

Asian Paints Alchemy 2026
Company Interview Questions for Freshers
- TCS Technical Interview Questions & Answers
- TCS Managerial Interview Questions & Answers
- TCS HR Interview Questions & Answers
- Overview of Cognizant Recruitment Process
- Cognizant Interview Questions: Technical
- Cognizant Interview Questions: HR Round
- Overview of Wipro Technologies Recruitment Rounds
- Wipro Interview Questions
- Technical Round
- HR Round
- Online Assessment Sample Questions
- Frequently Asked Questions
- Overview of Google Recruitment Process
- Google Interview Questions: Technical
- Google Interview Questions: HR round
- Interview Preparation Tips
- About Google
- Deloitte Technical Interview Questions
- Deloitte HR Interview Questions
- Deloitte Recruitment Process
- Technical Interview Questions and Answers
- Level 1 difficulty
- Level 2 difficulty
- Level 3 difficulty
- Behavioral Questions
- Eligibility Criteria for Mindtree Recruitment
- Mindtree Recruitment Process: Rounds Overview
- Skills required to crack Mindtree interview rounds
- Mindtree Recruitment Rounds: Sample Questions
- About Mindtree
- Preparing for Microsoft interview questions
- Microsoft technical interview questions
- Microsoft behavioural interview questions
- Aptitude Interview Questions
- Technical Interview Questions
- Easy
- Intermediate
- Hard
- HR Interview Questions
- Eligibility criteria
- Recruitment rounds & assessments
- Tech Mahindra interview questions - Technical round
- Tech Mahindra interview questions - HR round
- Hiring process at Mphasis
- Mphasis technical interview questions
- Mphasis HR interview questions
- About Mphasis
- Technical interview questions
- HR interview questions
- Recruitment process
- About Virtusa
- Goldman Sachs Interview Process
- Technical Questions for Goldman Sachs Interview
- Sample HR Question for Goldman Sachs Interview
- About Goldman Sachs
- Nagarro Recruitment Process
- Nagarro HR Interview Questions
- Nagarro Aptitude Test Questions
- Nagarro Technical Test Questions
- About Nagarro
- PwC Recruitment Process
- PwC Technical Interview Questions: Freshers and Experienced
- PwC Interview Questions for HR Rounds
- PwC Interview Preparation
- Frequently Asked Questions
- EY Technical Interview Questions (2023)
- EY Interview Questions for HR Round
- About EY
- Morgan Stanley Recruitment Process
- HR Questions for Morgan Stanley Interview
- HR Questions for Morgan Stanley Interview
- About Morgan Stanley
- Recruitment Process at Flipkart
- Technical Flipkart Interview Questions
- Code-Based Flipkart Interview Questions
- Sample Flipkart Interview Questions- HR Round
- Conclusion
- FAQs
- Recruitment Process at Paytm
- Technical Interview Questions for Paytm Interview
- HR Sample Questions for Paytm Interview
- About Paytm
- Most Probable Accenture Interview Questions
- Accenture Technical Interview Questions
- Accenture HR Interview Questions
- Amazon Recruitment Process
- Amazon Interview Rounds
- Common Amazon Interview Questions
- Amazon Interview Questions: Behavioral-based Questions
- Amazon Interview Questions: Leadership Principles
- Company-specific Amazon Interview Questions
- 43 Top Technical/ Coding Amazon Interview Questions
- Juspay Recruitment: Stages and Timeline
- Juspay Interview Questions and Answers
- How to prepare for Juspay interview questions
- Prepare for the Juspay Interview: Stages and Timeline
- Frequently Asked Questions
- Adobe Interview Questions - Technical
- Adobe Interview Questions - HR
- Recruitment Process at Adobe
- About Adobe
- Cisco technical interview questions
- Sample HR interview questions
- The recruitment process at Cisco
- About Cisco
- JP Morgan interview questions (Technical round)
- JP Morgan interview questions HR round)
- Recruitment process at JP Morgan
- About JP Morgan
- Wipro Elite NTH: Selection Process
- Wipro Elite NTH Technical Interview Questions
- Wipro Elite NTH Interview Round- HR Questions
- BYJU's BDA Interview Questions
- BYJU's SDE Interview Questions
- BYJU's HR Round Interview Questions
- A Quick Overview of the KPMG Recruitment Process
- Technical Questions for KPMG Interview
- HR Questions for KPMG Interview
- About KPMG
- DXC Technology Interview Process
- DCX Technical Interview Questions
- Sample HR Questions for DXC Technology
- About DXC Technology
- Recruitment Process at PayPal
- Technical Questions for PayPal Interview
- HR Sample Questions for PayPal Interview
- About PayPal
- Capgemini Recruitment Rounds
- Capgemini Interview Questions: Technical round
- Capgemini Interview Questions: HR round
- Preparation tips
- FAQs
- Technical interview questions for Siemens
- Sample HR questions for Siemens
- The recruitment process at Siemens
- About Siemens
- HCL Technical Interview Questions
- HR Interview Questions
- HCL Technologies Recruitment Process
- List of EPAM Interview Questions for Technical Interviews
- About EPAM
- Atlassian Interview Process
- Top Skills for Different Roles at Atlassian
- Atlassian Interview Questions: Technical Knowledge
- Atlassian Interview Questions: Behavioral Skills
- Atlassian Interview Questions: Tips for Effective Preparation
- Walmart Recruitment Process
- Walmart Interview Questions and Sample Answers (HR Round)
- Walmart Interview Questions and Sample Answers (Technical Round)
- Tips for Interviewing at Walmart and Interview Preparation Tips
- Frequently Asked Questions
- Uber Interview Questions For Engineering Profiles: Coding
- Technical Uber Interview Questions: Theoretical
- Uber Interview Question: HR Round
- Uber Recruitment Procedure
- About Uber Technologies Ltd.
- Intel Technical Interview Questions
- Computer Architecture Intel Interview Questions
- Intel DFT Interview Questions
- Intel Interview Questions for Verification Engineer Role
- Recruitment Process Overview
- Important Accenture HR Interview Questions
- Points to remember
- What is Selenium?
- What are the components of the Selenium suite?
- Why is it important to use Selenium?
- What's the major difference between Selenium 3.0 & Selenium 2.0?
- What is Automation testing and what are its benefits?
- What are the benefits of Selenium as an Automation Tool?
- What are the drawbacks to using Selenium for testing?
- Why should Selenium not be used as a web application or system testing tool?
- Is it possible to use selenium to launch web browsers?
- What does Selenese mean?
- What does it mean to be a locator?
- Identify the main difference between "assert", and "verify" commands within Selenium
- What does an exception test in Selenium mean?
- What does XPath mean in Selenium? Describe XPath Absolute & XPath Relation
- What is the difference in Xpath between "//"? and "/"?
- What is the difference between "type" and the "typeAndWait" commands within Selenium?
- Distinguish between findElement() & findElements() in context of Selenium
- How long will Selenium wait before a website is loaded fully?
- What is the difference between the driver.close() and driver.quit() commands in Selenium?
- Describe the different navigation commands that Selenium supports
- What is Selenium's approach to the same-origin policy?
- Explain the difference between findElement() in Selenium and findElements()
- Explain the pause function in SeleniumIDE
- Explain the differences between different frameworks and how they are connected to Selenium's Robot Framework
- What are your thoughts on the Page Object Model within the context of Selenium
- What are your thoughts on Jenkins?
- What are the parameters that selenium commands come with a minimum?
- How can you tell the differences in the Absolute pathway as well as Relative Path?
- What's the distinction in Assert or Verify declarations within Selenium?
- What are the points of verification that are in Selenium?
- Define Implicit wait, Explicit wait, and Fluent
- Can Selenium manage windows-based pop-ups?
- What's the definition of an Object Repository?
- What is the main difference between obtainwindowhandle() as well as the getwindowhandles ()?
- What are the various types of Annotations that are used in Selenium?
- What is the main difference in the setsSpeed() or sleep() methods?
- What is the way to retrieve the alert message?
- How do you determine the exact location of an element on the web?
- Why do we use Selenium RC?
- What are the benefits or advantages of Selenium RC?
- Do you have a list of the technical limitations when making use of Selenium RC? Selenium RC?
- What's the reason to utilize the TestNG together with Selenium?
- What Language do you prefer to use to build test case sets in Selenium?
- What are Start and Breakpoints?
- What is the purpose of this capability relevant in relation to Selenium?
- When do you use AutoIT?
- Do you have a reason why you require Session management in Selenium?
- Are you able to automatize CAPTCHA?
- How can we launch various browsers on Selenium?
- Why should you select Selenium rather than QTP (Quick Test Professional)?
- Airbus Interview Questions and Answers: HR/ Behavioral
- Industry/ Company-Specific Airbus Interview Questions
- Airbus Interview Questions and Answers: Aptitude
- Airbus Software Engineer Interview Questions and Answers: Technical
- Importance of Spring Framework
- Spring Interview Questions (Basic)
- Advanced Spring Interview Questions
- C++ Interview Questions and Answers: The Basics
- C++ Interview Questions: Intermediate
- C++ Interview Questions And Answers With Code Examples
- C++ Interview Questions and Answers: Advanced
- Test Your Skills: Quiz Time
- MBA Interview Questions: B.Com Economics
- B.Com Marketing
- B.Com Finance
- B.Com Accounting and Finance
- Business Studies
- Chartered Accountant
- Q1. Please tell us something about yourself/ Introduce yourself to us.
- Q2. Describe yourself in one word.
- Q3. Tell us about your strengths and weaknesses.
- Q4. Why did you apply for this job/ What attracted you to this role?
- Q5. What are your hobbies?
- Q6. Where do you see yourself in five years OR What are your long-term goals?
- Q7. Why do you want to work with this company?
- Q8. Tell us what you know about our organization
- Q9. Do you have any idea about our biggest competitors?
- Q10. What motivates you to do a good job?
- Q11. What is an ideal job for you?
- Q12. What is the difference between a group and a team?
- Q13. Are you a team player/ Do you like to work in teams?
- Q14. Are you good at handling pressure/ deadlines?
- Q15. When can you start?
- Q16. How flexible are you regarding overtime?
- Q17. Are you willing to relocate for work?
- Q18. Why do you think you are the right candidate for this job?
- Q19. How can you be an asset to the organization?
- Q20. What is your salary expectation?
- Q21. How long do you plan to remain with this company?
- Q22. What is your objective in life?
- Q23. Would you like to pursue your Master's degree anytime soon?
- Q24. How have you planned to achieve your career goal?
- Q25. Can you tell us about your biggest achievement in life?
- Q26. What was the most challenging decision you ever made?
- Q27. What kind of work environment do you prefer to work in?
- Q28. What is the difference between a smart worker and a hard worker?
- Q29. What will you do if you don't get hired?
- Q30. Tell us three things that are most important for you in a job.
- Q31. Who is your role model and what have you learned from him/her?
- Q32. In case of a disagreement, how do you handle the situation?
- Q33. What is the difference between confidence and overconfidence?
- Q34. If you have more than enough money in hand right now, would you still want to work?
- Q35. Do you have any questions for us?
- Interview Tips for Freshers
- Tell me about yourself
- What are your greatest strengths?
- What are your greatest weaknesses?
- Tell me about something you did that you now feel a little ashamed of
- Why are you leaving (or did you leave) this position??
- 15+ resources for preparing most-asked interview questions
- CoCubes Interview Process Overview
- Common CoCubes Interview Questions
- Key Areas to Focus on for CoCubes Interview Preparation
- Conclusion
- Frequently Asked Questions (FAQs)
- Data Analyst Interview Questions With Answers
- About Data Analyst
Tech Mahindra Interview Questions For Technical And HR Round (2026)
Tech Mahindra Limited, founded in 1986, is a leading multinational tech consulting company. Its headquarter is in Pune, Maharashtra, India. The company has branches in more than 60 countries and has over 125,000 employees from around 90 countries. Tech Mahindra is among the top five IT firms. It ranks 47th on the Fortune India 500 list. The company serves industries in all areas, such as health care, manufacturing, retail, etc. Further, its services include Digital Infrastructure, Digital Supply Chain, Cyber Security, etc.
The company conducts regular recruitment drives, and job seekers worldwide can apply. You can go through the details of the Tech Mahindra Recruitment process here.
Eligibility Criteria For Tech Mahindra Interview
Candidates appearing for Tech Mahindra interviews must have above 70% marks in X, XII, and graduation. They must be BE, B.Tech, MCA, ME, or M.Tech graduates and must satisfy the following criteria:
- No backlogs
- Education gap: Not more than one year
- Qualifying degrees must be for full time courses
Tech Mahindra Recruitment Rounds & Assessments
The hiring process of Tech Mahindra includes four rounds:
- Written Round
- Technical Written Round
- Technical Round
- HR Round

Tech Mahindra Interview Questions: Technical Round
To ace the Tech Mahindra interview questions for the technical round you must know computer science fundamentals, such as data structures, algorithms, database management systems, etc. You may get interview questions about your internships or projects. Try to highlight the problem and the solutions while talking about them. Some of the common Tech Mahindra interview questions are listed below.
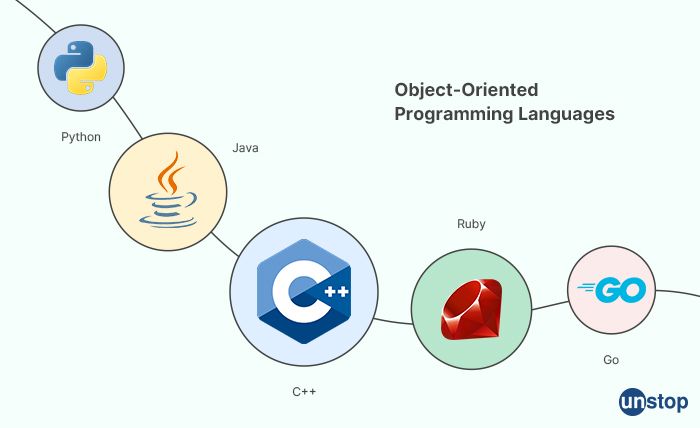
1. What are object-oriented programming languages?
Object-oriented programming (OOP) languages are a type of programming language that focuses on organizing code into reusable objects or classes, which encapsulate data and behavior. OOP languages are designed to model real-world entities and their interactions, making it easier to represent complex systems and solve problems in a modular and organized manner. Some popular object-oriented programming languages include:
-
Java: Java is a widely used and popular OOP language known for its "write once, run anywhere" (WORA) feature, which allows Java code to be run on different platforms without recompilation.
-
Python: Python is a versatile and dynamically-typed OOP language that is widely used in various domains, such as web development, scientific computing, data analysis, and artificial intelligence (AI).
-
C++: C++ is a powerful and performance-oriented OOP language that is commonly used for system programming, game development, and embedded systems, as it provides low-level memory manipulation and efficient execution.
-
C#: C# (pronounced as "C-sharp") is a Microsoft-developed OOP language that is primarily used for Windows desktop applications, game development with Unity, and enterprise-level applications using the .NET framework.
-
Ruby: Ruby is a dynamic and flexible OOP language known for its elegant syntax and focus on developer productivity. It is often used in web development with popular frameworks like Ruby on Rails.
-
PHP: PHP is a widely used OOP language specifically designed for server-side web development. It is commonly used to build dynamic websites and web applications.
-
Swift: Swift is an OOP language developed by Apple for iOS, macOS, watchOS, and tvOS app development. It is known for its safety features, modern syntax, and performance optimization for Apple platforms.
2. What are the methods of Request Dispatcher?
RequestDispatcher is an interface in Java Servlet API that provides methods for dispatching requests from one servlet to another or from a servlet to a JSP page. The methods of RequestDispatcher are:
-
forward(ServletRequest request, ServletResponse response): This method forwards the request and response objects from the current servlet to another servlet or JSP page for further processing. The original request and response objects are not visible to the client, and the forwarded servlet or JSP page can generate a response that is sent back to the client.
-
include(ServletRequest request, ServletResponse response): This method includes the response of another servlet or JSP page in the response of the current servlet. The original request and response objects are visible to the client, and the included servlet or JSP page can generate output that is merged with the output of the current servlet and sent back to the client.
3. Mention some features of modular programming.
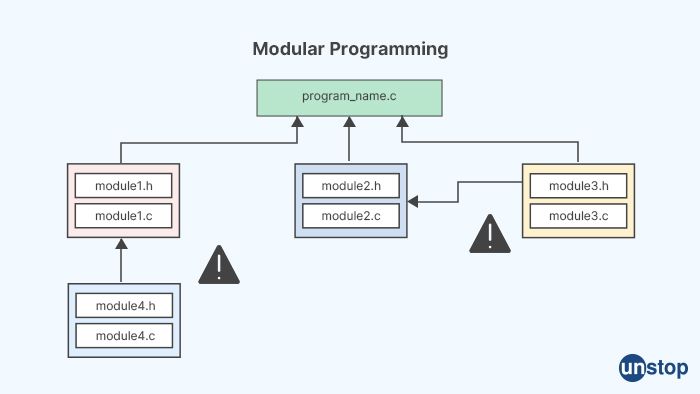
Here are some features of modular programming:
-
Modularity: Modular programming promotes the use of self-contained, independent modules that can be developed, tested, and maintained separately. Each module focuses on a specific task or functionality, making it easier to understand and modify.
-
Encapsulation: Modules in modular programming encapsulate their implementation details, hiding them from other modules. This helps to reduce complexity and improve maintainability, as changes to the implementation of one module do not affect other modules.
-
Abstraction: It encourages the use of abstraction, where modules provide well-defined interfaces to communicate with other modules. This allows programmers to work at a higher level of abstraction, focusing on the overall logic and functionality of the program, without worrying about the internal details of each module.
-
Reusability: Modular programming promotes the reuse of modules in different programs, as modules can be developed independently and plugged into different applications. This can save development time and effort, and also improve consistency and reliability across multiple projects.
-
Scalability: It also allows for easy scalability, as new modules can be added or existing modules can be modified without affecting the entire program. This makes it easier to adapt the program to changing requirements or to extend its functionality.
-
Maintainability: It improves code maintainability, as each module has a clear purpose and responsibility, making it easier to locate and fix bugs or make updates. It also promotes code readability, as modules can be designed with a clear and consistent structure.
-
Testability: Modular programming facilitates unit testing, as modules can be tested independently, isolated from the rest of the program. This makes it easier to identify and fix issues during the testing phase of software development.
-
Collaboration: It promotes team collaboration, as modules can be assigned to different team members for development, testing, and maintenance. This allows for parallel development, making it easier to manage large and complex projects.
-
Flexibility: It provides flexibility, as modules can be replaced or modified without affecting the overall program. This allows for easy updates or modifications to specific functionalities, without having to rewrite the entire program.
-
Performance: Modular programming can improve performance, as modules can be optimized independently, and unnecessary modules can be removed without affecting the rest of the program. This can lead to more efficient and faster code execution.
4. Explain the difference between request processor and request dispatcher.
Here's a brief explanation of the difference between the two:
Request Processor: A request processor is responsible for handling incoming HTTP requests from clients, such as web browsers or API clients. It typically performs tasks such as parsing the incoming request, extracting relevant information such as the requested URL, HTTP method, headers, and query parameters, and validating the request for correctness. The request processor may also handle tasks such as authentication, authorization, and input validation, before passing the request to the appropriate request handler or controller for further processing.
Request Dispatcher: A request dispatcher, on the other hand, is responsible for routing incoming requests to the appropriate request handler or controller for further processing. It receives requests from the request processor and determines the appropriate destination for the request based on predefined rules or configurations. The request dispatcher may use various routing techniques, such as URL-based routing, path-based routing, or parameter-based routing, to determine the correct request handler or controller to handle the request. Once the request is routed to the appropriate handler, the request dispatcher hands over the control to the handler to perform the necessary processing, such as generating a response or executing business logic.
5. What is a 2-ary tree?
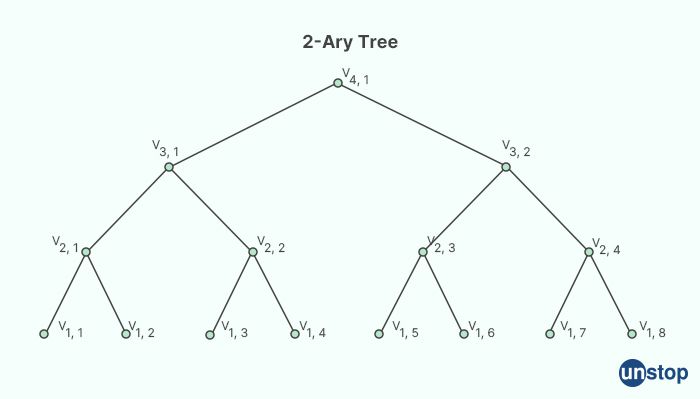
A 2-ary tree, also known as a binary tree, is a type of tree data structure in which each node has at most two child nodes, typically referred to as the left child and the right child. The binary tree is a fundamental data structure widely used in computer science and programming for tasks such as searching, sorting, and organizing data in a hierarchical manner.
In a binary tree, each node can have zero, one, or two child nodes. The child nodes of a binary tree are organized in a way that each node can have at most one parent node. The child nodes are usually arranged in a way that satisfies a specific ordering property, such as the "left child is smaller, and the right child is larger" property in a binary search tree.
6. Discuss the techniques of memory management in C++.
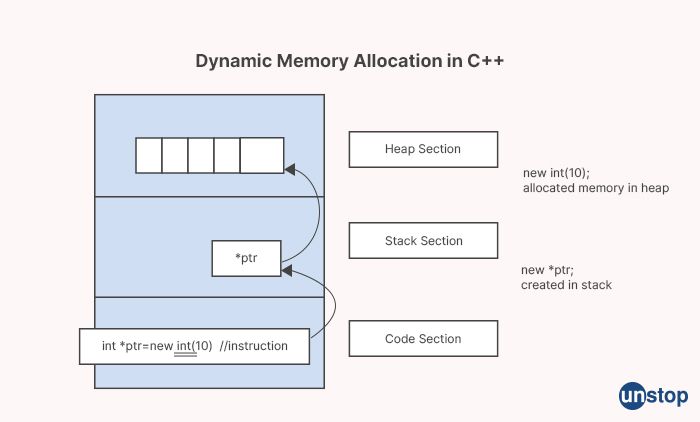
Memory management in C++ involves the allocation and deallocation of memory for objects during program execution. C++ provides several techniques for managing memory, including:
-
Stack allocation: Memory is allocated on the stack for automatic (local) static variables within functions. The stack is a region of memory that is automatically managed by the compiler, and the memory allocated on the stack is automatically deallocated when it goes out of scope. Stack allocation is efficient and fast, but the amount of memory that can be allocated on the stack is limited.
-
Heap allocation: Memory can be allocated on the heap using dynamic memory allocation operators, such as "new" and "new[]". Heap allocation allows for dynamic allocation of memory during runtime, and the memory remains allocated until explicitly deallocated using the "delete" and "delete[]" operators. Heap allocation provides greater flexibility in terms of memory size and lifetime, but it requires careful management to avoid memory leaks and other issues.
-
Smart pointers: C++11 and later versions provide smart pointers, which are special types of pointers that automatically manage the memory they point to. Smart pointers, such as "std::unique_ptr" and "std::shared_ptr", use RAII (Resource Acquisition Is Initialization) technique to automatically deallocate memory when it is no longer needed or when the owning object goes out of scope. Smart pointers help prevent memory leaks and simplify memory management in C++ programs.
-
Memory pools: Memory pools are pre-allocated regions of memory that are used for object allocation and deallocation. Memory pools can be implemented using custom memory management techniques, such as fixed-size block allocation or object pooling, to optimize memory usage and reduce overhead associated with dynamic memory allocation and deallocation.
-
Custom memory management: C++ allows for custom memory management techniques, where programmers can implement their own memory allocation and deallocation routines using specialized memory management libraries or techniques. Custom memory management can be useful in specific scenarios where fine-grained control over memory allocation and deallocation is required, or to optimize memory usage for specific use cases.
7. Define reentrancy in multiprogramming systems that use time-sharing.
Reentrancy in multiprogramming systems that use time-sharing refers to the ability of a program or subroutine to be executed concurrently by multiple users or processes without interference or contention for shared resources. In other words, a reentrant program or subroutine can be safely executed by multiple users or processes simultaneously without causing conflicts or unexpected behaviors.
In a time-sharing system, multiple users or processes share system resources, such as CPU time, memory, and I/O devices, concurrently. Each user or process is allocated a time slice or quantum of CPU time to execute their tasks, and then the CPU is switched to another user or process. This allows multiple users or processes to run concurrently and share the system resources efficiently.
In such a system, reentrant programs or subroutines are designed in a way that they do not depend on a global or shared state that can be modified by other users or processes. They do not rely on shared resources or maintain a global state that can be accessed or modified by multiple users or processes simultaneously. Instead, reentrant programs or subroutines use local state or private data that is specific to each invocation, and do not interfere with the state of other users or processes.
8. Explain the concept of destructors in C++.
In C++, a destructor is a special member function of a class that is called automatically when an object of that class goes out of scope or is explicitly deleted. A destructor has the same name as the class with a tilde (~) prefix, and it is used to clean up resources, such as memory allocations, file handles, and other system resources, that were acquired by the object during its lifetime.
The main purpose of a destructor is to perform cleanup operations for an object before it is destroyed, to prevent resource leaks and ensure proper management of resources. Destructors are especially useful for classes that manage resources that are not automatically reclaimed by the system, such as dynamically allocated memory, file handles, database connections, or other external resources.
9. What is structured programming?
Structured programming is a programming paradigm that emphasizes the use of structured flow control constructs, such as loops, conditionals, and subroutines, to create well-organized, modular, and efficient code. Structured programming aims to improve the clarity, readability, and maintainability of software by using a disciplined approach to programming that avoids unstructured or "spaghetti" code.
Structured programming has been widely used in various programming languages, such as C, Pascal, and Fortran, and it has laid the foundation for other programming paradigms, such as object-oriented programming and procedural programming. It is still considered an important approach to software development, as it promotes good coding practices, maintainability, and code reusability.
10. Explain checkpoints in Database Management Systems.
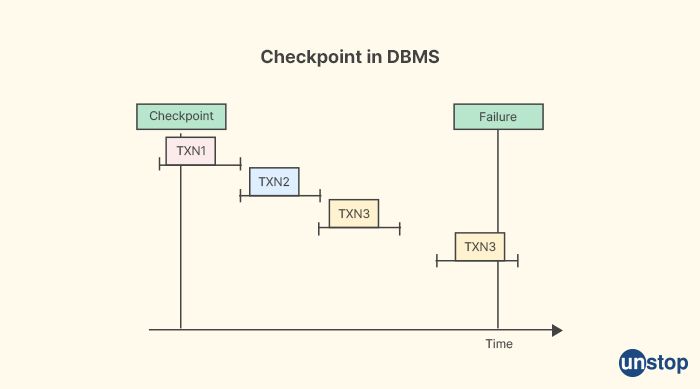
In the context of database management systems (DBMS), checkpoints refer to a mechanism used to ensure the consistency and durability of data in a database. Checkpoints are used in DBMS to periodically save the changes made to the database from the main memory to a stable storage medium, such as disk, to prevent data loss or inconsistencies in case of system failures or crashes.
Checkpoints are typically implemented as a background process or a system task that runs periodically or based on specific triggers. When a checkpoint is triggered, the DBMS performs the following tasks:
-
Write Modified Pages to Disk: The DBMS writes all the modified data pages in the buffer pool (i.e., the portion of main memory used to temporarily hold data pages from the disk) that have not been written to disk since the last checkpoint to stable storage, such as a disk. This ensures that any changes made to the data in the main memory are persisted on disk and are not lost in case of a system failure.
-
Update Checkpoint Record: The DBMS updates a checkpoint record or log, which keeps track of the checkpoint information, such as the log sequence number (LSN) or the transaction log records that have been flushed to disk. This information is used during recovery processes to restore the database to a consistent state in case of failures.
-
Flush Transaction Logs: The DBMS flushes any transaction logs or log buffers that contain records of committed transactions to disk. Transaction logs are used to record changes made to the database during transactions and are crucial for maintaining data consistency and durability in case of failures.
-
Update Metadata: The DBMS updates metadata or system catalog information that keeps track of the database schema, data structures, and other database-related information. This ensures that the metadata is also persisted to disk and reflects the latest changes made to the database.
11. What is a binary tree insertion?
Binary tree insertion is the process of adding a new node with a specified value to a binary tree data structure in a way that maintains the binary tree's properties. A binary tree is a tree data structure in which each node can have at most two child nodes, and it has the following properties:
-
Left Subtree Property: The value of the node in the left subtree is less than the value of the parent node.
-
Right Subtree Property: The value of the node in the right subtree is greater than or equal to the value of the parent node.
Binary tree insertion involves finding the appropriate position in the binary tree to add the new node while maintaining these properties. The insertion process typically starts at the root node and follows a recursive or iterative approach to search for the correct position to insert the new node.
12. Are there different types of integration testing?
Yes, integration testing is a type of software testing that focuses on testing the integration and interactions between different components or modules of a software system. There are several different types of integration testing, including:
-
Big Bang Integration Testing: In this approach, all the individual components or modules of a software system are integrated together at once, and the integrated system is tested as a whole. This approach is typically used when the system is relatively small, and the components are not complex or tightly interdependent. However, it can be challenging to identify and isolate issues when testing the entire system at once.
-
Top-down Integration Testing: In this approach, testing starts with the higher-level or top-level components of the system, and lower-level components are gradually integrated and tested. This approach allows for early testing of higher-level functionality and helps in identifying issues related to higher-level interactions. Placeholder or stub components may be used to simulate the behavior of lower-level components that are not yet integrated.
-
Bottom-up Integration Testing: In this approach, testing starts with the lower-level or foundational components of the system, and higher-level components are gradually integrated and tested. This approach allows for early testing of lower-level functionality and helps in identifying issues related to lower-level interactions. Drivers or test harnesses may be used to simulate the behavior of higher-level components that are not yet integrated.
-
Incremental Integration Testing: In this approach, components or modules are incrementally integrated and tested in a specific order based on priority or dependency, and the integrated system is tested at each step. This approach allows for early testing of critical or high-priority components, and incremental additions of components provide more frequent feedback on system functionality and issues.
-
Hybrid Integration Testing: This approach combines elements of the above-mentioned integration testing approaches, depending on the specific needs and characteristics of the software system being tested. For example, a combination of top-down and bottom-up integration testing may be used to strike a balance between testing higher-level and lower-level components, based on the complexity and dependencies of the system.
13. How is #include <file> different from #include "file"?
In C and C++ programming languages, the "#include" preprocessor directive is used to include external files into a source code file. There are two different ways to specify the file to be included: using angle brackets ("< >") or using double quotes (" ").
Here are the key differences between "#include <file>" and "#include "file"":
-
Search Path: When using angle brackets ("< >"), the compiler searches for the file in the system or standard include directories, which are typically predefined by the compiler installation. These directories contain header files that are part of the standard library or other system-level libraries.
-
Standard Library Files: "#include <file>" is typically used for including standard library files, such as headers from the C or C++ standard libraries, which provide standard functions, macros, and definitions that are part of the language specification.
-
Compiler-Specific Files: Some compilers may also provide additional system-specific or compiler-specific header files that can be included using angle brackets ("< >"). These files are not part of the standard library and may provide platform-specific functionality.
-
User-Defined Files: When using double quotes (" "), the compiler searches for the file in the current directory or other directories specified by the user, and it treats the file as a user-defined or project-specific header file.
-
Relative vs Absolute Path: When using double quotes (" "), the file path can be either relative or absolute. If a relative path is used, the compiler searches for the file relative to the current directory of the source file that includes it. If an absolute path is used, the compiler looks for the file at the specified absolute path.
14. Describe function overloading.

Function overloading is a feature in programming languages that allows defining multiple functions with the same name but different parameter lists or argument types. This means that in a program, you can have multiple functions with the same name, but each function can have a unique set of parameters or arguments.
The key characteristics of function overloading are:
-
Function Name: Multiple functions with the same name can be defined in the same scope or class, as long as they have different parameter lists. For example, you can define two functions with the same name "print" in a class, where one takes an integer parameter and the other takes a string parameter.
-
Parameter List: Functions in function overloading must have different parameter lists, which can include differences in the number of parameters, types of parameters, or the order of parameters. For example, you can define functions "add(int a, int b)" and "add(float a, float b)" as overloaded functions, where one takes two integers as arguments and the other takes two floats.
-
Return Type: The return type of a function is not considered as part of the function overloading criteria. Two functions can have the same name, same parameter list, but different return types, and they can still be considered overloaded functions.
-
Compile-time Resolution: The correct overloaded function to be called is determined by the compiler at compile-time based on the number, types, and order of arguments passed during function invocation. This is also known as compile-time polymorphism or static polymorphism.
Never miss a job or internship opportunity! Stay Ahead!
15. Differentiate between swapping and paging.
Swapping and paging are two memory management techniques used in operating systems to handle the allocation and management of memory for processes. Here are the key differences between swapping and paging:
Swapping:
- Whole Process: In swapping, the entire process is moved in and out of main memory (RAM) as a whole.
- I/O Overhead: Swapping involves significant I/O overhead as the entire process, including all its data and instructions, needs to be swapped in and out of main memory.
- External Fragmentation: Swapping can cause external fragmentation, as the processes may not fit into available contiguous blocks of memory, leading to unused memory blocks scattered throughout the system.
- Memory Requirement: The entire process, including both code and data, must fit into the available main memory for swapping to occur. If a process exceeds the available memory, it cannot be swapped in.
Paging:
- Fixed-size Pages: Paging divides the physical memory into fixed-size pages and the processes into fixed-size blocks called pages, which may not be equal to the size of the physical memory pages.
- Granularity: Paging allows for finer-grained memory allocation as compared to swapping, as only the required pages of a process are loaded into the main memory, instead of the entire process.
- Page Table: Paging uses a page table to map virtual addresses to physical addresses, allowing for efficient address translation.
- No External Fragmentation: Paging does not suffer from external fragmentation, as the fixed-size pages can be allocated and deallocated independently, without leaving behind unused memory blocks.
- Memory Requirement: In paging, the physical memory can be utilized more efficiently, as only the required pages of a process need to be loaded into memory, and the rest can be kept on secondary storage, such as a disk.
16. What are spooling operating systems?
Spooling (Simultaneous Peripheral Operations On-Line) is a technique used in computer operating systems to buffer input and output data for devices such as printers, plotters, and disk drives. It allows multiple processes or users to share a single device efficiently by queueing the input/output (I/O) requests and spooling them to the device one at a time, in a sequential manner.
In a spooling system, instead of sending data directly to the device, the data is first stored in a buffer, often in a disk file called a "spool file" or "spool queue". The spool file holds the data temporarily until the device is ready to process it. The spooling system manages the spool files and the order in which the I/O requests are sent to the device, ensuring that they are processed in a sequential and efficient manner.
Spooling provides several benefits in operating systems, including:
-
Device independence: Spooling process allows different processes or users to submit I/O requests to a single device without having to worry about the specific characteristics or availability of the device. The spooling system takes care of buffering and queuing the requests, providing a level of abstraction and device independence to the processes or users.
-
Parallelism: Spooling process enables multiple processes or users to submit I/O requests to the same device simultaneously. The spooling system can buffer and queue the requests, allowing them to be processed in parallel, which can improve system throughput and efficiency.
-
Background processing: Spooling process allows I/O requests to be queued and processed in the background while the submitting process or user can continue with other tasks. This can improve the overall responsiveness and performance of the system by allowing processes or users to continue working without waiting for I/O requests to complete.
-
Error recovery: Spooling systems can handle errors or failures that may occur during I/O operations, such as device failures or data transmission errors. The spooling system can detect and handle these errors, allowing the submitting process or user to be notified of the failure and take appropriate action.
-
Print management: Spooling process is commonly used in print management systems, where print jobs from multiple users or processes are queued and processed in the order they are submitted. This allows for efficient printing of documents, prevents conflicts or contention for the printer, and provides features such as print job prioritization, job cancellation, and print queue management
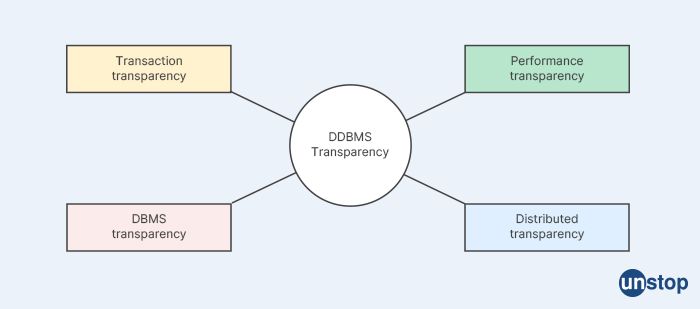
17. Explain the concept of transparent Distributed Database Management Systems?
Transparent Distributed Database Management Systems (DDBMS) refer to a type of distributed database management system where the distribution of data across multiple nodes or sites is hidden from the users and applications accessing the database. In other words, the distributed nature of the database is transparent or hidden, and users and applications interact with the database as if it were a single, centralized database.
The concept of transparency in DDBMS can encompass various aspects, including:
-
Location transparency: The physical location of data in a distributed database is abstracted, and users and applications can access the data without needing to know where it is physically stored. Data can be distributed across multiple nodes or sites, but users and applications can interact with the database using a single logical name or identifier for the data, without having to specify the actual physical location.
-
Fragmentation transparency: Data fragmentation, which involves dividing the data into smaller pieces and storing them on different nodes, is hidden from users and applications. Users and applications can access the data as if it were stored in a single, unified database, without needing to be aware of the fragmentation and distribution of data across multiple nodes.
-
Replication transparency: Data replication, which involves creating and maintaining multiple copies of data on different nodes for redundancy and fault tolerance, is hidden from users and applications. Users and applications can access the data without needing to know how many copies of the data exist or which specific copies are being accessed.
-
Transaction transparency: The execution of distributed transactions, which involve multiple operations on different nodes and need to be coordinated and managed to ensure consistency and integrity, is hidden from users and applications. Users and applications can perform transactions on the distributed database as if it were a single, centralized database, without needing to explicitly manage the distributed nature of the transactions.
18. What is the difference between a file and a storage structure?
A file and a storage structure are two related but distinct concepts in computer science and data storage. Here's how they differ:
File: A file is a named collection of related data that is stored on a secondary storage device, such as a hard disk, SSD, or magnetic tape. Files are used to organize and store data in a hierarchical manner, with directories or folders containing files, and files containing data. Files can be of various types, such as text files, binary files, image files, audio files, and more. Files are typically managed by an operating system or a file system, which provides the abstraction and interface for creating, reading, writing, and managing files.
Storage structure: A storage structure refers to the way data is organized and stored within a file or a data structure in memory. It determines the layout, format, and organization of data, and how it is accessed and manipulated. Storage structures can be simple or complex, depending on the requirements of the data and the operations that need to be performed on it. Examples of storage structures include arrays, linked lists, hash tables, trees, and databases.
19. How is multithreaded programming useful?
Multithreaded programming, also known as concurrent programming, involves the concurrent execution of multiple threads within a single process. Each thread represents an independent flow of execution that can perform tasks concurrently with other threads, sharing the same memory space and system resources. Multithreading can be highly beneficial in a number of ways:
-
Increased responsiveness: Multithreading can improve the responsiveness of a program or system by allowing tasks to be performed concurrently. For example, in a graphical user interface (GUI) application, the main thread can handle user input and respond to events, while separate threads can perform time-consuming tasks, such as file I/O, network communication, or data processing, in the background without blocking the main thread. This helps prevent the application from becoming unresponsive or "freezing" during lengthy operations.
-
Improved performance: Multithreading can lead to improved performance by leveraging multiple CPU cores or processors in a system. Modern computers often have multiple CPU cores, and multithreading can take advantage of these cores to parallelize tasks and perform them concurrently, leading to faster execution times. This is especially beneficial for compute-intensive or data-intensive applications, such as scientific simulations, multimedia processing, and data analysis.
-
Enhanced scalability: Multithreading can enable applications to scale their performance with the available hardware resources. By utilizing multiple threads, an application can take advantage of the increasing number of CPU cores in modern processors and achieve better scalability as the number of cores or processors increases. This can help applications perform well on a wide range of hardware configurations, from single-core systems to high-end multi-core processors and multi-processor systems.
-
Simplified programming model: Multithreading can simplify the programming model for certain types of tasks by allowing them to be expressed as separate threads of execution. For example, in a client-server application, separate threads can handle incoming client requests concurrently, allowing for more efficient handling of multiple clients without having to manage multiple processes or multiple instances of the application. This can result in cleaner, more modular code and easier maintenance.
-
Flexibility and responsiveness to changing requirements: Multithreading can provide flexibility in handling changing requirements in a program or system. For example, as the workload or the number of users increases, additional threads can be added to handle the increased load, providing more responsiveness and scalability. Conversely, as the workload decreases, threads can be scaled down to conserve resources.
20. Describe inline functions in C and C++.
In C and C++, an inline function is a function whose code is inserted directly into the calling code during compilation, instead of being called as a separate function at runtime. Inline functions are a form of compiler optimization that can improve performance by eliminating the overhead of function call and return operations.
In C++, inline functions are defined using the inline keyword, either explicitly or implicitly. The inline function definition is typically placed in a header file, which is included in multiple source files. When the inline function is called in the source code, the compiler replaces the function call with the actual function code, as if the code was written directly at the call site. This avoids the overhead of function call and return operations, and can result in faster execution.
Here's an example of an inline function in C++:
// Declaration of an inline function
inline int add(int a, int b) {
return a + b;
}// Usage of the inline function
int result = add(5, 10);
In C, the inline keyword is not supported, but some compilers may provide similar functionality using compiler-specific extensions, such as __inline in GCC or __inline__ in Clang. However, in C, the compiler is free to ignore the inline keyword and treat the function as a regular function. In practice, the inlining of functions in C is less common compared to C++, as it is not well-supported by the C language standard.
21. What are microkernels in an operating system?
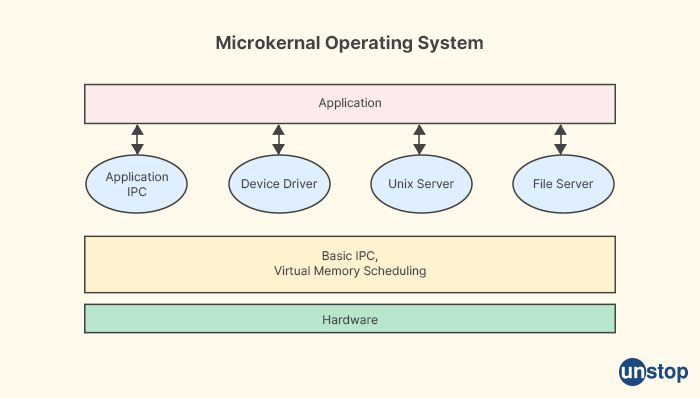
Microkernels are a type of operating system kernel architecture that aims to minimize the size and complexity of the kernel by providing only essential operating system services, while moving most of the traditional operating system functions and services, such as device drivers, file systems, and networking protocols, out of the kernel and into separate user-level processes known as servers. In a microkernel-based operating system, the kernel provides only basic functionality, such as inter-process communication (IPC), thread management, and memory management, while higher-level services are implemented as separate user-level processes that communicate with the kernel through well-defined interfaces.
22. List the necessary and sufficient conditions for a deadlock.
A deadlock is a situation in a computer system where two or more processes are unable to proceed because each is waiting for a resource that is being held by another process, resulting in a cyclic dependency and a system-wide deadlock. The necessary and sufficient conditions for a deadlock to occur in a system are:
-
Mutual Exclusion: At least one resource must be held in a non-shareable mode, meaning that only one process can access the resource at a time. If a process is currently holding a resource, other processes requesting the same resource must wait until it is released.
-
Hold and Wait: A process must be holding at least one resource and must be waiting for at least one more resource that is currently being held by another process. This creates a situation where processes are waiting for each other to release the resources they are holding, resulting in a cyclic dependency.
-
No Preemption: Resources cannot be forcibly taken away from a process that is holding them. A process can only release a resource voluntarily after it has completed its task or request. This means that a process holding a resource may refuse to release it until it has obtained all the resources it needs, leading to a potential deadlock.
-
Circular Wait: There must be a circular dependency among two or more processes in terms of the resources they are holding and waiting for. This means that process A is waiting for a resource held by process B, process B is waiting for a resource held by process C, and so on, until process N is waiting for a resource held by process A, completing the cycle.
23. What is a logical address space? How is it different from the physical address space?
A logical address space, also known as a virtual address space, is the address space that a process "sees" or uses when it is executing in a computer system. It is a conceptual address space that represents the memory addresses that a process uses to access its data and instructions. The logical address space is typically defined by the programming language and the operating system, and it provides an abstract view of the memory that is independent of the underlying physical memory.
On the other hand, a physical address space is the actual physical memory addresses that correspond to the physical RAM (Random Access Memory) or other memory devices in a computer system. It represents the real physical locations where data and instructions are stored in the memory.
The main differences between a logical address space and a physical address space are as follows:
-
Abstraction: The logical address space provides an abstract view of the memory that is independent of the underlying physical memory. It is defined by the programming language and the operating system, and it represents the memory addresses that a process uses to access its data and instructions. In contrast, the physical address space represents the actual physical memory addresses that correspond to the physical memory devices in the system.
-
Size and Layout: The logical address space is typically larger and continuous, spanning the entire address range that a process can access. It may be larger than the actual physical memory available in the system, allowing processes to have a larger address space than the physical memory size. The physical address space, on the other hand, is limited by the size of the physical memory available in the system and is typically divided into fixed-size blocks or pages.
-
Protection and Isolation: The logical address space provides process isolation and protection, allowing each process to have its own private address space that is protected from other processes. Processes can access their own logical address space without directly accessing the physical memory. The physical address space, on the other hand, is the actual memory that is shared by all processes and is managed by the operating system to provide memory protection and allocation.
-
Mapping: The logical address space needs to be mapped to the physical address space for actual data and instruction storage in the physical memory. This is typically done by the operating system using techniques such as virtual memory management, where logical addresses are translated to physical addresses during runtime.
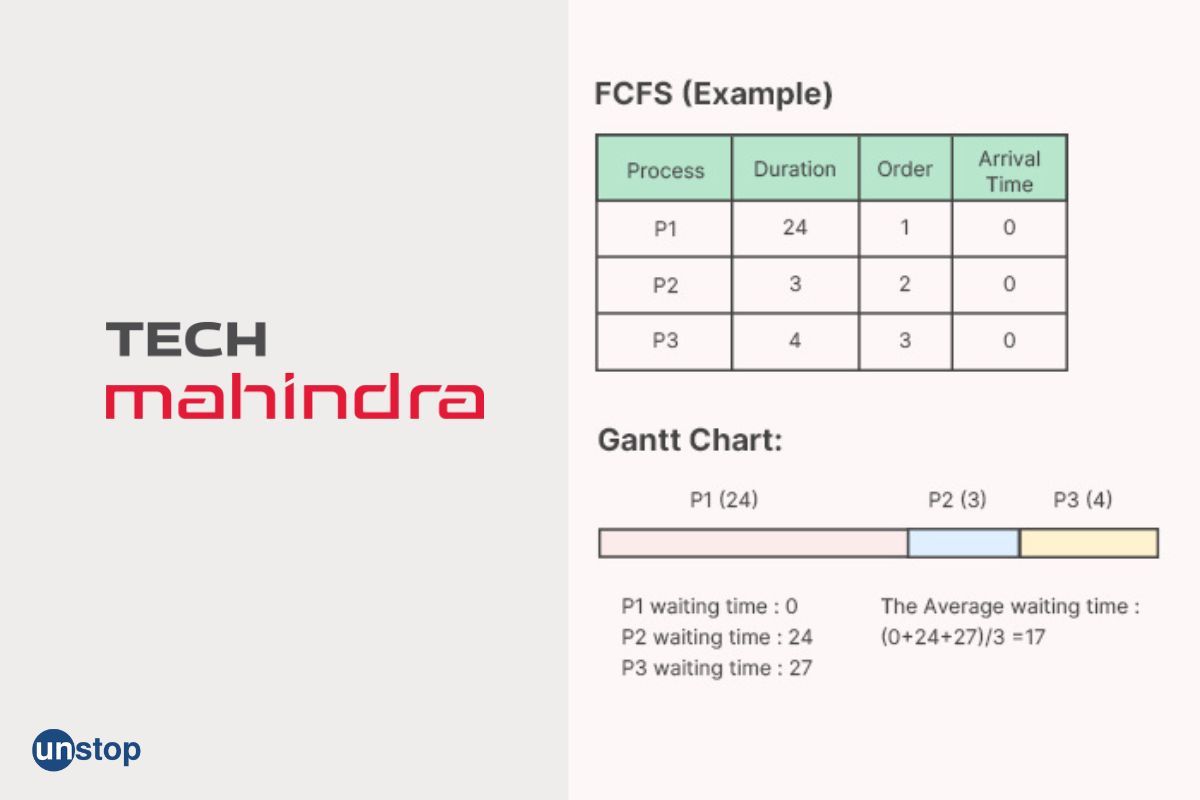
24. Explain FCFS?
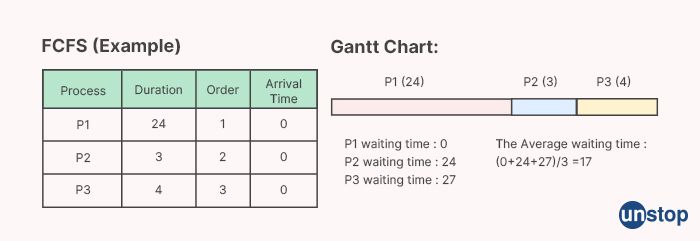
FCFS stands for "First-Come, First-Served," and it is a scheduling algorithm used in computer systems for process or task scheduling. In FCFS scheduling, the processes or tasks are executed in the order they arrive in the system, with the first process that arrives being the first one to be executed, and so on.
The FCFS scheduling algorithm follows a simple and straightforward approach, where the processes are scheduled in the order of their arrival time, without considering their execution time or priority. Once a process is allocated the CPU (Central Processing Unit) for execution, it continues to execute until it completes or is preempted by a higher-priority process or an interrupt occurs.
25. What is fragmentation?
Fragmentation refers to the division or splitting of a larger entity into smaller, disconnected parts or fragments. It can occur in various contexts, including computer systems, computer networks, databases, and storage devices. Fragmentation can have different implications depending on the context in which it occurs.
- Memory Fragmentation: In computer systems, memory fragmentation refers to the phenomenon where free memory in a computer's memory (RAM) is divided into small, non-contiguous blocks, resulting in inefficient memory utilization. There are two types of memory fragmentation: external fragmentation and internal fragmentation.
-
External Fragmentation: External fragmentation occurs when free memory is scattered in non-contiguous blocks, resulting in wasted memory that cannot be used for allocating new processes or data. It can happen due to the allocation and deallocation of memory blocks of varying sizes over time, leaving gaps or "holes" in the memory that cannot be effectively utilized.
-
Internal Fragmentation: Internal fragmentation occurs when allocated memory blocks are larger than the actual data or process that is stored in them, resulting in wasted memory space within the allocated block. It typically happens when memory is allocated in fixed-size blocks, and the allocated block is larger than the data or process that needs to be stored, leading to inefficient utilization of memory.
Tech Mahindra Interview Questions: HR Round
You can only appear in an HR interview if you clear the Tech Mahindra technical interview. It is the final round. You may get questions about your backgrounds, strengths, weaknesses, passions, regrets, etc. The questions try to assess your confidence, temperament, and communication skills. The interviewer might want to know if you can work in a highly stressful environment or a group.
1. Tell me something about Tech Mahindra.
Here, you should introduce Tech Mahindra as a subsidiary of the Mahindra Group. Then you can say that it is a multinational technology corporation that provides IT and business consulting services. You can then talk about the major projects completed by the company.
2. What are your strengths and weaknesses?
This is the most often asked interview question. It would be best if you honestly answered this question. Your answer should show that despite your strengths, you want to improve and learn despite your weaknesses.
3. Why do you think you are suitable for this role?
It would help if you started by mentioning the skills you think the job would require here. Then it would be best to tell them about the skills you have. Your answers should show that you have researched this position and care about this job.
4. Why do you want to change your current job?
An experienced employee will always get this question. You should tell them whatever the real reason is; even if it is due to better pay. It will show that you are honest. Additionally, it would be best to include your dreams and passions while answering.
5. Why do you want to work in IT?
Show your ambitions and goals while answering this Tech Mahindra interview question. The best way would be to tell a story, for example, how you got inspired by a person or technology. You can also tell them what you consider the best thing about IT.
6. Are you comfortable working 15-18 hours a day?
Here, you should be upfront if you are comfortable or not. If you can work that long, tell them a story that shows your experience. The interviewer wants to know if you are committed or not.
7. On a scale of 1-10, what would be your skill level?
It would be best if you rate yourself on the basis of the skills required for the job. Then, evaluate yourself by comparing yourself with the person who would be perfect for the job. However, whatever score you give to yourself, provide ample justification.
8. Do you like to solve problems?
In this question, you should always tell a story about how you had to face a specific challenge. And, how you overcame that. While sharing your experience, ensure that you highlight your skills.
Interview Preparation Tips
Here are some tips to ace your interviews:
- You should do thorough research on the company.
- Prepare the answers to the questions you expect the interviewer to ask. It would be best if you also prepare some questions you want to ask them; this will show your interest in the position.
- Ensure that you take care of the details, such as a good internet connection/Webcam (for online interviews) and the interview venue (for onsite interviews). Leaving them for the last minute will use the extra time, which can be better used for relaxing and thinking about your preparation.
- last but not least - dress well!
Tech Mahindra provides long-term job opportunities for its employees. Therefore, Tech Mahindra is the perfect place to start as a fresher. Its work environment is welcoming and promotes your growth as an individual and a professional. If you want to join this company, ensure that you practice the above-mentioned Tech Mahindra interview questions. These questions are just the tip of the iceberg. You should go through the tech-based study material to brush up on the fundamentals.
Suggested reads:
- 35+ Airbus Interview Questions With Answers To Help Get The Job!
- Important Capgemini Interview Questions That You Must Not Ignore!
- Top Netflix Interview Questions For Software Engineer And SRE Roles
- D. E. Shaw Interview Questions For Coding, Technical & HR Round
- Important TCS Ninja Interview Questions 2024 For Jobseekers
Login to continue reading
And access exclusive content, personalized recommendations, and career-boosting opportunities.
Don't have an account? Sign up
Never miss an
Update

Featured Opportunities
Top-Rated Practice by Students





Subscribe
to our newsletter
Blogs you need to hog!

This Is My First Hackathon, How Should I Prepare? (Tips & Hackathon Questions Inside)
D2C Admin

10 Best C++ IDEs That Developers Mention The Most!
D2C Admin

Advantages and Disadvantages of Cloud Computing That You Should Know!
D2C Admin

Is IoT Valuable? Advantages And Disadvantages Of IoT Explained
Shivangi Vatsal
Comments
Add comment