


Asian Paints Alchemy 2026
Company Interview Questions for Freshers
- TCS Technical Interview Questions & Answers
- TCS Managerial Interview Questions & Answers
- TCS HR Interview Questions & Answers
- Overview of Cognizant Recruitment Process
- Cognizant Interview Questions: Technical
- Cognizant Interview Questions: HR Round
- Overview of Wipro Technologies Recruitment Rounds
- Wipro Interview Questions
- Technical Round
- HR Round
- Online Assessment Sample Questions
- Frequently Asked Questions
- Overview of Google Recruitment Process
- Google Interview Questions: Technical
- Google Interview Questions: HR round
- Interview Preparation Tips
- About Google
- Deloitte Technical Interview Questions
- Deloitte HR Interview Questions
- Deloitte Recruitment Process
- Technical Interview Questions and Answers
- Level 1 difficulty
- Level 2 difficulty
- Level 3 difficulty
- Behavioral Questions
- Eligibility Criteria for Mindtree Recruitment
- Mindtree Recruitment Process: Rounds Overview
- Skills required to crack Mindtree interview rounds
- Mindtree Recruitment Rounds: Sample Questions
- About Mindtree
- Preparing for Microsoft interview questions
- Microsoft technical interview questions
- Microsoft behavioural interview questions
- Aptitude Interview Questions
- Technical Interview Questions
- Easy
- Intermediate
- Hard
- HR Interview Questions
- Eligibility criteria
- Recruitment rounds & assessments
- Tech Mahindra interview questions - Technical round
- Tech Mahindra interview questions - HR round
- Hiring process at Mphasis
- Mphasis technical interview questions
- Mphasis HR interview questions
- About Mphasis
- Technical interview questions
- HR interview questions
- Recruitment process
- About Virtusa
- Goldman Sachs Interview Process
- Technical Questions for Goldman Sachs Interview
- Sample HR Question for Goldman Sachs Interview
- About Goldman Sachs
- Nagarro Recruitment Process
- Nagarro HR Interview Questions
- Nagarro Aptitude Test Questions
- Nagarro Technical Test Questions
- About Nagarro
- PwC Recruitment Process
- PwC Technical Interview Questions: Freshers and Experienced
- PwC Interview Questions for HR Rounds
- PwC Interview Preparation
- Frequently Asked Questions
- EY Technical Interview Questions (2023)
- EY Interview Questions for HR Round
- About EY
- Morgan Stanley Recruitment Process
- HR Questions for Morgan Stanley Interview
- HR Questions for Morgan Stanley Interview
- About Morgan Stanley
- Recruitment Process at Flipkart
- Technical Flipkart Interview Questions
- Code-Based Flipkart Interview Questions
- Sample Flipkart Interview Questions- HR Round
- Conclusion
- FAQs
- Recruitment Process at Paytm
- Technical Interview Questions for Paytm Interview
- HR Sample Questions for Paytm Interview
- About Paytm
- Most Probable Accenture Interview Questions
- Accenture Technical Interview Questions
- Accenture HR Interview Questions
- Amazon Recruitment Process
- Amazon Interview Rounds
- Common Amazon Interview Questions
- Amazon Interview Questions: Behavioral-based Questions
- Amazon Interview Questions: Leadership Principles
- Company-specific Amazon Interview Questions
- 43 Top Technical/ Coding Amazon Interview Questions
- Juspay Recruitment: Stages and Timeline
- Juspay Interview Questions and Answers
- How to prepare for Juspay interview questions
- Prepare for the Juspay Interview: Stages and Timeline
- Frequently Asked Questions
- Adobe Interview Questions - Technical
- Adobe Interview Questions - HR
- Recruitment Process at Adobe
- About Adobe
- Cisco technical interview questions
- Sample HR interview questions
- The recruitment process at Cisco
- About Cisco
- JP Morgan interview questions (Technical round)
- JP Morgan interview questions HR round)
- Recruitment process at JP Morgan
- About JP Morgan
- Wipro Elite NTH: Selection Process
- Wipro Elite NTH Technical Interview Questions
- Wipro Elite NTH Interview Round- HR Questions
- BYJU's BDA Interview Questions
- BYJU's SDE Interview Questions
- BYJU's HR Round Interview Questions
- A Quick Overview of the KPMG Recruitment Process
- Technical Questions for KPMG Interview
- HR Questions for KPMG Interview
- About KPMG
- DXC Technology Interview Process
- DCX Technical Interview Questions
- Sample HR Questions for DXC Technology
- About DXC Technology
- Recruitment Process at PayPal
- Technical Questions for PayPal Interview
- HR Sample Questions for PayPal Interview
- About PayPal
- Capgemini Recruitment Rounds
- Capgemini Interview Questions: Technical round
- Capgemini Interview Questions: HR round
- Preparation tips
- FAQs
- Technical interview questions for Siemens
- Sample HR questions for Siemens
- The recruitment process at Siemens
- About Siemens
- HCL Technical Interview Questions
- HR Interview Questions
- HCL Technologies Recruitment Process
- List of EPAM Interview Questions for Technical Interviews
- About EPAM
- Atlassian Interview Process
- Top Skills for Different Roles at Atlassian
- Atlassian Interview Questions: Technical Knowledge
- Atlassian Interview Questions: Behavioral Skills
- Atlassian Interview Questions: Tips for Effective Preparation
- Walmart Recruitment Process
- Walmart Interview Questions and Sample Answers (HR Round)
- Walmart Interview Questions and Sample Answers (Technical Round)
- Tips for Interviewing at Walmart and Interview Preparation Tips
- Frequently Asked Questions
- Uber Interview Questions For Engineering Profiles: Coding
- Technical Uber Interview Questions: Theoretical
- Uber Interview Question: HR Round
- Uber Recruitment Procedure
- About Uber Technologies Ltd.
- Intel Technical Interview Questions
- Computer Architecture Intel Interview Questions
- Intel DFT Interview Questions
- Intel Interview Questions for Verification Engineer Role
- Recruitment Process Overview
- Important Accenture HR Interview Questions
- Points to remember
- What is Selenium?
- What are the components of the Selenium suite?
- Why is it important to use Selenium?
- What's the major difference between Selenium 3.0 & Selenium 2.0?
- What is Automation testing and what are its benefits?
- What are the benefits of Selenium as an Automation Tool?
- What are the drawbacks to using Selenium for testing?
- Why should Selenium not be used as a web application or system testing tool?
- Is it possible to use selenium to launch web browsers?
- What does Selenese mean?
- What does it mean to be a locator?
- Identify the main difference between "assert", and "verify" commands within Selenium
- What does an exception test in Selenium mean?
- What does XPath mean in Selenium? Describe XPath Absolute & XPath Relation
- What is the difference in Xpath between "//"? and "/"?
- What is the difference between "type" and the "typeAndWait" commands within Selenium?
- Distinguish between findElement() & findElements() in context of Selenium
- How long will Selenium wait before a website is loaded fully?
- What is the difference between the driver.close() and driver.quit() commands in Selenium?
- Describe the different navigation commands that Selenium supports
- What is Selenium's approach to the same-origin policy?
- Explain the difference between findElement() in Selenium and findElements()
- Explain the pause function in SeleniumIDE
- Explain the differences between different frameworks and how they are connected to Selenium's Robot Framework
- What are your thoughts on the Page Object Model within the context of Selenium
- What are your thoughts on Jenkins?
- What are the parameters that selenium commands come with a minimum?
- How can you tell the differences in the Absolute pathway as well as Relative Path?
- What's the distinction in Assert or Verify declarations within Selenium?
- What are the points of verification that are in Selenium?
- Define Implicit wait, Explicit wait, and Fluent
- Can Selenium manage windows-based pop-ups?
- What's the definition of an Object Repository?
- What is the main difference between obtainwindowhandle() as well as the getwindowhandles ()?
- What are the various types of Annotations that are used in Selenium?
- What is the main difference in the setsSpeed() or sleep() methods?
- What is the way to retrieve the alert message?
- How do you determine the exact location of an element on the web?
- Why do we use Selenium RC?
- What are the benefits or advantages of Selenium RC?
- Do you have a list of the technical limitations when making use of Selenium RC? Selenium RC?
- What's the reason to utilize the TestNG together with Selenium?
- What Language do you prefer to use to build test case sets in Selenium?
- What are Start and Breakpoints?
- What is the purpose of this capability relevant in relation to Selenium?
- When do you use AutoIT?
- Do you have a reason why you require Session management in Selenium?
- Are you able to automatize CAPTCHA?
- How can we launch various browsers on Selenium?
- Why should you select Selenium rather than QTP (Quick Test Professional)?
- Airbus Interview Questions and Answers: HR/ Behavioral
- Industry/ Company-Specific Airbus Interview Questions
- Airbus Interview Questions and Answers: Aptitude
- Airbus Software Engineer Interview Questions and Answers: Technical
- Importance of Spring Framework
- Spring Interview Questions (Basic)
- Advanced Spring Interview Questions
- C++ Interview Questions and Answers: The Basics
- C++ Interview Questions: Intermediate
- C++ Interview Questions And Answers With Code Examples
- C++ Interview Questions and Answers: Advanced
- Test Your Skills: Quiz Time
- MBA Interview Questions: B.Com Economics
- B.Com Marketing
- B.Com Finance
- B.Com Accounting and Finance
- Business Studies
- Chartered Accountant
- Q1. Please tell us something about yourself/ Introduce yourself to us.
- Q2. Describe yourself in one word.
- Q3. Tell us about your strengths and weaknesses.
- Q4. Why did you apply for this job/ What attracted you to this role?
- Q5. What are your hobbies?
- Q6. Where do you see yourself in five years OR What are your long-term goals?
- Q7. Why do you want to work with this company?
- Q8. Tell us what you know about our organization
- Q9. Do you have any idea about our biggest competitors?
- Q10. What motivates you to do a good job?
- Q11. What is an ideal job for you?
- Q12. What is the difference between a group and a team?
- Q13. Are you a team player/ Do you like to work in teams?
- Q14. Are you good at handling pressure/ deadlines?
- Q15. When can you start?
- Q16. How flexible are you regarding overtime?
- Q17. Are you willing to relocate for work?
- Q18. Why do you think you are the right candidate for this job?
- Q19. How can you be an asset to the organization?
- Q20. What is your salary expectation?
- Q21. How long do you plan to remain with this company?
- Q22. What is your objective in life?
- Q23. Would you like to pursue your Master's degree anytime soon?
- Q24. How have you planned to achieve your career goal?
- Q25. Can you tell us about your biggest achievement in life?
- Q26. What was the most challenging decision you ever made?
- Q27. What kind of work environment do you prefer to work in?
- Q28. What is the difference between a smart worker and a hard worker?
- Q29. What will you do if you don't get hired?
- Q30. Tell us three things that are most important for you in a job.
- Q31. Who is your role model and what have you learned from him/her?
- Q32. In case of a disagreement, how do you handle the situation?
- Q33. What is the difference between confidence and overconfidence?
- Q34. If you have more than enough money in hand right now, would you still want to work?
- Q35. Do you have any questions for us?
- Interview Tips for Freshers
- Tell me about yourself
- What are your greatest strengths?
- What are your greatest weaknesses?
- Tell me about something you did that you now feel a little ashamed of
- Why are you leaving (or did you leave) this position??
- 15+ resources for preparing most-asked interview questions
- CoCubes Interview Process Overview
- Common CoCubes Interview Questions
- Key Areas to Focus on for CoCubes Interview Preparation
- Conclusion
- Frequently Asked Questions (FAQs)
- Data Analyst Interview Questions With Answers
- About Data Analyst
Top 50 Paytm Interview Questions With Detailed Answers (2026)
Paytm is among the leading payment platforms in India, with huge market coverage. The company looks forward to hiring a candidate who is a technology enthusiast by nature and wishes to experiment with exciting technologies. However, getting into the Paytm team is not that easy. You need to be well prepared, which is why we have created a list of frequently asked interview questions for technical interviews at Paytm.
Recruitment Process at Paytm
The first step in the interview process at Paytm, much like the first step in any other interview, is for the applicant to submit a job application. If Paytm determines that you have the qualifications necessary for the job, then it will contact you to set up an interview, and you will go through an intense round of interview questions. It is possible that Paytm recruiters offer other jobs to you that are a better match for your qualifications than the one you applied for in the first place.
You will first have a technical phone screening, followed by a series of on-site or online technical interviews with in-depth technical questions once you have been shortlisted for the position. In the vast majority of instances, the duration of both the phone screening and the in-person interview is approximately 45 to 60 minutes. In a nutshell, the interview process at Paytm may be broken down into the following stages:
- Competition in online coding
- Rounds of the technical interviews
- HR round

Technical Interview Questions for Paytm Interview
Here is a list of some essential Paytm interview questions that you must have a look at. These questions have been taken from the personal interview experience of many people and experts.
1. What is seven-layer architecture in the OSI model?
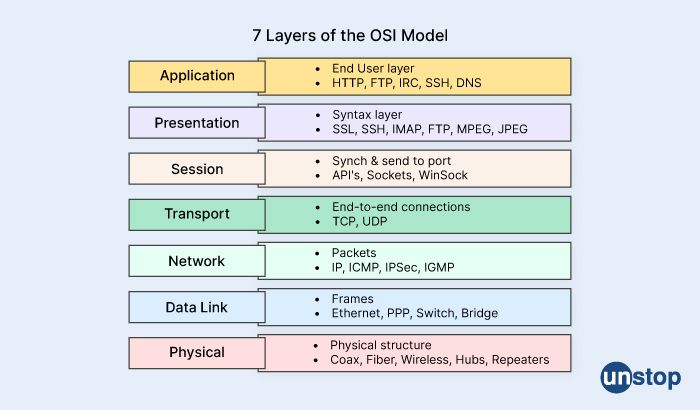
The seven-layer architecture is the commonly used name for the Open Systems Interconnection (OSI) model, which is a conceptual framework for understanding and designing network communication systems.
The seven layers in the OSI model are:
- Physical layer: This layer defines the physical characteristics of the communication medium, such as the electrical, mechanical, and functional specifications.
- Data Link layer: This layer provides reliable transmission of data over the physical layer. It is responsible for error detection and correction, flow control, and framing.
- Network layer: This layer provides routing and forwarding of data between different networks. It also manages the logical addressing and determines the best path for data transmission.
- Transport layer: This layer provides end-to-end communication between applications on different devices. It ensures the reliable and ordered delivery of data and handles congestion control and flow control.
- Session layer: This layer establishes, manages, and terminates communication sessions between applications. It also handles security and synchronization issues.
- Presentation layer: This layer provides a common representation of data that can be understood by different applications. It handles data translation, encryption, and compression.
- Application layer: This layer provides a user interface for accessing network services. It includes protocols such as HTTP, FTP, SMTP, and Telnet.
Experience is the key to opportunity—unlock yours with an internship at Paytm!
2. What is client-server architecture?
Client-server architecture is a computing model where client devices (such as computers, smartphones, or tablets) request services or resources from a server, which provides the requested services or resources. In this model, the client and server software run on different devices, and they communicate with each other over a network, such as the Internet.
The client device typically runs software that provides a user interface for accessing the server's resources or services. For example, a web browser is client software that allows users to request web pages from a web server, which then sends the requested pages back to the client for display. Similarly, a mobile app may be a client that communicates with a server to retrieve and store data.
The server, on the other hand, provides the requested resources or services to the client. It typically runs software that listens for requests from clients, processes the requests, and returns the requested data or resources to the client. The server may also provide additional services such as data storage, authentication, or security.
Client-server architecture is widely used in many different applications and services, including web browsing, email, file sharing, database management, and online gaming. It allows for efficient use of computing resources and enables the separation of concerns between client and server, making it easier to develop, maintain, and scale complex applications.
3. What are the steps in the automation lifecycle?
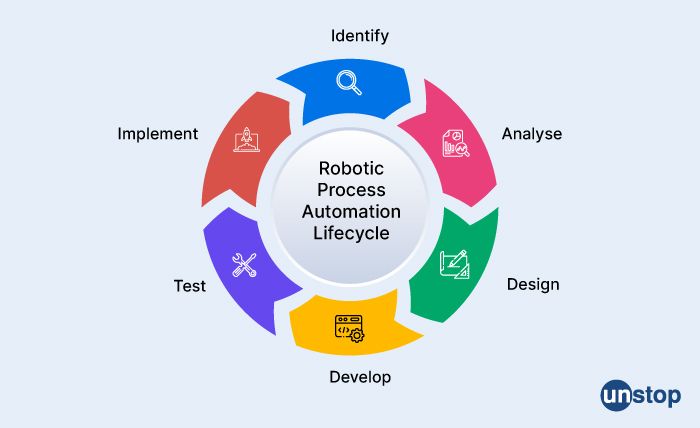
The automation lifecycle consists of several stages or steps that organizations follow to automate their business processes effectively. The steps in the automation lifecycle may vary depending on the methodology and organization, but some of the common steps are:
-
Identifying and selecting the process to automate: The first step is to identify the business process that needs to be automated. Organizations need to analyze the process to ensure that it is suitable for automation and that it provides significant benefits.
-
Analyzing the process: The next step is to analyze the process in detail to identify the requirements, inputs, outputs, and stakeholders involved. This step may also involve process mapping to identify areas of inefficiencies or bottlenecks that can be addressed through automation.
-
Designing the automation solution: Once the process has been analyzed, the next step is to design the automation solution. This step involves defining the scope of the automation, selecting the appropriate tools and technologies, and defining the workflows and rules.
-
Developing and testing the automation solution: In this step, the automation solution is developed and tested. The development involves configuring or programming the selected tools and technologies to perform the desired tasks automatically. The testing step involves verifying that the automation solution performs as expected and meets the identified requirements.
-
Deploying the automation solution: Once the automation solution has been developed and tested, it is deployed in the production environment. This step involves installing the automation solution, configuring it, and testing it again to ensure that it works as expected in the live environment.
-
Monitoring and maintaining the automation solution: After the automation solution has been deployed, it needs to be monitored and maintained to ensure that it continues to perform as expected. This step involves monitoring the system for errors or issues, troubleshooting problems, and performing updates or maintenance as needed.
-
Evaluating the automation solution: The final step is to evaluate the automation solution to determine whether it has achieved the desired benefits and to identify areas for improvement. This step may involve collecting and analyzing data on the process performance and identifying opportunities for further automation or optimization.
4. What is project framework?
A project framework, also known as a project management framework, is a structured approach to managing projects. It is a set of guidelines, processes, and best practices that provide a common language and understanding of how projects are planned, executed, and monitored.
A detailed explanation would be - A project framework provides a standardized approach to managing projects, which can help to improve project outcomes by reducing risks and increasing efficiency. It provides a common language and understanding for project team members, stakeholders, and sponsors, which can improve communication and collaboration. Additionally, it can help to ensure that projects are aligned with organizational goals and objectives.
5. What is socket-based programming?
Socket-based programming is a method of developing network applications that enable communication between computers over a network. It involves using software sockets, which are endpoints that allow applications to send and receive data across a network connection.
In socket-based programming, an application creates a socket and binds it to a specific network address and port. The socket can then send and receive data to and from other sockets on the network. Socket-based programming can be used for many types of network applications, including web servers, email clients, and file transfer applications.
The two most common types of sockets used in socket-based programming are the Transmission Control Protocol (TCP) and the User Datagram Protocol (UDP). TCP provides a reliable, connection-oriented service that guarantees the delivery of data packets in the order they were sent. UDP, on the other hand, provides a connectionless, unreliable service that does not guarantee the delivery of data packets or their order.
6. What are the waits in selenium?
Whenever it comes to running selenium tests, the wait commands are an absolutely necessary component. They provide assistance in observing and diagnosing problems that may arise as a result of variations in the time lag.
It is not uncommon for testers to encounter the error message "Element Not Visible Exception" while executing tests created with selenium. This occurs when “WebDriver” attempts to connect with a specific web element that is experiencing a delay in its loading process. The use of selenium wait commands is required in order to avoid this exception.
The wait commands are used in automated testing to instruct the test execution to wait for a predetermined amount of time before continuing on to the next step. This enables WebDriver to verify if one or more web components are there on the page, if they are visible if they have been enhanced if they are clickable, and so on.
7. What is explicit code?
Explicit code refers to programming code that is written in a clear and unambiguous manner, making it easy to understand and modify. It is typically self-documenting, meaning that it includes clear and descriptive variable names, function names, and comments that make it easy for other developers to understand the code's purpose and functionality.
Explicit code is also characterized by its directness and lack of ambiguity. It avoids using complex or abstract code constructs that can be difficult to understand or prone to error. Instead, explicit code is written using simple and straightforward language that clearly conveys the programmer's intentions.
8. What is the difference between status codes 200 and 201?
HTTP status codes are three-digit codes that are returned by a web server to indicate the status of a request. The two status codes you mentioned, 200 and 201, have different meanings:
-
200 OK: This status code indicates that the request was successful and the server has returned the requested data. This is the most common status code that you will encounter when making HTTP requests.
-
201 Created: This status code indicates that the request was successful and a new resource has been created on the server. This status code is typically returned in response to a POST request that creates a new resource on the server.
In other words, a 200 status code means that the request was successful and the requested data has been returned, whereas a 201 status code means that the request was successful and a new resource has been created on the server.
9. What do you comprehend about the idea of memory that is virtual?
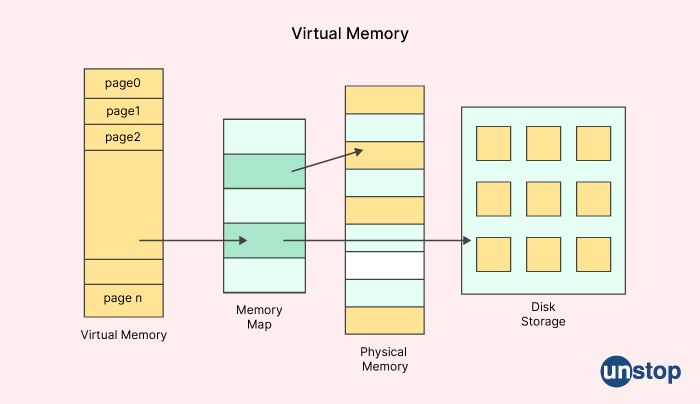
A sort of memory known as virtual memory is made temporarily available on the storage device in question. This memory is only available for use for a limited amount of time. This occurrence takes place when a computer's random access memory (RAM) becomes depleted as a result of several programs executing at the same time. A section of the storage disc is made accessible for usage as random access memory (RAM) by the operating system. Since processing power is spent on moving data around like that in virtual memory rather than carrying out commands, virtual memory is much slower than main memory.
Memory management is broken out in the handbook to operating systems, which explains how the operating system handles memory. When a computer needs to use its virtual memory, there is an increase in the amount of time it takes. The operating system makes use of a process called swapping in order to shift data from random access memory (RAM) to virtual memory. The operating system takes data from processes that are not now being used and stores it in virtual memory rather than the RAM that the computer is currently using.
When it becomes necessary to carry out the procedure once more, the data is stored in RAM and later copied back. When you use virtual memory, the computer moves at a considerably more glacial pace since transferring data to and from a hard disc takes far more time than learning to read and write to RAM.
10. What is meant by the term "callback" when referring to JavaScript?
In JavaScript, a callback is a function that is passed as an argument to another function and is executed by that function when a certain event occurs or a certain task is completed. The function that accepts the callback is known as the "higher-order function". Callbacks are often used in asynchronous programming, where a function needs to wait for a potentially long-running task to complete before it can return a result. Instead of blocking the main thread of execution, the function can accept a callback function that will be called when the task is complete.
For example, in JavaScript, the setTimeout function can be used to execute a function after a certain amount of time has elapsed:
setTimeout(function() {
console.log('Hello, world!');
}, 1000);
In this example, the setTimeout function accepts a callback function as its first argument. The function will be executed after a delay of 1000 milliseconds (1 second) has elapsed. Callbacks can also be used to handle events in the browser, such as mouse clicks or keyboard input. Event listeners are attached to elements in the document, and when an event occurs, the callback function is executed.
11. How do you debug JavaScript code?
Debugging is an important part of the software development process, and JavaScript provides several tools and techniques for debugging code. Here are some common ways to debug JavaScript code:
-
Console.log() statements: One of the most basic ways to debug JavaScript code is to use console.log() statements to output values to the console. You can use console.log() to print variables, function outputs, or other values to help you understand how your code is working.
-
Browser debugging tools: Most modern browsers come with built-in debugging tools that allow you to step through your JavaScript code, set breakpoints, and inspect variables. In Google Chrome, for example, you can open the Developer Tools by pressing F12 and navigate to the Sources tab to see your JavaScript code.
-
Debugging extensions: There are several browser extensions available that can enhance the debugging experience, such as the Firefox Debugger or the React Developer Tools.
-
Linters: Linters are tools that analyze your code for potential errors and coding style issues. By using a linter like ESLint, you can catch potential errors before running your code.
-
Automated testing: Writing tests for your code can help you catch errors early on in the development process. Automated testing tools like Jest or Mocha can help you test your code and catch bugs before they make it into production.
-
Debugging in IDEs: Many IDEs (Integrated Development Environments) such as Visual Studio Code, WebStorm, or Eclipse, offer features like code highlighting, code completion, syntax analysis, and more to ease the debugging process.
12. How would you interpret the message written on a cookie?
Cookies are small text files that are stored on a user's device by a website. Cookies can be used to store information about the user's browsing activity, preferences, and login status, among other things.
When a message is written on a cookie, it typically means that the website is storing some information about the user's activity or preferences on their device. The message on the cookie can be read by the website when the user visits again, allowing the website to personalize the user's experience or remember their login information.
For example, a website might write a message on a cookie that indicates the user's preferred language or shopping cart contents. When the user returns to the website, the website can read the message on the cookie and use it to customize the user's experience.
It's important to note that cookies can also be used for tracking purposes, which has raised concerns about privacy and security. Most modern web browsers offer options for managing cookies and blocking third-party cookies, which can help users protect their privacy while browsing the web.
13. What is the difference between the let and var keywords?

In JavaScript, var and let are both used to declare variables, but there are some important differences between the two.
-
Scope: Variables declared with
varare function-scoped, while variables declared withletare block-scoped. This means that a variable declared withvaris available throughout the entire function, while a variable declared withletis only available within the block where it was declared. -
Hoisting: Variables declared with
varare hoisted to the top of their scope, which means that they are available throughout the entire scope, even before they are declared. Variables declared withletare not hoisted, which means that they are not available until they are declared. -
Re-assignability: Variables declared with
varcan be re-assigned to a new value within their scope, while variables declared withletcan also be re-assigned, but only within the block where they were declared.
Here's an example that demonstrates the difference between var and let:
function example() {
var x = 1;
if (true) {
var x = 2;
console.log(x); // output: 2
}
console.log(x); // output: 2
}
function example2() {
let y = 1;
if (true) {
let y = 2;
console.log(y); // output: 2
}
console.log(y); // output: 1
}
ZnVuY3Rpb24gZXhhbXBsZSgpIHsKdmFyIHggPSAxOwppZiAodHJ1ZSkgewp2YXIgeCA9IDI7CmNvbnNvbGUubG9nKHgpOyAvLyBvdXRwdXQ6IDIKfQpjb25zb2xlLmxvZyh4KTsgLy8gb3V0cHV0OiAyCn0KCmZ1bmN0aW9uIGV4YW1wbGUyKCkgewpsZXQgeSA9IDE7CmlmICh0cnVlKSB7CmxldCB5ID0gMjsKY29uc29sZS5sb2coeSk7IC8vIG91dHB1dDogMgp9CmNvbnNvbGUubG9nKHkpOyAvLyBvdXRwdXQ6IDEKfQ==
14. What is the difference between properties and attributes?
An attribute is an HTML attribute that is included in the opening tag of an HTML element. Attributes are used to provide additional information about an element, such as its ID, class, or data. Attributes do not affect the visual appearance of an element but can be used to target elements in CSS or to provide information to JavaScript.
A property, on the other hand, is a CSS property that is used to style an element. Properties affect the visual appearance of an element, such as its color, font size, or margin. Properties are set using CSS and can be applied to HTML elements using selectors.
Here's an example to illustrate the difference:
<button>Click me!</button>
.btn {
background-color: blue;
color: white;
}document.getElementById("myButton").disabled = true;
In this example, id and class are attributes of the button element. They provide additional information about the element but do not affect its visual appearance. The disabled property, on the other hand, is a property that is set using JavaScript to disable the button. The .btn CSS class sets the background color and text color of the button, which affects its visual appearance.
15. What is the JavaScript for-in loop used for?

The for-in loop is a JavaScript loop that is used to iterate over the properties of an object. It allows you to loop through all the enumerable properties of an object, including properties that are inherited from its prototype.
The syntax of the for-in loop is as follows:
for (var prop in object) {
// do something with object[prop]
}
In this syntax, prop is a variable that will be assigned to each property name in the object during each iteration of the loop. object is the object you want to loop over.
Here's an example of how you can use the for-in loop to iterate over the properties of an object:
var person = {
name: 'John',
age: 30,
address: {
street: '123 Main St',
city: 'Anytown',
state: 'CA'
}
};
for (var prop in person) {
console.log(prop + ': ' + person[prop]);
}
dmFyIHBlcnNvbiA9IHsKbmFtZTogJ0pvaG4nLAphZ2U6IDMwLAphZGRyZXNzOiB7CnN0cmVldDogJzEyMyBNYWluIFN0JywKY2l0eTogJ0FueXRvd24nLApzdGF0ZTogJ0NBJwp9Cn07Cgpmb3IgKHZhciBwcm9wIGluIHBlcnNvbikgewpjb25zb2xlLmxvZyhwcm9wICsgJzogJyArIHBlcnNvbltwcm9wXSk7Cn0=
16. What purpose do the postponed scripts provide in the JavaScript programming language?
Postponed scripts in JavaScript refer to scripts that have been marked with the defer attribute in an HTML document. When a script is marked as defer, it tells the browser to download the script in the background while continuing to parse the HTML document. The script will be executed after the HTML document has been fully parsed. The purpose of deferred scripts is to speed up the loading of web pages. By deferring the loading and execution of scripts, the browser can render the page faster and give users a better experience.
Unlock endless job & internship opportunities!
17. What do we mean by closure?
When a variable that is also defined outside of the current scope is accessible from within some inner scope, a closure is produced. Closures can also be created when a variable that would be defined inside the current scope is accessed. It allows you to access the scope of an outer function from within a function that is inside another function. When a function is generated in JavaScript, a closure is also produced at the same moment. To take advantage of a closure, you only need to define a function inside of another function and then make that function public.
18. Where can I find an explanation of the naming standards for variables in JavaScript?
JavaScript naming conventions are widely used by developers to make their code more readable and maintainable. Here are some common naming standards for variables in JavaScript:
-
Use camelCase: Variable names in JavaScript should use camelCase, where the first word is in lowercase and subsequent words are capitalized, with no spaces or underscores between words. For example:
firstName,lastName,myVariable. -
Use descriptive names: Variable names should be descriptive and indicate what the variable represents. Avoid using generic names like
x,y, ortemp. -
Use meaningful abbreviations: If you need to use an abbreviation in a variable name, make sure it's a well-known abbreviation and that it makes the variable name more readable. For example,
numfornumber. -
Avoid starting with underscores: Although it's allowed in JavaScript, it's a convention to avoid starting variable names with an underscore.
-
Use lowercase for boolean variables: Boolean variables should be in lowercase. For example,
isConnected,hasPermission,canSubmit. -
Use uppercase for constants: Constants should be in all uppercase with underscores separating words. For example,
MAX_WIDTH,PI,SECRET_KEY.
19. How can you remove a cookie from your computer using JavaScript?
To remove a cookie from a computer using JavaScript, you can set the cookie's expiration date to a date in the past. This will cause the browser to delete the cookie. Here's an example of how to do this:
function deleteCookie(name) {
document.cookie = name + '=; expires=Thu, 01 Jan 1970 00:00:01 GMT;';
}
In this example, the deleteCookie function takes a cookie name as its parameter. The function sets the cookie's expiration date to January 1, 1970 (which is in the past), effectively deleting the cookie. The function does this by setting the document.cookie property to the cookie name and expiration date.
20. What is the distinction between a value that is null and one that is undefined?
In JavaScript, null and undefined are two distinct values that indicate different things:
-
nullis a value that represents the intentional absence of any object value. It is a special value that can be assigned to a variable to indicate that the variable has no value. For example, if you have a variable that should hold an object, but you haven't assigned an object to it yet, you can assign it the valuenullto indicate that it has no value yet. -
undefinedis a value that represents the absence of any value, including the absence of a defined value. It is a value that is automatically assigned to a variable that has not been assigned a value, or to a function parameter that has not been passed a value.
Here's an example to illustrate the difference between null and undefined:
let x = null;
let y;
console.log(x); // Output: null
console.log(y); // Output: undefined
bGV0IHggPSBudWxsOwpsZXQgeTsKCmNvbnNvbGUubG9nKHgpOyAvLyBPdXRwdXQ6IG51bGwKY29uc29sZS5sb2coeSk7IC8vIE91dHB1dDogdW5kZWZpbmVk
In this example, the variable x has been explicitly assigned the value null, while the variable y has not been assigned any value. When we log the values of these variables, we see that x is logged as null, while y is logged as undefined.
21. What is meant by the term "event bubbling" when referring to “JavaScript"?
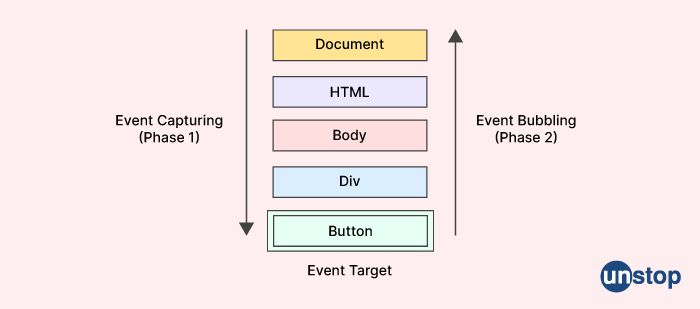
In the HTML DOM API, the term 'event bubbling' refers to a method of event propagation that takes place when an event takes place in one element that is contained within another element and both elements have registered a handle for the incident in question.
During the bubbling process, the event is first recorded and processed by the element that is located closest to the center and then it is passed on to components that are further away. This event is where the execution begins and it will continue up the event tree until it reaches its parent element. Then, control of the execution moves up to the element's parent and so on up the hierarchy until it reaches the body element.
22. What does the not a number (NaN) symbol mean in “JavaScript”?
In JavaScript, NaN is a special value that represents "Not a Number". It is a value that is returned when a mathematical operation or function is performed on a value that is not a valid number.
For example, consider the following code:
let x = "hello";
let y = parseInt(x);
console.log(y); // Output: NaN
bGV0IHggPSAiaGVsbG8iOwpsZXQgeSA9IHBhcnNlSW50KHgpOwpjb25zb2xlLmxvZyh5KTsgLy8gT3V0cHV0OiBOYU4=
In this code, the variable x is assigned the value "hello", which is not a valid number. When we try to parse x as an integer using the parseInt() function, the result is NaN. NaN is often used as a way to indicate that a mathematical operation or function has failed or returned an invalid result.
23. What is the term prompt box mean when referring to JavaScript?

A prompt box is a box that provides the user with a text box and enables customers to enter input into the prompt box. The prompt() method causes a dialog box to be displayed on the screen, which then requests input from the site visitor. If you want the user to enter a value before they may proceed to the next page, you can ask them to do so through the usage of a prompt box. After the user enters an input value, a popup box will appear, at which point the user will be required to click either "OK" or "Cancel" to continue.
24. What are these default parameters we keep hearing about?
Default parameters are a feature in JavaScript that allows you to specify default values for function parameters. With default parameters, you can provide a default value for a function parameter in case the parameter is not passed or is passed with a value of undefined.
Here's an example of how you can use default parameters in a function:
function greet(name = 'World') {
console.log(`Hello, ${name}!`);
}
greet(); // Output: Hello, World!
greet('Alice'); // Output: Hello, Alice!
ZnVuY3Rpb24gZ3JlZXQobmFtZSA9ICdXb3JsZCcpIHsKY29uc29sZS5sb2coYEhlbGxvLCAke25hbWV9IWApOwp9CgpncmVldCgpOyAvLyBPdXRwdXQ6IEhlbGxvLCBXb3JsZCEKZ3JlZXQoJ0FsaWNlJyk7IC8vIE91dHB1dDogSGVsbG8sIEFsaWNlIQ==
25. What is meant by the phrase inline function when referring to C++?
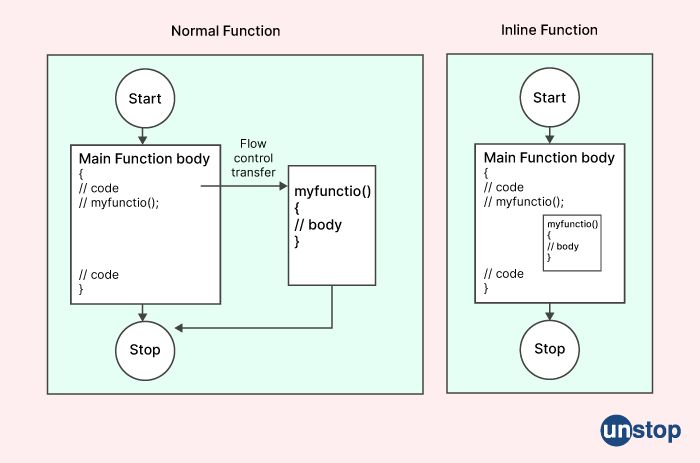
In C++, an inline function is a function that is expanded in place by the compiler, rather than being called a regular function. When a function is declared as inline, the compiler will attempt to replace calls to the function with the actual function code, rather than generating a function call at runtime.
Here's an example of how to define an inline function in C++:
#include
inline int add(int x, int y) {
return x + y;
}
int main() {
int a = 2, b = 3;
int result = add(a, b); // The compiler will replace this call with the function code.
std::cout << "Result: " << result << std::endl;
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgoKaW5saW5lIGludCBhZGQoaW50IHgsIGludCB5KSB7CnJldHVybiB4ICsgeTsKfQoKaW50IG1haW4oKSB7CmludCBhID0gMiwgYiA9IDM7CmludCByZXN1bHQgPSBhZGQoYSwgYik7IC8vIFRoZSBjb21waWxlciB3aWxsIHJlcGxhY2UgdGhpcyBjYWxsIHdpdGggdGhlIGZ1bmN0aW9uIGNvZGUuCnN0ZDo6Y291dCA8PCAiUmVzdWx0OiAiIDw8IHJlc3VsdCA8PCBzdGQ6OmVuZGw7CnJldHVybiAwOwp9
26. Differentiate between a class and a structure.
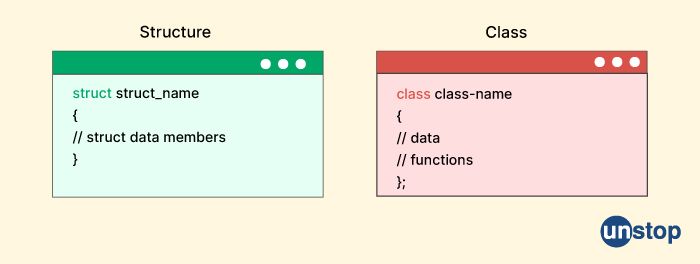
In C++, a class and a structure are both user-defined data types that allow you to group together variables of different data types and functions that operate on those variables. However, there are some differences between classes and structures:
-
Default Member Access: In a class, members are private by default, meaning that they can only be accessed by member functions and friends of the class. In a structure, members are public by default, meaning that they can be accessed from outside the structure.
-
Inheritance: Classes can be inherited using the
classkeyword, while structures cannot be inherited. -
Usage: Classes are typically used for implementing complex data structures and algorithms, while structures are more commonly used for storing simple data types that don't require complex methods.
-
Constructors and Destructors: Classes can have constructors and destructors, which are special member functions that are automatically called when an object is created or destroyed. Structures can also have constructors and destructors in C++11 and later, but they were not supported in earlier versions of the language.
-
Type of Data: Structures are typically used to represent collections of related data that don't have behavior associated with them. Classes, on the other hand, are used to represent objects that have behavior associated with them.
Here's an example that illustrates some of the differences between classes and structures in C++:
#include
class MyClass {
private:
int x;
public:
MyClass(int x) {
this->x = x;
}
void printX() {
std::cout << "X = " << x << std::endl;
}
};
struct MyStruct {
int x;
void printX() {
std::cout << "X = " << x << std::endl;
}
};
int main() {
MyClass obj1(5);
obj1.printX(); // Output: X = 5
MyStruct obj2 = {10};
obj2.printX(); // Output: X = 10
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgoKY2xhc3MgTXlDbGFzcyB7CnByaXZhdGU6CmludCB4OwoKcHVibGljOgpNeUNsYXNzKGludCB4KSB7CnRoaXMtPnggPSB4Owp9Cgp2b2lkIHByaW50WCgpIHsKc3RkOjpjb3V0IDw8ICJYID0gIiA8PCB4IDw8IHN0ZDo6ZW5kbDsKfQp9OwoKc3RydWN0IE15U3RydWN0IHsKaW50IHg7Cgp2b2lkIHByaW50WCgpIHsKc3RkOjpjb3V0IDw8ICJYID0gIiA8PCB4IDw8IHN0ZDo6ZW5kbDsKfQp9OwoKaW50IG1haW4oKSB7Ck15Q2xhc3Mgb2JqMSg1KTsKb2JqMS5wcmludFgoKTsgLy8gT3V0cHV0OiBYID0gNQoKTXlTdHJ1Y3Qgb2JqMiA9IHsxMH07Cm9iajIucHJpbnRYKCk7IC8vIE91dHB1dDogWCA9IDEwCgpyZXR1cm4gMDsKfQ==
27. If a class is derived from another class, does it inherit or does it not inherit?
When a class is derived from another class, it inherits the members of the base class, unless they are marked as private. In C++, the public and protected members of the base class are inherited by the derived class, while the private members are not inherited. Inheritance is a fundamental concept in object-oriented programming, and it allows you to create new classes that are based on existing classes, reusing their properties and behavior. The derived class can add new members or modify the behavior of the base class, but it also has access to all the members of the base class.
Here's an example that illustrates how a derived class inherits the members of its base class in C++:
#include
class Base {
public:
int x;
void printX() {
std::cout << "X = " << x << std::endl;
}
};
class Derived : public Base {
public:
int y;
void printY() {
std::cout << "Y = " << y << std::endl;
}
};
int main() {
Derived obj;
obj.x = 5;
obj.y = 10;
obj.printX(); // Output: X = 5
obj.printY(); // Output: Y = 10
return 0;
}
I2luY2x1ZGUgPGlvc3RyZWFtPgoKY2xhc3MgQmFzZSB7CnB1YmxpYzoKaW50IHg7CnZvaWQgcHJpbnRYKCkgewpzdGQ6OmNvdXQgPDwgIlggPSAiIDw8IHggPDwgc3RkOjplbmRsOwp9Cn07CgpjbGFzcyBEZXJpdmVkIDogcHVibGljIEJhc2UgewpwdWJsaWM6CmludCB5Owp2b2lkIHByaW50WSgpIHsKc3RkOjpjb3V0IDw8ICJZID0gIiA8PCB5IDw8IHN0ZDo6ZW5kbDsKfQp9OwoKaW50IG1haW4oKSB7CkRlcml2ZWQgb2JqOwpvYmoueCA9IDU7Cm9iai55ID0gMTA7Cm9iai5wcmludFgoKTsgLy8gT3V0cHV0OiBYID0gNQpvYmoucHJpbnRZKCk7IC8vIE91dHB1dDogWSA9IDEwCgpyZXR1cm4gMDsKfQ==
28. What are 'virtual functions'?
The base class may supply an implementation for a virtual function, but derived classes can provide their own in its stead using virtual functions.
Whenever we attempt to access the object of a child class by using a pointer from the base class, we run into ambiguity because the base class and the child class both have functions with almost the same name. Since we are making use of a pointer to the base class, the function that will be called is the one that is found in the base class and has the same name.
We add the word "virtual" before the function prototype mostly in the base class so that there is no longer any room for confusion about what should be done. To put it another way, we transform this polymorphic function into a virtual one. We can get rid of the uncertainty and access all of the functions of the child classes in the right way by employing a base class reference. Thanks to the utilization of a virtual function!
29. What is the meaning of the term friend class?
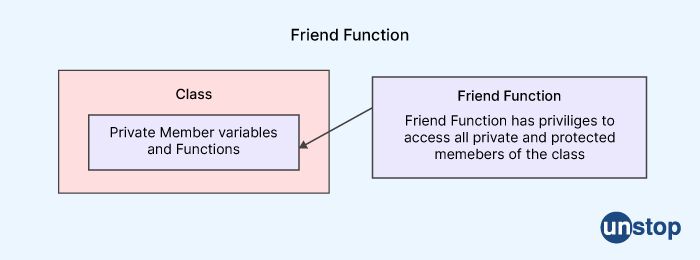
In C++, the term "friend class" refers to a class that is granted access to the private and protected members of another class. A friend class is declared using the friend keyword, which allows it to access the private and protected members of the class it is declared in.
The friend class declaration must appear in the class definition of the class that grants access. It can be placed either in the public, protected, or private section of the class definition, but it does not affect the access level of the members of the friend class.
30. What is meant by the phrase "exception handling"? Does the C++ programming language provide handling of exceptions?
Exception handling is a programming mechanism that allows a program to detect and respond to exceptional situations, such as errors or unexpected events, in a controlled and predictable manner. The goal of exception handling is to enable the program to recover from errors and continue its execution, rather than crashing or producing incorrect results.
In C++, the language provides built-in support for exception handling through the try-catch statement. The try block contains the code that may potentially throw an exception, while the catch block handles the exception that is thrown. If an exception is thrown within the try block, the program jumps to the appropriate catch block to handle the exception.
Here's an example of using exception handling in C++:
#include
int main() {
try {
int num1, num2;
std::cout << "Enter two numbers: ";
std::cin >> num1 >> num2;
if (num2 == 0) {
throw "Division by zero";
}
std::cout << "Result: " << num1 / num2 << std::endl;
}
catch (const char* msg) {
std::cout << "Error: " << msg << std::endl;
}
return 0;
}
aW5jbHVkZSA8aW9zdHJlYW0+CgppbnQgbWFpbigpIHsKdHJ5IHsKaW50IG51bTEsIG51bTI7CnN0ZDo6Y291dCA8PCAiRW50ZXIgdHdvIG51bWJlcnM6ICI7CnN0ZDo6Y2luID4+IG51bTEgPj4gbnVtMjsKCmlmIChudW0yID09IDApIHsKdGhyb3cgIkRpdmlzaW9uIGJ5IHplcm8iOwp9CgpzdGQ6OmNvdXQgPDwgIlJlc3VsdDogIiA8PCBudW0xIC8gbnVtMiA8PCBzdGQ6OmVuZGw7Cn0KY2F0Y2ggKGNvbnN0IGNoYXIqIG1zZykgewpzdGQ6OmNvdXQgPDwgIkVycm9yOiAiIDw8IG1zZyA8PCBzdGQ6OmVuZGw7Cn0KCnJldHVybiAwOwp9
31. What is meant by the phrase "iterator class"?
In C++, an iterator class is a class that allows us to traverse or iterate over a collection of data elements, such as an array, a vector, a list, or a map. Iterators provide a unified interface for accessing the elements of a container, regardless of the specific type of container, and enable us to perform operations such as iterating forward or backward, accessing elements by index, checking for the end of the sequence, and modifying the values of elements.
The C++ Standard Library provides a set of predefined iterator classes that can be used with various containers, including:
-
Input iterators: allow read-only access to a sequence of elements, and support operations such as dereferencing, incrementing, and testing for equality or inequality. Examples of input iterators include
istream_iterator,istreambuf_iterator, andforward_iterator. -
Output iterators: allow write-only access to a sequence of elements, and support operations such as dereferencing, incrementing, and assignment. Examples of output iterators include
ostream_iteratorandback_insert_iterator. -
Forward iterators: allow both read and write access to a sequence of elements, and support operations such as dereferencing, incrementing, and testing for equality or inequality. Examples of forward iterators include
vector::iteratorandlist::iterator. -
Bidirectional iterators: allow bidirectional traversal of a sequence of elements, and support operations such as decrementing and testing for inequality. Examples of bidirectional iterators include
list::iteratoranddeque::iterator. -
Random-access iterators: allow random access to a sequence of elements, and support operations such as addition, subtraction, indexing, and comparison. Examples of random-access iterators include
vector::iterator,deque::iterator, andarray::iterator.
Iterator classes provide a powerful and flexible way to work with data collections in C++ and are a fundamental concept in many algorithms and data structures.
32. What precisely is meant by the term "function overriding"?
In C++, function overriding refers to a feature of object-oriented programming where a subclass provides a different implementation of a virtual function that is already defined in its parent class. When a virtual function is overridden in a subclass, the subclass function with the same name, parameters, and return type as the parent function is called instead of the parent function when the program is executed and the object is of the subclass type.
Function overriding is used to implement polymorphism in C++, which allows objects of different classes to be treated as if they are of the same class hierarchy. It enables the code to be more flexible, extensible, and maintainable, by allowing derived classes to customize the behavior of inherited functions to suit their specific needs. To override a function in a subclass, the function in the parent class must be declared as virtual.
This tells the compiler to allow a subclass to provide its implementation of the function. The syntax for overriding a function in a subclass is to use the same function name, parameter list, and return type as the parent function, and to prefix the function declaration with the virtual keyword.
33. What is meant by the term data abstraction when referring to C++?
Data abstraction is a fundamental concept in object-oriented programming that allows the programmer to hide the implementation details of a data type and expose only the essential features and behaviors that are necessary to use the data type. In C++, data abstraction is achieved through the use of classes, which define a data type by specifying its properties (data members) and operations (member functions).
The idea behind data abstraction is to reduce the complexity of a program by hiding the details of how the data is represented and manipulated. This allows the programmer to focus on the essential aspects of the problem at hand without being distracted by low-level details. In addition, data abstraction helps to modularize the program by separating the interface (what the class does) from the implementation (how the class does it).
C++ provides several features that support data abstraction, including:
- Access modifiers (public, private, and protected) that control the visibility of class members.
- Constructors and destructors that initialize and clean up the object's state.
- Member functions that define the object's behavior and provide an interface to interact with the object's state.
- Operator overloading allows the object to be used in expressions and operations.
By using data abstraction, C++ programs can be designed to be more modular, maintainable, and extensible, as changes to the implementation details of a data type do not affect the code that uses the data type.
34. What does it mean when you say that JavaScript uses escape characters?
In JavaScript, escape characters are special characters that are used to represent other characters that cannot be typed directly into a string or a character literal. These special characters are preceded by a backslash () to indicate that they are escape characters.
Escape characters are also used in regular expressions to represent special characters that have a special meaning in the context of the regular expression. For example, the dot (.) character in a regular expression matches any character except for newline characters. However, to match a literal dot character, it must be escaped using the backslash character (.).
35. What constitutes the blue/green deployment pattern?
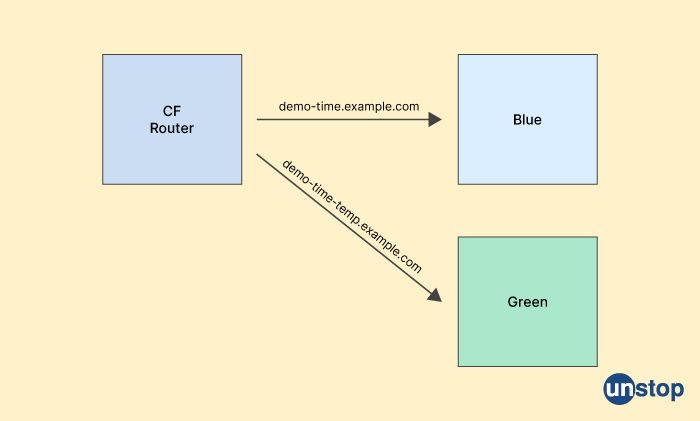
Blue/green deployment is a deployment pattern used in software development to minimize downtime and risk during a release or update. The idea is to have two identical environments, called blue and green, where only one is live at any given time.
The blue environment is the production environment where the current version of the application is running, while the green environment is the staging environment where the updated version is deployed and tested. Once the new version has been fully tested and approved, traffic is shifted from the blue environment to the green environment, making the green environment the new production environment.
Blue/green deployment is often used with continuous integration and continuous deployment (CI/CD) pipelines, where code changes are automatically built, tested, and deployed to the green environment. Once the changes have been approved, they are deployed to the blue environment. This way, the deployment process is automated and can be repeated quickly and reliably.
36. What is meant by the expression continuous testing?
Continuous testing refers to the practice of running automated tests as part of the software delivery pipeline. The goal of this practice is to offer immediate feedback on the business risks that are posed by the most recent release. Every build is put through these kinds of tests continuously to ensure that difficulties with step-switching in the software delivery lifecycle are avoided and that development teams seem to be able to obtain feedback as quickly as possible.
This eliminates the need to re-run all of the tests after each update as well as re-build the project, which leads to a significant increase in velocity with which a developer can complete his/her work. This results in a considerable increase in velocity with which a developer's productivity can be completed.
37. What is meant by the phrase automation testing?
Automation testing, also known as automated testing, is a software testing method that involves the use of software tools to run tests automatically and compare actual results with expected results. It is an efficient and reliable method of software testing that reduces the time and effort required for manual testing.
Automation testing is performed by writing test scripts or test cases that are executed by automation testing tools. These test scripts are designed to perform the same tasks repeatedly, which helps to identify defects, performance issues, and other software errors quickly and accurately.
38. What makes continuous testing such a crucial part of the DevOps process?
Continuous testing is a crucial part of the DevOps process for several reasons:
-
Early detection of defects: Continuous testing allows teams to detect defects early in the development cycle. This helps to avoid the accumulation of technical debt and minimizes the risk of project delays.
-
Faster feedback: It provides immediate feedback to developers, allowing them to identify and address issues quickly. This leads to faster resolution of defects and accelerates the overall development process.
-
Improved quality: Continuous testing ensures that code is thoroughly tested and meets quality standards. This results in a higher-quality end product that is more reliable and less prone to defects.
-
Reduced risk: Continuous testing helps to reduce risk by identifying defects early in the development cycle. This minimizes the risk of costly defects making their way into production and reduces the risk of project delays or failure.
39. What does the term stash refer to in Git?
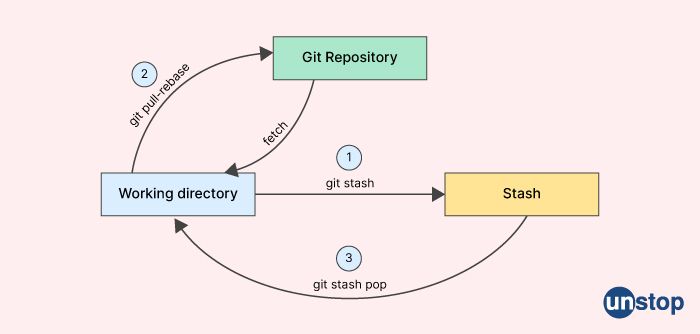
In Git, "stash" refers to a feature that allows you to temporarily save and store changes that are not yet ready to be committed. Stashing is useful when you need to switch to a different branch or work on a different task without committing your current changes.
When you run the git stash command, Git will save your uncommitted changes in a "stash" and revert your working directory to the last committed state. You can later retrieve the saved changes by running the git stash apply command. You can also apply specific stashes or delete stashes using the git stash apply <stash> and git stash drop <stash> commands, respectively.
Stashing is a powerful feature that can help you keep your Git repository organized and make it easier to switch between tasks without losing any work.
40. What is the selenium IDE?
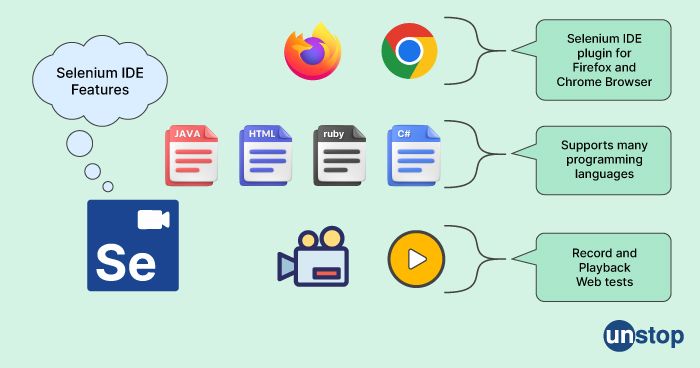
Selenium IDE (Integrated Development Environment) is a tool used for the automated testing of web applications. It is a Firefox plugin that provides a user-friendly interface for recording and playing back tests, without requiring knowledge of programming languages. The recorded tests can be exported in various programming languages such as Java, C#, Ruby, and Python for further modifications or integration into a larger automation framework.
Selenium IDE also provides various features such as commands, assertions, and variables that help in the creation of complex test cases.41.
41. Why do we need to utilize SSL certificates in chef?
SSL (Secure Sockets Layer) certificates are used in Chef to provide secure communication between a Chef server and its clients. Chef uses SSL certificates to verify the identity of the client and the server and to encrypt the data exchanged between them. This ensures that the data being transmitted is secure and cannot be intercepted or modified by unauthorized parties.
SSL certificates are used to establish a secure, encrypted connection between the Chef server and its clients. They are used to verify the identity of the client and the server and to encrypt the data exchanged between them. This helps to prevent eavesdropping, tampering, and other security threats.
In Chef, SSL certificates are used to secure communication between the Chef server and its clients. They are also used to secure communication between Chef servers in a distributed environment. SSL certificates are required for both the Chef server and the Chef clients to communicate securely. Without SSL certificates, the communication between the Chef server and its clients would be vulnerable to security threats.
42. What do you know about the namespaces that are available in Python?
In Python, a namespace is a container that holds a set of identifiers (names) and their corresponding objects. Namespaces are used to avoid naming conflicts and to organize code in a modular and reusable way.
Python provides several namespaces:
-
Built-in namespace: This namespace contains built-in functions, modules, and types such as print(), len(), and str.
-
Global namespace: This namespace contains all the names defined at the module level. These names can be accessed from anywhere in the module.
-
Local namespace: This namespace contains all the names defined inside a function or method. These names are only accessible within the scope of the function or method.
-
Enclosing namespace: This namespace contains the names defined in the enclosing function or method. It is only accessible from within the nested function or method.
Namespaces can be accessed using the dot notation, e.g., module.function(), object.attribute, etc. In Python, namespaces are created dynamically and can be modified at runtime. Developers can create their own namespaces by defining classes, modules, and packages.
43. In Python, what are decorators?
Decorators are a useful tool for augmenting the design of a function without modifying the function's underlying structure. In most cases, decorators are defined before the function whose appearance they improve. To begin the process of applying a decorator, we must first define this same decorator function. Then, after we have written the function that it will be applied to, we simply add the decorator function at the top of the function it needs to be applied to. In order to accomplish this, we use the @ sign before the decorator.
44. How does Python handle the management of memory?
Python has a built-in memory management mechanism called automatic memory management. It uses a technique called reference counting to keep track of objects and their memory allocation. When an object is created, Python assigns a reference count value to it, which is the number of references to that object. When the reference count of an object becomes zero, it means that the object is no longer in use and can be removed from memory.
Python also has a garbage collector that runs periodically to collect and free the memory used by objects with a reference count of zero. The garbage collector identifies and releases objects that are no longer referenced by any part of the program.
Overall, Python's memory management is designed to be simple and easy to use, allowing developers to focus on writing code without having to worry about low-level memory management details.
45. What is an example of a NumPy array?
Here's an example of a NumPy array:
import numpy as np
# Create a 1-dimensional NumPy array
arr1 = np.array([1, 2, 3, 4, 5])
print(arr1) # Output: [1 2 3 4 5]# Create a 2-dimensional NumPy array
arr2 = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(arr2)
# Output:
# [[1 2 3]
# [4 5 6]
# [7 8 9]]
46. What is the swap case() method used in Python?
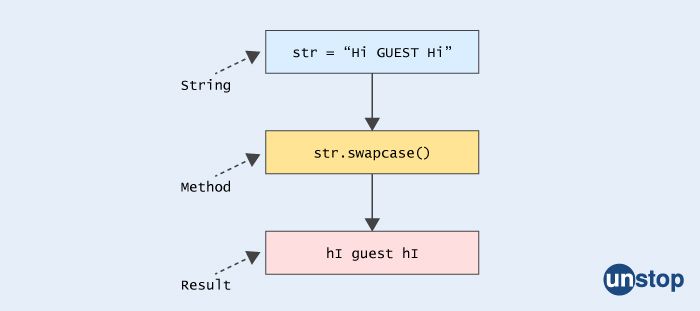
The swapcase() method is a built-in string method in Python that returns a new string with all the alphabetic characters in the original string swapped to their opposite case (upper to lower and vice versa). The non-alphabetic characters remain unchanged.
Here's an example:
original_str = "Hello, World!"
swapped_str = original_str.swapcase()
print(swapped_str) # Output: hELLO, wORLD!
b3JpZ2luYWxfc3RyID0gIkhlbGxvLCBXb3JsZCEiCnN3YXBwZWRfc3RyID0gb3JpZ2luYWxfc3RyLnN3YXBjYXNlKCkKcHJpbnQoc3dhcHBlZF9zdHIpICMgT3V0cHV0OiBoRUxMTywgd09STEQh
47. What is the function of the break statement?
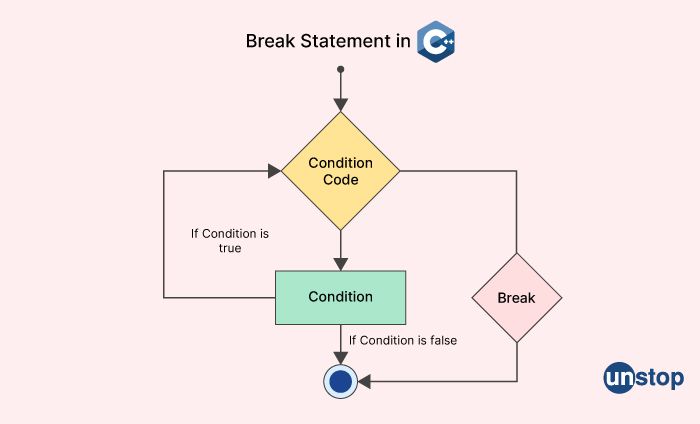
In C++, the break statement is used to terminate the execution of a loop or a switch statement before the normal completion of the loop or switch.
In a loop, when the break statement is encountered inside the loop body, the loop is terminated immediately, and control is transferred to the statement immediately following the loop. This is useful when a certain condition is met inside the loop, and the programmer wants to exit the loop without completing all the remaining iterations.
In a switch statement, the break statement is used to terminate the execution of a switch block. When the break statement is encountered inside a switch case, control is transferred to the statement immediately following the switch block. This is necessary to avoid the execution of subsequent switch cases after the current case has been executed. Without the break statement, the loop or switch statement would continue executing until the end of the loop or switch block, which may not be desirable in all situations.
48. What does the term operator mean in Python?
In Python, an operator is a special symbol or keyword that performs an operation on one or more operands (i.e., variables or values). The most commonly used operators in Python are arithmetic operators (+, -, *, /, %, **), comparison operators (==, !=, >, <, >=, <=), logical operators (and, or, not), assignment operators (=, +=, -=, *=, /=, %=), identity operators (is, is not), and membership operators (in, not in).
49. What is a Python decorator?
In Python, a decorator is a special kind of function that can modify the behavior of other functions or classes. It is a way to wrap a function or class with additional functionality, without having to modify the original function or class.
A decorator function takes another function as its input and returns a new function that wraps the original function. The new function can modify the input function in any way it likes, before calling it or returning it.
Decorators are typically used to add functionality such as logging, caching, or authorization to existing functions or classes, without modifying the original code. They are also used to define reusable code that can be applied to multiple functions or classes.
Here's an example of a simple Python decorator:
def my_decorator(func):
def wrapper():
print("Before function call")
func()
print("After function call")
return wrapper
@my_decorator
def my_function():
print("Hello, world!")
my_function()
ZGVmIG15X2RlY29yYXRvcihmdW5jKToKZGVmIHdyYXBwZXIoKToKcHJpbnQoIkJlZm9yZSBmdW5jdGlvbiBjYWxsIikKZnVuYygpCnByaW50KCJBZnRlciBmdW5jdGlvbiBjYWxsIikKcmV0dXJuIHdyYXBwZXIKCkBteV9kZWNvcmF0b3IKZGVmIG15X2Z1bmN0aW9uKCk6CnByaW50KCJIZWxsbywgd29ybGQhIikKCm15X2Z1bmN0aW9uKCk=
50. What does it mean for arguments to be passed by value or reference?
In computer programming, when we pass arguments to a function or method, we can pass them either by value or by reference.
Passing arguments by value means that a copy of the argument is created, and this copy is passed to the function. This copy can be modified within the function, but the original argument remains unchanged. When the function returns, the copy of the argument is discarded.
Passing arguments by reference means that the memory address of the argument is passed to the function, rather than a copy of the argument itself. This allows the function to modify the original argument, and these modifications will persist even after the function returns.
In some programming languages, such as C++, passing arguments by reference is accomplished using pointers or references. In other languages, such as Java and Python, all arguments are passed by reference, but the language may use a technique called "pass-by-value-of-reference" to make it seem like they are being passed by value.
HR Interview Questions for Paytm
Here are some of the most significant HR interview questions that could be asked during your interview. Have a look at them and prepare the answers for the best performance:
- Which is your favorite programming language?
- How much will you rate your technical abilities on a scale of 1 to 10?
- Can you structure questions and arguments fast during brainstorming?
- What is your job role at your current organization?
- Do you possess leadership and problem-solving abilities?
- How would you deal with experienced people working under you?
- Tell me something about your family background.
- What do you do in your spare time?
- Will you be able to handle a team of 15-20 people at once?
- Explain a leadership role you were delegated at the last job and how you handled it.
About Paytm
Paytm, which stands for "payment through mobile," is the most popular payment processing, electronic wallet, and e-commerce application in India. It is a brand that was introduced by Vijay Sharma in 2010 and is owned by the parent firm, One97 Communications. The software gives you the ability to carry out a variety of activities, such as paying your electricity bills, paying a local vendor, and many other things. It began as online payment and recharge services provider and eventually evolved into a concept for a virtual and marketplace bank that provides a variety of services, including mobile banking, recharge, and an online marketplace, among other things. During the past eight years, Paytm has catered to more than 250 million different users. It can process over 5000 transactions each second because of its capacity.
You may also like to read:
Login to continue reading
And access exclusive content, personalized recommendations, and career-boosting opportunities.
Don't have an account? Sign up
Never miss an
Update

Featured Opportunities
Top-Rated Practice by Students





Subscribe
to our newsletter




Comments
Add comment