in C++:
class MyClass {
public:
// Constructor
MyClass() {
// Constructor logic
}
// Destructor
~MyClass() {
// Destructor logic
}
};
Y2xhc3MgTXlDbGFzcyB7CnB1YmxpYzoKLy8gQ29uc3RydWN0b3IKTXlDbGFzcygpIHsKLy8gQ29uc3RydWN0b3IgbG9naWMKfQoKLy8gRGVzdHJ1Y3Rvcgp+TXlDbGFzcygpIHsKLy8gRGVzdHJ1Y3RvciBsb2dpYwp9Cn07
29. What is abstract?
In the context of object-oriented programming (OOP), an abstract method is a method that is declared in an abstract class or an interface but does not have an implementation. Instead, it is meant to be overridden by subclasses or implemented by classes that implement the interface.
An abstract method serves as a blueprint or a contract for the derived classes or implementing classes, specifying what methods they must provide with their own implementation. Abstract methods are declared in abstract classes or interfaces using the "abstract" keyword, and they do not have a body or implementation. Here's an example of an abstract method declaration in Java:
public abstract class Animal {
public abstract void makeSound(); // Abstract method declaration
30. What are macros in Excel?
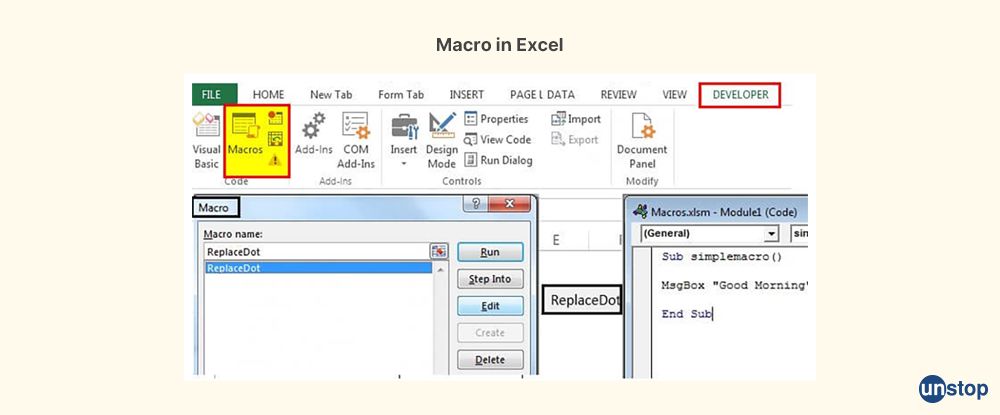
Macros in Excel refers to a feature that allows users to automate repetitive tasks by recording a series of actions and then playing them back as a single command or function. Macros are essentially sequences of Excel commands or actions that can be recorded, stored, and executed to automate tasks, such as data entry, formatting, calculations, and data manipulation, in Microsoft Excel.
Macros in Excel are written in a programming language called Visual Basic for Applications (VBA), which is a powerful and flexible programming language that allows users to create custom functions, automate tasks, and interact with Excel objects and data. VBA is an event-driven programming language, which means that macros can be triggered by specific events or actions, such as clicking a button, changing a cell value, or opening a workbook.
Excel macros can be created and managed using the Excel "Developer" tab, which needs to be enabled in the Excel ribbon through Excel options. Users can create macros by recording their actions in Excel and then saving the recorded actions as a macro. The macro can then be executed with a single click or assigned to a button, keyboard shortcut, or other trigger for easy execution.
31. What is meant by the term two-dimensional linked lists?
In computer programming and data structures, a two-dimensional linked list, also known as a 2D linked list, is a data structure that represents a collection of data elements organized in a two-dimensional grid or matrix-like structure, where each element is connected to its adjacent elements using pointers or references.
A standard linked list is a linear data structure in which each element, called a node, contains a data value and a reference or pointer to the next node in the list. In a two-dimensional linked list, each node may contain multiple references or pointers, allowing it to be connected to nodes in both horizontal and vertical directions, forming a grid-like structure.
A two-dimensional linked list can be thought of as a matrix, where each cell in the matrix corresponds to a node in the linked list. Each node contains a data value, as well as pointers or references to its adjacent nodes, such as the node above, the node below, the node to the left, and the node to the right. This allows for efficient traversal and manipulation of data elements in both horizontal and vertical directions.
32. Can you clarify the procedure that you will follow to run a linked array?
The data and a reference to the following node are the two components that make up each element (which we shall refer to as a node) of a list. The very last node does have a reference to the value null. The location at which one begins the journey through a linked list is referred to as the list's head. It is important to notice that the head is not a distinct node but rather a reference to the first node in the tree.
33. What is the meaning of the term merge?
In the context of data, "merge" typically refers to the process of combining data from two or more sources into a unified dataset. Data merging is a common data integration technique used in data management and data analysis to combine data from different sources and create a consolidated and integrated view of the data.
Data merging may involve combining data from multiple databases, spreadsheets, files, or other data sources. This can be done using various techniques, such as matching records based on common fields or keys, aggregating data, resolving conflicts or inconsistencies in the data, and creating a merged dataset that retains relevant information from all the sources.
Data merging is commonly used in data integration scenarios, such as data warehousing, data consolidation, and data analysis, where data from multiple sources needs to be combined to create a single, unified dataset for further processing or analysis. This process may also involve data cleansing, data transformation, and data enrichment to ensure data quality and consistency in the merged dataset.
34. What is memory management in Java?
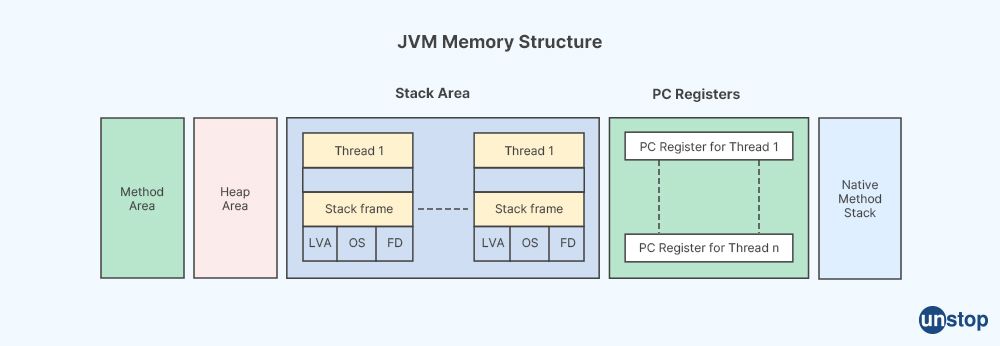
Memory management in the context of Java refers to the management of computer memory resources by the Java Virtual Machine (JVM), which is the component of the Java runtime environment (JRE) responsible for executing Java programs. Java uses an automatic memory management system known as garbage collection to automatically allocate and deallocate memory resources used by Java programs.
In Java, objects are created dynamically at runtime and stored in the heap memory, which is a region of memory used for storing objects and arrays. The JVM automatically allocates memory for objects when they are created using the "new" keyword, and deallocates memory for objects that are no longer reachable, i.e., objects that are no longer referenced by any live variables or reachable object graph. This automatic memory management system frees developers from explicitly allocating and deallocating memory, reducing the risk of memory-related bugs such as memory leaks and dangling pointers.
35. What is the distinction between the main key and the foreign key?
The main key, also known as the primary key, and the foreign key are two important concepts in relational database management systems (DBMS) that are used to establish relationships between tables in a database. They have distinct roles and characteristics:
Primary Key:
- A primary key is a unique identifier that is used to uniquely identify each row or record in a table in a relational database.
- It must have a unique value for each row in the table, meaning no two rows in the same table can have the same primary key value.
- It must be not null, meaning it must have a value for every row in the table.
- It is used to uniquely identify each record in the table and ensure data integrity and consistency.
- A table can have only one primary key, although it can be a composite key composed of multiple attributes.
Foreign Key:
- A foreign key is a column or set of columns in a table that refers to the primary key of another table in a relational database.
- It establishes a relationship between two tables, where the table containing the foreign key is called the referencing table or child table, and the table referred to by the foreign key is called the referenced table or parent table.
- It is used to establish relationships between tables and enforce referential integrity, which ensures that data in the referencing table corresponds to the data in the referenced table.
- It does not have to be unique and can have duplicate values in the referencing table.
- It allows for navigation between related tables and enables the creation of relationships, such as one-to-many or many-to-many, between tables in a database.
36. What is meant by multi-threading?
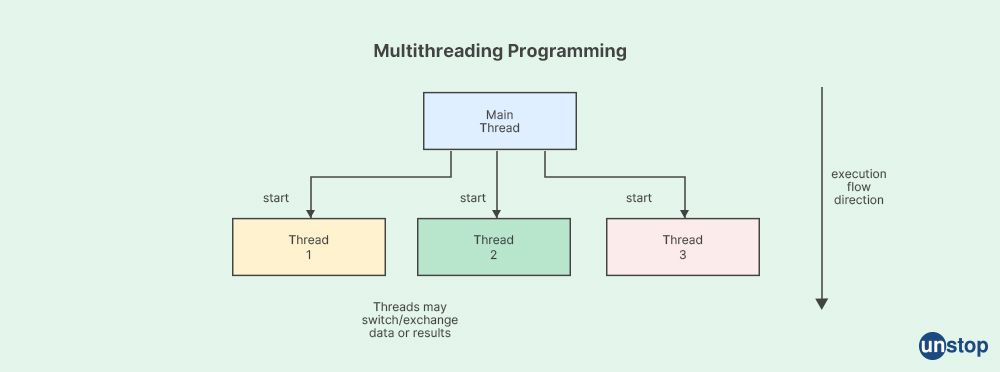
Multithreading refers to a computing concept where a single process or program is divided into multiple threads of execution that can be executed concurrently by the operating system or a computing system with multiple processors or cores. Each thread represents a separate sequence of instructions that can be scheduled and executed independently, allowing for concurrent execution of multiple threads within a single process.
Threads are smaller units of a program that share the same memory space and system resources, such as CPU time, file handles, and network connections, with the parent process. Threads within a process can communicate with each other more easily and quickly compared to separate processes running in isolation, as they share the same memory space. This makes multithreading a popular approach for achieving parallelism and improving the performance and responsiveness of concurrent software applications.
Multithreading can be used in various types of applications, including desktop applications, server applications, embedded systems, and high-performance computing. Common use cases for multithreading include performing multiple tasks concurrently, handling concurrent user requests, improving performance in resource-intensive applications, and achieving responsiveness in user interfaces.
37. Please explain ER model.
An ER (Entity-Relationship) model is a conceptual data model that represents the structure and relationships of data in a database system. It is a graphical representation used in database design to describe the entities, attributes, and relationships among entities in a database in a clear and organized manner.
In an ER model, entities are represented as rectangles, and relationships between entities are represented as lines connecting the rectangles. Attributes, which are properties or characteristics of entities, are depicted as ovals or ellipses connected to the respective entity rectangle. The ER model provides a visual representation of how data entities are related to each other and how they are organized in a database.
The main components of an ER model are:
-
Entities: Entities represent real-world objects, such as customers, products, employees, or orders, that are stored in a database. Each entity is identified by a unique attribute called a primary key, which distinguishes it from other entities of the same type.
-
Attributes: Attributes are properties or characteristics of entities that describe the data stored in the entities. For example, a customer entity may have attributes such as customer ID, name, address, and email.
-
Relationships: Relationships represent associations or connections between entities in a database. They describe how entities are related to each other and how they interact. Examples of relationships include "has-a," "belongs-to," "is-a," or "works-for." Relationships can be one-to-one, one-to-many, or many-to-many, depending on the cardinality and participation constraints of the relationship.
38. What are checkpoints?
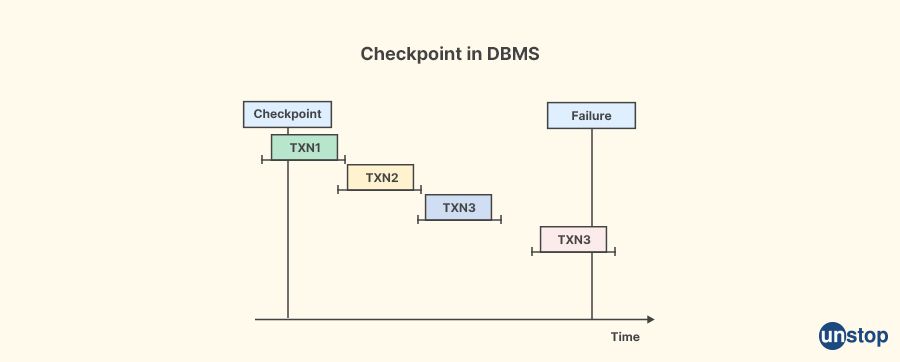
In the context of Database Management Systems (DBMS), a "checkpoint" refers to a mechanism used to periodically save the current state of a database system to stable storage, such as a disk, in order to provide a reliable point of recovery in case of system failures or crashes. Checkpoints are used to ensure the durability and consistency of data in a database.
Checkpoints typically involve writing the current state of the database, including any changes made by active transactions, to a persistent storage location. This creates a stable, consistent point that can be used as a reference during recovery in case of failures. Once the checkpoint is completed, the system can continue processing transactions from the updated state of the database.
39. What are transactions when it comes to DBMS?
In the context of a Database Management System (DBMS), transactions refer to a unit of work or a sequence of operations that are executed on a database and are treated as a single, indivisible operation. Transactions are used to ensure the integrity, consistency, and reliability of data in a database, particularly in multi-user environments where multiple users may access and modify the data concurrently.
Transactions in DBMS typically have four properties, known as the ACID properties:
-
Atomicity: Transactions are atomic, which means that either all of their operations are executed successfully or none of them are. If any part of a transaction fails, the entire transaction is rolled back, and all changes made by the transaction are undone, leaving the database in its original state.
-
Consistency: Transactions ensure that the database starts in a consistent state and ends in a consistent state. This means that the database transitions from one valid state to another valid state after a transaction is executed, maintaining data integrity and any defined constraints.
-
Isolation: Transactions are isolated from each other, meaning that the intermediate state of a transaction is not visible to other transactions until it is committed. This prevents interference and conflicts among concurrent transactions that may access the same data simultaneously.
-
Durability: Once a transaction is committed, its changes are permanently saved in the database and cannot be rolled back, even in the case of system failures. This ensures that the changes made by a committed transaction persist in the database and are not lost.
40. What is a collection of entities?
A collection of entities refers to a group or set of individual objects or items that are considered as a whole. It could be a gathering of similar or dissimilar things, such as objects, data, or concepts, that are grouped together based on a common characteristic or purpose. Collections are commonly used in various fields, including but not limited to, computer science, mathematics, statistics, biology, and social sciences. Examples of collections of entities include a library of books, a database of customer records, a collection of biological specimens in a museum, a portfolio of investments, or a set of images in a photo album.
41. What is a unique key?
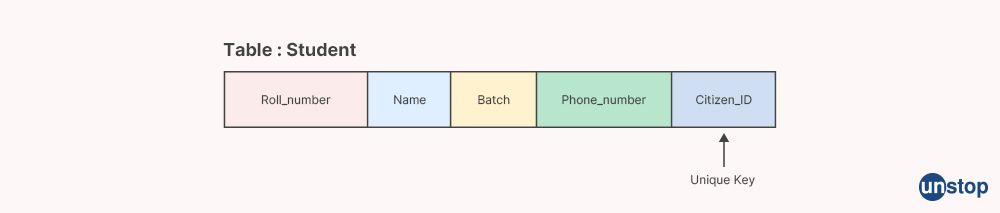
A unique key, also known as a unique constraint, is a database concept that specifies that the values in one or more columns of a table must be unique across all rows in that table. In other words, a unique key ensures that no duplicate values are allowed in the specified column(s) of a table.
A unique key provides a way to uniquely identify each row in a table, and it can be used as a means of enforcing data integrity and consistency in a database. When a unique key is defined on one or more columns of a table, the database management system (DBMS) automatically checks and enforces the uniqueness of values in those columns. Any attempt to insert or update a row with a value that violates the unique key constraint will result in an error, preventing duplicate data from being stored in the table.
42. What is an entity-relationship model and how does it work?
An entity-relationship (ER) model is a conceptual data model used to represent the relationships between entities (or objects) in a database system. It is a graphical representation that helps in understanding and designing the structure and relationships of data in a database.
The main components of an ER model are:
-
Entities: Entities are objects or things that exist and have attributes (or properties) that describe them. In a database context, entities represent the real-world objects or concepts that we want to store and manage data about, such as customers, employees, products, or orders.
-
Relationships: Relationships represent the associations or connections between entities in the database. They define how entities are related to each other and can be one-to-one, one-to-many, or many-to-many relationships. Relationships are usually depicted as lines connecting entities in an ER diagram, with labels indicating the type of relationship, such as "is-a," "has," "owns," "works-for," etc.
-
Attributes: Attributes are the properties or characteristics of entities that describe them. Attributes represent the specific data or information we want to store about an entity, such as the name, age, address, or phone number of a customer.
ER models use graphical notations, such as ER diagrams, to visually represent the structure and relationships of entities and their attributes in a database. ER diagrams typically consist of boxes (representing entities) connected by lines (representing relationships) and labeled with the types of relationships. Attributes of entities are listed within the boxes, and additional notations, such as cardinality and participation constraints, may be used to further define the relationships between entities.
43. What is the difference between atomicity and aggregation?
Atomicity and aggregation are two different concepts in the context of databases and data management:
-
Atomicity: Atomicity refers to the property of a database transaction that ensures that either all of its operations are executed or none of them are, and that the database remains in a consistent state even in the presence of failures or errors. In other words, if a transaction consists of multiple operations or steps, either all of them are executed successfully and the transaction is committed, or none of them are executed and the transaction is rolled back, leaving the database in its original state. Atomicity ensures that a transaction is treated as a single, indivisible unit of work, and that the database remains in a consistent state even in case of failures or errors during the transaction.
-
Aggregation: Aggregation refers to the process of combining or summarizing data from multiple rows or records in a database into a single value or result. Aggregation is typically used to perform calculations, summarizations, or calculations on groups of data in a database, such as calculating the average, sum, or count of a particular field or attribute across multiple records. Aggregation functions, such as COUNT, SUM, AVG, MAX, MIN, etc., are commonly used in SQL and other database query languages to perform aggregation operations on data in a database.
44. What is the difference between triggers and stored procedures?
| Feature | Triggers | Stored Procedures |
|---|---|---|
| Purpose | Automatically executed in response to | Explicitly invoked by a user or application |
| specific events or actions in the database | ||
| Invocation | Automatically invoked by the database | Explicitly invoked by a user or application |
| system based on predefined events or | ||
| actions | ||
| Scope | Scoped to a specific table or view in the | Standalone objects |
| database | ||
| Transaction Control | Executed within the same transaction as | Changes need to be explicitly managed |
| the triggering operation | within the stored procedure code | |
| Reusability | Limited to the specific table or view to | Can be reused across multiple database |
| which they are attached | operations |
45. What does it mean to be in a deadlock?
In the context of computer science and database management, a deadlock refers to a difficult situation where two or more processes or transactions are waiting for each other to release resources, resulting in a circular dependency that prevents any of them from progressing, leading to a standstill or deadlock.
Deadlocks can occur in various computing systems, including databases, operating systems, distributed systems, and concurrent programming environments. They typically arise when processes or transactions are competing for shared resources, such as database locks, file locks, or other system resources, and are not properly managed or coordinated.
Deadlocks can cause the affected processes or transactions to hang indefinitely, leading to a system or application becoming unresponsive or stuck. Resolving deadlocks typically involves detecting the deadlock condition and then taking appropriate actions to break the deadlock, such as releasing resources, rolling back transactions, or applying deadlock avoidance or deadlock detection algorithms.
To prevent deadlocks, proper concurrency control mechanisms, such as locking protocols, can be implemented to manage shared resources effectively, ensuring that processes or transactions do not enter into a cyclic dependency that can lead to a deadlock. Careful design and implementation of systems and applications, including proper resource allocation and synchronization techniques, can help prevent deadlocks and ensure the smooth and efficient execution of concurrent processes or transactions.
46. What is meant by static SQL?
"Static SQL" refers to SQL (Structured Query Language) statements that are embedded directly in application programs or scripts, and are compiled or parsed by the application or database system during the compilation or execution of the program, rather than being generated dynamically at runtime.
In other words, static SQL refers to SQL statements that are hard-coded in the application code or script, and their text is known and fixed at compile-time or load-time, without changing during the runtime of the application. These SQL statements are typically written in the source code of an application or script and are compiled or parsed along with the rest of the application code.
Static SQL is often used in traditional database application development approaches, where SQL statements are embedded directly in the source code of the application program or script, and are typically written in the same programming language as the application itself (e.g., Java, C++, C#, etc.). The SQL statements are usually concatenated or embedded within the application code as strings, and are passed directly to the database system for execution during the runtime of the application.
47. What are indexes and their role in databases?
Indexes in databases are data structures that provide a quick and efficient way to look up and retrieve data based on specific columns or fields in a table. Indexes serve as a reference or a pointer to the actual data stored in a database table, allowing for faster retrieval of data when querying the database.
The main role of indexes in databases is to improve query performance by reducing the amount of data that needs to be scanned or searched when executing a query. Indexes can significantly speed up query execution times, especially for large tables or complex queries, by providing a way to quickly locate relevant data based on the indexed columns. Indexes can be created on one or more columns of a table, and they are typically implemented using various data structures such as B-trees, hash indexes, or bitmap indexes, depending on the database management system (DBMS) being used.
48. How is it that a database is not the same as a file processing system?
A database and a file processing system are not the same due to several key differences:
-
Data structure and organization: In a file processing system, data is typically stored in individual files that are managed separately by different applications. Each file may have its own format, structure, and organization, and there may be redundancy and inconsistency in data storage. On the other hand, in a database, data is organized into tables with predefined schemas, where each table contains rows (records) and columns (fields) that define the structure and relationships of the data in a systematic and organized manner.
-
Data integration and consistency: In a file processing system, data integration and consistency may be challenging, as data may be duplicated or inconsistent across multiple files or applications. In contrast, a database system provides mechanisms for data integration and consistency, such as data normalization, referential integrity, and transaction management, which help maintain the consistency, accuracy, and integrity of the data across the database.
-
Data sharing and concurrency: In a file processing system, sharing and concurrent access to data by multiple users or applications may be complex and prone to conflicts, as files may be locked or accessed in an ad-hoc manner. In a database system, concurrent access to data is typically managed through database management systems (DBMS) that provide mechanisms such as locking, transactions, and isolation levels to ensure that multiple users can access and modify data concurrently without conflicts.
-
Scalability and performance: Database systems are designed to handle large amounts of data and concurrent users efficiently and provide performance optimizations, such as indexing, caching, and query optimization, to improve query execution times. In contrast, file processing systems may lack such optimizations and may not be as scalable or performant when dealing with large or complex datasets.
-
Data integrity and security: Database systems provide built-in mechanisms for ensuring data integrity, such as data validation, referential integrity, and access controls, to protect data from unauthorized access, modification, or corruption. File processing systems may lack these built-in mechanisms, making data integrity and security more challenging to manage.
49. What is the function of the DROP command?
The DROP command is used in computer programming and database management to remove or delete a database object, such as a table, view, index, or schema, from a database system. The DROP command is typically used to permanently delete database objects that are no longer needed or that need to be removed from the database system for various reasons, such as to free up storage space, clean up unnecessary data, or perform maintenance tasks.
In the context of SQL (Structured Query Language), which is a widely used language for managing relational databases, the DROP command is used to delete database objects. For example, the syntax for dropping a table in SQL would typically be:
DROP TABLE table_name;
This command would delete the specified table and permanently remove all data and metadata associated with it from the database.
50. What does the integrity of data refer to?
The integrity of data refers to its accuracy, reliability, consistency, and completeness throughout its lifecycle, ensuring that it remains unchanged and reliable. Data integrity is a critical aspect of data management and information security, as it ensures that data remains reliable, consistent, and accurate, and is not compromised by unauthorized modifications, deletions, or corruptions. Data integrity is typically maintained through various means such as data validation, data verification, and data backup and recovery mechanisms, as well as through access controls and data encryption techniques. Ensuring data integrity is essential for maintaining the trustworthiness and usability of data for decision-making, analysis, and other business or operational purposes.
Additional questions for JP Morgan interview
Here are some additional questions that you must prepare while going for a JP Morgan interview:
- How can the level of a node be determined when all you have is a binary tree?
- Count the number of inversions that occur in a sorted array.
- Create a function that utilizes iteration and recursion to flip the items in a linked list.
- To create a stack using a queue, what steps would you need to follow?
- Write a program that, when given an array of size N, prints the array in the opposite direction.
- Create a program that will turn a single linked list upside down.
- Create a function that determines the height of a binary tree and use it.
- If you are given a graph with V vertices and E edges, you need to figure out whether or not the graph has a cycle.
- What characteristics does a good financial model have, in your opinion?
- What kind of activity can now be seen in the markets?
- What does it mean to program in the C language?
JP Morgan interview questions: HR round
Here are some of the most important HR questions that you can prepare for while getting ready for your JP Morgan interview:
- How would you deal with a disappointed company client?
- Have you ever worked for a financial services company?
- Are you a determined person? If yes, explain how.
- Can you give an example proving that you are an ambitious person?
- Can you manage the data of billions of people?
- How will you deal with a difficult person in your team?
- Are you able to ensure adaptability in times when needed?
- Can you deliver projects to the banker on time?
- Can you take us through your decision-making process?
- What is your ambition in life?
- Tell us something about your college life.
JP Morgan recruitment process
The selection procedure that the organization uses is rigorous and objective since it is developed with the belief that the best approach to identifying the appropriate people is to do it openly and honestly. The recruitment process at JP Morgan might be quite competitive, yet the company nevertheless takes the proper amount of time for each candidate as per their business principles. As it is among the biggest companies, getting hired is not that easy for candidates.
If you are fortunate enough to be given a position with JP Morgan, the application process could be lengthy; nonetheless, it will be well worth your effort. It is possible to have a long and successful career if you choose to work for this fantastic organization with a great code of conduct. JP Morgan is a wonderful organization that provides its employees with numerous prospects for advancement and the perks they receive are exceptional. You can also consider following the STAR interview method for preparation.
Be careful to prepare adequately for the interview and give special attention to distinguishing your CV from other applicants. The interviewing process will normally consist of numerous rounds, but the exact number of rounds and their order may vary from program to program. They use a variety of interviewing methods, including in-person, over the phone, and online video chat, to test a candidate's knowledge of the industry.
These are the rounds that you may need to face for career interviews at JP Morgan:
- Job application
- Discussion rounds with JP Morgan experts
- Technical interview to assess your technical fundamentals
- HR round with behavioral questions
About JP Morgan
As a result of the merger that took place between JP Morgan and Chase Manhattan Bank in December of 2000, this financial institution quickly rose to become one of the most successful in the United States. With a total asset value of $2.5 trillion, JPMorgan Chase & Co. occupies the sixth spot on the list of the world's top banks based on assets, making it the sixth-largest bank in the world overall. It is also the biggest bank by market capitalization across the globe.
Suggested Reads:
Login to continue reading
And access exclusive content, personalized recommendations, and career-boosting opportunities.
Don't have an account? Sign up
Never miss an
Update

Featured Opportunities
Top-Rated Practice by Students





Subscribe
to our newsletter
Blogs you need to hog!

How To Write Finance Cover Letter For Morgan Stanley (+Free Sample!)
Unstop

55+ Data Structure Interview Questions For 2026 (Detailed Answers)
Muskaan Mishra

How To Negotiate Salary With HR: Tips And Insider Advice
Srishti Magan

80+ TCS NQT Interview Questions & Answers (2026) You Must Prepare
Urvashi Singhal
Comments
Add comment