
Asian Paints Alchemy 2026
Company Interview Questions for Freshers
- TCS Technical Interview Questions & Answers
- TCS Managerial Interview Questions & Answers
- TCS HR Interview Questions & Answers
- Overview of Cognizant Recruitment Process
- Cognizant Interview Questions: Technical
- Cognizant Interview Questions: HR Round
- Overview of Wipro Technologies Recruitment Rounds
- Wipro Interview Questions
- Technical Round
- HR Round
- Online Assessment Sample Questions
- Frequently Asked Questions
- Overview of Google Recruitment Process
- Google Interview Questions: Technical
- Google Interview Questions: HR round
- Interview Preparation Tips
- About Google
- Deloitte Technical Interview Questions
- Deloitte HR Interview Questions
- Deloitte Recruitment Process
- Technical Interview Questions and Answers
- Level 1 difficulty
- Level 2 difficulty
- Level 3 difficulty
- Behavioral Questions
- Eligibility Criteria for Mindtree Recruitment
- Mindtree Recruitment Process: Rounds Overview
- Skills required to crack Mindtree interview rounds
- Mindtree Recruitment Rounds: Sample Questions
- About Mindtree
- Preparing for Microsoft interview questions
- Microsoft technical interview questions
- Microsoft behavioural interview questions
- Aptitude Interview Questions
- Technical Interview Questions
- Easy
- Intermediate
- Hard
- HR Interview Questions
- Eligibility criteria
- Recruitment rounds & assessments
- Tech Mahindra interview questions - Technical round
- Tech Mahindra interview questions - HR round
- Hiring process at Mphasis
- Mphasis technical interview questions
- Mphasis HR interview questions
- About Mphasis
- Technical interview questions
- HR interview questions
- Recruitment process
- About Virtusa
- Goldman Sachs Interview Process
- Technical Questions for Goldman Sachs Interview
- Sample HR Question for Goldman Sachs Interview
- About Goldman Sachs
- Nagarro Recruitment Process
- Nagarro HR Interview Questions
- Nagarro Aptitude Test Questions
- Nagarro Technical Test Questions
- About Nagarro
- PwC Recruitment Process
- PwC Technical Interview Questions: Freshers and Experienced
- PwC Interview Questions for HR Rounds
- PwC Interview Preparation
- Frequently Asked Questions
- EY Technical Interview Questions (2023)
- EY Interview Questions for HR Round
- About EY
- Morgan Stanley Recruitment Process
- HR Questions for Morgan Stanley Interview
- HR Questions for Morgan Stanley Interview
- About Morgan Stanley
- Recruitment Process at Flipkart
- Technical Flipkart Interview Questions
- Code-Based Flipkart Interview Questions
- Sample Flipkart Interview Questions- HR Round
- Conclusion
- FAQs
- Recruitment Process at Paytm
- Technical Interview Questions for Paytm Interview
- HR Sample Questions for Paytm Interview
- About Paytm
- Most Probable Accenture Interview Questions
- Accenture Technical Interview Questions
- Accenture HR Interview Questions
- Amazon Recruitment Process
- Amazon Interview Rounds
- Common Amazon Interview Questions
- Amazon Interview Questions: Behavioral-based Questions
- Amazon Interview Questions: Leadership Principles
- Company-specific Amazon Interview Questions
- 43 Top Technical/ Coding Amazon Interview Questions
- Juspay Recruitment: Stages and Timeline
- Juspay Interview Questions and Answers
- How to prepare for Juspay interview questions
- Prepare for the Juspay Interview: Stages and Timeline
- Frequently Asked Questions
- Adobe Interview Questions - Technical
- Adobe Interview Questions - HR
- Recruitment Process at Adobe
- About Adobe
- Cisco technical interview questions
- Sample HR interview questions
- The recruitment process at Cisco
- About Cisco
- JP Morgan interview questions (Technical round)
- JP Morgan interview questions HR round)
- Recruitment process at JP Morgan
- About JP Morgan
- Wipro Elite NTH: Selection Process
- Wipro Elite NTH Technical Interview Questions
- Wipro Elite NTH Interview Round- HR Questions
- BYJU's BDA Interview Questions
- BYJU's SDE Interview Questions
- BYJU's HR Round Interview Questions
- A Quick Overview of the KPMG Recruitment Process
- Technical Questions for KPMG Interview
- HR Questions for KPMG Interview
- About KPMG
- DXC Technology Interview Process
- DCX Technical Interview Questions
- Sample HR Questions for DXC Technology
- About DXC Technology
- Recruitment Process at PayPal
- Technical Questions for PayPal Interview
- HR Sample Questions for PayPal Interview
- About PayPal
- Capgemini Recruitment Rounds
- Capgemini Interview Questions: Technical round
- Capgemini Interview Questions: HR round
- Preparation tips
- FAQs
- Technical interview questions for Siemens
- Sample HR questions for Siemens
- The recruitment process at Siemens
- About Siemens
- HCL Technical Interview Questions
- HR Interview Questions
- HCL Technologies Recruitment Process
- List of EPAM Interview Questions for Technical Interviews
- About EPAM
- Atlassian Interview Process
- Top Skills for Different Roles at Atlassian
- Atlassian Interview Questions: Technical Knowledge
- Atlassian Interview Questions: Behavioral Skills
- Atlassian Interview Questions: Tips for Effective Preparation
- Walmart Recruitment Process
- Walmart Interview Questions and Sample Answers (HR Round)
- Walmart Interview Questions and Sample Answers (Technical Round)
- Tips for Interviewing at Walmart and Interview Preparation Tips
- Frequently Asked Questions
- Uber Interview Questions For Engineering Profiles: Coding
- Technical Uber Interview Questions: Theoretical
- Uber Interview Question: HR Round
- Uber Recruitment Procedure
- About Uber Technologies Ltd.
- Intel Technical Interview Questions
- Computer Architecture Intel Interview Questions
- Intel DFT Interview Questions
- Intel Interview Questions for Verification Engineer Role
- Recruitment Process Overview
- Important Accenture HR Interview Questions
- Points to remember
- What is Selenium?
- What are the components of the Selenium suite?
- Why is it important to use Selenium?
- What's the major difference between Selenium 3.0 & Selenium 2.0?
- What is Automation testing and what are its benefits?
- What are the benefits of Selenium as an Automation Tool?
- What are the drawbacks to using Selenium for testing?
- Why should Selenium not be used as a web application or system testing tool?
- Is it possible to use selenium to launch web browsers?
- What does Selenese mean?
- What does it mean to be a locator?
- Identify the main difference between "assert", and "verify" commands within Selenium
- What does an exception test in Selenium mean?
- What does XPath mean in Selenium? Describe XPath Absolute & XPath Relation
- What is the difference in Xpath between "//"? and "/"?
- What is the difference between "type" and the "typeAndWait" commands within Selenium?
- Distinguish between findElement() & findElements() in context of Selenium
- How long will Selenium wait before a website is loaded fully?
- What is the difference between the driver.close() and driver.quit() commands in Selenium?
- Describe the different navigation commands that Selenium supports
- What is Selenium's approach to the same-origin policy?
- Explain the difference between findElement() in Selenium and findElements()
- Explain the pause function in SeleniumIDE
- Explain the differences between different frameworks and how they are connected to Selenium's Robot Framework
- What are your thoughts on the Page Object Model within the context of Selenium
- What are your thoughts on Jenkins?
- What are the parameters that selenium commands come with a minimum?
- How can you tell the differences in the Absolute pathway as well as Relative Path?
- What's the distinction in Assert or Verify declarations within Selenium?
- What are the points of verification that are in Selenium?
- Define Implicit wait, Explicit wait, and Fluent
- Can Selenium manage windows-based pop-ups?
- What's the definition of an Object Repository?
- What is the main difference between obtainwindowhandle() as well as the getwindowhandles ()?
- What are the various types of Annotations that are used in Selenium?
- What is the main difference in the setsSpeed() or sleep() methods?
- What is the way to retrieve the alert message?
- How do you determine the exact location of an element on the web?
- Why do we use Selenium RC?
- What are the benefits or advantages of Selenium RC?
- Do you have a list of the technical limitations when making use of Selenium RC? Selenium RC?
- What's the reason to utilize the TestNG together with Selenium?
- What Language do you prefer to use to build test case sets in Selenium?
- What are Start and Breakpoints?
- What is the purpose of this capability relevant in relation to Selenium?
- When do you use AutoIT?
- Do you have a reason why you require Session management in Selenium?
- Are you able to automatize CAPTCHA?
- How can we launch various browsers on Selenium?
- Why should you select Selenium rather than QTP (Quick Test Professional)?
- Airbus Interview Questions and Answers: HR/ Behavioral
- Industry/ Company-Specific Airbus Interview Questions
- Airbus Interview Questions and Answers: Aptitude
- Airbus Software Engineer Interview Questions and Answers: Technical
- Importance of Spring Framework
- Spring Interview Questions (Basic)
- Advanced Spring Interview Questions
- C++ Interview Questions and Answers: The Basics
- C++ Interview Questions: Intermediate
- C++ Interview Questions And Answers With Code Examples
- C++ Interview Questions and Answers: Advanced
- Test Your Skills: Quiz Time
- MBA Interview Questions: B.Com Economics
- B.Com Marketing
- B.Com Finance
- B.Com Accounting and Finance
- Business Studies
- Chartered Accountant
- Q1. Please tell us something about yourself/ Introduce yourself to us.
- Q2. Describe yourself in one word.
- Q3. Tell us about your strengths and weaknesses.
- Q4. Why did you apply for this job/ What attracted you to this role?
- Q5. What are your hobbies?
- Q6. Where do you see yourself in five years OR What are your long-term goals?
- Q7. Why do you want to work with this company?
- Q8. Tell us what you know about our organization
- Q9. Do you have any idea about our biggest competitors?
- Q10. What motivates you to do a good job?
- Q11. What is an ideal job for you?
- Q12. What is the difference between a group and a team?
- Q13. Are you a team player/ Do you like to work in teams?
- Q14. Are you good at handling pressure/ deadlines?
- Q15. When can you start?
- Q16. How flexible are you regarding overtime?
- Q17. Are you willing to relocate for work?
- Q18. Why do you think you are the right candidate for this job?
- Q19. How can you be an asset to the organization?
- Q20. What is your salary expectation?
- Q21. How long do you plan to remain with this company?
- Q22. What is your objective in life?
- Q23. Would you like to pursue your Master's degree anytime soon?
- Q24. How have you planned to achieve your career goal?
- Q25. Can you tell us about your biggest achievement in life?
- Q26. What was the most challenging decision you ever made?
- Q27. What kind of work environment do you prefer to work in?
- Q28. What is the difference between a smart worker and a hard worker?
- Q29. What will you do if you don't get hired?
- Q30. Tell us three things that are most important for you in a job.
- Q31. Who is your role model and what have you learned from him/her?
- Q32. In case of a disagreement, how do you handle the situation?
- Q33. What is the difference between confidence and overconfidence?
- Q34. If you have more than enough money in hand right now, would you still want to work?
- Q35. Do you have any questions for us?
- Interview Tips for Freshers
- Tell me about yourself
- What are your greatest strengths?
- What are your greatest weaknesses?
- Tell me about something you did that you now feel a little ashamed of
- Why are you leaving (or did you leave) this position??
- 15+ resources for preparing most-asked interview questions
- CoCubes Interview Process Overview
- Common CoCubes Interview Questions
- Key Areas to Focus on for CoCubes Interview Preparation
- Conclusion
- Frequently Asked Questions (FAQs)
- Data Analyst Interview Questions With Answers
- About Data Analyst
Top Intel Interview Questions - Technical | DFT | Computer Architecture

Intel is one of the biggest tech companies in the semiconductor industry and attracts top talent from all over the world. The company's hiring process is rigorous and includes several rounds of interviews, including a wide range of technical and behavioral interview questions. If you are preparing for Intel India interview questions, it is essential to know what to expect from the hiring manager and how to prepare for behavioral-based and technical interviews. Here are some tips that will help you ace your interview:
-
Research the company: Before the interview, make sure you have basic knowledge and a good understanding of Intel, its products, the company mission statement, and the company culture. You can know more about it on the company blog website.
-
Review your resume: Be prepared to discuss your experience, skills, career goals, and achievements listed on your resume. Make sure you can articulate your qualifications, analytical programming skills, and experience clearly and concisely during the personal interview.
-
Prepare for technical questions: Be ready to answer technical questions related to the position you are interviewing for. This may include topics such as digital design, verification, software engineering, or manufacturing. Showcase your coding skills, analytical skills, and other additional skills throughout the interview process.
-
Practice your communication skills: Intel values effective communication and soft skills, so practice your ability to explain technical concepts clearly and give concise answers to behavioral questions. Use specific examples from your previous work experience to demonstrate your expertise.
-
Be prepared to collaborate: Intel fosters a collaborative work environment, so be prepared to discuss your experience working with teams, your core skills, and your ability to work as a team player or team leader along with others.
-
Demonstrate your interest in the company: Show your enthusiasm for the position of software engineer at the company by asking thoughtful questions about Intel, the current team you will be working with, and the products you will be working on.
Also Read: Intel Recruitment Process: Eligibility, Stages, & Salary
Intel Technical Interview Questions
Q1. What is a semaphore? Explain in detail.
A semaphore is a synchronization tool used in operating systems to coordinate access to shared resources. It is a software-based data structure that can be used by multiple processes or threads to control access to a shared resource, such as a file or a section of memory.
Semaphores were first introduced by Edsger Dijkstra in 1962 and have since become an essential part of operating systems and concurrent programming. A semaphore consists of a non-negative integer value and two atomic operations: wait and signal. The wait operation decrements the value of the semaphore by one, while the signal operation increments it by one. A semaphore can be initialized to any non-negative integer value.
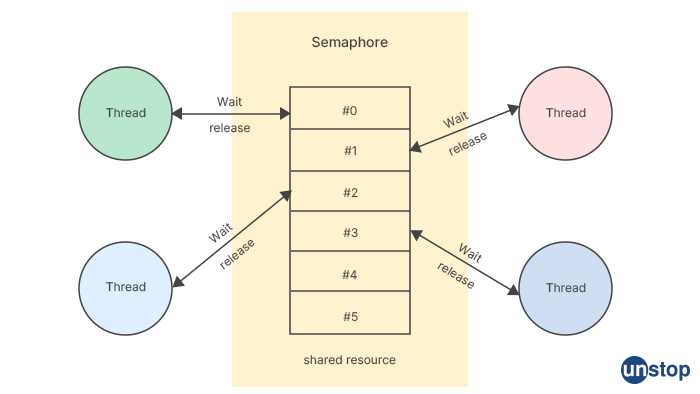
When a process or thread wants to access a shared resource, it first tries to decrement the value of the semaphore using the wait operation. If the semaphore value is positive, the process or thread can access the company resource, and the semaphore value is decremented. If the semaphore value is zero or negative, the process or thread is blocked, and it waits until the semaphore value becomes positive. When the process or thread releases the shared resource, it uses the signal operation to increase the value of the semaphore. If there are any blocked processes or threads waiting for the semaphore, one of them will be unblocked, and it can access the shared resource.
Semaphores can be implemented using various algorithms, such as binary semaphores, counting semaphores, and mutex semaphores. Binary semaphores can have only two values, 0 and 1, and are used for mutual exclusion, where only one process or thread can access the shared resource at a time. Counting semaphores can have any non-negative integer value and are used for resource allocation, where multiple processes or threads can access the resource simultaneously up to a certain limit. Mutex semaphores are similar to binary semaphores but are more flexible and can be used for more complex synchronization scenarios.
Q2. What is the exact role of the Memory Management Unit?
A Memory Management Unit (MMU) is a hardware component that is responsible for managing and organizing the memory hierarchy in a computer system. It provides virtual memory mapping, protection, and translation services between the physical memory and the virtual address space of a program.
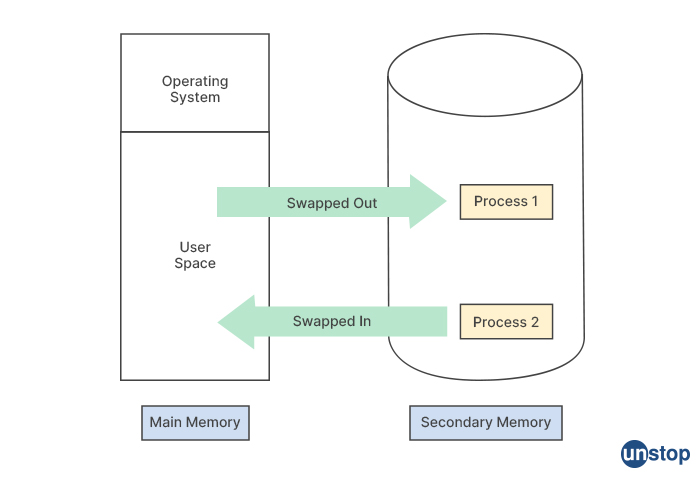
The primary role of the MMU is to ensure that each process has access to its own virtual address space, which is isolated from other processes. This is achieved by translating virtual addresses used by the process into physical addresses that correspond to locations in the physical memory. The MMU maintains a page table that maps each virtual address to its corresponding physical address.
Additionally, the MMU enforces memory protection by controlling access to different areas of memory. It ensures that each process can only access the memory locations that it is authorized to access, preventing one process from interfering with another process's data or code. The MMU also supports virtual memory, which enables the system to use more memory than is physically available by temporarily transferring data from the physical memory to the hard disk or other storage devices. This allows multiple processes to run simultaneously without running out of memory.
Q3. Swap two numbers using XOR.
Yes, you can swap two numbers using XOR bitwise operator. The basic idea is to use the properties of XOR that it returns 1 if and only if the bits being compared are different.
Here is an example code to swap two numbers using XOR:
#include
#include
#include
#include
int main()
{
/* Enter your code here. Read input from STDIN. Print output to STDOUT */
return 0;
}
I2luY2x1ZGUgPHN0ZGlvLmg+IAojaW5jbHVkZSA8c3RyaW5nLmg+IAojaW5jbHVkZSA8bWF0aC5oPiAKI2luY2x1ZGUgPHN0ZGxpYi5oPiAKaW50IG1haW4oKSAKewovKiBFbnRlciB5b3VyIGNvZGUgaGVyZS4gUmVhZCBpbnB1dCBmcm9tIFNURElOLiBQcmludCBvdXRwdXQgdG8gU1RET1VUICovCiAgICAKcmV0dXJuIDA7Cn0K
In the above code, we first declare two integers a and b with values 10 and 20, respectively. We then print the initial values of a and b. To swap the values of a and b using XOR, we first assign the XOR of a and b to a. Then we assign the XOR of the new a and the original b to b. Finally, we assign the XOR of the new a and the new b to a. After the swapping is done, we print the new values of a and b to verify that the swap was successful.
Q4. What are various storage classifiers and quantifiers in C?
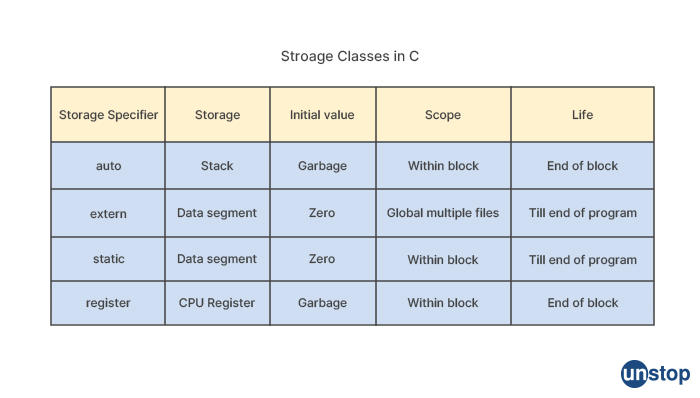
In C programming language, the storage class specifiers determine the scope and lifetime of a variable or a function. There are four storage class specifiers in C:
-
Auto: Variables declared inside a block (such as a function) are by default auto variables. Auto variables are stored in the stack memory and are created when the block is entered and destroyed when the block is exited.
-
Static: The static storage class is used to declare variables that are persistent throughout the execution of the program. Static variables are stored in the data segment of the memory and retain their value between function calls. If a variable is declared static inside a function, it retains its value across function calls.
-
Extern: The extern storage class is used to declare variables or functions that are defined in a separate file. Extern variables are not allocated memory when they are declared, but they are used to access variables or functions that are defined in a different file.
-
Register: The register storage class is used to request that a variable be stored in a CPU register instead of memory. This can improve performance by reducing memory access time. However, the use of the register specifier is merely a hint to the compiler and does not guarantee that the variable will be stored in a register.
Q5. Write the most efficient algorithm to find if a number is prime or not.
The most efficient algorithm to determine whether a number is prime or not is the Sieve of Eratosthenes. The algorithm works by generating a list of all prime numbers up to a given limit and then checking if the input number is divisible by any of the primes in the list. Here is how the algorithm works:
- Generate a list of all integers from 2 to the input number.
- Mark all the multiples of 2 as composite.
- For each prime number p from 3 up to the square root of the input number, mark all multiples of p as composite.
- The remaining unmarked numbers are prime.
Here is a sample implementation of the Sieve of Eratosthenes in C:
#include
#include
#include
bool is_prime(int n) {
if (n <= 1) {
return false;
}
int i;
int limit = sqrt(n);
for (i = 2; i <= limit; i++) {
if (n % i == 0) {
return false;
}
}
return true;
}
int main() {
int n;
printf("Enter a number: ");
scanf("%d", &n);
if (is_prime(n)) {
printf("%d is a prime number.\n", n);
} else {
printf("%d is not a prime number.\n", n);
}
return 0;
}
I2luY2x1ZGUgPHN0ZGlvLmg+CiNpbmNsdWRlIDxzdGRib29sLmg+CiNpbmNsdWRlIDxtYXRoLmg+Cgpib29sIGlzX3ByaW1lKGludCBuKSB7CmlmIChuIDw9IDEpIHsKcmV0dXJuIGZhbHNlOwp9CgppbnQgaTsKaW50IGxpbWl0ID0gc3FydChuKTsKCmZvciAoaSA9IDI7IGkgPD0gbGltaXQ7IGkrKykgewppZiAobiAlIGkgPT0gMCkgewpyZXR1cm4gZmFsc2U7Cn0KfQoKcmV0dXJuIHRydWU7Cn0KCmludCBtYWluKCkgewppbnQgbjsKCnByaW50ZigiRW50ZXIgYSBudW1iZXI6ICIpOwpzY2FuZigiJWQiLCAmbik7CgppZiAoaXNfcHJpbWUobikpIHsKcHJpbnRmKCIlZCBpcyBhIHByaW1lIG51bWJlci5cbiIsIG4pOwp9IGVsc2UgewpwcmludGYoIiVkIGlzIG5vdCBhIHByaW1lIG51bWJlci5cbiIsIG4pOwp9CgpyZXR1cm4gMDsKfQ==
In this implementation, the is_prime function checks whether the input number n is prime or not by checking if it is divisible by any integer from 2 to the square root of n. If it is, the function returns false. If no integer from 2 to the square root of n evenly divides n, the function returns true, indicating that n is prime.
Q6. What is call by value, call by reference in C language?
In C language, there are two ways to pass arguments to a function: call by value and call by reference.
1. Call by value: In call by value, a copy of the argument is passed to the function. The function works on the copy of the argument and any changes made to the argument inside the function do not affect the original variable that was passed in. The original variable remains unchanged. Here is an example:
void change(int a) {
a = 10;
}
int main() {
int x = 5;
change(x);
printf("%d", x); // Output: 5
return 0;
}
dm9pZCBjaGFuZ2UoaW50IGEpIHsKYSA9IDEwOwp9CgppbnQgbWFpbigpIHsKaW50IHggPSA1OwpjaGFuZ2UoeCk7CnByaW50ZigiJWQiLCB4KTsgLy8gT3V0cHV0OiA1CnJldHVybiAwOwp9
2. Call by reference: In call by reference, a reference to the argument is passed to the function, and any changes made to the argument inside the function affect the original variable that was passed in. Here is an example:
void change(int *a) {
*a = 10;
}
int main() {
int x = 5;
change(&x);
printf("%d", x); // Output: 10
return 0;
}
dm9pZCBjaGFuZ2UoaW50ICphKSB7CiphID0gMTA7Cn0KCmludCBtYWluKCkgewppbnQgeCA9IDU7CmNoYW5nZSgmeCk7CnByaW50ZigiJWQiLCB4KTsgLy8gT3V0cHV0OiAxMApyZXR1cm4gMDsKfQ==
Q7. What is an interrupt? How does a processor handle an interrupt?
An interrupt is a signal sent by a device or additional software to the processor indicating that an event has occurred that needs immediate attention. The processor interrupts its current task, saves the state of the interrupted task, and starts executing a special routine called an interrupt handler to handle the interrupt. The interrupt handler performs the necessary actions to respond to the interrupt, such as reading data from a device, writing data to a device, or processing an error condition.
Here is a brief overview of how a processor handles an interrupt:
- The processor is executing a program.
- An interrupt signal is sent to the processor by a device or graphics software.
- The processor acknowledges the interrupt signal and saves the state of the interrupted program onto the stack, including the value of the program counter (PC) and other registers that are used by the program.
- The processor sets the PC to the address of the interrupt handler routine.
- The interrupt handler routine executes, performs the necessary actions to respond to the interrupt, and then returns control to the interrupted program.
- The processor restores the saved state of the interrupted program from the stack, including the value of the PC and other registers, and resumes the execution of the interrupted program from where it left off in the graphics software.
The interrupt handling mechanism allows the processor to respond to external events and perform multiple tasks simultaneously. Without interrupts, the processor would have to continuously poll the devices to check for events, which would waste a lot of processing time and reduce the overall system performance. By using interrupts, the processor can handle events as they occur, allowing for a more efficient and responsive system.
Q8. At Bit-level, how will you find if a number is a power of 2 or not?
At the bit level, a number that is a power of 2 has only one bit set to 1, and all other bits are 0. Therefore, to check if a number is a power of 2 or not, we can use bitwise operations.
Here is one way to check if a number is a power of 2 or not:
bool isPowerOfTwo(int n) {
if (n <= 0) {
return false;
}
return (n & (n - 1)) == 0;
}
Ym9vbCBpc1Bvd2VyT2ZUd28oaW50IG4pIHsKaWYgKG4gPD0gMCkgewpyZXR1cm4gZmFsc2U7Cn0KcmV0dXJuIChuICYgKG4gLSAxKSkgPT0gMDsKfQ==
In the above code, we first check if the number n is less than or equal to 0, in which case it cannot be a power of 2. Then, we perform a bitwise AND operation between n and n-1. If the result of the bitwise AND operation is 0, it means that n has only one bit set to 1, and all other bits are 0, which is the characteristic of a power of 2. If the result of the bitwise AND operation is not 0, it means that n has more than one bit set to 1, and therefore it is not a power of 2.
Q9. What is Buffer overflow?
Buffer overflow is a type of software vulnerability that occurs when a program attempts to write data to a buffer that is too small to hold the data. A buffer is a temporary storage area in computer memory that is used to hold data while it is being processed. If the program writes more data to the buffer than it can hold, the excess data overflows into adjacent memory locations, corrupting the data stored there.
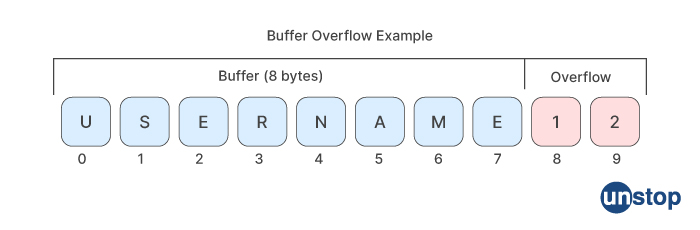
Buffer overflow can lead to serious security issues as an attacker can exploit it to execute arbitrary code or gain unauthorized access to the system. An attacker can use a buffer overflow to overwrite the memory contents with malicious code and then trick the program into executing the code. Buffer overflow vulnerabilities can occur in any program that reads input from an untrusted source and does not properly validate the input or check the size of the input buffer. Examples of such programs include web servers, network services, and command-line utilities.
To prevent buffer overflow vulnerabilities, it is important to use secure computations skills and coding concepts, such as input validation, bounds checking, and using safe programming functions that automatically check for buffer overflow. Additionally, the applicable skills and modern programming languages provide features such as automatic memory management and bounds checking, which can help prevent buffer overflow vulnerabilities.
Q10. What is Round Robin Scheduling?
Round Robin Scheduling is a CPU scheduling algorithm that is widely used in computer systems. It is a preemptive scheduling algorithm that is based on the concept of time slicing, which means that each process is allocated a fixed time slice or quantum, and the CPU switches from one process to another at regular intervals, usually every few milliseconds.
In Round Robin Scheduling, all processes are placed in a circular queue, and the CPU executes each process for a fixed time slice. When the time slice expires, the CPU saves the state of the currently running process, and the next process in the queue is selected to run. The selected process is then executed for the next time slice, and the process queue is rotated accordingly. If a process completes its execution before the time slice expires, it is removed from the queue, and the next process in the queue is selected to run.
Round Robin Scheduling is a simple and fair scheduling algorithm that provides bonus opportunities to all processes to execute on the CPU. It also ensures that no process is given preference over others, which makes it useful in time-sharing systems where multiple users are using the same system simultaneously. Additionally, Round Robin Scheduling is effective in preventing starvation, as no process is indefinitely blocked from accessing the CPU.
Q11. Reverse a link list using the iterative method as well as the recursive method.
Sure, here are two ways to reverse a basic list, one using an iterative approach and the other using a recursive approach.
The iterative approach to reverse a linked list:
struct Node* reverseList(struct Node* head)
{
struct Node* prev = NULL;
struct Node* curr = head;
struct Node* next = NULL;
while (curr != NULL) {
next = curr->next; // Store next pointer
curr->next = prev; // Reverse the link
prev = curr; // Move prev to current node
curr = next; // Move current to next node
}
head = prev; // Update the head of the list to the new first node
return head; // Return the head of the reversed list
}
c3RydWN0IE5vZGUqIHJldmVyc2VMaXN0KHN0cnVjdCBOb2RlKiBoZWFkKSB7CnN0cnVjdCBOb2RlKiBwcmV2ID0gTlVMTDsKc3RydWN0IE5vZGUqIGN1cnIgPSBoZWFkOwpzdHJ1Y3QgTm9kZSogbmV4dCA9IE5VTEw7CndoaWxlIChjdXJyICE9IE5VTEwpIHsKbmV4dCA9IGN1cnItPm5leHQ7IC8vIFN0b3JlIG5leHQgcG9pbnRlcgpjdXJyLT5uZXh0ID0gcHJldjsgLy8gUmV2ZXJzZSB0aGUgbGluawpwcmV2ID0gY3VycjsgLy8gTW92ZSBwcmV2IHRvIGN1cnJlbnQgbm9kZQpjdXJyID0gbmV4dDsgLy8gTW92ZSBjdXJyZW50IHRvIG5leHQgbm9kZQp9CmhlYWQgPSBwcmV2OyAvLyBVcGRhdGUgdGhlIGhlYWQgb2YgdGhlIGxpc3QgdG8gdGhlIG5ldyBmaXJzdCBub2RlCnJldHVybiBoZWFkOyAvLyBSZXR1cm4gdGhlIGhlYWQgb2YgdGhlIHJldmVyc2VkIGxpc3QKfQ==
A recursive approach to reverse a linked list:
struct Node* reverseList(struct Node* head)
{
if (head == NULL || head->next == NULL) { // Base case
return head;
}
struct Node* rest = reverseList(head->next); // Recursive call
head->next->next = head; // Reverse the link
head->next = NULL; // Set the next pointer of the last node to NULL
return rest; // Return the new head of the reversed list
}
c3RydWN0IE5vZGUqIHJldmVyc2VMaXN0KHN0cnVjdCBOb2RlKiBoZWFkKSB7CmlmIChoZWFkID09IE5VTEwgfHwgaGVhZC0+bmV4dCA9PSBOVUxMKSB7IC8vIEJhc2UgY2FzZQpyZXR1cm4gaGVhZDsKfQpzdHJ1Y3QgTm9kZSogcmVzdCA9IHJldmVyc2VMaXN0KGhlYWQtPm5leHQpOyAvLyBSZWN1cnNpdmUgY2FsbApoZWFkLT5uZXh0LT5uZXh0ID0gaGVhZDsgLy8gUmV2ZXJzZSB0aGUgbGluawpoZWFkLT5uZXh0ID0gTlVMTDsgLy8gU2V0IHRoZSBuZXh0IHBvaW50ZXIgb2YgdGhlIGxhc3Qgbm9kZSB0byBOVUxMCnJldHVybiByZXN0OyAvLyBSZXR1cm4gdGhlIG5ldyBoZWFkIG9mIHRoZSByZXZlcnNlZCBsaXN0Cn0=
Both of these functions take a pointer to the head of a linked list as input and return a pointer to the head of the reversed list. The iterative approach uses a loop to traverse the list, reversing the links as it goes. The recursive approach uses a base case to stop the recursion and then reverses the links as it unwinds the call stack.
Q12. Given a sequence, return its next lexicographically greater permutation. If such a permutation does not exist, then return it in ascending order.
To find the next lexicographically greater permutation of a given sequence, we can follow the following algorithm:
- Find the largest index i such that a[i] < a[i+1]. If no such index exists, the sequence is already in descending order, so we just reverse it and return the result.
- Find the largest index j greater than i such that a[i] < a[j].
- Swap a[i] with a[j].
- Reverse the sequence from index i+1 to the end of the sequence.
Here's an implementation of the algorithm in Python:
def next_permutation(sequence):
i = len(sequence) - 2
while i >= 0 and sequence[i] >= sequence[i+1]:
i -= 1
if i < 0:
return sequence[::-1]
j = len(sequence) - 1
while sequence[j] <= sequence[i]:
j -= 1
sequence[i], sequence[j] = sequence[j], sequence[i]
sequence[i+1:] = reversed(sequence[i+1:])
return sequence
ZGVmIG5leHRfcGVybXV0YXRpb24oc2VxdWVuY2UpOgppID0gbGVuKHNlcXVlbmNlKSAtIDIKd2hpbGUgaSA+PSAwIGFuZCBzZXF1ZW5jZVtpXSA+PSBzZXF1ZW5jZVtpKzFdOgppIC09IDEKaWYgaSA8IDA6CnJldHVybiBzZXF1ZW5jZVs6Oi0xXQpqID0gbGVuKHNlcXVlbmNlKSAtIDEKd2hpbGUgc2VxdWVuY2Vbal0gPD0gc2VxdWVuY2VbaV06CmogLT0gMQpzZXF1ZW5jZVtpXSwgc2VxdWVuY2Vbal0gPSBzZXF1ZW5jZVtqXSwgc2VxdWVuY2VbaV0Kc2VxdWVuY2VbaSsxOl0gPSByZXZlcnNlZChzZXF1ZW5jZVtpKzE6XSkKcmV0dXJuIHNlcXVlbmNl
The function next_permutation takes a sequence of comparable elements as input and returns the next lexicographically greater permutation of the sequence. If no such permutation exists, it returns the sequence in ascending order.
Q13. We have an unsorted array of integers such as the following: 0, 3, 1, 2, 1 In the above example, the minimum number is 2 and the maximum is 3. Given an array of integers, return the indices of the two numbers in it that add up to a specific "goal" number.
To find the indices of two numbers in an array that add up to a specific goal number, you can use a hash table to store the value of each number along with its index. Then, for each number in the array, check if the complement (i.e., the difference between the goal and the current number) is already in the hash table. If it is, then you have found the two numbers that add up to the goal, and you can return their indices.
Here's an example implementation in Python:
def find_indices(array, goal):
hash_table = {}
for i, num in enumerate(array):
complement = goal - num
if complement in hash_table:
return [hash_table[complement], i]
hash_table[num] = i
return None
ZGVmIGZpbmRfaW5kaWNlcyhhcnJheSwgZ29hbCk6Cmhhc2hfdGFibGUgPSB7fQpmb3IgaSwgbnVtIGluIGVudW1lcmF0ZShhcnJheSk6CmNvbXBsZW1lbnQgPSBnb2FsIC0gbnVtCmlmIGNvbXBsZW1lbnQgaW4gaGFzaF90YWJsZToKcmV0dXJuIFtoYXNoX3RhYmxlW2NvbXBsZW1lbnRdLCBpXQpoYXNoX3RhYmxlW251bV0gPSBpCnJldHVybiBOb25l
For example, if you have the array [1, 3, 7, 9, 2] and you want to find the indices of two numbers that add up to 10, you can call find_indices([1, 3, 7, 9, 2], 10) which will return [1, 3] (the indices of the numbers 3 and 9, which add up to 10). If no such pair of numbers exists, the function returns None.
Q14. How would you ensure the overall security of a scalable system?
Ensuring the overall security of a scalable system involves implementing a combination of measures that address different aspects of security, including access control, authentication, authorization, encryption, monitoring, and incident response. Here are some steps that can be taken to ensure the security of a scalable system:
-
Identify and prioritize security risks: Conduct a risk assessment to identify potential vulnerabilities, threats, and attack vectors that could compromise the security of the system. Prioritize the risks based on their likelihood and potential impact.
-
Implement strong access controls: Use a combination of authentication and authorization mechanisms to ensure that only authorized users have access to the system and its resources. This could include using multi-factor authentication, role-based access control, and least privilege principles.
-
Encrypt sensitive data: Use encryption to protect sensitive data both in transit and at rest. Use strong encryption algorithms and key management practices to ensure the confidentiality and integrity of the data.
-
Implement monitoring and logging: Implement logging and monitoring capabilities to detect and respond to security incidents. Use security information and event management (SIEM) tools to collect and analyze security logs, and use intrusion detection and prevention systems to identify and block malicious activity.
-
Implement incident response procedures: Develop and test incident response procedures to ensure that the organization can quickly and effectively respond to security incidents. This could include having a designated incident response team, documenting incident response procedures, and conducting regular incident response drills.
-
Stay up-to-date with security best practices: Stay informed about new security threats and best practices for securing scalable systems. This could include participating in security forums and conferences, subscribing to security alerts and updates, and engaging with industry experts and security professionals.
-
Conduct regular security assessments: Conduct regular security assessments to identify new security risks and ensure that existing security measures are effective. This could include penetration testing, vulnerability scanning, and security audits.
Overall, ensuring the security of a scalable system requires a holistic approach that addresses all aspects of security, from access control to incident response. By implementing a combination of measures and staying vigilant about new security risks and best practices, organizations can ensure the security and integrity of their scalable systems.
Q15. Convert a structure into a hex string and reverse it back to a structure.
Here's an example of how to convert a struct into a hex string and back to a struct using reinterpret_cast with a void pointer in C++:
#include
#include
#include
using namespace std;
struct MyStruct {
int a;
double b;
char c[10];
};
int main() {
// Create an instance of MyStruct
MyStruct myStruct;
myStruct.a = 1234;
myStruct.b = 56.78;
strncpy(myStruct.c, "hello", sizeof(myStruct.c));
// Convert MyStruct to hex string
char hexStr[sizeof(myStruct) * 2 + 1]; // allocate space for hex string
void* ptr = &myStruct; // create void pointer to myStruct
memcpy(hexStr, ptr, sizeof(myStruct)); // copy struct to hex string
for (int i = 0; i < sizeof(myStruct); i++) { // convert each byte to hex
sprintf(&hexStr[i * 2], "%02X", ((unsigned char*)ptr)[i]);
}
// Print hex string
cout << "Hex string: " << hexStr << endl;
// Convert hex string back to MyStruct
MyStruct* ptr2 = reinterpret_cast<MyStruct*>(hexStr); // create pointer to hex string
MyStruct myStruct2 = *ptr2; // copy hex string to new struct
// Print values of MyStruct2
cout << "a: " << myStruct2.a << endl;
cout << "b: " << myStruct2.b << endl;
cout << "c: " << myStruct2.c << endl;
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgojaW5jbHVkZSA8aW9tYW5pcD4KI2luY2x1ZGUgPGNzdHJpbmc+Cgp1c2luZyBuYW1lc3BhY2Ugc3RkOwoKc3RydWN0IE15U3RydWN0IHsKaW50IGE7CmRvdWJsZSBiOwpjaGFyIGNbMTBdOwp9OwoKaW50IG1haW4oKSB7Ci8vIENyZWF0ZSBhbiBpbnN0YW5jZSBvZiBNeVN0cnVjdApNeVN0cnVjdCBteVN0cnVjdDsKbXlTdHJ1Y3QuYSA9IDEyMzQ7Cm15U3RydWN0LmIgPSA1Ni43ODsKc3RybmNweShteVN0cnVjdC5jLCAiaGVsbG8iLCBzaXplb2YobXlTdHJ1Y3QuYykpOwoKLy8gQ29udmVydCBNeVN0cnVjdCB0byBoZXggc3RyaW5nCmNoYXIgaGV4U3RyW3NpemVvZihteVN0cnVjdCkgKiAyICsgMV07IC8vIGFsbG9jYXRlIHNwYWNlIGZvciBoZXggc3RyaW5nCnZvaWQqIHB0ciA9ICZteVN0cnVjdDsgLy8gY3JlYXRlIHZvaWQgcG9pbnRlciB0byBteVN0cnVjdAptZW1jcHkoaGV4U3RyLCBwdHIsIHNpemVvZihteVN0cnVjdCkpOyAvLyBjb3B5IHN0cnVjdCB0byBoZXggc3RyaW5nCmZvciAoaW50IGkgPSAwOyBpIDwgc2l6ZW9mKG15U3RydWN0KTsgaSsrKSB7IC8vIGNvbnZlcnQgZWFjaCBieXRlIHRvIGhleApzcHJpbnRmKCZoZXhTdHJbaSAqIDJdLCAiJTAyWCIsICgodW5zaWduZWQgY2hhciopcHRyKVtpXSk7Cn0KCi8vIFByaW50IGhleCBzdHJpbmcKY291dCA8PCAiSGV4IHN0cmluZzogIiA8PCBoZXhTdHIgPDwgZW5kbDsKCi8vIENvbnZlcnQgaGV4IHN0cmluZyBiYWNrIHRvIE15U3RydWN0Ck15U3RydWN0KiBwdHIyID0gcmVpbnRlcnByZXRfY2FzdDxNeVN0cnVjdCo+KGhleFN0cik7IC8vIGNyZWF0ZSBwb2ludGVyIHRvIGhleCBzdHJpbmcKTXlTdHJ1Y3QgbXlTdHJ1Y3QyID0gKnB0cjI7IC8vIGNvcHkgaGV4IHN0cmluZyB0byBuZXcgc3RydWN0CgovLyBQcmludCB2YWx1ZXMgb2YgTXlTdHJ1Y3QyCmNvdXQgPDwgImE6ICIgPDwgbXlTdHJ1Y3QyLmEgPDwgZW5kbDsKY291dCA8PCAiYjogIiA8PCBteVN0cnVjdDIuYiA8PCBlbmRsOwpjb3V0IDw8ICJjOiAiIDw8IG15U3RydWN0Mi5jIDw8IGVuZGw7CgpyZXR1cm4gMDsKfQ==

Computer Architecture Intel Interview Questions
Q16. What are some of the components of a microprocessor?
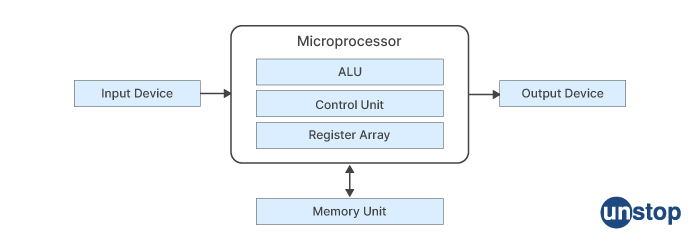
A microprocessor is a complex integrated circuit that performs various operations such as arithmetic, logic, and control functions. Some of the essential components of a microprocessor are:
-
Control Unit (CU): The control unit of a microprocessor is responsible for fetching and executing instructions from memory. It decodes the instructions and generates control signals to manage the data flow within the microprocessor.
-
Arithmetic and Logic Unit (ALU): The ALU of a microprocessor performs arithmetic and logical operations, such as addition, subtraction, multiplication, and comparison.
-
Registers: Registers are small, high-speed storage areas within a microprocessor that hold data, addresses, and control information. Examples of registers in a microprocessor include the program counter (PC), instruction register (IR), accumulator (ACC), and flag register.
-
Cache Memory: Cache memory is a small, high-speed memory that stores frequently accessed data and instructions. Cache memory is used to improve the performance of the microprocessor by reducing the time required to access data from the main memory.
-
Bus Interface Unit (BIU): The BIU of a microprocessor is responsible for managing the communication between the microprocessor and the external devices, such as memory and I/O devices. It controls the address bus, data bus, and control bus.
-
Clock Generator: The clock generator generates a clock signal that synchronizes the operation of the microprocessor. The clock signal determines the rate at which instructions are executed and the speed of data transfer within the microprocessor.
-
Power Management Unit: The power management unit of a microprocessor controls the power consumption of the device. It manages the voltage and clock frequency of the microprocessor to optimize power consumption.
Q17. What is a snooping protocol?
A snooping protocol is a type of cache coherence protocol used in computer systems to ensure that all processors have consistent and up-to-date copies of shared data stored in the system's memory. In a multi-processor system, each processor has its cache memory, which stores frequently accessed data for quick access. When a processor writes data to its cache memory, the snooping protocol ensures that any other processor's cache memory holding a copy of that data is invalidated or updated, to ensure coherence.
Snooping protocols work by having each cache monitor the bus for memory transactions. When a processor writes to a memory location, the other processors snooping the bus are notified of the write and either invalidate or update their cached copy of the data. Similarly, when a processor reads from a memory location, the snooping protocol ensures that the data being read is up-to-date by either fetching the latest copy from memory or updating the cached copy held by another processor.
Q18. What is a RAID system?
RAID stands for Redundant Array of Independent Drives, which is a technology that uses multiple hard drives to improve the performance, reliability, and capacity of data storage systems. In a RAID system, multiple physical hard drives are combined into a logical unit to provide data redundancy, improved performance, or both.
There are several different types of RAID levels, each with its advantages and disadvantages. Some of the most commonly used RAID levels are:
-
RAID 0: Also known as striping, this level uses two or more disks to store data in blocks across the disks, resulting in increased performance as data can be accessed in parallel from multiple disks. However it doesn't provide any data redundancy and if any disk fails it results in data loss
-
RAID 1: Also known as mirroring, this level uses two or more disks to create an exact copy of the data on one disk on another disk, providing redundancy in case of disk failure. However, it does not provide any performance benefits.
-
RAID 5: This level uses three or more disks to store data along with parity information that can be used to reconstruct data in case of disk failure. It provides both performance benefits and redundancy but requires more complex data handling and is slower than RAID 0.
-
RAID 6: This level is similar to RAID 5, but uses two sets of parity data instead of one, providing better fault tolerance in case of multiple disk failures.
-
RAID 10: Also known as RAID 1+0, this level combines the performance benefits of RAID 0 with the redundancy benefits of RAID 1 by striping data across mirrored sets of disks. It provides both high performance and fault tolerance but requires a minimum of four disks.
Q19. What is associate mapping?
Associative mapping, also known as fully associative mapping, is a mapping technique used in cache memory systems. In this technique, each block of main memory can be mapped to any line in the cache memory. Unlike direct mapping, where each block of main memory is mapped to a specific line in the cache, associative mapping allows any block of memory to be placed in any cache line, provided that the line is not already occupied by another block.
In associative mapping, the cache controller searches the entire cache memory for a matching block when cache access is requested. This search is usually done using a content-addressable memory (CAM), which allows the cache controller to search for a particular block of data by comparing its contents with the contents of all cache lines in parallel.
The main advantage of associative mapping is its flexibility, as it can handle any block of memory regardless of its location in the main memory. This technique also results in a higher cache hit rate compared to direct mapping, as there is less likelihood of cache conflicts. However, associative mapping is more complex and expensive to implement than direct mapping, as it requires additional hardware to perform the cache search operation.
Q20. What is a DMA?
DMA stands for Direct Memory Access, which is a technique used in computer systems to allow hardware devices to access the main memory directly, without involving the CPU in the data transfer process. In DMA, the hardware device uses a dedicated DMA controller to transfer data directly to or from the main memory, while the CPU is free to perform other tasks.
The main advantage of DMA is that it reduces the load on the CPU, as it no longer needs to be involved in the data transfer process. This allows the CPU to perform other tasks while the data is being transferred, improving the overall system performance. DMA is commonly used in devices that transfer large amounts of data, such as disk controllers, network adapters, and graphics cards.
The basic steps involved in a DMA transfer are:
-
The device sends a request to the DMA controller to transfer data.
-
The DMA controller requests access to the main memory from the CPU.
-
Once access is granted, the DMA controller transfers data directly between the device and the main memory.
-
Once the transfer is complete, the DMA controller sends an interrupt signal to the CPU to notify it of the completion.
Intel DFT Interview Questions
Q21. What is test point insertion? Can you explain its scenario?
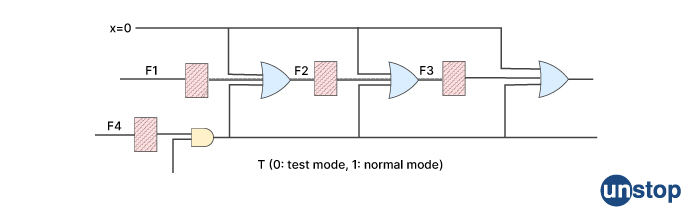
Test point insertion refers to the process of adding a point in a digital or analog circuit where the signals can be probed for testing or debugging purposes. These points are typically added during the design phase of the circuit, but can also be added later during the manufacturing process or in the field if necessary.
The purpose of test point insertion is to provide engineers and technicians with access to various signals in the circuit, so they can monitor and analyze the behavior of the circuit under different conditions. By probing the signals at these test points, engineers can verify the functionality of the circuit and identify any faults or defects that may be present.
There are various scenarios where test point insertion can be useful. For example, in the design phase of a circuit, test points can be added to measure the voltage and current levels at different points in the circuit, which can help the designer identify any issues that may arise. During manufacturing, test points can be added to test the functionality of the circuit before it is shipped to the customer. In the field, test points can be used to diagnose and fix any problems that may arise during operation.
Q22. Can you explain some uses of clock gating in design?
Clock gating is a technique used in digital circuit design to reduce power consumption by selectively disabling the clock signal to parts of the circuit that are not currently in use. Here are some common uses of clock gating in design:
-
Power saving: One of the most common uses of clock gating is to reduce power consumption in digital circuits. By gating the clock signal to unused portions of the circuit, power consumption can be significantly reduced, which is particularly important in battery-powered devices.
-
Timing optimization: Clock gating can also be used to optimize the timing of a circuit. By selectively disabling the clock signal to certain parts of the circuit, designers can reduce the delay and improve the performance of the circuit.
-
Debugging: Clock gating can also be useful for debugging purposes. By gating the clock signal to certain parts of the circuit, designers can isolate and test specific portions of the circuit, which can make it easier to identify and fix bugs.
-
Security: Clock gating can also be used as a security measure to prevent unauthorized access to sensitive parts of the circuit. By gating the clock signal to these parts of the circuit, unauthorized users will not be able to access or modify sensitive data.
Q23. Can you explain the scan insertion steps?
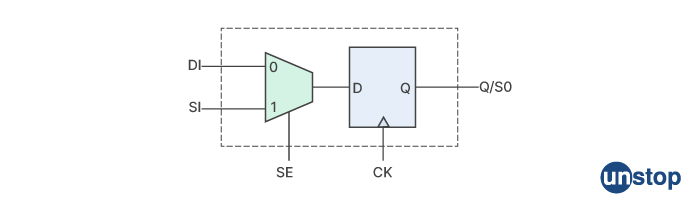
Scan insertion is a technique used in digital circuit design for testability. It involves adding scan chains to the design to enable the testing of the circuit during manufacturing and in-field service. Here are the steps involved in scan insertion:
-
Design Partitioning: The first step in scan insertion is to partition the design into smaller modules that can be tested independently. This helps to reduce the complexity of the testing process and allows for easier identification of any faults or defects that may be present.
-
Scan Chain Creation: The next step is to create scan chains for each of the modules. A scan chain is a series of flip-flops that are connected in a shift register configuration. The input to each flip-flop is connected to the output of the previous flip-flop in the chain, and the output of the last flip-flop in the chain is connected back to the input of the first flip-flop. This creates a loop that allows the contents of the flip-flops to be shifted out and then shifted back in again.
-
Scan Chain Insertion: Once the scan chains have been created, they need to be inserted into the design. This involves replacing the original flip-flops in the design with the scan flip-flops that make up the scan chains. The scan flip-flops have two inputs, one for the normal input to the flip-flop and one for the test data input.
-
Test Vector Generation: The next step is to generate test vectors that will be used to test the circuit. Test vectors are sequences of input values that are applied to the circuit to check its functionality. The test vectors are loaded into the scan chains and shifted through the circuit.
-
Test Execution: The final step is to execute the test vectors and check the output of the circuit. The output of the circuit is shifted out of the scan chains and compared to the expected output. If there are any discrepancies, this indicates that there is a fault or defect in the circuit that needs to be fixed.
Q24. What is a lockup latch and why do we use it?
A lockup latch is a type of latch that is added to a digital circuit design to prevent it from entering an undefined state, which can occur when multiple inputs are changing at the same time. When a circuit enters an undefined state, it can lead to incorrect output values, which can cause the circuit to malfunction.
A lockup latch is designed to prevent this by latching the circuit output when the inputs are changing at the same time. The latch is designed to hold the output at its current value until the inputs have stabilized, at which point the latch is released and the circuit can resume normal operation.
The lockup latch works by detecting when the inputs are changing at the same time and holding the circuit output at its previous value until the inputs have stabilized. This prevents the circuit from entering an undefined state and ensures that the output is stable and reliable. Lockup latches are commonly used in high-speed digital circuits where multiple inputs are changing simultaneously. They are particularly useful in circuits that a
The compression ratio for a core in a digital circuit design can be determined by considering several factors, including the type and size of the design, the desired test time, and the available resources for testing.
-
Type and size of the design: The complexity of the design and the number of inputs and outputs can impact the compression ratio. For larger designs with many inputs and +outputs, a higher compression ratio may be necessary to achieve the desired test time.
-
Desired test time: The amount of time available for testing can also impact the compression ratio. A higher compression ratio can reduce the number of test vectors required for testing, which can reduce the overall test time.
-
Available resources: The available resources for testing, such as memory and processing power, can also impact the compression ratio. A higher compression ratio may require more memory and processing power to compress and decompress test data, which may not be feasible in some cases.
-
Test coverage: The compression ratio should be chosen to ensure that the compressed test data provide sufficient test coverage to detect faults and defects in the design. A higher compression ratio may reduce the number of test vectors required, but if the compressed data does not provide sufficient test coverage, it may not be effective for detecting faults.
Overall, lockup latches are an important tool in digital circuit design for ensuring the reliability and stability of circuits in the presence of multiple input transitions. They are used to prevent circuits from entering undefined states, which can cause incorrect output values and circuit malfunctions.
Q25. How will you decide the compression ratio for the core?
The compression ratio for a core in a digital circuit design can be determined by considering several factors, including the type and size of the design, the desired test time, and the available resources for testing.
-
Type and size of the design: The complexity of the design and the number of inputs and outputs can impact the compression ratio. For larger designs with many inputs and outputs, a higher compression ratio may be necessary to achieve the desired test time.
-
Desired test time: The amount of time available for testing can also impact the compression ratio. A higher compression ratio can reduce the number of test vectors required for testing, which can reduce the overall test time.
-
Available resources: The available resources for testing, such as memory and processing power can also impact the compression ratio. A higher compression ratio may require more memory and processing power to compress and decompress test data, which may not be feasible in some cases.
-
Test coverage: The compression ratio should be chosen to ensure that the compressed test data provide sufficient test coverage to detect faults and defects in the design. A higher compression ratio may reduce the number of test vectors required, but if the compressed data does not provide sufficient test coverage, it may not be effective for detecting faults.
Intel Verification Engineer Interview Questions
Q26. What are the various stages in PCIe linkup?
The PCIe linkup process involves several stages to establish communication between the two devices connected via the PCIe interface. The following are the various stages in the PCIe linkup process:
-
Electrical Link Initialization: In this stage, the physical layer of the PCIe interface is initialized, and the two devices negotiate the electrical characteristics of the link, such as the transmission rate and lane configuration. The devices also exchange electrical test patterns to verify the link's integrity and performance.
-
Link Training: After the electrical link is initialized, the devices enter the link training phase. During this stage, the devices exchange link training sequences to establish a reliable and error-free data transmission link. The link training includes equalization, which adjusts the signal voltage and timing to compensate for any signal loss or distortion in the transmission.
-
Logical Link Initialization: Once the link training is complete, the devices initiate logical link initialization to configure the logical parameters of the link, such as the maximum payload size and the number of lanes used for data transmission.
-
Data Link Layer Initialization: After the logical link initialization is complete, the devices initialize the data link layer to establish the virtual channels and ensure error-free data transmission between the two devices. The data link layer also performs flow control to regulate the flow of data between the devices to prevent buffer overflows or underflows.
-
Transaction Layer Initialization: The final stage of the PCIe linkup process is the transaction layer initialization, where the devices establish the transaction layer protocols for exchanging data, commands, and status information between the two devices.
Q27. How do you ensure no data loss happens in HW to SW communication?
To ensure that no data loss occurs in HW to SW communication, it is important to use appropriate communication protocols and techniques that provide reliable and error-free data transmission. The following are some ways to ensure no data loss in HW to SW communication:
-
Use Reliable Communication Protocols: When communicating between hardware and software, it is important to use reliable communication protocols that guarantee the delivery of data without any loss or corruption. For example, protocols like TCP/IP, USB, and PCIe are reliable and widely used for communication between hardware and software.
-
Implement Error-Checking Mechanisms: Hardware devices should include error-checking mechanisms like CRC or checksum to ensure data integrity. Similarly, software applications should have error detection and correction mechanisms that can identify and correct data errors.
-
Use Flow Control: Flow control mechanisms can be implemented to regulate the flow of data between hardware and software to prevent data loss due to buffer overflows or underflows.
-
Implement Timeouts: Timeouts can be used to ensure that hardware devices and software applications do not wait indefinitely for data transfer to complete. Timeouts can help detect and handle situations where data transfer is stalled or has failed.
-
Use Reliable Hardware Components: The hardware components used for communication, such as cables and connectors, should be of high quality and designed for reliable data transfer. Poor quality hardware components can lead to data loss due to signal degradation or noise.
By implementing these techniques, it is possible to ensure reliable and error-free communication between hardware and software and prevent data loss.
Q28. Design muxes and write code for the Fibonacci series.
Design of Mux:
A multiplexer, or MUX, is a combinational logic circuit that selects one of several inputs and forwards the selected input to a single output. The selection of input is determined by the values of select lines. Below is the truth table for a 2:1 MUX:
| Select | Input A | Input B | Output |
|---|---|---|---|
| 0 | 0 | 1 | 0 |
| 1 | 0 | 1 | 1 |
Code for Fibonacci series:
The Fibonacci sequence is a series of numbers in which each number is the sum of the two preceding ones. Below is the code to print the first n numbers of the Fibonacci sequence:
#include
int main() {
int n, i, t1 = 0, t2 = 1, nextTerm;
printf("Enter the number of terms: ");
scanf("%d", &n);
printf("Fibonacci Series: ");
for (i = 1; i <= n; ++i) {
printf("%d, ", t1);
nextTerm = t1 + t2;
t1 = t2;
t2 = nextTerm;
}
return 0;
}
I2luY2x1ZGUgPHN0ZGlvLmg+CgppbnQgbWFpbigpIHsKaW50IG4sIGksIHQxID0gMCwgdDIgPSAxLCBuZXh0VGVybTsKCnByaW50ZigiRW50ZXIgdGhlIG51bWJlciBvZiB0ZXJtczogIik7CnNjYW5mKCIlZCIsICZuKTsKCnByaW50ZigiRmlib25hY2NpIFNlcmllczogIik7Cgpmb3IgKGkgPSAxOyBpIDw9IG47ICsraSkgewpwcmludGYoIiVkLCAiLCB0MSk7Cm5leHRUZXJtID0gdDEgKyB0MjsKdDEgPSB0MjsKdDIgPSBuZXh0VGVybTsKfQpyZXR1cm4gMDsKfQ==
This code prompts the user to enter the number of terms to be printed and uses a for loop to calculate and print the Fibonacci sequence. The loop runs n times, and at each iteration, it prints the current term (t1) and calculates the next term using the formula t1 + t2. The values of t1 and t2 are updated to generate the next term in the sequence.
Q29. What is your experience with verification methodologies such as UVM, OVM, or VMM?
UVM (Universal Verification Methodology) is a standard verification methodology used in the design and verification of digital circuits. It is an advanced verification methodology that is based on the use of object-oriented programming (OOP) techniques. UVM provides a standard methodology for creating a reusable, scalable, and maintainable testbench environment.
OVM (Open Verification Methodology) is another verification methodology that is similar to UVM but is an older standard. OVM is based on SystemVerilog and provides a set of open-source classes, libraries, and methodology guidelines for creating verification environments.
VMM (Verification Methodology Manual) is another widely used verification methodology that provides a set of guidelines, practices, and classes for developing verification environments. VMM is similar to UVM and OVM but is based on the e-verification language (EVL).
Q30. Can you explain the difference between a directed test and a constrained-random test?
Directed tests and constrained-random tests are two common approaches to creating test cases in the field of verification engineering.
Directed tests are test cases that are specifically designed to exercise a particular feature or behavior of a design. Directed tests are typically created by the verification engineer, and the input stimuli and expected output results are specified manually. These tests are deterministic and are usually created based on the design specification or requirements.
Constrained-random tests, on the other hand, are generated using a random number generator with constraints that ensure the generated inputs are valid and meaningful. Constrained-random tests are useful in finding corner cases or unexpected behaviors that might not be caught by directed tests. These tests are non-deterministic and can generate a large number of possible test cases.
We hope that you have gained a great deal of clarity and knowledge from these Intel Interview questions with detailed answers. Here are some suggested reads to help you brush up on fundamental technical knowledge:
- The Structure of C++ Programs Explained With Examples!
- What is Linux OS? | Architecture | Features | Installing Linux
- How To Open A File In Linux Using 3 Different Approaches
- Advantages And Disadvantages Of Linked Lists Summed Up For You!
- Top Netflix Interview Questions For Software Engineer And SRE Roles
Login to continue reading
And access exclusive content, personalized recommendations, and career-boosting opportunities.
Don't have an account? Sign up
Never miss an
Update

Featured Opportunities
Top-Rated Practice by Students





Subscribe
to our newsletter




Comments
Add comment