

Asian Paints Alchemy 2026
Company Interview Questions for Freshers
- TCS Technical Interview Questions & Answers
- TCS Managerial Interview Questions & Answers
- TCS HR Interview Questions & Answers
- Overview of Cognizant Recruitment Process
- Cognizant Interview Questions: Technical
- Cognizant Interview Questions: HR Round
- Overview of Wipro Technologies Recruitment Rounds
- Wipro Interview Questions
- Technical Round
- HR Round
- Online Assessment Sample Questions
- Frequently Asked Questions
- Overview of Google Recruitment Process
- Google Interview Questions: Technical
- Google Interview Questions: HR round
- Interview Preparation Tips
- About Google
- Deloitte Technical Interview Questions
- Deloitte HR Interview Questions
- Deloitte Recruitment Process
- Technical Interview Questions and Answers
- Level 1 difficulty
- Level 2 difficulty
- Level 3 difficulty
- Behavioral Questions
- Eligibility Criteria for Mindtree Recruitment
- Mindtree Recruitment Process: Rounds Overview
- Skills required to crack Mindtree interview rounds
- Mindtree Recruitment Rounds: Sample Questions
- About Mindtree
- Preparing for Microsoft interview questions
- Microsoft technical interview questions
- Microsoft behavioural interview questions
- Aptitude Interview Questions
- Technical Interview Questions
- Easy
- Intermediate
- Hard
- HR Interview Questions
- Eligibility criteria
- Recruitment rounds & assessments
- Tech Mahindra interview questions - Technical round
- Tech Mahindra interview questions - HR round
- Hiring process at Mphasis
- Mphasis technical interview questions
- Mphasis HR interview questions
- About Mphasis
- Technical interview questions
- HR interview questions
- Recruitment process
- About Virtusa
- Goldman Sachs Interview Process
- Technical Questions for Goldman Sachs Interview
- Sample HR Question for Goldman Sachs Interview
- About Goldman Sachs
- Nagarro Recruitment Process
- Nagarro HR Interview Questions
- Nagarro Aptitude Test Questions
- Nagarro Technical Test Questions
- About Nagarro
- PwC Recruitment Process
- PwC Technical Interview Questions: Freshers and Experienced
- PwC Interview Questions for HR Rounds
- PwC Interview Preparation
- Frequently Asked Questions
- EY Technical Interview Questions (2023)
- EY Interview Questions for HR Round
- About EY
- Morgan Stanley Recruitment Process
- HR Questions for Morgan Stanley Interview
- HR Questions for Morgan Stanley Interview
- About Morgan Stanley
- Recruitment Process at Flipkart
- Technical Flipkart Interview Questions
- Code-Based Flipkart Interview Questions
- Sample Flipkart Interview Questions- HR Round
- Conclusion
- FAQs
- Recruitment Process at Paytm
- Technical Interview Questions for Paytm Interview
- HR Sample Questions for Paytm Interview
- About Paytm
- Most Probable Accenture Interview Questions
- Accenture Technical Interview Questions
- Accenture HR Interview Questions
- Amazon Recruitment Process
- Amazon Interview Rounds
- Common Amazon Interview Questions
- Amazon Interview Questions: Behavioral-based Questions
- Amazon Interview Questions: Leadership Principles
- Company-specific Amazon Interview Questions
- 43 Top Technical/ Coding Amazon Interview Questions
- Juspay Recruitment: Stages and Timeline
- Juspay Interview Questions and Answers
- How to prepare for Juspay interview questions
- Prepare for the Juspay Interview: Stages and Timeline
- Frequently Asked Questions
- Adobe Interview Questions - Technical
- Adobe Interview Questions - HR
- Recruitment Process at Adobe
- About Adobe
- Cisco technical interview questions
- Sample HR interview questions
- The recruitment process at Cisco
- About Cisco
- JP Morgan interview questions (Technical round)
- JP Morgan interview questions HR round)
- Recruitment process at JP Morgan
- About JP Morgan
- Wipro Elite NTH: Selection Process
- Wipro Elite NTH Technical Interview Questions
- Wipro Elite NTH Interview Round- HR Questions
- BYJU's BDA Interview Questions
- BYJU's SDE Interview Questions
- BYJU's HR Round Interview Questions
- A Quick Overview of the KPMG Recruitment Process
- Technical Questions for KPMG Interview
- HR Questions for KPMG Interview
- About KPMG
- DXC Technology Interview Process
- DCX Technical Interview Questions
- Sample HR Questions for DXC Technology
- About DXC Technology
- Recruitment Process at PayPal
- Technical Questions for PayPal Interview
- HR Sample Questions for PayPal Interview
- About PayPal
- Capgemini Recruitment Rounds
- Capgemini Interview Questions: Technical round
- Capgemini Interview Questions: HR round
- Preparation tips
- FAQs
- Technical interview questions for Siemens
- Sample HR questions for Siemens
- The recruitment process at Siemens
- About Siemens
- HCL Technical Interview Questions
- HR Interview Questions
- HCL Technologies Recruitment Process
- List of EPAM Interview Questions for Technical Interviews
- About EPAM
- Atlassian Interview Process
- Top Skills for Different Roles at Atlassian
- Atlassian Interview Questions: Technical Knowledge
- Atlassian Interview Questions: Behavioral Skills
- Atlassian Interview Questions: Tips for Effective Preparation
- Walmart Recruitment Process
- Walmart Interview Questions and Sample Answers (HR Round)
- Walmart Interview Questions and Sample Answers (Technical Round)
- Tips for Interviewing at Walmart and Interview Preparation Tips
- Frequently Asked Questions
- Uber Interview Questions For Engineering Profiles: Coding
- Technical Uber Interview Questions: Theoretical
- Uber Interview Question: HR Round
- Uber Recruitment Procedure
- About Uber Technologies Ltd.
- Intel Technical Interview Questions
- Computer Architecture Intel Interview Questions
- Intel DFT Interview Questions
- Intel Interview Questions for Verification Engineer Role
- Recruitment Process Overview
- Important Accenture HR Interview Questions
- Points to remember
- What is Selenium?
- What are the components of the Selenium suite?
- Why is it important to use Selenium?
- What's the major difference between Selenium 3.0 & Selenium 2.0?
- What is Automation testing and what are its benefits?
- What are the benefits of Selenium as an Automation Tool?
- What are the drawbacks to using Selenium for testing?
- Why should Selenium not be used as a web application or system testing tool?
- Is it possible to use selenium to launch web browsers?
- What does Selenese mean?
- What does it mean to be a locator?
- Identify the main difference between "assert", and "verify" commands within Selenium
- What does an exception test in Selenium mean?
- What does XPath mean in Selenium? Describe XPath Absolute & XPath Relation
- What is the difference in Xpath between "//"? and "/"?
- What is the difference between "type" and the "typeAndWait" commands within Selenium?
- Distinguish between findElement() & findElements() in context of Selenium
- How long will Selenium wait before a website is loaded fully?
- What is the difference between the driver.close() and driver.quit() commands in Selenium?
- Describe the different navigation commands that Selenium supports
- What is Selenium's approach to the same-origin policy?
- Explain the difference between findElement() in Selenium and findElements()
- Explain the pause function in SeleniumIDE
- Explain the differences between different frameworks and how they are connected to Selenium's Robot Framework
- What are your thoughts on the Page Object Model within the context of Selenium
- What are your thoughts on Jenkins?
- What are the parameters that selenium commands come with a minimum?
- How can you tell the differences in the Absolute pathway as well as Relative Path?
- What's the distinction in Assert or Verify declarations within Selenium?
- What are the points of verification that are in Selenium?
- Define Implicit wait, Explicit wait, and Fluent
- Can Selenium manage windows-based pop-ups?
- What's the definition of an Object Repository?
- What is the main difference between obtainwindowhandle() as well as the getwindowhandles ()?
- What are the various types of Annotations that are used in Selenium?
- What is the main difference in the setsSpeed() or sleep() methods?
- What is the way to retrieve the alert message?
- How do you determine the exact location of an element on the web?
- Why do we use Selenium RC?
- What are the benefits or advantages of Selenium RC?
- Do you have a list of the technical limitations when making use of Selenium RC? Selenium RC?
- What's the reason to utilize the TestNG together with Selenium?
- What Language do you prefer to use to build test case sets in Selenium?
- What are Start and Breakpoints?
- What is the purpose of this capability relevant in relation to Selenium?
- When do you use AutoIT?
- Do you have a reason why you require Session management in Selenium?
- Are you able to automatize CAPTCHA?
- How can we launch various browsers on Selenium?
- Why should you select Selenium rather than QTP (Quick Test Professional)?
- Airbus Interview Questions and Answers: HR/ Behavioral
- Industry/ Company-Specific Airbus Interview Questions
- Airbus Interview Questions and Answers: Aptitude
- Airbus Software Engineer Interview Questions and Answers: Technical
- Importance of Spring Framework
- Spring Interview Questions (Basic)
- Advanced Spring Interview Questions
- C++ Interview Questions and Answers: The Basics
- C++ Interview Questions: Intermediate
- C++ Interview Questions And Answers With Code Examples
- C++ Interview Questions and Answers: Advanced
- Test Your Skills: Quiz Time
- MBA Interview Questions: B.Com Economics
- B.Com Marketing
- B.Com Finance
- B.Com Accounting and Finance
- Business Studies
- Chartered Accountant
- Q1. Please tell us something about yourself/ Introduce yourself to us.
- Q2. Describe yourself in one word.
- Q3. Tell us about your strengths and weaknesses.
- Q4. Why did you apply for this job/ What attracted you to this role?
- Q5. What are your hobbies?
- Q6. Where do you see yourself in five years OR What are your long-term goals?
- Q7. Why do you want to work with this company?
- Q8. Tell us what you know about our organization
- Q9. Do you have any idea about our biggest competitors?
- Q10. What motivates you to do a good job?
- Q11. What is an ideal job for you?
- Q12. What is the difference between a group and a team?
- Q13. Are you a team player/ Do you like to work in teams?
- Q14. Are you good at handling pressure/ deadlines?
- Q15. When can you start?
- Q16. How flexible are you regarding overtime?
- Q17. Are you willing to relocate for work?
- Q18. Why do you think you are the right candidate for this job?
- Q19. How can you be an asset to the organization?
- Q20. What is your salary expectation?
- Q21. How long do you plan to remain with this company?
- Q22. What is your objective in life?
- Q23. Would you like to pursue your Master's degree anytime soon?
- Q24. How have you planned to achieve your career goal?
- Q25. Can you tell us about your biggest achievement in life?
- Q26. What was the most challenging decision you ever made?
- Q27. What kind of work environment do you prefer to work in?
- Q28. What is the difference between a smart worker and a hard worker?
- Q29. What will you do if you don't get hired?
- Q30. Tell us three things that are most important for you in a job.
- Q31. Who is your role model and what have you learned from him/her?
- Q32. In case of a disagreement, how do you handle the situation?
- Q33. What is the difference between confidence and overconfidence?
- Q34. If you have more than enough money in hand right now, would you still want to work?
- Q35. Do you have any questions for us?
- Interview Tips for Freshers
- Tell me about yourself
- What are your greatest strengths?
- What are your greatest weaknesses?
- Tell me about something you did that you now feel a little ashamed of
- Why are you leaving (or did you leave) this position??
- 15+ resources for preparing most-asked interview questions
- CoCubes Interview Process Overview
- Common CoCubes Interview Questions
- Key Areas to Focus on for CoCubes Interview Preparation
- Conclusion
- Frequently Asked Questions (FAQs)
- Data Analyst Interview Questions With Answers
- About Data Analyst
Top Goldman Sachs Interview Questions With Answers (2026)
Seeking a job at Goldman Sachs? Here are some important interview questions that you shouldn't miss out!

Goldman Sachs is one of the biggest companies and leading global financial firms. The American multinational investment bank and financial services company was founded in the year 1869 and is currently ranked the second-largest investment bank in the world by revenue. Considered one of the most desirable companies for people seeking professional advancement, Goldman Sachs offers a broad range of financial services for its client base such as investment banking, securities, investment management, and consumer banking.
Landing a job at Goldman Sachs is a different story as it holds one of the most challenging interview rounds for candidates. In this article, we will expose you to some of the important Goldman Sachs interview questions to help you prepare for the interview rounds of the company. We will be sharing some of the frequently asked technical and HR questions in Goldman Sachs interviews.
Goldman Sachs Interview Process
For a software engineering profile, one is required to meet the minimum educational qualifications, required for the role.
Before you apply, you should have a solid understanding of the recruitment process at Goldman Sachs. Candidates need to go through 4-6 selection rounds that test their analytical abilities and subject knowledge. Apart from written rounds, the interview rounds include technical interviews (for testing their technical abilities), and HR interview rounds for assessing the communication abilities as well as other interpersonal skills of the candidate.
Goldman Sachs Interview Questions for Technical Round
Here are some of the frequently asked technical questions that will help you in your tech interview prep.
Note: Apart from computer science questions, the candidate may be asked basic questions related to the banking sector. Hence, one must be prepared for the same.
1. How do you find the middle element?
To find the middle element of a sequence, you need to know the length of the sequence. If the sequence has an odd number of elements, the middle element is simply the one that has the same number of elements on either side of it. If the sequence has an even number of elements, there are two middle elements, and you can choose which one to use.
Here's some sample code in Python to find the middle element of a list:
#def find_middle_element(lst):
length = len(lst)
if length % 2 == 0:
# if the length is even, there are two middle elements
middle_index_1 = length // 2 - 1
middle_index_2 = length // 2
return (lst[middle_index_1], lst[middle_index_2])
else:
# if the length is odd, there's just one middle element
middle_index = length // 2
return lst[middle_index] Enter your code here. Read input from STDIN. Print output to STDOUT
I2RlZiBmaW5kX21pZGRsZV9lbGVtZW50KGxzdCk6DQpsZW5ndGggPSBsZW4obHN0KQ0KaWYgbGVuZ3RoICUgMiA9PSAwOg0KIyBpZiB0aGUgbGVuZ3RoIGlzIGV2ZW4sIHRoZXJlIGFyZSB0d28gbWlkZGxlIGVsZW1lbnRzDQptaWRkbGVfaW5kZXhfMSA9IGxlbmd0aCAvLyAyIC0gMQ0KbWlkZGxlX2luZGV4XzIgPSBsZW5ndGggLy8gMg0KcmV0dXJuIChsc3RbbWlkZGxlX2luZGV4XzFdLCBsc3RbbWlkZGxlX2luZGV4XzJdKQ0KZWxzZToNCiMgaWYgdGhlIGxlbmd0aCBpcyBvZGQsIHRoZXJlJ3MganVzdCBvbmUgbWlkZGxlIGVsZW1lbnQNCm1pZGRsZV9pbmRleCA9IGxlbmd0aCAvLyAyDQpyZXR1cm4gbHN0W21pZGRsZV9pbmRleF0gRW50ZXIgeW91ciBjb2RlIGhlcmUuIFJlYWQgaW5wdXQgZnJvbSBTVERJTi4gUHJpbnQgb3V0cHV0IHRvIFNURE9VVA==
In this code, lst is the list you want to find the middle element of. The len() function is used to find the length of the list. If the length is even, the two middle elements are returned as a tuple. If the length is odd, the single middle element is returned. Note that the // operator is used for integer division, which ensures that the middle index is always an integer (even if the length of the list is odd).
2. Explain the inventory accounting method.
- Inventory accounting is a method used to track and value the inventory of goods a company has on hand. The primary purpose of inventory accounting is to determine the cost of goods sold and the value of inventory on the balance sheet.
- There are several inventory accounting methods, but the two most common are FIFO (First-In, First-Out) and LIFO (Last-In, First-Out). Under FIFO, the first items purchased or produced are assumed to be the first ones sold or used, while under LIFO, the last items purchased or produced are assumed to be the first ones sold or used.
- For example, let's say a company purchases 100 widgets at USD 5 each, and then later purchases 50 more widgets at USD 7 each. Under FIFO, the cost of the first 100 widgets sold would be calculated at USD 5 each, while under LIFO, the cost of the first 100 widgets sold would be calculated at USD 7 each.
- There's also the weighted average cost method, which calculates the average cost of all units available for sale during the period.
- Each inventory accounting method has its advantages and disadvantages. FIFO generally results in a higher ending inventory value and lower cost of goods sold, while LIFO generally results in a lower ending inventory value and higher cost of goods sold. The weighted average cost method typically falls somewhere in between.
- The choice of inventory accounting method can have a significant impact on a company's financial statements and tax liability, so it's important for businesses to carefully consider which method is most appropriate for their operations and goals.
3. What is the use of abstract class?
An abstract class in object-oriented programming is a class that cannot be instantiated on its own, but instead must be subclassed and implemented by its derived classes. The primary use of an abstract class is to provide a common interface or contract for a set of related classes while allowing for specific implementation details to be left to the individual subclasses.
Here are some of the main uses of abstract classes:
-
Defining a common interface: Abstract classes can define a set of methods or properties that any derived class must implement. This can help ensure consistency and standardization across a group of related classes.
-
Encapsulating implementation details: An abstract class can provide a common implementation for some methods or properties while leaving others to be implemented by derived classes. This can help simplify the code in the derived classes and provide a more consistent and unified implementation.
-
Enforcing design rules: Abstract classes can be used to enforce design rules or constraints on the derived classes. For example, an abstract class might specify that all derived classes must implement a particular method or use a certain design pattern.
-
Providing a base for polymorphism: Abstract classes can be used as a base class for polymorphism, which allows different objects to be treated as if they were the same type. By defining a common interface or contract, abstract classes allow for polymorphism across a set of related classes.
Overall, the use of abstract classes can help promote code reusability, simplify code design, and provide a consistent and standardized interface across a set of related classes.
4. What is an asset class?
An asset class is a group of financial instruments or investments that have similar characteristics and behave similarly in the market. Asset classes are typically defined by their risk and return characteristics, as well as by the underlying economic factors that drive their performance.
Some common asset classes include:
-
Stocks: Equity ownership in a company, representing a portion of the company's assets and earnings.
-
Bonds: Debt securities that represent a loan made by an investor to a borrower, typically a government or corporation.
-
Real estate: Physical property, such as land or buildings, that can be bought or sold.
-
Commodities: Physical goods that are traded on exchanges, such as oil, gold, or agricultural products.
-
Cash and cash equivalents: Highly liquid assets, such as money market funds or short-term government bonds.
Each asset class has its own unique risk and return profile, and the performance of each class can be influenced by different economic factors. For example, stocks may be affected by changes in corporate earnings or interest rates, while commodities may be influenced by supply and demand factors or geopolitical current events.
Investors often use asset allocation strategies to diversify their portfolios across multiple asset classes, in order to manage risk and potentially enhance returns. By selecting a mix of asset classes with different risk and return characteristics, investors can aim to achieve a balance between capital preservation and growth.
5. Why do bond prices go up?
Bond prices can go up or down based on various factors, such as changes in interest rates, credit ratings, inflation, and market demand. However, there are a few key reasons why bond prices generally go up:
-
Interest rates decrease: When interest rates decrease, the price of existing bonds with higher coupon rates becomes more valuable, as they offer a higher yield than newly issued bonds. This causes investors to bid up the price of existing bonds, driving up their value.
-
Inflation expectations decrease: When inflation expectations decrease, investors are willing to accept lower yields, as their purchasing power is expected to be stronger in the future. This increases demand for bonds, pushing up their prices.
-
Improvements in credit ratings: When the credit rating of a bond issuer improves, the risk of default decreases, making the bond more attractive to investors. This increases demand for the bond, causing its price to rise.
-
Increased demand for safe-haven assets: During times of uncertainty or market volatility, investors may seek out safe-haven assets such as high-quality bonds. This increases demand for bonds, driving up their prices.
It's important to note that bond prices and yields have an inverse relationship, meaning that when bond prices go up, yields go down, and vice versa. This is because the coupon rate remains fixed, so as the price of the bond goes up, the yield (or return) on the bond decreases. Conversely, when bond prices go down, yields go up.
6. Can you make an array of integers?
Yes, an array of integers can be created in many programming languages. Here is an example in Python:
# Accessing elements of the array
print(my_array[0]) # prints 1
print(my_array[2]) # prints 3
# Modifying elements of the array
my_array[1] = 10
print(my_array) # prints [1, 10, 3, 4, 5]
# Adding elements to the array
my_array.append(6)
print(my_array) # prints [1, 10, 3, 4, 5, 6]
# Getting the length of the array
print(len(my_array)) # prints 6
IyBBY2Nlc3NpbmcgZWxlbWVudHMgb2YgdGhlIGFycmF5DQpwcmludChteV9hcnJheVswXSkgIyBwcmludHMgMQ0KcHJpbnQobXlfYXJyYXlbMl0pICMgcHJpbnRzIDMNCg0KIyBNb2RpZnlpbmcgZWxlbWVudHMgb2YgdGhlIGFycmF5DQpteV9hcnJheVsxXSA9IDEwDQpwcmludChteV9hcnJheSkgIyBwcmludHMgWzEsIDEwLCAzLCA0LCA1XQ0KDQojIEFkZGluZyBlbGVtZW50cyB0byB0aGUgYXJyYXkNCm15X2FycmF5LmFwcGVuZCg2KQ0KcHJpbnQobXlfYXJyYXkpICMgcHJpbnRzIFsxLCAxMCwgMywgNCwgNSwgNl0NCg0KIyBHZXR0aW5nIHRoZSBsZW5ndGggb2YgdGhlIGFycmF5DQpwcmludChsZW4obXlfYXJyYXkpKSAjIHByaW50cyA2
In this example, we create an array of integers using square brackets [] and assign it to the variable my_array. We can access elements of the array using their index (starting from 0), and modify them using the assignment operator =. We can also add elements to the array using the append method, and get the length of the array using the len function.
7. What are the five accounting statements?
There are five primary financial statements in accounting:
-
Income Statement: Also known as the profit and loss statement, the income statement shows a company's revenues, expenses, and net income (or loss) for a specific period of time. It provides a snapshot of a company's profitability during that period.
-
Balance Sheet: The balance sheet presents a company's financial position at a specific point in time, showing its assets, liabilities, and equity. Assets represent what a company owns, liabilities represent what it owes, and equity represents the difference between the two.
-
Statement of Cash Flows: The statement of cash flows shows the sources and uses of cash over a specific period of time. It categorizes a company's cash inflows and outflows into three sections: operating activities, investing activities, and financing activities.
-
Statement of Retained Earnings: The statement of retained earnings shows how a company's earnings have been distributed between dividends and retained earnings over a specific period of time. It is derived from the income statement and the balance sheet.
-
Financial Statement Footnotes: Financial statement footnotes provide additional information about a company's financial performance and position that cannot be directly inferred from the primary financial statements. This can include details about significant accounting policies, contingent liabilities, and other financial information.
Together, these five financial statements provide a comprehensive view of a company's financial performance and position. They are often used by investors, analysts, and other stakeholders to evaluate a company's financial health and make informed decisions.
8. What is Java Virtual Machine (JVM)?
- Java Virtual Machine (JVM) is an abstract machine that provides the runtime environment in which Java programs are executed. It is a crucial component of the Java platform, as it is responsible for interpreting compiled Java code and executing it on the underlying hardware.
- When a Java program is compiled, it is converted into a platform-independent bytecode format that can be executed on any device that has a JVM installed. The JVM takes care of translating the bytecode into machine-specific instructions, managing memory allocation and deallocation, performing garbage collection, and enforcing Java's security model.
- The JVM also provides a set of standard Java libraries and APIs, which allow Java developers to write code that can run on any platform without needing to worry about hardware-specific details. Additionally, the JVM supports Just-In-Time (JIT) compilation, which can improve the performance of Java programs by dynamically optimizing the bytecode as it is executed.
- Overall, the JVM plays a critical role in making Java a cross-platform language, as it allows Java code to run on a wide range of devices and operating systems without needing to be recompiled.
9. What is a thread in Java?
 A thread in Java refers to a separate execution path that runs concurrently with other threads within a single program. In Java, threads are a fundamental component of the language and are used to implement concurrent and parallel programming.
A thread in Java refers to a separate execution path that runs concurrently with other threads within a single program. In Java, threads are a fundamental component of the language and are used to implement concurrent and parallel programming.
Each thread in Java has its own call stack, which allows it to execute a separate sequence of instructions independently of other threads. Threads can communicate with each other and share resources such as memory, but this must be done carefully to avoid conflicts and synchronization issues.
In Java, threads can be created and managed using the Thread class or by implementing the Runnable interface. The Thread class provides methods for starting, pausing, resuming, and stopping threads, while the Runnable interface defines a single run() method that must be implemented to specify the thread's behavior.
Using threads, Java developers can implement concurrent and parallel programming to improve application performance and responsiveness. However, threading must be done carefully to avoid synchronization issues, race conditions, and other problems that can arise when multiple threads access shared resources simultaneously.
10. What is overloading and overriding?
Overloading and overriding are two concepts in object-oriented programming that involve the use of methods with the same name but different behavior.
Overloading: Method overloading is the ability to define multiple methods in a class with the same name but different parameters. In Java, the compiler distinguishes between overloaded methods based on their parameter types and number of parameters. Method overloading allows developers to create more readable and concise code by providing methods with different behavior but the same name.
For example:
public int sum(int a, int b) {
return a + b;
}
public double sum(double a, double b) {
return a + b;
}
cHVibGljIGludCBzdW0oaW50IGEsIGludCBiKSB7CnJldHVybiBhICsgYjsKfQoKcHVibGljIGRvdWJsZSBzdW0oZG91YmxlIGEsIGRvdWJsZSBiKSB7CnJldHVybiBhICsgYjsKfQ==
In the above example, two sum() methods are defined, one for integers and one for doubles. The compiler can determine which method to call based on the data types of the arguments passed to the method.
Overriding: Method overriding is the ability to provide a different implementation of a method that is already defined in the superclass. In Java, method overriding is achieved by defining a method with the same signature (i.e., the same name and parameter types) in the subclass. Method overriding allows developers to create more specialized behavior for a specific class, while still reusing code from the superclass.
For example:
public class Animal {
public void makeSound() {
System.out.println("Animal is making a sound");
}
}
public class Cat extends Animal {
@Override
public void makeSound() {
System.out.println("Meow");
}
}
cHVibGljIGNsYXNzIEFuaW1hbCB7CnB1YmxpYyB2b2lkIG1ha2VTb3VuZCgpIHsKU3lzdGVtLm91dC5wcmludGxuKCJBbmltYWwgaXMgbWFraW5nIGEgc291bmQiKTsKfQp9CgpwdWJsaWMgY2xhc3MgQ2F0IGV4dGVuZHMgQW5pbWFsIHsKQE92ZXJyaWRlCnB1YmxpYyB2b2lkIG1ha2VTb3VuZCgpIHsKU3lzdGVtLm91dC5wcmludGxuKCJNZW93Iik7Cn0KfQ==
In the above example, the makeSound() method is overridden in the Cat class to provide a more specific implementation for a Cat object. When the makeSound() method is called on a Cat object, the overridden implementation in the Cat class will be executed instead of the implementation in the Animal class.
11. What is the final keyword?
In Java, the final keyword is used to indicate that a variable, method, or class cannot be changed or overridden.
- Final Variables: If a variable is declared as
final, its value cannot be changed once it has been initialized. Final variables are typically used to represent constant values in the code, and can be useful for improving readability and preventing bugs caused by accidentally changing a value.
For example:
final int MAX_VALUE = 100;
In the above example, the MAX_VALUE variable is declared as final and initialized to the value of 100. Once initialized, its value cannot be changed.
- Final Methods: If a method is declared as
final, it cannot be overridden by subclasses. Final methods can be useful when you want to prevent subclasses from changing the behavior of a method that is critical to the class's functionality.
For example:
public class Animal {
public final void move() {
System.out.println("The animal is moving");
}
}
public class Cat extends Animal {
// The move() method cannot be overridden in this subclass
}
cHVibGljIGNsYXNzIEFuaW1hbCB7CnB1YmxpYyBmaW5hbCB2b2lkIG1vdmUoKSB7ClN5c3RlbS5vdXQucHJpbnRsbigiVGhlIGFuaW1hbCBpcyBtb3ZpbmciKTsKfQp9CnB1YmxpYyBjbGFzcyBDYXQgZXh0ZW5kcyBBbmltYWwgewovLyBUaGUgbW92ZSgpIG1ldGhvZCBjYW5ub3QgYmUgb3ZlcnJpZGRlbiBpbiB0aGlzIHN1YmNsYXNzCn0=
In the above example, the move() method in the Animal class is declared as final, which means that it cannot be overridden in the Cat class.
- Final Classes: If a class is declared as
final, it cannot be subclassed. Final classes can be useful when you want to prevent other developers from modifying the behavior of a class that is critical to the application's functionality.
For example:
public final class MathUtil {
// The MathUtil class cannot be subclassed
}
In the above example, the MathUtil class is declared as final, which means that it cannot be subclassed by other classes.
12. What are Java annotations?
Java annotations are a type of metadata that can be added to Java code to provide additional information about the code's behavior and usage. Annotations are represented by the @ symbol followed by an annotation name and optional parameters.
Annotations can be used to provide additional information to the compiler or runtime environment or to enable the generation of code or documentation. Annotations are commonly used for:
-
Providing additional information to the compiler or runtime environment: Annotations can be used to provide additional information to the compiler or runtime environment that is not specified in the code itself. For example, annotations can be used to specify the expected behavior of a method or class, or to specify how the code should be compiled or optimized.
-
Enabling the generation of code or documentation: Annotations can also be used to enable the generation of code or documentation based on the code itself. For example, annotations can be used to generate XML files or HTML documentation based on the code's annotations.
There are several built-in annotations in Java, such as @Override, which indicates that a method is intended to override a method in a superclass, and @Deprecated, which indicates that a method or class is no longer recommended for use.
Developers can also create their own custom annotations in Java by defining an annotation interface with the @interface keyword. Custom annotations can be used to provide additional information about the code or to enable the generation of custom documentation or code based on the annotation.

13. What is an exception when referring to Java?
In Java, an exception is an event that occurs during the execution of a program that disrupts the normal flow of instructions. When an exception occurs, the program stops executing its normal instructions and jumps to a special code block called an exception handler, which is responsible for handling the exception and taking appropriate action.
Exceptions in Java can be caused by a variety of factors, such as invalid input, network failures, or programming errors. Java has a built-in mechanism for handling exceptions, which consists of a try-catch block. The try block contains the code that may throw an exception, and the catch block contains the code that handles the exception.
When an exception is thrown in the try block, Java searches for a matching catch block that can handle the exception. If a matching catch block is found, the code in the catch block is executed, and the program can continue executing normally. If no matching catch block is found, the program terminates with an error message.
Java also provides a hierarchy of exception classes that can be used to handle different types of exceptions. The Throwable class is the superclass of all exceptions in Java, and it has two main subclasses: Exception and Error. Exception is used to handle expected exceptions that can be recovered from, while Error is used to handle unexpected exceptions that usually cannot be recovered from, such as system failures or out-of-memory errors.
Developers can also define their own custom exception classes by extending the Exception class or one of its subclasses. Custom exceptions can be used to handle specific types of exceptions that are not covered by the built-in exception classes.
14. What is an anonymous inner class?
In Java, an anonymous inner class is a local class that is defined and instantiated in a single expression, without specifying a name for the class. Anonymous inner classes are often used when a class is needed for a short, one-time use, and there is no need to create a named class for it.
Anonymous inner classes are typically used to implement abstract classes or interfaces that have only one or a few methods. For example, if you have an interface that defines a single method doSomething(), you can create an anonymous inner class to implement the interface and provide the implementation for the method:
interface MyInterface {
void doSomething();
}
MyInterface myObject = new MyInterface() {
public void doSomething() {
// implementation here
}
};
aW50ZXJmYWNlIE15SW50ZXJmYWNlIHsKdm9pZCBkb1NvbWV0aGluZygpOwp9CgpNeUludGVyZmFjZSBteU9iamVjdCA9IG5ldyBNeUludGVyZmFjZSgpIHsKcHVibGljIHZvaWQgZG9Tb21ldGhpbmcoKSB7Ci8vIGltcGxlbWVudGF0aW9uIGhlcmUKfQp9Ow==
In this example, the anonymous inner class implements the MyInterface interface and provides the implementation for the doSomething() method. The class is defined and instantiated in a single expression, without specifying a name for the class.
Anonymous inner classes can also be used to extend a class and override its methods. For example, if you have a class MyClass with a method doSomething(), you can create an anonymous inner class to override the method and provide a custom implementation:
MyClass myObject = new MyClass() {
public void doSomething() {
// custom implementation here
}
};
In this example, the anonymous inner class extends the MyClass class and overrides the doSomething() method to provide a custom implementation. Again, the class is defined and instantiated in a single expression, without specifying a name for the class.
15. What is a Java string pool?

In Java, a string pool is a special area of the heap memory where string literals are stored. When a Java program creates a string literal, the string is stored in the string pool instead of creating a new object each time the literal is used in the program.
The string pool is created and managed by the Java Virtual Machine (JVM). By using the string pool, the JVM can optimize memory usage and improve the performance of the program by reducing the number of objects that need to be created.
When a string is created in Java using the String class constructor or the new operator, a new object is created in memory, even if the string value is the same as an existing string in the string pool. However, when a string literal is used in the program, the JVM checks the string pool to see if an identical string already exists. If a matching string is found, the program uses the existing string object from the string pool instead of creating a new object.
For example, consider the following Java code:
String str1 = "Hello";
String str2 = "Hello";
String str3 = new String("Hello");
System.out.println(str1 == str2); // true
System.out.println(str1 == str3); // false
In this example, the string literals "Hello" are stored in the string pool, so str1 and str2 both refer to the same string object in the string pool. The string created using the new operator, str3, is a new object created in memory, even though it has the same value as the string literals in the pool.
By using the string pool, Java programs can improve their memory usage and performance, particularly when dealing with frequently used strings such as constants or configuration values. However, it's important to be aware of how strings are created and used in the program to avoid unintentionally creating new objects in memory.
16. What is the difference between a HashMap and a HashTable?
In Java, HashMap and HashTable are two classes that implement the Map interface and provide similar functionality for storing and retrieving key-value pairs. However, there are some important differences between the two classes:
-
Thread-safety:
HashTableis thread-safe, which means that it can be safely accessed by multiple threads at the same time without the risk of data corruption.HashMap, on the other hand, is not thread-safe and should not be used in multi-threaded environments unless proper synchronization is applied. -
Null keys and values:
HashTabledoes not allownullkeys or values. If you attempt to add anullkey or value to aHashTable, aNullPointerExceptionwill be thrown.HashMap, on the other hand, allowsnullkeys and values. -
Iteration:
HashTableis enumerated in a random order, whileHashMapis not guaranteed to be enumerated in any particular order. If you need to iterate over the elements of a map in a specific order, you should use aTreeMapinstead. -
Performance:
HashMapgenerally provides better performance thanHashTable. This is becauseHashTableis synchronized, which can create contention and reduce performance in multi-threaded environments.
In summary, HashMap is a non-synchronized implementation of the Map interface that allows null keys and values and provides better performance than HashTable, while HashTable is a thread-safe implementation of the Map interface that does not allow null keys or values but may provide slower performance due to synchronization overhead.
17. What are Java naming conventions?
In Java, naming conventions are a set of guidelines that are used to name variables, classes, methods, packages, and other program elements. Following these conventions helps to improve the readability and maintainability of Java code by making it easier for developers to understand the purpose and function of each program element.
Here are some common naming conventions in Java:
-
Class names should start with a capital letter and use camel case, with the first letter of each word capitalized. For example,
MyClassorMyClassName. -
Variable names should start with a lowercase letter and use camel case, with the first letter of each word capitalized except for the first word. For example,
myVariableormyVariableName. -
Constant names should be in all capital letters and use underscores to separate words. For example,
MAX_VALUEorMY_CONSTANT. -
Method names should start with a lowercase letter and use camel case, with the first letter of each word capitalized. For example,
myMethodormyMethodName. -
Package names should be in all lowercase letters and use dots to separate words. For example,
com.mycompany.mypackage. -
Interface names should start with a capital letter and use camel case, with the first letter of each word capitalized. For example,
MyInterfaceorMyInterfaceName. -
Enum types should be in all uppercase letters and use underscores to separate words. For example,
Color.REDorDayOfWeek.MONDAY.
By following these naming conventions, Java developers can create code that is easier to read, understand, and maintain.
18. What are the packages Java comes with?
Java comes with a set of standard packages that provide a wide range of functionality. Here are some of the main packages that Java comes with:
-
java.lang: Provides fundamental classes and interfaces such asObject,String,Exception,Thread, andMath. -
java.util: Provides classes for working with collections, such asArrayList,HashMap,HashSet,LinkedList, andTreeSet. -
java.io: Provides classes for input and output operations, such asFile,InputStream,OutputStream,Reader, andWriter. -
java.net: Provides classes for working with network resources, such asURL,URLConnection, andSocket. -
java.awt: Provides classes for building graphical user interfaces, such asFrame,Button,TextField, andLabel. -
java.swing: Provides more advanced classes for building graphical user interfaces, such asJFrame,JButton,JTextField, andJLabel. -
java.sql: Provides classes for working with databases, such asConnection,Statement, andResultSet. -
java.text: Provides classes for formatting and parsing text, such asDecimalFormat,SimpleDateFormat, andMessageFormat. -
java.security: Provides classes for implementing security features such as encryption, decryption, and digital signatures.
These packages and many others are included in the Java Standard Library and can be used to build a wide range of applications in Java.
19. What is a JIT compiler?
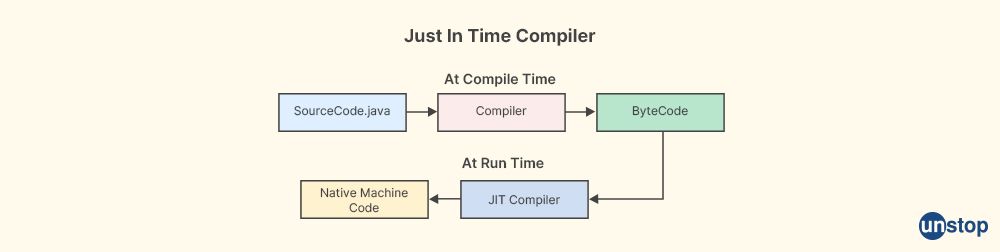
JIT stands for Just-In-Time, and a JIT compiler is a type of compiler that is used in Java to improve the performance of Java applications. In Java, the source code is first compiled into bytecode by the Java compiler, and then the bytecode is executed by the Java Virtual Machine (JVM). The JIT compiler is a component of the JVM that compiles the bytecode into machine code at runtime, just before it is executed.
The JIT compiler analyzes the bytecode and identifies parts of the code that are frequently executed, and then compiles those parts into native machine code. This makes the execution of those parts faster because the compiled machine code can be executed directly by the CPU, without the need for interpretation by the JVM.
One of the advantages of using a JIT compiler is that it can provide significant performance improvements for Java applications. Because the compiled machine code is executed directly by the CPU, it can be many times faster than interpreted bytecode. Additionally, the JIT compiler can optimize the compiled code based on the specific hardware and operating system on which the JVM is running, further improving performance.
Overall, the JIT compiler is an important component of the JVM that plays a critical role in making Java a high-performance language for building a wide range of applications.
21. What is AWT in Java?
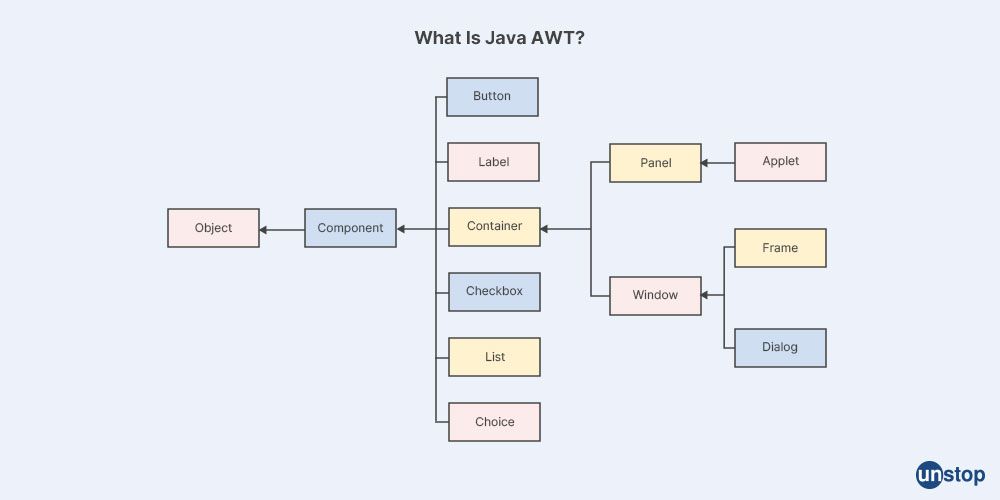
AWT stands for Abstract Window Toolkit, and it is a set of Java classes that provide a foundation for building graphical user interfaces (GUIs) in Java. AWT was one of the first GUI toolkits available for Java and was introduced with the release of Java Development Kit (JDK) 1.0 in 1996.
AWT provides a set of classes for building windows, buttons, text fields, labels, menus, and other GUI components. AWT components are lightweight and rely on the platform-specific windowing system to render themselves. This makes AWT applications more efficient than their heavyweight counterparts, but also means that AWT components may look different on different platforms.
AWT provides a range of layout managers that can be used to arrange GUI components on a window or panel. The layout managers automatically adjust the size and position of the components based on the size of the window or panel, making it easy to create responsive and flexible GUIs.
Despite its age, AWT is still used in some Java applications, particularly those that need to run on older versions of Java or on platforms where other GUI toolkits may not be available. However, many developers now prefer to use more modern GUI toolkits such as Swing or JavaFX, which provide a richer set of features and better cross-platform compatibility than AWT.
22. What is 'public static void main' in the Java programming language?
public static void main is a special method in the Java programming language that serves as the entry point for a Java program. It is a required method for every Java application, as it tells the Java Virtual Machine (JVM) where to start executing the program.
Here is a breakdown of the meaning of each keyword in public static void main:
public: This keyword indicates that the method can be accessed from any other class in the same package or from a different package.static: This keyword indicates that the method belongs to the class and not to an instance of the class. This means that the method can be called without having to create an object of the class.void: This keyword indicates that the method does not return any value.main: This is the name of the method. When the Java program is started, the JVM looks for this method to begin executing the program.
The main method must have a specific signature, which is: public static void main(String[] args). The args parameter is an array of String objects that can be used to pass command-line arguments to the Java program.
23. What is a constructor in C++?
In C++, a constructor is a special member function that is called automatically when an object of a class is created. It is used to initialize the data members of the class and perform any other required initialization tasks.
A constructor has the same name as the class and does not have a return type, not even void. It can have parameters, which are used to initialize the data members of the class.
Here's an example of a constructor for a class called Person:
class Person {
public:
// Constructor
Person(std::string name, int age) {
m_name = name;
m_age = age;
}
// Other member functions...
private:
std::string m_name;
int m_age;
};
Y2xhc3MgUGVyc29uIHsKcHVibGljOgovLyBDb25zdHJ1Y3RvcgpQZXJzb24oc3RkOjpzdHJpbmcgbmFtZSwgaW50IGFnZSkgewptX25hbWUgPSBuYW1lOwptX2FnZSA9IGFnZTsKfQoKLy8gT3RoZXIgbWVtYmVyIGZ1bmN0aW9ucy4uLgoKcHJpdmF0ZToKc3RkOjpzdHJpbmcgbV9uYW1lOwppbnQgbV9hZ2U7Cn07
In this example, the constructor takes two parameters, a std::string for the person's name and an int for their age. It then initializes the m_name and m_age data members of the Person class with these values.
Constructors can be overloaded to take different sets of parameters, just like regular member functions. A class can have multiple constructors with different parameter lists, allowing objects of the class to be initialized in different ways.
If a class does not define a constructor, a default constructor is provided by the compiler. The default constructor has an empty body and does not take any parameters.
In C++, there are several types of constructors that can be used to initialize objects of a class:
-
Default constructor: This constructor is called when an object is created without any arguments. It has no parameters and initializes the data members with default values. If a class does not define a constructor, the compiler provides a default constructor.
-
Parameterized constructor: This constructor takes one or more arguments, which are used to initialize the data members of the class.
-
Copy constructor: This constructor is used to create a new object as a copy of an existing object. It takes a reference to an object of the same class as its parameter and creates a new object with the same data members.
24. What is C++ exceptional handling?
Exception handling is the term given to the process of dealing with errors that occur during runtime in C++. We manage exceptions such that the normal flow of the program can be maintained despite the occurrence of runtime errors. The term 'exception' refers to a runtime event or object in the C++ programming language. Every single exception can be traced down to the std::exception class, which is the parent of all exceptions.
25. What is visual C++?
The programming language C++ has been standardized and the software package known as Visual C++ is an implementation of the C++ standard. Using Visual C++, it is possible to develop programs that are portable using the C++ programming language. However, it is also possible to add extensions that are exclusive to Microsoft, which eliminates portability but increases efficiency.
Visual C++ is an integrated development environment (IDE) and a set of programming tools and libraries for developing C++ applications on the Microsoft Windows platform. It is a part of the Visual Studio suite of development tools from Microsoft.
Visual C++ provides a range of features and tools for C++ development, including a code editor, a compiler, a debugger, and a graphical user interface designer. It also includes a large set of libraries and frameworks for building Windows applications, such as the Windows API, the .NET Framework, and the Microsoft Foundation Classes (MFC).
Visual C++ supports several programming paradigms, including object-oriented programming, generic programming, and procedural programming. It also supports the latest C++ language standards, including C++11, C++14, C++17, and C++20.
Visual C++ is widely used for developing a wide range of applications, such as desktop applications, games, drivers, and system software, as well as for building libraries and frameworks for other developers to use. It is a powerful and versatile tool that allows developers to create high-performance and feature-rich applications for the Windows platform.
26. What is a destructor?
In C++, a destructor is a special member function that is called automatically when an object of a class is destroyed or goes out of scope. It is used to perform any required cleanup tasks, such as releasing resources that were acquired during the lifetime of the object.
A destructor has the same name as the class, preceded by a tilde (~), and does not take any parameters. It is invoked automatically by the compiler when the object is destroyed or goes out of scope.
Here's an example of a destructor for a class called Person:
class Person {
public:
// Constructor
Person(std::string name, int age) {
m_name = name;
m_age = age;
}
// Destructor
~Person() {
std::cout << "Person object destroyed" << std::endl;
}
// Other member functions...
private:
std::string m_name;
int m_age;
};
Y2xhc3MgUGVyc29uIHsKcHVibGljOgovLyBDb25zdHJ1Y3RvcgpQZXJzb24oc3RkOjpzdHJpbmcgbmFtZSwgaW50IGFnZSkgewptX25hbWUgPSBuYW1lOwptX2FnZSA9IGFnZTsKfQoKLy8gRGVzdHJ1Y3Rvcgp+UGVyc29uKCkgewpzdGQ6OmNvdXQgPDwgIlBlcnNvbiBvYmplY3QgZGVzdHJveWVkIiA8PCBzdGQ6OmVuZGw7Cn0KCi8vIE90aGVyIG1lbWJlciBmdW5jdGlvbnMuLi4KCnByaXZhdGU6CnN0ZDo6c3RyaW5nIG1fbmFtZTsKaW50IG1fYWdlOwp9Ow==
In this example, the destructor simply prints a message to the console indicating that the Person object has been destroyed.
Destructors can be useful for releasing resources that were allocated during the lifetime of an object, such as memory, file handles, or network connections. They can also be used to perform other cleanup tasks, such as closing database connections or releasing locks.
If a class does not define a destructor, the compiler provides a default destructor that has an empty body and does not perform any cleanup tasks. However, if a class owns resources that need to be released when the object is destroyed, it is usually a good practice to define a destructor explicitly.
27. What is the default constructor?
In C++, a default constructor is a special constructor that is automatically generated by the compiler if a class does not have any user-defined constructors. It is a constructor that takes no parameters and initializes the data members of the class to their default values.
The default constructor is used to create objects of the class when no arguments are specified. For example, if you declare an object of a class that has no user-defined constructors, the compiler will automatically generate a default constructor for you:
class MyClass {
public:
int m_value;
};
int main() {
MyClass obj; // Calls the default constructor
obj.m_value = 42;
return 0;
}
Y2xhc3MgTXlDbGFzcyB7CnB1YmxpYzoKaW50IG1fdmFsdWU7Cn07CgppbnQgbWFpbigpIHsKTXlDbGFzcyBvYmo7IC8vIENhbGxzIHRoZSBkZWZhdWx0IGNvbnN0cnVjdG9yCm9iai5tX3ZhbHVlID0gNDI7CnJldHVybiAwOwp9
In this example, the class MyClass has no user-defined constructors, so the compiler generates a default constructor for it. When the obj object is declared in main(), the default constructor is called automatically to initialize the m_value data member to its default value of 0.
If a class has any user-defined constructors, the compiler will not generate a default constructor unless you explicitly define one yourself. If you define a constructor with parameters, but you still want to have a default constructor, you can provide a default value for the parameters to create a default constructor:
class MyClass {
public:
int m_value;
MyClass(int value = 0) {
m_value = value;
}
};
int main() {
MyClass obj1; // Calls the default constructor with value = 0
MyClass obj2(42); // Calls the constructor with value = 42
return 0;
}
Y2xhc3MgTXlDbGFzcyB7CnB1YmxpYzoKaW50IG1fdmFsdWU7Ck15Q2xhc3MoaW50IHZhbHVlID0gMCkgewptX3ZhbHVlID0gdmFsdWU7Cn0KfTsKCmludCBtYWluKCkgewpNeUNsYXNzIG9iajE7IC8vIENhbGxzIHRoZSBkZWZhdWx0IGNvbnN0cnVjdG9yIHdpdGggdmFsdWUgPSAwCk15Q2xhc3Mgb2JqMig0Mik7IC8vIENhbGxzIHRoZSBjb25zdHJ1Y3RvciB3aXRoIHZhbHVlID0gNDIKcmV0dXJuIDA7Cn0=
In this example, the MyClass constructor has a default value of 0 for its value parameter, which allows it to act as a default constructor when no arguments are provided.
28. What is the Reference variable?
In C++, a reference variable is an alias for another variable. It provides an alternative way to access the same memory location as the original variable, allowing you to refer to the same value using different names.
A reference variable is declared using the & operator, which indicates that the variable is a reference to another variable. For example:
int value = 42;
int& ref = value; // ref is a reference to value
In this example, ref is a reference variable that refers to the value variable. Any changes made to ref will also affect value, since they both refer to the same memory location.
Reference variables are useful in many situations, such as when you want to pass a variable to a function by reference, allowing the function to modify the original value. They are also useful for avoiding unnecessary copies of large objects, since passing a reference is more efficient than passing a copy.
It's important to note that a reference variable must be initialized at the time of declaration, and it cannot be changed to refer to a different variable later. Once a reference is established, it always refers to the same variable. Additionally, reference variables cannot be null, and they cannot refer to a temporary object that has been destroyed.
29. What is upcasting in C++?
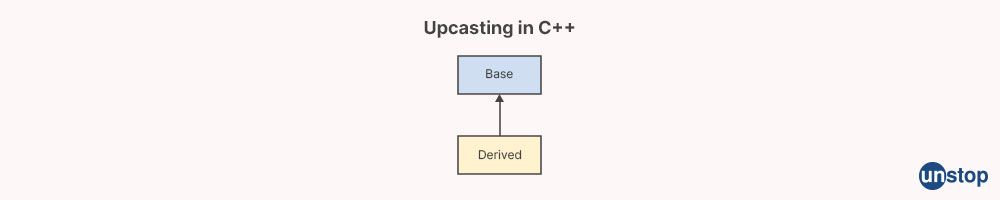
In C++, upcasting is the process of converting a derived class pointer or reference to a pointer or reference of its base class. It is a type of implicit conversion that allows you to treat an object of a derived class as if it were an object of its base class.
Here's an example:
class Base {
public:
void foo() {
std::cout << "Base::foo()" << std::endl;
}
};
class Derived : public Base {
public:
void bar() {
std::cout << "Derived::bar()" << std::endl;
}
};
int main() {
Derived d;
Base& b = d; // Upcasting
b.foo(); // Calls Base::foo()
return 0;
}
Y2xhc3MgQmFzZSB7CnB1YmxpYzoKdm9pZCBmb28oKSB7CnN0ZDo6Y291dCA8PCAiQmFzZTo6Zm9vKCkiIDw8IHN0ZDo6ZW5kbDsKfQp9OwoKY2xhc3MgRGVyaXZlZCA6IHB1YmxpYyBCYXNlIHsKcHVibGljOgp2b2lkIGJhcigpIHsKc3RkOjpjb3V0IDw8ICJEZXJpdmVkOjpiYXIoKSIgPDwgc3RkOjplbmRsOwp9Cn07CgppbnQgbWFpbigpIHsKRGVyaXZlZCBkOwpCYXNlJiBiID0gZDsgLy8gVXBjYXN0aW5nCmIuZm9vKCk7IC8vIENhbGxzIEJhc2U6OmZvbygpCnJldHVybiAwOwp9
In this example, we have a Base class and a Derived class that inherits from Base. The Derived class has an additional member function called bar(). In the main() function, we create an object of Derived and then upcast it to a reference of Base. We can then call the foo() function on the Base reference, even though it refers to an object of Derived. This is because Derived is a subclass of Base, and therefore inherits all of its member functions.
Upcasting is useful for treating objects of derived classes as if they were objects of their base classes, allowing you to write more general and reusable code. It is often used in polymorphism, where you want to write a function that can operate on objects of different derived classes using a base class interface.
30. What is session management?
Session management is the process of keeping track of a user's interactions with a web application during a single visit or "session" to the application. A session typically starts when a user logs in or visits a website, and ends when the user logs out or closes their browser.
Session management is important in web development because it allows the application to maintain state information about a user's actions and preferences across multiple requests. This information can be used to customize the user experience, personalize content, and provide a more seamless interaction with the application.
To implement session management, web developers typically use a combination of server-side and client-side technologies. Server-side technologies such as cookies, sessions, and tokens are used to store session data on the server, while client-side technologies such as HTML5 web storage, session storage, and local storage are used to store session data on the user's device.
Some common techniques used in session management include:
-
Session IDs: A unique identifier that is assigned to a user's session and used to associate the user's requests with their session data on the server.
-
Cookies: Small text files that are stored on the user's device and used to store session information such as the session ID or user preferences.
-
Sessions: A server-side mechanism for storing session data in memory or on disk, associated with a unique session ID.
-
Tokens: An encrypted string that is used to authenticate and authorize a user's requests during a session, often used in RESTful web services.
Proper session management is important for maintaining the security and privacy of user data, as well as preventing unauthorized access to sensitive information. It is therefore critical for web developers to use secure session management techniques and follow best practices for session management.
31. What is serialization?
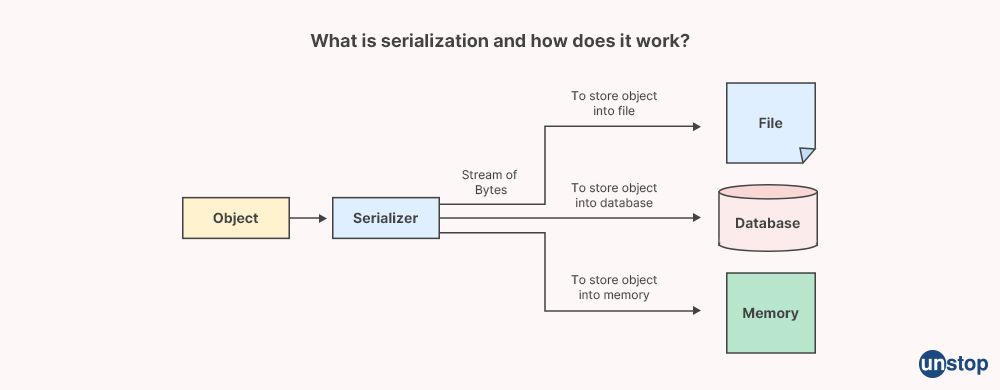
Serialization is the process of converting an object into a format that can be easily stored, transmitted, or reconstructed at a later time. In computer science, serialization is often used in networking and file I/O operations, where data needs to be transmitted or stored in a way that can be easily read and reconstructed.
In serialization, an object is converted into a sequence of bytes that represent the object's state. The resulting byte stream can then be transmitted over a network or stored in a file, and later deserialized to recreate the original object.
Serialization can be used for a variety of purposes, such as:
-
Transferring data over a network: Serialized objects can be transmitted over a network and reconstructed on the receiving end, allowing data to be transferred between different machines or applications.
-
Storing data in a database: Serialized objects can be stored in a database as binary data, allowing complex data structures to be stored and retrieved easily.
-
Saving program state: Serialized objects can be used to save the state of a program to disk, allowing the program to be resumed at a later time.
Serialization can be implemented using various techniques and formats, such as binary serialization, XML serialization, and JSON serialization. Some programming languages, such as Java and C#, have built-in support for serialization, while others require the use of third-party libraries or custom serialization code.
It's important to note that serialization can introduce security risks, as attackers may be able to manipulate the serialized data to perform malicious actions. For this reason, it's important to use secure serialization techniques and validate serialized data before deserializing it.
32. What is synchronization?
In computer science, synchronization refers to the coordination of multiple processes or threads to ensure that they operate correctly and avoid conflicts or data race conditions. Synchronization is important in concurrent programming, where multiple processes or threads share resources such as memory or I/O devices.
There are various techniques for synchronization, including:
-
Locks and mutexes: Locks and mutexes are used to ensure that only one process or thread can access a shared resource at a time. A lock is a synchronization mechanism that is used to protect a shared resource from being accessed simultaneously by multiple processes or threads. A mutex is a type of lock that allows multiple processes or threads to take turns accessing a shared resource.
-
Semaphores: Semaphores are a synchronization mechanism that are used to control access to a shared resource. A semaphore is a variable that is used to signal between processes or threads to indicate that a shared resource is available or unavailable.
-
Monitors: Monitors are a higher-level synchronization mechanism that provides a way to synchronize the access to a shared resource. A monitor is a programming construct that allows a process or thread to lock and unlock a shared resource, and to wait for a specific condition to be true before continuing.
-
Atomic operations: Atomic operations are operations that are executed as a single, indivisible unit, ensuring that no other process or thread can access the data being modified. Atomic operations are commonly used to implement synchronization for shared variables in concurrent programming.
Synchronization is important for ensuring the correctness and consistency of concurrent programs along with maximizing CPU efficiency. Without proper synchronization, multiple processes or threads can access shared resources simultaneously, leading to race conditions, deadlocks, and other synchronization-related issues. Proper use of synchronization techniques can improve the performance, scalability, and reliability of concurrent programs.
33. What is servlet in Java?
In Java, a servlet is a Java class that is used to extend the capabilities of a web server and provide dynamic web content. Servlets are server-side components that run on the web server, allowing them to interact with the HTTP protocol and generate dynamic content based on client requests.
When a client sends an HTTP request to the web server, the server passes the request to the appropriate servlet based on the URL specified in the request. The servlet processes the request, generates the response, and sends it back to the client in the form of an HTTP response.
Servlets can be used for a variety of purposes, such as:
-
Generating dynamic HTML pages: Servlets can be used to generate HTML pages dynamically based on data from a database or other source.
-
Processing form data: Servlets can be used to process data submitted by clients through HTML forms.
-
Handling file uploads: Servlets can be used to handle file uploads from clients.
-
Implementing RESTful web services: Servlets can be used to implement RESTful web services that expose functionality to other web applications or clients.
Servlets are typically deployed on a Java-enabled web server, such as Apache Tomcat or Jetty. They are part of the Java Servlet API, which provides a set of interfaces and classes that can be used to create servlets and manage their lifecycle. Servlets are often used in conjunction with JavaServer Pages (JSP), which are used to generate dynamic HTML pages using Java code.
34. What is a namespace in C++?
In C++, the idea of a namespace was first presented, whereas the C programming language lacked this feature. In most cases, resolving a conflict between two variables that have names that are too similar requires the utilization of a namespace. With the assistance of namespace, we can declare multiple identifiers or variables that share the same name for various values and different scopes and then access them as per our specific requirements.
35. What is the default parameter?
In programming, a default parameter is a parameter in a function or method that has a default value assigned to it. When a function or method is called, the default parameter is used if no value is provided for that parameter.
Here is an example in Python:
def greet(name="world"):
print("Hello, " + name + "!")
# Call the function with no argument, using the default value
greet()
# Call the function with an argument, overriding the default value
greet("Alice")
ZGVmIGdyZWV0KG5hbWU9IndvcmxkIik6DQpwcmludCgiSGVsbG8sICIgKyBuYW1lICsgIiEiKQ0KDQojIENhbGwgdGhlIGZ1bmN0aW9uIHdpdGggbm8gYXJndW1lbnQsIHVzaW5nIHRoZSBkZWZhdWx0IHZhbHVlDQpncmVldCgpDQoNCiMgQ2FsbCB0aGUgZnVuY3Rpb24gd2l0aCBhbiBhcmd1bWVudCwgb3ZlcnJpZGluZyB0aGUgZGVmYXVsdCB2YWx1ZQ0KZ3JlZXQoIkFsaWNlIik=
In this example, the greet() function has a default parameter name with a default value of "world". When the function is called with no argument, the default value is used. When the function is called with an argument, the argument value is used instead of the default value.
Default parameters can be useful for providing a default behavior or value for a function or method, while allowing callers to override the default if necessary. They can also simplify function calls by reducing the number of required parameters. Default parameters are supported in many programming languages, including Python, JavaScript, C++, and Java.
36. What is inline function when referring to C++?
In C++, an inline function is a function that is expanded by the compiler at the point where it is called, rather than being executed as a separate function call. Inline functions are used to improve the performance of code by reducing the overhead of function calls and can be especially useful for small, frequently-used functions.
When a function is declared as inline, the compiler replaces each call to the function with the actual body of the function, similar to a macro. This can eliminate the overhead of the function call, such as stack manipulation and parameter passing, resulting in faster code execution.
Here is an example of an inline function in C++:
inline int add(int a, int b) {
return a + b;
}
int main() {
int x = 3, y = 4;
int z = add(x, y); // The call to add() is replaced by the expression "x + y"
return 0;
}
aW5saW5lIGludCBhZGQoaW50IGEsIGludCBiKSB7CnJldHVybiBhICsgYjsKfQoKaW50IG1haW4oKSB7CmludCB4ID0gMywgeSA9IDQ7CmludCB6ID0gYWRkKHgsIHkpOyAvLyBUaGUgY2FsbCB0byBhZGQoKSBpcyByZXBsYWNlZCBieSB0aGUgZXhwcmVzc2lvbiAieCArIHkiCnJldHVybiAwOwp9
In this example, the add() function is declared as inline, and the call to add() in the main() function is replaced with the expression x + y by the compiler.
It is important to note that the use of inline functions is a trade-off between code size and performance. Inlining too many functions can increase the size of the code and decrease performance due to memory and cache considerations. Therefore, inline functions should be used judiciously and only for small, frequently-used functions.
37. What is the distinction between a class and an object?
In object-oriented programming, a class is a blueprint or template for creating objects, while an object is an instance of a class.
A class defines the characteristics and behavior of a set of objects that share common properties, such as attributes and methods. Attributes are the data members of a class that represent its state, while methods are the functions that define its behavior. A class is defined once and can be used to create multiple objects, each with its own set of attributes and state.
An object is an instance of a class that has its own set of attributes and state. When an object is created, memory is allocated for its data members and its constructor is called to initialize its state. Objects can also have their own unique behaviors, which are defined by the methods of their class.
Here is an example in Python:
class Car:
# Class attribute
num_wheels = 4
# Constructor
def __init__(self, make, model):
# Instance attributes
self.make = make
self.model = model
# Instance method
def drive(self):
print(f"The {self.make} {self.model} is driving...")
# Create two objects of the Car class
car1 = Car("Toyota", "Corolla")
car2 = Car("Honda", "Civic")
# Call the drive() method of each object
car1.drive()
car2.drive()
Y2xhc3MgQ2FyOg0KIyBDbGFzcyBhdHRyaWJ1dGUNCm51bV93aGVlbHMgPSA0DQoNCiMgQ29uc3RydWN0b3INCmRlZiBfX2luaXRfXyhzZWxmLCBtYWtlLCBtb2RlbCk6DQojIEluc3RhbmNlIGF0dHJpYnV0ZXMNCnNlbGYubWFrZSA9IG1ha2UNCnNlbGYubW9kZWwgPSBtb2RlbA0KDQojIEluc3RhbmNlIG1ldGhvZA0KZGVmIGRyaXZlKHNlbGYpOg0KcHJpbnQoZiJUaGUge3NlbGYubWFrZX0ge3NlbGYubW9kZWx9IGlzIGRyaXZpbmcuLi4iKQ0KDQojIENyZWF0ZSB0d28gb2JqZWN0cyBvZiB0aGUgQ2FyIGNsYXNzDQpjYXIxID0gQ2FyKCJUb3lvdGEiLCAiQ29yb2xsYSIpDQpjYXIyID0gQ2FyKCJIb25kYSIsICJDaXZpYyIpDQoNCiMgQ2FsbCB0aGUgZHJpdmUoKSBtZXRob2Qgb2YgZWFjaCBvYmplY3QNCmNhcjEuZHJpdmUoKQ0KY2FyMi5kcml2ZSgp
In this example, Car is a class that represents a type of object that has a make and model attribute, and a drive() method. car1 and car2 are objects of the Car class, each with their own unique make and model attributes. When the drive() method is called on each object, it prints a message with the object's make and model attributes.
In summary, a class is a blueprint or template for creating objects, while an object is an instance of a class that has its own unique set of attributes and state.
38. Does a derived class inherit or doesn’t inherit?
In object-oriented programming, a derived class inherits properties and behaviors from its base class. In other words, a derived class extends the functionality of its base class by adding its own unique properties and behaviors, while still retaining the properties and behaviors of its base class.
When a derived class is created, it automatically includes all of the properties and behaviors of its base class. This includes public and protected data members and member functions. However, private data members and member functions of the base class are not directly accessible by the derived class.
The derived class can also add its own new properties and behaviors that are not present in its base class. These can include new data members and member functions, as well as overriding or overloading existing member functions of the base class.
Here is an example in C++:
class Animal {
public:
void move() {
cout << "This animal moves" << endl;
}
};
class Dog : public Animal {
public:
void bark() {
cout << "This dog barks" << endl;
}
};
int main() {
Dog myDog;
myDog.move(); // This calls the move() function of the base class
myDog.bark(); // This calls the bark() function of the derived class
return 0;
}
Y2xhc3MgQW5pbWFsIHsKcHVibGljOgp2b2lkIG1vdmUoKSB7CmNvdXQgPDwgIlRoaXMgYW5pbWFsIG1vdmVzIiA8PCBlbmRsOwp9Cn07CgpjbGFzcyBEb2cgOiBwdWJsaWMgQW5pbWFsIHsKcHVibGljOgp2b2lkIGJhcmsoKSB7CmNvdXQgPDwgIlRoaXMgZG9nIGJhcmtzIiA8PCBlbmRsOwp9Cn07CgppbnQgbWFpbigpIHsKRG9nIG15RG9nOwpteURvZy5tb3ZlKCk7IC8vIFRoaXMgY2FsbHMgdGhlIG1vdmUoKSBmdW5jdGlvbiBvZiB0aGUgYmFzZSBjbGFzcwpteURvZy5iYXJrKCk7IC8vIFRoaXMgY2FsbHMgdGhlIGJhcmsoKSBmdW5jdGlvbiBvZiB0aGUgZGVyaXZlZCBjbGFzcwpyZXR1cm4gMDsKfQ==
In this example, Animal is the base class and Dog is the derived class. The Dog class inherits the move() function from the Animal class, and adds its own bark() function. In the main() function, an object of the Dog class is created and both the inherited move() function and the new bark() function are called.
In summary, a derived class inherits properties and behaviors from its base class, and can add its own unique properties and behaviors as well.
39. Define the block scope variable.
In programming, a block scope variable is a variable that is declared within a block of code and is only accessible within that block, and any nested blocks within it.
A block is a section of code that is delimited by a pair of curly braces { }. For example, in C++, a block can be a function, a loop, or an if statement.
When a variable is declared within a block, it is only visible within that block and any nested blocks within it. Once the block is exited, the variable is destroyed and cannot be accessed anymore.
Here is an example in C++:
#include
using namespace std;
int main() {
int x = 5; // This is a variable with function scope
if (x > 3) {
int y = 10; // This is a block scope variable
cout << "x = " << x << endl; // This is allowed, since x is in function scope
cout << "y = " << y << endl; // This is allowed, since y is in block scope
}
cout << "x = " << x << endl; // This is allowed, since x is in function scope
//cout << "y = " << y << endl; // This is NOT allowed, since y is out of scope
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgp1c2luZyBuYW1lc3BhY2Ugc3RkOwoKaW50IG1haW4oKSB7CmludCB4ID0gNTsgLy8gVGhpcyBpcyBhIHZhcmlhYmxlIHdpdGggZnVuY3Rpb24gc2NvcGUKCmlmICh4ID4gMykgewppbnQgeSA9IDEwOyAvLyBUaGlzIGlzIGEgYmxvY2sgc2NvcGUgdmFyaWFibGUKCmNvdXQgPDwgInggPSAiIDw8IHggPDwgZW5kbDsgLy8gVGhpcyBpcyBhbGxvd2VkLCBzaW5jZSB4IGlzIGluIGZ1bmN0aW9uIHNjb3BlCmNvdXQgPDwgInkgPSAiIDw8IHkgPDwgZW5kbDsgLy8gVGhpcyBpcyBhbGxvd2VkLCBzaW5jZSB5IGlzIGluIGJsb2NrIHNjb3BlCn0KCmNvdXQgPDwgInggPSAiIDw8IHggPDwgZW5kbDsgLy8gVGhpcyBpcyBhbGxvd2VkLCBzaW5jZSB4IGlzIGluIGZ1bmN0aW9uIHNjb3BlCi8vY291dCA8PCAieSA9ICIgPDwgeSA8PCBlbmRsOyAvLyBUaGlzIGlzIE5PVCBhbGxvd2VkLCBzaW5jZSB5IGlzIG91dCBvZiBzY29wZQpyZXR1cm4gMDsKfQ==
In this example, x is a variable with function scope, which means it is accessible throughout the entire main() function. y is a variable with block scope, which means it is only accessible within the if statement block where it is declared. If we try to access y outside of the block, we will get a compiler error.
In summary, a block scope variable is a variable that is declared within a block of code and is only accessible within that block and any nested blocks within it.
40. What are void pointers?

In C and C++, a void pointer is a pointer that has no specific data type associated with it. A void pointer can point to any type of data, but it cannot be directly dereferenced because the compiler does not know the size or layout of the pointed-to data.
The syntax for a void pointer is:
void* ptr;
Here, ptr is a void pointer that can point to any type of data. To assign a value to a void pointer, you need to explicitly cast it to the appropriate type. For example:
int x = 10;
void* ptr = (void*) &x; // casting to void pointer
In this example, ptr is a void pointer that points to the address of x. The & operator gives the address of x, and the (void*) cast converts it to a void pointer.
41. What is polymorphism when referring to C++?
Polymorphism is one of the fundamental concepts in object-oriented programming (OOP) that allows objects of different classes to be treated as if they were objects of the same class. In C++, there are two types of polymorphism: compile-time polymorphism and run-time polymorphism.
Compile-time polymorphism is achieved through function overloading and operator overloading. In function overloading, multiple functions can have the same name but different parameters. The correct function to call is determined at compile time-based on the type and number of arguments passed to it. In operator overloading, operators such as +, -, *, /, and = can be overloaded to work with objects of user-defined classes.
Run-time polymorphism is achieved through virtual functions and inheritance. In inheritance, a derived class can inherit properties and methods from a base class. Polymorphism allows a derived class to override the virtual functions of the base class and provide its own implementation. At runtime, the correct function to call is determined based on the type of the object, not the type of the pointer or reference used to access it. This allows objects of different derived classes to be treated as if they were objects of the same base class.
Here's an example of run-time polymorphism in C++:
#include
using namespace std;
class Shape {
public:
virtual void draw() {
cout << "Drawing a shape." << endl;
}
};
class Circle : public Shape {
public:
void draw() {
cout << "Drawing a circle." << endl;
}
};
class Square : public Shape {
public:
void draw() {
cout << "Drawing a square." << endl;
}
};
int main() {
Shape* s1 = new Circle();
Shape* s2 = new Square();
s1->draw();
s2->draw();
delete s1;
delete s2;
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgp1c2luZyBuYW1lc3BhY2Ugc3RkOwoKY2xhc3MgU2hhcGUgewpwdWJsaWM6CnZpcnR1YWwgdm9pZCBkcmF3KCkgewpjb3V0IDw8ICJEcmF3aW5nIGEgc2hhcGUuIiA8PCBlbmRsOwp9Cn07CgpjbGFzcyBDaXJjbGUgOiBwdWJsaWMgU2hhcGUgewpwdWJsaWM6CnZvaWQgZHJhdygpIHsKY291dCA8PCAiRHJhd2luZyBhIGNpcmNsZS4iIDw8IGVuZGw7Cn0KfTsKCmNsYXNzIFNxdWFyZSA6IHB1YmxpYyBTaGFwZSB7CnB1YmxpYzoKdm9pZCBkcmF3KCkgewpjb3V0IDw8ICJEcmF3aW5nIGEgc3F1YXJlLiIgPDwgZW5kbDsKfQp9OwoKaW50IG1haW4oKSB7ClNoYXBlKiBzMSA9IG5ldyBDaXJjbGUoKTsKU2hhcGUqIHMyID0gbmV3IFNxdWFyZSgpOwpzMS0+ZHJhdygpOwpzMi0+ZHJhdygpOwpkZWxldGUgczE7CmRlbGV0ZSBzMjsKcmV0dXJuIDA7Cn0=
In this example, Shape is a base class with a virtual function draw(). Circle and Square are derived classes that override the draw() function. In the main function, two objects s1 and s2 are created, one of type Circle and one of type Square, but both are declared as type Shape*. When the draw() function is called on each object, the correct version of the function is called based on the actual type of the object, not the type of the pointer used to access it. This demonstrates the power of polymorphism, which allows objects of different types to be treated as if they were objects of the same type, and allows for more flexible and reusable code.
42. What is a red-black tree in context to data structures?
A red-black tree is a type of self-balancing binary search tree, where each node has an extra bit of information called a color, which can be either red or black. The color of each node is used to enforce certain properties that help maintain a balanced tree. These trees have a similar memory footprint as a standard (uncolored) binary search tree because each node only needs one bit of memory to store the color information.
The key properties of a red-black tree are:
- Every node is either red or black.
- The root node is black.
- Every leaf node (i.e., NULL node) is black.
- If a node is red, then both its children are black.
- For each node, all simple paths from the node to descendant leaves contain the same number of black nodes (this is called the "black height" of the node).
By enforcing these properties, a red-black tree guarantees that the longest path from the root to a leaf is no more than twice as long as the shortest path from the root to a leaf, which ensures a balanced tree and a worst-case time complexity of O(log n) for operations such as search, insertion, and deletion.
Red-black trees are commonly used in computer science for efficient storage and retrieval of large data sets, such as in databases and file systems.
43. Explain hashCode() and equals() in Java.
In Java, hashCode() and equals() are two methods that are used to compare objects and determine if they are equal or not.
hashCode(): The hash Code () method in Java returns an integer value that represents the unique identifier of an object. This method is used to provide a hash value to an object that can be used in hash-based data structures like HashMap, HashSet, etc.It returns an integer representation of the object's memory reference. The hash Code () method is inherited from the Object class, and it returns a unique positive integer value for each object based on the memory address of the object. However, if two objects are equal, their hashCode() method should return the same integer value to the memory reference.
equals(): The equals() method in Java is used to compare two objects to check if they are equal or not. This method is used to check the actual contents of the objects rather than their memory addresses. The equals() method is also inherited from the Object class, and it checks if two objects are equal based on their values. If the equals() method returns true, it means that the two objects are equal, and if it returns false, it means that the two objects are not equal.
When implementing the equals() method, it is important to follow some guidelines, such as:
- Reflexive: An object should be equal to itself.
- Symmetric: If A is equal to B, then B should be equal to A.
- Transitive: If A is equal to B and B is equal to C, then A should be equal to C.
- Consistent: The equals() method should return the same result every time it is called for the same object.
- Null check: The equals() method should return false if the argument is null.
The hashCode() and equals() methods are closely related, as the hashCode() method is used to optimize the performance of hash-based data structures like the hash table, while the equals() method is used to compare the actual contents of the objects. It is important to override both methods properly when creating custom classes in Java to ensure the correct behavior of hash-based data structures and comparison operations.
44. What is a garbage collector?
A garbage collector is a component of a programming language's runtime system that automatically manages the memory used by a program. The garbage collector is responsible for identifying and freeing memory that is no longer being used by the program. This eliminates the need for developers to manually manage memory allocation and deallocation, which can be error-prone and time-consuming.
In most modern programming languages, such as Java and C#, a garbage collector runs periodically in the background, scanning the program's memory space to identify objects that are no longer being used. When the garbage collector identifies such an object, it marks the memory space used by the object as eligible for reclaiming. The garbage collector then deallocates the memory and makes it available for future use.
45. Given a positive integer n and a string s consisting only of letters D or I, you have to find any permutation of the first n positive integer that satisfies the given input string.
This problem can be solved using a simple approach.
First, we create an array of size n and initialize it with the values from 1 to n in ascending order.
Then, we iterate through the input string s and for each character:
- If it is 'D', we reverse the sub-array from the current index to the end of the array.
- If it is 'I', we do nothing.
Finally, we return the resulting array as the permutation.
Here's the code for the same:
vector findPermutation(int n, string s) {
vector result(n);
for (int i = 0; i < n; i++) {
result[i] = i + 1;
}
for (int i = 0; i < s.size(); i++) {
if (s[i] == 'D') {
reverse(result.begin() + i, result.end());
}
}
return result;
}
dmVjdG9yPGludD4gZmluZFBlcm11dGF0aW9uKGludCBuLCBzdHJpbmcgcykgewp2ZWN0b3I8aW50PiByZXN1bHQobik7CmZvciAoaW50IGkgPSAwOyBpIDwgbjsgaSsrKSB7CnJlc3VsdFtpXSA9IGkgKyAxOwp9CmZvciAoaW50IGkgPSAwOyBpIDwgcy5zaXplKCk7IGkrKykgewppZiAoc1tpXSA9PSAnRCcpIHsKcmV2ZXJzZShyZXN1bHQuYmVnaW4oKSArIGksIHJlc3VsdC5lbmQoKSk7Cn0KfQpyZXR1cm4gcmVzdWx0Owp9
This approach has a time complexity of O(n^2) due to the reverse operation in the loop, but it can be optimized to O(n) using a two-pointer approach to find the sub-array to be reversed.
Behavioral Interview Questions for Goldman Sachs HR Interview
For Goldman Sachs HR Interview round, the candidate must be prepared with general introduction-based questions as well as behavioral interview questions. One important point to remember while answering these questions is to maintain a positive outlook in the responses.
Check out some HR and Behavioral Interview Questions that can be asked during the Goldman Sachs interview.
- What is your approach to teamwork and collective work?
- Why do you want to join Goldman Sachs?
- Where do you see yourself in the next five years?
- What is your biggest weakness?
- Are you currently considering any other banks for job interviews?
- Are you open to relocation?
- Will you be able to handle stressful situations at work?
- What are your thoughts on productivity at work?
Goldman Sachs is consistently ranked as one of the best financial institutions to be a part of. If you want to join this firm, good preparation is a must. We hope the above article would help you to revise all the important technical topics and amp up your preparation for the Goldman Sachs interview. All the best!

You may also like to read:
Login to continue reading
And access exclusive content, personalized recommendations, and career-boosting opportunities.
Don't have an account? Sign up
Never miss an
Update

Featured Opportunities
Top-Rated Practice by Students





Subscribe
to our newsletter
Blogs you need to hog!

This Is My First Hackathon, How Should I Prepare? (Tips & Hackathon Questions Inside)
D2C Admin

10 Best C++ IDEs That Developers Mention The Most!
D2C Admin

Advantages and Disadvantages of Cloud Computing That You Should Know!
D2C Admin

Is IoT Valuable? Advantages And Disadvantages Of IoT Explained
Shivangi Vatsal
Comments
Add comment