
Asian Paints Alchemy 2026
Company Interview Questions for Freshers
- TCS Technical Interview Questions & Answers
- TCS Managerial Interview Questions & Answers
- TCS HR Interview Questions & Answers
- Overview of Cognizant Recruitment Process
- Cognizant Interview Questions: Technical
- Cognizant Interview Questions: HR Round
- Overview of Wipro Technologies Recruitment Rounds
- Wipro Interview Questions
- Technical Round
- HR Round
- Online Assessment Sample Questions
- Frequently Asked Questions
- Overview of Google Recruitment Process
- Google Interview Questions: Technical
- Google Interview Questions: HR round
- Interview Preparation Tips
- About Google
- Deloitte Technical Interview Questions
- Deloitte HR Interview Questions
- Deloitte Recruitment Process
- Technical Interview Questions and Answers
- Level 1 difficulty
- Level 2 difficulty
- Level 3 difficulty
- Behavioral Questions
- Eligibility Criteria for Mindtree Recruitment
- Mindtree Recruitment Process: Rounds Overview
- Skills required to crack Mindtree interview rounds
- Mindtree Recruitment Rounds: Sample Questions
- About Mindtree
- Preparing for Microsoft interview questions
- Microsoft technical interview questions
- Microsoft behavioural interview questions
- Aptitude Interview Questions
- Technical Interview Questions
- Easy
- Intermediate
- Hard
- HR Interview Questions
- Eligibility criteria
- Recruitment rounds & assessments
- Tech Mahindra interview questions - Technical round
- Tech Mahindra interview questions - HR round
- Hiring process at Mphasis
- Mphasis technical interview questions
- Mphasis HR interview questions
- About Mphasis
- Technical interview questions
- HR interview questions
- Recruitment process
- About Virtusa
- Goldman Sachs Interview Process
- Technical Questions for Goldman Sachs Interview
- Sample HR Question for Goldman Sachs Interview
- About Goldman Sachs
- Nagarro Recruitment Process
- Nagarro HR Interview Questions
- Nagarro Aptitude Test Questions
- Nagarro Technical Test Questions
- About Nagarro
- PwC Recruitment Process
- PwC Technical Interview Questions: Freshers and Experienced
- PwC Interview Questions for HR Rounds
- PwC Interview Preparation
- Frequently Asked Questions
- EY Technical Interview Questions (2023)
- EY Interview Questions for HR Round
- About EY
- Morgan Stanley Recruitment Process
- HR Questions for Morgan Stanley Interview
- HR Questions for Morgan Stanley Interview
- About Morgan Stanley
- Recruitment Process at Flipkart
- Technical Flipkart Interview Questions
- Code-Based Flipkart Interview Questions
- Sample Flipkart Interview Questions- HR Round
- Conclusion
- FAQs
- Recruitment Process at Paytm
- Technical Interview Questions for Paytm Interview
- HR Sample Questions for Paytm Interview
- About Paytm
- Most Probable Accenture Interview Questions
- Accenture Technical Interview Questions
- Accenture HR Interview Questions
- Amazon Recruitment Process
- Amazon Interview Rounds
- Common Amazon Interview Questions
- Amazon Interview Questions: Behavioral-based Questions
- Amazon Interview Questions: Leadership Principles
- Company-specific Amazon Interview Questions
- 43 Top Technical/ Coding Amazon Interview Questions
- Juspay Recruitment: Stages and Timeline
- Juspay Interview Questions and Answers
- How to prepare for Juspay interview questions
- Prepare for the Juspay Interview: Stages and Timeline
- Frequently Asked Questions
- Adobe Interview Questions - Technical
- Adobe Interview Questions - HR
- Recruitment Process at Adobe
- About Adobe
- Cisco technical interview questions
- Sample HR interview questions
- The recruitment process at Cisco
- About Cisco
- JP Morgan interview questions (Technical round)
- JP Morgan interview questions HR round)
- Recruitment process at JP Morgan
- About JP Morgan
- Wipro Elite NTH: Selection Process
- Wipro Elite NTH Technical Interview Questions
- Wipro Elite NTH Interview Round- HR Questions
- BYJU's BDA Interview Questions
- BYJU's SDE Interview Questions
- BYJU's HR Round Interview Questions
- A Quick Overview of the KPMG Recruitment Process
- Technical Questions for KPMG Interview
- HR Questions for KPMG Interview
- About KPMG
- DXC Technology Interview Process
- DCX Technical Interview Questions
- Sample HR Questions for DXC Technology
- About DXC Technology
- Recruitment Process at PayPal
- Technical Questions for PayPal Interview
- HR Sample Questions for PayPal Interview
- About PayPal
- Capgemini Recruitment Rounds
- Capgemini Interview Questions: Technical round
- Capgemini Interview Questions: HR round
- Preparation tips
- FAQs
- Technical interview questions for Siemens
- Sample HR questions for Siemens
- The recruitment process at Siemens
- About Siemens
- HCL Technical Interview Questions
- HR Interview Questions
- HCL Technologies Recruitment Process
- List of EPAM Interview Questions for Technical Interviews
- About EPAM
- Atlassian Interview Process
- Top Skills for Different Roles at Atlassian
- Atlassian Interview Questions: Technical Knowledge
- Atlassian Interview Questions: Behavioral Skills
- Atlassian Interview Questions: Tips for Effective Preparation
- Walmart Recruitment Process
- Walmart Interview Questions and Sample Answers (HR Round)
- Walmart Interview Questions and Sample Answers (Technical Round)
- Tips for Interviewing at Walmart and Interview Preparation Tips
- Frequently Asked Questions
- Uber Interview Questions For Engineering Profiles: Coding
- Technical Uber Interview Questions: Theoretical
- Uber Interview Question: HR Round
- Uber Recruitment Procedure
- About Uber Technologies Ltd.
- Intel Technical Interview Questions
- Computer Architecture Intel Interview Questions
- Intel DFT Interview Questions
- Intel Interview Questions for Verification Engineer Role
- Recruitment Process Overview
- Important Accenture HR Interview Questions
- Points to remember
- What is Selenium?
- What are the components of the Selenium suite?
- Why is it important to use Selenium?
- What's the major difference between Selenium 3.0 & Selenium 2.0?
- What is Automation testing and what are its benefits?
- What are the benefits of Selenium as an Automation Tool?
- What are the drawbacks to using Selenium for testing?
- Why should Selenium not be used as a web application or system testing tool?
- Is it possible to use selenium to launch web browsers?
- What does Selenese mean?
- What does it mean to be a locator?
- Identify the main difference between "assert", and "verify" commands within Selenium
- What does an exception test in Selenium mean?
- What does XPath mean in Selenium? Describe XPath Absolute & XPath Relation
- What is the difference in Xpath between "//"? and "/"?
- What is the difference between "type" and the "typeAndWait" commands within Selenium?
- Distinguish between findElement() & findElements() in context of Selenium
- How long will Selenium wait before a website is loaded fully?
- What is the difference between the driver.close() and driver.quit() commands in Selenium?
- Describe the different navigation commands that Selenium supports
- What is Selenium's approach to the same-origin policy?
- Explain the difference between findElement() in Selenium and findElements()
- Explain the pause function in SeleniumIDE
- Explain the differences between different frameworks and how they are connected to Selenium's Robot Framework
- What are your thoughts on the Page Object Model within the context of Selenium
- What are your thoughts on Jenkins?
- What are the parameters that selenium commands come with a minimum?
- How can you tell the differences in the Absolute pathway as well as Relative Path?
- What's the distinction in Assert or Verify declarations within Selenium?
- What are the points of verification that are in Selenium?
- Define Implicit wait, Explicit wait, and Fluent
- Can Selenium manage windows-based pop-ups?
- What's the definition of an Object Repository?
- What is the main difference between obtainwindowhandle() as well as the getwindowhandles ()?
- What are the various types of Annotations that are used in Selenium?
- What is the main difference in the setsSpeed() or sleep() methods?
- What is the way to retrieve the alert message?
- How do you determine the exact location of an element on the web?
- Why do we use Selenium RC?
- What are the benefits or advantages of Selenium RC?
- Do you have a list of the technical limitations when making use of Selenium RC? Selenium RC?
- What's the reason to utilize the TestNG together with Selenium?
- What Language do you prefer to use to build test case sets in Selenium?
- What are Start and Breakpoints?
- What is the purpose of this capability relevant in relation to Selenium?
- When do you use AutoIT?
- Do you have a reason why you require Session management in Selenium?
- Are you able to automatize CAPTCHA?
- How can we launch various browsers on Selenium?
- Why should you select Selenium rather than QTP (Quick Test Professional)?
- Airbus Interview Questions and Answers: HR/ Behavioral
- Industry/ Company-Specific Airbus Interview Questions
- Airbus Interview Questions and Answers: Aptitude
- Airbus Software Engineer Interview Questions and Answers: Technical
- Importance of Spring Framework
- Spring Interview Questions (Basic)
- Advanced Spring Interview Questions
- C++ Interview Questions and Answers: The Basics
- C++ Interview Questions: Intermediate
- C++ Interview Questions And Answers With Code Examples
- C++ Interview Questions and Answers: Advanced
- Test Your Skills: Quiz Time
- MBA Interview Questions: B.Com Economics
- B.Com Marketing
- B.Com Finance
- B.Com Accounting and Finance
- Business Studies
- Chartered Accountant
- Q1. Please tell us something about yourself/ Introduce yourself to us.
- Q2. Describe yourself in one word.
- Q3. Tell us about your strengths and weaknesses.
- Q4. Why did you apply for this job/ What attracted you to this role?
- Q5. What are your hobbies?
- Q6. Where do you see yourself in five years OR What are your long-term goals?
- Q7. Why do you want to work with this company?
- Q8. Tell us what you know about our organization
- Q9. Do you have any idea about our biggest competitors?
- Q10. What motivates you to do a good job?
- Q11. What is an ideal job for you?
- Q12. What is the difference between a group and a team?
- Q13. Are you a team player/ Do you like to work in teams?
- Q14. Are you good at handling pressure/ deadlines?
- Q15. When can you start?
- Q16. How flexible are you regarding overtime?
- Q17. Are you willing to relocate for work?
- Q18. Why do you think you are the right candidate for this job?
- Q19. How can you be an asset to the organization?
- Q20. What is your salary expectation?
- Q21. How long do you plan to remain with this company?
- Q22. What is your objective in life?
- Q23. Would you like to pursue your Master's degree anytime soon?
- Q24. How have you planned to achieve your career goal?
- Q25. Can you tell us about your biggest achievement in life?
- Q26. What was the most challenging decision you ever made?
- Q27. What kind of work environment do you prefer to work in?
- Q28. What is the difference between a smart worker and a hard worker?
- Q29. What will you do if you don't get hired?
- Q30. Tell us three things that are most important for you in a job.
- Q31. Who is your role model and what have you learned from him/her?
- Q32. In case of a disagreement, how do you handle the situation?
- Q33. What is the difference between confidence and overconfidence?
- Q34. If you have more than enough money in hand right now, would you still want to work?
- Q35. Do you have any questions for us?
- Interview Tips for Freshers
- Tell me about yourself
- What are your greatest strengths?
- What are your greatest weaknesses?
- Tell me about something you did that you now feel a little ashamed of
- Why are you leaving (or did you leave) this position??
- 15+ resources for preparing most-asked interview questions
- CoCubes Interview Process Overview
- Common CoCubes Interview Questions
- Key Areas to Focus on for CoCubes Interview Preparation
- Conclusion
- Frequently Asked Questions (FAQs)
- Data Analyst Interview Questions With Answers
- About Data Analyst
50+ Mphasis Interview Questions for Technical & HR Round (2026)
Mphasis is among the best organizations offering a great place to work for any potential candidate looking for technical career growth or future. If you are among those applicants then you must look at this list of Mphasis interview basic questions to prepare for the technical interview.
Hiring process at Mphasis
Numerous individuals dream about working at Mphasis because the opportunities presented here, in terms of both the experiences you may have and the skills you can acquire, are unparalleled. During your time spent working here, every action you take generates a significant amount of value for you. In India, applicants can apply for jobs at Mphasis Chennai, Mphasis Bangalore, and Mphasis Pune branches. The company goes through the motions of holding a recruiting procedure every year to pick new employees.
The candidate selection procedure that the firm uses includes a total of 3 phases where you will be asked some interview questions including programming questions. The following are the rounds during Mphasis technical and Mphasis HR interview and hiring process-
- Online Test
- Group Discussion (There can also be a tool-based communication test or coding round before GD).
- Technical Interview
- Mphasis HR Interview

List of Mphasis technical interview questions
Here we have shared some of the frequently asked technical questions in the Mpshais interview that can help you.
1. What is a 2D array?

A 2D array, also known as a two-dimensional array, is a data structure that stores values in a grid of rows and columns. It is essentially an array of arrays.
Each element in a 2D array is identified by a pair of indices, representing its position in the row and column dimensions. For example, to access the element at row i and column j, you would use the syntax array[i][j].
2D arrays are commonly used in programming to represent data that naturally lends itself to a grid structure, such as images, game boards, and matrices.

2. What is the difference between structure and union?
In programming, structures and unions are both used to define custom data types, but they differ in their fundamental properties and intended uses.
A structure is a composite data type that groups together variables of different data types under a single name. Each variable within a structure can be accessed independently and has its own unique memory location. Structures are commonly used to represent objects with multiple attributes or properties, such as a person with a name, age, and address.
On the other hand, a union is a special data type that allows different data types to be stored in the same memory location. Unlike structures, where all variables have their own memory location, a union's variables share the same memory location, and only one variable can be active at any given time. This means that changing the value of one variable in a union can affect the value of other variables in the same union. Unions are often used to conserve memory by allowing different data types to share the same memory space.
3. What is binary search tree data structure?
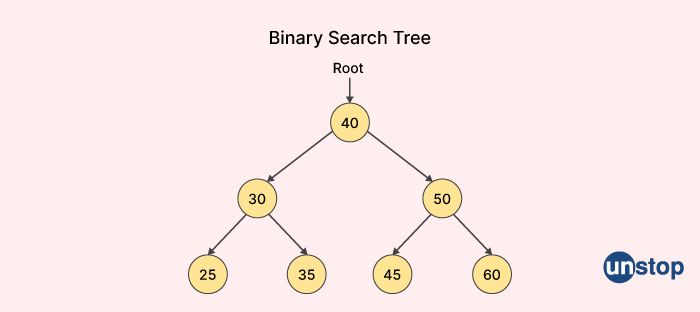
A binary search tree (BST) is a type of data structure used in computer programming that organizes a collection of data items (often integers) in a tree-like structure. In a binary search tree, each node in the tree has a value, and each node also has two child nodes, referred to as the left child and the right child.
The left child of a node contains a value that is less than or equal to the value of the node, while the right child contains a value that is greater than the value of the node. This property, known as the "BST property," allows binary search trees to be used efficiently for searching and sorting data.
To search for a value in a binary search tree, we start at the root node and compare the value we are searching for with the value of the current node. If the value is less than the current node's value, we move to the left child. If the value is greater than the current node's value, we move to the right child. We continue this process until we find the value we are searching for or determine that it is not in the tree.
4. What are clouds in cloud computing?
In cloud computing, the term "clouds" generally refers to the virtualized IT resources that are made available to users over the Internet. These resources can include servers, storage, databases, software applications, and other services.
Clouds are typically hosted in data centers that are managed by cloud service providers, such as Amazon Web Services, Microsoft Azure, or Google Cloud Platform. These providers offer a wide range of services and pricing options, making it possible for organizations of all sizes to take advantage of the benefits of cloud computing, such as scalability, flexibility, and cost-efficiency.
5. What are the three basic components of cloud computing?
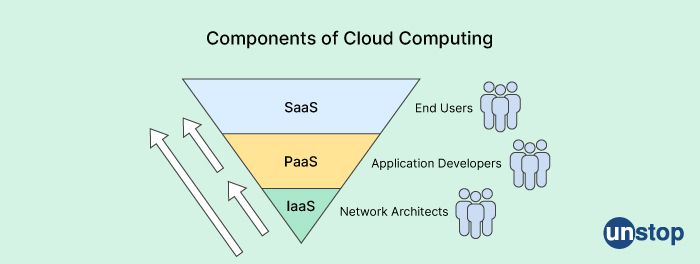
The three basic components of cloud computing are:
-
Infrastructure as a Service (IaaS): This component provides access to virtualized computing resources, such as servers, storage, and networking, that can be rented on a pay-per-use basis. Users have control over the operating system, applications, and other software running on the infrastructure.
-
Platform as a Service (PaaS): This component provides a platform for developers to build, deploy, and manage applications without having to worry about the underlying infrastructure. The platform typically includes development tools, programming languages, and libraries.
-
Software as a Service (SaaS): This component provides access to software applications that are hosted and maintained by a third-party provider. Users can access the software over the internet using a web browser or other client software. SaaS applications can be used for a wide range of purposes, such as email, document management, customer relationship management, and more.
These three components work together to provide a flexible and scalable computing environment that can be used to meet the needs of businesses of all sizes. By using cloud computing, organizations can avoid the need to invest in expensive hardware and software, and can instead pay for the resources they need on a pay-per-use basis.
6. What are the components of cloud computing MCQ?
In the process of planning for cloud computing, there seem to be generally 3 phases, which are referred to as the strategy phase, the planning phase, and the deployment phase.
7. What is a separate network?
A separate network is a network that is isolated from other networks, either physically or logically, and is designed to provide secure communication between a specific set of devices or users.
A separate network can be created using a variety of technologies, such as virtual private networks (VPNs), firewalls, and network segmentation. In some cases, a separate network may be completely disconnected from the internet, providing an additional layer of security and privacy.
Separate networks are often used in business and government settings to protect sensitive information and prevent unauthorized access to critical systems. For example, a company might use a separate network to provide secure communication between employees working on a particular project, or to ensure that financial data is only accessible to authorized personnel.
8. Why does IoT have separate networks?
The Internet of Things (IoT) often involves a large number of devices that are connected to the Internet and communicate with each other and with central servers or cloud-based services. Because of the large number of devices and the potentially sensitive data they transmit, IoT often uses separate networks to ensure security, privacy, and reliability.
Separate networks can provide several benefits for IoT, including:
-
Security: By using separate networks, IoT devices can be isolated from other devices and networks, reducing the risk of unauthorized access or data breaches. This is particularly important for IoT devices that are used in critical infrastructure, such as power grids or transportation systems, where a security breach could have serious consequences.
-
Reliability: By separating IoT traffic from other types of network traffic, it's possible to ensure that IoT devices have the bandwidth and network resources they need to operate reliably. This is particularly important for time-sensitive applications, such as real-time monitoring of industrial processes or medical devices.
-
Privacy: Separate networks can also help to ensure the privacy of IoT data by limiting access to authorized users and devices. This is particularly important for applications that involve sensitive personal information, such as healthcare or financial data.
9. What is the network layer protocol used for?
The network layer protocol is used for routing packets of data across a network. The network layer is the third layer in the OSI (Open Systems Interconnection) model of networking, and it provides logical addressing and routing services to the upper layers of the model.
The network layer protocol is responsible for creating, transmitting, and receiving packets of data, also known as IP packets, and for determining the best path for those packets to travel between network devices. This involves examining the destination IP address of each packet and using routing tables to determine the next hop on the path to the destination.
The most widely used network layer protocol is the Internet Protocol (IP), which is used by the Internet and many other networks to route packets of data between devices. IP packets can be transmitted over a variety of physical networks, such as Ethernet, Wi-Fi, or cellular networks, using different network technologies.
10. What is the network layer in IoT?
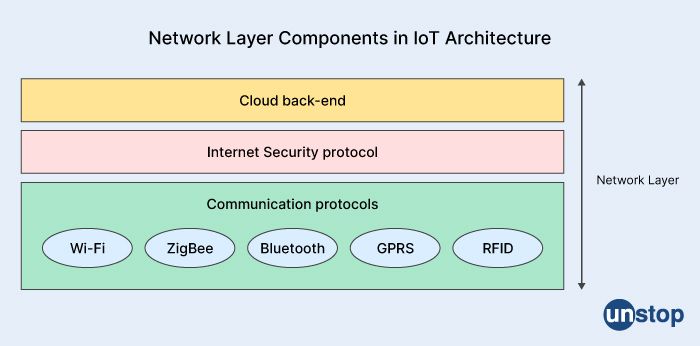
In the context of IoT, the network layer refers to the layer in the network stack that is responsible for routing data between devices on the Internet. The network layer provides the necessary protocols and mechanisms for transmitting data over a variety of networks, including wired and wireless networks.
Here, the network layer typically uses a combination of protocols and technologies to provide reliable and efficient communication between devices. Some common protocols used in the IoT network layer include:
-
IPv6: Internet Protocol version 6 (IPv6) is a network layer protocol that provides a unique address for each device on the Internet. IPv6 is designed to provide better scalability and security than its predecessor, IPv4, and is often used in IoT networks.
-
6LoWPAN: 6LoWPAN (IPv6 over Low-power Wireless Personal Area Networks) is a protocol that allows IPv6 packets to be transmitted over low-power wireless networks, such as Zigbee and Bluetooth Low Energy (BLE).
-
CoAP: Constrained Application Protocol (CoAP) is a lightweight protocol that is designed for use in resource-constrained IoT devices. CoAP provides a simple and efficient way for devices to communicate with each other over the Internet.
-
MQTT: Message Queuing Telemetry Transport (MQTT) is a messaging protocol that is often used in IoT applications. MQTT provides a publish-subscribe model for communication between devices and is designed to be lightweight and efficient.
11. How do you create a 2D array?
To create a 2D array, you need to use the new keyword, followed by a space and insert the type, the number of rows in square brackets, followed by the number of columns in square brackets, to construct an array. For example, new int[numRows][numCols] creates an array with two rows and two columns. Multiply the number of rows by the number of columns to get the total number of elements in a two-dimensional auxiliary array.
Here's an example:
// create a 2D array with 3 rows and 4 columns
int[][] myArray = new int[3][4];
// assign values to the array
myArray[0][0] = 1;
myArray[0][1] = 2;
myArray[0][2] = 3;
myArray[0][3] = 4;
myArray[1][0] = 5;
myArray[1][1] = 6;
myArray[1][2] = 7;
myArray[1][3] = 8;
myArray[2][0] = 9;
myArray[2][1] = 10;
myArray[2][2] = 11;
myArray[2][3] = 12;
This creates a 2D array with 3 rows and 3 columns and initializes it with the given values.
12. How do you deal with circular arrays?
To work with circular arrays, there are a few key things to keep in mind:
-
Keep track of the array size: Since circular arrays wrap around, it can be easy to lose track of the actual size of the array. It's important to keep track of the number of elements in the array and to ensure that you don't overflow the array by adding more elements than it can hold.
-
Use modular arithmetic: When indexing into a circular array, you'll need to use modular arithmetic to ensure that you wrap around to the beginning of the array when you reach the end. For example, if you have an array of size N and you want to access element i, you would use the index i % N to get the correct element.
-
Keep track of the front and back of the array: Since circular arrays are often used to implement queues or circular buffers, it's important to keep track of the front and back of the array. You can do this using two pointers, one for the front and one for the back. When you add an element to the array, you would add it to the back of the queue and update the back pointer. When you remove an element from the array, you would remove it from the front of the queue and update the front pointer.
-
Handle resizing carefully: Resizing a circular array can be tricky since you need to preserve the circular nature of the array. One common approach is to create a new array with a larger size and copy the elements from the old array to the new array, using modular arithmetic to wrap around as needed. Another approach is to use a dynamic circular array implementation that automatically resizes the array as needed.
13. Why do we use circular arrays for the queue?
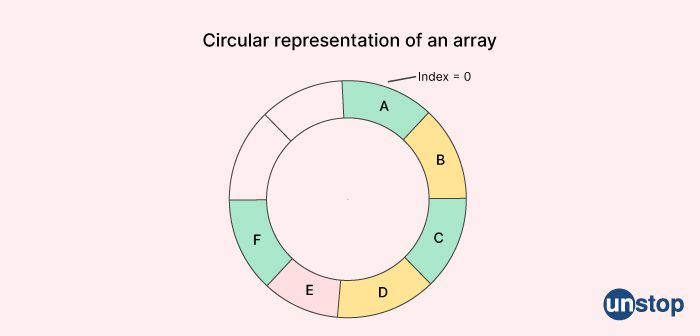
Circular arrays are often used to implement queues because they allow for efficient use of memory and simplify the logic needed to manage the queue.
One advantage of a circular array over a regular array is that it allows us to implement a circular buffer. This means that when we reach the end of the array, instead of allocating new memory for new elements, we can wrap around to the beginning of the array and add new elements there. This avoids the overhead of having to reallocate memory and copy elements from one location to another, which can be expensive in terms of time and memory usage.
14. What is circular array implementation?
A circular array implementation is a way of representing an array data structure in which the end of the array "wraps around" to the beginning, creating a circular sequence of elements. In other words, the last element in the array is connected to the first element, creating a loop.
This implementation has several advantages over a traditional linear array implementation, including:
-
Efficient use of memory: With a circular array implementation, it is possible to reuse memory that would be wasted in a linear implementation. For example, if the end of the array is reached, elements can be added to the beginning of the array instead of allocating new memory.
-
Easy to implement: The circular array implementation is often simpler to implement than other data structures like linked lists or trees.
-
Faster access to elements: Accessing elements in a circular array can be faster than in a linked list or other data structure, since elements are stored in contiguous memory.
One common application of a circular array implementation is in creating circular buffers, which are used to store data in a first-in, first-out (FIFO) manner. In a circular buffer, new data is added to the end of the buffer, and old data is removed from the front, with the buffer wrapping around as needed to maintain the circular sequence of elements.
15. What is a pseudocode?
Pseudocode is a type of informal language used in software development to describe the logic of an algorithm or program without using the syntax of a specific programming language. It is a high-level description of the steps that a program will take to solve a problem, using English-like phrases and simple programming concepts.
Pseudocode is often used as a tool for planning and designing software programs, as it allows developers to focus on the logic and structure of the program without getting bogged down in the details of syntax or implementation.
16. What is project code?
In software development, project code refers to the source code of a software project. The source code is the human-readable text that programmers write to create software applications. It typically includes instructions written in a programming language, which are then compiled or interpreted to create an executable program that can be run on a computer or other device.
Project code can include many different types of files, such as source code files, configuration files, build scripts, and documentation. These files are organized into directories and subdirectories, and may be stored in a version control system like Git or SVN to enable collaboration and tracking of changes over time.
17. How do I find a project code?
If you are looking for the source code of a specific software project, there are a few different ways you can find it:
-
Check the project's website: Many software projects make their source code available on their website or on a code hosting platform like GitHub, GitLab, or Bitbucket. Check the project's website or search for the project on a code hosting platform to see if the source code is available.
-
Search for the project on a search engine: You can try searching for the project name along with keywords like "source code" or "GitHub" on a search engine like Google or Bing. This may help you find a link to the project's source code if it is available online.
-
Contact the project's developers: If you cannot find the source code online, you can try contacting the project's developers or maintainers to ask if they can provide it to you. This may be especially useful if the project is not open source and does not make its code available to the public.
-
Once you have found the project's source code, you can download it or clone the repository to your local machine, depending on the version control system used by the project. From there, you can view the source code and modify it if necessary, depending on the project's license and any restrictions on use.
18. What is the default pooling time in implicit and explicit wait?
The time for the implicit wait is set to 0 by default, and it will continue to poll for the needed element after a period of 500 milliseconds. Explicit wait helps to pause the execution of the script depending on a given circumstance for a set period. The explicit wait may be used in a variety of programming languages.
19. Why is method overriding used?
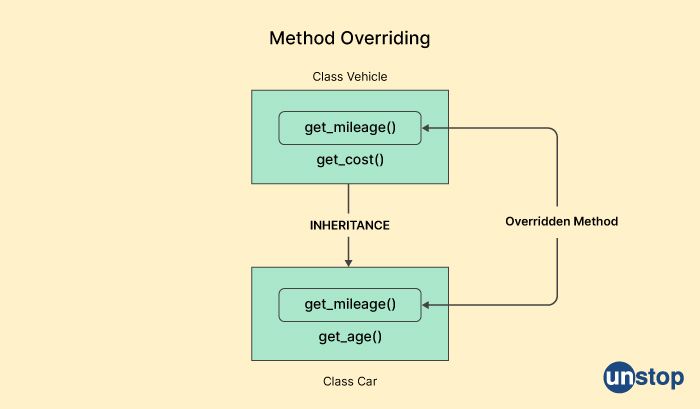
Method overriding is used in object-oriented programming to provide a way for a subclass to customize or extend the behavior of a method that is already defined in its superclass. It allows a subclass to provide its own implementation of a method that has the same name, return type, and parameters as a method in its superclass.
Method overriding is useful in many situations, such as:
-
Modifying the behavior of a method: A subclass can override a method in its superclass to modify its behavior or provide a more specialized implementation. For example, a subclass of a
Vehicleclass may override thedrive()method to provide a specific implementation for a particular type of vehicle, such as aCar. -
Adding new functionality: A subclass can override a method to add new functionality to it. For example, a subclass of a
Listclass may override theadd()method to perform additional operations when an element is added to the list. -
Implementing polymorphism: Method overriding is a key feature of polymorphism, which allows objects of different classes to be treated as if they are of the same type. By overriding a method in a superclass, a subclass can be treated as if it is an object of its superclass, which can be useful for creating more flexible and reusable code.
20. What is method override in Java?
Method overriding is a feature in Java (and other object-oriented programming languages) that allows a subclass to provide a different implementation of a method that is already defined in its superclass. When a subclass overrides a method, it provides its own implementation of the method that is executed instead of the implementation provided by the superclass.
To override a method in Java, the subclass must provide a method with the same name, return type, and parameter list as the method in the superclass. The method in the subclass must also be marked with the @Override annotation to indicate that it is intended to override a method in the superclass.
21. What are non-primitive and primitive data types?
In computer programming, primitive data types are the basic data types that are built into a programming language and are used to represent simple values. These data types are predefined by the language and have a fixed size and format. Examples of primitive data types include integers, floating-point numbers, characters, and Boolean values.
Non-primitive data types, on the other hand, are more complex data types that are built from primitive data types or other non-primitive data types. They are also known as composite or derived data types. Examples of non-primitive data types include arrays, strings, structures, classes, and pointers.
22. What is a folder structure called?
In computers, a directory is a structure for cataloging files, which is part of a file system. This structure may also contain references to other directories and files. On several computers, directories are referred to as folders or drawers, and their function is comparable to that of a workbench or a conventional office filing cabinet.
23. Is TCP a network layer protocol?
No, TCP (Transmission Control Protocol) is not a network layer protocol. It is a transport layer protocol that provides reliable, ordered, and error-checked delivery of data between applications running on different hosts over IP networks.
The TCP protocol operates at the transport layer (Layer 4) of the OSI (Open Systems Interconnection) model, above the network layer (Layer 3) where IP (Internet Protocol) operates. TCP provides a connection-oriented service, establishing a virtual circuit between two hosts before transmitting data. It breaks the data into segments and provides flow control, congestion control, and error recovery mechanisms to ensure reliable data transmission.
The network layer protocols, such as IP, provide routing and addressing services to enable communication between devices on different networks. They define the format and structure of IP packets, which contain the source and destination IP addresses and other information necessary for delivering the data across the network.
24. What is a Layer 2 protocol?
A Layer 2 protocol is a protocol that operates at the Data Link layer (Layer 2) of the OSI (Open Systems Interconnection) model. This layer is responsible for the transfer of data between adjacent network nodes on the same physical network segment, typically using a LAN (Local Area Network) technology such as Ethernet or Wi-Fi.
Layer 2 protocols define the format and structure of the data frames that are used to transmit data between devices on the same network segment. They also specify the rules for addressing, error detection, and flow control that are necessary for reliable data transfer over the network.
25. What is a network protocol?
A network protocol is a set of rules and procedures used to govern the communication between devices on a computer network. It defines the format, timing, sequencing, and error handling of data exchange between network devices, allowing them to communicate and exchange information in a standardized way.
Network protocols can be implemented in hardware, software, or a combination of both. They can be categorized into different layers, such as the application layer, transport layer, network layer, and data link layer. Each layer of the network protocol stack performs specific functions and communicates with the adjacent layers through standardized interfaces.
26. Could you explain regression testing?
Regression testing is a type of software testing that verifies that changes to a software application or system have not introduced new defects or caused unintended effects to previously tested functionality. It involves rerunning previously executed test cases on the modified software to ensure that it still behaves correctly and meets the specified requirements.
Regression testing is performed whenever changes are made to the software, such as bug fixes, new features, or system upgrades. The objective is to identify any unexpected side effects or functional regressions that may have been introduced as a result of the changes.
Regression testing typically involves the following steps:
-
Selecting the appropriate test cases to be re-executed based on the scope and impact of the changes.
-
Running the selected test cases on the modified software to verify that the functionality has not been negatively impacted.
-
Comparing the results of the new test run with the results of the previous run to identify any discrepancies or failures.
-
Investigating and resolving any defects or failures found during the regression testing.
-
Documenting the results of the regression testing and communicating them to the relevant stakeholders.
27. Explain the agile software development paradigm?
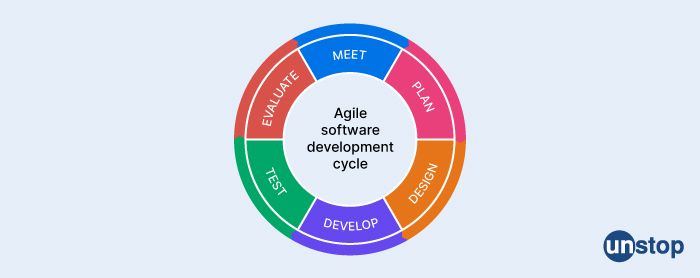
Agile software development is a project management methodology that emphasizes flexibility, collaboration, and iterative development. It is based on the Agile Manifesto, a set of values and principles for software development that prioritize customer satisfaction, working software, and continuous improvement.
The Agile approach emphasizes short development cycles called "sprints," typically lasting two to four weeks. Each sprint involves a collaborative effort between the development team and the customer or product owner to define and prioritize a set of requirements or user stories for the sprint.
During the sprint, the development team works on the highest-priority items, breaking them down into smaller tasks that can be completed within the sprint. The team holds daily stand-up meetings to discuss progress and address any issues or roadblocks.
At the end of each sprint, the team delivers a working product increment that can be reviewed and tested by the customer or product owner. Feedback is then incorporated into the next sprint planning cycle, and the process repeats until the final product is delivered.
The Agile approach emphasizes collaboration, communication, and flexibility. The development team works closely with the customer or product owner throughout the project, responding to changing requirements and feedback in real-time. This allows for faster feedback cycles and ensures that the final product meets the customer's needs.
28. What is meant by the term "private cloud"?
A private cloud is a type of cloud computing environment. It also is known as an internal cloud or a corporate cloud. In this type of cloud, all of the hardware and software resources are dedicated to a single customer, and only that customer has access to those resources. The advantages of cloud computing, such as elasticity, scalability, and simplicity of service delivery, are combined in a private cloud, along with the advantages of on-premises infrastructures, such as access control, protection, and resource customization. There is also a public cloud available.
The private cloud is preferred by many businesses over the public cloud because it is a more effective way to fulfill regulatory compliance criteria, and in some cases, it is the only way to do so (cloud computing services supplied over shared infrastructure by numerous clients). Other than the public cloud, the private cloud may include personally identifiable information (PII), health records, financial details, confidential papers, or other types of sensitive data.
29. Define data warehousing?
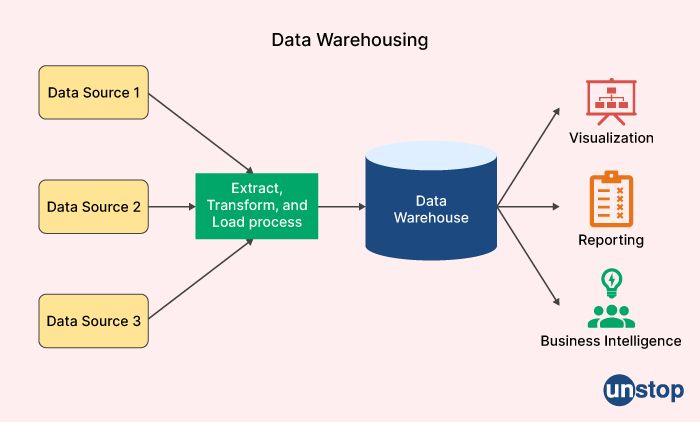
Data warehousing is a process of collecting, storing, and managing data from various sources to provide meaningful insights for decision-making purposes. It involves the extraction, transformation, and loading of data from operational systems into a central repository, known as a data warehouse.
A data warehouse is designed to support the analytical needs of an organization by providing a consolidated and consistent view of data across different sources. It typically stores historical data and can be used to analyze trends, patterns, and relationships in the data over time.
The data in a data warehouse is organized into subject areas or domains, such as sales, finance, or customer data. It is optimized for querying and analysis, with tools and techniques such as OLAP (Online Analytical Processing) and data mining used to extract insights and knowledge from the data.
30. What does 'degree of connection' mean?
The degree of connection in a database refers to the number of relationships between tables in a database schema. It indicates how closely the tables are connected or related to each other in terms of the data they represent.
In a database, tables are typically related to each other through primary and foreign keys, which establish the relationships between them. The degree of connection refers to the number of tables that are related to a particular table through these keys.
There are three main types of degrees of connection in a database schema:
-
One-to-one (1:1): In a one-to-one relationship, each row in one table is related to at most one row in another table, and vice versa.
-
One-to-many (1:N): In a one-to-many relationship, each row in one table can be related to many rows in another table, but each row in the other table is related to at most one row in the first table.
-
Many-to-many (N:M): In a many-to-many relationship, each row in one table can be related to many rows in another table, and vice versa. This type of relationship typically requires the use of an intermediary table to represent the relationship between the two tables.
31. What is an index?
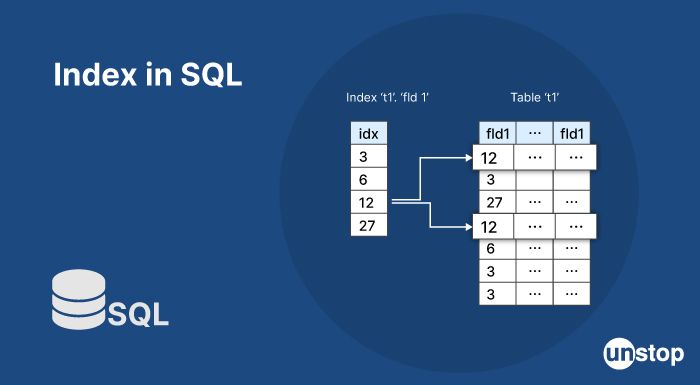
In the context of a database, an index is a data structure that is used to optimize the speed of data retrieval operations. An index is created on one or more columns of a table and is essentially a copy of a subset of the table data, organized in a way that makes it faster to search.
When a query is executed that includes a search condition on the indexed column(s), the database engine uses the index to locate the relevant rows much faster than it would if it had to scan the entire table. The index can also be used to speed up sorting and grouping operations.
Indexes can be created on a single column or a combination of columns, and they can be either unique or non-unique. Unique indexes ensure that no two rows in the indexed column(s) have the same value, while non-unique indexes allow duplicate values.
32. What is QBE?
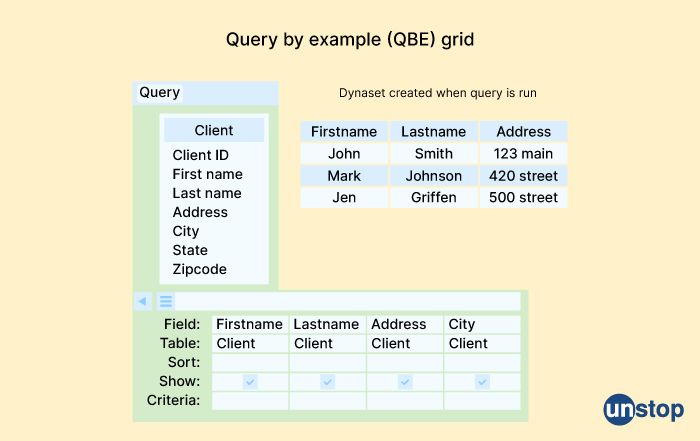
QBE stands for Query By Example, which is a graphical query language used to retrieve data from a relational database. It was developed by IBM in the 1970s as a user-friendly alternative to SQL, which can be more challenging for non-technical users to understand and use.
With QBE, users can construct queries by specifying the search criteria in a visual format, using examples of the desired data rather than writing complex SQL statements. The interface typically involves a grid with rows and columns representing the fields and records of a table, with the user entering values in the appropriate cells to create the query.
QBE supports various query operations, such as sorting, filtering, and joining data from multiple tables. It also allows users to save and reuse queries, making it easier to retrieve data that is frequently requested.
33. What is "conceptual design" in a database?
Conceptual design in a database refers to the process of creating a high-level abstract representation of the data requirements for an application or system. It is the first step in database design and involves identifying the entities, attributes, relationships, and constraints that will form the basis of the database schema.
The conceptual design phase focuses on understanding the business requirements and data needs of the organization or application, without getting into the technical details of how the data will be stored or accessed.
34. Describe the functions of the DML Compiler?
The DML Compiler is responsible for converting DML statements into query language, which is then communicated to the query evaluation engine for processing. A DML compiler is required because DML is indeed a set of grammar components that is somewhat comparable to other computer languages that need to be compiled, and these languages all require compilation. As a consequence of this, it is of the utmost importance to generate the selenium code in a language that perhaps the query evaluation engine is capable of comprehending and then to work on the queries using the right output.
35. What do you mean by the endurance of DBMS?
The endurance of a database management system (DBMS) refers to its ability to operate effectively over a prolonged period of time without encountering critical issues that can impact its reliability, performance, or availability.
DBMS endurance is a crucial aspect of any database system, especially for applications that require high availability, consistent performance, and data integrity. A reliable and robust DBMS should be able to handle large volumes of data, numerous concurrent users, and high transaction rates without failing or causing significant downtime.
To achieve high endurance, DBMS developers must focus on several factors, including:
-
Scalability: The DBMS should be able to scale up or down to accommodate changes in data volume, users, or workload demands.
-
Fault tolerance: The DBMS should have built-in mechanisms to prevent data loss or corruption in case of hardware or software failures.
-
Backup and recovery: The DBMS should provide reliable backup and recovery features that can restore the system to a consistent state in case of data loss or corruption.
-
Performance tuning: The DBMS should be optimized for fast data access and processing, with efficient indexing, query optimization, and resource utilization.
36. What are system integrators?
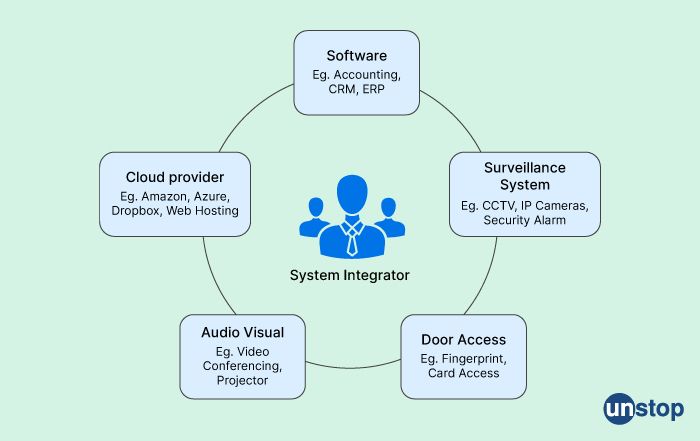
System integrators are companies or individuals who specialize in integrating various systems and technologies into a cohesive and functional system. They work with different hardware and software components, third-party products, and legacy systems to create a seamless solution that meets the client's needs.
System integrators may be involved in different stages of a project, such as planning, design, implementation, testing, and maintenance. They may also provide consulting services, project management, and technical support to ensure the success of the integration.
The systems that system integrators work on can range from simple to complex, depending on the client's requirements. They may integrate various systems, including IT systems, automation systems, security systems, communication systems, and more.
37. What are the differences between the hybrid cloud and the community cloud?
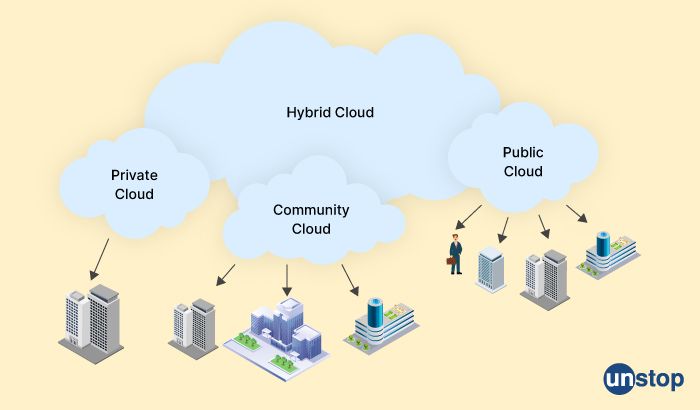
Hybrid cloud and community cloud are two different types of cloud computing deployment models with distinct characteristics.
-
Hybrid Cloud: A hybrid cloud is a cloud computing environment that combines public and private clouds. It allows organizations to utilize both on-premises infrastructure and public cloud services to run their applications and services. The main difference between a hybrid cloud and other cloud models is the ability to move applications and data between the public and private clouds as required.
-
Community Cloud: A community cloud is a cloud computing environment that is shared by multiple organizations with a common goal, such as a specific industry or government regulations. It is typically managed by a third-party provider, and the infrastructure is shared among a specific community of users. The community cloud is designed to provide greater levels of security, privacy, and compliance than public clouds while still allowing organizations to share resources and collaborate.
38. Which of the following is elastic IP?
Elastic IP is a feature of cloud computing services, such as Amazon Web Services (AWS), that allows users to allocate a static IP address to their account and then associate it with instances or services in the cloud.
Elastic IP provides a way for users to maintain a consistent IP address for their instances or services, even if they are stopped and restarted or moved to a different availability zone. This is useful for applications that require a fixed IP address for DNS or firewall rules.
Elastic IP is "elastic" because it can be easily reassigned to other instances or services within the same account, providing flexibility and scalability for the user's infrastructure. It also allows users to mask the failure of an instance or service by rapidly remapping the IP address to another instance or service in the same account.
39. Where can I find out more information on the Elastic BeanStalk?
Elastic BeanStalk simplifies the deployment of Amazon services by performing the function of a control panel and so minimizing the level of environmental complexity. It ensures that the configuration of the available resources is performed correctly. It is sufficient to upload the application for Elastic Beanstalk to take care of the necessary configuration and management of the resources and services. EBS is responsible for handling a variety of services, including load balancing, scalability, health monitoring, and on-demand provisioning.

40. What is the difference between elasticity and scalability when it comes to cloud computing?
Cloud computing is characterized by several characteristics, one of which is scalability, which allows for the workload to be increased proportionately to the number of available resources. Scalability allows for the handling of growing workloads. The design delivers resources on requirement BA as and when the requirement is being raised by the traffic, thanks to the utilization of scalability.
Elasticity, on the other hand, is a quality that allows for the notion of dynamically commissioning and decommissioning a massive amount of resource capacity. This is accomplished via the use of a feature known as "elasticity." In most cases, it is evaluated based on how quickly the resources are meeting the demand, and how effectively those resources are being utilized.
41. What are programs that are specifically designed to run on the cloud?
Programs that are specifically designed to run on the cloud are often referred to as cloud-native applications or cloud-native software.
Cloud-native applications are designed to take advantage of the unique features and capabilities of cloud computing, such as elastic scalability, high availability, and multi-tenancy. They are typically built using a microservices architecture, where the application is divided into a set of small, loosely-coupled services that can be independently developed, deployed, and scaled.
Cloud-native applications are often developed using containerization technology, such as Docker, which provides a lightweight and portable runtime environment for the application services. Containerization allows the application to be easily deployed and managed across different cloud platforms and environments.
42. What is the API Gateway referred to as?
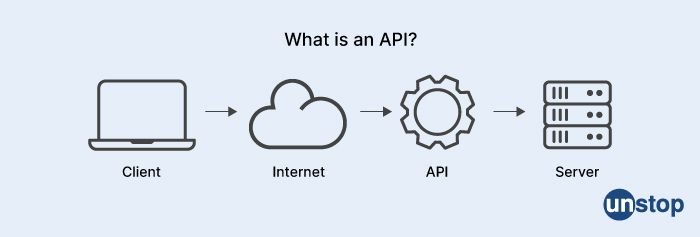
The API Gateway is often referred to as a reverse proxy.
In a traditional client-server architecture, the client makes requests to the server, and the server responds with data. In a reverse proxy architecture, the client makes requests to the API Gateway, which then forwards the requests to the appropriate backend services or servers. The backend services respond to the API Gateway, which then forwards the response back to the client.
The API Gateway acts as a single point of entry for clients to access backend services, providing a unified API that hides the complexity of the underlying systems. It also provides features such as routing, load balancing, authentication, and rate limiting to improve the performance, security, and scalability of the system.
43. What is meant by the term 'low-density data centers'?
The term "low-density data centers" refers to data centers that are designed to operate at a lower power and cooling density than traditional data centers. In a low-density data center, the amount of power and cooling provided per unit of floor space is typically lower than in a traditional data center.
Low-density data centers are typically used for applications and workloads that do not require high levels of processing power or data storage, such as web hosting, email, and basic office applications. By operating at a lower power density, low-density data centers can reduce their energy consumption and operating costs, as well as their environmental footprint.
44. What use do application programming interfaces (APIs) serve?
Application Programming Interfaces (APIs) are a set of protocols, routines, and tools for building software applications. APIs provide a way for different software systems to communicate with each other, exchange data, and access functionality.
APIs serve several important uses in software development and technology:
-
Integration: APIs allow different software systems to integrate and exchange data, enabling the creation of more complex and powerful applications.
-
Automation: APIs can automate routine tasks and processes, reducing the need for manual intervention and improving efficiency.
-
Customization: APIs can be used to customize and extend software applications, enabling developers to add new functionality or modify existing features.
-
Scalability: APIs can enable applications to scale more easily and efficiently, by allowing them to access resources and functionality from other systems and services.
-
Innovation: APIs can enable developers to build new and innovative applications and services that leverage existing functionality and data.
APIs are commonly used in web development, mobile app development, cloud computing, and the Internet of Things (IoT), among other areas. There are many types of APIs, including web APIs, which allow web applications to communicate with each other, and hardware APIs, which allow software applications to interact with hardware devices.
45. How can you ensure that your data is protected while it is being sent to the cloud?
An advantage of cloud computing is that it gives an organization access to many useful features that are simple to operate, but it also raises many questions about the safety of the data that must be moved from one location to another in the cloud. Despite these drawbacks, many businesses are adopting cloud computing because it offers many advantages. Verify that there is not a data leak with the encryption key that is implemented with the data that you are transferring to guarantee that it will continue to be safe as it travels from point A to point B within the cloud.
46. What are system integrators, and what do they do?
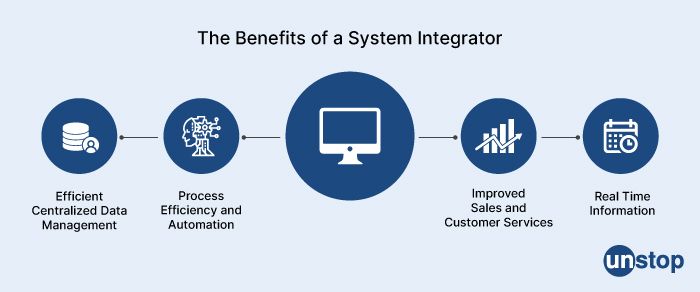
System integrators (SIs) are companies that specialize in integrating different software and hardware systems, applications, and services to create a unified solution that meets the specific needs of a business or organization.
SIs provide a range of services, including:
-
Planning and design: SIs work with clients to understand their requirements, analyze their existing systems, and design a comprehensive solution that meets their needs.
-
Integration and implementation: SIs integrate different systems, applications, and services into a unified solution, and implement the solution across the client's organization.
-
Customization and development: SIs can customize existing software and hardware solutions, or develop custom solutions to meet the unique needs of a business or organization.
-
Testing and quality assurance: SIs test and validate the integrated solution to ensure it meets the required performance, security, and reliability standards.
-
Maintenance and support: SIs provide ongoing maintenance and support services to ensure the integrated solution remains operational and up-to-date.
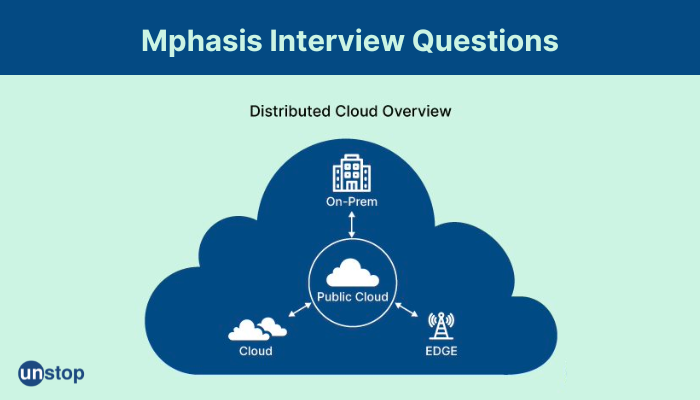
47. What is a distributed cloud?
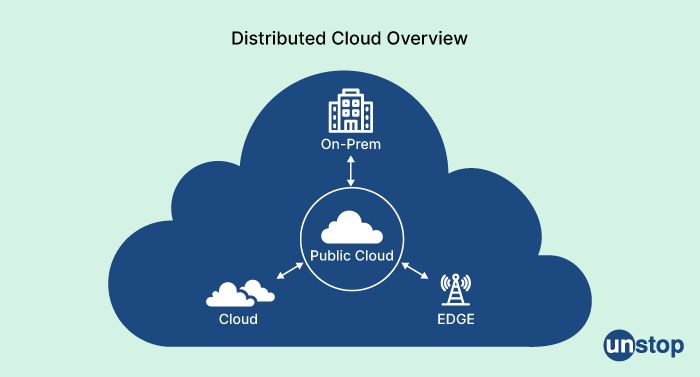
A distributed cloud is a cloud computing model that extends the traditional cloud infrastructure beyond a single data center or location to multiple geographically dispersed data centers. In a distributed cloud, the cloud resources and services are spread across different regions or locations, and connected through a high-speed network.
The concept of a distributed cloud is based on the idea of edge computing, which involves processing data and running applications closer to the source of the data, rather than sending it to a central cloud data center for processing. By distributing cloud resources and services across multiple locations, a distributed cloud can provide several benefits, such as:
-
Reduced latency: By processing data closer to the source, a distributed cloud can reduce the latency and improve the performance of applications and services.
-
Improved availability: By distributing cloud resources across multiple locations, a distributed cloud can improve the availability and reliability of applications and services, as failures in one location can be handled by other locations.
-
Data sovereignty: A distributed cloud can help address concerns around data sovereignty and compliance by ensuring that data is stored and processed in the appropriate location.
-
Scalability: By distributing resources across multiple locations, a distributed cloud can scale more easily and efficiently to meet changing demands.
48. What is the purpose of a buffer in Amazon Web Services (AWS)?
In Amazon Web Services (AWS), a buffer is a component that is used to temporarily store data or requests before they are processed by a downstream system or application. The purpose of a buffer is to smooth out any unevenness or spikes in traffic or workload, allowing the downstream system or application to process the data or requests more efficiently and effectively.
49. Define VPC?
VPC stands for Virtual Private Cloud. It is a cloud computing feature offered by many cloud service providers, including Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform.
A VPC is a virtual network environment that provides a logically isolated section of the cloud where customers can launch and run their own resources, such as virtual machines (VMs), databases, and storage. The VPC is completely customizable, allowing customers to define their own IP address ranges, subnets, routing tables, and network gateways.
50. Please explain load balancing in cloud computing.
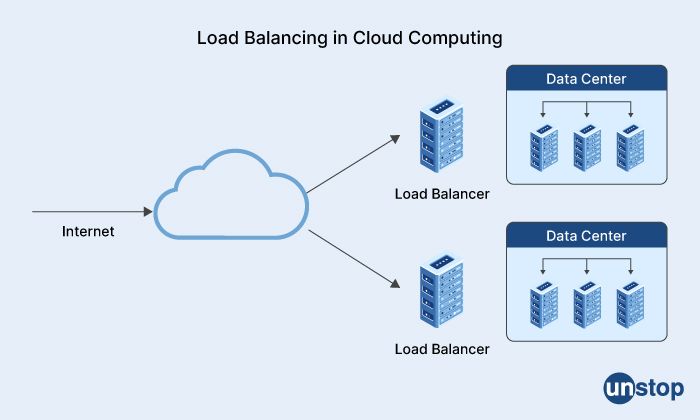
Load balancing is a technique used in cloud computing to distribute network traffic and computing workloads across multiple servers or virtual machines (VMs) to ensure that no single server or VM becomes overwhelmed with too much traffic or work.
Load balancing in cloud computing typically involves a load balancer, which is a software or hardware device that sits between the clients and the servers or VMs. The load balancer receives incoming network traffic and routes it to the appropriate server or VM based on a variety of factors, such as the server's available capacity, response time, and geographic location.
There are several different types of load-balancing techniques that can be used in cloud computing, including:
-
Round-robin load balancing: This technique distributes traffic evenly across multiple servers or VMs in a round-robin fashion, ensuring that each server or VM gets an equal share of the traffic.
-
Weighted load balancing: This technique assigns a weight or priority to each server or VM based on its available capacity or performance, and routes traffic accordingly.
-
Dynamic load balancing: This technique monitors the traffic and workload on each server or VM in real-time, and dynamically adjusts the traffic routing to ensure that the workload is evenly distributed across all servers or VMs.
51. Will you be able to handle data from big server drives while saving network costs?
Yes, if it is managed under one nodal network.
HR interview questions for Mphasis
Here are some of the essential HR questions for the Mphasis HR interview round that you must prepare for:
- Tell us something about yourself.
- Why do you want to join Mphasis?
- Explain your job role at your current company.
- Will you be able to handle the work under pressure on a daily basis? Tell us how.
- How will you manage a big and diverse team for a crucial project on a regular basis?
- What do you think your biggest strength is?
- How will you handle a disappointed or angry client?
- How do you define your work ethic?
- Tell me something about your family background.
- How did you get into this field?
- What is your routine on a regular basis?
- Do you have any experience as a network administrator?
- Are you able to work on a single client with high expectations at once?
About Mphasis
Mphasis Ltd. is a technology firm that specializes in providing application services and infrastructure services, including business process outsourcing services. The services provided by the company include software development, application management, enterprise software services, technology practices, business solutions, remote monitoring, human resource outsourcing, data center services, private and public network services, mortgage services, and managed scheduled maintenance, among others.
Talking about industries, it has a huge foothold in various sectors and domains. It serves banking, financial markets, medical, biomedical, manufacturing, transportation, media and entertainment, commerce, shipping, administration, energy, and as well as utilities.
You may also like to read:
- What Is GitHub? An Introduction, How-To Use It, Components & More!
- Top 50+ Cisco Interview Questions With Answers For Freshers And Experienced Candidates
- 50+ Adobe Interview Questions With Answers
- Top 50+ TCS Interview Questions And Answers (Bookmark Them!)
- 5 Interesting Coding Projects That’ll Make Your Resume Stand Out!
Login to continue reading
And access exclusive content, personalized recommendations, and career-boosting opportunities.
Don't have an account? Sign up
Never miss an
Update

Featured Opportunities
Top-Rated Practice by Students





Subscribe
to our newsletter




Comments
Add comment